数据结构与算法详细笔记
数据结构与算法
文章目录
- 数据结构与算法
-
- @[toc]
- 1.关键词
-
- 1.1.有效数字
- 1.2.字节对齐
- 1.3.数组名与指针
- 1.4.大小端
- 1.5.别名与指针(C++)
- 1.5.动态申请内存(new malloc())
- 1.6.预处理指令
- 1.7.指针NULL 0 nullptr
- 1.8 fflush(stdin)与fflush(stdout)
- 1.9 动态二维数组
-
- 一、利用一个二级指针来实现
- 二、利用数组指针来实现
- 三、利用一维数组来模拟二维数组
- 1.10 随机存取、顺序存取、顺序存储、随机存储
-
- 存取结构:随机存取和顺序存取
-
- 1.1`随机存取`
- 1.2`顺序存取`
- 存储结构:顺序存储、随机存储
-
- 2.1顺序存储
- 2.2随机存储
-
- 2.2.1 随机存储——链式存储
- 2.2.2 随机存储——索引存储
- 2.2.3 随机存储——散列存储
- 2.基本概念和术语
- 3.LIST
-
- 3.1.SeqList顺序表
-
- 3.1.1查找
- 3.2.LinkList链表
- 3.3.栈和队列
-
- 3.3.1双头栈
- 3.3.2队列
- 3.4 ARRAY
- 4.TREE
-
- 4.1.二叉树
-
- 4.1.1.二叉树的存储结构
- 4.1.2.二叉树的性质
- 4.1.3.常见的二叉树
- 4.1.4.二叉树的遍历
-
- DFS
- BFS
- 4.2.特殊的二叉树
-
- 4.2.1.线索二叉树 Threaded Binary Tree
-
- 线索二叉树的结构
- 遍历过程
- 4.2.2.二叉排序树 BST
-
- 删除操作
- 查找性能
- 4.2.3.平衡二叉树AVL
- 4.2.4.最优二叉树 Haffuman Tree
- 4.2.5.堆积树 Heap Tree
-
- TOP-K 问题
- 5.Graph
-
- 5.1 相关概念:
- 5.2 图的存储结构
-
- 5.2.1 邻接矩阵
-
- **图上顶点的邻接**
- 求度容易
- 带权邻接矩阵
- 5.2.2 邻接表(Adjacency List)
-
- **无向图邻接表特点:**
- 有向图邻接表特点
- 5.2.3 十字链表(Orthogonal List)
- 5.3 图的遍历
- 5.4 图的经典算法
-
- 5.4.1 生成树 Spanning Tree & MST
-
- Prim 算法
- Kruskal算法
- 两者比较
- 5.4.2 拓扑排序Topological sort
-
- **标号法求解关键路径**
- 5.4.3 最短路径
-
- Dijkestra
- Floyd算法
- 6. 查找
-
- 6.1 分类
- 6.2 算法性能评估
- 6.3 顺序表的查找
-
- 6.3.1 顺序查找
- 6.3.2 折半查找
- 6.3.3 索引表
- 6.3.4 散列表
- 7. 排序
- 8. 动态归化
- 好代码TIPS
-
- 变量命名规则
- 能用局部变量就用局部变量
- 代码可读性
- 命中率
-
- 6.3.3 索引表
- 6.3.4 散列表
- 7. 排序
- 8. 动态归化
- 好代码TIPS
-
- 变量命名规则
- 能用局部变量就用局部变量
- 代码可读性
- 命中率
文章目录
- 数据结构与算法
-
- @[toc]
- 1.关键词
-
- 1.1.有效数字
- 1.2.字节对齐
- 1.3.数组名与指针
- 1.4.大小端
- 1.5.别名与指针(C++)
- 1.5.动态申请内存(new malloc())
- 1.6.预处理指令
- 1.7.指针NULL 0 nullptr
- 1.8 fflush(stdin)与fflush(stdout)
- 1.9 动态二维数组
-
- 一、利用一个二级指针来实现
- 二、利用数组指针来实现
- 三、利用一维数组来模拟二维数组
- 1.10 随机存取、顺序存取、顺序存储、随机存储
-
- 存取结构:随机存取和顺序存取
-
- 1.1`随机存取`
- 1.2`顺序存取`
- 存储结构:顺序存储、随机存储
-
- 2.1顺序存储
- 2.2随机存储
-
- 2.2.1 随机存储——链式存储
- 2.2.2 随机存储——索引存储
- 2.2.3 随机存储——散列存储
- 2.基本概念和术语
- 3.LIST
-
- 3.1.SeqList顺序表
-
- 3.1.1查找
- 3.2.LinkList链表
- 3.3.栈和队列
-
- 3.3.1双头栈
- 3.3.2队列
- 3.4 ARRAY
- 4.TREE
-
- 4.1.二叉树
-
- 4.1.1.二叉树的存储结构
- 4.1.2.二叉树的性质
- 4.1.3.常见的二叉树
- 4.1.4.二叉树的遍历
-
- DFS
- BFS
- 4.2.特殊的二叉树
-
- 4.2.1.线索二叉树 Threaded Binary Tree
-
- 线索二叉树的结构
- 遍历过程
- 4.2.2.二叉排序树 BST
-
- 删除操作
- 查找性能
- 4.2.3.平衡二叉树AVL
- 4.2.4.最优二叉树 Haffuman Tree
- 4.2.5.堆积树 Heap Tree
-
- TOP-K 问题
- 5.Graph
-
- 5.1 相关概念:
- 5.2 图的存储结构
-
- 5.2.1 邻接矩阵
-
- **图上顶点的邻接**
- 求度容易
- 带权邻接矩阵
- 5.2.2 邻接表(Adjacency List)
-
- **无向图邻接表特点:**
- 有向图邻接表特点
- 5.2.3 十字链表(Orthogonal List)
- 5.3 图的遍历
- 5.4 图的经典算法
-
- 5.4.1 生成树 Spanning Tree & MST
-
- Prim 算法
- Kruskal算法
- 两者比较
- 5.4.2 拓扑排序Topological sort
-
- **标号法求解关键路径**
- 5.4.3 最短路径
-
- Dijkestra
- Floyd算法
- 6. 查找
-
- 6.1 分类
- 6.2 算法性能评估
- 6.3 顺序表的查找
-
- 6.3.1 顺序查找
- 6.3.2 折半查找
- 6.3.3 索引表
- 6.3.4 散列表
- 7. 排序
- 8. 动态归化
- 好代码TIPS
-
- 变量命名规则
- 能用局部变量就用局部变量
- 代码可读性
- 命中率
-
- 6.3.3 索引表
- 6.3.4 散列表
- 7. 排序
- 8. 动态归化
- 好代码TIPS
-
- 变量命名规则
- 能用局部变量就用局部变量
- 代码可读性
- 命中率
周益民,主要研究数字图像处理,音视频编解码,高等教育研究。
联系方式:
- [email protected] (专接受大文件)
参考书
- 《数据结构与算法》 林劼 教材
- 《数据结构与算法分析—C语言描述》 推荐
- 《大话数据结构》
- 《数据结构(C语言)》严蔚敏
环境配置
关于gcc和g++,安装编译器是后面所有工作的基础,如果没有编译器,后面的一切都无从谈起。在windows下使用gcc和g++,是通过安装MinGW实现的。
MinGW是Minimalist GNU on Windows的首字母缩写,安装后就可以使用很多的GNU工具。GNU(GNU’s Not Unix)是linux中的一个著名的项目,包含了gcc\g++\gdb等工具。也就是说,安装MinGw后,我们就可以使用gcc和g++命令了。
1.关键词
1.1.有效数字

| 类型说明符 | 比特数(字节数) | 有效数字 | 数的范围 |
|---|---|---|---|
| float | 32(4) | 6~7 | -3.40E+38 ~ +3.40E+38 |
| double | 64(8) | 15~16 | -1.79E+308 ~ +1.79E+308 |
由以上特点,可以知道当位数超过有效位数后就无法真实存储了,会出现估计值
float
789.335276-->a
789.335279-->b
-------------------
if(a>b)这个语句会出错,可能会出现a>b。这时应该使用
if(a-b<1e-6) 这个就可以比较较小的数了。
1.2.字节对齐
//sizeof(int)=4 double 8
// short int 2 | long int 4 | long long int 8
// 最初的C语言编译器的int为2B,后来就将其规定为short int
typeedef struct node
{
char ca; //1Byte=8bit
int ivalue; //4B
struct node *next; //4B
char arr[3]; //3B
} node, anode;
/*
这个结构体/类型所占的内存空间大小为
char ca; //1Byte=8bit
空出1B,存储开始位置为偶数//1B
int ivalue; //4B
struct node *next; //4B
char arr[3]; //3B
空出1B //1B
下一个数据开始的位置
所以这个结构体所占的位置为2+4+4+4=14B
*/
#include
int main() {
struct A {
int a;
char b;
short c;
};
struct B {
char b;
int a;
short c;
};
#pragma pack(2) //指定按2字节对齐
struct C {
char b;
int a;
short c;
};
#pragma pack() //取消指定对齐,恢复缺省对齐
#pragma pack(1) //指定按1B对齐
struct D {
char b;
int a;
short c;
};
#pragma pack() //取消
int s1 = sizeof(struct A);
int s2 = sizeof(struct B);
int s3 = sizeof(struct C);
int s4 = sizeof(struct D);
printf("%d\n", s1);
printf("%d\n", s2);
printf("%d\n", s3);
printf("%d\n", s4);
};
/*
8
12
8
7
*/
1.3.数组名与指针
数组名和指针的一个不同之处:对数组名进行&操作,并不是取其地址,而是得到了指 向整个数组的指针。也就是说,arr与&arr指向的是同一个地址,但是他们的类型不一样。arr相当于&arr[0],类型是int *,而&arr是==指向整个数组的指针,==类型是int (*)[5]。
#include
#include
int main(){
int a[5]={1,2,3,4,5};
printf("a\t%d\n",a);
printf("a[0]\t%d\n",&a[0]);
printf("&a\t%d\n",&a);
//a与&a指向的是同一个地址,但是他们的类型不一样。
//a相当于&a[0],类型是int *,而&a是指向整个数组的指针,类型是int (*)5]。
//####################################################
//malloc <---stdlib.h;new<----iostream
//C only have malloc; C++ new & delete
//malloc <--->free
int *p =(int *)malloc(5*sizeof(int));
printf("p\t%d\n",p);
printf("*p\t%d\n",*p);
printf("&p\t%d\n",&p);
//free memory
free(p);
printf("%d\n", *a);
printf("%d\n", *(a + 1));
printf("%d\n", &a[4]);
//首先得到了指向整个数组的指针,对其进行加一操作,指针就指向了整个数组后面的地址,也就是5后面的地址
printf("%d\n", ((int*)(&a + 1)));
//is a[5] pointer
//指针指向5后面的地址,转为int*类型,此时的减一操作使指针移动一个int类型大小的地址空间,那么便指向了5
printf("%d\n", ((int*)(&a + 1) - 1));
return 0;
}
/*
a 268265600
a[0] 268265600
&a 268265600
p 26302128
*p 0
&p 268265592
1
2
268265616
268265620
268265616
*/
typdef
在C语言里,struct结构体里,如果使用typedef的形式定义一个别名,如题目模板这样:
typedef struct {
} LinkedList;
如果在这个struct定义里面,直接把next指针定义为 LinkedList *next 就会报错
因为别名LinkedList是在结构体定义结束后才可以识别的一个别名;
所以在结构体里面,是不认识这个别名的。这是一个小坑。
那么正确的定义方法是什么?
如下:
typedef struct LinkedList_t{
int val;
struct LinkedList_t *next;
} LinkedList;
它的不同之处在于,我们也规定了struct本身的名字。
这个定义的意思是:我有一个struct LinkedList_t, 它的别名是LinkedList;
那么在struct的里面,我就可以识别struct LinkedList_t这个结构体定义,成功地定义我们的next指针。
后面我们同样也可以直接用别名作为类型名去定义变量。
变量的定义有两种方式:
1. struct LinkedList_t 变量名A;
2. LinkedList 变量名B;
1.4.大小端
来源:吃鸡蛋的方法,从大端还是小端吃
定义:
数字: 0x 12 34 56 78
从左往右是高字节到低字节(人为规定)
1)大端 Big-Endian 高字节放在内存低地址端;
2)小端Little-Endian 高字节放在内存高地址端
| 内存地址 | 小端模式存放内容 | 大端模式存放内容 |
|---|---|---|
| 0x4000 | 0x78 | 0x12 |
| 0x4001 | 0x56 | 0x34 |
| 0x4002 | 0x34 | 0x56 |
| 0x4003 | 0x12 | 0x78 |
一般操作系统都是小端,而通讯协议是大端的。
- 常见CPU的字节序
- Big Endian : PowerPC、IBM、Sun
- Little Endian : x86、DEC
- ARM既可以工作在大端模式,也可以工作在小端模式。
- 常见文件的字节序
- Adobe PS – Big Endian
- BMP – Little Endian
- DXF(AutoCAD) – Variable
- GIF – Little Endian
- JPEG – Big Endian
- MacPaint – Big Endian
- RTF – Little Endian
- 另外,Java和所有的网络通讯协议都是使用Big-Endian的编码。
1.5.别名与指针(C++)
在说别名之前,说一下实参与形参。
由于在程序运行时,尽量要保持变量在上下文的统一。所以在调用函数时会出现一下几种情况。
int Swap1(int a,int b){
//形参
//...
}
int Swap2(int* a,int* b){
//实参
//...
}
int main(){
int a=1;
int b=2;
Swap1(a,b);//不会改变a,b的值,维持变量在上下文的统一。
Swap2(&a,&b);//这里直接传的地址,会改变变量的值 int* a= & a;
}
//以上是C语言的做法,到了C++。为了程序员写代码的高效性,所以就提出引用的概念。
//在调用函数的时候直接传参数,不用地址。
/*eg:
int main(){
int a=1;
int b=2;
Swap3(a,b);//这里就会改变参数的值 这里就是int &a= a;
}
*/
int Swap3(int &a,int &b){
//...
}
引用(reference): 引用只是别名,不是实体类型(也就是说c++编译器不为引用单独分配内存空间),对一个对象的引用,就是直接对这个对象的操作。
所以引用的定义要求有:
- 引用不能为空(必须指向所引用的对象)
- 引用不能更换对象
与指针的区别
在C++底层引用是通过指针实现的,但在C++语法上来说,编译器不会为应用单独分配内存空间。
所以有一下几点区别:
- 存在空指针,不存在空引用
- 指针可以更换对象,引用不可以
#include
using namespace std;
int main(void){
void * a=NULL;//空指针
void * b;//是通用指针,会随机指向一个地址
//void& b;
int x = 1;
int y = 2;
int z = 3 ;
//指针c可以不初始化,可以更改其指向的目标,
int * c;
c = &x;
c = &y;
//引用必须初始化,不可以更改其指向的目标
//int& ra ;//报错,ra 必须要指定初值
int & ra = x;
ra = y;//这里只是把y的值赋给 ra 也就是x 而并不是使引用的目标由 对x的引用到对y的引用
return 0;
}
/*
ptr 的类型为 int *
&iNum 的类型为 int * const 是一个指向非 常量的 常量指针。也就是说指针(地址)不可变,但是所指的数据可以变
*/
1.5.动态申请内存(new malloc())
申请动态数组
int n = 100;
int * parr1 = new int[n];//C++里的写法
//这里的 new 对象 与return 0;类似,系统会自动添加 new(对象) return(0)
delete(parr1); //需要自己回收内存空间
int * parr2 =(int *) malloc(n*sizeof(int)); //C原始写法
//这里就写的很清楚: (回传类型) malloc (数量* 空间大小) ===》 推荐
free(parr2);//回收
1.6.预处理指令
参考:http://c.biancheng.net/view/289.html
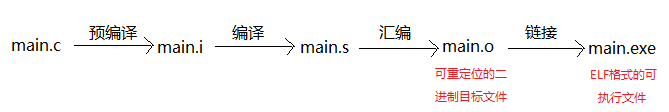
预处理器执行以#开头的指令,预处理器类似于编辑器,它可以给程序添加内容,也可以修改程序。
以#开头的源文件行主要有:
-
宏定义(#define)
-
文件包括(#include)
-
条件编译(#if #elif #else #endif #ifdef #ifndef)
| 条件编译指令 | 说 明 |
|---|---|
| #if | 如果条件为真,则执行相应操作 |
| #elif | 如果前面条件为假,而该条件为真,则执行相应操作 |
| #else | 如果前面条件均为假,则执行相应操作 |
| #endif | 结束相应的条件编译指令 |
| #ifdef | 如果该宏已定义,则执行相应操作 |
| #ifndef | 如果该宏没有定义,则执行相应操作 |
#include注:
宏定义注意其本质是替换,认真理解替换的意思,A—》B
常见错误:
- 优先级问题
#define mult(x,y) (x)*(y) VS #define mult(x,y) ((x)*(y))
//使用 4/mult(x,y)
//注意: 这里的mult(x,y)并不是一个函数,而是一个宏替换命令
//4/(x)*(y) 这里就有优先级问题 VS 4/((x)*(y))
//同如果 #define mult(x,y) x*y 这会出现mult(1,2+2) 1*2+2
1.7.指针NULL 0 nullptr
int iNum =0x64;
int *ptr =&iNum;
虽然 ptr与&iNum的值相等,但是他们的类型不一样。
ptr 的类型为 int *
&iNum 的类型为 int * const 是一个指向非 常量的 常量指针。也就是说指针(地址)不可变,但是所指的数据可以变
//C
#define NULL ((void *) 0)
//C++
#ifdef __cplusplus ---简称:cpp c++ 文件
#define NULL 0
#else
#define NULL ((void *)0)
#endif
也就是说在C语言中NULL实际上是一个void *的指针,然后把void *指针赋值给int *和foolt *的指针的时候,隐式转换成相应的类型。
而C++是强类型的,void *是不能隐式转换成其他指针类型的,所以通常情况下,编译器提供的头文件会定义NULL 为0或者((void *)0)
由于不能隐式转换成其他指针类型的,所以为何不直接用0来表示能,这还是有问提,因为在函数重载的时候会出现歧义。如下例子
//在 foo.h 中声明一个函数
void bar(sometype1 a, sometype2 *b);
//此时
这个函数在a.cpp、b.cpp中调用了,分别是:
//a.cpp:
bar(a, b);
//b.cpp:
bar(a, 0);
//可以预见这些代码都会完美运行,但是如果重载函数如下
void bar(sometype1 a, sometype2 *b);void bar(sometype1 a, int i);
//那么就会出错,b.cpp中的0会按int 型的0进行运行
bar(a, NULL);//还是会出错,因为在C++中NULL其实就是0,这样更难察觉
由于 C++ 98 标准使用期间,NULL 已经得到了广泛的应用,出于兼容性的考虑,C++11 标准并没有对 NULL 的宏定义做任何修改。为了修正 C++ 存在的这一 BUG,C++ 标准委员会最终决定另其炉灶,在 C++11 标准中引入一个新关键字,即nullptr。
如果替换成nullptr就可以避免这个问题了。可以实现隐式转换。
nullptr 是 nullptr_t类型的右值常量,专用于初始化空类型指针。nullptr_t是 C++11 新增加的数据类型,可称为“指针空值类型”。也就是说,nullpter 仅是该类型的一个实例对象(已经定义好,可以直接使用),如果需要我们完全定义出多个同 nullptr 完全一样的实例对象。
1.8 fflush(stdin)与fflush(stdout)
https://www.cnblogs.com/melons/p/5791826.html
1.fflush(stdin):
作用:清理标准输入流,把多余的未被保存的数据丢掉。。
如:
int main()
{
int num;
char str[10];
cin>>num;
cout<>str;
cout< 从stdin获得一个整数存入num,接着立马打印出来;从stdin获得一个字符串存入str,也立马打印出来。但是下面这种可能需要特别考虑:在首行输入了两个整数,在cin>>num之后,stdin缓冲还有一个整数没被读取。接下来,不等输入字符串,就直接把上面多出来的数字存入到str中去并打印。某种程度上这是操作不规范造成的,但是程序应该要有健壮性,程序员应该提前预防这种不规范的操作。可以在程序界面上提示“请输入1个整数”,甚至有时候不厌其烦的强调和警告也必要。当然,本例为求简单,并不在UI友好方面做文章。这时,可以在cin>>str语句前插入fflush(stdin),如此一来就可以清空标准输入缓冲里多余的数据。
2.fflush(stdout):
对标准输出流的清理,但是它并不是把数据丢掉,而是及时地打印数据到屏幕上。标准输出是以行为单位进行的,也即碰到\n才打印数据到屏幕。这就可能造成延时,但是Windows平台上,似乎并看不出差别来。也即MSFT已经将stdout的输出改成及时生效了。
fflush函数被广泛使用在多线程、网络编程的消息处理中。
fflush(stdout):清空输出缓冲区,并把缓冲区内容输出。
1.9 动态二维数组
一、利用一个二级指针来实现
思路:二级指针的使用类似于二维数组名的使用
#include
特点:
- 同一行中元素地址是连续的,不同行中元素地址不一定是连续的。
- 释放申请的空间的过程也需要注意。
二、利用数组指针来实现
数组指针和指针数组是不同的。数组指针是指针变量,其本质仍然是一个变量。指针数组其本质是一个数组,存放的元素类型是指针类型。
就算很了解它们之间的区别,时间长了,在定义的时候还是容易混淆。运算符的优先级也是很重要的。()> [] > *。牢记于心。
#include
特点:
- 申请的地址空间始终是连续的。
- 释放申请空间的方式值得注意进行比较。
三、利用一维数组来模拟二维数组
#include
特点:
- 申请的地址是连续的。
- 释放所申请空间的方式值得注意。
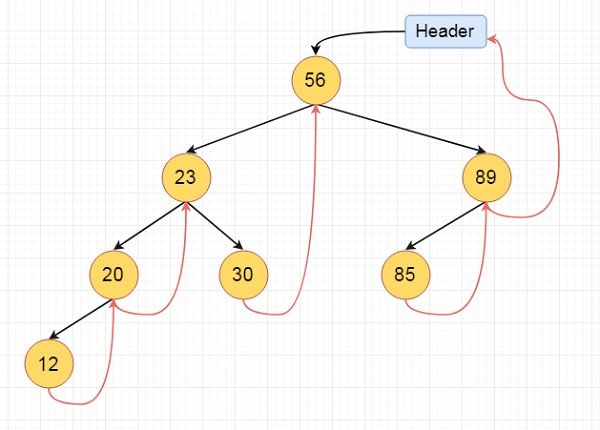
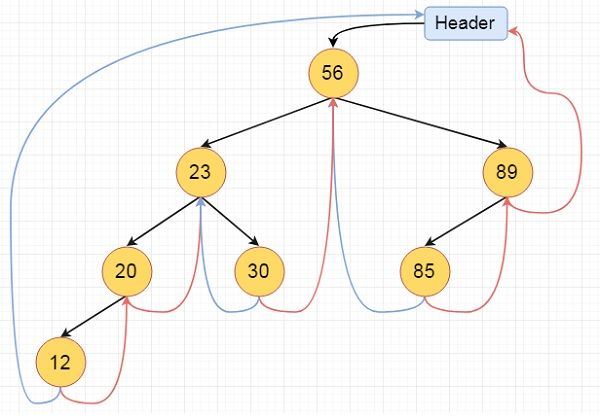
1.10 随机存取、顺序存取、顺序存储、随机存储
https://blog.csdn.net/wq6ylg08/article/details/103358596
存取结构:随机存取和顺序存取
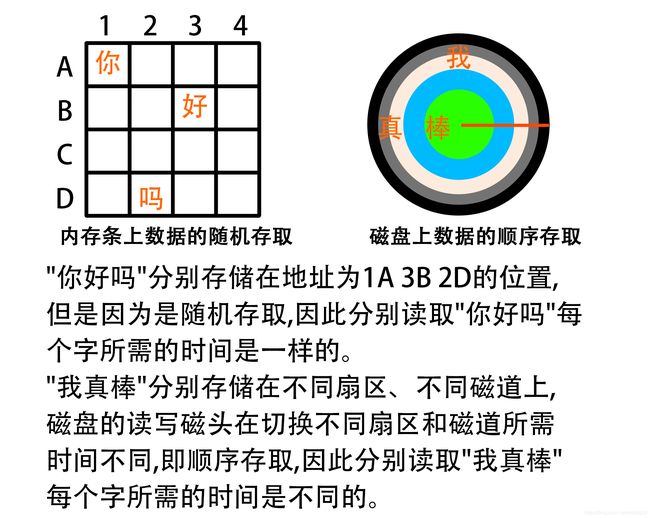
1.1随机存取
随机存取(直接存取,Random Access)指的是当存储器中的数据被读取或写入时,所需要的时间与该数据所在的物理地址无关。
随机存取的微观现实例子就是编程语言中的数组。
随机存取的宏观现实例子就是我们的随机存取存储器(RAM:Random Access Memory),通俗的说也就是我们电脑的内存条。因为RAM利用电容存储电荷的原理保存信息,所以RAM可以高速存取,且与物理地址无关。
1.2顺序存取
顺序存取(Sequential Access)是一种按记录的逻辑顺序进行读、写操作的存取方法,所需要的时间与该数据所在的物理地址有关。顺序存取表现为:在存取第N个数据时,必须先访问前(N-1)个数据。
顺序存取的微观现实例子就是数据结构中的链表。
顺序存取的现实例子就是我们的录音磁带、光盘、机械硬盘里面的磁盘。磁带、光盘、磁盘上的数据分别存储在不同扇区、不同磁道上,磁盘的读写磁头通过切换不同扇区和磁道来读取物理地址不连续的数据时,该过程中要经过不同扇区和不同磁道上的无关数据,磁盘的读写磁头在切换不同扇区和磁道所需时间也不同,故为顺序存取。
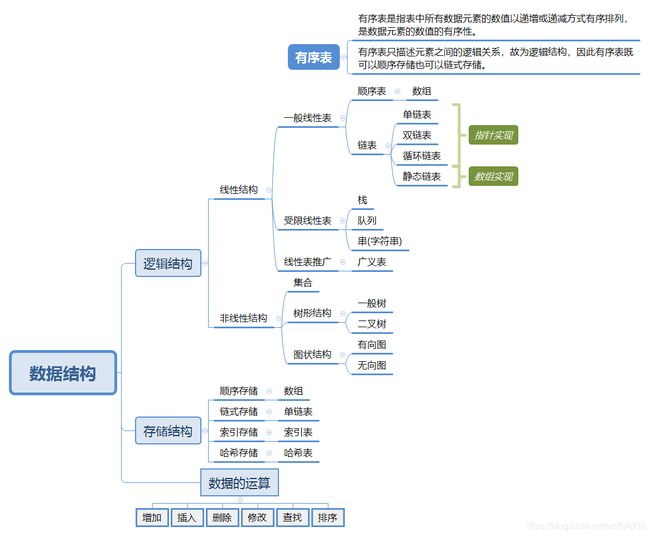
存储结构:顺序存储、随机存储
存储结构是数据元素三大组成要素之一,下图是博主对数据元素三要素所画的思维导图。
2.1顺序存储
顺序存储是把逻辑上相邻的数据元素存储在物理位置上相邻的存储单元中,数据元素之间的逻辑关系由存储单元的邻接关系来体现。
顺序存储的主要优点:
- 节省存储空间。因为分配给数据的存储单元全用存放数据元素(不考虑c/c++语言中数组需指定大小的情况),数据元素之间的逻辑关系没有占用额外的存储空间。
- 可实现对数据元素的随机存取(直接存取)。即每一个数据元素对应一个元素下标,由该元素下标可以直接计算出来数据元素的物理存储地址。
顺序存储的主要缺点:
- 不便于数据修改。对数据元素的插入、删除运算时,可能要移动一系列的数据元素。
- 产生磁盘碎片。因为顺序存储只能使用相邻的一整块存储单元,因此会产生较多的磁盘碎片。
顺序存储的典型实例就是编程语言中的数组。例如,使用顺序表存储集合 {1,2,3,4,5},数据最终的存储状态如下图所示:

