VM虚拟机 - Docker - CentOS 7 - 快速使用Docker从零搭建Hadoop完全分布式集群详细教程(亲测有效,※吐血推荐※)(内含快速启动容器脚本)
目录
- 阅读须知
- 最小安装(可跳)
- 安装VMware Tool(可直接安装)
- 关闭防火墙和Selinux
- 安装docker
- 迁移docker安装目录
- docker安装CentOS 7
- 安装必要工具
- 安装Java和Scala
- 安装Hadoop
- 编写脚本
- 启动集群
- Windows连接容器
- 测试集群
- 关闭集群
- 编写快速启动容器脚本
- 安装MySQL
- 安装Hive
- 安装ZooKeeper
- 安装Kafka
- 安装Spark(Standalone)
- 动态添加端口映射
- 遇到的问题
- 附录:常见框架端口
- 参考博客
阅读须知
- 为什么用 docker 搭建 hadoop 集群呢?虚拟机超级超级慢,一开始可以带三台虚拟机,慢慢的连一台都慢死了。一怒之下干脆从零再用 docker 搭一个集群算了。除了开始的一些步骤图形化界面是不用操作的,接下来的操作都一样,大部分坑我都走了,好多操作我都从头执行了好几遍,直接复制即可。
虚拟机-Linux-CentOS 7吐血安装Hadoop2.9.2搭建集群教程(详细图解)
- 本博客采用最小安装。一开始我是安装了图形化界面(KDE),由于在 docker 里面不能直接使用
systemctl,如果直接 docker run 会报错:Failed to get D-Bus connection: Operation not permitted。解决方法是在创建容器时加上--privileged和/usr/sbin/init。但是我只要一执行就会跳出图形化界面,进入一个命令行界面,然后就回不去了!!!我以为是 CentOS 版本的问题,用最新版也一样,这个问题困扰了我好久都没解决。一怒之下干脆不要图形化界面了,直接最小安装算了,还没这么卡。但是还是会跳转界面,后来我直接用 XShell 控制虚拟机,懒得看它了。

- 像 Java、Scala、Hadoop、Hive、Spark 这些东西都是从官网下个 tar 包,再继续操作。所以需要用到共享文件夹。


- 集群配置,所以弄三个容器
| - | master | slave1 | slave2 |
|---|---|---|---|
| HDFS | NameNode DataNode |
DataNode | SecondaryNameNode DataNode |
| Yarn | NodeManager | ResourceManager NodeManager |
NodeManager |
- 过程中适当拍摄快照

- 每一步都很关键!!!
Ctrl C + Ctrl V 走起
最小安装(可跳)
安装虚拟机和CentOS的过程:略
-
用 ip addr 查看 IP,接下来的操作都在 XShell
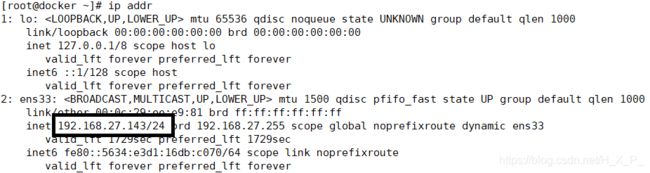
-
安装必要的工具
yum -y install vim #编辑器
yum -y install net-tools #ifconfig
yum -y install httpd
yum -y install wget
yum -y install iproute
yum -y install lsof
yum -y install bash-completion #tab补全
yum -y install gcc gcc-c++ autoconf pcre pcre-devel make automake #gcc
#yum -y update #升级
#yum -y install kernel-devel #升级kernel-devel
#yum -y install kernel-headers
- 修改 /etc/vimrc 文件,防止中文乱码,vim /etc/vimrc,添加如下代码

