谷粒商城-个人笔记(高级篇二)
目录
二、商城业务-首页
1、整合thymeleaf渲染首页
1)、在“gulimall-product”项目中导入前端代码:
2)、渲染一级分类数据&&整合dev-tools
3)、渲染二级三级分类数据
2、搭建域名访问环境
1)、商城业务-nginx-搭建域名访问环境一(反向代理配置)
2)、nginx-搭建域名访问环境二(负载均衡到网关)
3、性能压测与优化
3.1、压力测试
1)、基本介绍
2)、Apache JMeter安装使用
3)、性能监控-jvisualvm使用
3.2、性能优化
1)、中间件对性能的影响
2)、简单优化吞吐量测试
3)、Nginx动静分离
4)、模拟线上应用内存崩溃宕机情况
5)、优化三级分类数据获取
三、缓存
1、缓存使用
1)、缓存的演化
2)、分布式缓存
2、整合redis测试
3、改造三级分类业务
4、压力测试出的内存泄露及解决
5、高并发下缓存失效问题--缓存击穿、穿透、雪崩
1)、加锁解决缓存击穿问题
2)、锁时序问题
6、本地锁在分布式下的问题
7、分布式锁原理与使用
1) 、本地缓存面临问题
2)、分布式锁
3) 、分布式锁的演进
8、Redisson
1)、Redisson-lock锁测试
3)、Redisson-lock看门狗原理-redisson如何解决死锁
4)、读写锁测试
6)、信号量测试
7)、缓存一致性解决
9、SpringCache-简介
1)、简洁
2)、基础概念
3)、SpringCache-整合&体验@Cacheable
4)、@Cacheable细节设置
5)、自定义缓存配置
6)、@CacheEvict
7)、SpringCache-原理与不足
四、检索
1. 检索条件分析
2. DSL分析
3. 检索代码编写
4. 页面效果
五、异步
1、线程池
1)、七大参数
2)、工作顺序
3)、常见的4种线程池
4)、使用线程池的好处
2、CompletableFuture组合式异步编程
1)、创建异步对象
2)、计算结果完成时的回调方法
3)、handle 方法
4)、线程串行化
5)、两任务组合-都要完成
6)、两任务组合-只要有一个任务完成就执行第三个
7)、多任务组合
六、商品详情
1、搭建好域名跳转环境
2、模型抽取
3、 封装商品属性
3、页面渲染
4、页面的sku切换
5、使用异步编排
二、商城业务-首页
1、整合thymeleaf渲染首页
1)、在“gulimall-product”项目中导入前端代码:

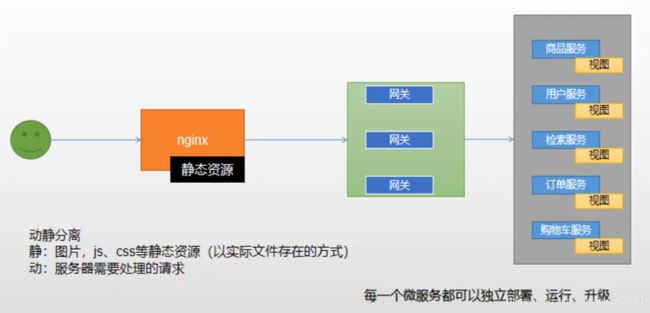
项目在发布的时候,将静态资源放到nginx中,实现动静分离
引入"thymeleaf"依赖:
前端使用了thymeleaf开发,因此要导入该依赖,并且为了改动页面实时生效导入devtools
org.springframework.boot
spring-boot-starter-thymeleaf
将静态资源放入到static文件夹下,而将index.html放入到templates文件夹下:

在“application.yml”文件中设置thymeleaf,关闭thymeleaf缓存,路径为:spring.thymeleaf
spring:
thymeleaf:
cache: false同时将“controller”修改为app,以后它都是被移动APP所访问的地方。
创建web文件夹:

启动“gulimall-product”服务,根据路径就可以直接访问静态资源
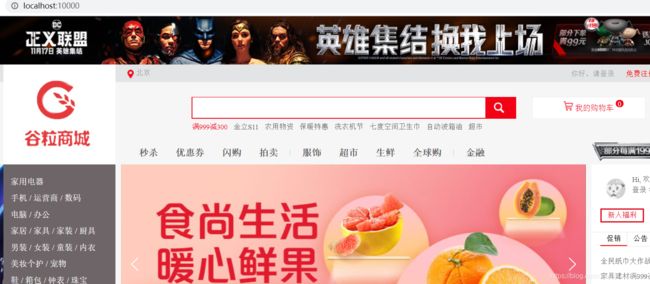
在静态资源目录static下的资源,可以直接访问,如:http://localhost:10000/index/css/GL.css