数组中的所有元素存储在一个连续性的内存块中,并通过数组的首地址和元素下标来访问。因此一个数组就是由1个数组首地址和N个数组元素构成,数组不需要像链表一样,链表的每个节点必须存储下一个结点的物理地址,在存储同样多的数据下,数组比链表节省空间。
数组可通过数组的首地址和元素下标来直接存取数组中的没每一个元素,而不需要像链表一样,在存取第N个链表结点的数据时,必须先访问前(N-1)个链表结点。
但对数组的数据元素的插入、删除运算时,可能要移动一系列的数据元素,特别的麻烦,因此顺序存储结构的数组不便于修改。
2.2随机存储
在计算机中用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的)。它不要求逻辑上相邻的元素在物理位置上也相邻,而是借助指示元素存储地址的指针来表示元素之间的逻辑关系。
随机存储的主要优点:
- 不会产生磁盘碎片。因为随机存储不要求逻辑上相邻的元素在物理位置上也相邻,而是借助指示元素存储地址的指针来表示元素之间的逻辑关系,因此不会产生磁盘碎片。
- 数据修改方便。对数据元素的插入、删除运算时,随机存储不必移动结点,只要改变结点中的指针。
随机 存储的主要缺点:
\3. 占用空间大。随机存储的每个结点都由数据域和指针域组成,所以相同空间内假设全存满,顺序存储比随机存储可存更多数据。
\4. 查找结点时链式存储要比顺序存储慢,且只能实现顺序存取。
2.2.1 随机存储——链式存储
链式存储是随机存储最典型的代表,因此链式存储的定义、优点和缺点就是2.2随机存储中的定义、优点和缺点。
2.2.2 随机存储——索引存储
除建立存储结点信息外,还建立附加的索引表来标识结点的地址,索引表由若干索引项组成,索引项的一般形式是(关键字,地址)。
索引存储的主要优点:检索速度快。
索引存储的主要缺点:增加了附加的索引表,会占用较多的存储空间。
2.2.3 随机存储——散列存储
散列存储,又称Hash存储,是一种将数据元素的存储位置与关键码之间建立确定对应关系的查找技术,即根据元素的关键字直接计算出该元素的存储地址。
散列存储的主要优点:检索、增加和删除节点的操作更快。
散列存储的主要缺点:若散列函数不好,则可能出现元素存储单元的冲突。
2.基本概念和术语
-
数据(data)
- 数据元素(data element)
-
三元组
(D,S,P)
其中:D是数据对象,S是D上的关系集,P是对D的基本操作集。
ADT 抽象数据类型{
数据对象:<数据对象的定义>
数据关系:<数据关系的定义>
基本操作:<基本操作的定义>
}ADT 抽象数据类型名
其中,数据对象和数据关系用伪代码描述,基本操作的定义为:
基本操作名(参数表)
初始条件:<初始条件描述>
操作结果:<操作结果描述>
3.LIST
-
表的基本操作
- 查值 ListLocate(L,pos)
- 插入 ListInsert(L)
- 删除 ListDelete(L,pos)
-
除此之外还有
- 查地址 ListSearch(L,Value)
- 初始化 ListInit(L)
- 销毁 DestoryList(L)
- 置空 ListClear(L)
- 遍历 ListTraverse(L)
- 求前驱 PriorElem(L,cur,&pre)
- 求后驱 NextElem(L,cur,&next)
3.1.SeqList顺序表
-
查找
- 查命中失败: n n n
- 查命中成功: n + 1 2 = ∑ i = 1 n p i ∗ i = 1 n ( 1 + 2 + 3 + . . . + n ) = 1 n n ( n + 1 ) 2 \frac{n+1}2=\sum_{i=1}^n p_i*i=\frac1n(1+2+3+...+n)=\frac1n \frac{n(n+1)}2 2n+1=∑i=1npi∗i=n1(1+2+3+...+n)=n12n(n+1)
-
插入
- n 2 = ∑ i = 1 n p i ∗ ( n − i + 1 ) = 1 n + 1 n ( n + 1 ) 2 \frac n2=\sum_{i=1}^np_i*(n-i+1)=\frac1{n+1}\frac{n(n+1)}2 2n=∑i=1npi∗(n−i+1)=n+112n(n+1)
-
删除
- n − 1 2 = ∑ i = 1 n p i ( n − i ) = 1 n ( n − 1 ) n 2 \frac{n-1}2=\sum_{i=1}^np_i(n-i)=\frac1n\frac{(n-1)n}2 2n−1=∑i=1npi(n−i)=n12(n−1)n
3.1.1查找
#define MAXSIZE 100
typedef int ElemType;
typedef struct SeqList
{
ElemType elem[MAXSIZE];
int last;
}SeqList;
int ListLocate(SeqList L,ElemType e){
}
3.2.LinkList链表
代码
#include
#include
typedef struct ListNode{
int val;
struct ListNode *next;
}ListNode;
//初始化节点
ListNode * ListInit(int x){
ListNode *node =(ListNode *)malloc(sizeof(ListNode));
node->val=x;
node->next=NULL;
return node;
}
//在头节点后插入值
void ListAddAtHead(ListNode *head,int val){
//初始化节点
ListNode *newNode=ListInit(val);
if(head->next==NULL){
//头节点为空时,直接插到头节点后
head->next=newNode;
return;
}
else{
//不为空时,进行变换
newNode->next=head->next;
head->next=newNode;
}
}
//在链表尾部添加值
void ListAddAtTail(ListNode *head,int val){
ListNode *newNode =ListInit(val);
//设置哨兵指针
ListNode *p=head;
//遍历到尾节点
while(p->next!=NULL){
p=p->next;
}
//在尾部节点添加新节点
p->next=newNode;
}
//链表遍历
void ListTraverse(ListNode *head){
ListNode *p=head;
while(p->next!=NULL){
p=p->next;
printf("%d ",p->val);
}
printf("\n");
}
//就地逆置
void ListReverse(ListNode *head){
if(head==NULL||head->next==NULL){}
else{
ListNode * pre,*p;
pre =head->next;
head->next=NULL;
while(pre){
p=pre;
pre=pre->next;
p->next=head->next;
head->next=p;
}
}
}
int main(){
ListNode *head=ListInit(0);
//printf("This is head node %d\n",head1->val);
int sum_node;
printf("please input sum of listnode:\t");
scanf("%d",&sum_node);
printf("please input node:\t");
for(sum_node;sum_node>0;sum_node--){
int temp;
scanf("%d",&temp);
ListAddAtTail(head,temp);
}
ListTraverse(head);
ListReverse(head);
ListTraverse(head);
return 0;
}
3.3.栈和队列
-
栈Stack
- 基本操作puch(),pop() 只能这两个操作,并且只能在一端进行(而线性表的插入和删除都是随机的)
- 后进先出(Last in hfirst out LIFO)
-
队列
- 先进先出(FIFO)
- 约定:
- 队头指针指向队头元素前一个位置
- 队尾指针指向队尾元素位置
-
相同点
-
逻辑结构都为线性结构
-
存储结构同样是有顺序和链式两种
带尾指针的单循环链表 就是天然的队列
带头节点的单链表 且只在头节点后插入删除,就是栈
3.3.1双头栈
这是栈在系统内存真实的存在。这个方式的系统资源利用率很高。
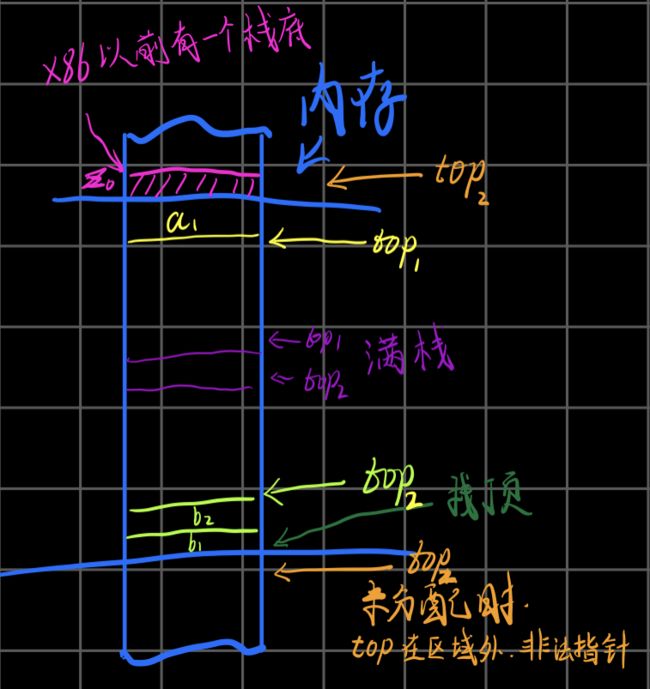
当该栈为满栈时,就可以构成队列,一端进,一端出。
应用:
在变量保护中,常用到栈。
int main(){
int x=3;
int y=5;
add(x,y);
}
//在调用add(x,y)时,系统先把x,y puch进栈然后在用调用,调用完后,又pop出y,x
//这样就保证了上下文。
void add(a,b){
...
a=7;
b=9;
}
Q&A
A ,B,C 入栈有几种出栈顺序? ===》5种
ABC Apuch Apop Bpuch Bpop Cpuch Cpop
ACB Apuch Apop Bpuch Cpuch Cpop Bpop
BAC Apuch Bpuch Bpop Apop Cpuch Cpop
BCA Apuch Bpuch Bpop Cpuch Cpop Apop
CBA Apuch Bpuch Cpuch Cpop Bpop Apop
4个元素入栈? ==》14种
abcd abdc acbd acdb
adcb bacd badc bcad
bcda bdca cbad cbda
cdba dcban个元素? ===》卡特兰数
令 h ( 0 ) = 1 , h ( 1 ) = 1 h(0)=1,h(1)=1 h(0)=1,h(1)=1,卡特兰数满足递推式:
h ( n ) = h ( 0 ) ∗ h ( n − 1 ) + h ( 1 ) ∗ h ( n − 2 ) + . . . + h ( n − 1 ) h ( 0 ) ( n > = 2 ) h(n)= h(0)*h(n-1)+h(1)*h(n-2) + ... + h(n-1)h(0) (n>=2) h(n)=h(0)∗h(n−1)+h(1)∗h(n−2)+...+h(n−1)h(0)(n>=2)
例如:
h ( 2 ) = h ( 0 ) ∗ h ( 1 ) + h ( 1 ) ∗ h ( 0 ) = 1 ∗ 1 + 1 ∗ 1 = 2 h(2)=h(0)*h(1)+h(1)*h(0)=1*1+1*1=2 h(2)=h(0)∗h(1)+h(1)∗h(0)=1∗1+1∗1=2 h ( 3 ) = h ( 0 ) ∗ h ( 2 ) + h ( 1 ) ∗ h ( 1 ) + h ( 2 ) ∗ h ( 0 ) = 1 ∗ 2 + 1 ∗ 1 + 2 ∗ 1 = 5 h(3)=h(0)*h(2)+h(1)*h(1)+h(2)*h(0)=1*2+1*1+2*1=5 h(3)=h(0)∗h(2)+h(1)∗h(1)+h(2)∗h(0)=1∗2+1∗1+2∗1=5;
另类递推式: h ( n ) = h ( n − 1 ) ∗ ( 4 ∗ n − 2 ) / ( n + 1 ) h(n)=h(n-1)*(4*n-2)/(n+1) h(n)=h(n−1)∗(4∗n−2)/(n+1);
递推关系的解为: h ( n ) = C ( 2 n , n ) / ( n + 1 ) ( n = 1 , 2 , 3 , . . . ) h(n)=C(2n,n)/(n+1) (n=1,2,3,...) h(n)=C(2n,n)/(n+1)(n=1,2,3,...);
递推关系的另类解为: h ( n ) = C ( 2 n , n ) − C ( 2 n , n + 1 ) ( n = 1 , 2 , 3 , . . . ) h(n)=C(2n,n)-C(2n,n+1)(n=1,2,3,...) h(n)=C(2n,n)−C(2n,n+1)(n=1,2,3,...);
一维数组实现栈(一维数组其实就是天然的栈,只需要维护栈顶指针就可以了,入栈就往后增长,出栈就从数组末尾进行访问)
#include
#include
#include
#define TRUE 1
#define FALSE 0
#define Stack_Size 50
typedef char StackElementType;
/*顺序栈*/
typedef struct
{
StackElementType elem[Stack_Size]; /*用来存放栈中元素的一维数组*/
int top; /*用来存放栈顶元素的下标,top为-1表示空栈*/
}SeqStack;
//初始化
void SSInitStack(SeqStack *S)
{
S->top = -1;
}
//判空
int IsEmpty(SeqStack *S)
{
return(S->top==-1? TRUE : FALSE);
}
//判满
int IsFull(SeqStack *S)
{
return(S->top==Stack_Size-1?TRUE:FALSE);
}
//压栈
int SSPush(SeqStack *S,StackElementType x)
{
if(S->top==Stack_Size-1)
return(FALSE);
S->top++;
S->elem[S->top] = x;
return(TRUE);
}
//释放
int SSPop(SeqStack *S,StackElementType *x)
{
if(S->top == -1)
return(FALSE);
else
{
*x = S->elem[S->top];
S->top--;
return(TRUE);
}
}
//获取栈顶
int GetTop(SeqStack *S,StackElementType *x)
{
if(S->top == -1)
return(FALSE);
else
{
*x = S->elem[S->top];
return(TRUE);
}
}
int Match(char ch,char str)
{
if(ch=='(' && str==')')
{
return TRUE;
}
else if(ch=='[' && str==']')
{
return TRUE;
}
else if(ch=='{' && str=='}')
{
return TRUE;
}
else
return FALSE;
}
//带头节点的链表就是天然的栈
#include
#include
#include
#define TRUE 1
#define FALSE 0
typedef char StackElementType;
typedef struct node
{
StackElementType data;
struct node *next;
}LinkStackNode,*LinkStack;
/*进栈操作*/
int LSPush(LinkStack top, StackElementType x)/* 将数据元素x压入栈top中 */
{
LinkStackNode *temp;
temp=(LinkStackNode *)malloc(sizeof(LinkStackNode));
if(temp==NULL)
return(FALSE); /* 申请空间失败 */
temp->data=x;
temp->next=top->next;
top->next=temp; /* 修改当前栈顶指针 */
return(TRUE);
}
/*出栈操作*/
int LSPop(LinkStack top, StackElementType *x)
{
/* 将栈top的栈顶元素弹出,放到x所指的存储空间中 */
LinkStackNode * temp;
temp=top->next;
if(temp==NULL) /*栈为空*/
return(FALSE);
top->next=temp->next;
*x=temp->data;
free(temp); /* 释放存储空间 */
return(TRUE);
}
3.3.2队列
约定:
- 队头指针指向队头元素前一个位置
- 队尾指针指向队尾元素位置
假溢出

