大数据基本操作课程笔记(2)
课程目标
1、镜像master并配置slave1、slave2
2、三台节点互相免密登录
预处理
1、解决桥接模式更换网络无法连接问题
桥接模式就是将主机网卡与虚拟机的网卡利用虚拟网桥进行通信。在桥接的作用下,类似于把物理主机虚拟为一个交换机,所有桥接设置的虚拟机连接到这个交换机的一个接口上,物理主机也同样插在这个交换机当中,所以所有桥接下的网卡与网卡都是交换模式的,相互可以访问而不干扰。
在桥接模式下,虚拟机ip地址需要与主机在同一个网段,如果需要联网,则网关与DNS需要与主机网卡一致。
桥接模式的好处是虚拟机直接接入网络,与更加接近实际操作,坏处是主机每次连接新的网络都需要重新设置ip、网关、DNS
修改ip、网关、DNS
打开主机的网络适配器设置
打开WLAN详细信息
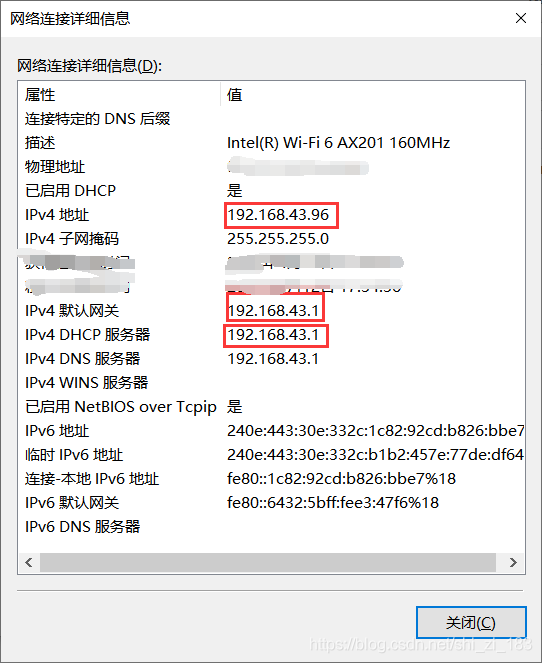
修改虚拟机ip与主机ip位于同一网络,网关与主机网关相同,DNS与主机相同
2、关闭防火墙
临时关闭
systemctl stop firewalld
禁止防火墙自启动
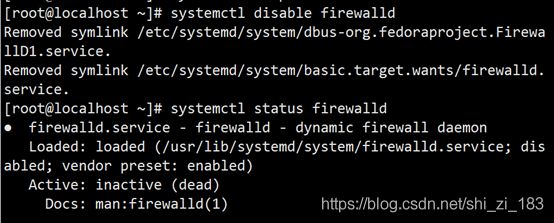
systemctl disable firewalld
查看防火墙状态
systemctl status firewalld
镜像master并配置slave
至此我们已经配置好了master、需要配置子节点slave,但配置过程一样所以我们可以克隆master修改ip来实现slave
注意:slave的mac地址需要重新分配,不可以与master重复
克隆过程取决你虚拟软件,这里使用的是Vbox
