Hadoop集群搭建及配置⑨——Hive 可靠的安装配置,远程连接MySQL
Hive安装
-
- 一、安装配置Hive
-
- 1.1 解压hive
- 1.2 配置环境变量(master 和 slave1)
- 1.3 配置 hive-env.sh
- 1.4 将hive复制到slave1中:
- 1.5 配置 hive-site.xml(slave1)
- 1.6 Hive与Mysql通信 (slave1)
-
- 1.6.1 maven配置下载mysql驱动器
- 1.7 解决版本冲突和jar包依赖问题 (master)
- 1.8 配置 hive-site.xml(master)
- 二、启动Hive
-
- 2.1 hive目录下启动Hive服务端(slave1)
- 2.2 hive 目录下启动 Hive客户端(master)
- 三、Hive 理论
-
- 3.1 Hive 的起源
- 3.2 数据仓库工具 Hive
- 3.3 hivae与hdfs、 hive元数据
- 3.4 Hive安装模式
Spark SQL:RDD、DataFrame、Dataset、反射推断机制 Schema 操作!!
Mysql+Hive:1、Centos7 MySQL安装 —— 用网盘简单安装
2、Hadoop集群搭建及配置⑨——Hive 可靠的安装配置
3、Spark SQ操作 MySQL数据库和 Hive数据仓库
4、Spark SQL RDD基本操作、RDD—DataFrame、API MySQL
云盘链接:https://pan.baidu.com/s/1u2TU5xhxLzv2GgENHdREuQ
提取码:z7pu
1、简单易懂,手把手带小白用VMware虚拟机安装Linux centos7系统
2、Hadoop集群搭建及配置〇 —— Hadoop组件获取 & 传输文件
3、Hadoop集群搭建及配置① —— 克隆节点
4、Hadoop集群搭建及配置② —— 网络IP配置,连接网络
5、Hadoop集群搭建及配置③ —— 基础环境搭建
6、Hadoop集群搭建及配置④ —— JDK简介及其安装
7、Hadoop集群搭建及配置⑤ —— Zookeeper 讲解及安装
8、Hadoop集群搭建及配置⑥ —— Hadoop组件安装及配置
9、Hadoop集群搭建及配置⑦—— Spark&Scala安装配置
10、Hadoop集群搭建及配置⑧——Hbase的安装配置
11、HDFS的 Java API编程配置
12、HDFS的 java API 编程实现基本功能
13、HBase API java表操作
一、安装配置Hive
1.1 解压hive
把Hive安装包apache-hive-2.1.1-bin 拖进shell 目录下
创建hive文件夹
mkdir -p /usr/hive