rear超出到数组的末尾后,就会出现假溢出
解决方法1
固定队头指针永远指向数据区开始位置;
如果数据元素出队,则将队列中所有数据元素前移一个位置(时间复杂度大),同时修改队尾指针。
解决方法2-----循环顺序队列
front=(front+1)%MAXQUEUE;//%为取余
rear=(rear+1)%MAXQUEUE;
但是有会引发新的问题:
由于初始状态是front=-1;rear=-1,及两个指针相同时为空
但是现在队列的判空判满问题?
front=rear时不知道时队列空还是满?产生了歧义
方式1(牺牲一存储单元): 牺牲一个单元来区分队空和队满,入队时少用一个队列单元,即约定以"队头指针在队尾指针的下一位置作为队满的标志"。
队满条件为:(rear+1)%QueueSize==front
队空条件为:front==rear
队列长度为:(rear-front++QueueSize)%QueueSize
方式2(采用计数器): 增设表示队列元素个数的数据成员size,此时,队空和队满时都有front==rear。
队满条件为:size==QueueSize
队空条件为:size==0
方式3(设置标志位): 增设tag数据成员以区分队满还是队空
tag表示0的情况下,若因删除导致front==rear,则队空;
tag等于1的情况,若因插入导致front==rear则队满
比较:这三个中,推荐牺牲一个存储单位来实现判空判满,因为它用了一个协议就解决了问题,而其他的都会增加变量,这样不尽增加了空间消耗,还让多了变量(变量还需要维护,这个成本比较大)
#include
#include
#include
#define TRUE 1
#define FALSE 0
#define MAXSIZE 50 /*队列的最大长度*/
typedef char QueueElementType;
typedef struct
{
QueueElementType element[MAXSIZE]; /* 队列的元素空间*/
int front; /*头指针指示器*/
int rear; /*尾指针指示器*/
}SeqQueue;
/*初始化操作*/
void InitQueue(SeqQueue *Q)
{
Q->front=Q->rear=0;
}
/*将元素x入队*/
int EnterQueue(SeqQueue *Q, QueueElementType x)
{
if(IsFull(&Q)) /*队列已经满了*/
return(FALSE);
Q->element[Q->rear]=x;
Q->rear=(Q->rear+1)%MAXSIZE; /* 重新设置队尾指针 */
return(TRUE); /*操作成功*/
}
/*删除队列的队头元素,用x返回其值*/
int DeleteQueue(SeqQueue *Q, QueueElementType *x)
{
if(Q->front==Q->rear) /*队列为空*/
return(FALSE);
*x=Q->element[Q->front];
Q->front=(Q->front+1)%MAXSIZE; /*重新设置队头指针*/
return(TRUE); /*操作成功*/
}
/*提取队列的队头元素,用x返回其值*/
int GetHead(SeqQueue *Q, QueueElementType *x)
{
if(Q->front==Q->rear) /*队列为空*/
{
return(FALSE);
}
*x=Q->element[Q->front];
return(TRUE); /*操作成功*/
}
int IsEmpty(SeqQueue *Q)
{
if(Q->front==Q->rear) /*队列为空*/
{
return(TRUE);
}
else
{
return(FALSE); /*操作成功*/
}
}
int IsFull(SeqQueue *Q)
{
if((Q->rear+1)%MAXSIZE==Q->front)/*牺牲一个存储单位来判定队满*/
return TRUE;
return FALSE;
}
当然使用链表来做队列的话就不会出现以下情况
#include "stdlib.h"
#include "stdio.h"
typedef struct Node{
int data;
struct Node *next;
}LinkQueueNode;
typedef struct{
LinkQueueNode *front;
LinkQueueNode *rear;
}LinkQueue;
// 这是关于队列的一些操作函数
int InitQueue(LinkQueue *Q){
Q->front=(LinkQueueNode*)malloc(sizeof(LinkQueueNode));
if(Q->front!=NULL) {
Q->rear=Q->front;
Q->front->next=NULL;
return(True);
}
else{
return(False);
}
}
int EnterQueue(LinkQueue *Q,int x){
LinkQueueNode *NewNode;
NewNode=(LinkQueueNode*)malloc(sizeof(LinkQueueNode));
if(NewNode!=NULL){
NewNode->data=x;
NewNode->next=NULL;
Q->rear->next=NewNode;
Q->rear=NewNode;
return(True);
}
else{
return(False);
}
}
int DeleteQueue(LinkQueue *Q,int *x){
LinkQueueNode *p;
if(Q->front==Q->rear){
return(False);
}
p=Q->front->next;
Q->front->next=p->next;
if(Q->rear==p){
Q->rear=Q->front;
}
*x=p->data;
free(p);
return(True);
}
int IsEmpty(LinkQueue *Q){
if(Q->front==Q->rear){
return(True);
}
else{
return(False);
}
}
3.4 ARRAY
数组是多维的结构,而存储空间是一个一维的结构。
对多维数组分配时,要把它的元素映象存储在一维存储器中,一般有两种顺序映象的方式:
-
①以行为主序:如BASIC、PASCAL、COBOL、C等程序设计语言中用的是以行为主的顺序分配,即一行一行地分配。如图b
-
②以列为主序:如FcORTRAN语言中,用的是以列为主的顺序分配,即一列一列地分配。如图c

一、特殊矩阵(规则矩阵 )
非零元在矩阵中的分布有一定规则
-
①三对角矩阵
-
②对称矩阵
-
③对角矩阵
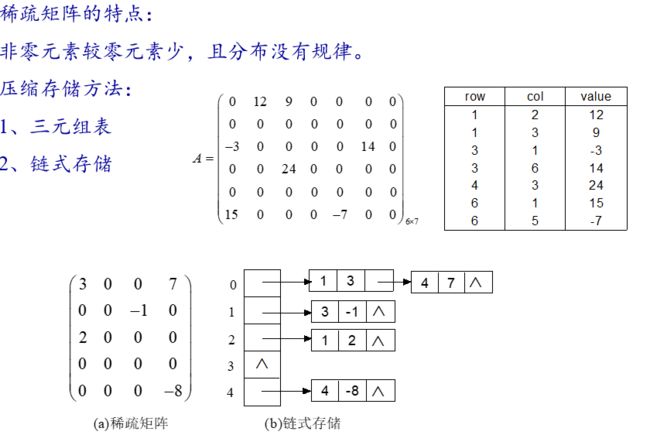
二、稀疏矩阵 (不规则矩阵 )
非零元在矩阵中随机出现
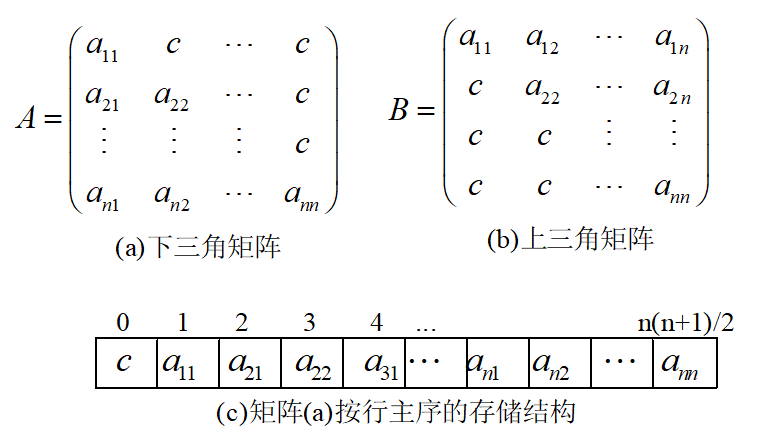


4.TREE
树型结构是一类重要的数据结构。
KEY WORDS
节点的度degree为子树的数量、
度为0的为叶子Leaf
同双亲的孩子之间互称兄弟Sibling
同层不同双亲的互称堂兄弟
层次Level从根开始定义,根为第一层。最大层次为树的深度。
森林去掉根节点所剩下的子树构成森林。

4.1.二叉树
二叉树是 n ( n ≥ 0 ) n(n≥0) n(n≥0)个有序节点构成的集合。 n = 0 n=0 n=0成为空二叉树; n > 0 n>0 n>0的二叉树有一个根节点和两个互不相交的,分别称为左子树和右子树的二叉树构成。
有上面的定义我们可以知道二叉树和递归的关系不浅。后面实现遍历、求叶子数、求节点数都会用到递归的方法。
4.1.1.二叉树的存储结构
链式存储:
每个节点有m+1个域,其中m个指针域指向孩子,则空指针的数目为 n × m − ( n − 1 ) = n × ( m − 1 ) + 1 n×m-(n-1)=n×(m-1)+1 n×m−(n−1)=n×(m−1)+1个。
所以如果m越大,存储效率越低。
typedef struct BiNode{
int val;
strcut BiNode * lchild;
strcut BiNode * lchild;
}BiNode;
顺序存储:
n的双亲节点是n/2(在C语言中,即取整),儿子节点是 $n2+1\ \ & \ \ n2 $
节点 i , j i,j i,j处于同一层的条件是 $ ⌊log_2i⌋ =⌊log_2j ⌋$
4.1.2.二叉树的性质
对于二叉树,包含一些性质:
- 在二叉树中,第 i i i层上至多有 2 i − 1 2^{i−1} 2i−1个节点( i ≥ 1 i≥1 i≥1)
- 深度为 k k k的二叉树至多有 2 k − 1 2^k−1 2k−1个节点( k ≥ 1 k≥1 k≥1)
- 对一棵二叉树,如果叶子节点的个数为 n 0 n_0 n0,度为 2 2 2的节点个数为 n 2 n_2 n2,则 n 0 = n 2 + 1 n_0=n_2+1 n0=n2+1
- 具有 n n n个节点的完全二叉树的深度为 ⌊ l o g 2 n ⌋ + 1 ⌊log_2n⌋+1 ⌊log2n⌋+1
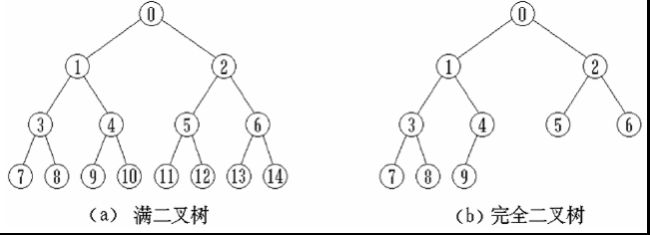
4.1.3.常见的二叉树
在一棵二叉树中,如果所有分支结点都存在左子树和右子树,并且叶子结点都在同一层上,这样的二叉树称作满二叉树。一棵深度为 k k k且由 2 k − 1 2^k-1 2k−1个结点的二叉树称为满二叉树。
如果一棵具有n个结点的二叉树的结构与满二叉树的前n个结点的结构相同,这样的二叉树称作完全二叉树。
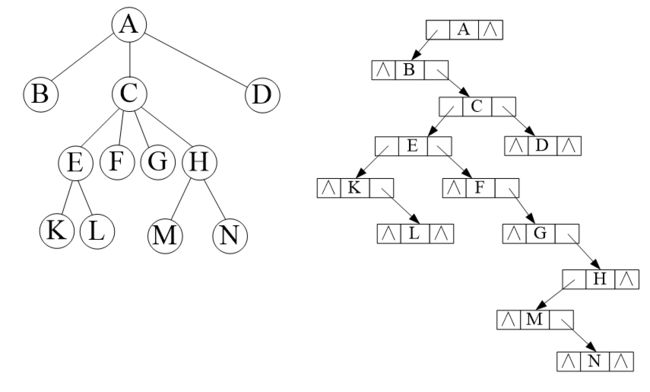
孩子兄弟表示法===》将多叉树映射为二叉树
孩子表示为二叉树的左孩子,兄弟表示为二叉树的右孩子
4.1.4.二叉树的遍历
| 树 | 图 | 非递归 |
|---|---|---|
| 先中后序 | DFS | 栈 |
| 层序 | BFS | 队列 |

