用scrapy爬取瓜子二手车车源信息
之前我们介绍了scrapy框架的使用,这次我们就是用scrapy框架具体的实现,到底是怎么用的我们这次的案例就是之前我们写过的瓜子二手车车源信息,使用scrapy框架改写之前我们爬取过的瓜子二手车车源信息,具体的网站是这个:
我们就不在一一介绍爬取步骤了,我们直接上代码,不明白的可以看看这个,里面分析的很详细了
https://blog.csdn.net/Yxh666/article/details/111146966
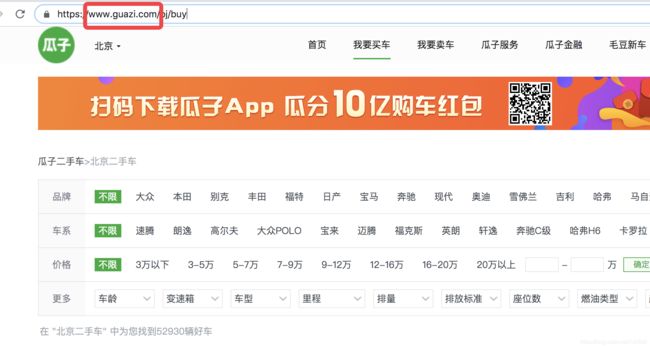
在创建项目之前我们要确定好域名,这个是域名,我们一会儿会用到
确定好域名后我们直接创建项目


这样一个项目就生成了,还有就是这个域名不要想当然,一定要去浏览器看,因为并不是所有的都是这样www开头,com结尾的
接着我们按照正规的流程去写这个项目,首先我们用pycharm打开这个项目,然后找到items.py

先定义要抓取的数据结构
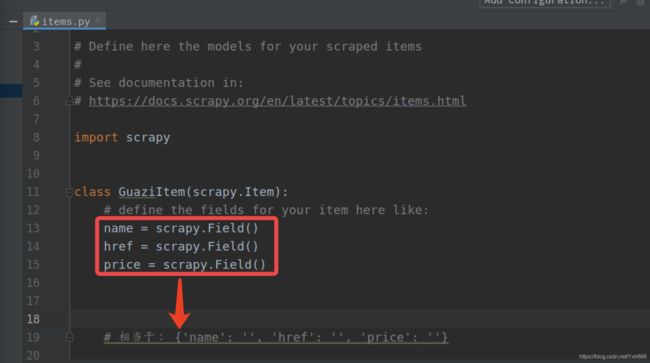
接下来我们找到爬虫文件来爬取数据,给到我们定义的这仨个变量赋值

这个爬虫文件里面其他的不用动,这个start_urls ,这里不可以写这个,因为我们爬取的不是这个地址,现在给的URL地址是整个网站的,而我们要爬取的是一页的数据,所以这个我们要改成这个:
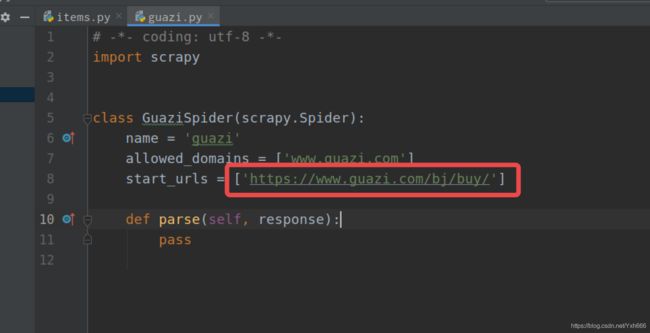
然后接下来就是写一个基准的xpath,匹配所有汽车的节点对象列表,在for 循环提取每辆汽车的数据