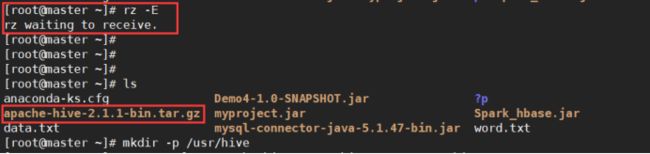
# 1.解压文件放在 /usr/hive目录下
tar zxvf ./apache-hive-2.1.1-bin.tar.gz -C /usr/hive/
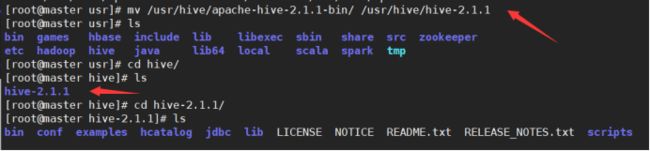
# 2.重命名hive解压文件
mv /usr/hive/apache-hive-2.1.1-bin/ /usr/hive/hive-2.1.1
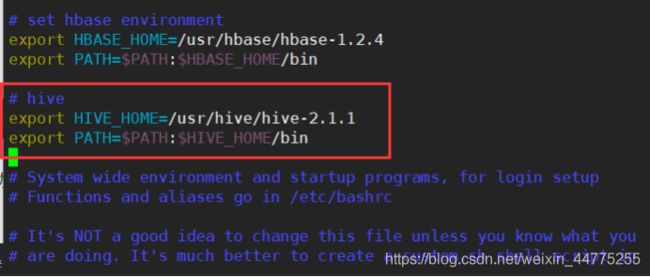
1.2 配置环境变量(master 和 slave1)
vim /etc/profile
# hive
export HIVE_HOME=/usr/hive/hive-2.1.1
export PATH=$PATH:$HIVE_HOME/bin
# 2.保存退出生效环境变量
source /etc/profile
查看hive是否安装成功 hive --version
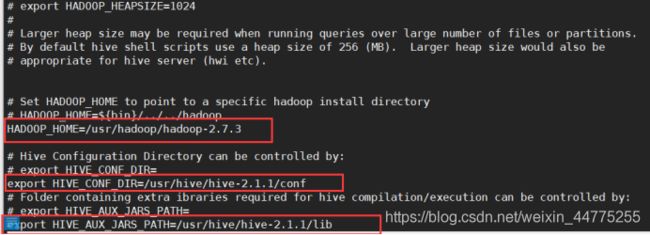
1.3 配置 hive-env.sh
# 将 hive-env.sh.template改名为 hive-env.sh
cp hive-env.sh.template hive-env.sh
vi hive-env.sh
# 修改HADOOP_HOME的路径
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
# 修改HIve配置文件的路径
export HIVE_CONF_DIR=/usr/hive/hive-2.1.1/conf
# 修改Hive需要jar包的路径
export HIVE_AUX_JARS_PATH=/usr/hive/hive-2.1.1/lib
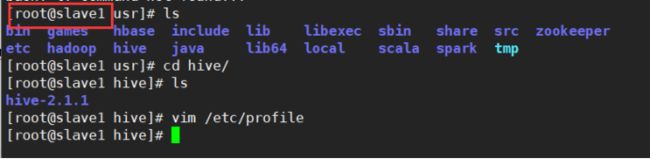
1.4 将hive复制到slave1中:
scp -r /usr/hive/hive-2.1.1/ root@slave1:/usr/hive/
1.5 配置 hive-site.xml(slave1)
slave1作为服务器端。需要相关连接的数据库的配置。比如ip、端口、数据库用户名、密码等。
# 进入conf目录
cd /usr/hive/hive-2.1.1/conf
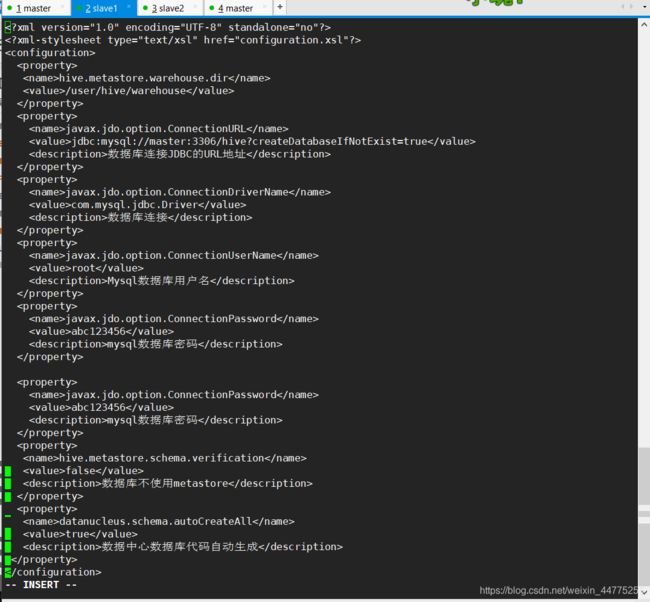
vi hive-site.xml
