大数据开发技术课程报告(搭建Hadoop完全分布式集群&&操作集群)
文章目录
-
- 大数据开发技术课程报告内容及要求
- 一、 项目简介和实验环境
- 二、 虚拟机的各项准备工作
- 三、 安装JDK并配置环境变量
- 四、 安装Hadoop并配置环境变量
- 五、 配置Hadoop完全分布式集群
- 六、 启动Hadoop完全分布式集群
- 七、 Hadoop完全分布式集群的Shell操作
- 八、 Hadoop完全分布式集群的Java API操作
- 九、 阶段总结
大数据开发技术课程报告内容及要求
报告内容及要求
本报告作为“大数据开发技术”课程的阶段性考试内容,需要独立完成,可以参考资料。
- 报告内容
在Linux系统上,利用课上所学知识,根据自身机器配置,创建一个伪分布式Hadoop集群或完全分布式Hadoop集群,并对集群进行操作。需要在项目实现过程中,体现出通过本课程所学知识。- 报告要求
集群形式可以根据机器配置在伪分布式和完全分布式间进行选择;
Hadoop集群及所需组件的安装和配置需要截图;
关于Java的目录:需要自定义名称,添加学号后缀,比如学号为18B12345,那么JAVA_HOME的路径应该是…/java-18B12345,需要截图在报告中进行体现;
关于集群的测试:在Hadoop集群安装完成后,需要分别用官方提供的例子和Web UI进行测试,需要截图在报告中进行体现;
关于集群的操作:需要分别使用Shell形式和Java API对集群进行操作并截图在报告中进行体现,其中:在使用Java API时,Java项目的命名需要具有学号后缀,比如;学号为18B12345,那么如果创建的Java项目为hdfs-api,则实际创建的Java项目为hadfs-api-18B12345;如果创建的Java代码文件为main.java,则实际创建的.java文件为main_18B12345.java。
一、 项目简介和实验环境
本项目主要是建立Hadoop完全分布式集群,并进行集群测试和操作。
主要内容:配置hadoop完全分布式集群的前期准备、安装过程、配置文件、启动过程、Shell操作、Java API操作。
(本文中的一些文件可能带有学号后缀,这是课程报告的要求,实际上不必写后缀)
Linux发行版:ubuntu-18.04.4-desktop-amd64
JDK版本:jdk1.8.0_144
Hadoop版本:hadoop-2.7.2
二、 虚拟机的各项准备工作
创建三台虚拟机,并完成各项准备工作。
以下的所有准备工作在三台虚拟机上都要做。由于在准备阶段,三台主机的操作几乎完全相同,所以在此以第一台主机hadoop1为例。
注意,本文的所有命令均是在root账号下运行。
(1) 修改主机名,依次为hadoop1,hadoop2,hadoop3。
(2) 关闭防火墙
输入命令ufw disable,关闭防火墙,重启后即可生效。
(3) 设置静态IP, hadoop1主机的设置如下图所示:
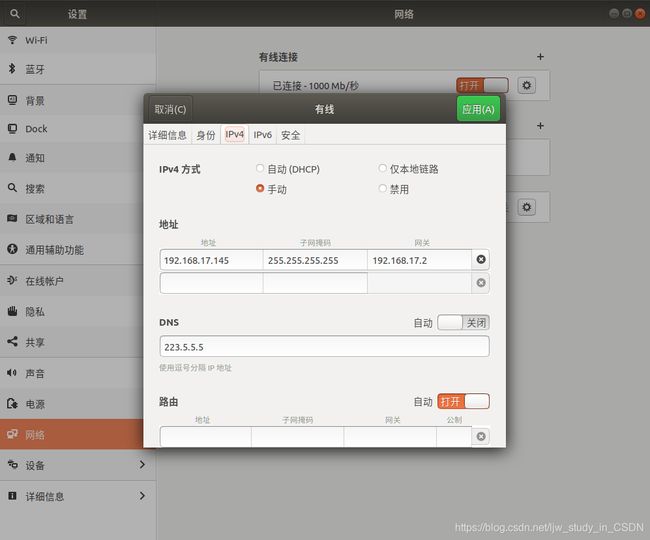
输入命令ifconfig,查看一下IP,显示设置成功:

(4) 配置ssh免密登录,方便之后用xsync脚本进行集群分发。
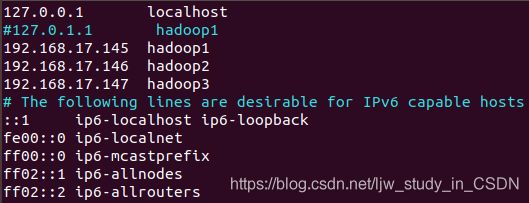
输入命令vim /etc/hosts,将主机名与各自IP相对应,如下图所示:
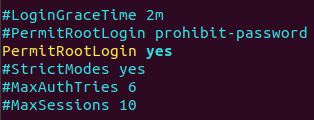
输入命令vim /etc/ssh/sshd_config,找到PermitRootLogin 配置项将原先的PermitRootLogin的prohibit-password修改为yes:
输入命令service ssh restart,重启ssh。
cd ~ (进入root目录)
ssh-keygen -t rsa,再按3次回车
~/.ssh会生成两个文件:id_rsa(私钥)、id_rsa.pub(公钥)
然后将其公钥加到3个虚拟机目录下(会生成一个authorized_keys的公钥,如果已经存在,则在该文件后面将会继续追加公钥内容),输入以下命令:
ssh-copy-id root@hadoop1
ssh-copy-id root@hadoop2
ssh-copy-id root@hadoop3
三台虚拟机都完成如上操作后,在hadoop1主机上测试是否能以root账号免密登录到hadoop2。
输入命令ssh root@hadoop2,无需输入密码则说明ssh免密登录配置成功,如下图所示:
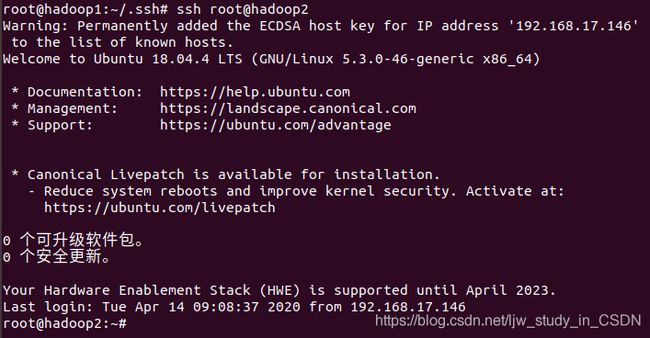
输入命令exit退出hadoop2的root账号,继续操作。
(5) 编写集群分发脚本xsync
输入命令vim /usr/local/bin/xsync,编写内容如下:
#!/bin/bash
if [[ -x $(command -v rsync) ]]; then
echo yes > /dev/null
else
echo no rsync found!
exit 1
fi
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args!
exit;
fi
#2 获取文件名称
p1=$1
fname=$(basename $p1)
echo fname=$fname
#3 获取文件绝对路径
pdir=$(cd -P $(dirname $p1); pwd)
echo pdir=$pdir
#4 获取当前用户名称
user=$(whoami)
#5 循环
for((host=2; host<4; host++)); do
echo --- hadoop$host ---
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
输入命令chmod +x xsync,将其提升为可执行文件的权限。
这个脚本只要写在hadoop1主机中即可,由它来向其他主机分发文件。
三、 安装JDK并配置环境变量
在hadoop1主机中安装JDK并配置相应文件,同时用xsync同步文件到其他主机。
输入命令tar -zxvf jdk-8u144-linux-x64.tar.gz解压得到jdk1.8.0_144目录,将其改名为jdk1.8.0_144-2018214184。
输入命令xsync jdk1.8.0_144-2018214184,将其分发到其他主机上。
输入命令vim /etc/profile.d/java.sh,配置环境变量:
![]()
输入命令xsync /etc/profile.d/java.sh,将其分发到其他主机上:
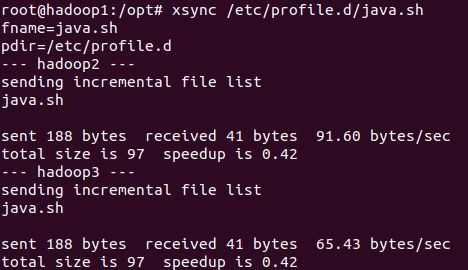
输入命令source /etc/profile使环境变量生效。
最后,输入命令java -version,检验是否配置成功,如图所示,说明java已经配置成功:

四、 安装Hadoop并配置环境变量
在hadoop1主机中安装Hadoop并配置相应文件,同时用xsync同步文件到其他主机。
输入命令tar -zxvf hadoop-2.7.2.tar.gz解压得到hadoop-2.7.2目录。
输入命令xsync hadoop-2.7.2,将其分发到其他主机上。
输入命令vim /etc/profile.d/hadoop.sh,配置环境变量:

输入命令xsync /etc/profile.d/hadoop.sh,将其分发到其他主机上:
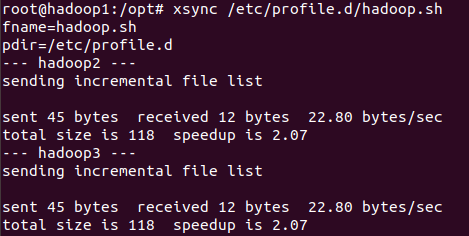
输入命令source /etc/profile使环境变量生效。
最后,再输入命令hadoop,检验是否配置成功,如图所示,说明Hadoop已经配置成功:

五、 配置Hadoop完全分布式集群
集群部署规划:

为了能群启集群,还需要配置/opt/hadoop-2.7.2/etc/hadoop目录下的一些文件。
(1)vim hadoop-env.sh,加入JAVA_HOME:
export JAVA_HOME=/opt/jdk1.8.0_144
如图:
![]()
(2)vim yarn-env.sh,加入JAVA_HOME:
export JAVA_HOME=/opt/jdk1.8.0_144
如图:

(3)vim mapred-env.sh,加入JAVA_HOME:
export JAVA_HOME=/opt/jdk1.8.0_144
如图:
![]()
(4)vim core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.2/data/tmp</value>
</property>
如图:
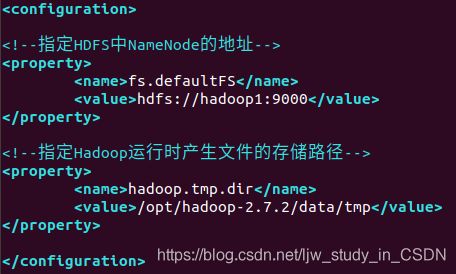
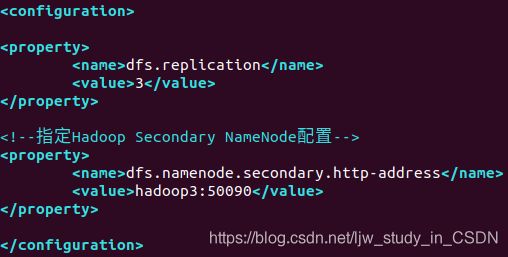
(5)vim hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop3:50090</value>
</property>
如图:
(6)vim yarn-site.xml,注意是在两个
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop2</value>
</property>
<property>
<name>yarn.resourcenamager.webapp.address</name>
<value>0.0.0.0:8088</value>
</property>
如图:
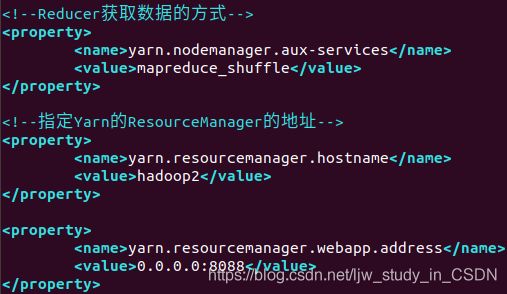
(7)vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
如图:
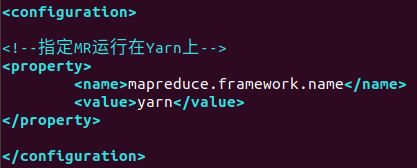
(8)vim slaves
hadoop1
hadoop2
hadoop3
最后,输入命令xsync /opt/hadoop-2.7.2/etc/hadoop,将配置文件同步到所有节点:
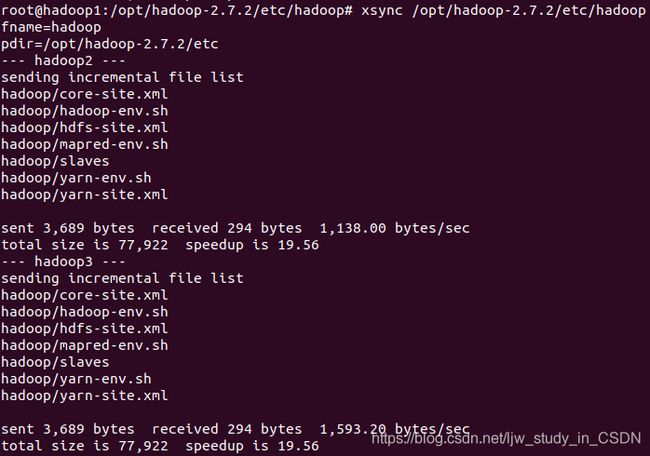
六、 启动Hadoop完全分布式集群
首先进入到 /opt/hadoop-2.7.2 目录下,jps确认节点都已关闭后,
输入命令rm -r logs data和bin/hdfs namenode -format,格式化NameNode。
(三台虚拟机都要执行该操作)
群启集群,先在规划的NameNode(hadoop1主机)执行命令sbin/start-dfs.sh,如下图:
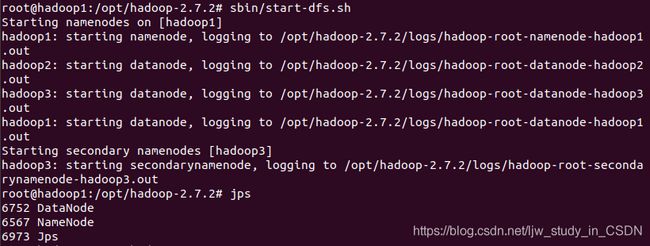
显示hadoop1主机上启动NameNode和DataNode成功。
继续检查hadoop2和hadoop3上是否启动成功,若成功则继续操作。
然后在规划的ResourceManager(hadoop2主机)执行命令sbin/start-yarn.sh,如下图:

然后输入jps命令检查三台主机是否都启动成功。
hadoop1主机:

hadoop2主机:
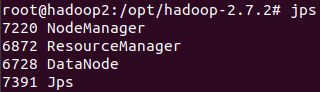
hadoop3主机:
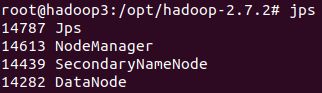
三个主机的jps表明,按照规划群启hadoop集群成功。
Web UI能正常访问hadoop1:50070,如下图:

Web UI能正常访问hadoop2:8088,如下图:
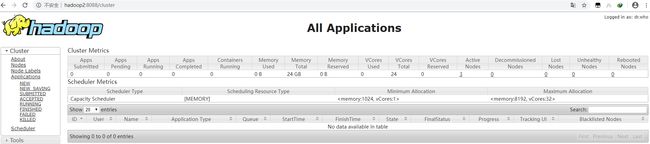
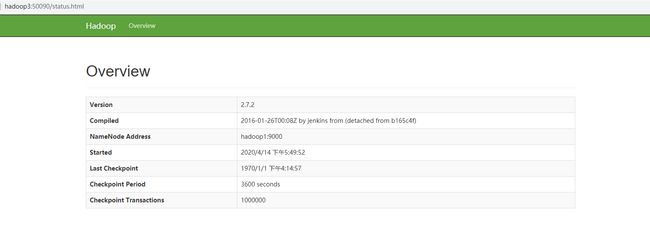
Web UI能正常访问hadoop3:50090,如下图:
七、 Hadoop完全分布式集群的Shell操作
(1) 在HDFS上创建目录:hadoop fs -mkdir -p /tmp/test
Web UI显示在HDFS上创建目录成功,如下图:

(2) 从本地系统中拷贝文件到HDFS路径中,输入以下命令:
touch /tmp/zhangsan.txt
echo “I am zhangsan” > /tmp/zhangsan.txt
hadoop fs -copyFromLocal /tmp/zhangsan.txt /tmp/test
Web UI显示从本地拷贝文件到HDFS成功,如下图:

(3) 从HDFS上拷贝文件到本地,输入以下命令:
rm /tmp/zhangsan.txt
hadoop fs -copyToLocal /tmp/test/zhangsan.txt /tmp
cat /tmp/zhangsan.txt
删除了本地文件,又得到了一模一样的文件,说明从HDFS上拷贝文件到本地成功,运行结果如图:

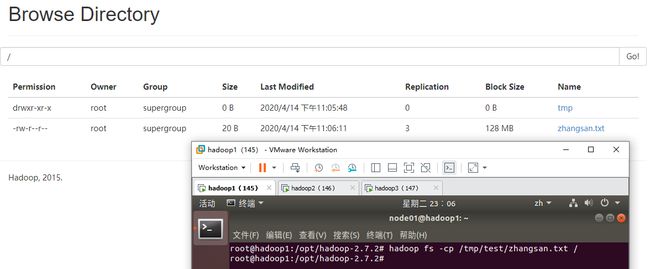
(4) 将文件从HDFS的一个路径拷贝到另一个路径:hadoop fs -cp /tmp/test/zhangsan.txt /
Web UI显示文件从HDFS的一个路径拷贝到另一个路径成功,如下图:
(5) 删除HDFS的文件:hadoop fs -rm /zhangsan.txt
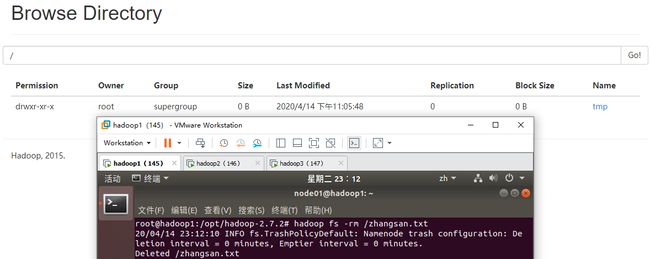
Web UI显示在HDFS上之前拷贝得到的/zhangsan.txt已被成功删除。
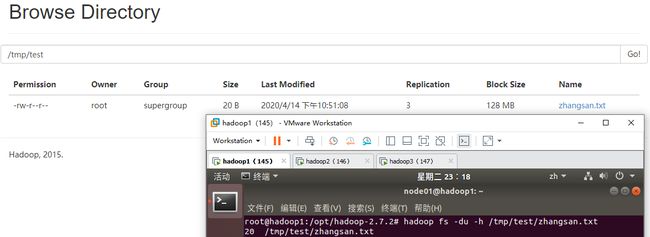
(6) 统计文件的大小信息:hadoop fs -du -h /tmp/test/zhangsan.txt
Web UI上显示的文件大小和终端显示的文件大小相同,都是20B,如下图:
(7) 运行官方案例中的WordCount程序
输入命令hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /tmp/test/zhangsan.txt /tmp/output
(这里注意在HDFS上/tmp/output事先不能存在,否则无法运行WordCount)
运行过程的后几十行如下:

输入命令hadoop fs -cat /tmp/output/p*,查看生成的文件,Web UI显示生成了/tmp/output/part-r-00000,查看该文件,显示是WordCount运行的结果,如下图:

八、 Hadoop完全分布式集群的Java API操作
先安装并配置好maven(maven安装步骤和jdk类似),输入命令mvn -version,如下图显示maven已安装成功:

输入命令vim ${MAVEN_HOME}/conf/settings.xml,更换${MAVEN_HOME}/conf/settings.xml文件中的mirror为阿里云:

输入命令mvn archetype:generate -DgroupId=com.root,显示创建目录hdfs-mkdir-2018214184成功,如下图:

进入hdfs-mkdir-2018214184目录,输入以下命令:
mvn clean
mvn package
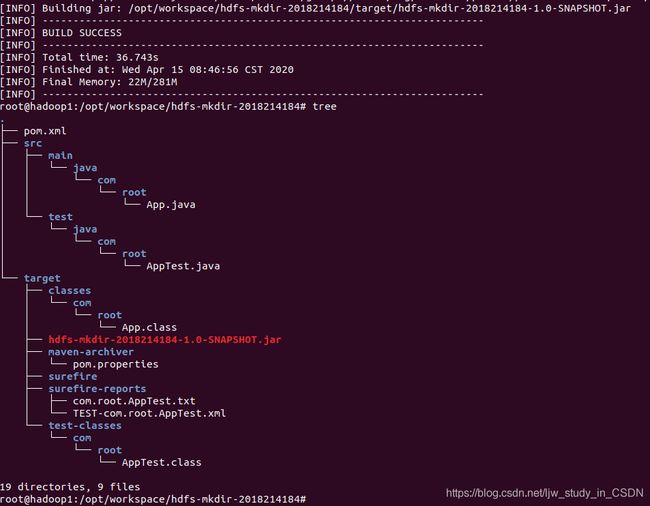
tree
结果如图所示,编译生成了target目录:
输入命令java -cp target/hdfs-mkdir-2018214184-1.0-SNAPSHOT.jar com.root.App
如图所示,能成功运行Java程序,输出Hello World

输入命令vim pom.xml,导入依赖和插件:
junit</groupId>
junit</artifactId>
RELEASE</version>
</dependency>
org.apache.logging.log4j</groupId>
log4j-core</artifactId>
2.8.2</version>
</dependency>
org.apache.hadoop</groupId>
hadoop-common</artifactId>
${
hadoop.version}</version>
</dependency>
org.apache.hadoop</groupId>
hadoop-client</artifactId>
${
hadoop.version}</version>
</dependency>
org.apache.hadoop</groupId>
hadoop-hdfs</artifactId>
${
hadoop.version}</version>
</dependency>
</dependencies>
org.apache.maven.plugins</groupId>
maven-jar-plugin</artifactId>
2.3.2</version>
true</addClasspath>
lib/</classpathPrefix>
com.root</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
org.apache.maven.plugins</groupId>
maven-dependency-plugin</artifactId>
copy</id>
package</phase>
copy-dependencies</goal>
</goals>
${
project.build.directory}/lib
</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
再次输入命令:
mvn clean
mvn package
java -cp target/hdfs-mkdir-1.0-SNAPSHOT.jar com.root.App
运行结果如图,说明导入依赖和插件后,程序能正常运行。

接下来可以自己编写Java程序,通过Java API操作HDFS。
(1) 调用Java API,在HDFS上创建目录。
输入命令vim /opt/workspace/hdfs-mkdir-2018214184/src/main/java/com/root/Mkdir_2018214184.java,编写源码如下:
package com.root;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Mkdir_2018214184
{
public static void main( String[] args ) throws IOException, Exception, URISyntaxException
{
Configuration conf = new Configuration();
//1 获取hdfs客户端对象
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop1:9000"), conf, "root");
//2 在hdfs上创建路径
fs.mkdirs(new Path("/0x00/usr"));
//3 关闭资源
fs.close();
System.out.println( "HDFS mkdir!" );
}
}
输入命令:
mvn clean
mvn package
java -cp target/hdfs-mkdir-1.0-SNAPSHOT.jar com.root.Mkdir_2018214184
在Web UI上可以看到成功创建0x00目录,如下图:

(2) 调用Java API,从本地拷贝文件到HDFS。
输入命令vim /opt/workspace/hdfs-mkdir-2018214184/src/main/java/com/root/CopyFromLocal_2018214184.java,编写源码如下:
package com.root;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CopyFromLocal_2018214184
{
public static void main( String[] args ) throws IOException, Exception, URISyntaxException
{
Configuration conf = new Configuration();
//1 获取hdfs客户端对象
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop1:9000"), conf, "root");
//2 将本地文件上传到hdfs上
fs.copyFromLocalFile(new Path("/tmp/java-api-2018214184.txt"), new Path("/java-api-2018214184.txt"));
//3 关闭资源
fs.close();
System.out.println( "HDFS copy from local!" );
}
}
输入命令:
touch /tmp/java-api-2018214184.txt
echo This is a java-api test > /tmp/java-api-2018214184.txt
mvn clean
mvn package
java -cp target/hdfs-mkdir-1.0-SNAPSHOT.jar com.root.CopyFromLocal_2018214184
在Web UI上可以看到从本地拷贝java-api-2018214184.txt到HDFS成功,如下图:

(3) 调用Java API,从HDFS拷贝文件到本地。
输入命令vim /opt/workspace/hdfs-mkdir-2018214184/src/main/java/com/root/CopyToLocal_2018214184.java,编写源码如下:
package com.root;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CopyToLocal_2018214184
{
public static void main( String[] args ) throws IOException, Exception, URISyntaxException
{
Configuration conf = new Configuration();
//1 获取hdfs客户端对象
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop1:9000"), conf, "root");
//2 下载操作
fs.copyToLocalFile(new Path("/java-api-2018214184.txt"), new Path("/tmp/java-api-2018214184.txt"));
//3 关闭资源
fs.close();
System.out.println( "HDFS copy to local!" );
}
}
输入命令:
mvn clean
mvn package
rm /tmp/java-api-2018214184.txt
java -cp target/hdfs-mkdir-1.0-SNAPSHOT.jar com.root.CopyToLocal_2018214184
cat /tmp/java-api-2018214184.txt
删除本地文件,再下载,cat命令显示能打开刚才从HDFS下载的文件,并且内容一致,如下图:
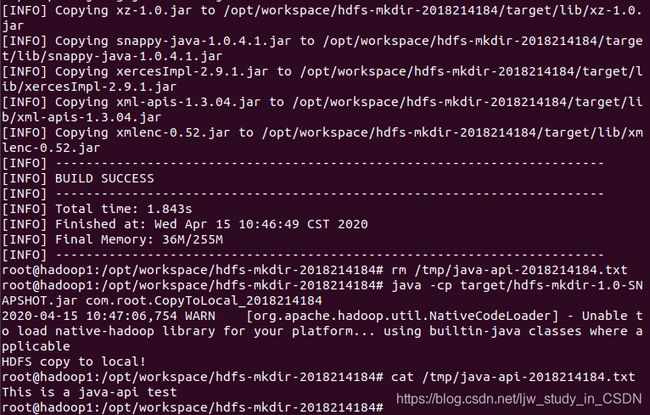
(4) 调用Java API,删除HDFS上的文件。
输入命令vim /opt/workspace/hdfs-mkdir-2018214184/src/main/java/com/root/Delete_2018214184.java,编写源码如下:
package com.root;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Delete_2018214184
{
public static void main( String[] args ) throws IOException, Exception, URISyntaxException
{
Configuration conf = new Configuration();
//1 获取hdfs客户端对象
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop1:9000"), conf, "root");
//2 文件删除
fs.delete(new Path("/0x00"), true);
//3 关闭资源
fs.close();
System.out.println( "HDFS delete!" );
}
}
输入命令:
mvn clean
mvn package
java -cp target/hdfs-mkdir-1.0-SNAPSHOT.jar com.root.Delete_2018214184
在Web UI上显示删除0x00目录成功,如下图:
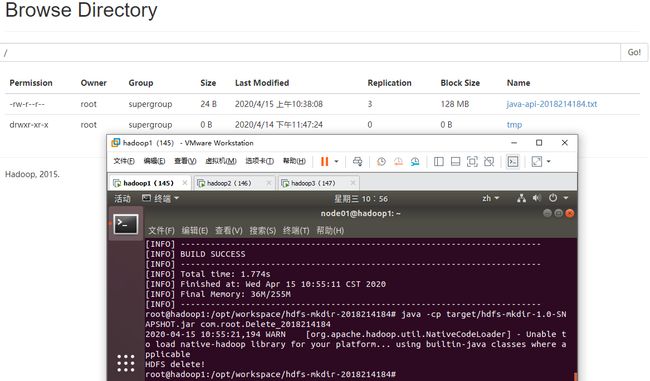
(5) 调用Java API,重命名HDFS上的文件。
输入命令vim /opt/workspace/hdfs-mkdir-2018214184/src/main/java/com/root/Rename_2018214184.java,编写源码如下:
package com.root;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Rename_2018214184
{
public static void main( String[] args ) throws IOException, Exception, URISyntaxException
{
Configuration conf = new Configuration();
//1 获取hdfs客户端对象
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop1:9000"), conf, "root");
//2 文件更名
fs.rename(new Path("/java-api-2018214184.txt"), new Path("/rename-2018214184.txt"));
//3 关闭资源
fs.close();
System.out.println( "HDFS rename!" );
}
}
输入命令:
mvn clean
mvn package
java -cp target/hdfs-mkdir-1.0-SNAPSHOT.jar com.root.Rename_2018214184
在Web UI上显示重命名文件成功,如下图:
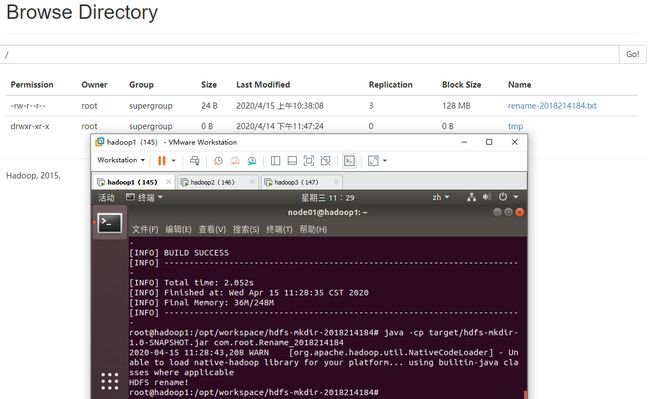
(6) 调用Java API,查看HDFS根目录下所有文件的详细信息。
输入命令vim /opt/workspace/hdfs-mkdir-2018214184/src/main/java/com/root/ListFiles_2018214184.java,编写源码如下:
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.BlockLocation;
public class ListFiles_2018214184
{
public static void main( String[] args ) throws IOException, Exception, URISyntaxException
{
Configuration conf = new Configuration();
//1 获取hdfs客户端对象
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop1:9000"), conf, "root");
//2 查看文件详情
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext())
{
LocatedFileStatus fileStatus = listFiles.next();
// 查看文件名称、权限、长度、块信息
System.out.println(fileStatus.getPath().getName());
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getLen());
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for (BlockLocation blockLocation: blockLocations)
{
String[] hosts = blockLocation.getHosts();
for (String host: hosts)
{
System.out.println(host);
}
}
System.out.println( "----------" );
}
//3 关闭资源
fs.close();
System.out.println( "HDFS list files" );
}
}
输入命令:
mvn clean
mvn package
java -cp target/hdfs-mkdir-1.0-SNAPSHOT.jar com.root.ListFiles_2018214184
列出了很多文件的详细信息,可以看到zhangsan.txt有三个副本,大小为20B,与之前Web UI显示的结果相同,如下图:

(7) 调用Java API,查看HDFS根目录下的各个文件的类型(文件或文件夹)。
输入命令vim /opt/workspace/hdfs-mkdir-2018214184/src/main/java/com/root/ListStatus_2018214184.java,编写源码如下:
package com.root;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.BlockLocation;
public class ListStatus_2018214184
{
public static void main( String[] args ) throws IOException, Exception, URISyntaxException
{
Configuration conf = new Configuration();
//1 获取hdfs客户端对象
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop1:9000"), conf, "root");
//2 判断操作
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus fileStatus: listStatus)
{
if (fileStatus.isFile())
{
// 文件
System.out.println("This is file: "+fileStatus.getPath().getName());
}
else
{
// 文件夹(目录)
System.out.println("This is directory: "+fileStatus.getPath().getName());
}
}
//3 关闭资源
fs.close();
System.out.println( "HDFS list status!" );
}
}
输入命令:
mvn clean
mvn package
java -cp target/hdfs-mkdir-1.0-SNAPSHOT.jar com.root.ListStatus_2018214184
可以看到rename-2018214184.txt是文件,tmp是文件夹(目录),与Web UI显示的结果相同,如下图:
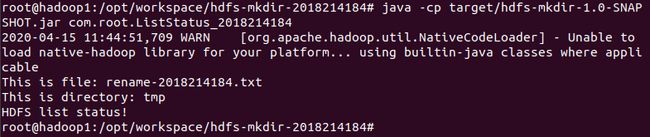
九、 阶段总结
这次的大数据开发技术课程报告,主要记录了配置hadoop完全分布式集群的前期准备、安装过程、配置文件、启动过程、Shell操作、Java API操作。
配合教学视频自己全部操作了一遍,可以感觉到这门课的内容是很丰富的。在操作过程中难免会出现很多问题,遇到问题不要怕,找到日志记录上的Error和Fatal信息,一般来说出现错误的情况大多是配置文件的问题,按照错误信息去改即可。
在课程报告中,有很多实用的知识点,比如xsync脚本实现多个节点的文件同步,ssh免密登录,以及Java API操作HDFS等等。其中xsync脚本实现了对rsync命令的二次封装, Java API则实现了由Java程序操作HDFS的各种功能,而Java程序的源码都是可以自己写的,也可以调用官方的库文件,可扩展性很强。
用编写好的程序代替手工繁琐的工作,实现各种想要的功能,这正是课程实践的乐趣所在,而解决一个个问题,创建出自己独特的项目,也是一件有成就感的事。希望在下次课程实践中能学到更多实用的知识,实现更加有意思的功能。
花了两天时间,终于写完了这篇课程报告,你现在看到的这篇文章是将近30页的Word文档。
![]()