set encoding=utf-8
set termencoding=utf-8
set fileencodings=utf-8
- 如果想格式化JSON可以在 /etc/vimrc 加上下面的代码:
command! JsonFormat :execute '%!python -m json.tool'
\ | :execute '%!python -c "import re,sys;chr=__builtins__.__dict__.get(\"unichr\", chr);sys.stdout.write(re.sub(r\"\\u[0-9a-f]{4}\", lambda x: chr(int(\"0x\" + x.group(0)[2:], 16)).encode(\"utf-8\"), sys.stdin.read()))"'
\ | :set ft=javascript
\ | :
打开json文件,输入:
:JsonFormat
详解Linux安装GCC方法
vmware + centos 7安装vmtools时提示The path “” is not a valid path to the xxx kernel header
VMware下CentOS7最小化安装及配置
CentOS 7 最小化安装后的注意事项及一些必备组件的安装
CentOS7最小化安装-Linux-1
Linux最小化安装后一般需要安装的命令的rpm包合集
让VIM彻底告别乱码
VIM中格式化json
安装VMware Tool(可直接安装)
- 在虚拟机菜单栏中点击 虚拟机 -> 安装 VMware Tools
- 创建挂载目录:mkdir /mnt/cdrom
- 将光驱挂载到/mnt/cdrom目录:mount /dev/cdrom /mnt/cdrom
- 将压缩包拷贝到其它地方:cp /mnt/cdrom/VMwareTools-10.3.2-9925305.tar.gz /opt
- 解压:tar -zxvf /opt/VMwareTools-10.3.2-9925305.tar.gz -C /opt
- 进入解压出来的目录:cd /opt/vmware-tools-distrib
- 安装:./vmware-install.pl。这一步可能会遇到问题:bash:./vmware-install.pl :/usr/bin/perl:bad interpreter:No such file or directory。输入 yum groupinstall “Perl Support” 即可。
- 卸载光驱:umount /dev/cdrom
Linux VMware Tools安装步骤简易版
CentOS-7 最小安装VMware-tools
在 Linux 虚拟机中手动安装 VMware Tools
关闭防火墙和Selinux
输入 systemctl status firewalld.service 查看防火墙状态输入 systemctl stop firewalld.service 关闭防火墙输入 systemctl disable firewalld.service 关闭防火墙自启- 输入 vim /etc/sysconfig/selinux,将 SELINUX=enforcing 改为 SELINUX=disabled
安装docker
- 卸载已安装的较旧的 Docker 以及相关的依赖项。
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engin
- 安装所需的软件包。yum-utils 提供了 yum-config-manager ,并且 device mapper 存储驱动程序需要 device-mapper-persistent-data 和 lvm2。
yum install -y yum-utils \
device-mapper-persistent-data \
lvm2
- 设置仓库源
yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
- 安装最新版本的 Docker Engine-Community 和 containerd
yum -y install docker-ce docker-ce-cli containerd.io
-
启动docker 服务:systemctl start docker
-
检测 docker 版本:docker version

-
停止docker服务:systemctl stop docker
-
修改镜像源:vim /etc/docker/daemon.json
{
"registry-mirrors": [
"https://registry.aliyuncs.com",
"https://hub-mirror.c.163.com",
"https://registry.docker-cn.com",
"https://docker.mirrors.ustc.edu.cn"
]
}
迁移docker安装目录
docker镜像容器目录默认存放在 /var/lib/docker,担心后期数据量大导致系统盘空间不足,现把它迁移到其它地方。我有一次好不容易装好了,提示我磁盘空间不足,vim 都用不了了。

- 通过 df -h 看下磁盘大概的情况,找一个大的空间
- 创建新目录作为docker的新目录:mkdir -p /opt/docker
- 迁移数据:cp -r /var/lib/docker/ /opt/docker
- 修改 docker.service:vim /lib/systemd/system/docker.service,在 ExecStart 后面添加 --data-root /opt/docker
- systemctl daemon-reload
- 重启 docker 服务:systemctl start docker
- 查看默认路径是否已修改:docker info | grep " Root Dir",如果修改了会提示这样:Docker Root Dir: /opt/docker
- 通过运行 hello-world 映像来验证是否正确安装了 Docker Engine-Community 。
docker run hello-world

- 删除原目录数据:rm -rf /var/lib/docker
attempt to change docker data-root fails - why
两种方式迁移 Docker 的默认安装 (存储) 目录
docker的/var/lib/docker目录迁移
docker镜像容器目录迁移
docker安装CentOS 7
- 拉取指定版本的 CentOS 镜像
docker pull centos:centos7

2. 查看本地镜像
docker images

- run 运行容器,然后可以通过 exec 命令进入 CentOS 容器。注意两个地方
--privileged,/usr/sbin/init,这样你才能使用systemctl
docker run -itd --privileged -h base --name base centos:centos7 /usr/sbin/init
docker exec -it 77b6c963033b /bin/bash

安装必要工具
- 分别安装 vim、net-tools、iputils-ping 等
yum -y install vim #编辑器
yum -y install net-tools #ifconfig
yum -y install iputils-ping #ping
yum -y install httpd
yum -y install iproute
yum -y install lsof
yum -y install wget
yum -y install rsync #同步数据
yum -y install bash-completion #tab补全
yum -y install gcc gcc-c++ autoconf pcre pcre-devel make automake #gcc
yum -y install openssh-server #ssh
yum -y install openssh-clients #ssh
systemctl start sshd.service #启动 ssh 服务
systemctl enable sshd.service #设置 ssh 开机启动
systemctl start rsyncd.service #启动 rsync 服务
systemctl enable rsyncd.service
- 修改 /etc/vimrc 文件,防止中文乱码,vim /etc/vimrc,添加如下代码
set encoding=utf-8
set termencoding=utf-8
set fileencodings=utf-8
-
vim /etc/ssh/sshd_config,将PermitRootLogin,PubkeyAuthentication 的设置打开。
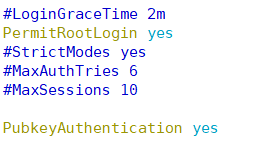
-
为了保证系统启动的时候也启动 ssh 服务,我们将启动命令放到bashrc文件末尾中:systemctl start sshd.service
vim ~/.bashrc
- 这一步很狠猩狼关键:passwd。输入你的密码,后面 ssh 登录要用!!!
安装Java和Scala
- 在主机将 JDK 和 Scala 复制到容器的 /opt 目录
docker cp /mnt/hgfs/share/jdk-8u241-linux-x64.tar.gz def8faf07d6b:/opt
docker cp /mnt/hgfs/share/scala-2.12.12.tgz def8faf07d6b:/opt
- 解压压缩包到 /opt,并重命名
tar -zxvf /opt/jdk-8u241-linux-x64.tar.gz -C /opt
mv /opt/jdk1.8.0_241 /opt/jdk-1.8.0
tar -zxvf /opt/scala-2.12.12.tgz -C /opt
- 更改文件的所有者和所在组:chown -R root:root /opt/jdk-1.8.0 && chown -R root:root /opt/scala-2.12.12
- 设置环境变量 vim /etc/profile,在末尾添加
#JAVA
export JAVA_HOME=/opt/jdk-1.8.0
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
#Scala
export SCALA_HOME=/opt/scala-2.12.12
#PATH
export PATH=$PATH:${JAVA_HOME}/bin:${SCALA_HOME}/bin
- source /etc/profile && java -version && scala -version 查看 Java 和 Scala 是否配置成功

