嵌入式常见面试题
嵌入式LINUX常见面试问题总结
声明:本文是将常见的面试问题进行汇总,但大多数问题也是开发中较为常见的技术盲区!在此进行了汇总,以便后续进行参考!所有的答案部分是自己编写,部分问题答案引用博客客友的优秀文章!问题不全,后续工作及学习中会不断更新!
如引用下面文章对问题进行解答:
1)、嵌入式系统移植步骤详解
2)、创建守护进程的步骤
3)、TCP/IP网络编程
4)、三次握手和四次挥手
5)、32位ARM处理器的几种工作模式和工作状态
6)、按键和CPU的中断系统
7)、uboot的作用和功能
感谢以上客友的经典文章!
-
如有侵权,请联系!
1、什么是嵌入式?
A: 嵌入式系统本身是一个相对模糊的定义。目前嵌入式系统已经渗透到我们生活中的每个角落,工业、服务业、消费电子……,而恰恰由于这种范围的扩大,使得“嵌入式系统”更加难于明确定义。以下是几种常见表达方式:
-
1、执行专用功能并被内部计算机控制的设备或者系统。嵌入式系统不能使用通用型计算机,而且运行的是固化的软件,用术语表示就是固件(firmware),终端用户很难或者不可能改变固件。
-
2、凡是专用的、小型或者微型的计算机系统都是嵌入式系统,比如MP3, 手机,高清电视
-
3、比较传神和从技术人员角度来看,嵌入式系统是以应用为中心,以计算机技术为基础,并且软硬件可裁剪,适用于应用系统对功能、可靠性、成本、体积、功耗有严格要求的专用计算机系统。
2、字符设备和块设备的区别?
A:
-
1、字符设备和块设备、网络设备是一个并列的概念
-
2、字符设备按照字符流的方式被有序访问,块设备以块为单位;二者根本区别在于字符设备只能顺序被读写,块设备可以随机访问
-
3、Linux为块设备和字符设备提供了两套机制。字符设备实现的比较简单,内核例程和用户态API一一对应,用户层的read函数直接对应了内核中的read例程,这种映射关系由字符设备的file_operations维护。块设备接口相对于字符设备复杂,read、write API没有直接到块设备层, 而是通过IO请求的方式通过OS的IO请求队列实现。内核管理块设备要比管理字符设备细致得多,内核对块设备的管理却提供一个专门的提供服务的子系统。块设备对执行性能的要求很高;,LINUX内核开发者门一直致力于优化块设备的驱动。
3、进程与程序,进程与线程的区别
进程与程序的联系
A:
1. 程序是一组指令的集合,它是静态的实体,没有执行的含义。进程程序的执行过程,是一个动态的实体,有自己的生命周期,包括产生、运行、消亡的过程。除此之外,进程还有并发性和交往性。简单地说,进程是程序的一部分,程序运行的时候会产生进程。
2.所涉及到的介质不同,程序保存在存储介质,比如FLASH,硬盘等中,进程运行在RAM中内容不完全相同,程序有数据段,代码段,调试信息等,进程执行时候,有代码段,数据段,以及堆栈
线程和进程的区别:
A:
1、线程是进程的一部分,所以线程有的时候被称为是轻权进程或者轻量级进程。
2、一个没有线程的进程是可以被看作单线程的,如果一个进程内拥有多个进程,进程的执行过程不是一条线(线程)的,而是多条线(线程)共同完成的。
3、系统在运行的时候会为每个进程分配不同的内存区域,但是不会为线程分配内存(线程所使用的资源是它所属的进程的资源),线程组只能共享资源。也就是 说,出了CPU之外(线程在运行的时候要占用CPU资源),计算机内部的软硬件资源的分配与线程无关,线程只能共享它所属进程的资源。
4、标准LINUX的进程具有独立的虚拟地址空间,而一个进程里面的多个线程共享同一个虚拟内存空间,进程是系统所有资源分配时候的一个基本单位
4、嵌入式的移植过程
下面我们就来看下一个内容叫做移植的基本步骤,也就是说我们要现有一个大体的思路,如果说我作为产品开发者,或者说是作为一个系统的整体架构来说,我们拿到一款板子过后我们是如何一步一步把我们的系统用起来呢?它整个系统流程又是什么样的,我们先要有个明确目标,第一个目标是我们要保证PC也就是我们的开发机器跟目标机也就是开发板或者说最终要做成产品的板子的硬件它们俩之间的连接方式。
因为我们在嵌入式开发中有一个很麻烦的事情就是开发板的能力跟PC的能力一般是不平等的,大家都知道PC的功能很强大也很贵而板子很便宜可能一个小系统一个路由器也就几十块钱,但是我们总不能在路由器上接个键盘接个鼠标然后装一个VC,在这里是不现实的,所以说我们一般的开发环境跟ARM讲的内容都是一样的,都是在主机上开发最终把主机编译好的内容跟我们的目标机进行一个数据传输,所以这就涉及到一个非常重要的问题。
数据传输的方式。因为我们数据无外乎就是高低电平这几种,那么传播有哪些传播方式呢?

