MySQL进阶:MGR最优化配置推荐,建议收藏
前言
写本篇文章的主要是希望给想用MGR的朋友提供一个参数配置参考,本次内容整理参考了3306π社区广州站《MGR Best Practice》万里DB CTO娄帅分享和一些个人的理解认识。
MySQL InnoDB Cluster架构
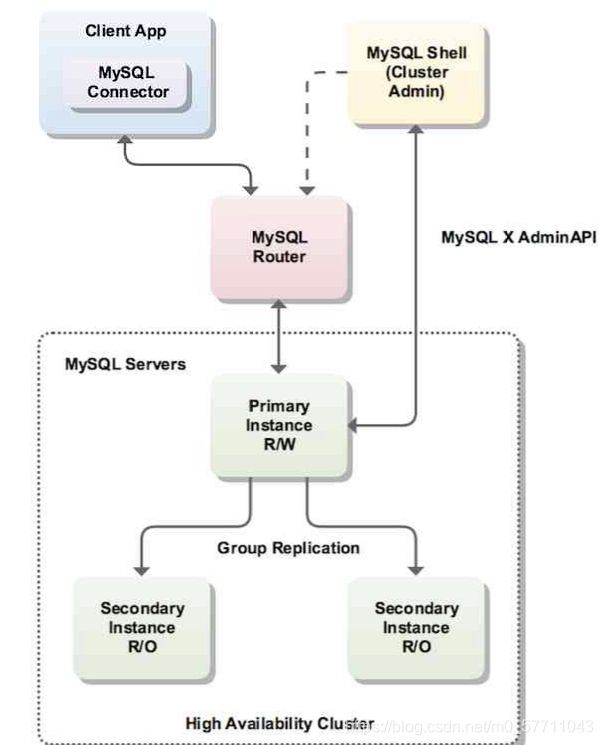
上图引用于官方手册。该架构中包含:MySQL Shell、MySQL router、MySQL Servers。
- MySQL Shell:用于搭建和管理MGR集群的一个客户端工具集。该工具基本是整合了原来官方的mysql utilis工具集。
- MySQL router:属于一个TCP模型的Proxy主要用于流量中转及基于端口号的读写分离。
- MySQL Servers:该部分即为MySQL Group Replication即MGR,这个MGR属于Single primary模式。
MGR配置
目前对于使用MGR还是优先建议使用Single Primary结合mysql router使用。MGR本身的是使用InnoDB,所以对于性能方面优化更多还是要关注InnoDB优化,从另一方面讲MGR也是基于GTID复制的另一种实现,另外使用上也有一些限制,我们可以也可以通过明确相应的约束来避免不支持的功能。
1. 功能需求配置
以下参数是MGR集群限制的必备参数:
default_storage_engine=InnoDB
默认引擎使用InnoDB
server-id
如果没使用mysqlsh搭建MGR,server_id是auto_increment_offset起始值,所以默认推荐使用1-9的数字,如果使用mysqlsh搭建,该值可以随意处理。
binlog_format=row
使用row格式的binlog,这个基本是新功能的标配
gtid_mode=on
启用GTID
enforce_gtid_consistency=on
配合启用GTID使用
sql_require_primary_key=on
每个表必须有主建
binlog_cache_size=8M
通过binlog cache size大小把事务限制在8M以内,减少因为写大事务把MGR搞挂的问题。基于这个配置如果遇到大事务应用端直接会收到报错。
binlog_checksum=none
低于8.0.21版本以前只能使用binlog_checksum=none,高于等于8.0.21可以启用binlog_checksum=crc32
log_error_verbosity=3
MGR还属于新一代的架构,所以运行中建议把log_error_verbosity设置为3,把运行中的INFO也打印到error log中。
2. MGR核心配置
group_replication_single_primary_mode=ON
推荐使用single primary节点,如果使用mysql router可以透明地实现把写传到mysql上。为了减少BUG,应用上失误建议使用single-primary
group_replication_consistency=before
在MGR中如果对于single primary又是大部分时间主节点处理业务,该参数可以配置成: EVENTUAL从而获取最佳的性能;配置成before,是为了保证secondary节点在读写操作时,也不会读以延迟的数据; after是必须保证数据在其它节点应用完毕,这个目前不推荐使用;
BEFORE_ON_PRIMARY_FAILOVER这个参数只是保证在故障接管时按BEFORE的逻辑走。目前这块比较完善的处理推荐:eventual 和 before,不推荐使用after。
group_replication_group_seeds=node1_IP:PORT;node2_IP:PORT;node3_IP:port
MGR节点成员通信的IP及端口后,所以有成员都要写里面。
group_replication_bootstrap_group=off
只有在搭建新集群的过程中打开,新集群搭建完成后立刻关闭,避免节点重启后,搭建新的集群
group_replication_transaction_size_limit=150000000
单个事务大小上限,尽量避免大事务出现,只会在commit时报错,事务执行过程中即使超过阈值也无感知。结合着我们上面提供的binlog_cache_size是8M,则我们在开启binlog的情况,可以把事务限制在8M以内。
group_replication_communication_max_message_size=10M
大事务拆成多个包传输,拆包的大小为10M。将大事务切分成小包,进行paxos传递。
group_replication_flow_control_mode=ON
流控开关,触发流控后,只会延迟等待1s。
group_replication_flow_control_certifier_threshold=25000
触发流控的待认证的队列长度。
3. 性能优化类参数
MGR在数据应用实质上还用的sql_thread,所以这块的优化主要是针对复制优化相关的配置。
- binlog_transaction_dependency_tracking=writeset
- transaction_write_set_extraction=XXHASH64
启用sql_thread的writeset功能 - slave_parallel_worker = 8
并行复制中sql_thread线程数,推荐使用CPU core数的2倍即可 - slave_parallel_type=LOGICAL_CLOCK
配置复制基于事务的并行复制。 - slave_preserve_commit_order=ON
保证事务并行提交按主库上执行的顺序进行。 - slave_checkpoint_period=2
- slave_checkpoint_group=256
加快sql_thread执行过的信息更新到相关的表里,方便看到show slave status及相关监控的数据是更加准确的。
4. 配合使用的配置
group_replication_exit_state_action=READ_ONLY
集群成员退出或是少数派变为read_only不能提供写服务
group_replication_unreachable_majority_timeout=10
网络分区时,少数派状等待此时长后,状态变为Error,回滚pending事务
group_replication_autorejoin_tries=3
自动尝试连入集群的次数,尝试间隔5s(
group_replication_member_expel_timeout),如果设置为0,表示禁用尝试。
group_replication_member_expel_timeout=5
将suspicious节点踢出集群的等待时长,如果网络环境一般,可以适当调大30-60,不要太大。如果设置为0,表示不用等待直接进行ERROR状态
group_replication_member_weight
选主过程中的节点权重,可以将主机房的节点权重加大
clone_valid_donor_list
新加入节点,clone全量数据时,选择的donor节点,尽量使用非主节点作为donor节点
5. InnoDB配置优化
InnoDB部分参数供大家参考一下,就不再单独解释了。
- innodb_buffer_pool_size = 内存的50%-80%
- innodb_buffer_pool_instances = 4-8
- innodb_data_file_path = ibdata1:1024M:autoextend
- innodb_flush_log_at_trx_commit = 1
- innodb_log_buffer_size = 16M
- innodb_log_file_size = 1024M
- innodb_log_files_in_group = 4
- innodb_max_dirty_pages_pct = 75
- innodb_file_per_table = 1
- innodb_rollback_on_timeout
- innodb_io_capacity = 3000
- transaction_isolation = READ-COMMITTED
- innodb_flush_method = O_DIRECT
- innodb_thread_concurrency= 0
- innodb_print_all_deadlocks =on
- innodb_deadlock_detect =on
- innodb_lock_wait_timeout =30
- innodb_parallel_read_threads=4
MGR监控注意事项
本节点是不是online及成员角色:
select member_host, member_port,member_state, member_role from replication_group_members where member_id=@@server_uuid;或是
select member_id,member_host, member_port, member_state, member_role from replication_group_members;
当前节点是不是可以写:
select * from performance_schema.global_variables where variable_name in ('read_only', 'super_read_only');
查看节点上的执行队列情况
select count_transactions_in_queue, count_transactions_remote_in_applier_queue from performance_schema.replication_group_member_stats;
MGR使用上的限制
- 使用奇数个节点:3,5,7,9 最多9个成员。
- 网络稳定,延迟低,尽量避免WAN部署。
- 尽量使用单主模式。
- 表必须有主键。
- 必须使用InnoDB引擎。
- BINLOG_FORMAT=ROW。
- 必须启用GTID。
- 禁止使用外键。
- 不支持GAP LOCK ,MGR工作在RC模式。
- 在多主模式下DML和DDL对同一个表的操作,必须在同一个节点进行,否则会导致集群会crash。
- 在多主模式使用select for update可能会导致整个集群死锁。
- 如果配合mysqlshell使用MySQL版本需要8.0.20及以上。
- 不支持serializable事务模式。
- MGR成员间不支持复制过滤规则。
目前MGR也是官方主推的MySQL InnoDB Cluster主要方案,现在使用的客户比较多,基本可以说比较稳。现在除了官方之外,国内万里数据库也在从事MGR的二次开发工作及商业支持。
本篇完毕,如果有需要补充的地方,可以在评论中交流。如有需要java实战指南、大厂核心面试题、源码解析等学习资料的,可以点击此处获得领取方式