面试官:你的App卡顿过吗?你是如何监控的?
一、故事开始
面试官:平时开发中有遇到卡顿问题吗?你一般是如何监控的?
来面试的小伙:额…没有遇到过卡顿问题,我平时写的代码质量比较高,不会出现卡顿。
面试官:…

这回答似乎没啥问题,但是如果你在面试中真这样说他们会认为你在卡顿监控以及优化这一块是0经验。
卡顿这个话题,相信大部分两年或以上工作经验的同学都应该能说出个大概。
一般都能说出卡顿的原因:
主要是主线程阻塞。在开发过程中,遇到的造成主线程阻塞的原因可能是:
- 主线程在进行大量I/O操作:为了方便代码编写,直接在主线程去写入大量数据
- 主线程在进行大量计算:代码编写不合理,主线程进行复杂计算
- 大量UI绘制:界面过于复杂,UI绘制需要大量时间
- 主线程在等锁:主线程需要获得锁A,但是当前某个子线程持有这个锁A,导致主线程不得不等待子线程完成任务。
- …
但是如果问得更深一点:
- 应用上线后程序频繁出现卡顿,如何定位问题?
- 当遇见OOM时,如何定位到真正导致内存溢出的原因?
- 如何在不影响性能的同时实现线上性能监控?

去过大厂面试的朋友就会知道大厂经常问这样的问题,主要是因为一旦发生卡顿就会被用户直观的感受到,而其他问题很难被及时的发现:比如内存占用高,耗费流量等。用户体验不好就很有可能卸载掉我们的 App,让公司白白付出高昂的用户成本,因此因为性能问题导致用户流失是我们开发人员的失职。
二、性能问题如何治理?
首先,搞客户端开发的同学应该都知道,解决卡顿的过程往往是曲折的,有些并没有我们想的那样简单、浅表。很多时候,大部分卡顿是很难及时发现的,不可重现的卡顿,经常出现在线上用户的真实使用过程中,这种卡顿往往跟机器性能,手机环境,甚至是操作偏好等因素息息相关。
我们平时从用户反馈的“好卡呀”这种描述中很难直接洞察到卡顿的根源。甚至有些连卡顿的场景都不知道,很难准确重现,所以这种卡顿容易让人摸不着头脑。

而内存作为计算机程序运行最重要的资源之一,需要运行过程中做到合理的资源分配与回收,不合理的内存占用轻则使得用户应用程序运行卡顿、ANR、黑屏,重则导致用户应用程序发生 OOM(out of memory)崩溃。
我们需要在各种机器资源上保持优秀的流畅性和稳定性,内存优化是必须要重视的环节。但是我们即使有接入如Bugly的线上异常采集平台,也不能够保证通过异常日志找到OOM的原因。绝大多数的OOM,异常日志显示的只是压倒骆驼的最后一根稻草,而不是直接的原因。
三、如何进行线上性能监控?
下面总结几种比较流行、有效的卡顿监控方式:
1基于消息队列
1.1替换 Looper 的 Printer
Looper 暴露了一个方法
public void setMessageLogging(@Nullable Printer printer) {
mLogging = printer;
}
在Looper 的loop方法有这样一段代码
public static void loop() {
...
for (;;) {
...
// This must be in a local variable, in case a UI event sets the logger
final Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
Looper轮循的时候,每次从消息队列取出一条消息,如果logging不为空,就会调用 logging.println,我们可以通过设置Printer,计算Looper两次获取消息的时间差,如果时间太长就说明Handler处理时间过长,直接把堆栈信息打印出来,就可以定位到耗时代码。不过println 方法参数涉及到字符串拼接,考虑性能问题,所以这种方式只推荐在Debug模式下使用。基于此原理的开源库代表是:BlockCanary,看下BlockCanary核心代码:
类:LooperMonitor
public void println(String x) {
if (mStopWhenDebugging && Debug.isDebuggerConnected()) {
return;
}
if (!mPrintingStarted) {
//1、记录第一次执行时间,mStartTimestamp
mStartTimestamp = System.currentTimeMillis();
mStartThreadTimestamp = SystemClock.currentThreadTimeMillis();
mPrintingStarted = true;
startDump(); //2、开始dump堆栈信息
} else {
//3、第二次就进来这里了,调用isBlock 判断是否卡顿
final long endTime = System.currentTimeMillis();
mPrintingStarted = false;
if (isBlock(endTime)) {
notifyBlockEvent(endTime);
}
stopDump(); //4、结束dump堆栈信息
}
}
//判断是否卡顿的代码很简单,跟上次处理消息时间比较,比如大于3秒,就认为卡顿了
private boolean isBlock(long endTime) {
return endTime - mStartTimestamp > mBlockThresholdMillis;
}
原理是这样,比较Looper两次处理消息的时间差,比如大于3秒,就认为卡顿了。细节的话大家可以自己去研究源码,比如消息队列只有一条消息,隔了很久才有消息入队,这种情况应该是要处理的,BlockCanary是怎么处理的呢?

这个我在BlockCanary 中测试,并没有出现此问题,所以BlockCanary 是怎么处理的?简单分析一下源码:
上面这段代码,注释1和注释2,记录第一次处理的时间,同时调用startDump()方法,startDump()最终会通过Handler 去执行一个AbstractSampler 类的mRunnable,代码如下:
abstract class AbstractSampler {
private static final int DEFAULT_SAMPLE_INTERVAL = 300;
protected AtomicBoolean mShouldSample = new AtomicBoolean(false);
protected long mSampleInterval;
private Runnable mRunnable = new Runnable() {
@Override
public void run() {
doSample();
//调用startDump 的时候设置true了,stop时设置false
if (mShouldSample.get()) {
HandlerThreadFactory.getTimerThreadHandler()
.postDelayed(mRunnable, mSampleInterval);
}
}
};
可以看到,调用doSample之后又通过Handler执行mRunnable,等于是循环调用doSample,直到stopDump被调用。
doSample方法有两个类实现,StackSampler和CpuSampler,分析堆栈就看StackSampler的doSample方法
protected void doSample() {
StringBuilder stringBuilder = new StringBuilder();
// 获取堆栈信息
for (StackTraceElement stackTraceElement : mCurrentThread.getStackTrace()) {
stringBuilder
.append(stackTraceElement.toString())
.append(BlockInfo.SEPARATOR);
}
synchronized (sStackMap) {
// LinkedHashMap中数据超过100个就remove掉链表最前面的
if (sStackMap.size() == mMaxEntryCount && mMaxEntryCount > 0) {
sStackMap.remove(sStackMap.keySet().iterator().next());
}
//放入LinkedHashMap,时间作为key,value是堆栈信息
sStackMap.put(System.currentTimeMillis(), stringBuilder.toString());
}
}
所以,BlockCanary 能做到连续调用几个方法也能准确揪出耗时是哪个方法,是采用开启循环去获取堆栈信息并保存到LinkedHashMap的方式,避免出现误判或者漏判。核心代码就先分析到这里,其它细节大家可以自己去看源码。
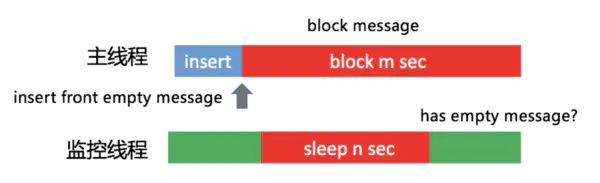
1.2插入空消息到消息队列
这种方式可以了解一下。
通过一个监控线程,每隔1秒向主线程消息队列的头部插入一条空消息。假设1秒后这个消息并没有被主线程消费掉,说明阻塞消息运行的时间在0~1秒之间。换句话说,如果我们需要监控3秒卡顿,那在第4次轮询中,头部消息依然没有被消费的话,就可以确定主线程出现了一次3秒以上的卡顿。
2.插桩
编译过程插桩(例如使用AspectJ),在方法入口和出口加入耗时监控的代码。 原来的方法:
public void test(){
doSomething();
}
通过编译插桩之后的方法类似这样
public void test(){
long startTime = System.currentTimeMillis();
doSomething();
long methodTime = System.currentTimeMillis() - startTime;//计算方法耗时
}
当然,原理是这样,实际上可能需要封装一下,类似这样
public void test(){
methodStart();
doSomething();
methodEnd();
}
在每个要监控的方法的入口和出口分别加上methodStart和methodEnd两个方法,类似插桩埋点。
当然,这种插桩的方法缺点比较明显:
- 无法监控系统方法
- apk体积会增大(每个方法都多了代码)
需要注意:
- 过滤简单的方法
- 只需要监控主线程执行的方法
四、性能优化
监控到了问题就要开始去优化了,针对“性能优化”这个要点,献上一份阿里大佬整理的Android性能优化实战手册,从各个方面对目标产品进行全方位的“优化”,让产品的性能从各个方面得到提升,希望大家喜欢。
这份《Android360°全方面性能调优》一共有722页,4个大点,25个小章节,不仅仅有详细的底层原理的解析,还有大厂的实践案例。
有需要的朋友,文末有免费领取方式~
第一章 设计思想与代码质量优化
六大原则
- 单一职责原则
- 里氏替换原则
- 依赖倒转原则
- 接口隔离原则
- ……
设计模式:结构型模式
- 桥接模式
- 适配器模式
- 装饰器模式
- 代理模式
- 门面(外观)模式
- ……
设计模式:创建型模式
- 建造者模式
- 单例模式
- 抽象工厂模式
- 工厂方法模式
- ……
数据结构
- 栈
- 队列
- 链表
- 树
- ……
算法
- 排序算法
- 查找算法
- ……

