YoLov4原理及对应代码详解【对比YoLov3】
目录
-
- 前言
- 一、yolov4性能表现
- 二、YOLOv4结构
- 三、YOLOv4新增训练技巧
前言
该篇文章主要是自己学习yolov4时做的一个总结,让自己理解更清晰,先看yolov3会有更为深刻理解哟。
yolov4论文pdf下载链接:https://pan.baidu.com/s/1dJ4Sj833Xzl_5_SQzgMGqQ
提取码:w8lf
yolov3原理:https://blog.csdn.net/weixin_39615182/article/details/109752498
一、yolov4性能表现
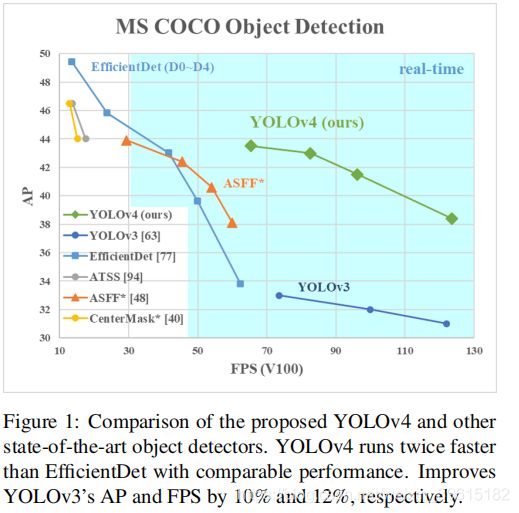
在论文的第一页就有上面这张图,意思是研究者对比了 YOLOv4 和当前最优目标检测器,发现YoLov4在取得EfficientDet同等性能的情况下,速度是它的两倍。,并且AP与FPS这两项指数相比YOLOv3分别提高了10%与12%。
AP:average precision,平均精确率,即多类预测的时候每一类的precision取平均,反映了模型对某个类别识别的好坏。
FPS:每秒帧率(Frame Per Second,FPS),即每秒内可以处理的图片数量。
上面两个是评价模型性能的指标,准确率与检测速度
作者在摘要中写到:我们使用以下新功能:WRC,CSP,CmBN,SAT,Mish激活,Mosaic数据增强,CmBN,DropBlock正则化和CIoU丢失。我们一起来看看吧
二、YOLOv4结构


上图为论文原图,形象将模型分为四部分:input,Backbone、Neck、Head
结构讲解:
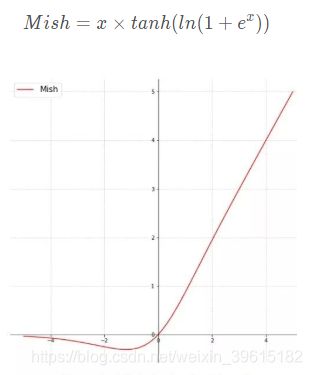
假设输入图像大小为416×416,可以看到主干网络Darknet53–>CSPDarknet53,激活函数由yolov3的Leak-Relu–>Mish,Mish激活函数公式与图像如下:
我们来分析一下网络结构:
1、主干网络Backbone
1.1、首先是输入层输入(416,416,3)的图,经过DarknetConv2D_BN_Mish(图中的Conv2d_BN_Mish)卷积块,卷积块由DarknetConv2D、BatchNormalization(BN)、Mish三部分组成,即该卷积结构包括l2正则化、批标准化、Mish激活函数这一系列操作。
# 单次卷积
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
darknet_conv_kwargs = {
'kernel_regularizer': l2(5e-4)}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2,2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
# 卷积块 DarknetConv2D + BatchNormalization + Mish
def DarknetConv2D_BN_Mish(*args, **kwargs):
no_bias_kwargs = {
'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
Mish())
1.2、然后后面有5个CSPResblockBody,分别为×1,×2,×8,×8,×4,表示重复多少次resblock_body,可以看到该残差结构块中先有个ZeroPadding2D对二维矩阵的四周填充0,即零填充层,然后三个DarknetConv2D_BN_Mish卷积块,第二个DarknetConv2D_BN_Mish卷积块会生成一个大的残差边(后面会解释残差边),然后有个for循环对通道进行整合[compose]与特征提取,这个循环多少次就是图中×1,×2,×8等。,在后面进行一次1x1DarknetConv2D_BN_Mish卷积,再concatenate堆叠拼接,最后再对通道数进行整合并返回。可以看到,resblockbody中有大量的DarknetConv2D_BN_Mish卷积块进行卷积提取特征。
# CSPdarknet的结构块
# 存在一个大残差边
def resblock_body(x, num_filters, num_blocks, all_narrow=True):
# 进行长和宽的压缩
preconv1 = ZeroPadding2D(((1,0),(1,0)))(x)
preconv1 = DarknetConv2D_BN_Mish(num_filters, (3,3), strides=(2,2))(preconv1)
# 生成一个大的残差边
shortconv = DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (1,1))(preconv1)
# 主干部分的卷积
mainconv = DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (1,1))(preconv1)
# 1x1卷积对通道数进行整合->3x3卷积提取特征,使用残差结构
for i in range(num_blocks):
y = compose(
DarknetConv2D_BN_Mish(num_filters//2, (1,1)),
DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (3,3)))(mainconv)
mainconv = Add()([mainconv,y])
# 1x1卷积后和残差边堆叠
postconv = DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (1,1))(mainconv)
route = Concatenate()([postconv, shortconv])
# 最后对通道数进行整合
return DarknetConv2D_BN_Mish(num_filters, (1,1))(route)
CSPDarknet(yolov4)与Darknet(yolov3)的resbodyblock不一样地方就是使用了CSPnet结构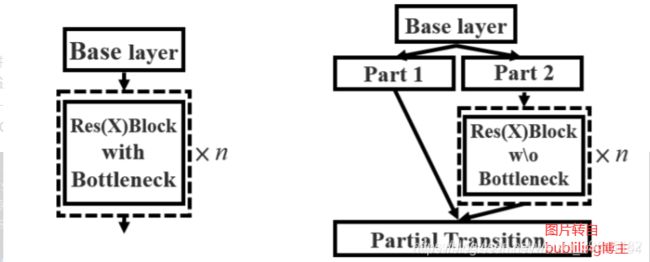
CSPnet结构将原来的残差块的堆叠进行了一个拆分,拆成左右两部分:
主干部分还是进行残差快的堆叠(Part 2)
另一部分则像是一条长边一样,经过少量处理直接连接到最后。
因此可以认为CSP中存在一个大的残差边。
残差边的作用:残差结构可以不通过卷积与堆叠,直接从前面一个特征层映射到后面的特征层(跳跃连接),有助于训练,也有助于特征的提取。
主干网络代码如下:
# CSPdarknet53 的主体部分
def darknet_body(x):
x = DarknetConv2D_BN_Mish(32, (3,3))(x)
x = resblock_body(x, 64, 1, False)
x = resblock_body(x, 128, 2)
x = resblock_body(x, 256, 8)
feat1 = x
x = resblock_body(x, 512, 8)
feat2 = x
x = resblock_body(x, 1024, 4)
feat3 = x
return feat1,feat2,feat3
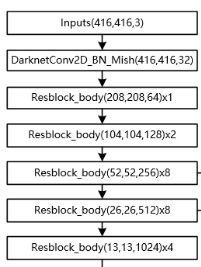
darknet_body(x)中的x即为输入传递来的图像数组(416,416,3),然后图像先通过 DarknetConv2D_BN_Mish卷积块进行卷积,得到shape为(416,416,32),再进行5次resblockbody,每一次宽高都减半,深度翻倍,其中feat1,feat2,feat3是对当时的特征层做一个记录,因为后面还需用到,变化如下图。
2、特征金字塔部分SSP与PAN
相比YOLOv3,YOLOV4结合了两种改进:
1).使用了SPP结构。
2).使用了PANet结构。
注:除去CSPDarknet53主干网络和Yolo Head的结构外,都是特征金字塔的结构。
2.1 SSP结构
首先SSP结构进行了三次DarknetConv2D_BN_Leaky卷积,你没看错,这里不是Mish,分别利用四个不同尺度的最大池化进行处理,最大池化的池化核大小分别为13x13、9x9、5x5、1x1(1x1–无处理),该结构能分离出最显著的上下文特征,是强有力的特征提取,池化后,再进行堆叠。如下图
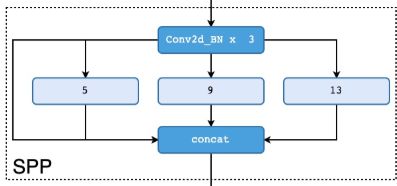
# 生成darknet53的主干模型
feat1,feat2,feat3 = darknet_body(inputs)
P5 = DarknetConv2D_BN_Leaky(512, (1,1))(feat3)
P5 = DarknetConv2D_BN_Leaky(1024, (3,3))(P5)
P5 = DarknetConv2D_BN_Leaky(512, (1,1))(P5)
# 使用了SPP结构,即不同尺度的最大池化后堆叠。
maxpool1 = MaxPooling2D(pool_size=(13,13), strides=(1,1), padding='same')(P5)
maxpool2 = MaxPooling2D(pool_size=(9,9), strides=(1,1), padding='same')(P5)
maxpool3 = MaxPooling2D(pool_size=(5,5), strides=(1,1), padding='same')(P5)
P5 = Concatenate()([maxpool1, maxpool2, maxpool3, P5])
简单描述下代码,首先darknet_body(inputs)可以获得返回的三个参数feat1,feat2,feat3,其中feat3为主干网络经过5个网络输出的特征层,然后对它进行3次 DarknetConv2D_BN_Leaky卷积,再经过三个最大池化分离特征,一个1×1池化即不变,还是P5,最后用 Concatenate()将四个进行堆叠。
2.2PANet
PANet是2018年发表的一种实例分割算法,它可以反复提取特征。
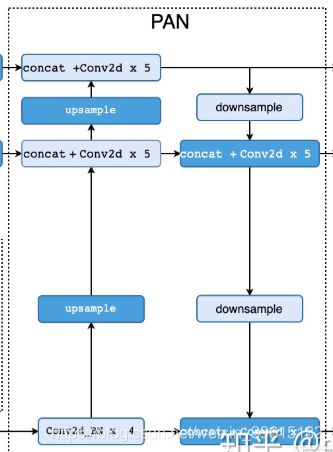
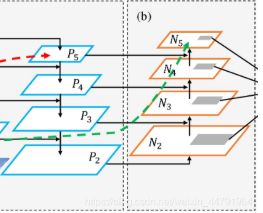
整个过程大致来讲就是上采样、再堆叠卷积重复,之后再进行下采样、堆叠,如上图,上采样是放大,下采样是压缩。
3、输出结果yolo head
与yolov3中一样,内部是一个3×3卷积,一个是1×1卷积,进行通道调整
最后得到三个输出(52,52,75),(26,26,75),(13,13,75)
注:假设基于VOC数据集

# 池化堆叠后的四次卷积,注意compose中还有一次
P5 = DarknetConv2D_BN_Leaky(512, (1,1))(P5)
P5 = DarknetConv2D_BN_Leaky(1024, (3,3))(P5)
P5 = DarknetConv2D_BN_Leaky(512, (1,1))(P5)
# 上采样
P5_upsample = compose(DarknetConv2D_BN_Leaky(256, (1,1)), UpSampling2D(2))(P5)
# 与左边主干网络的特征层feat2进行拼接
P4 = DarknetConv2D_BN_Leaky(256, (1,1))(feat2)
P4 = Concatenate()([P4, P5_upsample])
# Conv2d×5
P4 = make_five_convs(P4,256)
# 上采样
P4_upsample = compose(DarknetConv2D_BN_Leaky(128, (1,1)), UpSampling2D(2))(P4)
# 与左边主干网络的特征层feat1进行拼接
P3 = DarknetConv2D_BN_Leaky(128, (1,1))(feat1)
P3 = Concatenate()([P3, P4_upsample])
# Conv2d×5
P3 = make_five_convs(P3,128)
# 52x52的输出yolo head1,若是VOC数据集,则3×(20+5)=75,shape为(52,52,75)
# conv2d 3*3
P3_output = DarknetConv2D_BN_Leaky(256, (3,3))(P3)
# con2d 1*1
P3_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(P3_output)
# 注意一下,这里下采样有个零填充即可
P3_downsample = ZeroPadding2D(((1,0),(1,0)))(P3)
P3_downsample = DarknetConv2D_BN_Leaky(256, (3,3), strides=(2,2))(P3_downsample)
P4 = Concatenate()([P3_downsample, P4])
P4 = make_five_convs(P4,256)
# 38x38的out
P4_output = DarknetConv2D_BN_Leaky(512, (3,3))(P4)
P4_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(P4_output)
P4_downsample = ZeroPadding2D(((1,0),(1,0)))(P4)
P4_downsample = DarknetConv2D_BN_Leaky(512, (3,3), strides=(2,2))(P4_downsample)
P5 = Concatenate()([P4_downsample, P5])
P5 = make_five_convs(P5,512)
# 19x19的out
P5_output = DarknetConv2D_BN_Leaky(1024, (3,3))(P5)
P5_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(P5_output)
return Model(inputs, [P5_output, P4_output, P3_output])
输出三个yolo head后还需对其进行解码,因为这个yolo head预测结果并不对应着最终的预测框在图片上的位置,还需要解码才可以完成。这部分在yolov3文章的第二、三步已经写了,可以直接看2、3步,链接如下:
yolov3原理详解
下面讲下实现预测结果解码与得分排序、非极大抑制筛选两部分代码
解码是为了得到真实的边界框,但是不只一个,通过得分排序和非极大抑制筛选得到众多边框中最准确的一个,即最优的一个
#---------------------------------------------------#
# 将预测值的每个特征层调成真实值
#---------------------------------------------------#
def yolo_head(feats, anchors, num_classes, input_shape, calc_loss=False):
num_anchors = len(anchors)
# [1, 1, 1, num_anchors, 2]
anchors_tensor = K.reshape(K.constant(anchors), [1, 1, 1, num_anchors, 2])
# 获得x,y的网格
# (13, 13, 1, 2)
grid_shape = K.shape(feats)[1:3] # height, width
grid_y = K.tile(K.reshape(K.arange(0, stop=grid_shape[0]), [-1, 1, 1, 1]),
[1, grid_shape[1], 1, 1])
grid_x = K.tile(K.reshape(K.arange(0, stop=grid_shape[1]), [1, -1, 1, 1]),
[grid_shape[0], 1, 1, 1])
grid = K.concatenate([grid_x, grid_y])
grid = K.cast(grid, K.dtype(feats))
# (batch_size,19,19,3,85)
feats = K.reshape(feats, [-1, grid_shape[0], grid_shape[1], num_anchors, num_classes + 5])
# 将预测值调成真实值
# box_xy对应框的中心点
# box_wh对应框的宽和高
box_xy = (K.sigmoid(feats[..., :2]) + grid) / K.cast(grid_shape[::-1], K.dtype(feats))
box_wh = K.exp(feats[..., 2:4]) * anchors_tensor / K.cast(input_shape[::-1], K.dtype(feats))
box_confidence = K.sigmoid(feats[..., 4:5])
box_class_probs = K.sigmoid(feats[..., 5:])
# 在计算loss的时候返回如下参数
if calc_loss == True:
return grid, feats, box_xy, box_wh
return box_xy, box_wh, box_confidence, box_class_probs
#---------------------------------------------------#
# 对box进行调整,使其符合真实图片的样子
#---------------------------------------------------#
def yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape):
box_yx = box_xy[..., ::-1]
box_hw = box_wh[..., ::-1]
input_shape = K.cast(input_shape, K.dtype(box_yx))
image_shape = K.cast(image_shape, K.dtype(box_yx))
new_shape = K.round(image_shape * K.min(input_shape/image_shape))
offset = (input_shape-new_shape)/2./input_shape
scale = input_shape/new_shape
box_yx = (box_yx - offset) * scale
box_hw *= scale
box_mins = box_yx - (box_hw / 2.)
box_maxes = box_yx + (box_hw / 2.)
boxes = K.concatenate([
box_mins[..., 0:1], # y_min
box_mins[..., 1:2], # x_min
box_maxes[..., 0:1], # y_max
box_maxes[..., 1:2] # x_max
])
boxes *= K.concatenate([image_shape, image_shape])
return boxes
#---------------------------------------------------#
# 获取每个box和它的得分
#---------------------------------------------------#
def yolo_boxes_and_scores(feats, anchors, num_classes, input_shape, image_shape):
# 将预测值调成真实值
# box_xy对应框的中心点
# box_wh对应框的宽和高
# -1,19,19,3,2; -1,19,19,3,2; -1,19,19,3,1; -1,19,19,3,80
box_xy, box_wh, box_confidence, box_class_probs = yolo_head(feats, anchors, num_classes, input_shape)
# 将box_xy、和box_wh调节成y_min,y_max,xmin,xmax
boxes = yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape)
# 获得得分和box
boxes = K.reshape(boxes, [-1, 4])
box_scores = box_confidence * box_class_probs
box_scores = K.reshape(box_scores, [-1, num_classes])
return boxes, box_scores
#---------------------------------------------------#
# 图片预测
#---------------------------------------------------#
def yolo_eval(yolo_outputs,
anchors,
num_classes,
image_shape,
max_boxes=20,
score_threshold=.6,
iou_threshold=.5):
# 获得特征层的数量
num_layers = len(yolo_outputs)
# 特征层1对应的anchor是678
# 特征层2对应的anchor是345
# 特征层3对应的anchor是012
anchor_mask = [[6,7,8], [3,4,5], [0,1,2]]
input_shape = K.shape(yolo_outputs[0])[1:3] * 32
boxes = []
box_scores = []
# 对每个特征层进行处理
for l in range(num_layers):
_boxes, _box_scores = yolo_boxes_and_scores(yolo_outputs[l], anchors[anchor_mask[l]], num_classes, input_shape, image_shape)
boxes.append(_boxes)
box_scores.append(_box_scores)
# 将每个特征层的结果进行堆叠
boxes = K.concatenate(boxes, axis=0)
box_scores = K.concatenate(box_scores, axis=0)
mask = box_scores >= score_threshold
max_boxes_tensor = K.constant(max_boxes, dtype='int32')
boxes_ = []
scores_ = []
classes_ = []
for c in range(num_classes):
# 取出所有box_scores >= score_threshold的框,和成绩
class_boxes = tf.boolean_mask(boxes, mask[:, c])
class_box_scores = tf.boolean_mask(box_scores[:, c], mask[:, c])
# 非极大抑制,去掉box重合程度高的那一些,获取局部最大值
nms_index = tf.image.non_max_suppression(
class_boxes, class_box_scores, max_boxes_tensor, iou_threshold=iou_threshold)
# 获取非极大抑制后的结果
# 下列三个分别是
# 框的位置,得分与种类
class_boxes = K.gather(class_boxes, nms_index)
class_box_scores = K.gather(class_box_scores, nms_index)
classes = K.ones_like(class_box_scores, 'int32') * c
boxes_.append(class_boxes)
scores_.append(class_box_scores)
classes_.append(classes)
boxes_ = K.concatenate(boxes_, axis=0)
scores_ = K.concatenate(scores_, axis=0)
classes_ = K.concatenate(classes_, axis=0)
return boxes_, scores_, classes_
三、YOLOv4新增训练技巧
为了使设计的检测器更适合于单 GPU 的训练,我们进行了如下其他设计和改进:
3.1 Mosaic数据增强
论文原话:Mosaic表示一种新的数据增强方法,该方法混合了4个训练图像。 因此,混合了4个不同的上下文,而CutMix仅混合了2个输入图像。 这样可以检测正常上下文之外的对象,增强模型的鲁棒性。。 此外,批量归一化从每层上的4张不同图像计算激活统计信息。 这大大减少了对大批量生产的需求。
这个Mosaic数据增强就是一次读取4张不同的图片,然后进行缩放,调整大小等操作,然后拼接成一幅图。这样能一次训练四个图像,增加了图片内容的丰富性,即丰富检测物体的背景。BN(标准化)计算的时候一下子会计算四张图片的数据
3.2 自对抗训练SAT
SAT是一种新的数据增强技术,该技术分前后两个阶段进行:
第一阶段,神经网络改变原始图像而不是网络权值。通过这种方式,神经网络对自身执行一种对抗性攻击,改变原始图像,从而造成图像上没有目标的假象。
第二阶段,训练神经网络对修改后的图像进行正常的目标检测。
yolov4论文讲解