python 爬虫框架_Python常用的爬虫框架、解析方式、存储方式对比
00 概况 以安居客杭州二手房信息为爬虫需求,分别对比实验了 三种爬虫框架、 三种字段解析方式和 三种数据存储方式,旨在全方面对比各种爬虫方式的效率高低。安居客平台没有太强的反爬措施,只要添加headers模拟头即可完美爬取,而且不用考虑爬虫过快的问题。选中杭州二手房之后,很容易发现url的变化规律。值得说明的是平台最大开放50页房源信息,每页60条。为使爬虫简单便于对比,我们只爬取房源列表页的概要信息,而不再进入房源详情页进行具体信息的爬取,共3000条记录, 每条记录包括10个字段: 标题,户型,面积,楼层,建筑年份,小区/地址,售卖标签,中介,单价, 总价 。Python爬虫的方式有多种,从爬虫框架到解析提取,再到数据存储,各阶段都有不同的手段和类库支持。虽然不能一概而论哪种方式一定更好,毕竟不同案例需求和不同应用场景会综合决定采取哪种方式,但对比之下还是会有很大差距。
01 3种爬虫框架
1. 常规爬虫
实现3个函数,分别用于解析网页、存储信息,以及二者的联合调用。在主程序中,用一个常规的循环语句逐页解析。
import requestsfrom lxml import etreeimport pymysqlimport timedef get_info(url):
passreturn infosdef save_info(infos):passdef getANDsave(url):
passif __name__ == '__main__':
urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1,51)]
start = time.time()#常规单线程爬取for url in urls:
getANDsave(url)
tt = time.time()-start
print("共用时:",tt, "秒。")耗时64.9秒。
2. Scrapy框架
Scrapy框架是一个常用的爬虫框架,非常好用,只需要简单实现核心抓取和存储功能即可,而无需关注内部信息流转,而且框架自带多线程和异常处理能力。
class anjukeSpider(scrapy.Spider):
name = 'anjuke'
allowed_domains = ['anjuke.com']
start_urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1, 51)]
def parse(self, response):
pass
yield item
耗时14.4秒。
3. 多线程爬虫
对于爬虫这种IO密集型任务来说,多线程可明显提升效率。实现多线程python的方式有多种,这里我们应用concurrent的futures模块,并设置最大线程数为8。
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
def get_info(url):
pass
return infos
def save_info(infos):
pass
def getANDsave(url):
pass
if __name__ == '__main__':
urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1,51)]
start = time.time()
executor = ThreadPoolExecutor(max_workers=8)
future_tasks = [executor.submit(getANDsave, url) for url in urls]