DFS
递归方法
// 前序遍历
void Traverse_PreOrder(BiNode* root) {
if (root != NULL) {
printf("%d ", root->val);
Traverse_PreOrder(root->lchild);
Traverse_PreOrder(root->rchild);
}
}
// 中序遍历
void Traverse_InOrder(BiNode* root) {
if (root != NULL) {
Traverse_InOrder(root->lchild);
printf("%d ", root->val);
Traverse_InOrder(root->rchild);
}
}
// 后序遍历
void Traverse_PostOrder(BiNode* root) {
if (root != NULL) {
Traverse_PostOrder(root->lchild);
Traverse_PostOrder(root->rchild);
printf("%d ", root->val);
}
}
非递归法
//非递归前序遍历
/*
先访问在入栈
对于任一结点P:
1)访问结点P,并将结点P入栈;
2)判断结点P的左孩子是否为空,若为空,则取栈顶结点并进行出栈操作,并将栈顶结点的右孩子置为当前的结点P,循环至1);若不为空,则将P的左孩子置为当前的结点P;
3)直到P为NULL并且栈为空,则遍历结束。
*/
void Traverse_PreOrder1(BiTree *root)
{
stack s;
BiTree *p=root;
while(p!=NULL||!s.empty())//出口 p==NULL&&s.empty
{
while(p!=NULL)//访问p节点,并入栈
{
cout<data<<"";
s.push(p);
p=p->lchild;
}
if(!s.empty())
{
p=s.top();
s.pop();
p=p->rchild;
}
}
}
/*
非递归中序遍历
对于任一结点P,
1)若其左孩子不为空,则将P入栈并将P的左孩子置为当前的P,然后对当前结点P再进行相同的处理;
2)若其左孩子为空,则取栈顶元素并进行出栈操作,访问该栈顶结点,然后将当前的P置为栈顶结点的右孩子;
3)直到P为NULL并且栈为空则遍历结束
*/
void Traverse_InOrder1(BiTree *root)
{
stack s;
BiTree *p=root;
while(p!=NULL||!s.empty())
{
while(p!=NULL)
{
s.push(p);
p=p->lchild;
}
if(!s.empty())
{
p=s.top();
cout<data<<"";
s.pop();
p=p->rchild;
}
}
}
后序遍历的非递归实现是三种遍历方式中最难的一种。因为在后序遍历中,要保证左孩子和右孩子都已被访问并且左孩子在右孩子前访问才能访问根结点,这就为流程的控制带来了难题。下面介绍两种思路。
这里需要理解左右根的一个顺序是对于每一个节点(这个很重要)都是这样的
eg : a
/
NULL b
/
c d
/ \ /
null null null null访问顺序:c,d, b,a
第一种思路:对于任一结点P,将其入栈,然后沿其左子树一直往下搜索,直到搜索到没有左孩子的结点,此时该结点出现在栈顶,但是此时不能将其出栈并访问,因此其右孩子还未被访问。所以接下来按照相同的规则对其右子树进行相同的处理,当访问完其右孩子时,该结点又出现在栈顶,此时可以将其出栈并访问。这样就保证了正确的访问顺序。可以看出,在这个过程中,每个结点都两次出现在栈顶,只有在第二次出现在栈顶时,才能访问它。因此需要多设置一个变量标识该结点是否是第一次出现在栈顶。
typedef struct BTNode{
BiTree *btnode;
bool isFirst;
}BTNode;
void postOrder2(BiTree *root) //非递归后序遍历
{
stack s;
BiTree *p=root;
BTNode *temp;
while(p!=NULL||!s.empty())
{
while(p!=NULL) //沿左子树一直往下搜索,直至出现没有左子树的结点
{
BTNode *btn=(BTNode *)malloc(sizeof(BTNode));
btn->btnode=p;
btn->isFirst=true;
s.push(btn);
p=p->lchild;
}
if(!s.empty())
{
temp=s.top();
s.pop();
if(temp->isFirst==true) //表示是第一次出现在栈顶
{
temp->isFirst=false;
s.push(temp);
p=temp->btnode->rchild;
}
else//第二次出现在栈顶
{
cout<btnode->data<<"";
p=NULL;
}
}
}
}
第二种思路:要保证根结点在左孩子和右孩子访问之后才能访问,因此对于任一结点P,先将其入栈。如果P不存在左孩子和右孩子,则可以直接访问它;或者P存在左孩子或者右孩子,但是其左孩子和右孩子都已被访问过了,则同样可以直接访问该结点。若非上述两种情况,则将P的右孩子和左孩子依次入栈,这样就保证了每次取栈顶元素的时候,左孩子在右孩子前面被访问,左孩子和右孩子都在根结点前面被访问。
void postOrder3(BinTree *root) //非递归后序遍历
{
stack s;
BinTree *cur; //当前结点
BinTree *pre=NULL; //前一次访问的结点
s.push(root);
while(!s.empty())
{
cur=s.top();
if((cur->lchild==NULL&&cur->rchild==NULL)||
(pre!=NULL&&(pre==cur->lchild||pre==cur->rchild)))
{
cout<data<<""; //如果当前结点没有孩子结点或者孩子节点都已被访问过
s.pop();
pre=cur;
}
else
{
if(cur->rchild!=NULL)
s.push(cur->rchild);
if(cur->lchild!=NULL)
s.push(cur->lchild);
}
}
}
参考资料:https://www.cnblogs.com/dolphin0520/archive/2011/08/25/2153720.html
BFS
// C中没有queue这个函数,只能自己造轮子
//入队函数
void EnQueue(BiNode **a,BiNode *node){
a[rear++]=node;
}
//出队函数
BiNode* DeQueue(BiNode** a){
return a[front++];
}
//层序遍历
void Traverse_LeverOrder(BiNode * root){
BiNode * p;
//采用顺序队列,初始化创建队列数组
BiNode * a[20];
//根结点入队
EnQueue(a, root);
//当队头和队尾相等时,表示队列为空
while(front < rear) {
//队头结点出队
p=DeQueue(a);
printf("%d ", p->val);
//将队头结点的左右孩子依次入队
if (p->lchild!=NULL) {
EnQueue(a, p->lchild);
}
if (p->rchild!=NULL) {
EnQueue(a, p->rchild);
}
}
}

图源:树:二叉树的层序遍历算法(超简洁实现及详细分析)
#include
void levelTravel(TiNode *root){
if(root == NULL)
return;
queue Q;
Q.push(root); //初始化
while(!Q.empty()){
TiNode* cur = Q.front();
Q.pop();
visit(cur);
if(cur->left) Q.push(cur->left);//一般从左到右
if(cur->right) Q.push(cur->right);
}
}
4.2.特殊的二叉树
4.2.1.线索二叉树 Threaded Binary Tree
Inorder traversal of a Binary tree can either be done using recursion or with the use of a auxiliary stack. The idea of threaded binary trees is to make inorder traversal faster and do it without stack and without recursion. A binary tree is made threaded by making all right child pointers that would normally be NULL point to the inorder successor of the node (if it exists). ---->https://www.geeksforgeeks.org/threaded-binary-tree/
如下图,我们可以看见一共有6个节点,一共12个指针域,有7个Null指针域。这样的指针域的利用效率非常低(n个节点: 2 n − ( n − 1 ) = n + 1 2n-(n-1)=n+1 2n−(n−1)=n+1个Null指针域)。

所以为了提高指针域的利用率,A.J.perils & C.Thornton 就提出了线索二叉树的概念。
实际上也就是当二叉树的左右孩子结点为Null 的时候,指向的地址是浪费的,为了减少浪费我们可以通过将其指向前驱或者后续来利用这些无用的空间,提升查找速度,值得注意的是实际使用中我们要根据选择的二叉树遍历规则来进行对应的指向(前序、中序、后序)要保持一直。一般来说我们使用中序遍历进行二叉树线索化。
下面用中序遍历来举例:
上面的例子的线索化如下

线索二叉树的结构
为了辨识出这个指针域是线索的用途还是指向孩子节点,我们在二叉树的结构上增加了左右标志位,如果为0,是指向孩子节点,为1为线索的用途。
For fully threaded binary tree, each node has five fields. Three fields like normal binary tree node, another two fields to store Boolean value to denote whether link of that side is actual link or thread.
struct Node
{
int data;
struct Node *lchild
struct Node *rchild;
bool ltag;
bool rtag;
}
| Left Thread Flag | Left Link | Data | Right Link | Right Thread Flag |
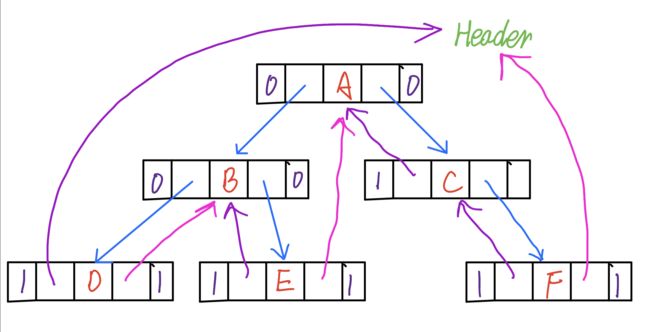
遍历过程

图源:https://www.geeksforgeeks.org/threaded-binary-tree/
// Insertion in Threaded Binary Search Tree.
#include
using namespace std;
struct Node
{
struct Node *left, *right;
int info;
// True if left pointer points to predecessor
// in Inorder Traversal
bool lthread;
// True if right pointer points to predecessor
// in Inorder Traversal
bool rthread;
};
// Insert a Node in Binary Threaded Tree
struct Node *insert(struct Node *root, int ikey)
{
// Searching for a Node with given value
Node *ptr = root;
Node *par = NULL; // Parent of key to be inserted
while (ptr != NULL)
{
// If key already exists, return
if (ikey == (ptr->info))
{
printf("Duplicate Key !\n");
return root;
}
par = ptr; // Update parent pointer
// Moving on left subtree.
if (ikey < ptr->info)
{
if (ptr -> lthread == false)
ptr = ptr -> left;
else
break;
}
// Moving on right subtree.
else
{
if (ptr->rthread == false)
ptr = ptr -> right;
else
break;
}
}
// Create a new node
Node *tmp = new Node;
tmp -> info = ikey;
tmp -> lthread = true;
tmp -> rthread = true;
if (par == NULL)
{
root = tmp;
tmp -> left = NULL;
tmp -> right = NULL;
}
else if (ikey < (par -> info))
{
tmp -> left = par -> left;
tmp -> right = par;
par -> lthread = false;
par -> left = tmp;
}
else
{
tmp -> left = par;
tmp -> right = par -> right;
par -> rthread = false;
par -> right = tmp;
}
return root;
}
// Returns inorder successor using rthread
struct Node *inorderSuccessor(struct Node *ptr)
{
// If rthread is set, we can quickly find
if (ptr -> rthread == true)
return ptr->right;
// Else return leftmost child of right subtree
ptr = ptr -> right;
while (ptr -> lthread == false)
ptr = ptr -> left;
return ptr;
}
// Printing the threaded tree
void inorder(struct Node *root)
{
if (root == NULL)
printf("Tree is empty");
// Reach leftmost node
struct Node *ptr = root;
while (ptr -> lthread == false)
ptr = ptr -> left;
// One by one print successors
while (ptr != NULL)
{
printf("%d ",ptr -> info);
ptr = inorderSuccessor(ptr);
}
}
// Driver Program
int main()
{
struct Node *root = NULL;
root = insert(root, 20);
root = insert(root, 10);
root = insert(root, 30);
root = insert(root, 5);
root = insert(root, 16);
root = insert(root, 14);
root = insert(root, 17);
root = insert(root, 13);
inorder(root);
return 0;
}
此外,线索二叉树还可以只有前驱线索或者后驱线索如下:
 |
 |
 |
依次是左线索、右线索、线索二叉树。
4.2.2.二叉排序树 BST
二叉排序树,又称为二叉查找树Binary Search Tree。二叉排序树或者是一棵空树,或者是具有以下性质的二叉树:若其左子树不为空,则左子树上的所有节点的值均小于它的根结点的值;若其右子树不为空,则右子树上的所有节点的值均大于它的根结点的值;左右子树又分别是二叉排序树。(中序递增)
删除操作
- 删除叶子节点,直接删除。
- 删除度为1的节点,以其非空子节点代替。
- 删除度为2的节点,以其前驱节点代替。
- 度为2的前驱(中序遍历) 度可能为0或1,回到前面两个操作。
//删除操作
BiNode* Delete(BiNode* BST,int data){
if(!BST){//树空时,直接返回NULL
return BST;
}else if(data < BST->data){
//data小于根节点时,到左子树去删除data
BST->lchild = Delete(BST->lchild,data);
}else if(data > BST->data){
//data大于根节点时,到右子树去删除data
BST->rchild = Delete(BST->rchild,data);
}else{//data等于根节点时,执行删除操作
if(BST->lchild && BST->rchild){
//删除度为2的节点,以其前驱节点代替。
//左右子树都不空时,用右子树的最小来代替根节点
BinarySearchTree* tmp = FindMin(BST->rchild);
BST->data = tmp->data;
//删除右子树的最小结点
BST->rchild = Delete(BST->rchild,tmp->data);
}else{//当左右子树都为空或者有一个空时
BiNode* tmp = BST;
if(!BST->lchild){//左子树为空时
BST = BST->rchild;
}else if(!BST->rchild){//右子树为空时
BST = BST->lchild;
}
delete tmp;
}
}
return BST;
}
查找性能
回顾:
- 顺序表:
- 查找
- 查命中失败: n n n
- 查命中成功: n + 1 2 = ∑ i = 1 n p i ∗ i = 1 n ( 1 + 2 + 3 + . . . + n ) = 1 n n ( n + 1 ) 2 \frac{n+1}2=\sum_{i=1}^n p_i*i=\frac1n(1+2+3+...+n)=\frac1n \frac{n(n+1)}2 2n+1=∑i=1npi∗i=n1(1+2+3+...+n)=n12n(n+1)
- 插入
- n 2 = ∑ i = 1 n p i ∗ ( n − i + 1 ) = 1 n + 1 n ( n + 1 ) 2 \frac n2=\sum_{i=1}^np_i*(n-i+1)=\frac1{n+1}\frac{n(n+1)}2 2n=∑i=1npi∗(n−i+1)=n+112n(n+1)
- 删除
- n − 1 2 = ∑ i = 1 n p i ( n − i ) = 1 n ( n − 1 ) n 2 \frac{n-1}2=\sum_{i=1}^np_i(n-i)=\frac1n\frac{(n-1)n}2 2n−1=∑i=1npi(n−i)=n12(n−1)n
平均查找长度(Average Search Length)
A S L = 1 n ∑ i = 1 n S l e n g t h ( i ) ASL=\frac1n\sum_{i=1}^nSlength(i) ASL=n1i=1∑nSlength(i)
由上图的结论可以知道,ASL的大小与树的深度有关(深度越小,ASL越小),所以就出现了平衡二叉树。
#include
#include
using namespace std;
int MAX = -32767;
class BinarySearchTree{
private:
int data;
BinarySearchTree* lchild;
BinarySearchTree* rchild;
public:
//查找最小值
BinarySearchTree* FindMin(BinarySearchTree* BST){
BinarySearchTree* cur = BST;
//搜索树为空时,返回NULL
if(cur == NULL){
return NULL;
}
while(cur){
//左子树为空时,返回该节点
if(cur->lchild == NULL){
return cur;
}else{//否则在左子树里找最小值
cur = cur->lchild;
}
}
}
//查找最大值
BinarySearchTree* FindMax(BinarySearchTree* BST){
BinarySearchTree* cur = BST;
//搜索树为空时,返回NULL
if(cur == NULL){
return NULL;
}
while(cur){
//右子树为空时,返回该节点
if(cur->rchild == NULL){
return cur;
}else{//否则在
cur = cur->rchild;
}
}
}
//按值查找结点
BinarySearchTree* Find(BinarySearchTree* BST,int data){
BinarySearchTree* cur = BST;
//搜索树为空,返回NULL
if(cur == NULL){
return NULL;
}
while(cur){
//根节点值与data相等,返回根节点
if(cur->data == data){
return cur;
}else if(cur->data < data){
//比data小,则在左子树里寻找
cur = cur->lchild;
}else{//否则在右子树里寻找
cur = cur->rchild;
}
}
}
//插入函数
BinarySearchTree* Insert(BinarySearchTree* BST,int data){
//搜索树为空,则构建根节点
if(!BST){
BST = new BinarySearchTree;
BST->data = data;
BST->lchild = BST->rchild = NULL;
}else{
//若data小于根节点的值,则插入到左子树
if(data < BST->data){
BST->lchild = BST->Insert(BST->lchild,data);
}else if(data > BST->data){
//若data小于根节点的值,则插入到左子树
BST->rchild = BST->Insert(BST->rchild,data);
}
}
return BST;
}
//二叉搜索树的构造,利用data数组构造二叉搜索树
BinarySearchTree* Create(int* data,int size){
BinarySearchTree* bst = NULL;
for(int i = 0 ; i < size ; i++){
bst = this->Insert(bst,data[i]);
}
return bst;
}
//递归前序遍历
void PreorderTraversal(BinarySearchTree* T){
if(T == NULL){
return;
}
cout<data<<" "; //访问根节点并输出
T->PreorderTraversal(T->lchild); //递归前序遍历左子树
T->PreorderTraversal(T->rchild); //递归前序遍历右子树
}
//递归中序遍历
void InorderTraversal(BinarySearchTree* T){
if(T == NULL){
return;
}
T->InorderTraversal(T->lchild); //递归中序遍历左子树
cout<data<<" "; //访问根节点并输出
T->InorderTraversal(T->rchild); //递归中序遍历左子树
}
//递归后序遍历
void PostorderTraversal(BinarySearchTree* T){
if(T == NULL){
return;
}
T->PostorderTraversal(T->lchild); //递归后序遍历左子树
T->PostorderTraversal(T->rchild); //递归后序遍历右子树
cout<data<<" "; //访问并打印根节点
}
//删除操作
BinarySearchTree* Delete(BinarySearchTree* BST,int data){
if(!BST){//树空时,直接返回NULL
return BST;
}else if(data < BST->data){
//data小于根节点时,到左子树去删除data
BST->lchild = this->Delete(BST->lchild,data);
}else if(data > BST->data){
//data大于根节点时,到右子树去删除data
BST->rchild = this->Delete(BST->rchild,data);
}else{//data等于根节点时
if(BST->lchild && BST->rchild){
//左右子树都不空时,用右子树的最小来代替根节点
BinarySearchTree* tmp = this->FindMin(BST->rchild);
BST->data = tmp->data;
//删除右子树的最小结点
BST->rchild = this->Delete(BST->rchild,tmp->data);
}else{//当左右子树都为空或者有一个空时
BinarySearchTree* tmp = BST;
if(!BST->lchild){//左子树为空时
BST = BST->rchild;
}else if(!BST->rchild){//右子树为空时
BST = BST->lchild;
}
delete tmp;
}
}
return BST;
}
int getdata(BinarySearchTree* BST){
return BST->data;
}
//删除最小值
BinarySearchTree* DeleteMin(BinarySearchTree* BST){
BinarySearchTree* cur = BST; //当前结点
BinarySearchTree* parent = BST; //当前结点的父节点
if(cur == NULL){
return BST;
}
//当前结点的左子树非空则一直循环
while(cur->lchild != NULL){
parent = cur; //保存当前结点父节点
cur = cur->lchild; //把当前结点指向左子树
}
if(cur == BST){//当前结点为根结点,即只有右子树
BST = BST->rchild;
}else{
if(cur->rchild == NULL){//右子树为空,即为叶子节点
parent->lchild = NULL; //父节点左子树置空
delete cur;
}else{//右子树非空
parent->lchild = cur->rchild; //把当前结点右子树放到父节点的左子树上
delete cur;
}
}
return BST;
}
//删除最大值
BinarySearchTree* DeleteMax(BinarySearchTree* BST){
BinarySearchTree* cur = BST; //当前结点
BinarySearchTree* parent = BST; //当前结点的父节点
if(cur == NULL){
return BST;
}
//当前结点右子树非空则一直循环
while(cur->rchild != NULL){
parent = cur; //保存当前结点父节点
cur = cur->rchild; //把当前结点指向右子树
}
if(cur == BST){//当前结点为根结点,即只有左子树
BST = BST->lchild;
}else{
if(cur->lchild == NULL){//左子树为空,即为叶子节点
parent->rchild = NULL; //父节点右子树置空
delete cur;
}else{//左子树非空
parent->rchild = cur->lchild; //把当前结点左子树放到父节点的右子树上
delete cur;
}
}
return BST;
}
};
int main()
{
int size;
cout<<"请输入结点个数:"<>size;
int* data;
data = new int[size];
cout<<"请输入每个结点的值:"<>data[i];
}
BinarySearchTree* bst;
bst = new BinarySearchTree;
bst = bst->Create(data,size);
cout<<"前序遍历(递归):"<PreorderTraversal(bst);
cout<InorderTraversal(bst);
cout<PostorderTraversal(bst);
cout<FindMax(bst);
cout<<"二叉搜索树的最大值为:"<getdata(bst_max);
cout<DeleteMax(bst);
cout<<"前序遍历(递归):"<PreorderTraversal(bst);
cout<InorderTraversal(bst);
cout<PostorderTraversal(bst);
cout<FindMin(bst);
cout<getdata(bst_min);
cout<DeleteMin(bst);
cout<<"前序遍历(递归):"<PreorderTraversal(bst);
cout<InorderTraversal(bst);
cout<PostorderTraversal(bst);
cout<>num;
bst = bst->Delete(bst,num);
cout<<"删除之后:"<PreorderTraversal(bst);
cout<InorderTraversal(bst);
cout<PostorderTraversal(bst);
cout< 4.2.3.平衡二叉树AVL
AVL树的名字来源于它的发明作者G.M. Adelson-Velsky 和 E.M. Landis。AVL树是最先发明的自平衡二叉查找树(Self-Balancing Binary Search Tree,简称平衡二叉树)。
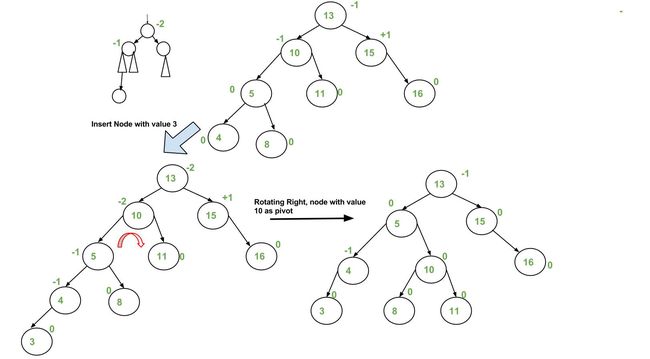
平衡二叉树定义(AVL):它或者是一颗空树,或者具有以下性质的二叉排序树:它的左子树和右子树的深度之差(平衡因子)的绝对值不超过1,且它的左子树和右子树都是一颗平衡二叉树。
a) Left Left Case
T1, T2, T3 and T4 are subtrees.
z y
/ \ / \
y T4 Right Rotate (z) x z
/ \ - - - - - - - - -> / \ / \
x T3 T1 T2 T3 T4
/ \
T1 T2
b) Left Right Case
z z x
/ \ / \ / \
y T4 Left Rotate (y) x T4 Right Rotate(z) y z
/ \ - - - - - - - - -> / \ - - - - - - - -> / \ / \
T1 x y T3 T1 T2 T3 T4
/ \ / \
T2 T3 T1 T2
c) Right Right Case
z y
/ \ / \
T1 y Left Rotate(z) z x
/ \ - - - - - - - -> / \ / \
T2 x T1 T2 T3 T4
/ \
T3 T4
d) Right Left Case
z z x
/ \ / \ / \
T1 y Right Rotate (y) T1 x Left Rotate(z) z y
/ \ - - - - - - - - -> / \ - - - - - - - -> / \ / \
x T4 T2 y T1 T2 T3 T4
/ \ / \
T2 T3 T3 T4
最少节点
对于一棵平衡树,如果以NhNh表示深度为h时含有的最少结点数。有如下的规律:
N 0 = 0 , N 1 = 1 , N 2 = 2 ; N h = N h − 1 + N h − 2 + 1 N_0=0,N_1=1,N_2=2;\\N_h=N_{h−1}+N_{h−2}+1 N0=0,N1=1,N2=2;Nh=Nh−1+Nh−2+1
这里研究的是最小结点数,最多结点数自然是满二叉树时的,不必像最少结点这样需要递推分析。
最少结点的情况还可以从平衡因子看:所有非叶结点的平衡因子均为1。可以推论的是,均为-1也是最少结点的情况。
通常会围绕着最少结点,最大深度反复考察这个知识点。比如给定深度问最少需要多少个结点。或者给定结点数问最大能达到多少深度。
因此这个知识点可以形象化为深度是想达成的效果,越大越好,结点数是花费的成本,越小越好。举例如下:
1.含有20个结点的平衡二叉树的最大深度是(6)。
分析: N 0 = 0 , N 1 = 1 , N 2 = 2 ⟹ N 5 = 12 , N 6 = 20 N_0=0,N_1=1,N_2=2⟹N_5=12,N_6=20 N0=0,N1=1,N2=2⟹N5=12,N6=20,即构成深度为5的树至少需要12个结点,深度为6至少需要20个结点,因此20个结点能够达到的最大深度是6.2.具有5层结点的AVL树至少含有(12)个结点。
分析:由上面同样分析模式,5层至少含有12个结点。
Insertion Examples:

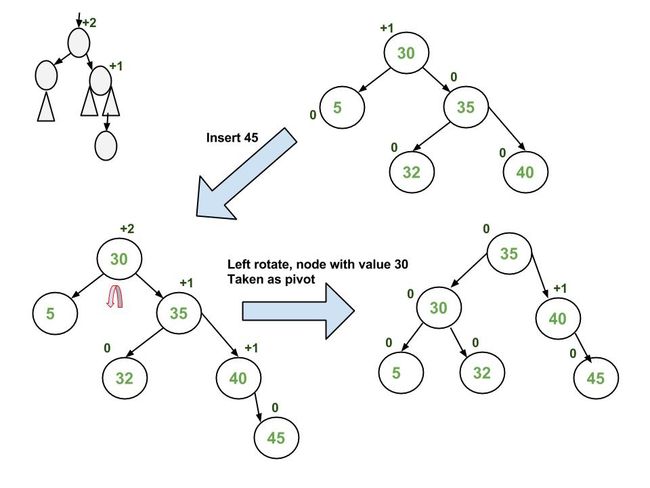

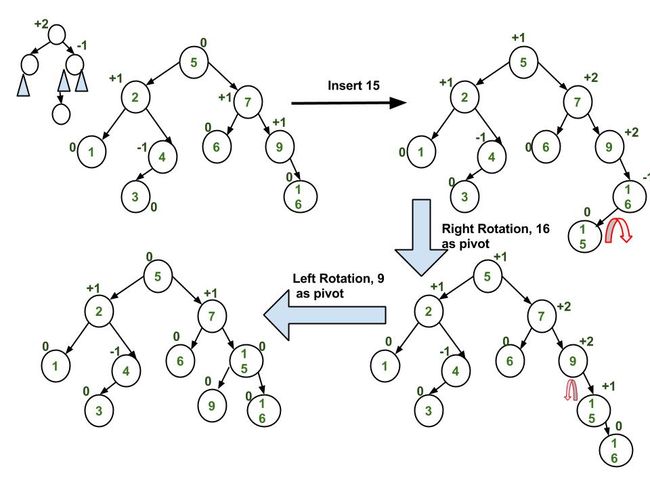
#include
#include
#include
#include
using namespace std;
typedef int KeyType;
typedef struct node
{
KeyType key ; //关键字的值
int bf;
struct node *lchild;
struct node *rchild;
}AVLTNode, *AVLTree;
//在平衡二叉树中插入元素K,使之成为一棵新的平衡二叉排序树
void ins_AVLtree(AVLTree *avlt , KeyType K)
{
AVLTNode *S;
AVLTNode *A,*FA,*p,*fp,*B,*C;
S=(AVLTree)malloc(sizeof(AVLTNode));
S->key=K;
S->lchild=S->rchild=NULL;
S->bf=0;
if (*avlt==NULL)
*avlt=S;
else
{
/* 首先查找S的插入位置fp,同时记录距S的插入位置最近且平衡因子不等于0(等于-1或1)的结点A,A为可能的失衡结点*/
A=*avlt; FA=NULL;
p=*avlt; fp=NULL;
while (p!=NULL)
{
if (p->bf!=0)
{
A=p; FA =fp;
}
fp=p;
if (K < p->key)
p=p->lchild;
else if (K > p->key)
p=p->rchild;
else
{
free(S);
return;
}
}
/* 插入S*/
if (K < fp->key)
fp->lchild=S;
else
fp->rchild=S;
/* 确定结点B,并修改A的平衡因子 */
if (K < A->key)
{
B=A->lchild;
A->bf=A->bf+1;
}
else
{
B=A->rchild;
A->bf=A->bf-1;
}
/* 修改B到S路径上各结点的平衡因子(原值均为0)*/
p=B;
while (p!=S)
if (K < p->key)
{
p->bf=1;
p=p->lchild;
}
else
{
p->bf=-1;
p=p->rchild;
}
/* 判断失衡类型并做相应处理 */
if (A->bf==2 && B->bf==1) /* LL型 */
{
B=A->lchild;
A->lchild=B->rchild;
B->rchild=A;
A->bf=0;
B->bf=0;
if (FA==NULL)
*avlt=B;
else
if (A==FA->lchild)
FA->lchild=B;
else
FA->rchild=B;
}
else
if (A->bf==2 && B->bf==-1) /* LR型 */
{
B=A->lchild;
C=B->rchild;
B->rchild=C->lchild;
A->lchild=C->rchild;
C->lchild=B;
C->rchild=A;
if (S->key < C->key)
{
A->bf=-1;
B->bf=0;
C->bf=0;
}
else
if (S->key >C->key)
{
A->bf=0;
B->bf=1;
C->bf=0;
}
else
{
A->bf=0;
B->bf=0;
}
if (FA==NULL)
*avlt=C;
else
if (A==FA->lchild)
FA->lchild=C;
else
FA->rchild=C;
}
else
if (A->bf==-2 && B->bf==1) /* RL型 */
{
B=A->rchild;
C=B->lchild;
B->lchild=C->rchild;
A->rchild=C->lchild;
C->lchild=A;
C->rchild=B;
if (S->key key)
{
A->bf=0;
B->bf=-1;
C->bf=0;
}
else
if (S->key >C->key)
{
A->bf=1;
B->bf=0;
C->bf=0;
}
else
{
A->bf=0;
B->bf=0;
}
if (FA==NULL)
*avlt=C;
else
if (A==FA->lchild)
FA->lchild=C;
else
FA->rchild=C;
}
else
if (A->bf==-2 && B->bf==-1) /* RR型 */
{
B=A->rchild;
A->rchild=B->lchild;
B->lchild=A;
A->bf=0;
B->bf=0;
if (FA==NULL)
*avlt=B;
else
if (A==FA->lchild)
FA->lchild=B;
else
FA->rchild=B;
}
}
}
void CreateAVLT(AVLTree *bst, char * filename)
/*从文件输入元素的值,创建相应的二叉排序树*/
{
FILE *fp;
KeyType keynumber;
*bst=NULL;
fp = fopen(filename,"r+");
while(EOF != fscanf(fp,"%d",&keynumber))
ins_AVLtree(bst, keynumber);
}
https://www.geeksforgeeks.org/avl-tree-set-1-insertio
https://blog.csdn.net/isunbin/article/details/81707606
4.2.4.最优二叉树 Haffuman Tree
一:什么是最优二叉树?
从我个人理解来说,最优二叉树就是从已给出的目标带权结点(单独的结点) 经过一种方式的组合形成一棵树.使树的权值最小. 最优二叉树是带权路径长度最短的二叉树。根据结点的个数,权值的不同,最优二叉树的形状也各不相同。它们的共同点是:带权值的结点都是叶子结点。权值越小的结点,其到根结点的路径越长
官方定义:
在权为wl,w2,…,wn的n个叶子所构成的所有二叉树中,带权路径长度最小(即代价最小)的二叉树称为最优二叉树或哈夫曼树。
二:下面先弄清几个几个概念:
1.路径长度
在树中从一个结点到另一个结点所经历的分支构成了这两个结点间的路径上的分支数称为它的路径长度
2.树的路径长度
树的路径长度是从树根到树中每一结点的路径长度之和。在结点数目相同的二叉树中,完全二叉树的路径长度最短。3.树的带权路径长度(Weighted Path Length of Tree,简记为WPL)
结点的权:在一些应用中,赋予树中结点的一个有某种意义的实数。
结点的带权路径长度:结点到树根之间的路径长度与该结点上权的乘积。
树的带权路径长度(Weighted Path Length of Tree):定义为树中所有叶结点的带权路径长度之和,通常记为:其中:
n表示叶子结点的数目
wi和li分别表示叶结点ki的权值和根到结点ki之间的路径长度。
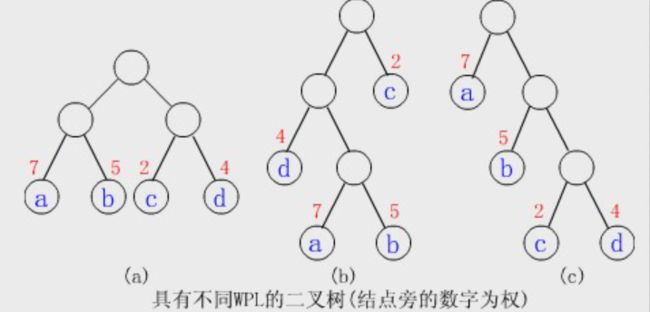
树的带权路径长度亦称为树的代价。三:用一个例子来理解一下以上概念
【例】给定4个叶子结点a,b,c和d,分别带权7,5,2和4。构造如下图所示的三棵二叉树(还有许多棵),它们的带权路径长度分别为:
(a) W P L = 7 ∗ 2 + 5 ∗ 2 + 2 ∗ 2 + 4 ∗ 2 = 36 WPL=7*2+5*2+2*2+4*2=36 WPL=7∗2+5∗2+2∗2+4∗2=36
(b) W P L = 7 ∗ 3 + 5 ∗ 3 + 2 ∗ 1 + 4 ∗ 2 = 46 WPL=7* 3+5*3+2*1+4*2=46 WPL=7∗3+5∗3+2∗1+4∗2=46
© W P L = 7 ∗ 1 + 5 ∗ 2 + 2 ∗ 3 + 4 ∗ 3 = 35 WPL=7*1+5*2+2*3+4*3=35 WPL=7∗1+5∗2+2∗3+4∗3=35其中©树的WPL最小,可以验证,它就是哈夫曼树。
注意:
① 叶子上的权值均相同时,完全二叉树一定是最优二叉树,否则完全二叉树不一定是最优二叉树。
② 最优二叉树中,权越大的叶子离根越近。
③ 最优二叉树的形态不唯一,WPL最小四.哈夫曼算法
对于给定的叶子数目及其权值构造最优二叉树的方法,由于这个算法是哈夫曼提出来的,故称其为哈夫曼算法。其基本思想是:
(1)根据给定的n个权值wl,w2,…,wn构成n棵二叉树的森林F={T1,T2,…,Tn},其中每棵二叉树Ti中都只有一个权值为wi的根结点,其左右子树均空。
(2)在森林F中选出两棵根结点权值最小的树(当这样的树不止两棵树时,可以从中任选两棵),将这两棵树合并成一棵新树,为了保证新树仍是二叉树,需 要增加一个新结点作为新树的根,并将所选的两棵树的根分别作为新根的左右孩子(谁左,谁右无关紧要),将这两个孩子的权值之和作为新树根的权值。
(3)对新的森林F重复(2),直到森林F中只剩下一棵树为止。这棵树便是哈夫曼树。
注意:
① 初始森林中的n棵二叉树,每棵树有一个孤立的结点,它们既是根,又是叶子
② n个叶子的哈夫曼树要经过n-1次合并,产生n-1个新结点。最终求得的哈夫曼树中共有2n-1个结点。
③ 哈夫曼树是严格的二叉树,没有度数为1的分支结点。
https://blog.csdn.net/csh624366188/article/details/7520997

https://www.codenong.com/cs106201947/
**霍夫曼编码(Huffman Coding)**是一种编码方式,是一种用于无损数据压缩的熵编码(权编码)算法。1952年,David A. Huffman在麻省理工攻读博士时所发明的,并发表于《一种构建极小多余编码的方法》(A Method for the Construction of Minimum-Redundancy Codes)一文。
在通信及数据传输中多采用二进制编码。为了使电文尽可能的缩短,可以对电文中每个字符出现的次数进行统计。设法让出现次数多的字符的二进制码短些,而让那些很少出现的字符的二进制码长一些。假设有一段电文,其中A,B,C,D出现的频率为0.4, 0.3, 0.2, 0.1。则得到的哈夫曼树和二进制前缀编码如图所示。在树中令所有左分支取编码为 0 ,令所有右分支取编码为1。将从根结点起到某个叶子结点路径上的各左、右分支的编码顺序排列,就得这个叶子结点所代表的字符的二进制编码。
这些编码拼成的电文不会混淆,因为每个字符的编码均不是其他编码的前缀,这种编码称做前缀编码。
https://www.iteye.com/blog/cake513-1184529
前缀编码:设计长短不等的编码,必须是任一字符的编码都不是另一个字符编码的前缀,这种编码称为前缀编码
https://blog.csdn.net/w_linux/article/details/78592274