# 添加以下配置:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true</value>
<description>数据库连接JDBC的URL地址</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>数据库连接Driver,class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Mysql数据库用户名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>abc123456</value>
<description>mysql数据库密码</description>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
<description>数据中心数据库代码自动生成</description>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>数据库不使用metastore</description>
</property>
</configuration>
1.6 Hive与Mysql通信 (slave1)
因为服务器端需要和Mysql通信,所以服务器端的驱动程序 mysql-connector-java-5.1.46-bin.jar 到hive的lib目录下。
1.6.1 maven配置下载mysql驱动器
在 pom.xml 添加配置:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>
在IDEA下载完成后,在External Libraiesc -> 右键 mysql-connector-java-5.1.46-bin -> Find in Path(查找路径) -> 复制路径(…\repository\ mysql\mysql-connector-java )
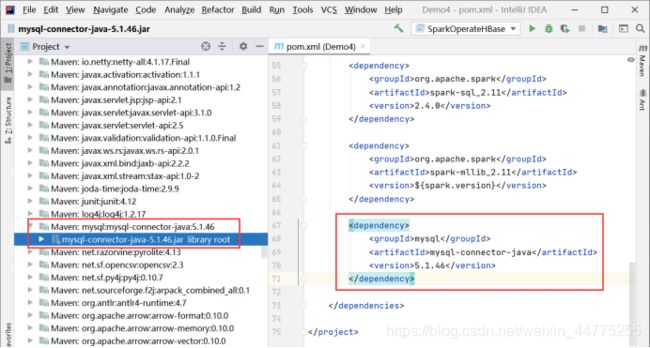
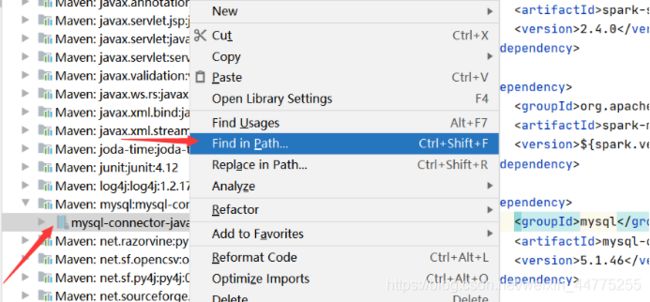
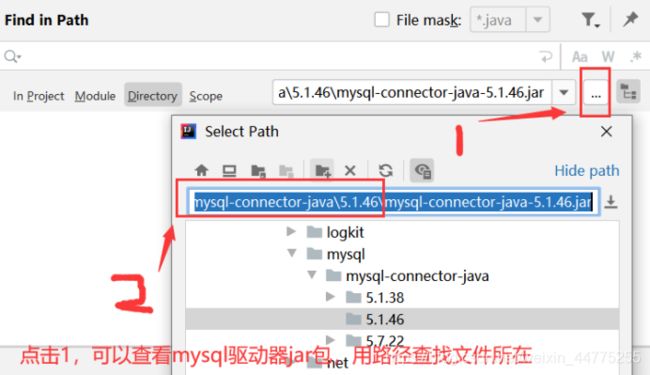

把 mysql-connector-java-5.1.46-bin.jar 传输到 虚拟机slave1节点的 /usr/hive/hive-2.1.1/lib目录下。

1.7 解决版本冲突和jar包依赖问题 (master)
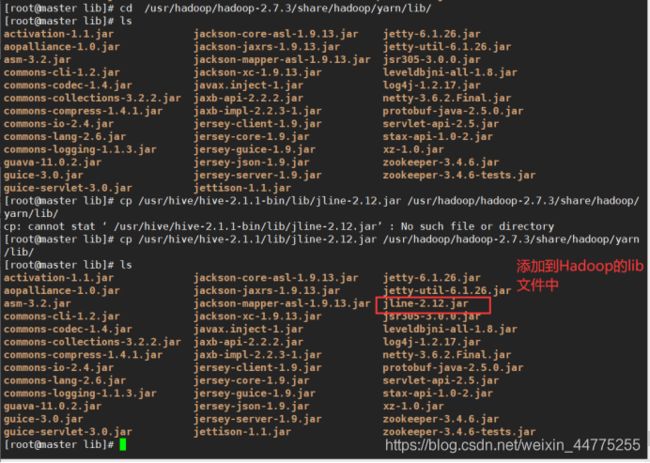
由于客户端需要和Hadoop通信,所以需要更改Hadoop中jline的版本。即保留一个高版本的jline jar包,从hive的lib包中拷贝到Hadoop中lib位置为:
/usr/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib.