- 输入 vim ~/.bashrc,加上 source /etc/profile
- 记得删除压缩包
安装Hadoop
- 在主机将 Hadoop 复制到容器的 /opt 目录
docker cp /mnt/hgfs/share/hadoop-2.9.2.tar.gz def8faf07d6b:/opt
- 解压压缩包到 /opt
tar -zxvf /opt/hadoop-2.9.2.tar.gz -C /opt
- 更改文件的所有者和所在组:chown -R root:root /opt/hadoop-2.9.2
- 配置 core-site.xml($HADOOP_HOME/etc/hadoop/下)fs.default.name 为默认的master节点。hadoop.tmp.dir为hadoop默认的文件路径。如果本机没有的话需要自己通过 mkdir 命令进行创建。
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/hadoop-2.9.2/data/tmpvalue>
property>
- 创建上面的文件目录:mkdir -p /opt/hadoop-2.9.2/data/tmp
- 输入 vim etc/hadoop/hadoop-env.sh,修改 JAVA_HOME 变量,将其改为Java的安装目录($HADOOP_HOME/etc/hadoop/下)
- 配置 hdfs-site.xml($HADOOP_HOME/etc/hadoop/下)
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>slave2:50090value>
property>
- 输入 vim etc/hadoop/yarn-env.sh,修改 JAVA_HOME 变量,将其改为Java的安装目录
- 配置 yarn-site.xml($HADOOP_HOME/etc/hadoop/下)
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>slave1value>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>slave1:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>slave1:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>slave1:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>slave1:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>slave1:8088value>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
- 输入 vim etc/hadoop/mapred-env.sh,修改 JAVA_HOME 变量,将其改为Java的安装目录($HADOOP_HOME/etc/hadoop/下)
- 输入 mv etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml,将mapred-site.xml.template 重命名为 mapred-site.xml
- 配置 mapred-site.xml($HADOOP_HOME/etc/hadoop/下)
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master:19888value>
property>
- 在master节点配置 $HADOOP_HOME/etc/hadoop/ 下的slaves文件,输入 vim etc/hadoop/slaves(注意不能有空格和空行!!!)删掉 localhost,改为下面
master
slave1
slave2
编写脚本
- xcall 在所有主机上同时执行相同的命令:vim /usr/local/bin/xcall
用法:xcall jps
#!/bin/bash
pcount=$#
if((pcount==0));then
echo "Error: No args...";
exit;
fi
# 获取当前主机名
hostname=`hostname`
# 同步到集群其它机器
for target in `cat /opt/hadoop-2.9.2/etc/hadoop/slaves`
do
echo ==================$target==================
if [ "$target" != "$hostname" ];then
ssh $target $@
else
$@
fi
done
- xsync 循环复制文件到所有节点的相同目录下:vim /usr/local/bin/xsync
用法:xsync /opt/hadoop-2.9.2/etc
rsync主要用于备份和镜像,具有速度快、避免复制相同内容和支持符号链接的优点。rsync和scp的区别是,rsync只对差异文件更改,scp是将所有文件复制。
#!/bin/sh
# 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0));then
echo "Error: No args...";
exit;
fi
# 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
# 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
# 获取当前用户名称
user=`whoami`
# 获取当前主机名
hostname=`hostname`
# 同步到集群其它机器
for target in `cat /opt/hadoop-2.9.2/etc/hadoop/slaves`
do
if [ "$target" != "$hostname" ];then
echo "$pdir/$fname->$user@$target:$pdir"
echo ==================$target==================
rsync -rvl $pdir/$fname $user@$target:$pdir
fi
done
rsync -rvl $pdir/$fname $user@$host:$pdir/$fname
命令 参数 要复制的文件路径/名称 目的用户@主机名:目的路径/名称
- 修改权限:chmod a+x /usr/local/bin/xcall && chmod a+x /usr/local/bin/xsync。u:表示用户,g:表示用户组,o: 表示其它,a: 表示所有
- jps 建立软连接:ln -sf /opt/jdk-1.8.0/bin/jps /usr/local/bin/