4.2.5.堆积树 Heap Tree
A Heap is a special Tree-based data structure in which the tree is a complete binary tree. Generally, Heaps can be of two types:
-
Max-Heap: In a Max-Heap the key present at the root node must be greatest among the keys present at all of it’s children. The same property must be recursively true for all sub-trees in that Binary Tree.
大顶堆:根节点上存在的值必须在所有子节点上存在的值中最大。 对于该二叉树中的所有子树具有相同属性。
-
Min-Heap: In a Min-Heap the key present at the root node must be minimum among the keys present at all of it’s children. The same property must be recursively true for all sub-trees in that Binary Tree.
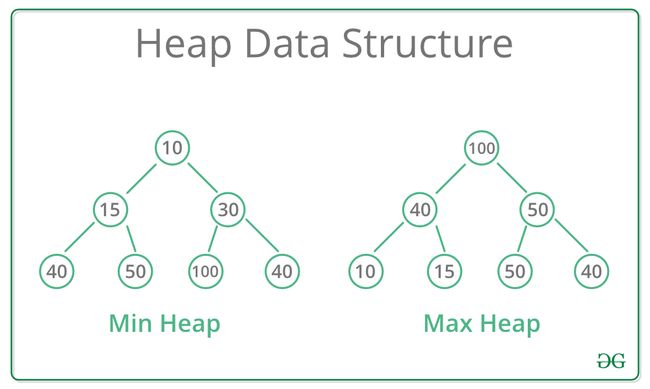
https://www.geeksforgeeks.org/heap-data-structure/
-
Applications of Heaps:
-
1) Heap Sort: Heap Sort uses Binary Heap to sort an array in O ( n ∗ l o g n ) O(n*logn) O(n∗logn) time.
-
2) Priority Queue: Priority queues can be efficiently implemented using Binary Heap because it supports insert(), delete() and extractmax(), decreaseKey() operations in O ( l o g n ) O(logn) O(logn) time. Binomoial Heap and Fibonacci Heap are variations of Binary Heap. These variations perform union also efficiently.
-
3) Graph Algorithms: The priority queues (优先队列) are especially used in Graph Algorithms like Dijkstra’s Shortest Path and Prim’s Minimum Spanning Tree.
-
4) Many problems can be efficiently solved using Heaps. See following for example.
a) K’th Largest Element in an array.
b) Sort an almost sorted array
c) Merge K Sorted Arrays.
TOP-K 问题

void heap_insert(int array[], int va,int Nnum,int Heapsize )
{
if (Nnum < Heapsize) {
array[Nnum++] = va;
if (Nnum == Heapsize) {
for (int i = Nnum / 2; i >= 0; i--) {
HeapAdjust(array, i, Nnum);
}
}
}
else {
int min = array[0];
if (va > min) {
array[0] = va;
HeapAdjust(array, 0, Nnum);
}
}
}
void HeapAdjust(int array[],int i,int nLength)
{
int temp =array[i];
for(int k=2*i+1;k=temp) break;
array[i]=array[k];
i=k;
}
array[i]=temp;
}
https://juejin.cn/post/6844903919932407821
5.Graph
定义:
A Graph consists of a finite set of vertices(or nodes) and set of Edges which connect a pair of nodes.

5.1 相关概念:
- 弧Arc : < v , w > ∈ V R
- 有向图Digraph
- 无向图Undigraph
- 边 Edge
- 完全图Completed graph
- 无向图 n ( n − 1 ) 2 \frac{n(n-1)}2 2n(n−1)条边
- 有向图 n ( n − 1 ) n(n-1) n(n−1)条弧
- 有权图
- 权:图的边或弧上搭载的权重数据
- 网:当图上的边或弧上带有权值时,图称为网
- 稀疏图Sparse graph e < n l o g n e
e<nlogn - 稠密图Dense graph
- 简单路径:序列($(v_i,v_j) $)中顶点不重复出现的路径称为简单路径
- 连通图(Connected Graph)
- 在无向图中,如果从顶点 v v v到顶点 v ′ v' v′有路径就说两个点是连通的。如果图中任意两点都是连通的,则称为连通图
- 连通分量(connected Commponent),指的是无向图中的极大连通子图
- 在有向图中,如果对于每对 v i , v j ∈ V , v i ≠ v j v_i,v_j\in V,v_i≠v_j vi,vj∈V,vi=vj,相互都存在路径,则称为强连通图
- 强连通分量,极大强连通子图
- 生成树:一个连通图的生成树是一个极小连通子图,它包含图中全部顶点,但只有构成树的n-1条边。如果再增加一条边必构成环
- 在无向图中,如果从顶点 v v v到顶点 v ′ v' v′有路径就说两个点是连通的。如果图中任意两点都是连通的,则称为连通图
5.2 图的存储结构
图没有顺序映像存储结构,因为图的结构比较复杂,任意两个顶点之间都可能存在联系,无法以数据元素在存储区的物理位置来表示元素之间的关系。但是可以借助数组的数据类型表示元素之间的关系。即邻接矩阵
那么自然就想到链式映像存储结构,但是由于顶点的度很可能不相同,这也给多重链表定义指针域带来了麻烦,如果取最大度空间浪费很大,如果灵活取的话,实现上也带来了 一定难度,很复杂。
常用的有邻接表、邻接多重表、十字链表
5.2.1 邻接矩阵
图上顶点的邻接
无向图中,两个顶点有边连接,则两个顶点互为邻接。

A与B邻接,B与A邻接。
有向图中,两个顶点有弧连接,则接收方邻接发送方。

A与B不邻接,B与A邻接。
定义:设图G=(V,{E})有n个顶点,则G的邻接矩阵定义为n阶方阵A。
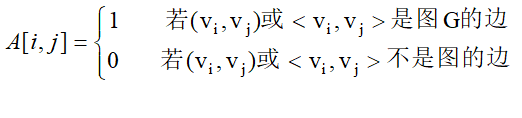
求度容易
无向图:

即顶点 v i v_i vi的度等于邻接矩阵中第i行(或第i列)的元素之和(非0元素个数)。
有向图:
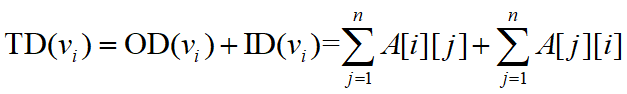
即顶点 v i v_i vi的出度为邻接矩阵中第 i i i行元素之和顶点 v i v_i vi的入度为邻接矩阵中第 i i i列元素之和。
带权邻接矩阵
如果G是带权图, w i , j w_{i,j} wi,j是边 ( v i , v j ) (v_i,v_j) (vi,vj)或 < v i , v j >


5.2.2 邻接表(Adjacency List)
对图中每个顶点 v i v_i vi建立一个单链表,链表中的结点表示依附于顶点 v i v_i vi的边,每个链表结点为两个域:

邻接点域 ( a d j v e x ) (adjvex) (adjvex)记载与顶点 v i v_i vi邻接的顶点信息;
链域 ( n e x t a r c ) (nextarc) (nextarc)指向下一个与顶点 v i v_i vi邻接的链表结点。
每个链表附设一个头结点,头结点结构为:

v e x d a t a vexdata vexdata存放顶点信息(姓名、编号等);
f r i s t a r c fristarc fristarc指向链表的第一个结点。
无向图邻接表特点:
-
n个顶点,e条边的无向图,需n个头结点和2e个链表结点;
-
顶点$ v_i $的度 $TD(v_i) = 链 表 链表 链表i$中的链表结点数。
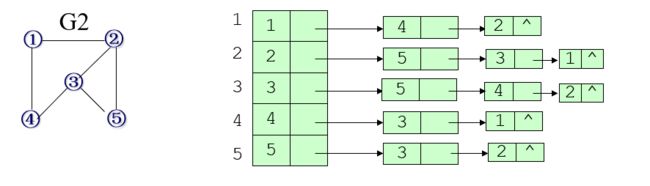
有向图邻接表特点
求顶点的出度易,求入度难
- n个顶点,e条弧的有向图,需n个表头结点,e 个链表结点;
- 第$ i 条 链 表 上 的 链 表 结 点 数 , 为 条链表上的链表结点数,为 条链表上的链表结点数,为 v_i$ 的出度。

有向图逆邻接表特点——求顶点的入度易,求出度难

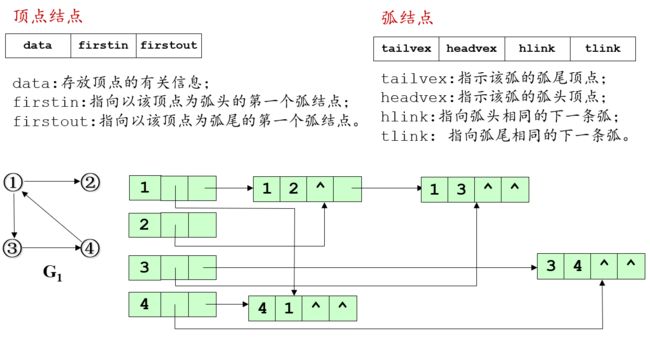
5.2.3 十字链表(Orthogonal List)
十字链表是将有向图的邻接表和逆邻接表结合起来的一种有向图链式存储结构。有向图的每一条弧有一个弧结点,每一个顶点有一个顶点结点。
5.3 图的遍历
从图中某个顶点出发,沿路径使图中每个顶点被访问且仅被访问一次的过程,称为图的遍历。
两种常用遍历图的方法:
- 深度优先搜索(depth-first-search)
① 访问指定的当前顶点顶点v;
② 设置新的当前顶点v为未被访问邻接点;
③ 重复②直到当前顶点v的所有邻接点都被访问;
④ 沿搜索路径回退,退到尚有邻接点未被访问过的某结点,将该结点作为新的当前结点v ,重复② ,直到所有顶点被访问过的为止。 - 广度优先搜索(breadth-first-search)
① 访问指定的当前顶点顶点v;
② 访问当前顶点的所有未访问过的邻接点;
③ 依次将访问的这些邻接点作为当前顶点v;
④ 重复②, 直到所有顶点被访问为止。

5.4 图的经典算法
- ①无向图求最小生成树——Prim算法、Kruskal算法
- ②有向图环的检查——拓扑排序算法
- ③有向无环图(AOV网)——关键路径算法
- ④图的最短路径——单源Dijkestra算法、全源Floyd算法
https://www.cnblogs.com/rude3knife/p/13546519.html

5.4.1 生成树 Spanning Tree & MST
定义:
设无向连通图 G = ( V , { E } ) G =(V,\{E\}) G=(V,{ E}),其子图 G ’ = ( V , { T } ) G’=(V,\{T\}) G’=(V,{ T})满足:
①$ V(G’)=V(G)$ n n n个顶点;
②$ G’$是连通的;
③ G ’ G’ G’中无回路,
则 G ’ G’ G’是 G G G的生成树(Spanning Tree)。
注:具有n个顶点的无向连通图 G G G其任一生成 G ’ G’ G’恰好含$ n-1 $条边,生成树不一定唯一,若有环存在甚至不是树。