然后我们去settings.py 做一下配置,一共三处
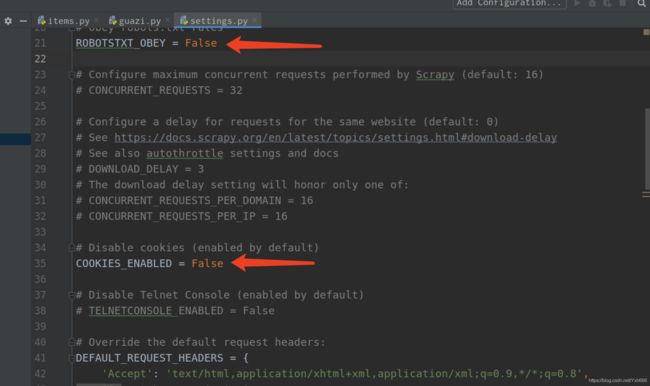
在这个里面取消注释,并添加Cookie和User-Agent,在页面直接F12抓包最后复制就可以了

然后我们再创建一个启动项目的run.py文件,注意创建位置
最后运行可以看到数据是可以出来的
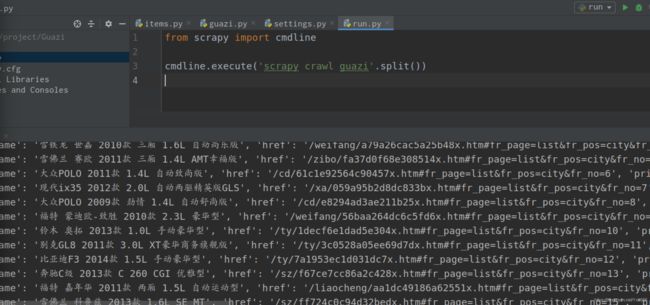
但是数据只是出来了,并没有赋值给当初我们定义的那三个变量,所以接下来的任务就是赋值
那我们就在爬虫文件里导入items.py文件里的类,再操作里面的三个变量,然后给它每一条数据实例化一下

这样就赋值好了,现在我们要把爬取的这些数据,存入到数据库里面,这下就要用到了管道文件pipelines.py,现在我们要在爬虫文件里写上一行代码,才能把爬到的文件传到管道文件里,把之前的输出换成yield,这样就可以传到管道文件里面做处理了
然后我们现在打开管道文件,写一点代码吧,因为我们刚刚把输出数据的换成了yield,所以现在我想让他再次能让我看到,我们这样做

然后我们要再次设置settings里面,打开管道设置,后面数字300是优先级,从1~1000不等,数字越小,优先级越高

我们再次运行,看到有那些红色的信息,这个不是报错,能有这个确实是走的管道,所以它会去进行调试,所以会有这些信息

至此我们的一级页面已经抓取完成了,接下来我们要改写目前的程序,让他可以抓取二级页面的数据,并且可以抓取多页数据
我们回到爬虫文件里面重写start_urls,因为爬虫项目启动就会找到这个,因为我们目前的话是只能爬取一页数据,所以我们要重写它,只要一重写他就会按照我们写的去执行,就不会找源文件里面的了
先找到URL地址页数的规律,然后重写start_urls,记得要去掉之前的

这个里面的scrapy.Request() 是交给调度器如队列的方法,里面的参数有我们要爬取的URL地址和回调解析函数,因为这个会返回一个response,所以我们要用到回滚给到那个函数,那个名字随便起,就是你这个名字叫什么,下面的那个接收response的函数就得叫什么,否则无法接受返回的response
现在我们就可以获取这几页的数据,是一级页面的
提前设置好数据的数据表的字段
提前设置好数据的数据表的字段
提前设置好数据的数据表的字段
要和下面的数据库和数据表对应的上
接下来我们写获取二级页面数据的代码,就是在原有的基础上修改就好了,大多没什么变换。
我们说一下存入数据库的方法,存入数据库的时候,scrapy给我们提供了专门连接数据库的函数,就是这个:

第一个就是我们连接数据库的时候用到的,但是这个注意了,他只是连接一次数据库,而我们要是第二次存入数据,它不会再次连接
第二个是我们关闭数据库的时候用到的,这个同样也是,使用一次,仅仅是关闭数据库用到的
接下来奉上每个文件的所有代码
定义抓取数据的变量文件----items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class GuaziItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
href = scrapy.Field()
price = scrapy.Field()
km = scrapy.Field()
displace = scrapy.Field()
type = scrapy.Field()
# 相当于: {'name': '', 'href': '', 'price': ''}
爬虫文件的----guazi.py
# -*- coding: utf-8 -*-
import scrapy
from ..items import GuaziItem
class GuaziSpider(scrapy.Spider):
name = 'guazi'
allowed_domains = ['www.guazi.com']
url = 'https://www.guazi.com/bj/buy/o{}/#bread'
def start_requests(self):
"""生成所有要抓取的url地址,交给调度器入队列"""
for o in range(1, 6):
page_url = self.url.format(o)
# 交给调度器入队列
yield scrapy.Request(url=page_url,
callback=self.parse_html)
def parse_html(self, response):
li_list = response.xpath('//ul[@class="carlist clearfix js-top"]/li')
for li in li_list:
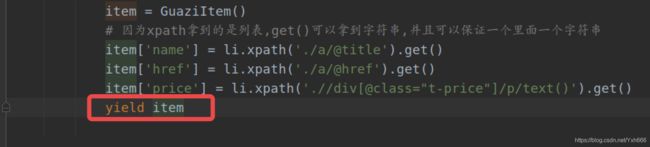
item = GuaziItem()
# 因为xpath拿到的是列表,get()可以拿到字符串,并且可以保证一个里面一个字符串
item['name'] = li.xpath('./a/@title').get()
item['href'] = 'https://www.guazi.com' + li.xpath('./a/@href').get()
item['price'] = li.xpath('.//div[@class="t-price"]/p/text()').get()
yield scrapy.Request(url=item['href'], meta={
'meta_1': item}, callback=self.detail_parse)
def detail_parse(self, response):
# 获取上个解析函数传递过来的 meta 数据
item = response.meta['meta_1']
item['km'] = response.xpath('//ul[@class="assort clearfix"]/li[2]/span/text()').get()
item['displace'] = response.xpath('//ul[@class="assort clearfix"]/li[3]/span/text()').get()
item['type'] = response.xpath('//ul[@class="assort clearfix"]/li[4]/span/text()').get()
yield item
管道文件----pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
class GuaziPipeline(object):
def process_item(self, item, spider):
print(item['name'], item['km'], item['price'])
return item
import pymysql
class GuaziMysqlPipeline(object):
def open_spider(self, spider):
"""爬虫项目启动时,只执行1次,一般用于数据库的连接"""
self.db = pymysql.connect('localhost', 'root', '123456', 'guazidb', charset='utf8')
self.cur = self.db.cursor()
self.ins = 'insert into guazitab values(%s,%s,%s,%s,%s)'
def process_item(self, item, spider):
li = [
item['name'], item['km'], item['displace'], item['type'], item['price'],
]
self.cur.execute(self.ins, li)
self.db.commit()
return item
def close_spider(self, spider):
"""爬虫项目结束时,只执行1次,一般用于数据库的断开"""
self.cur.close()
self.db.close()
如果存入数据库要在settings.py文件里面的ITEM_PIPELINES变量里面设置这个
ITEM_PIPELINES = {
# 终端显示爬取的数据
'Guazi.pipelines.GuaziPipeline': 300,
# 存入数据库的管道代码,注意,名字要和管道文件定义函数的一样
'Guazi.pipelines.GuaziMysqlPipeline': 200,
}
run.py文件
from scrapy import cmdline
# 添加 -o xx.csv就是存csv文件
cmdline.execute('scrapy crawl guazi -o guazi.csv'.split())
好了小伙伴们快去是一下吧,在说一下,记得要在数据里面 提前设置好数据表的字段