- 退出容器并停止容器:exit,docker stop 容器ID
Hadoop集群脚本工具rsync、xsync和xcall
简单教你写xsync和xcall的脚本
centos7搭建hadoop集群之xcall脚本
Shell $0, $#, $*, $@, $?, $$的含义
启动集群
- 将刚才的容器导出为镜像,并查看当前镜像
docker commit -m "hadoop" -a "hxp" def8faf07d6b hxp/hadoop:1.0

- 为了集群间可以通信,自定义网络
docker network create --driver=bridge --subnet=172.18.0.0/16 hadoop-net
- 创建3个容器,master,slave1,slave2。注意数据卷的目录是一个新的空目录,如果目录内有数据会被覆盖。这里固定 IP。
docker run -itd -h master --name master --network hadoop-net --privileged -v /opt/docker:/opt/docker --ip 172.18.0.2 -p 2181:2181 -p 3306:3306 -p 4040:4040 -p 7077:7077 -p 8080:8080 -p 8081:8081 -p 9000:9000 -p 9092:9092 -p 10000:10000 -p 18080:18080 -p 29094:29094 -p 50070:50070 -p 8088:8088 hxp/hadoop:1.0 /usr/sbin/init
docker run -itd -h slave1 --name slave1 --network hadoop-net --privileged -v /opt/docker:/opt/docker --ip 172.18.0.3 hxp/hadoop:1.0 /usr/sbin/init
docker run -itd -h slave2 --name slave2 --network hadoop-net --privileged -v /opt/docker:/opt/docker --ip 172.18.0.4 hxp/hadoop:1.0 /usr/sbin/init
![]()
-
在 master 节点 ping 其他节点检测是否正常

-
在 master 节点的家目录(cd ~)输入 ssh-keygen -t rsa 生成公钥和私钥(中间按三个Enter),然后依次输入 ssh-copy-id master,ssh-copy-id slave1,ssh-copy-id slave2(交换公钥)。这些操作分别在 slave1 和 slave2 做一次。(密码不正确的想一想是不是上面漏了一个很关键的地方)(logout 退出 ssh)

-
在每个节点设置时间(东八区),我这里原本是 UTC,所以要设为 CST
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
Linux —— 时间(tzselect、timedatactl命令,查看和修改时区,修改时区为东八区)
-
进入Hadoop安装目录,格式化 NameNode:bin/hdfs namenode -format

-
编写启动和停止集群脚本 start-cluster.sh,stop-cluster.sh。vim /usr/local/bin/start-cluster.sh,vim /usr/local/bin/stop-cluster.sh
#!/bin/sh
/opt/hadoop-2.9.2/sbin/start-dfs.sh
ssh slave1 /opt/hadoop-2.9.2/sbin/start-yarn.sh
#!/bin/sh
/opt/hadoop-2.9.2/sbin/stop-dfs.sh
ssh slave1 /opt/hadoop-2.9.2/sbin/stop-yarn.sh
-
chmod a+x /usr/local/bin/start-cluster.sh && chmod a+x /usr/local/bin/stop-cluster.sh
-
在 master 节点启动集群:start-cluster.sh