例1: n 台计算机之间建立通讯网,顶点表示计算机,边表示通信线,边上的权重表示通信的代价。要求:① n台计算机中的任何两台能通过网进行通讯;② 使总的代价最小。
MST
带权图的生成树中,总权重最小的称为最小生成树。
最小生成树MST
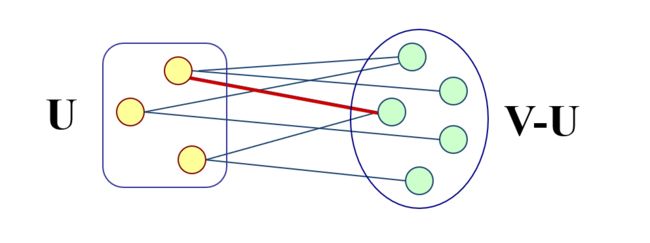
设 G = ( V , { E } ) G = (V,\{E\}) G=(V,{ E}),U是顶点集V的一个非空子集。$ u∈U,v∈V-U , 若 , 若 ,若 (u, v) $是一条具有最小权值的边,即
( u , v ) = a r g min { c o s t ( x , y ) ∣ x ∈ U , y ∈ V − U } (u, v) = arg \ \min\{cost (x, y) | x∈U, y∈V-U\} (u,v)=arg min{ cost(x,y)∣x∈U,y∈V−U}
则必存在一棵包含边 (u, v) 的最小生成树。0唯一性
如果图的每一条边的权值都互不相同,那么最小生成树将只有一个。这一定理同样适用于最小生成森林。
证明: 假设图 G G G为每条边权值互不相同的连通图,且有两个不同的最小生成树 T T T和 T ′ {\displaystyle T'} T′。
则 T T T中必然存在一些在 T ′ {\displaystyle T'} T′中并不存在的边,取其中一条这样的边 e 0 {\displaystyle e_{0}} e0.
因为 T ′ {\displaystyle T'} T′是最小生成树,所以若往 T ′ {\displaystyle T'} T′中添加边 e 0 {\displaystyle e_{0}} e0,则将会出现环路。(因为有 m m m个顶点的树有且仅有 m − 1 m-1 m−1条边)
同时可知,如果从 T T T中删除边 e 0 {\displaystyle e_{0}} e0,则 T T T将分为互不连通的两个连通分量。因为 e 0 ∉ T ′ {\displaystyle e_{0}\notin T'} e0∈/T′,所以 T ′ {\displaystyle T'} T′中必然有其他的边连接这两个连通分量。且将 e 0 {\displaystyle e_{0}} e0加入 T ′ {\displaystyle T'} T′后形成的环路中,除了 e 0 {\displaystyle e_{0}} e0外至少有另一条连接 T T T中删除 e 0 {\displaystyle e_{0}} e0后的这两个连通分量的边。取其中一条这样的边,记作 e 0 ′ {\displaystyle {e_{0}}'} e0′。此时若将 e 0 ′ {\displaystyle {e_{0}}'} e0′加入 T T T,则可连接从 T T T中删除 e 0 {\displaystyle e_{0}} e0后得到的两个连通分量,并形成一棵不同的生成树。
因为 G G G中所有边的权值互不相同,所以关于 e 0 {\displaystyle e_{0}} e0和 e 0 ′ {\displaystyle {e_{0}}'} e0′的权重大小关系,可能有以下两种情况之一:
若 e 0 < e 0 ′ {\displaystyle e_{0}<{e_{0}}'} e0<e0′,则可从 T ′ {\displaystyle T'} T′中删除 e 0 ′ {\displaystyle {e_{0}}'} e0′并加入 e 0 {\displaystyle e_{0}} e0,从而得到一棵总权值更小的生成树。这和 T ′ {\displaystyle T'} T′是最小生成树相矛盾。
若 e 0 > e 0 ′ {\displaystyle e_{0}>{e_{0}}'} e0>e0′,则可从 T {\displaystyle T} T中删除 e 0 {\displaystyle e_{0}} e0并加入 e 0 ′ {\displaystyle {e_{0}}'} e0′,从而得到一棵总权值更小的生成树。同样,这和 T T T是最小生成树相矛盾。
综上,若 G G G各边权重互不相等,则不可能存在两棵互不相同的最小生成树。即 G G G的最小生成树是唯一的。https://zh.m.wikipedia.org/zh-hans/最小生成树
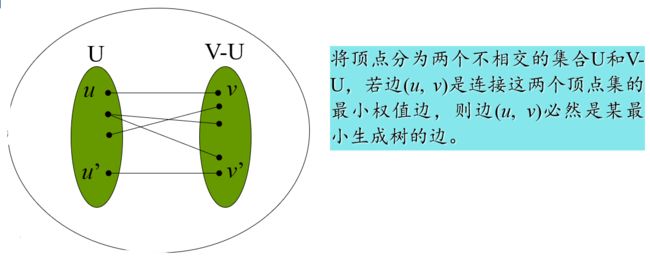
在生成树的构造过程中,图中 n 个顶点分属两个集合:已落在生成树上的顶点集 U 和尚未落在生成树上的顶点集V-U 。
则应在所有连通U中顶点和V-U中顶点的边中选取权值最小的边,且不构成回路。
求取最小生成树的算法:
计算稠密图的最小生成树最早是由罗伯特·普里姆(英语:Robert C. Prim)在1957年发明的,即Prim算法。之后艾兹赫尔·戴克斯特拉也独自发明了它。但该算法的基本思想是由沃伊捷赫·亚尔尼克(英语:Vojtěch Jarník)于1930年发明的。所以该算法有时候也被称为Jarník算法或者Prim-Jarník算法。20世纪70年代,优先队列发明之后很快被用在了寻找稀疏图中的最小生成树上。1984年,迈克尔·弗里德曼和罗伯特·塔扬发明了斐波那契堆,Prim算法所需要的运行时间在理论上由 E log E {\displaystyle E\log E} ElogE提升到了 E + V log V {\displaystyle E+V\log V} E+VlogV。约瑟夫·克鲁斯卡尔(英语:Joseph Kruskal)在1956年发表了他的算法,在他的论文中提到了Prim算法的一个变种,而奥塔卡尔·布卢瓦卡(英语:Otakar Borůvka)在20世纪20年代的论文中就已经提到了该变种。M.Sollin在1961年重新发现了该算法,该算法后成为实现较好渐进性能的最小生成树算法和并行最小生成树算法的基础。
- Kruskal算法 - 一种贪心算法,复杂度是 O ( E log E ) {\displaystyle O(E\log {E})} O(ElogE)。
- Prim算法 - 另一种贪心算法,用二叉堆优化时复杂度是 O ( E + V log V ) {\displaystyle O(E+V\log {V})} O(E+VlogV)。当边数远远大于点数,可近似认为是 ${\displaystyle O(E)} $。
Prim 算法
描述:
从单一顶点开始,普里姆算法按照以下步骤逐步扩大树中所含顶点的数目,直到遍及连通图的所有顶点。
输入:一个加权连通图,其中顶点集合为 V V V,边集合为 E E E;
初始化: V new = { x } {\displaystyle V_{\text{new}}=\{x\}} Vnew={ x},其中x为集合V中的任一节点(起始点), E new = { } {\displaystyle E_{\text{new}}=\{\}} Enew={ };
重复下列操作,直到 V new = V {\displaystyle V_{\text{new}}=V} Vnew=V:
在集合E中选取权值最小的边 ( u , v ) (u,v) (u,v),其中u为集合 V new {\displaystyle V_{\text{new}}} Vnew中的元素,而v则是V中没有加入 V new {\displaystyle V_{\text{new}}} Vnew的顶点(如果存在有多条满足前述条件即具有相同权值的边,则可任意选取其中之一);
将 v v v加入集合 V n e w V_{new} Vnew中,将 ( u , v ) (u,v) (u,v)加入集合 E new {\displaystyle E_{\text{new}}} Enew中;
输出:使用集合 V new {\displaystyle V_{\text{new}}} Vnew和 E new {\displaystyle E_{\text{new}}} Enew来描述所得到的最小生成树。
| 最小边、权的数据结构 | 时间复杂度(总计) |
|---|---|
| 邻接矩阵、搜索 | ${\displaystyle O( |
| 二叉堆(后文伪代码中使用的数据结构)、邻接表 | ${\displaystyle O(( |
| 斐波那契堆、邻接表 | ${\displaystyle O( |
通过邻接矩阵图表示的简易实现中,找到所有最小权边共需 O ( ∣ V ∣ 2 ) {\displaystyle O(|V|^{2})} O(∣V∣2))的运行时间。使用简单的二叉堆与邻接表来表示的话,普里姆算法的运行时间则可缩减为 O ( ∣ E ∣ log ∣ V ∣ ) {\displaystyle O(|E|\log |V|)} O(∣E∣log∣V∣),其中 ∣ E ∣ |E| ∣E∣为连通图的边集大小, ∣ V ∣ |V| ∣V∣为点集大小。如果使用较为复杂的斐波那契堆,则可将运行时间进一步缩短为 O ( ∣ E ∣ + ∣ V ∣ log ∣ V ∣ ) {\displaystyle O(|E|+|V|\log |V|)} O(∣E∣+∣V∣log∣V∣),这在连通图足够密集时(当 ∣ E ∣ |E| ∣E∣满足 Ω ( ∣ V ∣ log ∣ V ∣ ) {\displaystyle \Omega (|V|\log |V|)} Ω(∣V∣log∣V∣)时),可较显著地提高运行速度。
//来源:严蔚敏 吴伟民《数据结构(C语言版)》
void MiniSpanTree_PRIM (MGraph G, VertexType u) {
/* 用普利姆算法從第u個頂點出發構造網G 的最小生成樹T,輸出T的各條邊。
記錄從頂點集U到V-U的代價最小的邊的輔助數組定義:
struct
{
VertexType adjvex;
VRtype lowcost;
}closedge[MAX_VERTEX_NUM];
*/
k = LocateVex(G, u);
for (j = 0 ; j < G.vexnum; j++) { //輔助數組初始化
if (j != k)
closedge[j] = {u, G.arcs[k][j].adj}; //{adjvex, lowcost}
}
closedge[k].lowcost = 0; //初始,U={u}
for (i = 1; i < G.vexnum ; i++) { //選擇其餘G.vexnum -1 個頂點
k = minimum(closedge); //求出T的下個結點:第k結點
// 此时 closedge[k].lowcost = MIN{ closedge[Vi].lowcost|closedge[Vi].lowcost>0,Vi∈V-U}
printf(closedge[k].adjvex, G.vexs[k]); //輸出生成樹的邊
closedge[k].lowcost = 0; //第k條邊併入U集
for (j = 0; j < G.vexnum; j++) {
//新頂點併入U後重新選擇最小邊
if (G.arcs[k][j].adj < closedge[j].lowcost && closedge[j].lowcost!=0)
closedge[j] = {G.vex[k], G.arcs[k][j].adj};
}
}
}
//来源: 浙大-陈越 《数据结构》
#define ERROR -1
Vertex FindMinDist( MGraph Graph, WeightType dist[] )
{
/* 返回未被收录顶点中dist最小者 */
Vertex MinV, V;
WeightType MinDist = INFINITY;
for (V=0; VNv; V++) {
if ( dist[V]!=0 && dist[V]Nv; V++) {
/* 这里假设若V到W没有直接的边,则Graph->G[V][W]定义为INFINITY */
dist[V] = Graph->G[0][V];
parent[V] = 0; /* 暂且定义所有顶点的父结点都是初始点0 */
}
TotalWeight = 0; /* .
..........初始化权重和 */
VCount = 0; /* 初始化收录的顶点数 */
/* 创建包含所有顶点但没有边的图。注意用邻接表版本 */
MST = CreateGraph(Graph->Nv);
E = (Edge)malloc( sizeof(struct ENode) ); /* 建立空的边结点 */
/* 将初始点0收录进MST */
dist[0] = 0;
VCount ++;
parent[0] = -1; /* 当前树根是0 */
while (1) {
V = FindMinDist( Graph, dist );
/* V = 未被收录顶点中dist最小者 */
if ( V==ERROR ) /* 若这样的V不存在 */
break; /* 算法结束 */
/* 将V及相应的边收录进MST */
E->V1 = parent[V];
E->V2 = V;
E->Weight = dist[V];
InsertEdge( MST, E );
TotalWeight += dist[V];
dist[V] = 0;
VCount++;
for( W=0; WNv; W++ ) /* 对图中的每个顶点W */
if ( dist[W]!=0 && Graph->G[V][W]G[V][W] < dist[W] ) {
/* 若收录V使得dist[W]变小 */
dist[W] = Graph->G[V][W]; /* 更新dist[W] */
parent[W] = V; /* 更新树 */
}
}
} /* while结束*/
if ( VCount < Graph->Nv ) /* MST中收的顶点不到|V|个 */
TotalWeight = ERROR;
return TotalWeight; /* 算法执行完毕,返回最小权重和或错误标记 */
}
Kruskal算法
描述:
- 新建图G,G中拥有原图中相同的节点,但没有边
- 将原图中所有的边按权值从小到大排序
- 从权值最小的边开始,如果这条边连接的两个节点于图G中不在同一个连通分量中,则添加这条边到图G中
- 重复3,直至图G中所有的节点都在同一个连通分量中
KRUSKAL-FUNCTION(G, w)
1 F := 空集合
2 for each 图 G 中的顶点 v
3 do 将 v 加入森林 F
4 所有的边(u, v) ∈ E依权重 w 递增排序
5 for each 边(u, v) ∈ E
6 do if u 和 v 不在同一棵子树
7 then F := F ∪ {(u, v)}
8 将 u 和 v 所在的子树合并
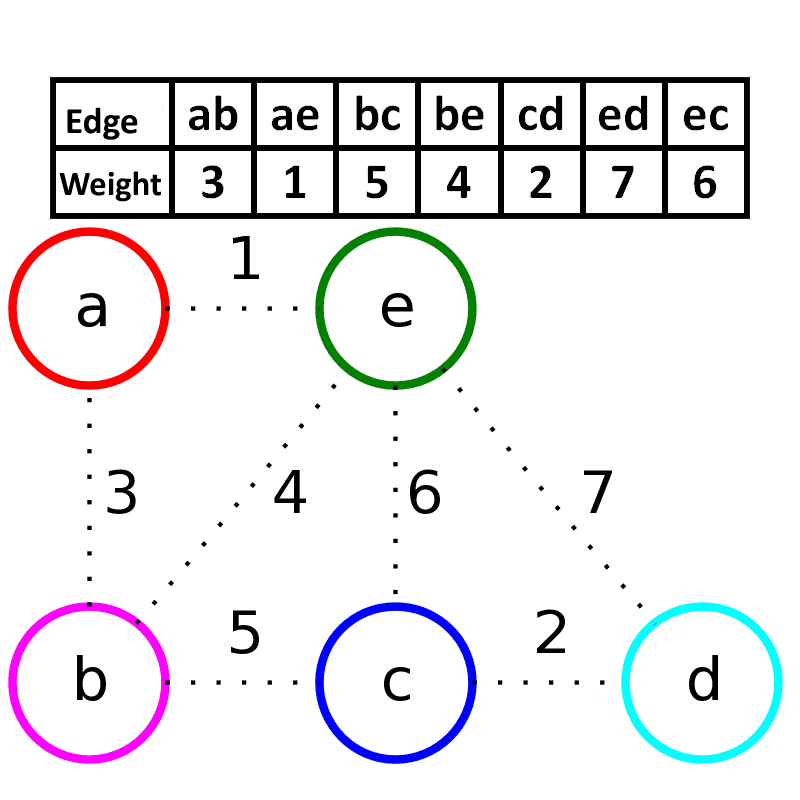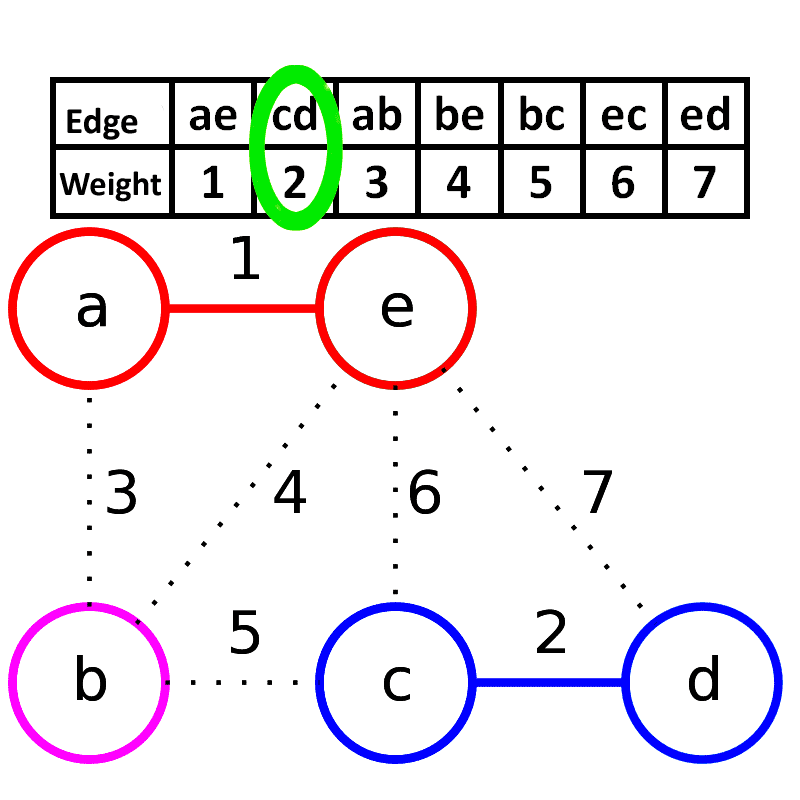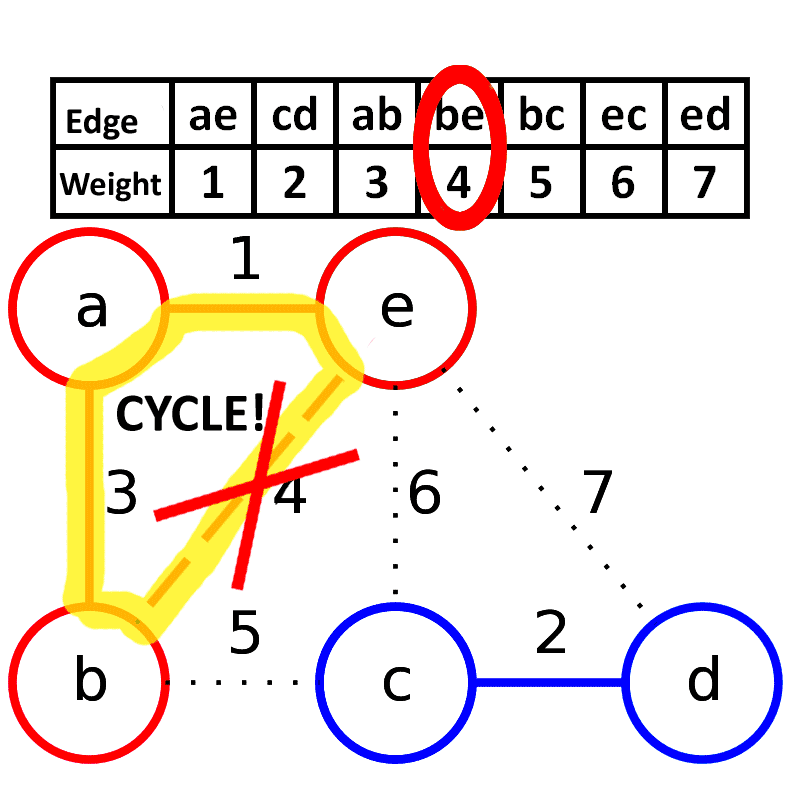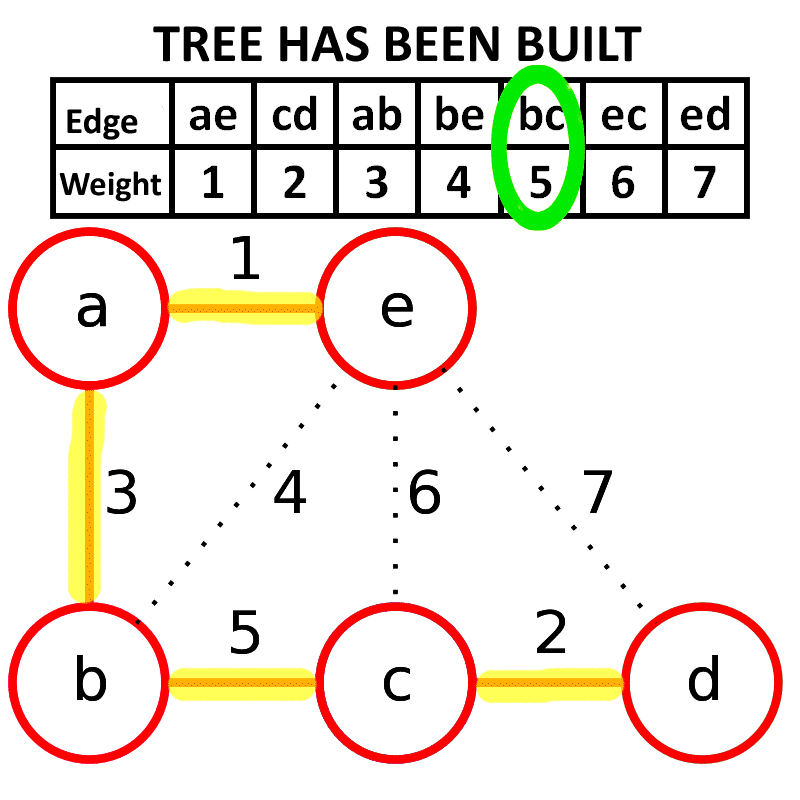
两者比较
| Prim算法 | Kruskal算法 |
|---|---|
| 以连通为主; | 以最小代价边主; |
| 选保证连通的代价最小的邻接边; | 添加不形成回路的当前最小代价边; |
| 普里姆算法的时间复杂度与边无关,为O(n2) ; | 算法时间复杂度与边相关,为Ο(elog2e) ; |
| 适合于求边稠密网的最小生成树。 | 适合于求边稀疏网的最小生成树。 |
5.4.2 拓扑排序Topological sort
拓扑排序是一种对非线性结构的有向图进行线性化的重要手段。
假设以有向图表示一个工程的施工图,则图中不允许出现回路。检查有向图中是否存在回路的方法之一,是对有向图进行拓扑排序。
AOV网(activity on vertex network)
一个有向图可用来表示一个施工流程图、一个产品生产流程图、或一个程序框图等。

按照有向图给出的前驱后继关系,将图中顶点排成一个线性序列,对于有向图中没有限定次序关系的顶点,则可以人为加上任意的次序关系。
由此所得顶点的线性序列称之为拓扑有序序列。

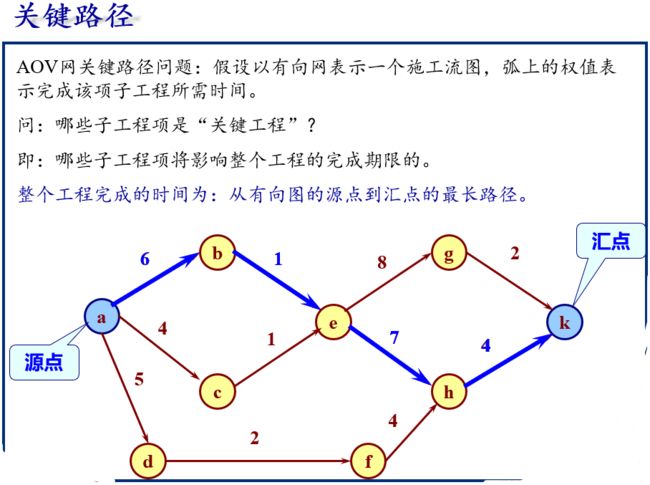
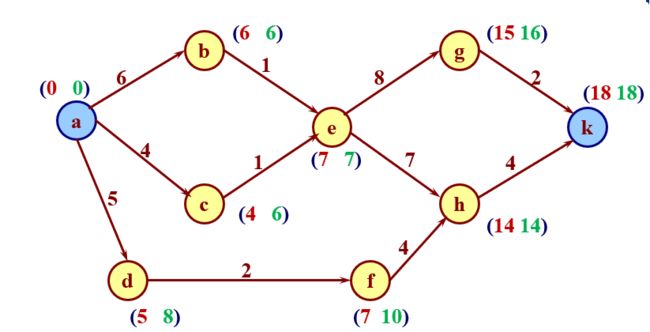
标号法求解关键路径
-
正向求和之最大
-
逆向求差之最小
正逆二向相等的节点为关键节点
5.4.3 最短路径
图的最短路径问题有二:
-
其一:求从某个源点到其余各点的最短路径——单源最短路径问题;
-
其二:每一对顶点之间的最短路径——全源最短路径问题。
Dijkestra
单源最短路径的迪杰斯特拉(Dijkestra)算法
-
(1) 路径长度最短的最短路径
- 在这条路径上,必定只含一条弧,并且这条弧的权值最小;
-
(2) 路径长度次短的最短路径
- 或者是直接从源点到该点(只含一条弧);
- 或者是从源点经过顶点v1,再到达该顶点(由两条弧组成);
-
(3) 其余最短路径的特点
- 或者是直接从源点到该点(只含一条弧);
- 或者是从源点经过已求得最短路径的顶点,再到达该顶点。
#include
#include
#define V 9
int minDistance(int dist[], bool sptSet[])
{
int min = INT_MAX, min_index;
for (int v = 0; v < V; v++)
if (sptSet[v] == false && dist[v] <= min)
min = dist[v], min_index = v;
return min_index;
}
void printSolution(int dist[])
{
printf("Vertex \t\t Distance from Source\n");
for (int i = 0; i < V; i++)
printf("%d \t\t %d\n", i, dist[i]);
}
void dijkstra(int graph[V][V], int src)
{
int dist[V];
bool sptSet[V];
for (int i = 0; i < V; i++)
dist[i] = INT_MAX, sptSet[i] = false;
dist[src] = 0;
for (int count = 0; count < V - 1; count++) {
int u = minDistance(dist, sptSet);
sptSet[u] = true;
//更新选取的顶点的相邻顶点的dist值。
for (int v = 0; v < V; v++)
//仅当不在sptSet中且在u到v之间存在边且从src到通过u的v的路径的总权重
//小于dist [v]的当前值时,才更新dist [v]。
if (!sptSet[v] && graph[u][v] && dist[u] != INT_MAX
&& dist[u] + graph[u][v] < dist[v])
dist[v] = dist[u] + graph[u][v];
} //输出结果
printSolution(dist);
}
int main()
{
int graph[V][V] = { { 0, 4, 0, 0, 0, 0, 0, 8, 0 },
{ 4, 0, 8, 0, 0, 0, 0, 11, 0 },
{ 0, 8, 0, 7, 0, 4, 0, 0, 2 },
{ 0, 0, 7, 0, 9, 14, 0, 0, 0 },
{ 0, 0, 0, 9, 0, 10, 0, 0, 0 },
{ 0, 0, 4, 14, 10, 0, 2, 0, 0 },
{ 0, 0, 0, 0, 0, 2, 0, 1, 6 },
{ 8, 11, 0, 0, 0, 0, 1, 0, 7 },
{ 0, 0, 2, 0, 0, 0, 6, 7, 0 } };
dijkstra(graph, 0);
return 0;
}
Floyd算法