如图,所以我们如果作为一个产品的研发者来说,你第一个需要考虑的就是我们是怎么连的。
那么给大家来列出了一下,目前来说,我们的PC跟我们的开发板的连接也就大概如上图四种比较常用的方式。第一种就是我们最经典90%的板子上,都支持的方式叫异部串行接口,也就是我们所说的串口。那么这个串口传输在我们之前学习ARM的时候也学习到过,其实别看它很简单,其实它的功能很强大。它既可以输入也可以输出,所以说我们基本上完成了一个输入输出这样数据出和进的功能。
所以说串口是我们比较常用的一个接口。但是它还是有它的特点就是它的速度比较低,因为比如说我们前面所配的速度是11520那这个其实是很低的,不是很高。因为他11520B比特也就是传多少位多少个高低电平的字节,所以说这个效率不是很高但是实用性比较强就几个接口就可以。
我们举个典型的例子就是家里的路由器,如果大家有兴趣,就把家里的老路由器拆下来看一下路由器里面一般都有3个架子或4个架子,3个小插针或4个小插针无外乎就几个电压,一个是D一个是电源很多情况下,路由器都会引出这个东西。如果你的动手能力比较强,你就去市场上买一个叫DB9的一个小头子,拿个烙铁把那里面的几根线给焊上去。然后就跟PC一接,就可能会看到路由器的一些打印信息。所以说串口在我们嵌入式开发中算是一个非常经典的跟PC之间通信的一个接口。
因为大家可以想一下,这个串口既可以输出我们可以把开发板上的信息往我们的平台上去看。 甚至来说,我们还可以通过串口把PC里面的东西传到开发板中,所以他说输入输出都可以,这样的话串口也算是一个比较万能的接口,它唯一的缺陷就是速度太低,如果我们传输一些大数据比如说以后我们会看到的安卓中的一些东西,安卓中涉及到的其实跟我们所学的也是一样,他比较麻烦的就是文件系统支柱,文件系统少的可能就要几百兆,或者说压缩过后就是几十兆。那你可以想象一下,我们如果用11520去传,有的时候就要传送一二十分钟,这样很影响开发效率的。
所以说用串口如果是小文件没有关系,但大文件一般情况下用串口传输的可能性不大。如果说你的板子功能比较强,传的东西比较多,这种情况下用串口我们还是不建议。
那么现在我们就需要换一下,串口我们可以把它当作后备资源。
然后我们就要使用如上图所说的USB。随着USB的发展,从USB1.0到2.0、3.0,它的速度越来越快。那么这个传输数据我们就不用担心,它速度快是没有问题的,但是现在唯一比较担心的一个问题就是板子刚刚上电,就让他用串口去工作,这个是不现实的。所以这种情况下,我们还涉及到在开发板要把串口的驱动做好。所以说这个时候我们还要考虑驱动的问题,到底支不支持如果不支持或者开发的周期比较长,那么串口就不把它作为目标机和主机连接的主要方式了。以上就是我们的串口。
串口退而求其次就还有一种叫做网络接口,这个网络接口也是我们嵌入式开发中使用很普遍的一个接口。
如上图因为这个TCP/IP这个协议已经很成熟了。
因为我们的PC本身就是TCP/IP中很重要的一个端口,比如你可以作为服务器,也可以作为客户端,然后我们的开发板也只需要跑一个服务器或者客户端就可以跟PC以CS的模式进行数据的传输和下载。所以说这个方式也是比较通用的而且说网卡的数据和速率都比较快最少最少都是十兆而且现在百兆网卡都是非常多的。这样的话,传输速率肯定是比11520是快得多。
所以说在我们后期课程中,大家会看到我们通过网络接口去下载数据的情况是比较多的。
驱动也是一样的它也需要移植,但相对而言,它可能要比USB上要方便一点,因为USB它涉及到速率,就是说它有些时序需要调整,可能会有一些麻烦,所以说对于TCP/IP中的网卡我们一般来说是优于USB去选择的。
最后一个叫做Debug Jtag调试接口,也就是说如果你是ARM CPU的话,那么ARM中还有一些相关Debug Jtag的ICE,也就是说它内部会集成一些这样的东西,然后可能你的厂商会提供这样的调制接口。比如说ARM9就有,但是像A系列的开发板一般来说很少在市面上能够买得到它的调制接口。也就是Debug Jtag调试接口。也不是说没有,我们曾经联系ARM公司问过像Debug Jtag调试接口一台就要一万块钱,所以这样来说,如果你为了学习花一万块钱是得不偿失的。所以这种情况除非真的是你们公司去开发跟ARM公司出芯片比较多才可能去买一台Debug Jtag调试接口。
当然Debug Jtag调试接口很方便,比上面三种都更好调试,调试效率也要高的多但是就是价格太高了,所以说我们个人学习已经很多企业来说更多的还是用以上的三种。
以上就是我们移植的第一个步骤,就是关于我们主机和目标机的连接方式。
交叉编译器
有了上面那个连接方式下一个就是交叉编译器了。
交叉编译器,在我们后面就会讲到所谓的交叉编译器它其实就是我们很多情况下在开发项目中必备的一个工具。因为我们一般的开发在PC,而PC很显然大家知道它的架构是在X86,但现在很显然,我们X86的程序跟ARM程序肯定是不兼容的,这样的话我们就需要一个交叉编译器来进行相应的编译开发,也就是说我们开发的程序不能开发成X86,也就是说X86里面的二进制程序下载到ARM开发板上ARM是不认识的,这样的话,程序是不能相通的,所以说以上就是我们需要安装交叉编译器的一个道理。

如图,安装交叉编译器也有两种方法,一般情况下是第一种就是芯片厂商已经给好的因为你买的芯片一般都有。第二种就是我们自己手动的去编译,自己动手编译交叉工具链,手动编译如果大家想做可以做但是它非常耗时间甚至来说遇到的问题可能会特别特别多,他有很多不兼容的问题这个他是需要一定的功底去调试非常麻烦,所以不推荐新手去做,甚至很多公司都不会自己贸然用编译器去做产品开发。
但是如果有兴趣的同学可以下去搜索一本书“The GNU Toolchain for ARM Target HOWTO”这其实也是一本官方手册,它会告诉你如何去做一个相关的工具链。当然这个工具念在制作的时候,他的方法比较单一,思路也比较单一,那唯一不好,就是他的版本之前依赖关系比较大,你可能会需要一些手动的去修改这些要做的比较多,所以对于编译原理你要知道的很清楚去找到问题所在点去编,所以相对而言比较耗时甚至编不通过很麻烦,所以这个部分一般情况下不建议使用。