-
xcall jps,如果出现 jps not found:source /etc/profile

-
输入 bin/hdfs dfsadmin -report 查看HDFS状态
[root@master hadoop-2.9.2]# bin/hdfs dfsadmin -report
Configured Capacity: 204447940608 (190.41 GB)
Present Capacity: 186659966976 (173.84 GB)
DFS Remaining: 186659942400 (173.84 GB)
DFS Used: 24576 (24 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (3):
Name: 172.18.0.2:50010 (master)
Hostname: master
Decommission Status : Normal
Configured Capacity: 68149313536 (63.47 GB)
DFS Used: 8192 (8 KB)
Non DFS Used: 5929324544 (5.52 GB)
DFS Remaining: 62219980800 (57.95 GB)
DFS Used%: 0.00%
DFS Remaining%: 91.30%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Nov 05 03:11:08 UTC 2020
Last Block Report: Thu Nov 05 02:52:23 UTC 2020
Name: 172.18.0.3:50010 (slave1.hadoop-net)
Hostname: slave1
Decommission Status : Normal
Configured Capacity: 68149313536 (63.47 GB)
DFS Used: 8192 (8 KB)
Non DFS Used: 5929324544 (5.52 GB)
DFS Remaining: 62219980800 (57.95 GB)
DFS Used%: 0.00%
DFS Remaining%: 91.30%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Nov 05 03:11:08 UTC 2020
Last Block Report: Thu Nov 05 02:52:23 UTC 2020
Name: 172.18.0.4:50010 (slave2.hadoop-net)
Hostname: slave2
Decommission Status : Normal
Configured Capacity: 68149313536 (63.47 GB)
DFS Used: 8192 (8 KB)
Non DFS Used: 5929324544 (5.52 GB)
DFS Remaining: 62219980800 (57.95 GB)
DFS Used%: 0.00%
DFS Remaining%: 91.30%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Nov 05 03:11:08 UTC 2020
Last Block Report: Thu Nov 05 02:52:23 UTC 2020
https://blog.csdn.net/u012943767/article/details/79767670
docker设置容器固定ip
Docker 配置容器固定IP
docker 创建容器时指定容器ip
Windows连接容器
|----------------------------------------|
| |
| |--------------------------------| |
| | | |
| | docker(CentOS) 172.18.0.2 | |
| |--------------------------------| |
| |
| Virtual Machine(CentOS) 192.168.27.143 |
|----------------------------------------|
Windows 192.168.137.123
由于 docker 容器处于内网,外网不可以直接访问内网,需要添加路由进行转发。当然也可以端口映射,但添加端口有点麻烦。
route add 将发送到 172.18.0.0/16 网段的数据有 192.168.27.143(具体IP) 来转发。(Ifconfig查看,-p永久)
route add -p 172.18.0.0 mask 255.255.0.0 192.168.27.143
道理都懂,找个中间人传递信息嘛,理论上是没问题的。可是为啥我就是 windows ping 不通 docker?这里我搞了好久,最终还是重头再装一次问题才解决(同样的操作,竟然神奇的通了。。。)
大家可以尝试打开并启动防火墙,然后在关闭防火墙,我有一次就是这样好了,也不知道为什么
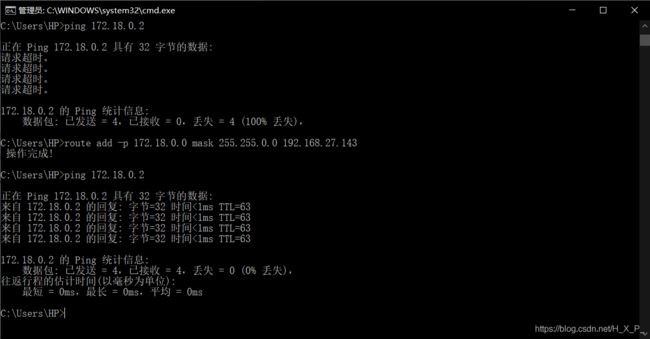
Windows连接Linux虚拟机里面的Docker容器
在Windows系统浏览器中访问虚拟机CentOS里面Docker容器运行nginx服务器
解决 docker 容器无法通过 IP 访问宿主机问题
在Windows宿主机中连接虚拟机中的Docker容器
Windows连接虚拟机里面的Docker容器ip
在Windows宿主机中连接虚拟机中的Docker容器总结
测试集群
-
在浏览器输入 http://master:50070/,检查 Datanode Information(有可能出现DataNode不够三个)


-
在浏览器输入 http://slave1:8088/
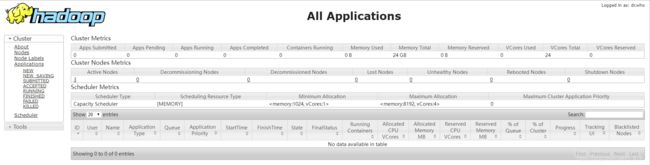
-
运行 WordCount:
- mkdir wcinput && vim wcinput/wc.input
- 在刚创建的文件写下
touch touch
window window
sun sun sun sun sun
phone
hadoop hadoop hadoop - 上传文件到 HDFS:bin/hdfs dfs -put wcinput/wc.input /
- 运行 WordCount:bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wc.input /output

关闭集群
关闭集群:stop-cluster.sh

出现:nodemanager did not stop gracefully after 5 seconds: killing with kill -9
好吧,这个问题我没解决,不过这个问题影响不大,我就不理它了。大伙有兴趣可以自行解决。我把原因和解决方法贴下面:
原因:原因在 hadoop-daemon.sh 找不到pid文件了,pid文件默认存放在 /tmp,而系统会定时清理该目录中的文件
解决:
- 确保关闭了集群
- 修改 hadoop 安装目录下的 sbin/hadoop-daemon.sh 的第 26 行

- 修改 hadoop 安装目录下的 sbin/yarn-daemon.sh 的第 26 行

- mkdir /opt/hadoop-2.9.2/pid
- 同步到其它集群:xsync /opt/hadoop-2.9.2/sbin

NodeManager did not stop gracefully after 5 seconds: kill
NodeManager did not stop gracefully after 5 seconds: kill
#docker cp /mnt/hgfs/share/kafka_2.12-2.6.0.tgz def8faf07d6b:/opt
#docker cp /mnt/hgfs/share/apache-flume-1.9.0-bin.tar.gz def8faf07d6b:/opt
#docker cp /mnt/hgfs/share/apache-hive-2.3.7-bin.tar.gz def8faf07d6b:/opt
编写快速启动容器脚本
效果如下:

#!/bin/bash
pcount=$#
#没有参数则退出程序
if((pcount==0));then
echo "Error: No args...";
exit;
fi
i=0
#docker集群数组
array=("master" "slave1" "slave2")
#启动docker
case $1 in
"start"){
systemctl stop firewalld
#开启docker服务
systemctl start docker
#将容器历史运行记录写到一个临时文件
docker ps -a | sed '1d' > /tmp/dockerPs
#循环读取运行记录的每一行
while read line
do
for target in ${array[*]}
do
#判断该行是否包含对应的容器
result=`echo "$line" | grep "$target"`
if [ "$result" != "" ];then
#如果包含则取该行记录空格隔开的第一个字符串
container_id=`echo $line | awk -F " " '{print $1}'`
#启动容器并打印日志
echo ==========start ${target}, container_id=`docker start ${
container_id}`===========
#下一个容器
let i++
fi
done
#全部容器启动完了就跳出循环
if [ $i -eq ${#array[*]} ];then
break
fi
done < /tmp/dockerPs
echo " "
docker ps
};;
"stop"){
while read line
do
for target in ${array[*]}
do
result=`echo "$line" | grep "$target"`
if [ "$result" != "" ];then
container_id=`echo $line | awk -F " " '{print $1}'`
echo ==========stop ${target}, container_id=`docker stop ${
container_id}`==========
let i++
fi
done
if [ $i -eq ${#array[*]} ];then
break
fi
done < /tmp/dockerPs
#删除临时文件
rm -rf /tmp/dockerPs
echo " "
docker ps
#睡眠15秒,如果发现异常则可以退出
sleep 15s
#停止服务
systemctl stop docker
echo " "
systemctl status docker
};;
esac
shell 判断字符串包含的5种方法
shell 数组遍历的3种方法
shell变量计算长度及加减运算方法总结
shell脚本中大于,大于等于,小于,小于等于、不等于的表示方法
shell读取文件每一行的方式
shell字符串空格分隔取第一个_shell按空格分隔字符串
安装MySQL
Linux-VMware15下CentOS 7安装MySQL5.7.28(tar.gz)
安装Hive
Linux-CentOS 7-基于Hadoop安装与配置Hive-2.3.7
安装ZooKeeper
- 在主机将 ZooKeeper 复制到容器的 /opt 目录
docker cp /mnt/hgfs/share/zookeeper-3.4.14.tar.gz def8faf07d6b:/opt
- 解压压缩包到 /opt
tar -zxvf /opt/zookeeper-3.4.14.tar.gz -C /opt
- 更改文件的所有者和所在组:chown -R root:root /opt/zookeeper-3.4.14
- 进入 ZooKeeper 目录,复制 zoo-sample.cfg 重命名为 zoo.cfg:cp conf/zoo_sample.cfg conf/zoo.cfg。这个名字固定写死,因为zookeeper启动会检查这个文件,根据这个配置文件里的信息来启动服务。
dataDir:指定zookeeper将数据保存在哪个目录下,如果不修改,默认在/tmp下,这个目录下的数据有可能会在磁盘空间不足或服务器重启时自动被linux清理,所以一定要修改这个地址。
加上 ZooKeeper 各个节点的 IP 和端口,2888原子广播端口,3888选举端口,zookeeper有几个节点,就配置几个server。

