《C语言进阶·重点难点与疑点解析》第一章·笔记
文章目录
-
-
-
-
-
- 本笔记阅读声明
- 本笔记阅读对象
- 如何阅读本笔记
-
-
-
-
- 第1章 理清核心概念
-
- 1.1 堆栈
- 1.2 全局变量和局部变量
- 1.3 生存期和作用域
-
- 1.3.1 生存域
- 1.3.2 作用域
- 1.4 内部函数和外部函数
- 1.5 指针变量
- 1.6 指针数组和数组指针
- 1.7 指针函数和函数指针
- 1.8 传值和传址
- 1.9 递归和嵌套
- 1.10 结构体
- 1.11 共用体
- 1.12 枚举
- 1.13 位域
- ==祝大家在努力的路上,以梦为马,砥砺前行 ------ 共勉
本笔记阅读声明
前言:笔记是参照牟海军的《C语言进阶·重点难点与疑点解析》所作,主要是代码的编写和知识归类,C语言小白可以查看我的C语言基础专栏学习,然后再来参照我的笔记
牟海军资深C语言开发工程师,钟爱C语言,对C语言有较深入的理解和研究,实践经验较为丰富;喜欢研究算法,谙熟各种常见算法和经典算法,颇有心得;擅长嵌入式Linux开发,以及使用Qt进行嵌入式开发;活跃于CSDN等技术社区,是CSDN的推荐博客专家
- 本笔记会不断更新 ~给自己的期限是两个月
- 整篇笔记代码实现后使用的编译器是gcc ------->与之相关的编译命令在我的博客里面也有介绍
笔记包含相关知识点对应的书中代码,都会一一粘贴进去,至于解释图,我要有时间就加进去
本笔记阅读对象
- C语言爱好者
- 嵌入式开发人员
- 初、中级C语言程序员
- 参加C语言培训的学员
如何阅读本笔记
笔记对应书籍分11个章节来书写
- 第1章主要是针对C语言学习中容易混淆的核心概念进行具体讲解,初学者读起来可能有点吃力,建议去我的C语言基础栏目简单了解一下C语言,了解过还没看懂的,可以跳过,从第二章开始学习。
- 第2~8章有针对性的对知识点进行具体记录,阅读者可以通过这几章的学习夯实基础。
- 第9章重点讲解C语言编程中进行调试和异常处理的常见方法和技巧。
- 第10章重点讲解C语言编程中的一些陷阱知识点,通过学习编程时可以绕过这些陷阱。
- 第11章讲解了编程时的常用算法,这是编程中必然遇到的,所以希望大家可以动手编程实现一下
----------------------------------- 开始喽! -------------------------------------
----- 加油撸代码吧!!! -------------编程进阶之路就此开始----------
第1章 理清核心概念
1.1 堆栈
等待更新中~~~~~~~~~~~~~~~~~~~~~~~~~~
1.2 全局变量和局部变量
1.全局变量(也叫外部变量)分为外部全局变量(extern修饰)和静态全局变量(static修饰)
2.静态全局变量(static修饰)------只能在被定义在的源程序使用,而外部全局变量(extern修饰)既可在被定义在的源程序使用,也可以在别的源程序的函数引用
3.在函数前定义过全局变量,那在这个函数里面使用时,可以不说明,通常要在函数前做全局变量做说明
例如:
#include全局变量a在print()函数前有定义,所以在print()函数中使用无需说明,但下面的代码将会运行出错。
#include可以在print()函数里面的printf()语句前加一个 extern int a;
4.局部变量是相对于全局变量来说的,局部变量就是定义在函数体里面的变量。当然,由于形参相当于函数中定义的变量,所以形参也属于一种局部变量。
1.3 生存期和作用域
1.3.1 生存域
注:1.生存期不是变量离开它的作用域,它的生存期就结束。
2.所谓生存期:指占用内存或者寄存器的时长。
3.根据变量存储类型不同,在编译的时候,变量将被存在动态存储区或静态内存区,所以生存期是由声明类别所决定的,声明在哪个存储区就被存储在哪个区
4.存储区介绍
-
静态存储区,存放函数里的全局变量和静态变量,在程序执行前分配好存储空间,占据固定的存储单元。
-
动态存储区,存放函数里的局部变量、返回值、形参等,在函数执行过程中进行动态分配,在执行完该函数时自动释放。因此函数每次被调用,临时变量的地址可能不同。
-
存储类别和相应的变量介绍
- (1)自动(auto)
非静态变量的局部变量即为自动变量,类型说明符是auto,无说明符就默认为自动(auto)
void print()
{
int a;
}
等价于
void print()
{
auto int a;
} - (2)寄存器(register)
指定register存储类别的变量即为寄存器变量。寄存器变量可以提高执行效率。在内存单元存取变量相比从寄存器中存取要耗时,register声明的寄存器类别变量存储放在寄存器中,不占用内存单元,可提高程序执行效率。注:只有局部变量才能被存储为此类型。 代码对比:
a.不使用register:
#include#include int main(int argc,char* argv[]) { struct timeval start,end; gettimeofday(&start,NULL);/*测试起始时间*/ double timeuse; double sum; int j,k; for(j=0;j<1000000000;j++) for(k=0;k<10;k++) sum=sum+1.0; gettimeofday(&end,NULL);/*测试终止时间*/ timeuse = 1000000 * (end.tv_sec - start.tv_sec) + end.tv_usec - start.tv_usec; timeuse /= 1000000; printf("运行时间为:%f\n",timeuse); return 0; } 运行结果:运行时间为:29.517167
b.使用register:
#include#include int main(int argc,char* argv[]) { struct timeval start,end; gettimeofday(&start,NULL);/*测试起始时间*/ double timeuse; register double sum; register int j,k; for(j=0;j<1000000000;j++) for(k=0;k<10;k++) sum=sum+1.0; gettimeofday(&end,NULL);/*测试终止时间*/ timeuse = 1000000 * (end.tv_sec - start.tv_sec) + end.tv_usec - start.tv_usec; timeuse /= 1000000; printf("运行时间为:%f\n",timeuse); return 0; } 运行结果:运行时间为:5.180455
对比发现 用register 速度提高了三倍多
- (3)静态(static)
它的生存期是从程序开始运行到程序运行结束。属于静态存储,作用域不变,且只能在被定义的源文件内使用。
静态局部变量和静态全局变量都是在数据类型前加static,两者的初始化方式不同------静态局部变量在所在的函数执行前初始化一次,之后再执行该函数,它不会被再次初始化,保留上一次的结果;而静态全局变量在main()之前就被初始化,值由最近的一次赋值操作决定。
举例说说静态全局的应用:
- (1)自动(auto)
#include运行结果:
静态局部变量 a = 0
静态局部变量 a = 1
- (4)外部(extern)时
在全局变量类型加上extern,如果没有指定全局变量的存储类型,则默认为extern。
1.3.2 作用域
一段程序代码中所用到的名字并不总是有效或可用的,限定这个名字的可用性的代码范围就是这个名字的作用域
代码:
#include运行结果:
main()里面的{ }封装的 a = 1
fun()函数的 a = 3
main() a = 0
结论:如果在同一区域中出现同名的变量,那么以在该区域的有效且定义最接近该区域的变量为准。
1.4 内部函数和外部函数
变量的作用域引申出来的函数的作用域。
若一个源文件定义的函数只能被该文件中的函数调用,不能被同一程序其他文件中的函数调用,我们称之为内部函数:
static 函数类型 函数名(参数表)
若一个源文件定义的函数既可以被该文件中的函数调用,也能被同一程序其他文件中的函数调用,我们称之为外部函数:
extern 函数类型 函数名(参数表)
如果没加关键字,默认为外部函数。
根据上面--------外部和内部函数最大区别就在于作用范围
接下来编写五个程序对其进行解释:
a./ ********* file.h文件中 ****************/
#ifndef __FILE_H__
#define __FILE_H__
#includeb./ ********* file1.cpp文件中 ***********/
/*函数 入口,有一个内部函数*/
#include"file.h"
static void input(stu student[],int n)
{
int i;
for(i=0;i<n;i++)
{
printf("请输入学生姓名:");
scanf("%s",&student[i].name);
printf("请输入学生的总成绩:");
scanf("%d",&student[i].score);
}
return;
}
int main()
{
stu student[4];
extern void sort(stu student[],int n);//声明
extern void bubble_sort(stu student[],int n);
extern void print(stu student[],int n);
input(student,4);
sort(student,4);//升序
print(student,4);
bubble_sort(student,4);//降序
print(student,4);
return 0;
}
c./ ********* file2cpp文件中 ***********/
/*外部函数----选择法升序排序*/
#include"file.h"
extern void sort(stu student[],int n)
{
int i,j,k;
stu temp;
for(i=0;i<n-1;i++)
{
k=i;
for(j=i+1;j<n;j++)
{
if (student[j].score<student[k].score)
k=j;
}
if(k != i)
{
temp = student[i];
student[i] = student[k];
student[k] = temp;
}
}
printf("使用选择法升序排列的结果:\n");
}
d./ ********* file3.cpp文件中 ***********/
/*外部 排序函数 -----冒泡法排序*/
#include"file.h"
void bubble_sort(stu student[],int n)
{
int i,j,flag;
stu temp;
for(i = 0; i < n - 1; i++)
{
flag = 1;
for(j = 0; j < n-i-1; j++)
{
if(student[j].score<student[j+1].score)
{
temp = student[j];
student[j] = student[j+1];
student[j+1] = temp;
flag = 0;
}
}
if(1 == flag)
break;
}
printf("使用冒泡降序排列的结果:\n");
return;
}
e./ ********* file4.cpp文件中 ***********/
/*打印结果*/
#include"file.h"
void print(stu student[],int n)
{
int j;
for(j = 0;j < n;j++)
{
printf("学生 %s 的总成绩为:%d\n",student[j].name,student[j].score);
}
return;
}
运行结果:
请输入学生姓名:lzq
请输入学生的总成绩:20
请输入学生姓名:lza
请输入学生的总成绩:30
请输入学生姓名:lzb
请输入学生的总成绩:40
请输入学生姓名:lzc
请输入学生的总成绩:50
使用选择法升序排列的结果:
学生 lzq 的总成绩为:20
学生 lza 的总成绩为:30
学生 lzb 的总成绩为:40
学生 lzc 的总成绩为:50
使用冒泡降序排列的结果:
学生 lzc 的总成绩为:50
学生 lzb 的总成绩为:40
学生 lza 的总成绩为:30
学生 lzq 的总成绩为:20
.cpp准确来说是C++文件后缀,但用gcc编译也可以通过,它只不过是C语言的威力加强版。
把这些文件都用到的头文件都 独立在file.h 文件里面。
使用内部函数的优点:不同人编写不同的函数时,不用担心自己定义的函数是否会与其他文件中的函数同名,因为作用域的关系,同名也不会产生影响。在只需要在一个源文件使用的函数,养成在前面加上static的习惯。
1.5 指针变量
懂C语言的人都知道,C语言之所以强大且具有自由性,主要体现在对指针的灵活运用上。因此,指针可以说成是C语言的灵魂。既然指针如此重要,那么指针究竟是什么呢?在回答这个问题之前,我们先通过接下来的代码来看看指针的使用。
pointer.c源程序:
#include运行结果是变化的
运行结果:
整形指针pa占的内存大小:8字节
整形指针pb占的内存大小:8字节
整形变量a的地址: 1171077300
整形变量b的地址: 1171077299
整形指针的pa的值: 1171077300
整形指针的pb的值: 1171077299
整形指针 pa+1 的值: 1171077304
整形指针 pb+1 的值: 1171077300
注意:指针占的内存大小始终是一定的,在64bit的电脑测试是 占8字节,在32bit电脑下测试是占4字节
通过结果我们可以看出pa pb 存的是a 和b 的地址
pa 跟 pb 的指针类型不同,所以在加1之后增加的是 所属类型对应的大小,整型就是四字节,字符型就是一字节。
指针不能简简单单的理解为地址,而应该把指着理解为指向一块内存区域的起始地址,指向区域的大小所指变量的类型而定。
指针变量与一般变量的区别在于,指针存地址,看看下面的代码:
p1.c
#include运行结果:
a的值: 1844825184
&a的值: 1844825184
a+1的值: 1844825188
&a+1的值: 1844825224
a 跟 &a 所指向的数据类型不同,a 就相当于一个整型指针,加一之后增大4字节,而&a 指向的则是int[10]类型的指针变量
(int a[10]—int* (&a)[10])
所以 &a+1 增大40 (4x10字节)字节。
前面都是对指针的初步认识,以后会有一章进行介绍。
1.6 指针数组和数组指针
先指针数组和数组指针的定义:
指针数组:
类型名 *数组名 [数组长度]
如:
int *p[8];
数组指针:
类型名 (*数组名) [数组长度]
如:
int( *p)[8];
现在分析上述的两种定义形式,通过“int *p[8]; ”来定义一个指针数组。因为优先级的关系,所以p先与[]结合,然后再与 " * "结合说明数组p的元素是指向整型数据的指针。相当于定义了整数指针变量,用于存放地址单元,p就是数组元素为指针的数组,本质为数组。
如果定义方式为“int( *p)[8]”,p先与“ * ”结合,形成一个指针,指针指向整型元素数组,p即为指向数组首元素地址的指针,其本质为指针。
代码演示(指针数组和数组指针如何访问二维数组)
pap.c
#include使用数组指针访问二维数组array
array[0][0] = 0 array[0][1] = 1 array[0][2] = 2 array[0][3] = 3
array[1][0] = 4 array[1][1] = 5 array[1][2] = 6 array[1][3] = 7
array[2][0] = 8 array[2][1] = 9 array[2][2] = 10 array[2][3] = 11
array[3][0] = 12 array[3][1] = 13 array[3][2] = 14 array[3][3] = 15
指针数组访问二维数组array:
arr[0][0] = 0 arr[0][1] = 1 arr[0][2] = 2 arr[0][3] = 3
arr[1][0] = 4 arr[1][1] = 5 arr[1][2] = 6 arr[1][3] = 7
arr[2][0] = 8 arr[2][1] = 9 arr[2][2] = 10 arr[2][3] = 11
arr[3][0] = 12 arr[3][1] = 13 arr[3][2] = 14 arr[3][3] = 15

还有其他表示数组每行的起始地址
如:
*(arr+i)
arr+i
……
为了方便记忆,请看代码:
#include运行结果:
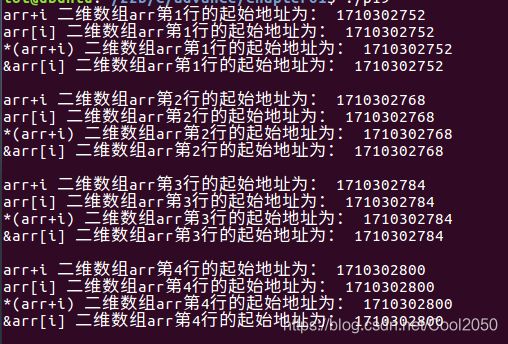
从上面 我们知道起始地址的表示方式不唯一
指针数组 和 数组指针是如何访问二维数组的:
数组指针:
数组指针指向的是一个有4个整型元素的数组,所以可以把二维数组arr看成由4个元素 arr[0] 、arr[1]、arr[2]、arr[3]组成,每个元素都是含有4个整型元素的一位数组,所以当在代码中使用 p1=arr的时候,p1指向了二维数组的第一行的首地址。在接下来的的访问中,由于p1指向的类型是int[4],所以从p1到p1+1的变化值为44个字节,