Python爬取虎牙颜值区美女主播照片!
本次干货内容给大家呈现的利用爬虫获取海量美女图片。不知道大家有没有上过斗鱼直播、虎牙直播。直播室里面美女姐姐可是比比皆是。
有很多美女姐姐的图片做桌面,即使加班也是高兴的!
公众号「Python专栏」回复 虎牙直播,获取本文详细代码和视频教程的网盘链接。
好啦!先唠叨一下爬虫的步骤:
- 获取请求链接,并判断响应结果的类型
- 使用requests发出请求,获取响应结果
- 解析响应结果
- 将响应的结果做持久化保存
按照步骤我们第一步是获取链接,虎牙直播平台: https://www.huya.com/,斗鱼直播平台: https://www.douyu.com/
我们以虎牙直播为例,进入首页
然后选择更多,但是如果你需要的在上面可以直接选择也可以,比如王者荣耀、英雄联盟等,我们选择【颜值】,进入颜值页面
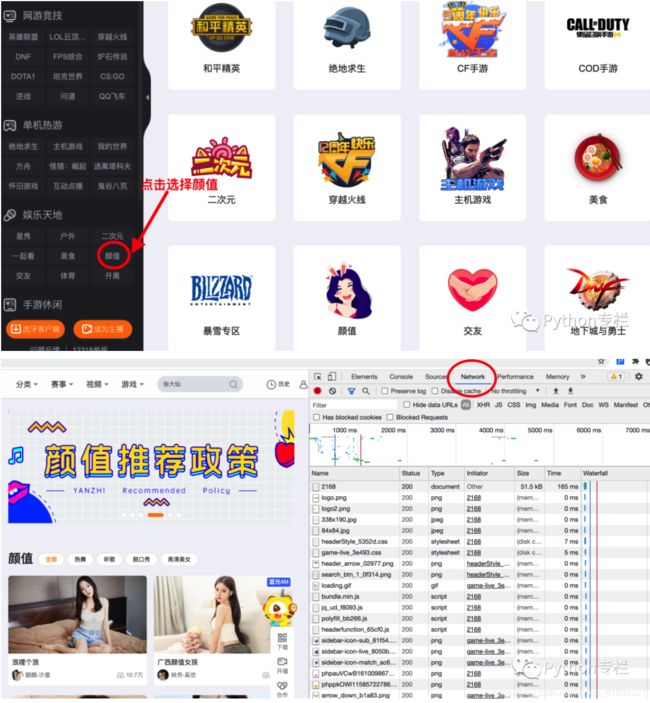
来到颜值页面后我们F11打开开发者工具,选择Network进行网络请求和响应的查看。我们的目的是获取海量的妹妹图片
将页面拉到底部,进行翻页。发现地址栏没有变化还仍然是:https://www.huya.com/g/2168
如果大家遇到这种情况,就要考虑是不是使用ajax进行异步请求了。在Network中选择XHR,进行异步请求的筛选。
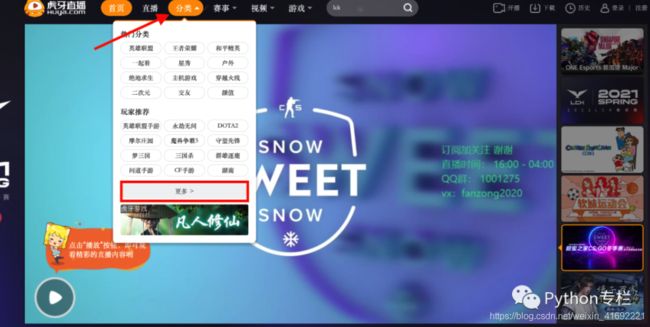
点开上图中圈起来的链接,发现在response处是一个json返回结果
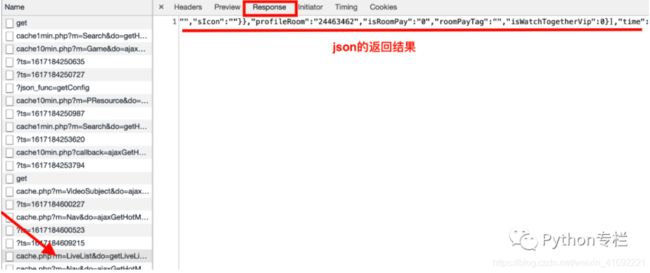
于是我们把此链接拷贝出来,继续分析:
1.https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=2168&tagAll=0&callback=getLiveListJsonpCallback&page=1
2.https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=2168&tagAll=0&callback=getLiveListJsonpCallback&page=2
3.https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=2168&tagAll=0&callback=getLiveListJsonpCallback&page=3
4.https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=2168&tagAll=0&callback=getLiveListJsonpCallback&page=4
这时我们兴奋了,因为发现了规律,链接其他的没有发生变化,唯独在最后位置page发生了改变。分别跟页码数对应上了。
于是我们就有了下面的代码:
# 获取响应结果json并解析
def get_parse_json(url):
pass
if __name__ == '__main__':
# 自动创建huya文件夹
if not os.path.exists('huya'):
os.mkdir('huya')
# 假设我们要爬取的是3页的主播封面图
for i in range(1,4):
url = 'https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=2168&tagAll=0&callback=getLiveListJsonpCallback&page='+str(i)
get_parse_json(url)
现在我们就来到了步骤二,使用requests发出请求了。
# 导入requests
import requests # 爬虫
# 模拟浏览器来访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
}
def get_parse_json(url):
# 开始爬取虎牙的妹子
response = requests.get(url, headers=headers)
content = response.text # 大家注意此处没有使用json()直接获取,是因为json字符串前面有一长串字符串
# 使用切片截取字符串
result = content[len('getLiveListJsonpCallback('): -1]
# 查看截取结果
print(result)
if __name__ == '__main__':
# 假设我们要爬取的是10页的主播封面图
for i in range(1,11):
url = 'https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=2168&tagAll=0&callback=getLiveListJsonpCallback&page='+str(i)
get_parse_json(url)
获取结果截图:
![]()
我们发现成功获取了3条json结果,接下来就是分析和解析数据了。
因为json内容很长,我们不变分析它们,所以我们使用json的格式化工具完成:https://www.bejson.com/
点开格式化工具的链接,将json数据复制到上面,进行格式化查看会更加清晰。
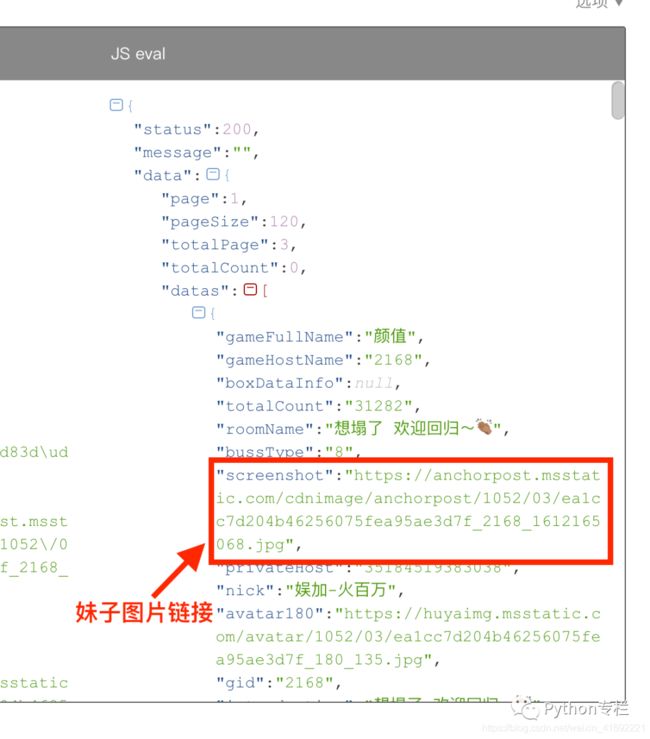
通过分析我们发现所有的数据都在data–>datas中,而图片在screenshot对应的值上。
所以我们开始解析,先将json字符串使用json.loads()进行转换,得到的是一个字典,然后层层的获取数据。
解析的代码是:
import json
# json解析: json字符串 => python字典
result2 = json.loads(result)
# 当前页的所有妹子
meizi_list = result2['data']['datas']
for meizi in meizi_list:
nick = meizi['nick'] # 昵称
img = meizi['screenshot'] # 图片url
我们虽然提取出来了图片的url,但是还没有保存到本地。所以接下来要做第四步持久化保存了。
因为我们下载的仅仅是图片,所以直接使用request.urlretrieve实现就可以
from urllib from request
request.urlretrieve(img, f'huya/{nick}.png')
request.urlcleanup() # 清空缓存
print(f'{nick}.png 下载完成!')
因此最后的完整代码是:
# 导入requests
import time
import json
from urllib import request
import ssl
import requests # 爬虫
# 模拟浏览器来访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
}
# ssl._create_default_https_context = ssl._create_unverified_context
def get_parse_json(url):
# 开始爬取虎牙的妹子
response = requests.get(url, headers=headers)
content = response.text # 大家注意此处没有使用json()直接获取,是因为json字符串前面有一长串字符串
# 使用切片截取字符串
result = content[len('getLiveListJsonpCallback('): -1]
# json解析: json字符串 => python字典
result2 = json.loads(result)
# 当前页的所有妹子
meizi_list = result2['data']['datas']
for meizi in meizi_list:
nick = meizi['nick'] # 昵称
img = meizi['screenshot'] # 图片url
try:
# 这句话是在下载图片的时候有可能会有证书认证问题,如果没有可以不加
ssl._create_default_https_context = ssl._create_unverified_context
request.urlretrieve(img, f'huya/{nick}.png')
request.urlcleanup() # 清空缓存
print(f'{nick}.png 下载完成!')
except:
print('error:', nick)
if __name__ == '__main__':
# 自动创建huya文件夹
if not os.path.exists('huya'):
os.mkdir('huya')
# 假设我们要爬取的是10页的主播封面图
for i in range(1, 3):
url = 'https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=2168&tagAll=0&callback=getLiveListJsonpCallback&page=' + str(
i)
get_parse_json(url)
time.sleep(5)
在上面的代码中我们我们使用过单线程完成的,代码中加完time.sleep(5)每页会有5秒的延迟。
当然要想速度更快可以使用多进程完成:multiprocessing,所以代码我们可以升级成:
# 导入requests
import requests # 爬虫
import json # json解析
import os # 自动创建文件夹
from urllib import request # 下载图片
import multiprocessing # 多进程爬取多页
import ssl
# 模拟浏览器来访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
}
def get_huya_meizi(page=1):
'''
:param url: 下载路径
:return:
'''
# 开始爬取虎牙的妹子
response = requests.get(url, headers=headers)
content = response.text
result = content[len('getLiveListJsonpCallback('): -1]
# json解析: json字符串 => python字典
result2 = json.loads(result)
# 当前页的所有妹子
meizi_list = result2['data']['datas']
for meizi in meizi_list:
nick = meizi['nick'] # 昵称
img = meizi['screenshot'] # 图片url
# 下载图片,并以昵称作为图片名
try:
ssl._create_default_https_context = ssl._create_unverified_context
request.urlretrieve(img, f'huya/{nick}.png')
request.urlcleanup() # 清空缓存
print(f'{nick}.png 下载完成!')
except Exception as e:
print('error:', e)
if __name__ == '__main__':
# 自动创建huya文件夹
if not os.path.exists('huya'):
os.mkdir('huya')
# 获取虎牙妹子
# 使用多进程
for i in range(1, 3):
url = 'https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=2168&tagAll=0&callback=getLiveListJsonpCallback&page=' + str(
i)
# 创建进程来同时获取多页数据
multiprocessing.Process(target=get_huya_meizi, args=(url,)).start()
斗鱼直播也是这样子哦!大家自己抓紧时间试试吧!当然如果感兴趣可以爬点其他的。
对爬虫感兴趣的小伙伴走起吧!
如果你在学习过程中遇到任何问题,都可以联系我们加入免费体验课或答疑Q群:591897914。