dataDir=/opt/zookeeper-3.4.14/data
dataLogDir=/opt/zookeeper-3.4.14/dataLog
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
- 创建刚才指定的两个目录:mkdir data dataLog
- 在 dataDir 目录下生产一个 myid 文件,其中写上一个数字 X 表明当前机器是哪一个编号的机器(就是刚才的server.X)。
- 同步:xsync /opt/zookeeper-3.4.14
- 修改 slave1 和 slave2 的 myid
- 建立脚本 zkServer:vim /usr/local/bin/zkServer,zkClient:vim /usr/local/bin/zkClient
#!/bin/bash
pcount=$#
if((pcount==0));then
echo "Error: No args...";
exit;
fi
# 获取当前主机名
hostname=`hostname`
for target in `cat /opt/hadoop-2.9.2/etc/hadoop/slaves`
do
echo ==================$target==================
if [ "$target" != "$hostname" ];then
ssh $target /opt/zookeeper-3.4.14/bin/zkServer.sh $@
else
/opt/zookeeper-3.4.14/bin/zkServer.sh $@
fi
done
#!/bin/bash
/opt/zookeeper-3.4.14/bin/zkCli.sh
- chmod a+x /usr/local/bin/zkServer && chmod a+x /usr/local/bin/zkClient
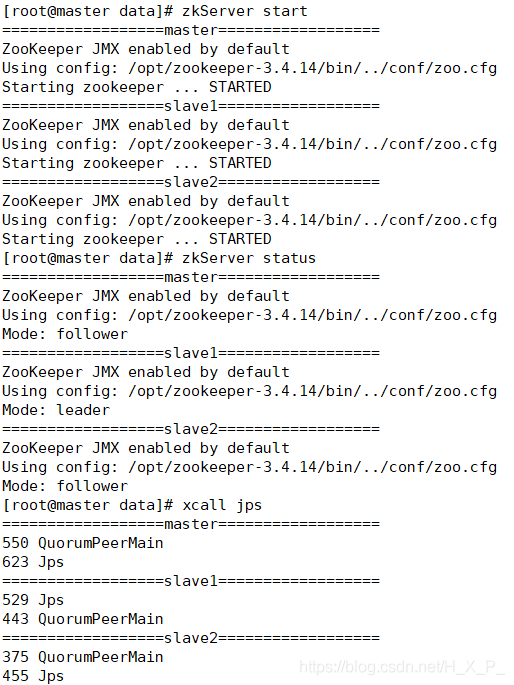
- 在各个节点启动 ZooKeeper,再查看 ZooKeeper 状态
#启动ZK服务:
bin/zkServer.sh start
#停止ZK服务:
bin/zkServer.sh stop
#重启ZK服务:
bin/zkServer.sh restart
#查看ZK服务状态:
bin/zkServer.sh status
Zookeeper完全分布式集群的搭建
Linux安装zookeeper集群(CentOS7+Zookeeper3.4.10)
zookeeper 集群搭建
Zookeeper系列一:Zookeeper基础命令操作
遇到的问题:
- 查看 zookeeper.out 报错:nohup: failed to run command `java’: No such file or directory。
解决方法:在 ~/.bashrc 加上 source /etc/profile,这样每次系统启动都会执行这个指令。 - 找不到 myid,解决方法是在 dataDir 目录下生产一个 myid 文件
org.apache.zookeeper.server.quorum.QuorumPeerConfig$ConfigException: Error processing /opt/zookeeper-3.4.14/bin/../conf/zoo.cfg
at org.apache.zookeeper.server.quorum.QuorumPeerConfig.parse(QuorumPeerConfig.java:156)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:104)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:81)
Caused by: java.lang.IllegalArgumentException: /opt/zookeeper-3.4.14/data/myid file is missing
at org.apache.zookeeper.server.quorum.QuorumPeerConfig.parseProperties(QuorumPeerConfig.java:408)
at org.apache.zookeeper.server.quorum.QuorumPeerConfig.parse(QuorumPeerConfig.java:152)
... 2 more
Invalid config, exiting abnormally
为什么每次进入命令都要重新source /etc/profile 才能生效?
myid文件缺失导致zookeeper无法启动(myid file is missing)
zookeeper环境搭建中的几个坑[Error contacting service. It is probably not running]的分析及解决
解决zookeeper集群重启 Error contacting service. It is probably not running 问题
安装Kafka
- 在主机将 Kafka 复制到容器的 /opt 目录
docker cp /mnt/hgfs/share/kafka_2.12-2.6.0.tgz def8faf07d6b:/opt
- 解压压缩包到 /opt,更改文件的所有者和所在组并重命名
tar -zxvf /opt/kafka_2.12-2.6.0.tgz -C /opt
chown -R root:root /opt/kafka_2.12-2.6.0
mv /opt/kafka_2.12-2.6.0 /opt/kafka-2.6.0
- 修改 vim /opt/kafka-2.6.0/config/server.properties
broker.id=1
#listeners=PLAINTEXT://master:9092
log.dirs=/opt/kafka-2.6.0/data
zookeeper.connect=master:2181,slave1:2181,slave2:2181
- 创建目录:mkdir /opt/kafka-2.6.0/data
- 同步:xsync /opt/kafka-2.6.0
- 修改 slave1 和 slave2 的 server.properties 的 broker.id
- 编写脚本:kafkaServer:vim /usr/local/bin/kafkaServer
#!/bin/bash
pcount=$#
if((pcount==0));then
echo "Error: No args...";
exit;
fi
# 获取当前主机名
hostname=`hostname`
case $1 in
"start"){
for target in `cat /opt/hadoop-2.9.2/etc/hadoop/slaves`
do
echo ==================$target==================
if [ "$target" != "$hostname" ];then
ssh $target /opt/kafka-2.6.0/bin/kafka-server-start.sh -daemon /opt/kafka-2.6.0/config/server.properties
else
/opt/kafka-2.6.0/bin/kafka-server-start.sh -daemon /opt/kafka-2.6.0/config/server.properties
fi
done
};;
"stop"){
for target in `cat /opt/hadoop-2.9.2/etc/hadoop/slaves`
do
echo ==================$target==================
if [ "$target" != "$hostname" ];then
ssh $target /opt/kafka-2.6.0/bin/kafka-server-stop.sh
else
/opt/kafka-2.6.0/bin/kafka-server-stop.sh
fi
done
};;
esac
-
chmod a+x /usr/local/bin/kafkaServer
-
启动 Kafka:kafkaServer start

-
创建主题(注意:副本数不能超过节点数,同一个节点两个副本没意义):bin/kafka-topics.sh --create --zookeeper master:2181 --replication-factor 2 --partitions 3 --topic test
-
查看主题列表:bin/kafka-topics.sh --list --zookeeper master:2181
-
查看主题详细信息:bin/kafka-topics.sh --describe --zookeeper master:2181 --topic test