更多时候我们用的是芯片厂商提供好的,那么芯片厂商提供的芯片,一般情况下有这么几种前缀名。
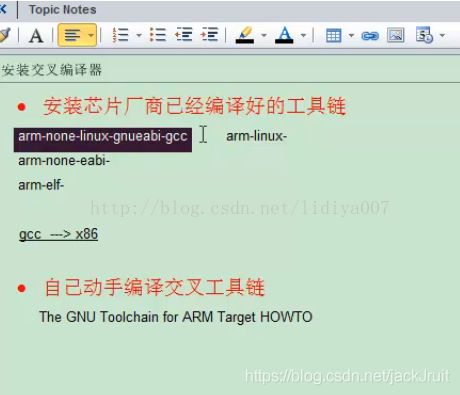
如图,就说在安装过后,都会有一些前缀名,我先简单的说一下它的意义。最常用的是这一种叫做 “arm-none-linux-gnueabi-”他的意思是第一例就是说目标题结构也就是说,这个工具目的是做什么的,比如说最典型的gcc什么都没写他默认就是编译X86,如果我这里有ARM说明他这个编译器编译的是ARM,记住这个编译器他其实是个集合,我只列出了前缀也就说他这个地方实际上隐含了一个概念叫gcc,也就是说相当于用了图上加黑的那个工具,只是说,我们现在更多的时候是用的一个前缀,我们后面还会讲到很多工具集,所以我们记这个前缀而不记后面的这个命令,前缀的第一个单词就是你最终生成的编译器和生成的体系结构,第二个就是厂商名一般如果你是开源的话就是none,比如说你是三星的话那就是ARM_sanxin,一般都是none。然后第三个linux也就是我们这个程序默认编译出来的功能是针对linux操作系统去用的,也就是这个好处在于这个编译器它的内部有一些标准C库而这个C库是跟linux的接口相关的,也就是这个软件编译出来的可执行程序不能在windows下运行的。 这样的话这个工具链就专门针对于Linux操作系统运行。而且是ARM下的Linux操作系统而不是Windows,然后后面的那个词gun大家都知道是开源的,而eabi指的是我们嵌入式的标准接口,它主要针对的是嵌入式精简的一些相关库所以说是eabi,还有一个是oabi是老的,我们现在基本上都是用的eabi的系统,主要由ARM的优化选项来决定的,这个我们到时候看到ARM优化的那一章内容可以去学习一下。
一般情况下“arm-none-linux-gnueabi-”这个名字太长了我们也不想去记所以就干脆把它简称为“arm-linux-”所以有些时候你经常会看到有些编译器中都做了一个小技巧,把“arm-linux-”和“arm-none-linux-gnueabi-”做了一个快捷方式,就是软链接,把两个名字关联起来,也就是输入其中一个名字就相当于在输入另一个名字。所以这一组就是比较常用的形式。
后面还可能会接触一些,比如“arm-none-eabi-”就是没有Linux的,没有Linux这款编辑器一般代表不能在有操作系统的ARM上运行,因为它不支持操作系统,所以这就是一款比较新的,而下面这个“rm-elf-”是非常老的,也是针对于无操作系统或者可能有操作系统也支持,只是这个是非常老的,很少能见到。主要见到的是前两种。
以上就是我们安装的工具链,其实工具链一般来说找厂商要就可以或者说你实在要不到也没关系,比如说下载安卓后其实它自动就把编译器给编译出来了,你可以直接把它拷出来用也可以。或者说你可以去找一个公司,这个公司现在已经被收购了,但是大家可以注意去查叫做“codesourcery”虽然它已经被收购,但是它其实也是提供交叉编译器的工具,大家如果有兴趣也可以去网上搜一下,然后去注册一下那个收购公司的账号下下来也可以。但是一般来说,用我们光盘已经配置好的编译器也问题不大。
其上就是我们说的第二个部分安装交叉编译器。
目标机传输通道
第三个部分:搭建主机,目标机传输通道。我们就要想办法确定连接方法后就要准备搭建传输通道的一些所具备的服务和客户。比如说我们用网络,最显然就涉及到服务配置。
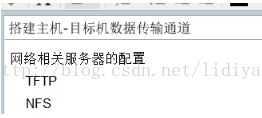
如图,有服务器有客户端,这样来说网络就可以成功传输数据。所以说一般情况下在嵌入式中我们用的比较多的服务就两个,在Linux下一个叫TFTP一个叫NFS,TFTP顾名思义就是FTP的一个简版,它是基于UDP传输的,相当于它的协议比较简单。而NFS它的全名叫做网络文件系统,这个网络文件系统主要是Linux和Linux之间做挂载用的,那么这个用处应该是非常大,比如说我们在后面学文件系统的调试的时候,我们很多时候都会用NFS作为我们调试的一个基本应用工具,所以这也是我们在搭建开发环境中的第三步。
烧写测试
最后,都准备好后,剩下就是一件事情也是最难的一件事情,就是把我们之前那三个子系统的功能全部做好,假如我们已经有这样的功能我们就把它们相应的编译出来,编译后剩下的最后一步就是烧写测试,最后把它整个集成放到工厂然后就开始集成化生产。
以上,就是基本的移植步骤,而具体编译三大系统就是我们后面的课程需要掌握的内容,最后我们在每一个内容中都涉及到怎么去烧写它。
5、守护进程的编写步骤
什么是守护进程?
答:守护进程是后台运行的、系统启动是就存在的、不予任何终端关联的,用于处理一些系统级别任务的特殊进程。
实现思路:
实现一个守护进程,其实就是将普通进程按照上述特性改造为守护进程的过程。
需要注意的一点是,不同版本的 Unix 系统其实现机制不同,BSD 和 Linux 下的实现细节就不同。
根据上述的特性,我们便可以创建一个简单的守护进程,这里以 Linux 系统下从终端 Shell 来启动为例。
在此有必要说一下两个概念:会话和进程组。
可点击参考会话和进程组概念
进程都有父进程,父进程也有父进程,这就形成了一个以init进程为根的家族树。除此以外,进程还有其他层次关系:进程、进程组和会话。进程组和会话在进程之间形成了两级的层次:进程组是一组相关进程的集合,会话是一组相关进程组的集合。
这样说来,一个进程会有如下ID:
·PID:进程的唯一标识。对于多线程的进程而言,所有线程调用getpid函数会返回相同的值。
·PGID:进程组ID。每个进程都会有进程组ID,表示该进程所属的进程组。默认情况下新创建的进程会继承父进程的进程组ID。
·SID:会话ID。每个进程也都有会话ID。默认情况下,新创建的进程会继承父进程的会话ID。
前面提到过,新进程默认继承父进程的进程组ID和会话ID,如果都是默认情况的话,那么追根溯源可知,所有的进程应该有共同的进程组ID和会话ID。但是调用ps axjf可以看到,实际情况并非如此,系统中存在很多不同的会话,每个会话下也有不同的进程组。
为何会如此呢?
