机器学习-45-ML-01-Meta Learning(元学习)
文章目录
-
- Meta Learning
-
- Introduction(介绍)
- Meta Learning的建模思路
-
- 总体介绍
- 第一步
- 第二步
- 第三步
- Meta Learning实例:Omniglot
- Techniques Today
-
- MAML(模型无关元学习)
-
- MAML
- MAML vs Model Pre-training
- MAML的trick
- Warning of Math
- MAML – Real Implementation(步骤可视化)
- MAML Toy Example
- MAML 应用:Translation
- Reptile(简单介绍)
- MAML vs Model Pre-training vs Reptile
- More about Meta Learning
Meta Learning
元学习,meta-learning,又叫learning to learn,直译即为学习如何学习,从中文字面上来理解,似乎这类算法更接近人类的学习方式——触类旁通,举一反三。而传统的深度学习方法虽然功力强大,但是框架无外乎都是从头开始学习(训练),即learning from scratch,对算力和时间都是更大的消耗和考验。
比如说GANs,GANs本身是一个特别吃数据集的模型,从某种意义上来说,数据集的好坏对最后生成效果的影响,不亚于甚至高于生成模型本身的设计对最后生成效果的影响。造成这一现象的原因是,GANs学习的本质是拟合数据的潜分布,而数据潜分布很大程度上由训练数据所具有的样本广度和质量来决定,因此GANs的训练效果容易受到来自训练数据的质量的影响。
如何摆脱这种GANs对于数据集的过度依赖呢?一个比较好的检测方法是在少样本学习(few-shot learning)上检验模型的学习效果。但是直接用GANs架构是很难实现少样本学习的,原因是在数据量大的时候,充足的训练样本能够让判别器精准地找到真假样本的划分界线,从而让生成器拟合出精确的生成分布,但是在数据量少的时候,要想准确地拟合数据的潜分布就会变得比较困难。
Meta learning为解决这一问题提供了比较好的方法,首先因为meta learning已经被证明在少样本学习上取得了较好的效果,另外meta learning的方法也比较符合GANs的学习需求。为何这么说呢?meta learning的目标是学习如何去学习,换言之,它能够依靠对数据集规律的探索去制定学习策略,从而将传统GANs的训练过程由设计模型->寻找数据->验证模型,变为寻找数据->设计模型->验证模型,这对于我们解决GANs训练中的数据不匹配以及数据缺乏问题带来很大的帮助。
Meta learning的诞生促使机器学习向另一侧面突进,以更接近人类和更具效率的方式实现人工智能,对于GANS来说,将GANs的传统训练思维,由用数据去匹配模型,转变为用模型去匹配数据,为解决生成模型的少样本学习问题提供了突破口。
Meta learning包括Zero-Shot/One-Shot/Few-Shot 学习,模型无关元学习(Model Agnostic Meta Learning)和元强化学习(Meta Reinforcement Learning)等,这篇文章主要说的是元学习中的两大经典算法——MAML和Reptile。
Introduction(介绍)
Meta Learning被称作元学习,不同于Machine Learning的目标是让机器能够学习,Meta Learning则是要让机器学会如何去学习。

举例来说,机器已经在过去的100个任务上进行了学习,现在我们希望,机器能够基于过去100个任务学习的经验,变成一个更厉害的学习者,这样当在第101个新任务到来之时,机器能够更快地学习。值得注意的是,机器之所以能够学习地更快并不是依赖于在旧任务中已获取的“知识”,而是机器学到了如何去更好获取知识的方法,并将这一方法应用于新任务当中,从而较快地提升学习效率。
以上图为例,假设前99个学习任务都是各种辨识任务,例如语音辨识、图像辨识等,在前99个任务学习完成之后,我们给机器一个新的学习任务,而这个新的学习任务与前99个任务没有任何关联,譬如是一个文本分类任务。而现在,Meta Learning的目的就是希望能够通过前99个辨识任务的学习让机器在新的文本分类任务上学习得更好,也就是说,机器在前面的学习中不仅仅学到了如何解决某些特定的任务,而是学习到了学习本身这件事情,从而能提升自己在面对新任务上的学习能力。所以,Meta Learning就是一门研究如何让机器学会更好地学习的新兴研究方向。
Meta Learning的建模思路
总体介绍
前篇提及的概念描述可能依然比较抽象,下面我们用具体的模型架构来解释一下Meta Learning实际上在做的事情。

首先,上图描述的是传统机器学习在做的事情——由人来设计一套学习算法,然后这个算法会输入一堆训练资料,通过长时间的训练得到算法里的参数,这堆参数拟合出一个函数 f ∗ f^* f∗ ,然后用测试资料来测试这个 f ∗ f^* f∗,如果效果达标就证明机器学到了该特定任务的实现函数 f ∗ f^* f∗ 。
而Meta Learning做的事情与上述描述不同的地方在于,将其中由人来设计学习方法的过程,改成了由机器来设计一套学习方法。

如上图所示,如果将原本机器学习中的训练资料记为 D t r a i n D_{train} Dtrain ,那么在Meta Learning中的训练资料变为一堆 D t r a i n D_{train} Dtrain和一堆 f ∗ f^* f∗ 的组合,然后现在机器要求解的结果不再是 f ∗ f^* f∗ ,而是一个新的函数 F F F,这个 F F F决定在给定 D t r a i n D_{train} Dtrain的情况下 f ∗ f^* f∗的结果。
简言之,如果机器学习的定义表述为:根据资料找一个函数f的能力,如下图所示:

那么Meta Learning的定义就可以表述为:根据资料找一个找一个函数f的函数 F 的能力,如下图所示:
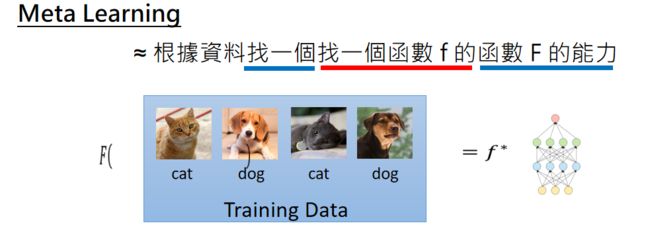
就是machine learning和meta learning都是要找一个function,但是两者所要寻找的function是不相同的,前者寻找的是解决一个问题的f,后者寻找的是生成f的F。
F的输入是训练数据,输出是解决一个小问题的f。

机器学习的方法可以简单理解为三步:
- 找到一个f的集合
- 找到一个判别f的方法(loss function)
- 在这个集合中寻找最好的f

我们meta learning的方法和machine learning的方法是十分相似的,也是三步:
- 找到一个learning algorithm的集合
- 之后寻找到一个判别learning algorithm好坏的方法
- 最后得到一个最好的learning algorithm做为F
现在,清楚了Meta Learning的架构搭建思路以后,我们就可以顺着该思路一步一步寻找解决方案。
第一步
首先第一步要做的,是准备Meta Learning的训练资料。前面说过,Meta Learning的训练资料是一堆 D t r a i n D_{train} Dtrain 和一堆 f ∗ f^* f∗ 的组合,显然一堆 D t r a i n D_{train} Dtrain 是很好准备的,于是重点在于,一堆 f ∗ f^* f∗ 该如何准备。事实上, f ∗ f^* f∗ 本身是一个抽象概念,我们需要知道它的具体实例是什么,不妨以传统的神经网络为例来介绍。

上图是大家都熟悉的梯度下降算法,它的流程可以简述为:
设计一个网络架构->给参数初始化->读入训练数据批次->计算梯度->基于梯度更新参数->进入下一轮训练->……
对于每一个具体的任务来说,它的全部算法流程就构成了一个 f ∗ f^* f∗ ,也就是说,(如图中红色框架)每当我们采用了一个不同的网络架构,或使用了不同的参数初始化,或决定了不同的参数更新方式时,我们都在定义一个新的 f ∗ f^* f∗ 。所以,针对梯度下降算法来说,Meta Learning的最终学习成果是在给定训练资料的条件下,机器能够找到针对这笔资料的SGD最佳训练流程( f b e s t ∗ f^*_{best} fbest∗)。因此,前边我们探讨的为Meta Learning准备的 f ∗ f^* f∗ ,实际上是由包含尽量多和丰富的组合方式的不同训练流程来组成的。
要更清晰地理解元学习,需要搞清其与传统深度学习、终身学习(life-long learning)、迁移学习中的model pre-training的区别与联系,尤其是与model pre-training的区别,这一点将在后文不断强调。终身学习的目标是学到一个模型可以做所有的任务,有点“一招鲜吃遍天”的意味,而元学习是掌握其他任务的内在原理从而举一反三,有点“学好数理化走遍天下都不怕”的意味。用我们这一行的话来理解元学习就是,当一个程序员掌握了基本的C++、python、Java,后面不管学什么语言都能迅速掌握,这就是元学习算法的魅力。
那元学习与传统深度学习的联系在哪儿呢?注意到红色方框中的东西都是人为设计定义的,其实元学习的目标就是去自动学习或者说代替方框中的东西,不同的代替方式就发明出不同的元学习算法。
比如说对于一个新任务的初始参数部分来说,如果能够提前获得一个来自其他任务学习到的较好的初始参数,可能经过很快的训练就能收敛到全局最优,也就是fast adaption。
第二步
在说这一步之前,我们先来看一下元学习的数据集:

一般的机器学习任务是单任务的,所以数据集是一堆训练数据,和测试数据(右上角图)。
但是在meta learning的任务是多任务的,所以在这种情况下,我们需要做的是将很多的任务分为训练任务和测试任务,之后每一个小的任务都有训练数据和测试数据。比如说一共有十个任务,我们将其中的八个作为是训练任务,剩余的两个作为测试任务,其中每一个任务都有自己的测试数据和训练数据。以此来检测meta learning的学习能力。我们为了名字混淆,我们将每一个任务的训练数据称为support set,并且将每一个人物的测试数据称为query set。
和机器学习一样,当我们的元学习中的训练任务很多的时候,我们可以将其中一部分切出来作为验证任务:validation tasks。
接下来我们来说第二步,这一步要做的,就是设计评价函数 F好坏的指标。
具体来说,F可以选择各种不同的训练流程 f ∗ f^* f∗ ,如何评价F找到的现有流程 f ∗ f^* f∗,以及如何提升 f ∗ f^* f∗,这是Meta Learning中比较重要的部分。
我们先来说明Meta Learning中函数F的损失函数的定义。

如上图所示,在Task1中,函数F学习到的训练算法是 f 1 f^1 f1 ,而Task1中的测试集在上 f 1 f^1 f1的测试结果被记作在Task1上的损失值 f 1 f^1 f1(注意测试结果不仅仅可以是分类任务中的分类损失,也可以定义为损失下降的速率等等,取决于我们希望F学习到什么样的算法效果);
同理,在Task2中的测试集在 f 2 f^2 f2上的测试结果记作在Task2上的损失值 f 2 f^2 f2。最终,函数F的损失函数就定义为所有Task上的损失的总和:
L ( F ) = ∑ n = 1 N l n L(F) = \sum_{n=1}^Nl^n L(F)=n=1∑Nln
第三步