wait(future_tasks, return_when = ALL_COMPLETED)
tt = time.time()-start
print("共用时:",tt, "秒。")
耗时8.1秒。
对比来看,多线程爬虫方案耗时最短,相比常规爬虫而言能带来数倍的效率提升,Scrapy爬虫也取得了不俗的表现。需要指出的是,这里3种框架都采用了Xpath解析和MySQL存储。
02 3种解析方式 在明 确爬虫框架的基础上,如何对字段进行解析提取就是第二个需要考虑 的问题,常用的解 析方式有3种,一般而言,论解析效率Re>=Xpath>Bs4; 论难易程度,Bs4则最为简单易懂。 因为前面已经对比得知,多线程爬虫有着最好的执行效率,我们以此 为基础,对比3种不同解 析方式,解析函数分别为: 1. Xpath
from lxml import etreedef get_info(url):import redef get_info(url):from bs4
03 存储方式 在 完成爬虫数据解析后,一般都要将数据进行本地存储,方便后续使用。 小型数据量时可以选用本地文件存储,例如CSV、txt或者json文件; 当数据量较大时,则一般需采用数据库存储,这里,我们分别选用关系型数据库的代表MySQL和文本型数据库的代表MongoDB加入对比。 1. MySQL
import pymysql
def save_info(infos):
#####infos为列表形式,其中列表中每个元素为一个元组,包含10个字段
db= pymysql.connect(host="localhost",user="root",password="123456",db="ajkhzesf")
sql_insert = 'insert into hzesfmulti8(title, houseType, area, floor, buildYear, adrres, tags, broker, totalPrice, price) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
cursor = db.cursor()
cursor.executemany(sql_insert, infos)
db.commit()
import pymongo
def save_info(infos):
# infos为列表形式,其中列表中的每个元素为一个字典,包括10个字段
client = pymongo.MongoClient()
collection = client.anjuke.hzesfmulti
collection.insert_many(infos)
client.close()
import csv
def save_info(infos):
# infos为列表形式,其中列表中的每个元素为一个列表,包括10个字段
with open(r"D:\PyFile\HZhouse\anjuke.csv", 'a', encoding='gb18030', newline="") as f:
writer = csv.writer(f)
writer.writerows(infos)
04 结论
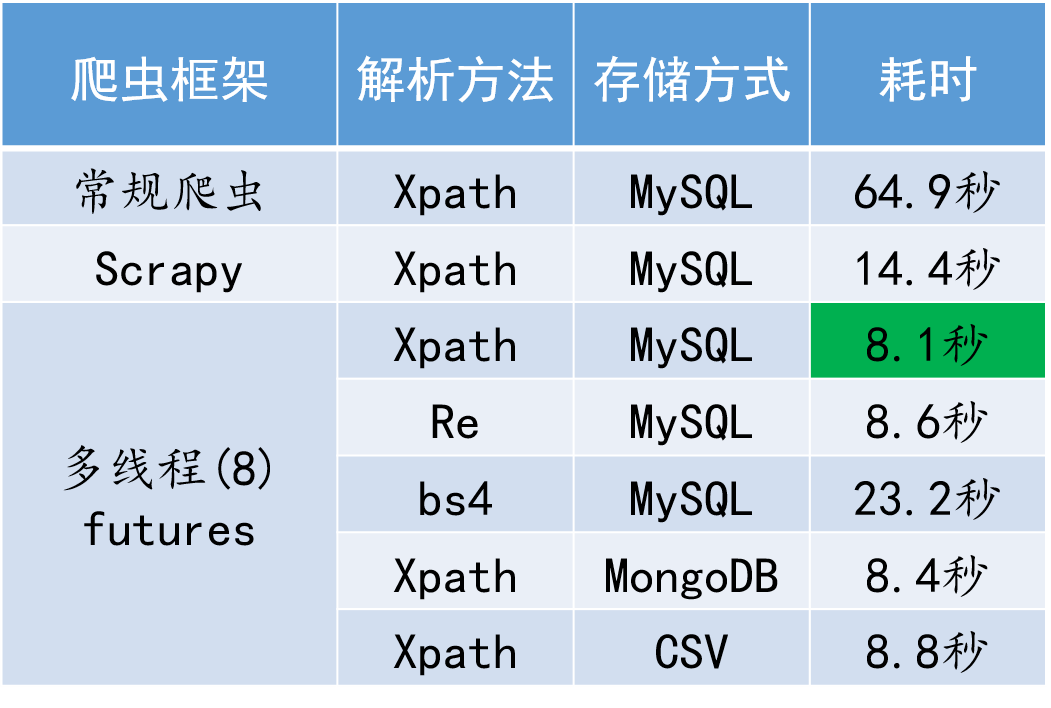
不同爬虫执行效率对比
易见,爬虫框架对耗时影响最大,甚至可带来数倍的效率提升;解析数据方式也会带来较大影响,而数据存储方式则不存在太大差异。对此,个人认为可以这样理解:类似于把大象装冰箱需要3步,爬虫也需要3步:网页源码爬取,
目标信息解析,
数据本地存储。
(完)
看完本文有收获?请转发分享给更多人
关注「Python那些事」,做全栈开发工程师

![]()
点「在看」的人都变好看了哦