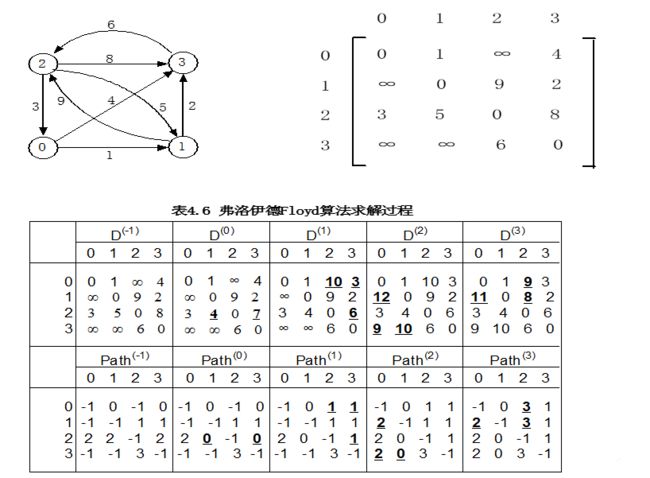
6. 查找
查找——查询给定key的物理位置
在数据集合上的查找涉及到两个主要问题:
-
一是数据及其结构是如何组织的 —— 查找表
-
二是在查找表上如何进行查找运算 —— 查找方法
强调:查找表是由同类型的数据元素(或记录)构成的集合。
在顺序表上的查找:①顺序查找、②折半查找;
在索引表上的查找:③索引查找
在散列表上的查找:④哈希查找
6.1 分类
静态查找:仅作查询和检索操作的查找。
动态查找:将查询结果“不在查找表中”的数据元素插入到查找表中;或者,从查找表中删除其查询结果为“在查找表中”的数据元素。
查找过程中往往是依据数据元素的某个数据项进行查找,这个数据项通常是数据的关键字。
关键字:是数据元素中某个数据项的值,用以标识一个数据元素。
若关键字能标识唯一的一个数据元素,则称谓主关键字(key word)。
若关键字能标识若干个数据元素,则称谓次关键字。
6.2 算法性能评估
平均查找长度(Average Search Length)
A S L = p 1 ∗ C 1 + p 2 ∗ C 2 + . . . + p n ∗ C n ASL = p_1*C_1+p_2*C_2+...+p_n*C_n ASL=p1∗C1+p2∗C2+...+pn∗Cn
p i p_i pi——查找第i个元素的概率
C i C_i Ci——查找第i个元素需要比较的次数
不失一般性,我们考虑等概率情况,则 p i = 1 n p_i = \frac1n pi=n1
那么,对ASL性能的评价重点都在 C i C_i Ci上。
6.3 顺序表的查找
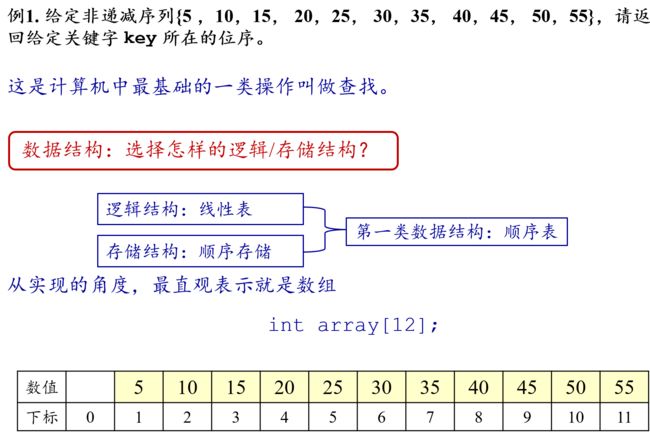
6.3.1 顺序查找
这就是数组的查找方式,从数组的一端开始一一比较,直到找到或者到达另一端查找失败。
时间复杂度为 n + 1 2 \frac{n+1}2 2n+1
6.3.2 折半查找
所给的序列必须是有序的
Binary Search: Search a sorted array by repeatedly dividing the search interval in half. Begin with an interval covering the whole array. If the value of the search key is less than the item in the middle of the interval, narrow the interval to the lower half. Otherwise narrow it to the upper half. Repeatedly check until the value is found or the interval is empty.
https://www.geeksforgeeks.org/binary-search/

// C program to implement recursive Binary Search
#include
// A recursive binary search function. It returns
// location of x in given array arr[l..r] is present,
// otherwise -1
int binarySearch(int arr[], int l, int r, int x)
{
if (r >= l) {
int mid = l + (r - l) / 2;
// If the element is present at the middle
// itself
if (arr[mid] == x)
return mid;
// If element is smaller than mid, then
// it can only be present in left subarray
if (arr[mid] > x)
return binarySearch(arr, l, mid - 1, x);
// Else the element can only be present
// in right subarray
return binarySearch(arr, mid + 1, r, x);
}
// We reach here when element is not
// present in array
return -1;
}
int main(void)
{
int arr[] = { 2, 3, 4, 10, 40 };
int n = sizeof(arr) / sizeof(arr[0]);
int x = 10;
int result = binarySearch(arr, 0, n - 1, x);
(result == -1) ? printf("Element is not present in array")
: printf("Element is present at index %d",
result);
return 0;
}
// C program to implement iterative Binary Search
#include
// A iterative binary search function. It returns
// location of x in given array arr[l..r] if present,
// otherwise -1
int binarySearch(int arr[], int l, int r, int x)
{
while (l <= r) {
int m = l + (r - l) / 2;
// Check if x is present at mid
if (arr[m] == x)
return m;
// If x greater, ignore left half
if (arr[m] < x)
l = m + 1;
// If x is smaller, ignore right half
else
r = m - 1;
}
// if we reach here, then element was
// not present
return -1;
}
int main(void)
{
int arr[] = { 2, 3, 4, 10, 40 };
int n = sizeof(arr) / sizeof(arr[0]);
int x = 10;
int result = binarySearch(arr, 0, n - 1, x);
(result == -1) ? printf("Element is not present"
" in array")
: printf("Element is present at "
"index %d",
result);
return 0;
}

6.3.3 索引表
索引,书的目录就是一种索引,使用索引能够快速地定位查找范围。
计算机中对数据的存储和管理可以采用索引以提高效率。
当数据量太大,以至内存装不下,建立数据“索引”以解决空间复杂度。
索引表的建立分三步
- ① 分块:按查找表中数据按关键字分成若干块:R1, R2, …, RL,使得数据“分块有序”;
- ② 建立索引项:为每一个块建立一个索引项:
- 关键字项(记录块中最大关键字值)
- 指针项(记录块的起始地址)
- ③ 建立索引表:将所有索引项管理起来组成索引表。

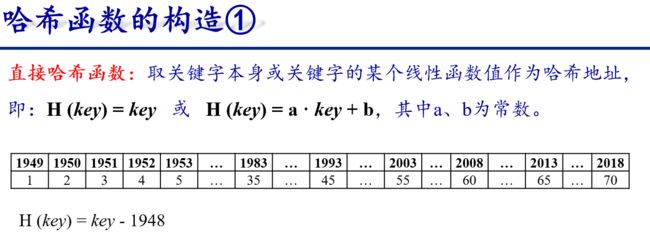
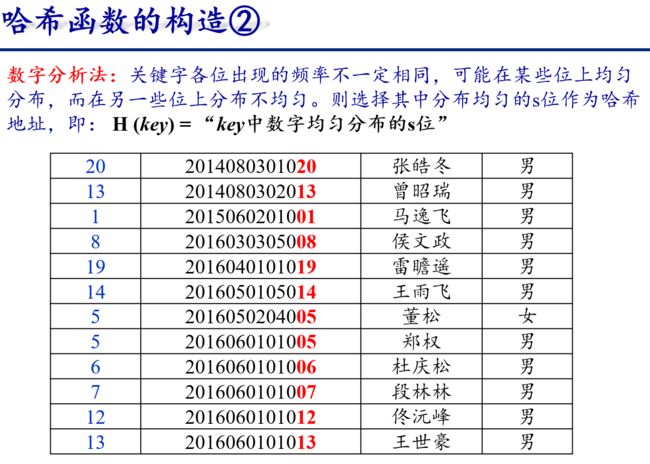
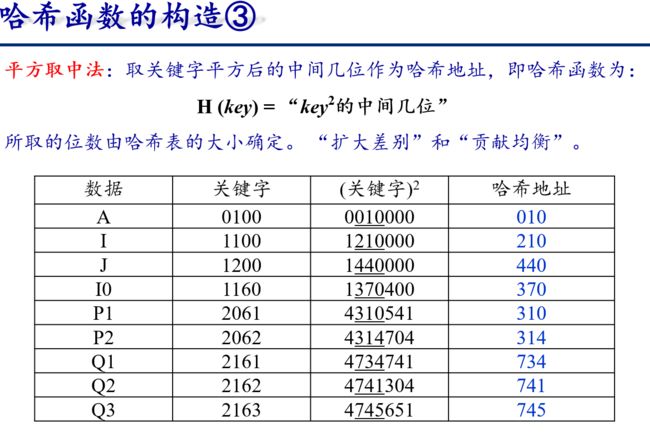
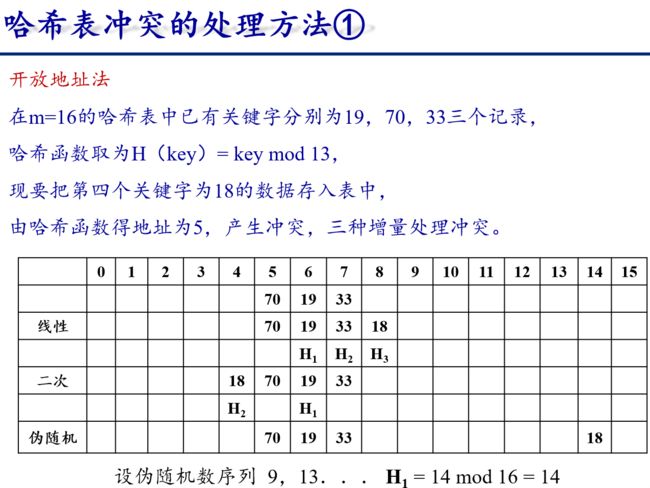
6.3.4 散列表

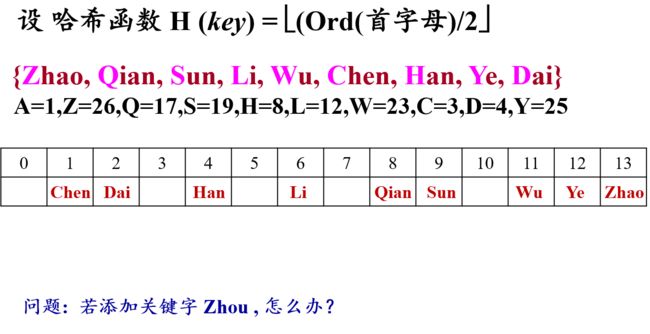
从上面例子可以看出
- 哈希函数是一个映象,它的设置很灵活,只要这个地址集合的大小不超出允许范围即可;
- 由于哈希函数是一个压缩映象,因此,一般容易产生“冲突”现象,即: key1 ≠ key2,而 H(key1) = H(key2)。
- 很难找到一个不产生冲突的哈希函数。只能选择恰当的哈希函数,使冲突尽可能少地产生。
因此,哈希查需要做两方面事情:
- 选择一个“好”的哈希函数;
- 提供一种“处理冲突” 的方法。











7. 排序
参考:https://www.cnblogs.com/onepixel/articles/7674659.html
8. 动态归化
https://www.zhihu.com/question/23995189
https://www.zhihu.com/question/410196236
https://www.zhihu.com/question/291280715
https://en.wikipedia.org/wiki/Dynamic_programming
好代码TIPS
变量命名规则
局部变量用小写 la_len
全局变量用大写开头 La_Len //慎用
宏定义 LA_LEN
对称性:
lchrild VS left_chrild
rchrild VS right_chrild
能用局部变量就用局部变量
int i;
for(i=1;...)
///
for(int i;...) //更好 推荐
局部变量能够减少一些不必要的麻烦,比如安全问题。
代码可读性
while循环里写return就会出现需要费时间去研究什么时候满足什么条件时返回值
但如果写进if语句里就一目了然了。
命中率
尽量将可能性高的写在if中或者switch前几项
-
(result == -1) ? printf(“Element is not present in array”)
-
printf(“Element is present at index %d”,
result);
return 0;
}
```C
// C program to implement iterative Binary Search
#include
// A iterative binary search function. It returns
// location of x in given array arr[l..r] if present,
// otherwise -1
int binarySearch(int arr[], int l, int r, int x)
{
while (l <= r) {
int m = l + (r - l) / 2;
// Check if x is present at mid
if (arr[m] == x)
return m;
// If x greater, ignore left half
if (arr[m] < x)
l = m + 1;
// If x is smaller, ignore right half
else
r = m - 1;
}
// if we reach here, then element was
// not present
return -1;
}
int main(void)
{
int arr[] = { 2, 3, 4, 10, 40 };
int n = sizeof(arr) / sizeof(arr[0]);
int x = 10;
int result = binarySearch(arr, 0, n - 1, x);
(result == -1) ? printf("Element is not present"
" in array")
: printf("Element is present at "
"index %d",
result);
return 0;
}
[外链图片转存中…(img-Ofy0W3x1-1609058590469)]
6.3.3 索引表
索引,书的目录就是一种索引,使用索引能够快速地定位查找范围。
计算机中对数据的存储和管理可以采用索引以提高效率。
当数据量太大,以至内存装不下,建立数据“索引”以解决空间复杂度。
索引表的建立分三步
- ① 分块:按查找表中数据按关键字分成若干块:R1, R2, …, RL,使得数据“分块有序”;
- ② 建立索引项:为每一个块建立一个索引项:
- 关键字项(记录块中最大关键字值)
- 指针项(记录块的起始地址)
- ③ 建立索引表:将所有索引项管理起来组成索引表。
[外链图片转存中…(img-sNN2Mydf-1609058590471)]
[外链图片转存中…(img-C1W56pKP-1609058590471)]
6.3.4 散列表
[外链图片转存中…(img-nkSjWx9k-1609058590472)]
[外链图片转存中…(img-1Avksabh-1609058590473)]
从上面例子可以看出
- 哈希函数是一个映象,它的设置很灵活,只要这个地址集合的大小不超出允许范围即可;
- 由于哈希函数是一个压缩映象,因此,一般容易产生“冲突”现象,即: key1 ≠ key2,而 H(key1) = H(key2)。
- 很难找到一个不产生冲突的哈希函数。只能选择恰当的哈希函数,使冲突尽可能少地产生。
因此,哈希查需要做两方面事情:
- 选择一个“好”的哈希函数;
- 提供一种“处理冲突” 的方法。
[外链图片转存中…(img-IR9RjEIu-1609058590474)]
[外链图片转存中…(img-BZbq6GIY-1609058590475)]
[外链图片转存中…(img-HvNt8Vr3-1609058590476)]
[外链图片转存中…(img-cT1IcZ3C-1609058590477)]
[外链图片转存中…(img-zriKabtU-1609058590478)]
[外链图片转存中…(img-9a3OA4QL-1609058590479)]
[外链图片转存中…(img-qYJOA3Oy-1609058590480)]
[外链图片转存中…(img-8NFg4tEG-1609058590481)]
[外链图片转存中…(img-XOBx14qb-1609058590482)]
[外链图片转存中…(img-EFng9gFc-1609058590483)]
[外链图片转存中…(img-JO4dRQEg-1609058590484)]
[外链图片转存中…(img-nG0GYoNK-1609058590485)]
[外链图片转存中…(img-nDp93bUI-1609058590486)]
[外链图片转存中…(img-HJneHaHu-1609058590488)]
[外链图片转存中…(img-6mOkaCpA-1609058590489)]
7. 排序
参考:https://www.cnblogs.com/onepixel/articles/7674659.html
8. 动态归化
https://www.zhihu.com/question/23995189
https://www.zhihu.com/question/410196236
https://www.zhihu.com/question/291280715
https://en.wikipedia.org/wiki/Dynamic_programming
好代码TIPS
变量命名规则
局部变量用小写 la_len
全局变量用大写开头 La_Len //慎用
宏定义 LA_LEN
对称性:
lchrild VS left_chrild
rchrild VS right_chrild
能用局部变量就用局部变量
int i;
for(i=1;...)
///
for(int i;...) //更好 推荐
局部变量能够减少一些不必要的麻烦,比如安全问题。
代码可读性
while循环里写return就会出现需要费时间去研究什么时候满足什么条件时返回值
但如果写进if语句里就一目了然了。
命中率
尽量将可能性高的写在if中或者switch前几项