上面一步我们已经求得了函数F的损失函数,即所有Task上的损失的总和:
L ( F ) = ∑ n = 1 N l n L(F) = \sum_{n=1}^Nl^n L(F)=n=1∑Nln
这一步我们就是要找到一个 F ∗ F^* F∗ ,使得L最小:
F ∗ = a r g min F L ( F ) F^* = arg\min\limits_FL(F) F∗=argFminL(F)
也就是说我们用梯度下降的方法不断的更新F的参数,得到一个最好的 F ∗ F^* F∗ ,之后我们将训练好的 F ∗ F^* F∗ 放入到测试任务集中进行测试,比如第一个测试任务是一个自行车汽车识别器(上图右),我们将小的训练数据放入到 F ∗ F^* F∗ 中,之后得到一个分类器 f ∗ f^* f∗ ,之后我们将测试数据放入到f中,得到最终的loss,作为这次测试的结果。
Meta Learning实例:Omniglot
https://github.com/brendenlake/omniglot

我们训练meta learning时候用到的数据集是一个叫做Omniglot的数据集,这里面一共有1623种不同的字符,每一个字符有20个例子,20个例子都是这个字符对应的不同的人写下的例子。

我们这个数据集究竟应该如何去使用呢!我们将整个数据集分为很多的N-ways K-shot classfication的任务。N-ways就是分为N类,K-shot就是每一类种有K个样本。就是一个总共类别有N类,每一类有K个样本的分类器。
举个例子20ways 1shot就是总共20类,每一类有1个样本的分类器。上图就是一个20ways1shot的分类器,训练集就是20类,每一类就只有一张图片的图片集。测试集就是一张图片,我们可以看到测试集和训练集中最下面一行中间的那个是一列的。
在我们使用Omniglot数据集的时候,我们先将其中的1623类拆分为训练集和测试集,之后我们再在训练集中采样出N类,每一类采样K个样本作为我们的一个分类任务,当然我们的训练集可以被拆分组合为很多分类任务的。
我们测试集是在测试类别中采样出n个,每一类蔡阳初k个样本作为我们的测试分类任务。当我们的F在测试集中被训练好以后,我们就开始将其放入到test中进行测试。
Techniques Today

下面我们来介绍两种meta learning的方法,分别是maml和reptile。
-
Model Agnostic Meta Learning,简称MAML,发音酷似英文中的哺乳动物mammal,中文名称是模型无关元学习,从MAML的英文名字我们可以发现,这是和模型无关的。MAML是2017年的paper,是近两年元学习领域的典型代表,
Chelsea Finn, Pieter Abbeel, and Sergey Levine, “Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks”, ICML, 2017
-
Reptile 的中文名称是爬行动物,它是什么的缩写呢?我也不知道!可能是因为MAML发音酷似哺乳动物,作者为了凑梗而硬叫这个名字的吧。 这是2018年的paper。
Alex Nichol, Joshua Achiam, John Schulman, On First-Order Meta-Learning Algorithms, arXiv, 2018
MAML(模型无关元学习)
MAML
MAML算法想要解决的问题是,对于F在每一个任务中学习到的 f f f,规定 f f f只负责决定参数的赋值方式,而不涉及模型的架构,也不改变参数更新的方式。也就是说,MAML中的的 f f f 网络结构和更新方式都是提前固定的,MAML要解决的是如何针对不同任务为网络赋不同的初始值,换种说法就是想让机器自己学会初始化参数。
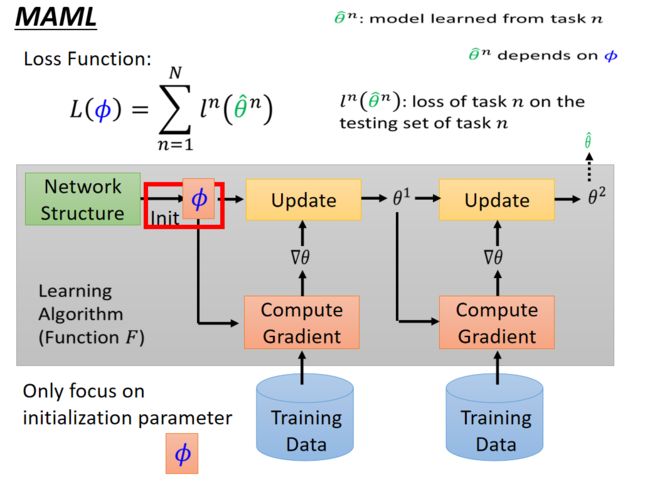
如上图所示, f f f只需考虑参数的初始化方式。我们用 θ n \theta^n θn 来表示第n个任务训练出来的初始化参数 θ \theta θ ,然而每一个 θ \theta θ都和这个学习算法有关。之后用的出来的 θ n \theta_n θn 去跑对应任务的数据,得到的loss function就是,把所有任务的loss function ln(θn)加在一起就是最后的损失函数L。
假设当前参数的初始化为 ϕ \phi ϕ,将 ϕ \phi ϕ应用于所有的训练任务中,并将所有任务最终训练结束后的参数记作 θ ^ n \hat{\theta}^n θ^n(n表示第m个任务,每一个 θ ^ \hat{\theta} θ^都和这个学习算法有关),然后将该参数作为当前任务测试的初始化参数,该参数下的测试loss记作 l n ( θ ^ n ) l^n(\hat{\theta}^n) ln(θ^n)。把所有任务的loss加在一起就是最后的损失函数。于是,当前的初始化参数 ϕ \phi ϕ的损失函数就表示为:
L ( ϕ ) = ∑ n = 1 N l n ( θ ^ n ) L(\phi) = \sum_{n=1}^Nl^n(\hat{\theta}^n) L(ϕ)=n=1∑Nln(θ^n)

