Github复现之视频异常检测(Future Frame Prediction for Anomaly Detection)
Future Frame Prediction for Anomaly Detection – A New Baseline
论文链接:https://arxiv.org/pdf/1712.09867.pdf
论文里面提供了GitHub链接但是似乎有些问题,直接转到另外一个
https://github.com/feiyuhuahuo/Anomaly_Prediction
这个是经过测试了,可以正常使用,用公共数据集效果还行,用在自己的数据集还在测试,但是初步试了下,是可以用一下的
先描述下这个论文的应用场景:就是把固定在一个位置的摄像头(静态)获取的视频流抽帧,得到图片训练数据,利用GAN网络学习常规场景下的图像空间特征,预测时,将前几帧图像输入模型生成一个固定状态下常规的图来比对下一帧图像从而达到对未来帧的判别,简单说来就是比如输入6帧图像,拿前5帧放入模型用来生成未来帧该有的样子,和真实的未来帧做比较从而判别未来帧是否异常,假如摄像头中较多的情况是走路的人场景多,如果突然出现了骑车的人,那这就是异常情况。我只说了大概,具体还是要看论文,我的重点是如何使用这个。
环境里有个需要装的cupy包注意下Windows要找自己python对用的whl文件比较好,直接pip安装可能会遇到麻烦,链接:https://www.lfd.uci.edu/~gohlke/pythonlibs/
1.数据准备:
直接下载GitHub提供的avenue数据集测试,如果是自己的数据就还用这个文件结构,建议先跑公共数据集看效果
注意数据的加载脚本Dataset.py,我加了一个predict_dataset函数,后面会用到
import random
import torch
import numpy as np
import cv2
import glob
import os
import scipy.io as scio
from torch.utils.data import Dataset
def np_load_frame(filename, resize_h, resize_w):
img = cv2.imread(filename)
image_resized = cv2.resize(img, (resize_w, resize_h)).astype('float32')
image_resized = (image_resized / 127.5) - 1.0 # to -1 ~ 1
image_resized = np.transpose(image_resized, [2, 0, 1]) # to (C, W, H)
return image_resized
class train_dataset(Dataset):
"""
No data augmentation.
Normalized from [0, 255] to [-1, 1], the channels are BGR due to cv2 and liteFlownet.
"""
def __init__(self, cfg):
self.img_h = cfg.img_size[0]
self.img_w = cfg.img_size[1]
self.clip_length = 5
self.videos = []
self.all_seqs = []
for folder in sorted(glob.glob(f'{cfg.train_data}/*')):
# all_imgs = glob.glob(f'{folder}/*.jpg')
all_imgs = glob.glob(f'{folder}/*.png')
all_imgs.sort()
self.videos.append(all_imgs)
random_seq = list(range(len(all_imgs) - 4))
random.shuffle(random_seq)
self.all_seqs.append(random_seq)
def __len__(self): # This decide the indice range of the PyTorch Dataloader.
return len(self.videos)
def __getitem__(self, indice): # Indice decide which video folder to be loaded.
one_folder = self.videos[indice]
video_clip = []
start = self.all_seqs[indice][-1] # Always use the last index in self.all_seqs.
for i in range(start, start + self.clip_length):
video_clip.append(np_load_frame(one_folder[i], self.img_h, self.img_w))
video_clip = np.array(video_clip).reshape((-1, self.img_h, self.img_w))
video_clip = torch.from_numpy(video_clip)
flow_str = f'{indice}_{start + 3}-{start + 4}'
return indice, video_clip, flow_str
class test_dataset:
def __init__(self, cfg, video_folder):
self.img_h = cfg.img_size[0]
self.img_w = cfg.img_size[1]
self.clip_length = 5
# self.imgs = glob.glob(video_folder + '/*.jpg')
self.imgs = glob.glob(video_folder + '/*.png')
self.imgs.sort()
def __len__(self):
return len(self.imgs) - (self.clip_length - 1) # The first [input_num] frames are unpredictable.
def __getitem__(self, indice):
video_clips = []
for frame_id in range(indice, indice + self.clip_length):
video_clips.append(np_load_frame(self.imgs[frame_id], self.img_h, self.img_w))
video_clips = np.array(video_clips).reshape((-1, self.img_h, self.img_w))
return video_clips
class predict_dataset:
def __init__(self, cfg, video_folder):
self.img_h = cfg.img_size[0]
self.img_w = cfg.img_size[1]
self.clip_length = 5
# self.imgs = glob.glob(video_folder + '/*.jpg')
self.imgs = glob.glob(video_folder + '/*.png')
self.imgs.sort()
self.video_dict = {
}
def __len__(self):
return len(self.imgs) - (self.clip_length - 1) # The first [input_num] frames are unpredictable.
def __getitem__(self, indice):
video_clips = []
video_names = []
for frame_id in range(indice, indice + self.clip_length):
video_clips.append(np_load_frame(self.imgs[frame_id], self.img_h, self.img_w))
video_names.append(self.imgs[frame_id])
video_clips = np.array(video_clips).reshape((-1, self.img_h, self.img_w))
self.video_dict['video_clip'] = video_clips
self.video_dict['video_name'] = video_names
return self.video_dict
class Label_loader:
def __init__(self, cfg, video_folders):
assert cfg.dataset in ('ped2', 'avenue', 'shanghaitech'), f'Did not find the related gt for \'{cfg.dataset}\'.'
self.cfg = cfg
self.name = cfg.dataset
self.frame_path = cfg.test_data
self.mat_path = f'{cfg.data_root + self.name}/{self.name}.mat'
self.video_folders = video_folders
def __call__(self):
if self.name == 'shanghaitech':
gt = self.load_shanghaitech()
else:
gt = self.load_ucsd_avenue()
return gt
def load_ucsd_avenue(self):
abnormal_events = scio.loadmat(self.mat_path, squeeze_me=True)['gt']
all_gt = []
for i in range(abnormal_events.shape[0]):
length = len(os.listdir(self.video_folders[i]))
sub_video_gt = np.zeros((length,), dtype=np.int8)
one_abnormal = abnormal_events[i]
if one_abnormal.ndim == 1:
one_abnormal = one_abnormal.reshape((one_abnormal.shape[0], -1))
for j in range(one_abnormal.shape[1]):
start = one_abnormal[0, j] - 1
end = one_abnormal[1, j]
sub_video_gt[start: end] = 1
all_gt.append(sub_video_gt)
return all_gt
def load_shanghaitech(self):
np_list = glob.glob(f'{self.cfg.data_root + self.name}/frame_masks/')
np_list.sort()
gt = []
for npy in np_list:
gt.append(np.load(npy))
return gt
1.增加
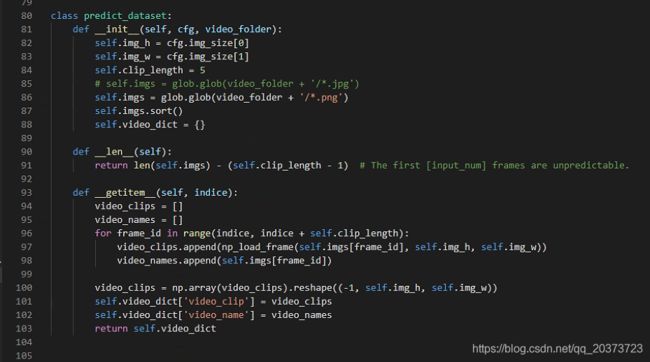
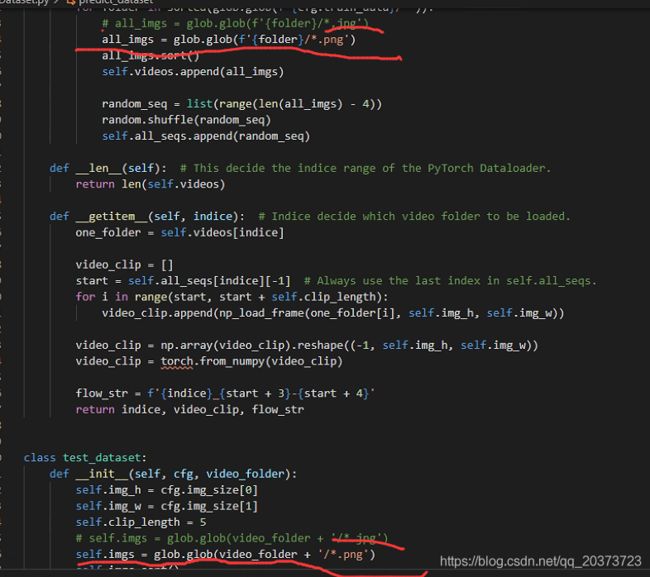
2.输入图片后缀
train_dataset,test_dataset,predict_dataset三个函数都有规定图片后缀的地方,自己改一下,原始的是jpg
2.修改配置文件config.py
这里我加了一个predict模式,后面会用到
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from glob import glob
import os
if not os.path.exists('tensorboard_log'):
os.mkdir('tensorboard_log')
if not os.path.exists('weights'):
os.mkdir('weights')
if not os.path.exists('results'):
os.mkdir('results')
share_config = {
'mode': 'training',
'dataset': 'avenue',
'img_size': (256, 256),
'data_root': './Data/'} # remember the final '/'
class dict2class:
def __init__(self, config):
self.mode = config['mode']
for k, v in config.items():
self.__setattr__(k, v)
def print_cfg(self):
print('\n' + '-' * 30 + f'{self.mode} cfg' + '-' * 30)
for k, v in vars(self).items():
print(f'{k}: {v}')
print()
def update_config(args=None, mode=None):
share_config['mode'] = mode
assert args.dataset in ('ped2', 'avenue', 'shanghaitech'), 'Dataset error.'