-
运行 producer 并发送信息:bin/kafka-console-producer.sh --broker-list master:9092 --topic test
This is a message
This is another message -
运行 consumer 并接收信息:bin/kafka-console-consumer.sh --bootstrap-server master:9092 --topic test --from-beginning(启动多个 consumer 也可以接收消息)

kafka中文教程
Kafka常用命令
安装Spark(Standalone)
- 在主机将 Kafka 复制到容器的 /opt 目录
docker cp /mnt/hgfs/share/spark-3.0.0-bin-hadoop2.7.tgz def8faf07d6b:/opt
- 解压压缩包到 /opt,更改文件的所有者和所在组并重命名
tar -zxvf /opt/spark-3.0.0-bin-hadoop2.7.tgz -C /opt
chown -R root:root /opt/spark-3.0.0-bin-hadoop2.7
mv /opt/spark-3.0.0-bin-hadoop2.7 /opt/spark-3.0.0
-
进入 spark 目录并将 conf 下的 slaves.template 改为 slaves:mv conf/slaves.template conf/slaves,vim conf/slaves 将 localhost 修改如下
master slave1 slave2 -
将 conf 目录下的 spark-env.sh.template 改为 spark-env.sh:mv conf/spark-env.sh.template conf/spark-env.sh,vim conf/spark-env.sh 修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点
export JAVA_HOME=/opt/jdk-1.8.0 SPARK_MASTER_HOST=master SPARK_MASTER_PORT=7077 export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=file:///opt/spark-3.0.0/directory -Dspark.history.retainedApplications=7" -
修改 conf 目录下的 spark-defaults.conf.template 为 spark-defaults.conf:mv conf/spark-defaults.conf.template conf/spark-defaults.conf,修改 spark-default.conf 文件,配置日志存储路径:vim conf/spark-defaults.conf
spark.eventLog.enabled true spark.eventLog.dir file:///opt/spark-3.0.0/directory -
创建目录:mkdir /opt/spark-3.0.0/directory
-
同步:xsync /opt/spark-3.0.0
-
启动:sbin/start-all.sh,sbin/start-history-server.sh,jps 查看

-
执行任务测试
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://master:7077 \ ./examples/jars/spark-examples_2.12-3.0.0.jar \ 10

10. http://master:8080/ 和 http://master:18080/ 分别查看


连接外部部署好的 Hive:
- 把 ${HIVE_HOME}/conf/hive-site.xml 拷贝到 ${SPARK_HOME}/conf/ 目录下
- 将 mysql-connector-java-5.1.48-bin.jar 驱动放到 ${SPARK_HOME}/jars/ 目录下
- 如果访问不到 HDFS,则需要把 ${HIVE_HOME}/conf/core-site.xml 和 ${HIVE_HOME}/conf/hdfs-site.xml 拷贝到 ${SPARK_HOME}/conf/目录下
- 启动 ${SPARK_HOME}/bin/spark-sql

IDEA 连接 Spark 操作 Hive:
- 导入依赖
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.12artifactId>
<version>3.0.0version>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>2.3.7version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.48version>
dependency>
- 将 hive-site.xml 文件拷贝到项目的 resources 目录中
- 代码验证连接是否成功
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object SQL {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL")
val spark: SparkSession = SparkSession.builder()
.enableHiveSupport() //<---------要加上这个
.config(conf).getOrCreate()
spark.sql("show databases").show
spark.close()
}
}
±--------------+
|namespace|
±--------------+
| default |
| study |
±--------------+
注意:在开发工具中创建数据库默认是在本地仓库,通过参数修改数据库仓库的地址:
config("spark.sql.warehouse.dir", "hdfs://master:8020/hive/warehouse")
如果遇到 HDFS 权限问题 Permission denied,可以代码最前面增加如下代码解决:
System.setProperty("HADOOP_USER_NAME", "root")
could only be replicated to 0 nodes instead of minReplication (=1). There are 1 datanode(s) running
解决方法:此时HDFS可以上传文件,说明不是HDFS的问题,关闭防火墙
动态添加端口映射
Docker动态添加端口映射方法总结【亲测有效】
在已运行的docker中增加映射端口
docker容器添加对外映射端口
遇到的问题
退出docker容器时出现there are stopped jobs如何解决?
Centos7 Docker容器中报错 Failed to get D-Bus connection: Operation not permitted
centos 下ssh命令找不到(-bash: ssh: command not found)
Can’t write viminfo file /*/.viminfo! 的解决办法
Docker 端口映射到宿主机后, 外部无法访问对应宿主机端口
附录:常见框架端口
大数据 默认各框架端口号(已给大佬么整理好,必知)
JAVA各种框架插件常用端口:redis、MySQL、rabbitmq、elasticsearch、tomcat等等
Hadoop集群的各部分常用端口
参考博客
基于 Docker 构建 Hadoop 平台
使用docker构建hadoop集群
Docker搭建Hadoop环境
Docker+Hadoop+Hive+Presto 使用Docker部署Hadoop环境和Presto
使用docker搭建hadoop分布式集群
基于Docker的Hadoop完全分布式安装
Docker安装Hadoop
使用Docker搭建Hadoop集群环境
基于docker的hadoop集群搭建
Docker 学习 | 第六篇:容器网络配置
docker设置容器固定ip
docker 创建容器时指定容器ip
如有错误,请指出哈─=≡Σ(((つ•̀ω•́)つ