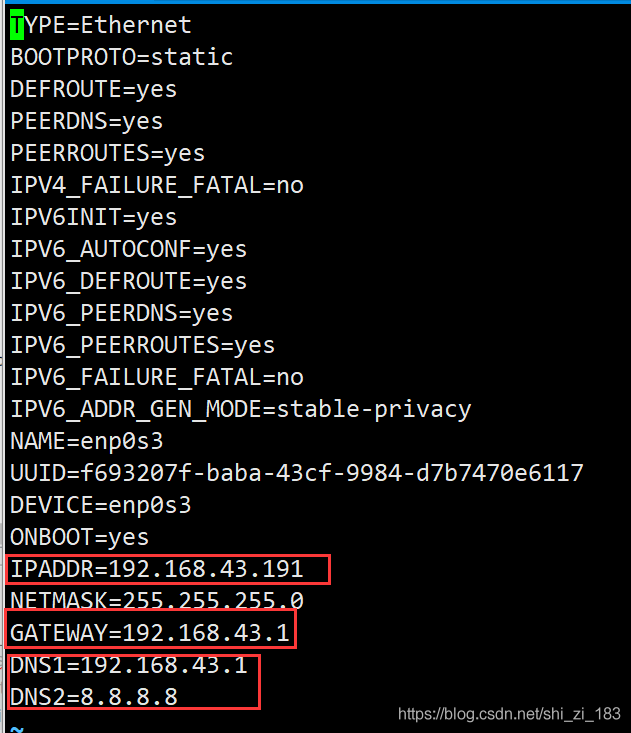
修改slave ip
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
![]()
![]()
重启网络服务
service network restart

成功启动
错误处理
上一步重启可能会失败

这时我们逐步排查问题
首先查看服务状态
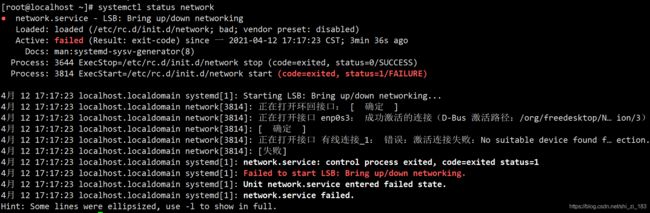
systemctl status network
查看日志文件
cat /var/log/messages | grep network
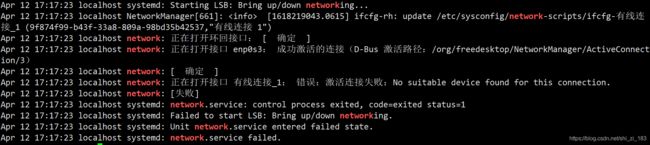
可以看到服务依次启动了环回接口(127.0.0.1)、enp0s3(192.168.43.201)、有线连接
其中有线连接失败了
这个原因是有限连接的mac地址没有更改,但实际mac地址更换了,所以mac地址与实际不匹配
解决方法
1、删除有线连接
因为这里是虚拟机并不使用有线连接所以可以直接将有线连接的配置文件删除了
rm -rf /etc/sysconfig/network-scripts/ifcfg- 有线连接_1
2、修改mac地址
查看虚拟机的网络配置选择有线连接的网卡Realtek PCIe……
记住mac地址
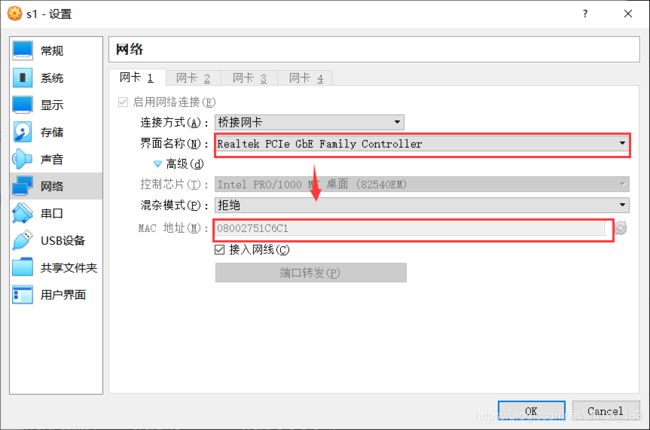
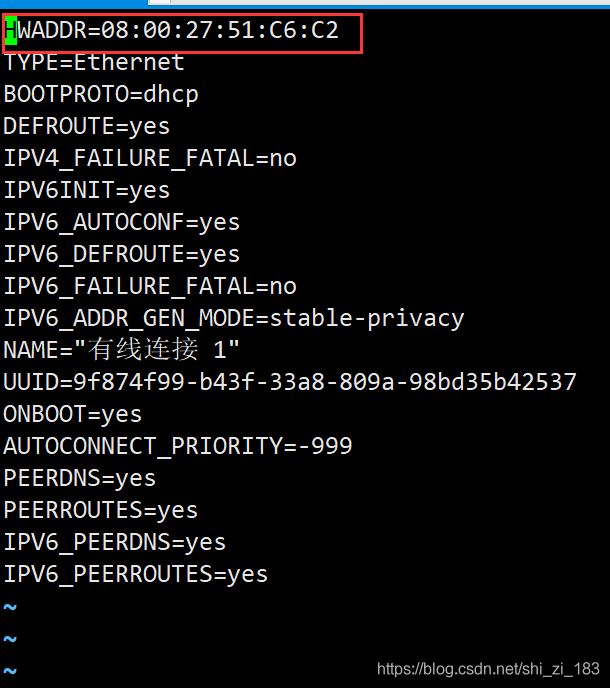
修改有线连接配置文件HWADDR
注意每两位一个冒号
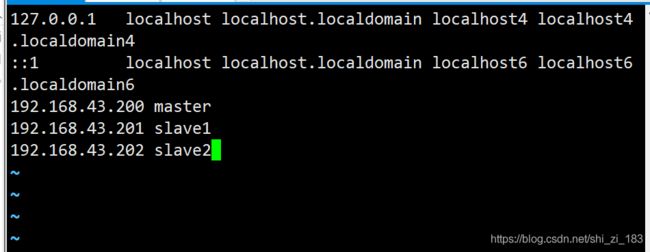
