变形自动编码器(Deforming Autoencoders)– 学习到解耦的表示形式
本博客针对计算机视觉领域一个新的模型:变形自动编码器。本文是论文 Deforming Autoencoders: Unsupervised Disentangling of Shape and Appearance 主要内容概括和思考,论文地址。部分内容翻译自 https://neurohive.io/en/computer-vision/deforming-autoencoders/ 因为本人水平有限,可能有不足之处,还请谅解。
生成模型在机器学习领域引起了很大的关注,此类型的模型在很多不同的领域都有实际的应用。最让我们熟知的要数生成对抗网络(Generative Adversarial Networks,GAN) 和变分自动编码器(Variational Autoencoders,VAE)了。
尽管寻常的编码器可以学习生成紧凑的表示形式,并且能够很好的对输入进行重建,但是在实际的应用中十分有限。标准的自动编码器有一个基本的问题: 自动编码器将输入数据的分布编码到一个潜在空间(latent space),但是这个潜在空间可能不是连续的,这就造成了无法使用平滑的插值。一种不同类型的自动编码器,即变分自动编码器(Variational Autoencoders,VAE),这种自动编码器的潜在空间被设计为连续的,这使得随机采样和插值很容易,可以很好的解决上述问题。这使 VAE 变得非常流行,并应用于许多不同的任务,尤其是在计算机视觉领域中。
然而,控制和理解深度神经网络,尤其是深度自动编码器是一项艰巨的任务,并且能够控制网络正在学习的内容至关重要。
先前的工作
很多文献,在不同领域上,例如图像和视频处理,文本分析等,都探讨了特征解耦分离的问题。为了达到控制和理解深层网络的目的,必须将变化因子进行解耦。对此,已有很多的研究工作开展。先前很多的工作已经很好的探索到将潜在图像表示分离为不同维度的表示,每一维代表变化中的不同因子。这些因子包括身份,光照,空间支持,低维度的变换(例如旋转,平移,缩放等)以及其它一些更具描述性的属性(例如年龄,性别,是否戴眼镜等)
本文介绍的方法
2018年,ECCV 论文 Deforming Autoencoders: Unsupervised Disentangling of Shape and Appearance中,研究人员基于一个假设:所有的对象实例都是在原型对象(或者说是模板)上进行变形获得的,来分离形状变形和外观纹理。这意味着对象的可变性被分离为作用于对象形状的,与空间变换相关的 变化 和与外观纹理相关的 变化。虽然该想法听起来比较简单,但是这种使用深度自动编码器和无监督学习的模型特征解耦分离能力十分强大。
论文所提出的方法可以解耦分离形状和外观,并将它们作为学习到的低维潜在空间中的变化因子。论文中的模型采用了一种深度学习体系结构,其中包括一个编码器网络,该网络将输入图像编码为两个潜在矢量(形状和外观各一个) ;和两个解码器网络,两个解码器分别以对应的潜在矢量作为输入,并分别输出生成的纹理和变形。
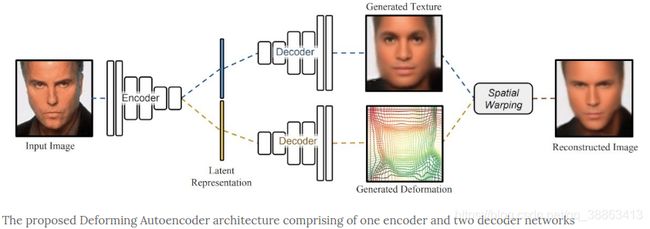
使用独立的解码器网络分别学习外观和变形特征。生成的空间变形用于使纹理变形为观察到的图像坐标。这样,变形自动编码器可以重建输入图像,并同时将形状和外观解耦分离为不同的特征。整个体系结构仅使用简答的图像重建损失以无监督的方式进行训练。
除了变形自动编码器,研究人员还提出了类感知的变形自动编码器。它在学习重建图像的同时,解开由类决定的变化的形状和外观因子。为了达到这个目的,研究人员引入了一个分类器网络,该网络采用一个新的潜在向量(除了用于形状变形和外观纹理的潜在向量之外的另一个潜在向量)用于对类信息进行编码。这种体系结构允许学习基于输入图像类别(而不是联合多模态分布)的混合模型。
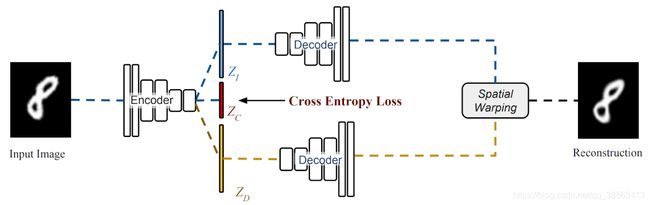
提出的类感知的变形自动编码器。
研究人员表明,使用具有类感知的学习可以大大提高训练的性能和稳定性。直观上,这可以解释为网络学习去分离不同类别之间不同的空间变形。
此外,研究人员提出一种变形自动编码器来学习解耦分离人脸图像的阴影和反照率(这是计算机视觉领域普遍存在的问题),他们称这种变形自动编码器为内在变形自动编码器(Intrinsic-deforming autoencoder),图示如下:
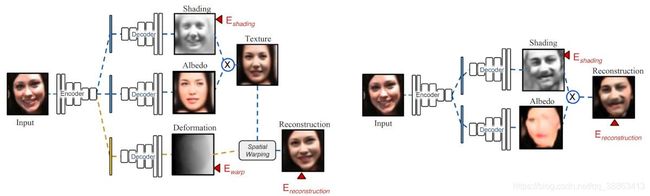
内在变形自动编码器(intrinsic-DAE)
研究结果
实验结果表明,该方法可以成功地解耦形状和外观纹理,同时学习以无监督的方式重建输入图像。他们表明,具有类感知能力的变形自动编码器在重建和外观学习方面都提供了更好的结果。