接下来,我们需要求解 ϕ \phi ϕ ,使得:
ϕ ∗ = a r g max ϕ L ( ϕ ) \phi^* = arg\max\limits_{\phi}L(\phi) ϕ∗=argϕmaxL(ϕ)
将 ϕ \phi ϕ 放入梯度下降算法中,得到:
ϕ ← ϕ − η ▽ ϕ L ( ϕ ) \phi \leftarrow \phi - \eta▽_{\phi}L(\phi) ϕ←ϕ−η▽ϕL(ϕ)
MAML vs Model Pre-training
可能很多人看到meta learning的更新参数方法以后就会想到迁移学习中的model pre-training(假设task2的训练集太小不好训练,我们将和task2相似的task1作为先导数据集,进行训练,将训练的结果作为task2的初始化)。那么这两种方法有什么区别呢?
- meta learning中的参数 θ ^ \hat{\theta} θ^ 是模型刚刚训练生成的,通过训练之后的参数用测试集求loss;
- 但是model pre-training的参数就是当前使用的模型的参数,也就是直接在原有基础上求loss没有经过训练。
我觉得关于Model pre-training可以参考一下之前讲迁移学习时候的Multitask Learning(多任务学习) 机器学习-44-Transfer Learning(迁移学习)
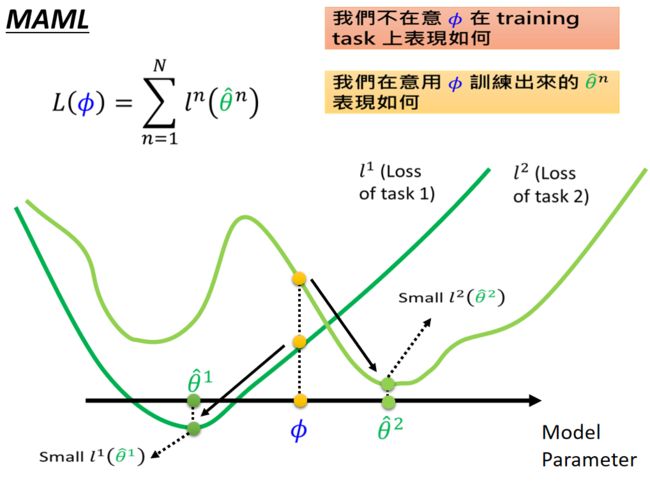
MAML方法中在意的不是参数 ϕ \phi ϕ 在task中的表现如何,而是在乎 ϕ \phi ϕ 在task中经过训练得到的 θ ^ \hat{\theta} θ^ 的表现究竟如何。比如上图中参数 ϕ \phi ϕ 在task1和task2中都不是最好的参数,但是却是一个比较好的 θ ^ \hat{\theta} θ^ ,就是因为参数 ϕ \phi ϕ 可以在各自task中训练从而得到最好的参数 θ ^ \hat{\theta} θ^ 。可以在task1中经过训练,到 θ ^ 1 \hat{\theta}^1 θ^1;在task2中经过训练,得到 θ ^ 2 \hat{\theta}^2 θ^2。所以这就是一个好的 ϕ \phi ϕ。

但是在model pre-train的方法中,我们想要的好的参数 ϕ \phi ϕ 就是在当下任务中表现好的参数,比如这个 ϕ \phi ϕ 在task1中表现还不错,在task2中表现也比较良好,这就是一个比较好的参数。但是这个参数 ϕ \phi ϕ 经过训练以后得到的 θ \theta θ 却不一定比较好,所以model pre-train的方法比较看重的是当前的表现,而MAML则更看重未来的表现。

总结一下就是:
-
Model Pre-training方法想要得到的参数 ϕ \phi ϕ 就是在任何task上都表现良好的参数。但是MEML想要得到的参数是在某一任务task中经过训练集训练所能得到的比较好的参数。
-
Model Pre-training看重的是现在的表现,但是Meml看重的是未来的潜力。
MAML的trick
MAML为了更快地计算出上式的结果,做了两处计算上的调整。