cp /usr/hive/hive-2.1.1/lib/jline-2.12.jar /usr/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/
1.8 配置 hive-site.xml(master)
# 在 msater 执行:
cd /usr/hive/hive-2.1.1/conf/
vi hive-site.xml
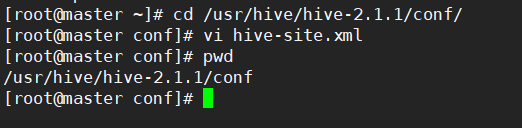
1. 添加配置:
<configuration>
<!-- Hive产生的元数据存放位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!--连接服务器-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://slave1:9083</value>
</property>
</configuration>
3. 保存退出。
<property>
<name>hive.metastore.localname>
<value>falsevalue>
<description>在0.10,0.11之后的HIVE版本hive.metastore.local 属性不再使用description>
property>
二、启动Hive
2.1 hive目录下启动Hive服务端(slave1)
slave1 作为服务端开启
输入:bin/hive --service metastore
2.2 hive 目录下启动 Hive客户端(master)
master 作为客户端开启 hive,bin/hive
总结下:Hive客户端在master,Hive服务端在slave1是因为,降低资源占有率,提高查询效率。以上hive安装完成,希望对你有所帮助。
除了实践,我们也要了解了解Hive的发展历史~
三、Hive 理论
3.1 Hive 的起源
- Hive起源于Facebook(一个美国的社交服务网络)。Facebook有着大量的数据,而Hadoop是一个开源的MapReduce实现,可以轻松处理大量的数据。
- 但是MapReduce程序对于Java程序员来说比较容易写,但是对于其他语言使用者来说不太方便。此时Facebook最早地开始研发Hive,它让对Hadoop使用SQL查询(实际上SQL后台转化为了MapReduce)成为可能,那些非Java程序员也可以更方便地使用。hive最早的目的也就是为了分析处理海量的日志。
- Hive是一个数据仓库技术,一次将一个SQL语句转化为 Mapreduce 代码,然后对代码进行编译,最后优化执行。
- Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。
- Hive做为 Hadoop 的数据仓库处理工具,它所有的数据都存储在Hadoop 兼容的文件系统中。
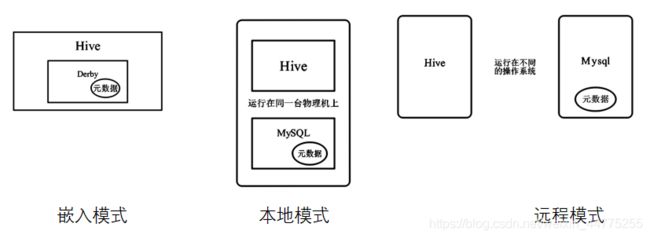
- Hive将元数据存储在关系数据库管理系统 (RDBMS) 中,一般常用 MySQL和Derby。默认情况下,Hive 元数据保存在内嵌的 Derby数据库中,只能允许一个会话连接,只适合简单的测试。实际生产环境中不适用, 为了支持多用户会话,则需要一个独立的元数据库,使用MySQL 作为元数据库,Hive内部对 MySQL 提供了很好的支持。
3.2 数据仓库工具 Hive
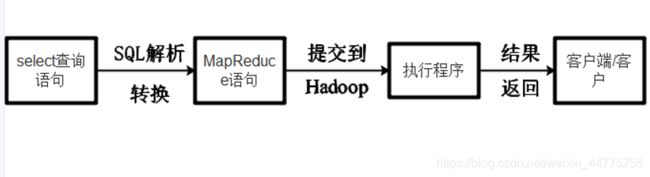
- Hive提供了一个类似SQL查询语句,即HQL来查询数据;
- Hive将SQL语句转换成M/R Job,然后在Hadoop上执行;
- Hive是建立在Hadoop HDFS上的数据仓库基础架构;
- Hive可以用来对数据进行提取转换加载。
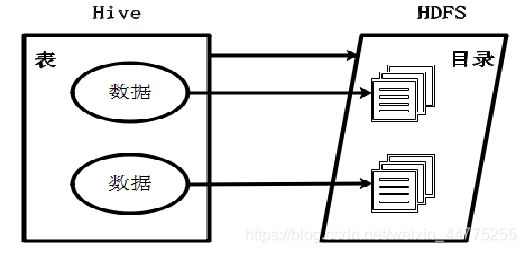
3.3 hivae与hdfs、 hive元数据
Hive的表= HDFS的目录
Hive数据=HDFS文件
- 元信息反应的是表的信息,和表中数据无关。
- Hive中的元数据包括表的名字、列(字段)名字、分区名字及其属性、表的属性(是否为外部表)、表的数据所在目录等。
3.4 Hive安装模式
- 嵌入模式
- 本地模式
- 远程模式
内置的Derby主要问题是并发性能很差,可以理解为单线程操作。