share_config['dataset'] = args.dataset
if mode == 'train':
share_config['batch_size'] = args.batch_size
share_config['train_data'] = share_config['data_root'] + args.dataset + '/training/'
share_config['test_data'] = share_config['data_root'] + args.dataset + '/testing/'
share_config['g_lr'] = 0.0002
share_config['d_lr'] = 0.00002
share_config['resume'] = glob(f'weights/{args.resume}*')[0] if args.resume else None
share_config['iters'] = args.iters
share_config['show_flow'] = args.show_flow
share_config['save_interval'] = args.save_interval
share_config['val_interval'] = args.val_interval
share_config['flownet'] = args.flownet
elif mode == 'test':
share_config['test_data'] = share_config['data_root'] + args.dataset + '/testing/'
share_config['trained_model'] = args.trained_model
share_config['show_curve'] = args.show_curve
share_config['show_heatmap'] = args.show_heatmap
elif mode == 'predict':
share_config['test_data'] = share_config['data_root'] + args.dataset + '/predicting/'
share_config['trained_model'] = args.trained_model
share_config['show_curve'] = args.show_curve
share_config['show_heatmap'] = args.show_heatmap
return dict2class(share_config) # change dict keys to class attributes
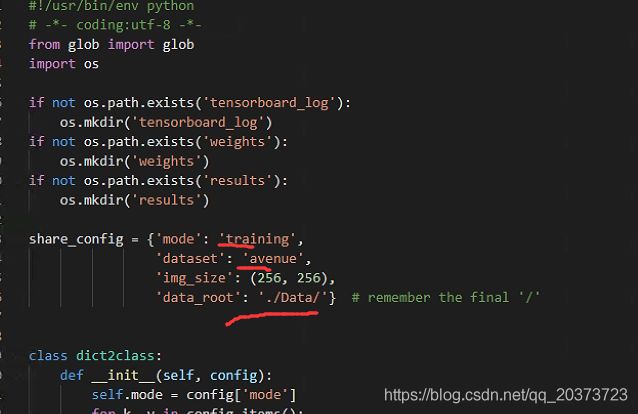
3.训练train.py
import os
from glob import glob
import cv2
import time
import datetime
from tensorboardX import SummaryWriter
from torch.utils.data import DataLoader
import argparse
import random
from utils import *
from losses import *
import Dataset
from models.unet import UNet
from models.pix2pix_networks import PixelDiscriminator
from models.liteFlownet import lite_flownet as lite_flow
from config import update_config
from models.flownet2.models import FlowNet2SD
from evaluate import val
parser = argparse.ArgumentParser(description='Anomaly Prediction')
parser.add_argument('--batch_size', default=8, type=int)
parser.add_argument('--dataset', default='avenue', type=str, help='The name of the dataset to train.')
parser.add_argument('--iters', default=40000, type=int, help='The total iteration number.')
parser.add_argument('--resume', default=None, type=str,
help='The pre-trained model to resume training with, pass \'latest\' or the model name.')
parser.add_argument('--save_interval', default=1000, type=int, help='Save the model every [save_interval] iterations.')
parser.add_argument('--val_interval', default=1000, type=int,
help='Evaluate the model every [val_interval] iterations, pass -1 to disable.')
parser.add_argument('--show_flow', default=False, action='store_true',
help='If True, the first batch of ground truth optic flow could be visualized and saved.')
parser.add_argument('--flownet', default='lite', type=str, help='lite: LiteFlownet, 2sd: FlowNet2SD.')
args = parser.parse_args()
train_cfg = update_config(args, mode='train')
train_cfg.print_cfg()
generator = UNet(input_channels=12, output_channel=3).cuda()
discriminator = PixelDiscriminator(input_nc=3).cuda()
optimizer_G = torch.optim.Adam(generator.parameters(), lr=train_cfg.g_lr)
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=train_cfg.d_lr)
if train_cfg.resume:
generator.load_state_dict(torch.load(train_cfg.resume)['net_g'])
discriminator.load_state_dict(torch.load(train_cfg.resume)['net_d'])
optimizer_G.load_state_dict(torch.load(train_cfg.resume)['optimizer_g'])
optimizer_D.load_state_dict(torch.load(train_cfg.resume)['optimizer_d'])
print(f'Pre-trained generator and discriminator have been loaded.\n')
else:
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
print('Generator and discriminator are going to be trained from scratch.\n')
assert train_cfg.flownet in ('lite', '2sd'), 'Flow net only supports LiteFlownet or FlowNet2SD currently.'
if train_cfg.flownet == '2sd':
flow_net = FlowNet2SD()
flow_net.load_state_dict(torch.load('basemodel/FlowNet2-SD.pth')['state_dict'])
else:
flow_net = lite_flow.Network()
flow_net.load_state_dict(torch.load('basemodel/network-default.pytorch'))
flow_net.cuda().eval() # Use flow_net to generate optic flows, so set to eval mode.
adversarial_loss = Adversarial_Loss().cuda()
discriminate_loss = Discriminate_Loss().cuda()
gradient_loss = Gradient_Loss(3).cuda()
flow_loss = Flow_Loss().cuda()
intensity_loss = Intensity_Loss().cuda()
train_dataset = Dataset.train_dataset(train_cfg)
# Remember to set drop_last=True, because we need to use 4 frames to predict one frame.
train_dataloader = DataLoader(dataset=train_dataset, batch_size=train_cfg.batch_size,
shuffle=True, num_workers=0, drop_last=True)
writer = SummaryWriter(f'tensorboard_log/{train_cfg.dataset}_bs{train_cfg.batch_size}')
start_iter = int(train_cfg.resume.split('_')[-1].split('.')[0]) if train_cfg.resume else 0
training = True
generator = generator.train()
discriminator = discriminator.train()
try:
step = start_iter
while training:
for indice, clips, flow_strs in train_dataloader:
input_frames = clips[:, 0:12, :, :].cuda() # (n, 12, 256, 256)
target_frame = clips[:, 12:15, :, :].cuda() # (n, 3, 256, 256)
input_last = input_frames[:, 9:12, :, :].cuda() # use for flow_loss
# pop() the used frame index, this can't work in train_dataset.__getitem__ because of multiprocessing.
for index in indice:
train_dataset.all_seqs[index].pop()
if len(train_dataset.all_seqs[index]) == 0:
train_dataset.all_seqs[index] = list(range(len(train_dataset.videos[index]) - 4))
random.shuffle(train_dataset.all_seqs[index])
G_frame = generator(input_frames)
if train_cfg.flownet == 'lite':
gt_flow_input = torch.cat([input_last, target_frame], 1)
pred_flow_input = torch.cat([input_last, G_frame], 1)
# No need to train flow_net, use .detach() to cut off gradients.
flow_gt = flow_net.batch_estimate(gt_flow_input, flow_net).detach()
flow_pred = flow_net.batch_estimate(pred_flow_input, flow_net).detach()
else:
gt_flow_input = torch.cat([input_last.unsqueeze(2), target_frame.unsqueeze(2)], 2)
pred_flow_input = torch.cat([input_last.unsqueeze(2), G_frame.unsqueeze(2)], 2)
flow_gt = (flow_net(gt_flow_input * 255.) / 255.).detach() # Input for flownet2sd is in (0, 255).
flow_pred = (flow_net(pred_flow_input * 255.) / 255.).detach()
if train_cfg.show_flow:
flow = np.array(flow_gt.cpu().detach().numpy().transpose(0, 2, 3, 1), np.float32) # to (n, w, h, 2)
for i in range(flow.shape[0]):
aa = flow_to_color(flow[i], convert_to_bgr=False)
path = train_cfg.train_data.split('/')[-3] + '_' + flow_strs[i]
cv2.imwrite(f'images/{path}.jpg', aa) # e.g. images/avenue_4_574-575.jpg
print(f'Saved a sample optic flow image from gt frames: \'images/{path}.jpg\'.')
inte_l = intensity_loss(G_frame, target_frame)
grad_l = gradient_loss(G_frame, target_frame)
fl_l = flow_loss(flow_pred, flow_gt)
g_l = adversarial_loss(discriminator(G_frame))
G_l_t = 1. * inte_l + 1. * grad_l + 2. * fl_l + 0.05 * g_l
# When training discriminator, don't train generator, so use .detach() to cut off gradients.
D_l = discriminate_loss(discriminator(target_frame), discriminator(G_frame.detach()))
# https://github.com/pytorch/pytorch/issues/39141
# torch.optim optimizer now do inplace detection for module parameters since PyTorch 1.5
# If I do this way:
# ----------------------------------------
# optimizer_D.zero_grad()
# D_l.backward()
# optimizer_D.step()
# optimizer_G.zero_grad()
# G_l_t.backward()
# optimizer_G.step()
# ----------------------------------------
# The optimizer_D.step() modifies the discriminator parameters inplace.
# But these parameters are required to compute the generator gradient for the generator.
# Thus I should make sure no parameters are modified before calling .step(), like this:
# ----------------------------------------
# optimizer_G.zero_grad()
# G_l_t.backward()
# optimizer_G.step()
# optimizer_D.zero_grad()
# D_l.backward()
# optimizer_D.step()
# ----------------------------------------
# Or just do .step() after all the gradients have been computed, like the following way:
optimizer_D.zero_grad()
D_l.backward()
optimizer_G.zero_grad()
G_l_t.backward()
optimizer_D.step()
optimizer_G.step()
torch.cuda.synchronize()
time_end = time.time()
if step > start_iter: # This doesn't include the testing time during training.
iter_t = time_end - temp
temp = time_end
if step != start_iter:
if step % 20 == 0:
time_remain = (train_cfg.iters - step) * iter_t
eta = str(datetime.timedelta(seconds=time_remain)).split('.')[0]
psnr = psnr_error(G_frame, target_frame)
lr_g = optimizer_G.param_groups[0]['lr']
lr_d = optimizer_D.param_groups[0]['lr']
print(f"[{step}] inte_l: {inte_l:.3f} | grad_l: {grad_l:.3f} | fl_l: {fl_l:.3f} | "
f"g_l: {g_l:.3f} | G_l_total: {G_l_t:.3f} | D_l: {D_l:.3f} | psnr: {psnr:.3f} | "
f"iter: {iter_t:.3f}s | ETA: {eta} | lr: {lr_g} {lr_d}")
save_G_frame = ((G_frame[0] + 1) / 2)
save_G_frame = save_G_frame.cpu().detach()[(2, 1, 0), ...]
save_target = ((target_frame[0] + 1) / 2)
save_target = save_target.cpu().detach()[(2, 1, 0), ...]
writer.add_scalar('psnr/train_psnr', psnr, global_step=step)
writer.add_scalar('total_loss/g_loss_total', G_l_t, global_step=step)
writer.add_scalar('total_loss/d_loss', D_l, global_step=step)
writer.add_scalar('G_loss_total/g_loss', g_l, global_step=step)
writer.add_scalar('G_loss_total/fl_loss', fl_l, global_step=step)
writer.add_scalar('G_loss_total/inte_loss', inte_l, global_step=step)
writer.add_scalar('G_loss_total/grad_loss', grad_l, global_step=step)
writer.add_scalar('psnr/train_psnr', psnr, global_step=step)
if step % int(train_cfg.iters / 100) == 0:
writer.add_image('image/G_frame', save_G_frame, global_step=step)
writer.add_image('image/target', save_target, global_step=step)
if step % train_cfg.save_interval == 0:
model_dict = {
'net_g': generator.state_dict(), 'optimizer_g': optimizer_G.state_dict(),
'net_d': discriminator.state_dict(), 'optimizer_d': optimizer_D.state_dict()}
torch.save(model_dict, f'weights/{train_cfg.dataset}_{step}.pth')
print(f'\nAlready saved: \'{train_cfg.dataset}_{step}.pth\'.')
if step % train_cfg.val_interval == 0:
# auc = val(train_cfg, model=generator)
# writer.add_scalar('results/auc', auc, global_step=step)
generator.train()
step += 1
if step > train_cfg.iters:
training = False
model_dict = {
'net_g': generator.state_dict(), 'optimizer_g': optimizer_G.state_dict(),
'net_d': discriminator.state_dict(), 'optimizer_d': optimizer_D.state_dict()}
torch.save(model_dict, f'weights/latest_{train_cfg.dataset}_{step}.pth')
break
except KeyboardInterrupt:
print(f'\nStop early, model saved: \'latest_{train_cfg.dataset}_{step}.pth\'.\n')
if glob(f'weights/latest*'):
os.remove(glob(f'weights/latest*')[0])
model_dict = {
'net_g': generator.state_dict(), 'optimizer_g': optimizer_G.state_dict(),
'net_d': discriminator.state_dict(), 'optimizer_d': optimizer_D.state_dict()}
torch.save(model_dict, f'weights/latest_{train_cfg.dataset}_{step}.pth')
注意:
1.预模型需要给下你自己放的路径,GitHub上可以下载到
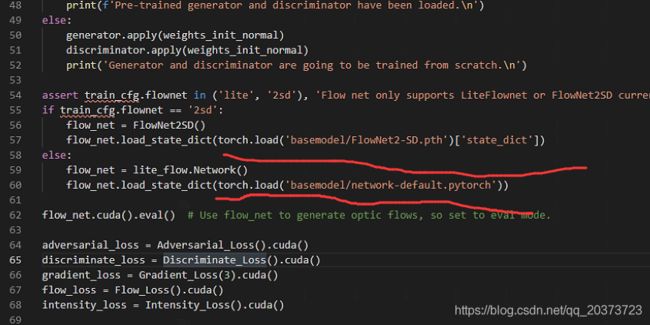
2.Windows需要改num_workers参数为0,否则可能报错
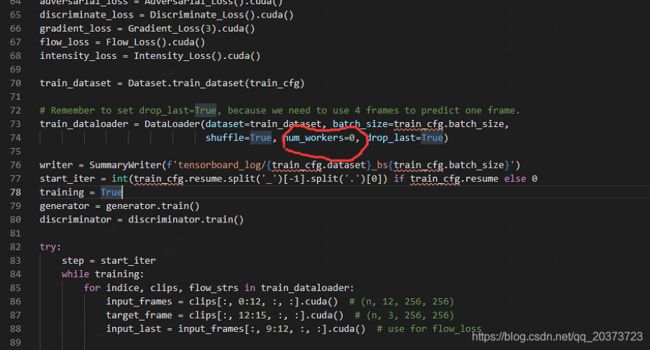
3.注释情况,注意我标出的两句,训练自己的数据时需要注释一下,因为那个val函数用到了一个.mat文件,这个文件你用自己的数据集的时候需要自己生成,没有就注释了吧,这里已经到了评价阶段,没有也行,如果先训练公共数据集avenue就先不要注释
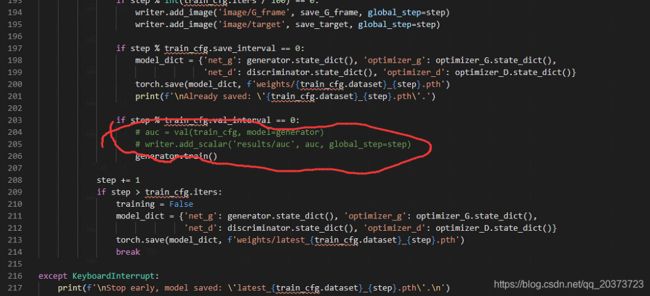
改完上面就可以训练了,模型生成到了weights里面,训练log在tensorboard_log,可以通过tensorboard查看
4.评价evaluate.py
import numpy as np
import os
import time
import torch
import argparse
import cv2
from PIL import Image
import io
from sklearn import metrics
import matplotlib.pyplot as plt
from config import update_config
from Dataset import Label_loader
from utils import psnr_error
import Dataset
from models.unet import UNet
parser = argparse.ArgumentParser(description='Anomaly Prediction')
parser.add_argument('--dataset', default='avenue', type=str, help='The name of the dataset to train.')
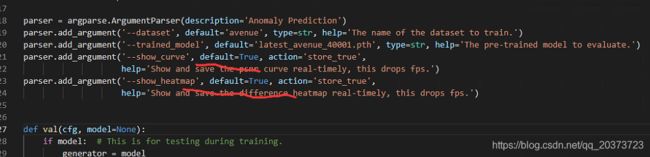
parser.add_argument('--trained_model', default='latest_avenue_40001.pth', type=str, help='The pre-trained model to evaluate.')
parser.add_argument('--show_curve', default=True, action='store_true',
help='Show and save the psnr curve real-timely, this drops fps.')
parser.add_argument('--show_heatmap', default=True, action='store_true',
help='Show and save the difference heatmap real-timely, this drops fps.')
def val(cfg, model=None):
if model: # This is for testing during training.
generator = model
generator.eval()
else:
generator = UNet(input_channels=12, output_channel=3).cuda().eval()
generator.load_state_dict(torch.load('weights/' + cfg.trained_model)['net_g'])
print(f'The pre-trained generator has been loaded from \'weights/{cfg.trained_model}\'.\n')
video_folders = os.listdir(cfg.test_data)
video_folders.sort()
video_folders = [os.path.join(cfg.test_data, aa) for aa in video_folders]
fps = 0
psnr_group = []
if not model:
if cfg.show_curve:
fig = plt.figure("Image")
manager = plt.get_current_fig_manager()
manager.window.setGeometry(550, 200, 600, 500)
# This works for QT backend, for other backends, check this ⬃⬃⬃.
# https://stackoverflow.com/questions/7449585/how-do-you-set-the-absolute-position-of-figure-windows-with-matplotlib
plt.xlabel('frames')
plt.ylabel('psnr')
plt.title('psnr curve')
plt.grid(ls='--')
cv2.namedWindow('target frames', cv2.WINDOW_NORMAL)
cv2.resizeWindow('target frames', 384, 384)
cv2.moveWindow("target frames", 100, 100)
if cfg.show_heatmap:
cv2.namedWindow('difference map', cv2.WINDOW_NORMAL)
cv2.resizeWindow('difference map', 384, 384)
cv2.moveWindow('difference map', 100, 550)
with torch.no_grad():
for i, folder in enumerate(video_folders):
dataset = Dataset.test_dataset(cfg, folder)
if not model:
name = folder.split('/')[-1]
fourcc = cv2.VideoWriter_fourcc('X', 'V', 'I', 'D')
if cfg.show_curve:
video_writer = cv2.VideoWriter(f'results/{name}_video.avi', fourcc, 30, cfg.img_size)
curve_writer = cv2.VideoWriter(f'results/{name}_curve.avi', fourcc, 30, (600, 430))
js = []
plt.clf()
ax = plt.axes(xlim=(0, len(dataset)), ylim=(30, 45))
line, = ax.plot([], [], '-b')
if cfg.show_heatmap:
heatmap_writer = cv2.VideoWriter(f'results/{name}_heatmap.avi', fourcc, 30, cfg.img_size)
psnrs = []
for j, clip in enumerate(dataset):
input_np = clip[0:12, :, :]
target_np = clip[12:15, :, :]
input_frames = torch.from_numpy(input_np).unsqueeze(0).cuda()
target_frame = torch.from_numpy(target_np).unsqueeze(0).cuda()
G_frame = generator(input_frames)
test_psnr = psnr_error(G_frame, target_frame).cpu().detach().numpy()
psnrs.append(float(test_psnr))
if not model:
if cfg.show_curve:
cv2_frame = ((target_np + 1) * 127.5).transpose(1, 2, 0).astype('uint8')
js.append(j)
line.set_xdata(js) # This keeps the existing figure and updates the X-axis and Y-axis data,
line.set_ydata(psnrs) # which is faster, but still not perfect.
plt.pause(0.001) # show curve
cv2.imshow('target frames', cv2_frame)
cv2.waitKey(1) # show video
video_writer.write(cv2_frame) # Write original video frames.
buffer = io.BytesIO() # Write curve frames from buffer.
fig.canvas.print_png(buffer)
buffer.write(buffer.getvalue())
curve_img = np.array(Image.open(buffer))[..., (2, 1, 0)]
curve_writer.write(curve_img)
if cfg.show_heatmap:
diff_map = torch.sum(torch.abs(G_frame - target_frame).squeeze(), 0)
diff_map -= diff_map.min() # Normalize to 0 ~ 255.
diff_map /= diff_map.max()
diff_map *= 255
diff_map = diff_map.cpu().detach().numpy().astype('uint8')
heat_map = cv2.applyColorMap(diff_map, cv2.COLORMAP_JET)
cv2.imshow('difference map', heat_map)
cv2.waitKey(1)
heatmap_writer.write(heat_map) # Write heatmap frames.
torch.cuda.synchronize()
end = time.time()
if j > 1: # Compute fps by calculating the time used in one completed iteration, this is more accurate.
fps = 1 / (end - temp)
temp = end
print(f'\rDetecting: [{i + 1:02d}] {j + 1}/{len(dataset)}, {fps:.2f} fps.', end='')
psnr_group.append(np.array(psnrs))
if not model:
if cfg.show_curve:
video_writer.release()
curve_writer.release()
if cfg.show_heatmap:
heatmap_writer.release()
print('\nAll frames were detected, begin to compute AUC.')
gt_loader = Label_loader(cfg, video_folders) # Get gt labels.
gt = gt_loader()
assert len(psnr_group) == len(gt), f'Ground truth has {len(gt)} videos, but got {len(psnr_group)} detected videos.'
scores = np.array([], dtype=np.float32)
labels = np.array([], dtype=np.int8)
for i in range(len(psnr_group)):
distance = psnr_group[i]
distance -= min(distance) # distance = (distance - min) / (max - min)
distance /= max(distance)
scores = np.concatenate((scores, distance), axis=0)
labels = np.concatenate((labels, gt[i][4:]), axis=0) # Exclude the first 4 unpredictable frames in gt.
assert scores.shape == labels.shape, \
f'Ground truth has {labels.shape[0]} frames, but got {scores.shape[0]} detected frames.'
fpr, tpr, thresholds = metrics.roc_curve(labels, scores, pos_label=0)
auc = metrics.auc(fpr, tpr)
print(f'AUC: {auc}\n')
return auc
if __name__ == '__main__':
args = parser.parse_args()
test_cfg = update_config(args, mode='test')
test_cfg.print_cfg()
val(test_cfg)
1.显示,下面直接加default=True吧
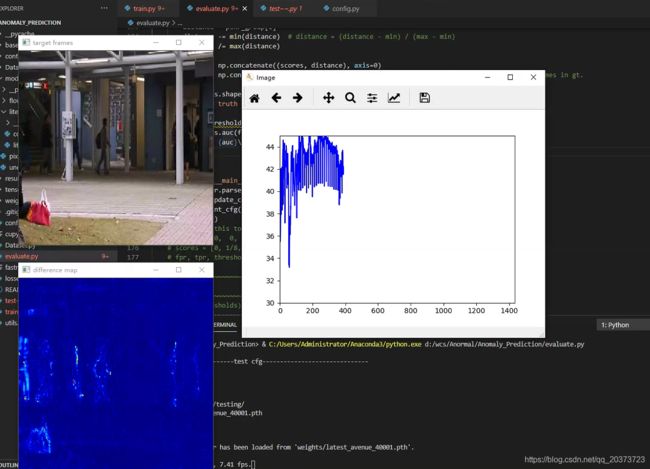
2.正常情况,跑起来以后应该是下面这样的,跑完会输出AUC
5.自己的数据evaluate2.py
因为不太想生成mat文件用来计算AUC,直接去掉一部分代码,跑完就不会输出AUC了
import numpy as np
import os
import time
import torch
import argparse
import cv2
from PIL import Image
import io
from sklearn import metrics
import matplotlib.pyplot as plt
from config import update_config
from Dataset import Label_loader
from utils import psnr_error
import Dataset
from models.unet import UNet
parser = argparse.ArgumentParser(description='Anomaly Prediction')
parser.add_argument('--dataset', default='avenue', type=str, help='The name of the dataset to train.')
parser.add_argument('--trained_model', default='latest_avenue_40001.pth', type=str, help='The pre-trained model to evaluate.')
parser.add_argument('--show_curve', default=True, action='store_true',
help='Show and save the psnr curve real-timely, this drops fps.')
parser.add_argument('--show_heatmap', default=True, action='store_true',
help='Show and save the difference heatmap real-timely, this drops fps.')
def val(cfg, model=None):
if model: # This is for testing during training.
generator = model
generator.eval()
else:
generator = UNet(input_channels=12, output_channel=3).cuda().eval()
generator.load_state_dict(torch.load('weights/' + cfg.trained_model)['net_g'])
print(f'The pre-trained generator has been loaded from \'weights/{cfg.trained_model}\'.\n')
video_folders = os.listdir(cfg.test_data)
video_folders.sort()
video_folders = [os.path.join(cfg.test_data, aa) for aa in video_folders]
fps = 0
psnr_group = []
if not model:
if cfg.show_curve:
fig = plt.figure("Image")
manager = plt.get_current_fig_manager()
manager.window.setGeometry(550, 200, 600, 500)
# This works for QT backend, for other backends, check this ⬃⬃⬃.
# https://stackoverflow.com/questions/7449585/how-do-you-set-the-absolute-position-of-figure-windows-with-matplotlib
plt.xlabel('frames')
plt.ylabel('psnr')
plt.title('psnr curve')
plt.grid(ls='--')
cv2.namedWindow('target frames', cv2.WINDOW_NORMAL)
cv2.resizeWindow('target frames', 384, 384)
cv2.moveWindow("target frames", 100, 100)
if cfg.show_heatmap:
cv2.namedWindow('difference map', cv2.WINDOW_NORMAL)
cv2.resizeWindow('difference map', 384, 384)
cv2.moveWindow('difference map', 100, 550)
with torch.no_grad():
for i, folder in enumerate(video_folders):
dataset = Dataset.test_dataset(cfg, folder)
if not model:
name = folder.split('/')[-1]
fourcc = cv2.VideoWriter_fourcc('X', 'V', 'I', 'D')
if cfg.show_curve:
video_writer = cv2.VideoWriter(f'results/{name}_video.avi', fourcc, 30, cfg.img_size)
curve_writer = cv2.VideoWriter(f'results/{name}_curve.avi', fourcc, 30, (600, 430))
js = []
plt.clf()
ax = plt.axes(xlim=(0, len(dataset)), ylim=(10, 45))
line, = ax.plot([], [], '-b')
if cfg.show_heatmap:
heatmap_writer = cv2.VideoWriter(f'results/{name}_heatmap.avi', fourcc, 30, cfg.img_size)
psnrs = []
for j, clip in enumerate(dataset):
input_np = clip[0:12, :, :]
target_np = clip[12:15, :, :]
input_frames = torch.from_numpy(input_np).unsqueeze(0).cuda()
target_frame = torch.from_numpy(target_np).unsqueeze(0).cuda()
G_frame = generator(input_frames)
test_psnr = psnr_error(G_frame, target_frame).cpu().detach().numpy()
psnrs.append(float(test_psnr))
if not model:
if cfg.show_curve:
cv2_frame = ((target_np + 1) * 127.5).transpose(1, 2, 0).astype('uint8')
js.append(j)
line.set_xdata(js) # This keeps the existing figure and updates the X-axis and Y-axis data,
line.set_ydata(psnrs) # which is faster, but still not perfect.
plt.pause(0.001) # show curve
cv2.imshow('target frames', cv2_frame)
cv2.waitKey(1) # show video
video_writer.write(cv2_frame) # Write original video frames.
buffer = io.BytesIO() # Write curve frames from buffer.
fig.canvas.print_png(buffer)
buffer.write(buffer.getvalue())
curve_img = np.array(Image.open(buffer))[..., (2, 1, 0)]
curve_writer.write(curve_img)
if cfg.show_heatmap:
diff_map = torch.sum(torch.abs(G_frame - target_frame).squeeze(), 0)
diff_map -= diff_map.min() # Normalize to 0 ~ 255.
diff_map /= diff_map.max()
diff_map *= 255
diff_map = diff_map.cpu().detach().numpy().astype('uint8')
heat_map = cv2.applyColorMap(diff_map, cv2.COLORMAP_JET)
cv2.imshow('difference map', heat_map)
cv2.waitKey(1)
heatmap_writer.write(heat_map) # Write heatmap frames.
