打脸!MLP-Mixer 里隐藏的卷积
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:Towser | 已授权转载(源:知乎)
https://zhuanlan.zhihu.com/p/370774186
最近 Google 的一篇文章 MLP-Mixer 很火,号称用只用 MLP 来做 CV 任务。不过显而易见的是,它在很多地方用到了卷积,只是没有说自己是在做卷积,而是用一堆奇奇怪怪的词来描述自己在做的运算。MLP-Mixer 的卷积本质已经有很多人指出了了,比如 LeCun 的 twitter。

再比如这个问题下的一票回答。当然,最出彩的要数论文自己附录 E 的第 36 行:
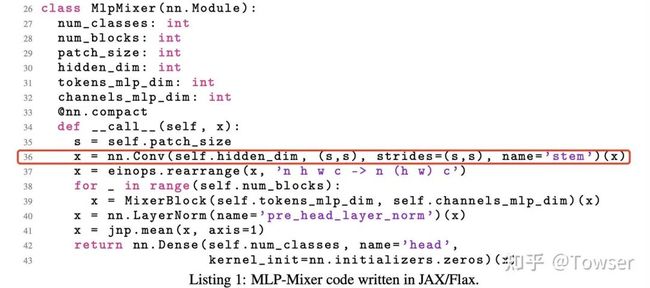
作为 "an architecture based exclusively on multi-layer perceptrons",第一步 patch projection 的官方实现就是 Conv,惊不惊喜?意不意外??
嘲讽完毕以后,这里还是要详细解释一下 MLP-Mixer 的几个结构到底和卷积如何对应,不然我写这篇文章也就毫无意义了。
首先,从原则上来说,卷积和全连接层可以按照如下的方式互相转化:
如果卷积核的尺寸大到包含了所有输入,以至于无法在输入上滑动,那么卷积就变成了全连接层
反过来,如果全连接层足够稀疏,后一层的每个神经元只跟前一层对应位置附近的少数几个神经元连接,并且这些连接的权重在不同的空间位置都相同,那么全连接层也就变成了卷积层。
一些更具体的例子可以参考 CS231N 这里的解释。
由于第一点关系,你甚至可以说一切层都是卷积层(pytorch 实现就是把输入从 [batch_size, ...] reshape 为 [batch_size, -1, 1, 1],然后和一个形如 [out_dim, in_dim, 1, 1] 的卷积核进行 1x1 卷积 ),只是这种说法过于宽泛而缺乏实际意义罢了。作为一个“有意义”的卷积层,至少要满足两个要素:局部连接和参数共享。也就是说,卷积核不要太大,要能够在输入上滑动,这才能体现“卷积”的计算过程。
在 MLP-Mixer 中,主要有三个地方用到了全连接层,而这些操作全部可以用卷积实现,方法如下:
第一步是把输入切分成若干 16x16 的 patch,然后对每个 patch 使用相同的投影。最简单的实现/官方实现就是采用 16x16 的卷积核,然后 stride 也取 16x16,计算二维卷积。当然,这一步也可以按照全连接层来实现:首先把每个 16x16 的 patch 中的像素通过 permute/reshape 等操作放在最后一维得到 x_mlp,然后再做一层线性变换。
为了方便参数共享、对比计算结果,这里全部采用 pytorch 里的 functional API 实现,代码如下:
import torch
import torch.nn.functional as F
# i) non-overlapping patch projection
batch_size, height, width, in_channels = 32, 224, 224, 3
out_channels, patch_size = 8, 16
x = torch.randn(batch_size, in_channels, height, width)
w1 = torch.randn(out_channels, in_channels, patch_size, patch_size)
b1 = torch.randn(out_channels)
conv_out1 = F.conv2d(x, w1, b1, stride=(patch_size, patch_size))
print(conv_out1.size()) # [batch_size, out_channels, num_patches_per_column, num_patches_per_row]
x_mlp = x.view(batch_size, in_channels, height // patch_size, patch_size, width // patch_size, patch_size).\
permute(0, 2, 4, 1, 3, 5).reshape(batch_size, -1, in_channels * patch_size ** 2)
mlp_out1 = x_mlp @ w1.view(out_channels, -1).T + b1
print(mlp_out1.size()) # [batch_size, num_patches, out_channels]
print(torch.allclose(conv_out1.view(-1), mlp_out1.transpose(1, 2).reshape(-1), atol=1e-4))可以看到,在对结果进行重新排列后(这一步繁琐但是意义不大,不展开讲了),conv_out1 和 mlp_out1 是相同的。
torch.Size([32, 8, 14, 14])
torch.Size([32, 196, 8])
True另一个操作是对同一通道内不同位置的像素信息进行整合。如果用 MLP 来实现,就是把同一个通道的像素值都放到最后一维,然后接一个线性变换即可;如果用卷积来实现,实质上是一个 depthwise conv,并且各个通道/深度要共享参数(因为每个通道都要按相同的方式整合不同位置的信息)。这就是 F.conv2d 的卷积核里 w2 和 b2 进行 repeat 的原因。
# ii) cross-location/token-mixing step
in_channels = out_channels # Use previous outputs as current inputs
out_hidden_dim = 7 # `C` in the paper
x = torch.randn(batch_size, in_channels, height // patch_size, width // patch_size)
w2 = torch.randn(out_hidden_dim, 1, height // patch_size, width // patch_size)
b2 = torch.randn(out_hidden_dim)
# This is a depthwise conv with shared parameters
conv_out2 = F.conv2d(x, w2.repeat(in_channels, 1, 1, 1),
b2.repeat(in_channels), groups=in_channels)
print(conv_out2.size()) # [batch_size, in_channels * out_hidden_dim, 1, 1]
mlp_out2 = x.view(batch_size, in_channels, -1) @ w2.view(out_hidden_dim, -1).T + b2
print(mlp_out2.size()) # [batch_size, in_channels, out_hidden_dim], or [B, S, C] in the paper
print(torch.allclose(conv_out2.view(-1), mlp_out2.view(-1), atol=1e-4))conv_out2 和 mlp_out2 的结果当然也是相同的(在进行适当重排的意义下):
torch.Size([32, 56, 1, 1])
torch.Size([32, 8, 7])
True还有一个操作是对同一位置的不同通道进行融合。显然这个操作就是一个逐点卷积(pointwise/1x1 conv)。当然,也可以利用 permute 把相同位置不同通道的元素丢到最后一维去,然后统一做一个线性变换,如下:
# iii) channel-mixing step
out_channels = 28
x = torch.randn(batch_size, in_channels, height // patch_size, width // patch_size)
w3 = torch.randn(out_channels, in_channels, 1, 1)
b3 = torch.randn(out_channels)
# This is a pointwise conv
conv_out3 = F.conv2d(x, w3, b3)
print(conv_out3.size()) # [batch_size, out_channels, num_patches_per_column, num_patches_per_row]
mlp_out3 = x.permute(0, 2, 3, 1).reshape(-1, in_channels) @ w3.view(out_channels, -1).T + b3
print(mlp_out3.size()) # [batch_size * num_patches, out_channels], or [B*C, S] in the paper
print(torch.allclose(conv_out3.permute(0, 2, 3, 1).reshape(-1), mlp_out3.view(-1), atol=1e-4))结果也是毫无悬念的相同:
torch.Size([32, 28, 14, 14])
torch.Size([6272, 28])
True大功告成!现在我们已经学会如何用 F.conv2d 实现 MLP-Mixer 了!
当 MLP-Mixer 对每个 patch 做相同的线性变换的时候,就已经在用卷积了(这一点在 ViT 里同样成立)。因为卷积的本质是局部连接+参数共享,而划分 patch = 局部连接,对各个 patch 应用相同的线性变换 = 参数共享。只不过,它用的卷积核大一点儿而已,有一个 patch 那么大。
而当他进行 token-mixing 和 channel mixing 的时候,实际就是把普通的卷积拆成了 depthwise conv with shared parameters 和 pointwise conv —— 在不考虑卷积核大小的情况下,这甚至比深度可分离卷积(depthwise separable conv)的表达能力还要弱:后者是把普通 conv 拆成了 depthwise conv + pointwise conv,而 MLP-Mixer 里的 depthwise conv 甚至还要在每个 depth/channel 上共享参数。于是,达不到 SOTA 也很好理解了。
写到这里,其实也就把 @Captain Jack的一句话评价 parameter-shared depth-wise separable convolution 掰开讲了。
当然,无意否认这篇文章的贡献,能把这么大的 patch/conv kernel 训出来绝不是一件容易的事情,只是我实在厌倦了 XXX is all you need. Indeed, money is all you need.
题外话:在 Transformer 中,有一个逐点前馈/全连接(pointwise feedforward)的操作,具体内容是给每个位置施加一个相同的前馈变换。有人称之为 1D 卷积,我认为也是合理的,因为它也体现了卷积核滑动的过程。其实,对一个形如 [B, T, D] 的张量做线性变换,得到一个形如 [B, T, D'] 的张量,不要把 D 和 D' 理解为隐层维度而是理解为通道数,很容易看出这是一个 conv1d。如果在写代码的时候想着用循环实现每个样本每个时间步如何操作,才会觉得 D -> D' 是一个全连接层(所以它叫逐点全连接:从单点的角度来看,它是全连接;从整个序列输入的角度来看,它是 conv1d)。
论文PDF和代码下载
后台回复:MLP,即可下载上述论文PDF
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
重磅!图像分割交流群成立
扫码添加CVer助手,可申请加入CVer-图像分割 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看