首先,如上图所示,我们通常希望MAML可以做到的是:得到的参数 ϕ \phi ϕ 在子任务task中只更新一次就得到最好的 θ ^ \hat{\theta} θ^,即只走一次梯度下降:
θ ^ n = ϕ − ϵ ▽ ϕ l n ( ϕ ) \hat{\theta}^n = \phi - \epsilon ▽_{\phi}l^n(\phi) θ^n=ϕ−ϵ▽ϕln(ϕ)
那么为什么要这么做呢?理由如下:
- 我们的meta learning有很多的任务,假设每一个任务都要更新很多次参数的话,会很慢,所以我们为了追求速度,就让模型只更新一次就好。
- 我们本来的想法就是希望参数 ϕ \phi ϕ 仅仅更新一次就得到这个子任务task的参数 θ \theta θ
- 当我们训练的时候,我们仅仅是让其更新一次,但是当我们真实测试的时候,我们往往可以更新无数次
- 我们的few-shot learning本身就是没有多少训练集,所以我们往往希望可以一次更新就得到参数。
总之就是:更新一次参数能加快训练的时间,如果模型只需训练一次就能达到好的效果,那么这样的训练初始参数基本上能符合好的参数,不过,在测试资料上依然需要训练多次以检验该初始参数的真正效果。
MAML的第二处调整是,对于 ▽ ϕ L ( ϕ ) ▽_{\phi}L(\phi) ▽ϕL(ϕ) 的实际计算做了简化,由于
▽ ϕ L ( ϕ ) = ▽ ϕ ∑ n = 1 N l n ( θ ^ n ) = ∑ n = 1 N ▽ ϕ l n ( θ ^ n ) ▽_{\phi}L(\phi) = ▽_{\phi}\sum_{n=1}^Nl^n(\hat{\theta}^n) = \sum_{n=1}^N▽_{\phi}l^n(\hat{\theta}^n) ▽ϕL(ϕ)=▽ϕn=1∑Nln(θ^n)=n=1∑N▽ϕln(θ^n)
进一步 ▽ ϕ l ( θ ^ ) ▽_{\phi}l(\hat{\theta}) ▽ϕl(θ^) 可简化为;
▽ ϕ l ( θ ^ ) = [ ∂ l ( θ ^ ) ∂ ϕ 1 ∂ l ( θ ^ ) ∂ ϕ 2 ⋮ ∂ l ( θ ^ ) ∂ ϕ i ⋮ ] = [ ∂ l ( θ ^ ) ∂ θ ^ 1 ∂ l ( θ ^ ) ∂ θ ^ 2 ⋮ ∂ l ( θ ^ ) ∂ θ ^ i ⋮ ] = ▽ θ ^ l ( θ ^ ) ▽_{\phi}l(\hat{\theta}) = \left[ \begin{matrix} \frac{\partial l(\hat{\theta})}{\partial \phi_1} \\ \frac{\partial l(\hat{\theta})}{\partial \phi_2} \\ \vdots \\ \frac{\partial l(\hat{\theta})}{\partial \phi_i}\\ \vdots \end{matrix}\right] = \left[ \begin{matrix} \frac{\partial l(\hat{\theta})}{\partial \hat{\theta}_1} \\ \frac{\partial l(\hat{\theta})}{\partial \hat{\theta}_2} \\ \vdots \\ \frac{\partial l(\hat{\theta})}{\partial \hat{\theta}_i}\\ \vdots \end{matrix}\right] = ▽_{\hat{\theta}}l(\hat{\theta}) ▽ϕl(θ^)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡∂ϕ1∂l(θ^)∂ϕ2∂l(θ^)⋮∂ϕi∂l(θ^)⋮⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡∂θ^1∂l(θ^)∂θ^2∂l(θ^)⋮∂θ^i∂l(θ^)⋮⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤=▽θ^l(θ^)
没看懂没关系,我们下面有具体的数学推导!
Warning of Math

看上图左上角,就是我们上面提到的三步要做的任务:
-
对于采样出来的所有任务 ,在support set上计算梯度并更新参数,只更新一次:
θ ^ = ϕ − ϵ ▽ ϕ l ( ϕ ) \hat{\theta} = \phi-\epsilon▽_{\phi}l(\phi) θ^=ϕ−ϵ▽ϕl(ϕ) -
计算所有任务在query set上的损失之和:
L ( ϕ ) = ∑ n = 1 N l n ( θ ^ n ) L(\phi) = \sum_{n=1}^Nl^n(\hat{\theta}^n) L(ϕ)=n=1∑Nln(θ^n) -
GD更新初始化参数
ϕ ← ϕ − η ▽ ϕ L ( ϕ ) \phi \leftarrow \phi - \eta▽_{\phi}L(\phi) ϕ←ϕ−η▽ϕL(ϕ)
前面两步还好,主要是第三步的梯度并不是太好求,因此我们要进行优化!
第三步中的梯度 ▽ ϕ L ( ϕ ) ▽_{\phi}L(\phi) ▽ϕL(ϕ)根据第二步中的式子,可以化为:
▽ ϕ L ( ϕ ) = ▽ ϕ ∑ n = 1 N l n ( θ ^ n ) = ∑ n = 1 N ▽ ϕ l n ( θ ^ n ) \bigtriangledown_{\phi}L(\phi) = \bigtriangledown_{\phi}\sum_{n=1}^Nl^n(\hat{\theta}^n) = \sum_{n=1}^N\bigtriangledown_{\phi}l^n(\hat{\theta}^n) ▽ϕL(ϕ)=▽ϕn=1∑Nln(θ^n)=n=1∑N▽ϕln(θ^n)
不妨观察一下 ▽ ϕ l n ( θ ^ n ) \bigtriangledown_{\phi}l^n(\hat{\theta}^n) ▽ϕln(θ^n)的展开式:
▽ ϕ l ( θ ^ ) = [ ∂ l ( θ ^ ) ∂ ϕ 1 ∂ l ( θ ^ ) ∂ ϕ 2 ⋮ ∂ l ( θ ^ ) ∂ ϕ i ⋮ ] ▽_{\phi}l(\hat{\theta}) = \left[ \begin{matrix} \frac{\partial l(\hat{\theta})}{\partial \phi_1} \\ \frac{\partial l(\hat{\theta})}{\partial \phi_2} \\ \vdots \\ \frac{\partial l(\hat{\theta})}{\partial \phi_i}\\ \vdots \end{matrix}\right] ▽ϕl(θ^)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡∂ϕ1∂l(θ^)∂ϕ2∂l(θ^)⋮∂ϕi∂l(θ^)⋮⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤
而 l ( θ ^ ) l(\hat{\theta}) l(θ^) 与的 ϕ i \phi_i ϕi具体关系是:

由此可以得到 ▽ ϕ l n ( θ ^ n ) \bigtriangledown_{\phi}l^n(\hat{\theta}^n) ▽ϕln(θ^n) 的具体计算式为:
∂ l ( θ ^ ) ∂ ϕ i = ∑ j ∂ l ( θ ^ ) ∂ θ ^ j ∂ θ ^ ∂ ϕ i \frac{\partial l(\hat{\theta})}{\partial \phi_i} = \sum_{j}\frac{\partial l(\hat{\theta})}{\partial \hat{\theta}_j}\frac{\partial\hat{\theta}}{\partial \phi_i} ∂ϕi∂l(θ^)=j∑∂θ^j∂l(θ^)∂ϕi∂θ^
很明显,上式的第一项 ∂ l ( θ ^ ) ∂ θ ^ j \frac{\partial l(\hat{\theta})}{\partial \hat{\theta}_j} ∂θ^j∂l(θ^)是容易计算的,因为它直接取决于 l l l 函数的定义是什么。下面我们来求解第二项 ∂ θ ^ ∂ ϕ i \frac{\partial\hat{\theta}}{\partial \phi_i} ∂ϕi∂θ^

将 θ ^ j \hat{\theta}_j θ^j 带回到 θ ^ j = ϕ − ϵ ▽ ϕ l ( ϕ ) \hat{\theta}_j = \phi-\epsilon\bigtriangledown_{\phi}l(\phi) θ^j=ϕ−ϵ▽ϕl(ϕ) 中,得到:
θ ^ j = ϕ j − ϵ ∂ l ( ϕ ) ∂ ϕ j \hat{\theta}_j = \phi_j-\epsilon\frac{\partial l(\phi)}{\partial\phi_j} θ^j=ϕj−ϵ∂ϕj∂l(ϕ)
-
当 i ≠ j i ≠ j i=j时:
∂ θ ^ j ∂ ϕ i = − ϵ ∂ l ( ϕ ) ∂ ϕ i ∂ ϕ j ≈ 0 \frac{\partial\hat{\theta}_j}{\partial\phi_i} = -\epsilon\frac{\partial l(\phi)}{\partial \phi_i\partial\phi_j} ≈ 0 ∂ϕi∂θ^j=−ϵ∂ϕi∂ϕj∂l(ϕ)≈0 -
当 i = j i=j i=j时:
∂ θ ^ j ∂ ϕ i = 1 − ϵ ∂ l ( ϕ ) ∂ ϕ i ∂ ϕ j ≈ 1 \frac{\partial\hat{\theta}_j}{\partial\phi_i} =1 -\epsilon\frac{\partial l(\phi)}{\partial \phi_i\partial\phi_j} ≈ 1 ∂ϕi∂θ^j=1−ϵ∂ϕi∂ϕj∂l(ϕ)≈1
现在的问题是,由于上式含有二次微分,并不好计算,MAML提出将二次微分项 ∂ l ( ϕ ) ∂ ϕ i ∂ ϕ j \frac{\partial l(\phi)}{\partial \phi_i\partial\phi_j} ∂ϕi∂ϕj∂l(ϕ)直接舍弃掉(这种仅保留一次微分项的方法叫做“first-order approximation”(一阶近似))。
舍弃二次微分项之后的计算结果就变成了:
∂ θ ^ j ∂ ϕ i = { 0 , i ≠ j 1 i = j \frac{\partial \hat{\theta}_j}{\partial \phi_i}=\left\{ \begin{array}{rcl} 0 &, i≠j \\ 1 & i=j \end{array} \right. ∂ϕi∂θ^j={ 01,i=ji=j
带回到 ▽ ϕ l n ( θ ^ n ) \bigtriangledown_{\phi}l^n(\hat{\theta}^n) ▽ϕln(θ^n)的计算式中,得到:
∂ l ( θ ^ ) ∂ ϕ i = ∑ j ∂ l ( θ ^ ) ∂ θ ^ j ∂ θ ^ j ∂ ϕ i ≈ ∂ l ( θ ^ ) ∂ θ ^ i \frac{\partial l(\hat{\theta})}{\partial \phi_i} = \sum_j\frac{\partial l(\hat{\theta})}{\partial \hat{\theta}_j}\frac{\partial\hat{\theta}_j}{\partial \phi_i} ≈ \frac{\partial l(\hat{\theta})}{\partial\hat{\theta}_i} ∂ϕi∂l(θ^)=j∑∂θ^j∂l(θ^)∂ϕi∂θ^j≈∂θ^i∂l(θ^)
进而得到最开始 ▽ ϕ l n ( θ ^ n ) \bigtriangledown_{\phi}l^n(\hat{\theta}^n) ▽ϕln(θ^n)的展开式变为:
▽ ϕ l ( θ ^ ) = [ ∂ l ( θ ^ ) ∂ ϕ 1 ∂ l ( θ ^ ) ∂ ϕ 2 ⋮ ∂ l ( θ ^ ) ∂ ϕ i ⋮ ] = [ ∂ l ( θ ^ ) ∂ θ ^ 1 ∂ l ( θ ^ ) ∂ θ ^ 2 ⋮ ∂ l ( θ ^ ) ∂ θ ^ i ⋮ ] = ▽ θ ^ l ( θ ^ ) ▽_{\phi}l(\hat{\theta}) = \left[ \begin{matrix} \frac{\partial l(\hat{\theta})}{\partial \phi_1} \\ \frac{\partial l(\hat{\theta})}{\partial \phi_2} \\ \vdots \\ \frac{\partial l(\hat{\theta})}{\partial \phi_i}\\ \vdots \end{matrix}\right] = \left[ \begin{matrix} \frac{\partial l(\hat{\theta})}{\partial \hat{\theta}_1} \\ \frac{\partial l(\hat{\theta})}{\partial \hat{\theta}_2} \\ \vdots \\ \frac{\partial l(\hat{\theta})}{\partial \hat{\theta}_i}\\ \vdots \end{matrix}\right] = ▽_{\hat{\theta}}l(\hat{\theta}) ▽ϕl(θ^)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡∂ϕ1∂l(θ^)∂ϕ2∂l(θ^)⋮∂ϕi∂l(θ^)⋮⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡∂θ^1∂l(θ^)∂θ^2∂l(θ^)⋮∂θ^i∂l(θ^)⋮⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤=▽θ^l(θ^)
最后我们的梯度优化项就变成了:
▽ ϕ L ( ϕ ) = ▽ ϕ ∑ n = 1 N l n ( θ ^ n ) = ∑ n = 1 N ▽ ϕ l n ( θ ^ n ) = ∑ n = 1 N ▽ θ ^ n l n ( θ ^ n ) \bigtriangledown_{\phi}L(\phi) = \bigtriangledown_{\phi}\sum_{n=1}^Nl^n(\hat{\theta}^n) = \sum_{n=1}^N\bigtriangledown_{\phi}l^n(\hat{\theta}^n) = \sum_{n=1}^N\bigtriangledown_{\hat{\theta}^n}l^n(\hat{\theta}^n) ▽ϕL(ϕ)=▽ϕn=1∑Nln(θ^n)=n=1∑N▽ϕln(θ^n)=n=1∑N▽θ^nln(θ^n)
综上,简化后的MAML计算就变得简单许多,MAML的理论分析也到此结束。
MAML – Real Implementation(步骤可视化)
下面我们用一个实际的例子来理解上面的计算是如何执行的。

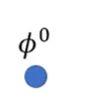
首先,最开始有一个初始化的参数 ϕ 0 \phi^0 ϕ0,然后把一个任务task看做是一个sample,当然可以用多个任务组成mini-batch,然后做GD,这里不用batch,而是用SGD。

然后,在Task m上训练一次 ϕ 0 \phi^0 ϕ0得到最终参数 θ ^ m \hat\theta^m θ^m ,接着计算 θ ^ m \hat\theta^m θ^m 下的梯度(即上图中第二根绿色箭头),将这一梯度乘以学习率赋给$\phi^0 , 得 到 ,得到 ,得到\phi^0$ 的第一次更新结果 ϕ 1 \phi^1 ϕ1。同向的绿色和蓝色箭头不一定等长,因为学习率可能不一样。

接下来,同样地,在Task n上训练一次$\phi^1 得 到 最 终 参 数 得到最终参数 得到最终参数\hat\thetan$,接着计算的梯$\hat\thetan$ 度(即上图中第二根黄色箭头),将这一梯度乘以学习率赋给, ϕ 1 \phi^1 ϕ1 得到第二次训练的更新结果 ϕ 2 \phi^2 ϕ2。
这样不断循环往复,直至在所有的训练Task上完成训练,就找到了最终的初始化参数 ϕ n \phi^n ϕn。
再次对比transfer learning的Model Pre-training在实现上和MAML有什么不一样:
上图,现有一个初始化参数
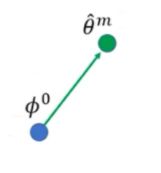
然后计算 θ ^ m \hat{\theta}^m θ^m

然后沿着绿色箭头更新 ϕ 0 \phi^0 ϕ0,因为有学习率的原因,绿色箭头和蓝色箭头的长度并不相同
然后不断重复:

上述就是MAML算法的完整介绍,其实参数初始化问题还有很多其他的解法,其中一个有趣的想法是用LSTM来训练! ϕ \phi ϕ ,因为梯度下降算法本质上可以看作序列模型(如下图所示),于是通过改LSTM的架构也能实现 ϕ \phi ϕ 的训练:

感兴趣的可以看这篇文章: 机器学习-46-Meta Learning - Gradient Descent as LSTM(元学习-用LSTM做Gradient Descen)
MAML Toy Example

我们来讲解一个mate learning的toy example。
- 给定一个正弦函数 y = a s i n ( x + b ) y = a \ sin(x+b) y=a sin(x+b)作为target function
- 从正弦函数中采样K个点作为样本
- 用这K个样本来估计target function。
我们可以不断的改变a和b的值,实现多个不同的任务,从而跑我们的mate learning。

假设使用Model Pre-training的方法的话,这个方法追求的是最开始的参数就可以适应不同的task。我们的task都是sin函数,sin函数都是在1到-1之间不断的波动的,如果要是一开始就适合所有的task的话,那么初始函数就是一条水平线。训练几次以后,仍然是水平线。
但是使用MAML就大不相同,MAML一开始的参数是一条波浪线,在训练一次以后大概可以知道哪里是波峰,训练十次以后,波峰和波谷几乎可以发现。

论文中是把MAML和其他的meta learning方法做比较,发现maml的方法是比较好的。
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
MAML 应用:Translation
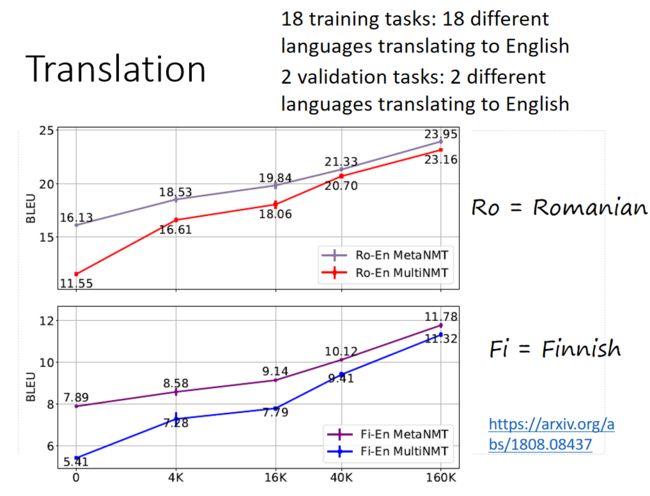
Meta-Learning for Low-Resource Neural Machine Translation
实验结果中用的是BLEU来做评估,横轴是数据量,当然数据量越大效果越好。
Baseline是多任务学习。
图中上图是验证集结果,罗马语翻译为英文
图中下图是测试任务结果,法语翻译英文
Reptile(简单介绍)
Reptile: A Scalable Meta- Learning Algorithm
为什么叫reptile呢?因为从原论文上找不出任何蛛丝马迹,上面也介绍了可能是为了硬凑一个爬行动物。同样,我又要说一个词了,易如反掌——只要理解了上面的一切,理解Reptile的思想就是分分钟钟的事情。看图:简而言之,Reptile就是在算法流程中的第一步更新了多次,在第三步时用 θ ^ m \hat{\theta}^m θ^m 到 ϕ 0 \phi^0 ϕ0 的差向量作为更新方向。