配置各节点的host文件
使主机名可以相互识别。
在master中
vi /etc/hosts
在slave1,slave2中同理
验证

使三台节点可以通过主机名相互ping通
配置免密登录
原理
一台电脑生成一个密钥对,包含一个公钥一个私钥,私钥是用来证明自己身份的,公钥是展示给其他人验证私钥正确的工具,所以记录了公钥的机器可以被拥有私钥的机器免密登录。
所以私钥是私人的,不可转交否则可能会被其他机器冒充。
权限配置
为了安全考虑,要保证.ssh和authorized_keys都只有用户自己有写权限,否则公钥失效。
基本步骤
令master,slave1,slave2,分别生成密钥对,取所有公钥存储在master中,这样所有的节点就可以免密登录master了,接着将master的公钥存储文件复制给slave1和slave2,至此完成配置。
切换用户
因为我们配置免密登录的目的是给hadoop集群使用,而hadoop软件使用的用户是hadoop用户所以我们应该配置hadoop用户的免密登录,而不是root用户。
su hadoop
cd ~
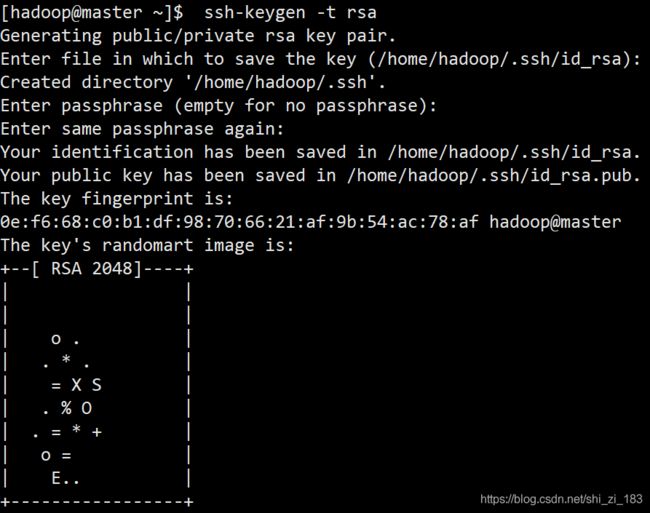
生成密钥对
master:
ssh-keygen -t rsa
slave1:同理

slave2:同理

使master获取所有子节点公钥
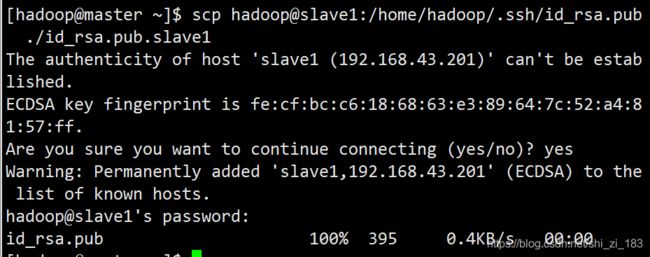
获取slave1的公钥
scp hadoop@slave1:/home/hadoop/.ssh/id_rsa.pub ./id_rsa.pub.slave1
获取slave2的公钥