就像家族企业一样,如果从创业之初,所有家族成员都墨守成规,循规蹈矩,默认情况下,就只会有一个公司、一个部门。但是也有些“叛逆”的子弟,愿意为家族公司开疆拓土,愿意成立新的部门。这些新的部门就是新创建的进程组。如果有子弟“离经叛道”,甚至不愿意呆在家族公司里,他别开天地,另创了一个公司,那这个新公司就是新创建的会话组。由此可见,系统必须要有改变和设置进程组ID和会话ID的函数接口,否则,系统中只会存在一个会话、一个进程组。
进程组和会话是为了支持shell作业控制而引入的概念。
当有新的用户登录Linux时,登录进程会为这个用户创建一个会话。用户的登录shell就是会话的首进程。会话的首进程ID会作为整个会话的ID。会话是一个或多个进程组的集合,囊括了登录用户的所有活动。在登录shell时,用户可能会使用管道,让多个进程互相配合完成一项工作,这一组进程属于同一个进程组。
当用户通过SSH客户端工具(putty、xshell等)连入Linux时,与上述登录的情景是类似的。
通常,会话开始于用户登录,终止于用户退出,期间的所有进程都属于这个会话。一个会话一般包含一个会话首进程、一个前台进程组和一个后台进程组,控制终端可有可无;此外,前台进程组只有一个,后台进程组可以有多个,这些进程组共享一个控制终端。
前台进程组:
该进程组中的进程可以向终端设备进行读、写操作(属于该组的进程可以从终端获得输入)。该进程组的 ID 等于控制终端进程组 ID,通常据此来判断前台进程组。
后台进程组:
会话中除了会话首进程和前台进程组以外的所有进程,都属于后台进程组。该进程组中的进程只能向终端设备进行写操作。
下图为会话、进程组、进程和控制终端之间的关系(登录 shell 进程本身属于一个单独的进程组)。
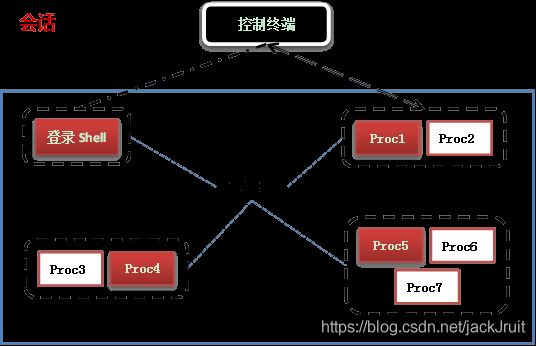
想了解更多关于会话 Sessions 内容,可以认真读一下 apue 这本书。
如果调用进程非组长进程,那么就能创建一个新会话:
该进程变成新会话的首进程
该进程成为一个新进程组的组长进程
该进程没有控制终端,如果之前有,则会被中断(会话过程对控制终端的独占性)
也就是说:组长进程不能成为新会话首进程,新会话首进程必定成为组长进程。
1、fork()创建子进程,父进程exit()退出;
这是创建守护进程的第一步。由于守护进程是脱离控制终端的,完成这一步后就会在Shell终端里造成程序已经运行完毕的假象。之后的所有工作都在子进程中完成,而用户在Shell终端里则可以执行其他命令,从而在形式上做到了与控制终端的脱离,在后台工作。
由于父进程先于子进程退出,子进程就变为孤儿进程,并由 init 进程作为其父进程收养。
2、在子进程调用setsid()创建新会话;
在调用了 fork() 函数后,子进程全盘拷贝了父进程的会话期、进程组、控制终端等,虽然父进程退出了,但会话期、进程组、控制终端等并没有改变。这还不是真正意义上的独立开来,而 setsid() 函数能够使进程完全独立出来。
setsid()创建一个新会话,调用进程担任新会话的首进程,其作用有:
使当前进程脱离原会话的控制
使当前进程脱离原进程组的控制
使当前进程脱离原控制终端的控制
这样,当前进程才能实现真正意义上完全独立出来,摆脱其他进程的控制。
3、再次 fork() 一个子进程,父进程exit退出;
现在,进程已经成为无终端的会话组长,但它可以重新申请打开一个控制终端,可以通过 fork() 一个子进程,该子进程不是会话首进程,该进程将不能重新打开控制终端。退出父进程。
也就是说通过再次创建子进程结束当前进程,使进程不再是会话首进程来禁止进程重新打开控制终端。
4、在子进程中调用chdir()让根目录“/”成为子进程的工作目录;
这一步也是必要的步骤。使用fork创建的子进程继承了父进程的当前工作目录。由于在进程运行中,当前目录所在的文件系统(如“/mnt/usb”)是不能卸载的,这对以后的使用会造成诸多的麻烦(比如系统由于某种原因要进入单用户模式)。因此,通常的做法是让"/"作为守护进程的当前工作目录,这样就可以避免上述的问题,当然,如有特殊需要,也可以把当前工作目录换成其他的路径,如/tmp。改变工作目录的常见函数是chdir。(避免原父进程当前目录带来的一些麻烦)
5、在子进程中调用umask()重设文件权限掩码为0;
文件权限掩码是指屏蔽掉文件权限中的对应位。比如,有个文件权限掩码是050,它就屏蔽了文件组拥有者的可读与可执行权限(就是说可读可执行权限均变为7)。由于使用fork函数新建的子进程继承了父进程的文件权限掩码,这就给该子进程使用文件带来了诸多的麻烦。因此把文件权限掩码重设为0即清除掩码(权限为777),这样可以大大增强该守护进程的灵活性。通常的使用方法为umask(0)。(相当于把权限开发)
6、在子进程中close()不需要的文件描述符;
同文件权限码一样,用fork函数新建的子进程会从父进程那里继承一些已经打开了的文件。这些被打开的文件可能永远不会被守护进程读写,但它们一样消耗系统资源,而且可能导致所在的文件系统无法卸下。其实在上面的第二步之后,守护进程已经与所属的控制终端失去了联系。因此从终端输入的字符不可能达到守护进程,守护进程中用常规方法(如printf)输出的字符也不可能在终端上显示出来。所以,文件描述符为0、1和2 的3个文件(常说的输入、输出和报错)已经失去了存在的价值,也应被关闭。(关闭失去价值的输入、输出、报错等对应的文件描述符)
for (i=0; i < MAXFILE; i++)
close(i);
7、守护进程退出处理
当用户需要外部停止守护进程运行时,往往会使用 kill 命令停止该守护进程。所以,守护进程中需要编码来实现 kill 发出的signal信号处理,达到进程的正常退出。
一张简单的图可以完美诠释之前几个步骤:

至此为止,一个简单的守护进程就建立起来了。
注意守护进程一般需要在 root 权限下运行。
