unity计算着色器入门
1.定义
做实验需要使用高性能计算,因此翻出来学习一下用法。
计算着色器(Compute Shader简称CS)的用途就是并行计算,适用于算法简单但数量庞大的算法
应用场景:液体模拟,布料解算,聚落模拟等。
下面尝试做一个CS的demo
之前在yt上看到一个CS的应用,效果非常帅

使用类似于体素的方法来渲染一张“假”屏幕,相当于一个三维的屏幕,很有全息投影的既视感。
原理不难想,生成X*Y个Quad组成一张假屏幕方阵,使用两个摄像机,一个主摄像机用于正常观察,另一个摄像机用来渲染深度图,最后将深度图信息映射到假屏幕上,就可以得到最后的结果。
如果用CPU来算,就是给每一个Quad获取一个深度然后计算世界矩阵,最后渲染。
那么下面尝试用CS算
2. 线程组
在计算之前,首先要定义并行计算单元的排布。
在逻辑上,cells分为两层,第一层是结构为[X,Y,Z]的一堆Cells,第二层在以一堆Cells为一个Group之上抽象出好几个Group同时工作。

假如我们要计算32✖32即1024个Quad,可以这么设计
单个Group内[8, 8, 1],一共4✖4个Group,加起来正好是1024个计算单元,对应着1024个数据。
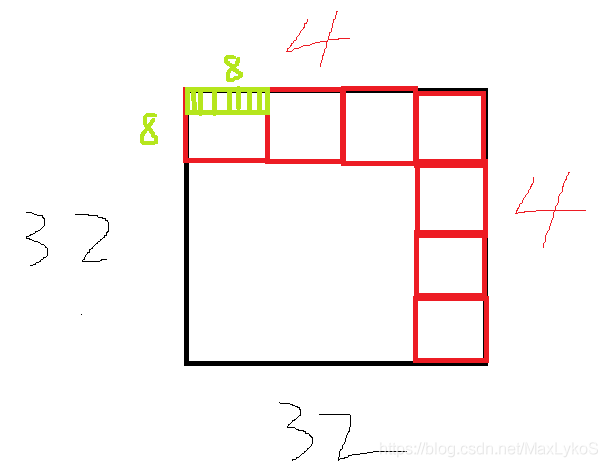
黑色是数据量,红色是ThreadGroup,绿色是Thread
当然也可以分成其他的方式
3.数据准备
先不考虑shader怎么写,把数据准备做完先。
由于CPU和GPU的沟通方式类似于客户端和服务器,因此需要CPU整理数据,后将数据发送到GPU计算,最后CPU再Retrieve。所以如果CPU耽误时间,那就得GPU干等,反过来也一样。
3.1获取深度图
获取深度图的方式很多,我用了最方便的
重写深度摄像机的OnRenderImage,将Built-in渲染管线内的_CameraDepthTexturen通过一个后处理Shader拿出来。
Shader "Custom/DepthShader"
{
Properties
{
//_MainTex ("Texture", 2D) = "white" {}
}
SubShader
{
// No culling or depth
Cull Off ZWrite Off ZTest Always
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
float2 uv : TEXCOORD0;
};
struct v2f
{
float2 uv : TEXCOORD0;
float4 vertex : SV_POSITION;
};
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
o.uv = v.uv;
return o;
}
//sampler2D _MainTex;
sampler2D _CameraDepthTexture;
fixed4 frag(v2f i) : SV_Target
{
float depth = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, i.uv);
float linearDepth = Linear01Depth(depth);
return fixed4(linearDepth, linearDepth, linearDepth, 1.0);
}
ENDCG
}
}
}
3.2 提交Buffer
需要用到两种Buffer
- ComputeBuffer,在CS里作为RWStructuredBuffer<>,支持泛型
- RenderTexture,在CS里作为RWTexture2D<>,就是个纹理,深度纹理的话只需要一个float
提交的是RenderTexture深度图,返回ComputeBuffer,里面是计算完后的坐标。
具体API就不写了,最后全放后面了。
还有一个常量缓冲区,通过ComputeShader直接提交
3.3 硬件实例化
渲染1023个Cube在一个DrawCall里完成,可以加快速度。因为每一次DrawCall都牵扯到渲染状态的设置,就是D3D底层各种Bind的那一套,还有各种其他的加速原理。同一个网格最多一次渲染1023个,如果多余1023个,就再Draw一次。
api是Graphics.DrawMeshInstanced()
之前有在知乎看到文章比较unity网格渲染器和GraphicsAPI渲染的效率,的确是直接调渲染API速度快,因为网格渲染器做渲染时还要考虑排序,具体是啥,我不知道,可能是透明物体吧。
要支持硬件实例化,必须是网格不变,参数可变,Shader也要支持,除了在shader下面打个enable_Instancing的勾以外,要加很多宏。如果好奇宏底下是什么代码,建议查阅《Unity内建着色器源码剖析》。
好像DX12有什么支持可变形网格合批的黑科技,mark一下,以后再看。
Shader "Custom/UnlitShader"
{
Properties
{
_Color ("Color", Color) = (1, 1, 1, 1)
}
SubShader
{
Tags { "RenderType"="Opaque" }
LOD 100
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile_instancing
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct v2f
{
float4 vertex : SV_POSITION;
UNITY_VERTEX_INPUT_INSTANCE_ID // necessary only if you want to access instanced properties in fragment Shader.