第二章 程序性能优化
启动速度与执行效率优化
- 冷启动和热启动解析
- APP 启动黑白屏解决办法
- APP 卡顿问题分析及解决方案
- 启动速度与执行效率优化之 StrictMode
- ……
布局检测与优化
- 布局层级优化
- 过度渲染
- ……
内存优化
- 内存抖动和内存泄漏
- 内存大户
- Bitmap 内存优化
- Profile 内存监测工具
- Mat 大对象与泄漏检测
- 耗电优化
- 网络传输与数据存储优化网络传输与数据存储优化
- APK 大小优化
- 屏幕适配
- ……

耗电优化
- Doze&Standby
- Battery Historian
- JobScheduler
- WorkManager
- 网络传输与数据存储优化
- google 序列化工具 protobuf
- 7z 极限压缩
- ……
APK 大小优化
- APK 瘦身
- 微信资源混淆原理
- ……
屏幕适配
- 进行适配的原理
- 屏幕分辨率限定符与 smallestWidth 限定符适配原理
- 为什么选择 smallestWidth 限定符适配
- 怎么适配其他 module
- 常见问题处理
- ……

OOM 问题原理解析
- adj 内存管理机制
- JVM 内存回收机制与 GC 算法解析
- 生命周期相关问题总结
- Bitmap 压缩方案总结
- ……
ANR 问题解析
- AMS 系统时间调节原理
- 程序等待原理分析
- ANR 问题解决方案
- ……
Crash 监控方案
- Java 层监控方案
- Nativie 层监控方案
- ……
第三章 开发效率优化
分布式版本控制系统 Git
- 企业高效持续集成平台场景介绍
- GIT 分布式版本控制系统
- GIT 分支管理
- ……
自动化构建系统 Gradle
- Gradle 与 Android 插件
- gradle 与 android gradle 插件的关系
- Gradle Transform API 的基本使用
- ……
Gradle Transform API 的基本使用
- 什么是 Transform
- Transform 的使用场景
- Transform API 学习
- 输入的类型
- ……
自定义插件开发
- Gradle 插件简介
- 开始准备
- 实践
- 自定义 Gradle 插件
- buildSrc 模块方式
- ……
插件实战
- 多渠道打包
- 发版自动钉钉
- ……

第四章 APP 性能优化实践
启动速度
- 应用启动的一般流程
- 冷启动和热启动
- 启动速度的测量
- 启动窗口优化
- 线程优化
- 系统调度优化
- GC 优化
- IO 优化
- 资源重排
- 主页布局优化
- 类加载优化
- 选择合适的启动框架
- 减少 Activity 的跳转层次
- 厂商优化
- 后台保活
- ……
流畅度
- 性能问题分析的一些工具和套路
- 通过性能数据数据分析
- Android 平台性能导致的性能案例
- Android App 自身导致的性能问题
- 低内存的数据特征和行为特征
- 应用宝
- 讯飞输入法无障碍服务导致的整机卡顿分析
- 字节跳动:今日头条图文详情页秒开实践
- ……
抖音在 APK 包大小资源优化的实践
- 图片压缩
- webp 无侵入式兼容
- 多 DPI 优化
- 重复资源合并
- shrinkResource 严格模式
- 资源混淆(兼容 aab 模式)
- ARSC 瘦身
- ……

优酷响应式布局技术全解析
- 优酷APP响应式布局技术概述
- 优酷APP响应式布局Android落地
- 在分发场景的落地
- 在消费场景的落地
- 优酷APP响应式布局之测试方案
- ……
网络优化
- 手机淘宝在网络的链路优化
- 百度 APP 在网络深度优化的实践
- ……
手机淘宝双十一性能优化项目揭秘
- 一秒法则的实现
- 启动时间和页面帧率提升 20%
- Android 手机内存节省50%
- ……
高德 APP 全链路源码依赖分析
- 高德 APP 平台架构
- 基础实现原理
- 项目架
- 应用场景及实现原理
- ……
彻底干掉OOM的实战经验分享
- 排查内存泄漏
- 兜底策略
- 内存峰值太高
- 特大图排查优化
- ……
微信 Android终端内存优化实践
- Activity 泄露检测
- Bitmap 分配及回收追踪
- Native 内存泄漏检测
- 线程监控
- 内存监控
- ……
如果你也想提升自己移动开发的性能优化技术,或者是正在准备移动开发岗的面试,我觉得这份笔记你必定不能错过。