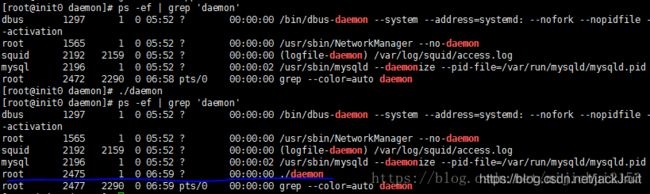
通过
- ps -ef | grep ‘daemon’
对比执行前后确实可以看到多了一个进程:
并且产生了 daemon.log,里面是这样的时间标签
Thu Dec 8 14:35:11 2016
Thu Dec 8 14:36:11 2016
Thu Dec 8 14:37:11 2016
最后我们想退出守护进程,只需给守护进程发送 SIGQUIT 信号即可
- sudo kill -3 26454
再次使用 ps 会发现进程已经退出。
程序如下:
#include 以下为其他的两种实现,大同小异:
C++实现 :
#includeC语言实现(有时间再研究):
test.c文件
#include 编译:gcc –g –o test init.c test.c
执行:./test
查看进程:ps –ef
从输出可以发现test守护进程的各种特性满足上面的要求。
6、网络的Socket交互过程
此问题是网络编程
1)、什么是网络编程
网络编程就是编写程序使两台连联网的计算机相互交换数据。怎么交换数据呢?两台电脑都插一根线就可以了吗?稍微夸张点说差不多是这个意思(需要物理连接)
有人就会问了,我平常跟张三聊QQ的时候我也没跟他直接连网线那怎么可以联网呢。你买了电信的宽带电信是不是得给你牵线装猫,最终这些线会连到电信的机房由他们来管理。在这个基础上,
如何编写数据传输软件呢。操作系统提供了“套接字”(socket)的组件我们基于这个组件进行网络通信开发。
本章主要讨论tcp套接字,接下来的工作流程都会以“打电话”来生动表达,tcp套接字可以比喻成电话。
电话可以同时用来拨打和接听的,但对套接字而言,拨打和接听是有区别的。我们先讲解套接字创建过程。其实这个过程跟我们生活中的打电话的场景比较相似。
我们来解析打电话的步骤:
1.通信方式有很多种,可以当面沟通、书信沟通、电话沟通、托人带话等等。
这里张三和李四约定好都用电话沟通(确认通讯协议,这里指TCP/IP),张三给李四打电话(张三在这里的身份是客户端,而李四对应身份是服务端 身份也确认好了)。
2.双方打电话得有电话机(创建socket对象)
3.张三必须知道拨打对象的电话号码(知道服务端的ip和port),李四电话号码是123456(绑定套接字)
4.张三拨打李四电话(客户端连接服务端,connect连接)
5.被打电话的那一方听到电话响了(listen监听)
6.李四害怕是推销电话想着要跟他确认身份是不是张三,不是张三就准备挂断电话
7.接起电话确认对方身份,张三问是李四吗(三次握手中,第一次握手)
8.李四回答,我是李四。你是?(三次握手,第二次握手)
9.张三说你好李四,我是张三(三次握手,第三次握手)
10.确认过眼神遇上对的人,李四决定跟他继续谈话(accept接受连接请求)
11.接下来就开始长篇大论的攀谈(数据交互)
12.最终要挂电话了,张三对李四说那今天就讲到这里(四次挥手,第一次)
13.李四说行啊今天就讲到这里(四次挥手,第二次)
14.张三说那我挂断了啊(四次挥手,第三次)
15.李四说好的你挂吧(四次挥手,第四次)
16.挂断(结束)
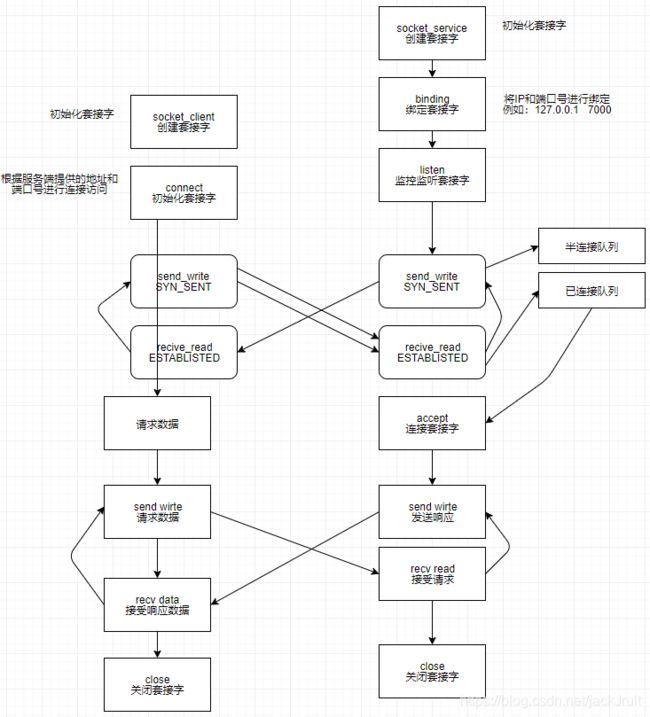
阅读以上流程接下来我们来看看流程图就非常好理解了
或者我阅读及学习过程中找到另外一个博客客友的一个解释:可参考:TCP/IP的TCP通信过程
7、TCP 三次握手和终止连接的4次握手过程
此问题再第六个问题中已进行阐述!也可在此处进行简单的说明:
1)、三次握手
①TCP是一种精致的,可靠的字节流协议。
②在TCP编程中,三路握手一般由客户端(Client)调用Connent函数发起。
③TCP3次握手后数据收发通道即打开(即建立了连接)。
④简述三路握手过程:
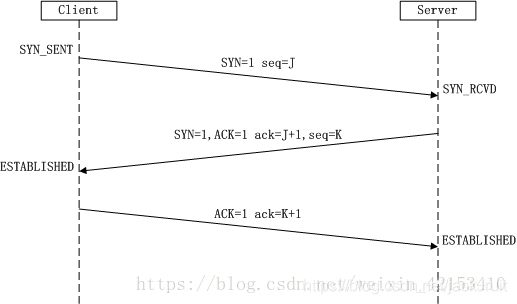
(1)第一次握手:Client将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN_SENT状态,等待Server确认。
(2)第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。
(3)第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
2)四次挥手
所谓四次挥手(Four-Way Wavehand)即终止TCP连接,就是指断开一个TCP连接时,需要客户端和服务端总共发送4个包以确认连接的断开。在socket编程中,这一过程由客户端或服务端任一方执行close来触发。
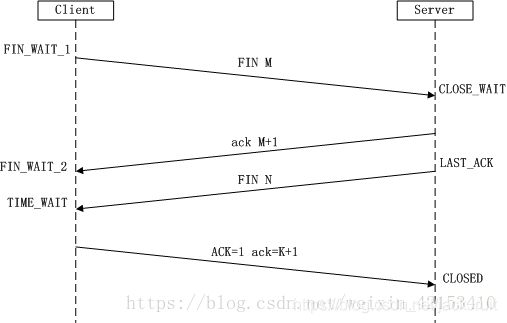
由于TCP连接是全双工的,因此,每个方向都必须要单独进行关闭,这一原则是当一方完成数据发送任务后,发送一个FIN来终止这一方向的连接,收到一个FIN只是意味着这一方向上没有数据流动了,即不会再收到数据了,但是在这个TCP连接上仍然能够发送数据,直到这一方向也发送了FIN。首先进行关闭的一方将执行主动关闭,而另一方则执行被动关闭,上图描述的即是如此。
(1)第一次挥手:Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。
(2)第二次挥手:Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。
(3)第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
(4)第四次挥手:Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号+1,Server进入CLOSED状态,完成四次挥手。
8、介绍一下你做过的XX项目(简历上的)?您在里面负责哪一块?