使用变形自动编码器重建 MNIST 图像的结果。
除了定性评估,所提出的变形自动编码器还针对地标定位精度进行了量化的评估。这种方法在以下几种方面进行评估:
- 无监督的图像对齐 / 外观推断。
- 为形状和外观学习语义上有意义的流形。
- 无监督的内在分解(分解为阴影和反照率)
- 无监督地标检测
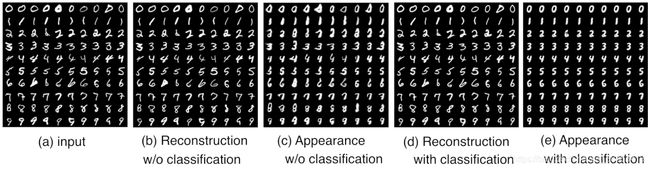
使用类感知的变形自动编码器对 MNIST 图像进行图像重建的结果
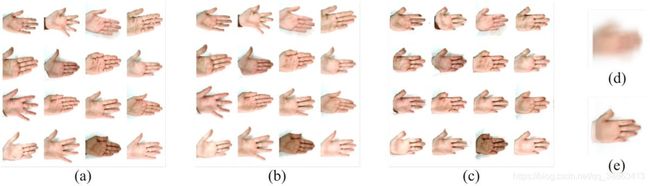
左手手掌图像无监督对齐:(a)输入图像(b)重建图像(c)纹理图像使用解码变形的平均值进行变形的结果(d)输入图像的平均值(e)纹理的平均值

潜在空间表示的平滑插值
比较
提出的方法在MAFL测试中进行了评估–无监督地标检测的平均误差。它优于 Thewlis等人提出的自我监督方法。

MAFL测试集上无监督地标检测的平均误差
结论

使用内在变形自动编码器进行光照插值
如前所述,对于许多任务而言,能够解耦变化因子至关重要。解耦之后可以完全控制和理解深度神经网络模型,这可能是解决问题的关键所在。对此引入了变形自动编码器体系结构,该体系结构可以解耦特定的变化因子(即形状和外观)。最终的结果也表明,采用自动编码器体系结构可以成功地解耦变化因子。
参考资料:
https://neurohive.io/en/computer-vision/deforming-autoencoders/
Deforming Autoencoders: Unsupervised Disentangling of Shape and Appearance