};
UNITY_INSTANCING_BUFFER_START(Props)
UNITY_DEFINE_INSTANCED_PROP(float4, _Color)
UNITY_INSTANCING_BUFFER_END(Props)
v2f vert(appdata v)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(v);
UNITY_TRANSFER_INSTANCE_ID(v, o); // necessary only if you want to access instanced properties in the fragment Shader.
o.vertex = UnityObjectToClipPos(v.vertex);
return o;
}
fixed4 frag(v2f i) : SV_Target
{
UNITY_SETUP_INSTANCE_ID(i); // necessary only if any instanced properties are going to be accessed in the fragment Shader.
return UNITY_ACCESS_INSTANCED_PROP(Props, _Color);
}
ENDCG
}
}
FallBack "Diffuse"
}
4. 计算着色器代码
#pragma kernel CSMain // 定义核函数入口
#define thread_group_x 4 // 参照第2节
#define thread_group_y 4 // 参照第2节
#define thread_x 8 // 参照第2节
#define thread_y 8 // 参照第2节
RWTexture2D DepthMap;
RWStructuredBuffer ResultPosition;
float Offset;
[numthreads(8,8,1)]
void CSMain (uint3 id : SV_DispatchThreadID)
{
int index = id.x
+ (id.y * thread_x * thread_group_x)
+ (id.z * thread_group_x * thread_group_y * thread_x * thread_y);
float depth = DepthMap[id.xy];
ResultPosition[index] = float3(id.xy, depth * Offset);
}
这个index的计算是三维降到1维,因为坐标数组是一维,另外深度图是二维。
SV_DispatchThreadID代表当前线程在全部线程组里的位置,唯一确定一个线程,或者说一个Cell,所以可以直接代表深度图里的某个像素(如果深度图也是32✖32的分辨率)
4.2 提交和获取计算着色器任务结果
在CPU端调用Dispatch方法,参数里提供核的索引,以及三个维度的线程组数量,本实例中是4✖4✖1,回顾第2节。
调用Dispatch之后,CPU会将数据发往GPU,由GPU计算。
调用buffer.GetData可以返回GPU的计算结果。这里有坑,GetData是同步的,在GPU算完并返回之前,CPU会在这里阻塞,消耗大量主线程时间。在分析器里可以看到底层有个blablaGetData的函数占用几十ms。
在unity2018某个版本之后,加入了异步版本。
AsyncGPUReadback.Request(resultBuffer, CallBackAction),参数前者是要接收数据的buffer,后者是接收完后的回调。
异步的缺点是引入延迟,感觉挺明显的,可能是我FPS的基因太强(ruo)。
5. C#代码以及结果
计算量不大,主要是了解使用方法,为将来的大招铺垫
如果要实现yt上的效果,加大数据量即可。
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.Rendering;
using UnityEngine.SceneManagement;
public class TestComputeShader : MonoBehaviour
{
public Mesh mesh; // 手拖unity内置的Cube
public Material mat; // 手拖,渲染Cube的
private Matrix4x4[] matrixs;
private MaterialPropertyBlock block;
public Camera DepthCam; // 手拖
public Material DepthMat; // 手拖
private RenderTexture depthRT;
public ComputeShader cs; // 手拖
private const int Resolution = 32;
private ComputeBuffer resultBuffer;
private Vector3[] resultPositions;
private const float Offset = 10.0f;
private void Start()
{
InitDepthCam();
InitCubeScreen();
InitCS();
}
// Update is called once per frame
private void Update()
{
UpdatePositionsFromCS();
Graphics.DrawMeshInstanced(mesh, 0, mat, matrixs, 1023, block, ShadowCastingMode.Off, false);
}
private void InitCubeScreen()
{
matrixs = new Matrix4x4[1023];
block = new MaterialPropertyBlock();
Vector4[] colors = new Vector4[1023];
for (var i = 0; i < 32; i++)
for (var j = 0; j < 32; j++)
{
var ind = j * 32 + i;
if (ind >= 1023) break;
matrixs[ind] = Matrix4x4.TRS(new Vector3(i, j, 0), Quaternion.identity, Vector3.one * 0.5f);
colors[ind] = new Vector4(1 - i / 32.0f, 1 - j / 32.0f, 1, 1);
}
block.SetVectorArray("_Color", colors);
}
private void InitCS()
{
resultPositions = new Vector3[Resolution * Resolution];
resultBuffer = new ComputeBuffer(resultPositions.Length, sizeof(float) * 3);
cs.SetFloat("Offset", Offset);
}
private void InitDepthCam()
{
depthRT = new RenderTexture(Resolution, Resolution, 24)
{
enableRandomWrite = true
};
depthRT.Create();
DepthCam.depthTextureMode |= DepthTextureMode.Depth;
DepthCam.targetTexture = depthRT;
}
private void UpdatePositionsFromCS()
{
int kernelHandle = cs.FindKernel("CSMain");
cs.SetTexture(kernelHandle, "DepthMap", depthRT);
cs.SetBuffer(kernelHandle, "ResultPosition", resultBuffer);
cs.Dispatch(kernelHandle, Resolution / 8, Resolution / 8, 1);
/*resultBuffer.GetData(resultPositions);
for (int i = 0; i < matrixs.Length; ++i)
{
matrixs[i] = Matrix4x4.TRS(resultPositions[i], Quaternion.identity, Vector3.one * 0.5f);
}*/
AsyncGPUReadback.Request(resultBuffer, CSBufferCallBack);
}
private void OnRenderImage(RenderTexture source, RenderTexture destination)
{
Graphics.Blit(source, depthRT, DepthMat);
}
private void CSBufferCallBack(AsyncGPUReadbackRequest request)
{
if (request.hasError)
{
Debug.Log("GPU readback error detected.");
return;
}
resultPositions = request.GetData<Vector3>().ToArray();
for (int i = 0; i < matrixs.Length; ++i)
{
matrixs[i] = Matrix4x4.TRS(resultPositions[i], Quaternion.identity, Vector3.one * 0.5f);
}
}
private void OnDestroy()
{
depthRT.Release();
resultBuffer.Release();
}
}