9、你用的是什么CPU?是什么样的内核?
10、ARM有几种CPU模式,分别是什么?
ARM体系的CPU有以下7种工作模式:
1、用户模式(usr):正常的程序执行状态
2、快速中断模式(fiq): 处理快速中断,支持高速数据传送或通道处理
3、中断模式(irq): 处理普通中断
4、管理模式(svc):操作系统使用的保护模式
5、系统模式(sys):运行具有特权的操作系统任务
6、数据访问终止模式(abt):数据或指令预取终止时进入该模式
7、未定义指令终止模式(und):未定义的指令执行时进入该模式
具体请参考32位ARM处理器的几种工作模式和工作状态
11、列举几种文件系统,分别说说他们的优缺点。
Linux支持多种文件系统,包括ext2、ext3、vfat、ntfs、iso9660、jffs、romfs和nfs等,为了对各类文件系统 进行统一管理,Linux引入了虚拟文件系统VFS(Virtual File System),为各类文件系统提供一个统一的操作界面和应用编程接口。
Jffs2(journaling flash filesystem V2),
主要用于NORflash,基于MTD驱动层,特点:可读写、支持数据压缩,基于哈希表的日志型文件系统,提供掉电保护。缺点是文件系统已满或接近满时,因为垃圾收集的原因运行速度放慢。
Yaffs :yet another flash file system
用于NAND flash,不支持数据压缩,速度快,yaffs2支持2kB的大页nand flash 。
Cramfs:只读文件系统,基于MTD驱动,压缩比高达2:1,运行时解压缩到Ram中
Romfs:只读的,按顺序存放数据。Uclinux常用的文件系统
Ramdisk:将一部分固定大小的内存当做分区来使用,可作为根文件系统。
NFS:network file system
在开发阶段,可以在主机上建立根文件系统用于调试,挂载到嵌入式设备,可以很方便修改根文件系统的内容
12、按键处理用了CPU哪个中断?
请参考:按键和CPU的中断系统
13、嵌入式LINUX 2.6和2.4有什么区别?
嵌入式LINUX 2.6和2.4有什么区别?
这个问题涉及的面非常广泛,我们只能列出基本部分:
每个内核主要的变化在http://lwn.net/Articles/2.6-kernel-api/,详细的参考http://blog.mcuol.com/User/bailang/Article/11222_1.htm, 下面列举的是比较基础和必须的部分
1、使用新的入口必须包含
module_init(your_init_func);
module_exit(your_exit_func);
老版本:int init_module(void);
void cleanup_module(voi);
2.4中两种都可以用,对如后面的入口函数不必要显示包含任何头文件。
2、模块参数必须显式包含
module_param(name, type, perm);
module_param_named(name, value, type, perm);
参数定义
module_param_string(name, string, len,perm);
module_param_array(name, type, num, perm);
老版本:
MODULE_PARM(variable,type);
MODULE_PARM_DESC(variable,type);
3、 模块别名MODULE_ALIAS(“alias-name”);
这是新增的,在老版本中需在/etc/modules.conf配置,现在在代码中就可以实现。
4、 模块计数int try_module_get(&module);module_put();
老版本:MOD_INC_USE_COUNT 和 MOD_DEC_USE_COUNT
5、 符号导出
只有显示的导出符号才能被其他模块使用,默认不导出所有的符号,不必使用EXPORT_NO,_SYMBOLS
老板本:默认导出所有的符号,除非使用EXPORT_NO_SYMBOLS
6、 设备号
kdev_t被废除不可用,新的dev_t拓展到了32位,12位主设备号,20位次设备号。
unsigned int iminor(struct inode *inode);
unsigned int imajor(struct inode *inode);
老版本:
8位主设备号,8位次设备号
int MAJOR(kdev_t dev);
int MINOR(kdev_t dev);
7、 内存分配头文件变更所有的内存分配函数包含在头文件
老版本:内存分配函数包含在头文件
8、 结构体的初试化
gcc开始采用ANSI C的struct结构体的初始化形式:
static struct some_structure = {.field1 = value,.field2 = value,…};
老版本:非标准的初试化形式static struct some_structure = {field1: value,field2: value,…};
9、 request_module()
request_module(“foo-device-%d”, number);
老版本:
char module_name[32];
printf(module_name, “foo-device-%d”, number);
request_module(module_name);
10、 dev_t引发的字符设备的变化
-
1、取主次设备号为unsigned iminor(struct inode *inode);
unsigned imajor(struct inode *inode); -
2、老的register_chrdev()用法没变,保持向后兼容,但不能访问设备号大于256的设备。
-
3、新的接口为
a)注册字符设备范围
int register_chrdev_region(dev_t from, unsigned count, char *name);b)动态申请主设备号
int alloc_chrdev_region(dev_t *dev, unsigned baseminor, unsigned count, char *name);
看了这两个函数郁闷吧_!怎么和file_operations结构联系起来啊?别急!c)包含
,利用struct cdev和file_operations连接
struct cdev *cdev_alloc(void);
void cdev_init(struct cdev *cdev, struct file_operations *fops);
int cdev_add(struct cdev *cdev, dev_t dev, unsigned count);
(分别为,申请cdev结构,和fops连接,将设备加入到系统中!好复杂啊!)d)void cdev_del(struct cdev *cdev);
只有在cdev_add执行成功才可运行。e)辅助函数
kobject_put(&cdev->kobj);struct kobject *cdev_get(struct cdev *cdev);
void cdev_put(struct cdev *cdev);
这一部分变化和新增的/sys/dev有一定的关联。
11、 新增对/proc的访问操作
以前的/proc中只能得到string, seq_file操作能得到如long等多种数据。
相关函数:
static struct seq_operations 必须实现这个类似file_operations得数据中得各个成员函数。seq_printf();
int seq_putc(struct seq_file *m, char c);
int seq_puts(struct seq_file *m, const char *s);
int seq_escape(struct seq_file *m, const char *s, const char *esc);
int seq_path(struct seq_file *m, struct vfsmount *mnt,
struct dentry *dentry, char *esc);
seq_open(file, &ct_seq_ops);等等
12、 底层内存分配
1)、
2)、分配标志GFP_BUFFER被取消,取而代之的是GFP_NOIO 和 GFP_NOFS
3)、新增__GFP_REPEAT,__GFP_NOFAIL,__GFP_NORETRY分配标志
4)、页面分配函数alloc_pages(),get_free_page()被包含在
5)、对NUMA系统新增了几个函数:a) struct page *alloc_pages_node(int node_id,unsigned int gfp_mask,unsigned int order);b) void free_hot_page(struct page *page);c) void free_cold_page(struct page *page);
13、 内核时间变化
1)、现在的各个平台的HZ为
Alpha: 1024/1200; ARM: 100/128/200/1000; CRIS: 100; i386: 1000; IA-64:
1024; M68K: 100; M68K-nommu: 50-1000; MIPS: 100/128/1000; MIPS64: 100;
PA-RISC: 100/1000; PowerPC32: 100; PowerPC64: 1000; S/390: 100; SPARC32:
100; SPARC64: 100; SuperH: 100/1000; UML: 100; v850: 24-100; x86-64: 1000.
2)、由于HZ的变化,原来的jiffies计数器很快就溢出了,引入了新的计数器jiffies_64
3)、#include
u64 my_time = get_jiffies_64();
4)、新的时间结构增加了纳秒成员变量struct timespec current_kernel_time(void);
5)、他的timer函数没变,新增
void add_timer_on(struct timer_list *timer, int cpu);
6)、新增纳秒级延时函数ndelay();
7)、POSIX clocks 参考kernel/posix-timers.c
14、 工作队列(workqueue)
1)、任务队列(task queue )接口函数都被取消,新增了workqueue接口函数
struct workqueue_struct *create_workqueue(const char *name);
DECLARE_WORK(name, void (*function)(void *), void *data);
INIT_WORK(struct work_struct *work,void (*function)(void *), void *data);
PREPARE_WORK(struct work_struct *work,void (*function)(void *), void *data);
2)、申明struct work_struct结构
int queue_work(struct workqueue_struct *queue,struct work_struct *work);
int queue_delayed_work(struct workqueue_struct *queue,struct work_struct *work,unsigned long delay);
int cancel_delayed_work(struct work_struct *work);
void flush_workqueue(struct workqueue_struct *queue);
void destroy_workqueue(struct workqueue_struct *queue);
int schedule_work(struct work_struct *work);
int schedule_delayed_work(struct work_struct *work, unsigned long delay);
15、 DMA的变化
未变化的有:
void *pci_alloc_consistent(struct pci_dev *dev, size_t size,dma_addr_t *dma_handle);
void pci_free_consistent(struct pci_dev *dev, size_t size,void *cpu_addr, dma_addr_t dma_handle);
变化的有:
1)、 void *dma_alloc_coherent(struct device *dev, size_t size,dma_addr_t *dma_handle, int flag);
void dma_free_coherent(struct device *dev, size_t size,void *cpu_addr, dma_addr_t dma_handle);
2)、列举了映射方向:enum dma_data_direction {DMA_BIDIRECTIONAL = 0,DMA_TO_DEVICE = 1,DMA_FROM_DEVICE = 2,DMA_NONE = 3,};
16、 新增完成事件(completion events)
void wait_for_completion(struct completion *comp);
void complete(struct completion *comp);void complete_all(structcompletion *comp);
RCU(Read-copy-update)
rcu_read_lock();
17、 中断处理
1)、中断处理有返回值了。
IRQ_RETVAL(handled);
2)、cli(), sti(), save_flags(), 和 restore_flags()不再有效,应该使用local_save_flags() 或local_irq_disable()。
3)、synchronize_irq()函数有改动
4)、新增int can_request_irq(unsigned int irq, unsigned long flags);
5)、 request_irq() 和free_irq() 从
18、 异步I/O(AIO)
ssize_t (*aio_write) (struct kiocb *iocb, const char __user *buffer,size_t count, loff_t pos);
int (*aio_fsync) (struct kiocb *, int datasync);
新增到了file_operation结构中。
is_sync_kiocb(struct kiocb *iocb);
int aio_complete(struct kiocb *iocb, long res, long res2);
19、 block I/O 层这一部分做的改动最大。不祥叙。
20、内核的一些功能函数的名称、参数、头文件、宏定义的变化
如:中断注册函数的格式及参数在2.4内核、2.6内核低版本和高版本之间都存在差别
在2.6.8中,中断注册函数的定义为:
int request_irq(unsigned int irq, irqreturn_t (*handler)(int, void *, struct pt_regs *),unsigned long irq_flags, const char * devname, void *dev_id)
irq_flags的取值主要为下面的某一种或组合:
SA_INTERRUPT、SA_SAMPLE_RANDOM、SA_SHIRQ
在2.6.26中,中断注册函数的定义为:
int request_irq(unsigned int irq, irq_handler_t handler,unsigned long irqflags, const char *devname, void *dev_id)typedef irqreturn_t (*irq_handler_t)(int, void *);
irq_flags的取值主要为下面的某一种或组合:(功能和2.6.8的对应)
IRQF_DISABLED、IRQF_SAMPLE_RANDOM、IRQF_SHARED
平台代码关于硬件操作方面封装的一些函数的变化
内 核中,硬件平台相关的代码在内核更新过程中变化比较频繁。和我们的设备驱动也是息息相关。所以在针对一个新内核编写设备驱动前,一定要熟悉你的平台代码的 结构。有时平台虽然提供了内核要求的接口函数,但使用起来功能却并不完善。下面还是先举个例子说明平台代码更新对设备驱动的影响。
如: 在linux-2.6.8内核中,调用set_irq_type(IRQ_EINT0, IRQT_FALLING);去设置S3C2410的IRQ_EINT0的中断触发信号类型,你会发现不会有什么效果。跟踪代码发现内核的 set_irq_type函数需要平台提供一个针对硬件平台的实现函数
static struct irqchip s3c_irqext_chip = {
.mask = s3c_irqext_mask, .unmask = s3c_irqext_unmask, .ack = s3c_irqext_ack, .type = s3c_irqext_type};
s3c_irqext_type就是linux内核需要的实现函数,而s3c_irqext_type在2.6.8中的实现为:
static int s3c_irqext_type(unsigned int irq, unsigned int type)
{
irqdbf(“s3c_irqext_type: called for irq %d, type %d\n”, irq, type);
return 0;
}
原来并没有实现。而在较高版本的内核,如2.6.26内核中,这个函数是实现了的。
14、Uboot的作用和功能
1)、uboot是用来干什么的,有什么作用?
uboot 属于bootloader的一种,是用来引导启动内核的,它的最终目的就是,从flash中读出内核,放到内存中,启动内核
所以,由上面描述的,就知道,UBOOT需要具有读写flash的能力。
2)、uboot是怎样引导启动内核的?
uboot刚开始被放到flash中,板子上电后,会自动把其中的一部分代码拷到内存中执行,这部分代码负责把剩余的uboot代码拷到内存中,然后uboot代码再把kernel部分代码也拷到内存中,并且启动,内核启动后,挂着根文件系统,执行应用程序。
3)、uboot启动的大过程是怎么样的?
uboot启动主要分为两个阶段,主要在start.s文件中,第一阶段主要做的是硬件的初始化,包括,设置处理器模式为SVC模式,关闭看门狗,屏蔽中断,初始化sdram,设置栈,设置时钟,从flash拷贝代码到内存,清除bss段等,bss段是用来存储静态变量,全局变量的,然后程序跳转到start_arm_boot函数,宣告第一阶段的结束。
第二阶段比较复杂,做的工作主要是1.从flash中读出内核。2.启动内核。start_arm_boot的主要流程为,设置机器id,初始化flash,然后进入main_loop,等待uboot命令,uboot要启动内核,主要经过两个函数,第一个是s=getenv(“bootcmd”),第二个是run_command(s…),所以要启动内核,需要根据bootcmd环境变量的内容启动,bootcmd环境变量一般指示了从某个flash地址读取内核到启动的内存地址,然后启动,bootm。
uboot启动的内核为uImage,这种格式的内核是由两部分组成:真正的内核和内核头部组成,头部中包括内核中的一些信息,比如内核的加载地址,入口地址。
uboot在接受到启动命令后,要做的主要是:
1,读取内核头部;
2,移动内核到合适的加载地址;
3,启动内核,执行do_bootm_linux;
do_bootm_linux主要做的为:
1,设置启动参数,在特定的地址,保存启动参数,函数分别为setup_start_tag,setup_memory_tag,setup_commandline_tag,setup_end_tag,根据名字我们就知道具体的段内存储的信息,memory中为板子的内存大小信息,commandline为命令行信息,
2,跳到入口地址,启动内核
启动的函数为the_kernel(0,bd->bi_arch_number,bd->bi_boot_param)
bd->bi_arch_number为板子的机器码,bd->bi_boot_param为启动参数的地址
总结:uboot到底是干嘛的,对应下面uboot必须要解决哪些问题!
1)uboot主要作用是用来启动操作系统内核。体现在uboot最后一句代码就是启动内核。
2)uboot还要负责部署整个计算机系统。体现在uboot最后的传参。
3)uboot中还有操作Flash等板子上硬件的驱动。例如串口要打印,ping网络成功,擦除、烧写flash是否成功等。
4)uboot还得提供一个命令行界面供人来操作。很简单,至少你能看到。
计算机系统的组成部件非常多,不同的计算机系统组成部件也不同。但是所有的计算机系统运行时需要的主要核心部件都是3个东西:CPU + 外部存储器(Flash/硬盘) + 内部存储器(DDR SDRAM/SDRAM/SRAM)。而一般的PC机启动过程为:PC上电后先执行BIOS程序(实际上PC的BIOS就是NorFlash),BIOS程序负责初始化DDR内存,负责初始化硬盘,然后从硬盘上将OS镜像读取到DDR中,然后跳转到DDR中去执行OS直到启动(OS启动后BIOS就无用了)。
嵌入式系统和PC机的启动过程几乎没有两样,只是BIOS成了uboot,硬盘成了Flash。
4)uboot必须解决哪些问题?
1自身可开机直接启动
1)一般的SoC都支持多种启动方式,譬如SD卡启动、NorFlash启动、NandFlash启动等•••••uboot要能够开机启动,必须根据具体的SoC的启动设计来设计uboot
2)uboot必须进行和硬件相对应的代码级别的更改和移植,才能够保证可以从相应的启动介质启动。uboot中第一阶段的start.S文件中具体处理了这一块。
2能够引导操作系统内核启动并给内核传参
1)uboot的终极目标就是启动内核。
2)linux内核在设计的时候,设计为可以被传参。也就是说我们可以在uboot中事先给linux内核准备一些启动参数放在内存中特定位置然后传给内核,内核启动后会到这个特定位置去取uboot传给他的参数,然后在内核中解析这些参数,这些参数将被用来指导linux内核的启动过程。
3能提供系统部署功能
1)uboot必须能够被人借助而完成整个系统(包括uboot、kernel、rootfs等的镜像)在Flash上的烧录下载工作。
2)裸机教程中刷机(ARM裸机第三部分)就是利用uboot中的fastboot功能将各种镜像烧录到iNand中,然后从iNand启动。
4 能进行soc级和板级硬件管理
1)uboot中实现了一部分硬件的控制能力(uboot中初始化了一部分硬件),因为uboot为了完成一些任务必须让这些硬件工作。譬如uboot要实现刷机必须能驱动iNand,譬如uboot要在刷机时LCD上显示进度条就必须能驱动LCD,譬如uboot能够通过串口提供操作界面就必须驱动串口。譬如uboot要实现网络功能就必须驱动网卡芯片。
2)SoC级(譬如串口)就是SoC内部外设,板级就是SoC外面开发板上面的硬件(譬如网卡、iNand)
5 uboot的"生命周期"
1)uboot的生命周期就是指:uboot什么时候开始运行,什么时候结束运行。
2)uboot本质上是一个裸机程序(不是操作系统),一旦uboot开始SoC就会单纯运行uboot(意思就是uboot运行的时候别的程序是不可能同时运行的),一旦uboot结束运行则无法再回到uboot(所以uboot启动了内核后uboot自己本身就死了,要想再次看到uboot界面只能重启系统。重启并不是复活了刚才的uboot,重启只是uboot的另一生)
3)uboot的入口和出口。uboot的入口就是开机自动启动,uboot的唯一出口就是启动内核。uboot还可以执行很多别的任务(譬如烧录系统),但是其他任务执行完后都可以回到uboot的命令行继续执行uboot命令,而启动内核命令一旦执行就回不来了。
总结:uboot的一切都是为了启动内核。
具体请参考:uboot的作用和功能