scp hadoop@slave2:/home/hadoop/.ssh/id_rsa.pub ./id_rsa.pub.slave2
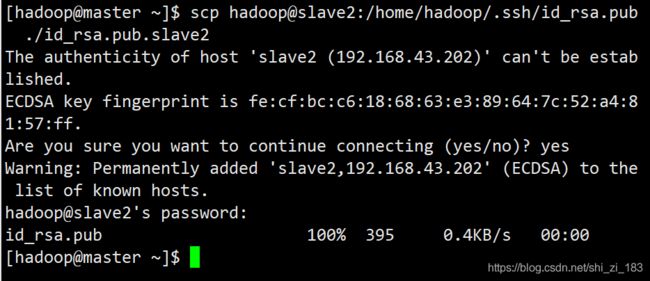
至此我们有了所有节点的公钥

写入公钥
将master公钥写入:
cat ./.ssh/id_rsa.pub >> ./.ssh/authorized_keys
其中>>是追加重定向,将cat得到的内容追加到authorized_keys中,这个文件是新建的,主要名字不要拼错不然无法生效。
将slave1,slave2公钥写入:
cat ./id_rsa.pub.slave1 >> ./.ssh/authorized_keys
cat ./id_rsa.pub.slave2 >> ./.ssh/authorized_keys
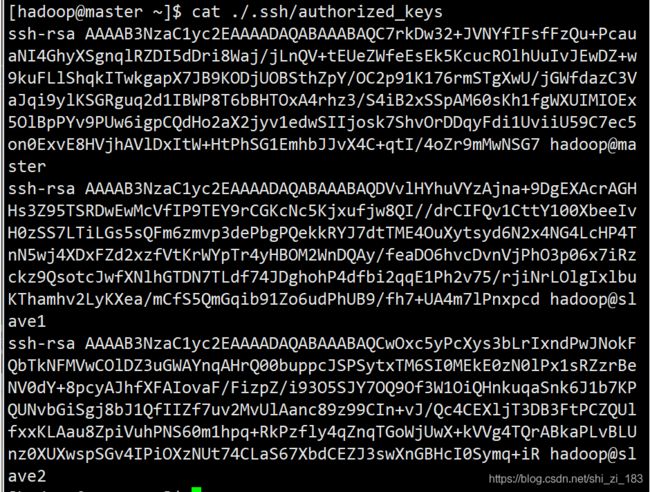
查看写入是否成功
cat ./.ssh/authorized_keys
可以看到三行加密字符串,以ssh-rsa开头,以hadoop@主机名结尾(主要查看这是是否为hadoop,这里如果是root说明之前没有切换用户)
更改authorized_keys权限
chmod 700 ./.ssh/authorized_keys
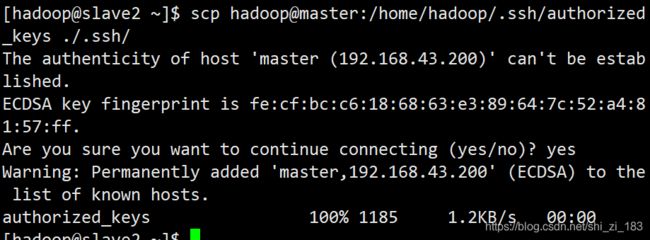
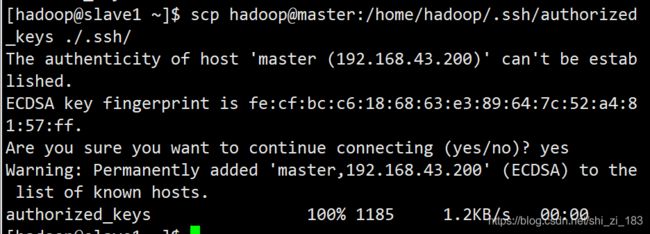
令slave1、slave2获取master储存文件
slave1:
scp hadoop@master:/home/hadoop/.ssh/authorized_keys ./.ssh/
slave2: