Java面试题2020,java游戏代码脚本之家
前言
最其实不管什么时候,找工作都跑不了面试。目前很多小编都做了面试手册了,那就是别人家的孩子都有糖了,作为一个自觉的小编,必须搞。
容我先絮叨一下,制作这个面试手册差不多花了3个多星期时间,过程还是比较磨人的,但是也很期待。要是因为我做的手册,帮助到了大家,那就真的开心啊!这就是这篇文章的目的,**帮你搜集了大量的面试题,已经整理成了一个Java面试手册PDF,《互联网面试2400页》,目前有65份PDF,共有2400多页,**后续还会不断的完善更新。
直接进入正题,由于pdf文档里的细节内容实在过多所以只编辑了部分知识点的章节粗略的介绍下,每个章节小节点里面都有更细化的内容!
题库非常全面
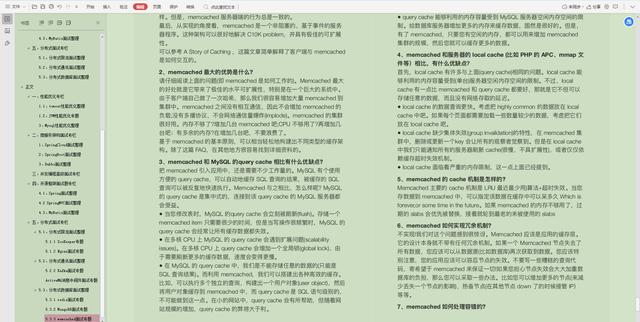
包括 Java 集合、JVM、多线程、并发编程、设计模式、Spring全家桶、Java、MyBatis、ZooKeeper、Dubbo、Elasticsearch、Memcached、MongoDB、Redis、MySQL、RabbitMQ、Kafka、Linux、Netty、Tomcat等大厂面试题等、等技术栈!

第一次压测

惨不忍睹,平均响应时间150ms,而且在这次压测过程中还发现其它的问题,后台报错,经查是OpenSearch每秒查询次数限制
优化代码与配置
1、修改OpenSearch配置,并且将压测环境中的OpenSearch连接地址改为内网地址。2、将代码中循环查询缓存的地方改为一次性批量查询返回。3、和相关同学确认后去掉项目中无用的代码。
第二次压测

虽然优化了代码,修改了配置,但是情况更糟糕了,而且还改出了新的问题。当时,反复检查了代码,确定查询缓存的次数已经是最少了,而且连接线程池相关参数也调到一个相对较大且合理的值了。如果,再压测还是无法达到要求的话,只有出最后一招了:缓存结果集。即,以用户ID和用户搜索的关键词为key,查询的结果为value,缓存5分钟。
第三次压测

总算符合要求了,并发60的时候响应时间达到32ms,而我又发现了新的优化点。

接口中居然还有查数据库的操作,这可不能忍,排查之后去掉了一些不必要的依赖。
成长
学会了使用RedisTemplate的executePipelined进行redis批量查询

针对本次优化的总结
1、一定要绝对避免循环查数据库和缓存(PS:循环里面就不能有查询缓存,更不能有查询数据库的操作,因为循环的次数没法控制);
2、对于API接口的话,一般都是直接查缓存的,没有查数据库的;
3、多用批量查询,少用单条查询,尽量一次查出来;
4、对于使用阿里云,要留意一下相应产品的配置,该花的钱还是得花,同时,千万要记得正式环境中使用相应产品的内网地址;
5、注意连接池大小(包括数据库连接池、Redis缓存连接池、线程池);
6、压测的机器上不要部署其它的服务,只跑待压测的服务,避免受其它项目影响;对于线上环境,最好一台机器上只部署一个重要的服务;
7、没有用的以及被注释掉的代码,没有用的依赖最好及时清理掉;
8、集群自不用说;
9、一些监控类的工具工具可以帮助我们更好的定位问题,比如链路跟踪,这次项目中使用了PinPoint;
10、如果技术上优化的空间已经非常小了,可以试着从业务上着手,用实际的数据说话,可以从日常的访问量,历史访问量数据来说服测试;
11、每一次代码改动都有可能引入新的问题,因此,每次修改代码后都要回归测试一下(PS:每次修改完以后,我都会用几组不同的关键词搜索,然后比对修改前和修改后返回的数据是否一致,这个时候postman,以及Beyond compare就派上用场了);
12、关键的地方一定要多加点儿日志,方便以后排除问题,因为排查线上问题最主要还是靠日志;
总结
我们总是喜欢瞻仰大厂的大神们,但实际上大神也不过凡人,与菜鸟程序员相比,也就多花了几分心思,如果你再不努力,差距也只会越来越大。
面试题多多少少对于你接下来所要做的事肯定有点帮助,但我更希望你能透过面试题去总结自己的不足,以提高自己核心技术竞争力。每一次面试经历都是对你技术的扫盲,面试后的复盘总结效果是极好的!如果你需要这份完整版的面试真题笔记,只需你多多支持我这篇文章。
资料领取方式:戳这里免费下载
多多支持我这篇文章。
资料领取方式:戳这里免费下载