上图,现有初始化参数 ϕ 0 \phi^0 ϕ0

取一个任务m(Sample a training task m),Reptile没有规定只能更新一次参数,因此上图中一个task更新了多次 θ \theta θ,最终的到一个 θ ^ \hat{\theta} θ^

从$\phi^0 到 到 到\hat{\theta}m$方向就是$\phi0$ 更新的方向,乘上学习率,更新 ϕ 0 \phi^0 ϕ0就得到了 ϕ 1 \phi^1 ϕ1

计算出 ϕ 1 \phi^1 ϕ1 后,取一个任务n(Sample a training task n)同样用 ϕ 1 \phi^1 ϕ1 计算出 θ ^ n \hat{\theta}^n θ^n并更新多次,取 ϕ 1 \phi^1 ϕ1到 θ ^ n \hat{\theta}^n θ^n的方向作为 ϕ 1 \phi^1 ϕ1 的更新方向。
MAML vs Model Pre-training vs Reptile
把MAML、model pre-training、Reptile三者的图放一起看看有什么区别:

- g 1 g_1 g1是pre-train的更新方向
- g 2 g_2 g2MAML的更新方向
- g 1 + g 2 g_1+g_2 g1+g2是Reptile的更新方向,当然还可以更新更多次
实验结果比较:

综合论文中的数据曲线来说的话,MAML和Reptile其实不分上下,pre-train的方法是十分垃圾的,是学不到东西的。
More about Meta Learning
上面讲的MAML和Reptile都是关于用Meta Learning来找初始化参数这个事情,那么能不能有别的应用呢?其实是可以的!我们在介绍Meta Learning的时候还有很多红色框框,这些也是可以用Meta Learning来进行研究如何学习的。
我们可以更新我们的神经网络的架构,也可以更新他们的更新的方法。当然只有初始化参数这里可以用GD!当让我们用一个网络去更新另一个网络的话,我们是没有办法进行微分的,所以我们经常使用rl的方法进行更新。
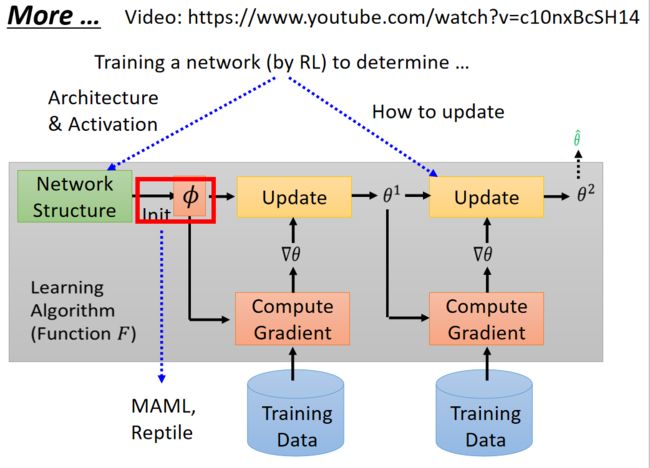
上图是用network来设计Architecture & Activation,以及如何更新参数。
下面套娃预警:
其实我们之前是训练如何设置初始化参数 ϕ \phi ϕ,但是我们本身就有一个初始化参数 ϕ 0 \phi^0 ϕ0 ,而这个初始化参数还是通过我们自己设置的,那么我们其实还可以继续去学这个 ϕ 0 \phi^0 ϕ0,这又需要初始化参数……一直套下去

看上图中,我们可以用一个例子来表示:
- 乌龟从哪里来?从乌龟的背上来!那这只乌龟又从哪里来?从另一只乌龟的背上来!……
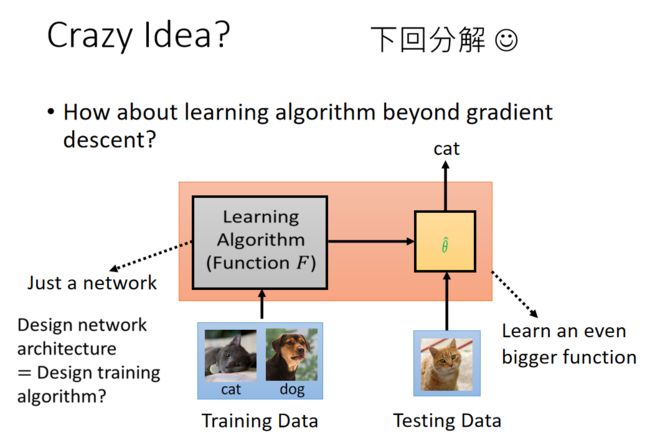
于是我们就有了一个十分疯狂的想法,我们现在做的是我们的learning algorithm本身就是一个大的network,之后我们去让神经网络输出我们训练的参数 θ \theta θ ,之后我们再用参数 θ \theta θ 的分类网络去分类,得到我们最终的预测标签。那么我们可不可以把learning algorithm网络和分类网络两个网络都搞在一起呢!就是我们直接将两个网络都设置为黑盒,输入的是training data,之后再黑盒里得到我们的参数和模型,我们不知道参数是什么,不知道模型是什么,我们就可以直接得到我们的分类结果了。
感兴趣的可以看下面这篇文章:
机器学习-47-Meta Learning-Metric-based Approach & Train+Test as RNN(元学习-support set和query set用于同一网络的方法)