torch.cuda.synchronize()
end = time.time()
if j > 1: # Compute fps by calculating the time used in one completed iteration, this is more accurate.
fps = 1 / (end - temp)
temp = end
print(f'\rDetecting: [{i + 1:02d}] {j + 1}/{len(dataset)}, {fps:.2f} fps.', end='')
psnr_group.append(np.array(psnrs))
if not model:
if cfg.show_curve:
video_writer.release()
curve_writer.release()
if cfg.show_heatmap:
heatmap_writer.release()
return None
if __name__ == '__main__':
args = parser.parse_args()
test_cfg = update_config(args, mode='test')
test_cfg.print_cfg()
val(test_cfg)
6.应用模式,predict.py
这里很关键,上面只是跑评价,那我们该怎么得到异常的帧呢?论文里说了用psnr这个指标来评判,并且设定阈值需要根据所有psnr的情况给出一个合适的数值,我这里暂时根据上面评价的时候可视化那个psnr曲线图给了30(psnr越小说明越有可能存在异常情况,根据这个规则认定小于阈值的就是异常)
import numpy as np
import os
import shutil
import time
import torch
import argparse
import cv2
from PIL import Image
import io
from sklearn import metrics
import matplotlib.pyplot as plt
from config import update_config
from Dataset import Label_loader
from utils import psnr_error
import Dataset
from models.unet import UNet
parser = argparse.ArgumentParser(description='Anomaly Prediction')
parser.add_argument('--dataset', default='avenue', type=str, help='The name of the dataset to train.')
parser.add_argument('--trained_model', default='avenue_15000.pth', type=str, help='The pre-trained model to evaluate.')
parser.add_argument('--show_curve', default=True, action='store_true',
help='Show and save the psnr curve real-timely, this drops fps.')
parser.add_argument('--show_heatmap', default=True, action='store_true',
help='Show and save the difference heatmap real-timely, this drops fps.')
def val(cfg, model=None):
if model: # This is for testing during training.
generator = model
generator.eval()
else:
generator = UNet(input_channels=12, output_channel=3).cuda().eval()
generator.load_state_dict(torch.load('weights/' + cfg.trained_model)['net_g'])
print(f'The pre-trained generator has been loaded from \'weights/{cfg.trained_model}\'.\n')
video_folders = os.listdir(cfg.test_data)
video_folders.sort()
video_folders = [os.path.join(cfg.test_data, aa) for aa in video_folders]
fps = 0
psnr_group = []
with torch.no_grad():
for i, folder in enumerate(video_folders):
dataset_use = Dataset.predict_dataset(cfg, folder)
psnrs = []
folder_name = folder.split('/')[-1]
save_path = './results/' + folder_name
if os.path.exists(save_path):
pass
else:
os.mkdir(save_path)
for j, clip in enumerate(dataset_use):
input_np = clip['video_clip'][0:12, :, :]
target_np = clip['video_clip'][12:15, :, :]
input_frames = torch.from_numpy(input_np).unsqueeze(0).cuda()
target_frame = torch.from_numpy(target_np).unsqueeze(0).cuda()
G_frame = generator(input_frames)
test_psnr = psnr_error(G_frame, target_frame).cpu().detach().numpy()
psnrs.append(float(test_psnr))
# print(input_np.shape)
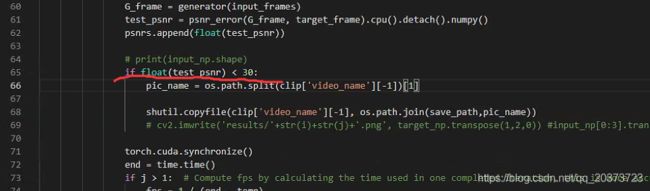
if float(test_psnr) < 20:
pic_name = os.path.split(clip['video_name'][-1])[1]
shutil.copyfile(clip['video_name'][-1], os.path.join(save_path,pic_name))
# cv2.imwrite('results/'+str(i)+str(j)+'.png', target_np.transpose(1,2,0)) #input_np[0:3].transpose(1,2,0)[...,::-1]
torch.cuda.synchronize()
end = time.time()
if j > 1: # Compute fps by calculating the time used in one completed iteration, this is more accurate.
fps = 1 / (end - temp)
temp = end
print(f'\rDetecting: [{i + 1:02d}] {j + 1}/{len(dataset_use)}, {fps:.2f} fps.', end='')
# print(psnrs)
print('\nAll frames were detected, begin to compute AUC.')
if __name__ == '__main__':
args = parser.parse_args()
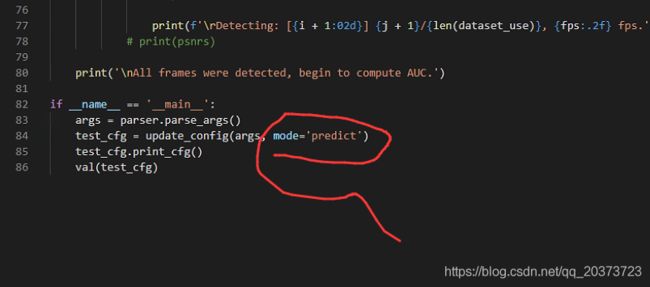
test_cfg = update_config(args, mode='predict')
test_cfg.print_cfg()
val(test_cfg)
1.阈值设置的地方
2.更改测试模式
3.记得新建results文件夹,这个是放结果的地方,没有自动创建,自己创建一下,建在根目录
觉得有用,记得点赞,关注啊!!!