SpringBoot在访问项目的时候,会默认找到index文件夹下的文件。
这些规则是配置在“ResourceProperties”文件中指定的:
private static final String[] CLASSPATH_RESOURCE_LOCATIONS = { "classpath:/META-INF/resources/",
"classpath:/resources/", "classpath:/static/", "classpath:/public/" };
关于欢迎页,它是在静态文件夹中,寻找index.html页面的:
org.springframework.boot.autoconfigure.web.servlet.WebMvcAutoConfigurationprivate Optional getWelcomePage() {
String[] locations = getResourceLocations(this.resourceProperties.getStaticLocations());
return Arrays.stream(locations).map(this::getIndexHtml).filter(this::isReadable).findFirst();
}
private Resource getIndexHtml(String location) {
return this.resourceLoader.getResource(location + "index.html");
} 2)、渲染一级分类数据&&整合dev-tools
现在想要实现的效果是访问http://localhost:10000/index.html能访问,另外当
在thymeleaf中,默认的访问的前缀和后缀
//前缀
public static final String DEFAULT_PREFIX = "classpath:/templates/";
//后缀
public static final String DEFAULT_SUFFIX = ".html";当controller中返回的是一个视图地址,它就会使视图解析器进行拼串。
查询出所有的一级分类:
2.1)、渲染一级分类菜单
由于访问首页时就要加载一级目录,所以我们需要在加载首页时获取该数据
修改“com.atguigu.gulimall.product.web.IndexController”类,修改如下:
@GetMapping({"/", "index.html"})
public String getIndex(Model model) {
//获取所有的一级分类
List catagories = categoryService.getLevel1Catagories();
model.addAttribute("catagories", catagories);
return "index";
} 修改“com.atguigu.gulimall.product.service.CategoryService”类,修改如下:
List getLevel1Category(); 修改“com.atguigu.gulimall.product.service.impl.CategoryServiceImpl”类,修改如下:
@Override
public List getLevel1Category() {
List categoryEntities = baseMapper.selectList(new QueryWrapper().eq("parent_cid", 0));
return categoryEntities;
} 2.2)、dev-tools实现不重启服务实时生效
1、添加devtools依赖
org.springframework.boot
spring-boot-devtools
true
2、编译页面
执行“ctrl+shift+F9”重新编译页面或“ctrl+F9”重新编译整个项目。
3、代码配置方面,还是建议重启服务
通过引入该devtools,能够实现在IDEA中修改了页面后,无效重启整个服务就可以实现刷新页面,但是在修改页面后,需要执行“ctrl+shift+F9”重新编译页面或“ctrl+F9”重新编译整个项目。
thymeleaf下载地址:https://www.thymeleaf.org/doc/tutorials/3.0/usingthymeleaf.pdf
渲染页面index.html页面:
引入Thymeleaf
页面遍历菜单数据
3)、渲染二级三级分类数据
首页加载的数据默认来自于静态资源的“index/catalog.json”,现在需要让它重数据库实时读取

添加“com.atguigu.gulimall.product.web.IndexController”类,代码如下:
@ResponseBody
@GetMapping("/index/catelog.json")
public Map> getCatelogJson(){
Map> catelogJson = categoryService.getCatelogJson();
return catelogJson;
} 添加“com.atguigu.gulimall.product.vo.Catelog2Vo”类,代码如下:
//二级分类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Catelog2Vo {
private String catelog1Id; //一级父分类id
private List catalog3List; //三级子分类
private String id;
private String name;
//三级分类
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Catalog3Vo{
private String catelog2Id; //父分类,2级分类id
private String id;
private String name;
}
}
修改“com.atguigu.gulimall.product.service.impl.CategoryServiceImpl”类,代码如下:
/**
* 逻辑是
* (1)根据一级分类,找到对应的二级分类
* (2)将得到的二级分类,封装到Catelog2Vo中
* (3)根据二级分类,得到对应的三级分类
* (3)将三级分类封装到Catalog3List
* @return
*/
@Override
public Map> getCatelogJson() {
//查出所有1级分类
List level1Category = getLevel1Category();
//2、封装数据
Map> parent_cid = level1Category.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
//1、每一个的一级分类,查到这个一级分类的二级分类
List categoryEntities = baseMapper.selectList(new QueryWrapper().eq("parent_cid", v.getCatId()));
//2、封装上面的结果
List catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
//1、找当前二级分类的三级分类封装vo
List level3Catelog = baseMapper.selectList(new QueryWrapper().eq("parent_cid", l2.getCatId()));
if (level3Catelog != null){
List collect = level3Catelog.stream().map(l3 -> {
//2、封装成指定格式
Catelog2Vo.Catelog3Vo catelog3Vo = new Catelog2Vo.Catelog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatelog3List(Collections.singletonList(collect));
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
}
2、搭建域名访问环境
1)、商城业务-nginx-搭建域名访问环境一(反向代理配置)
Nginx+windows搭建域名访问环境

正向代理和反向代理

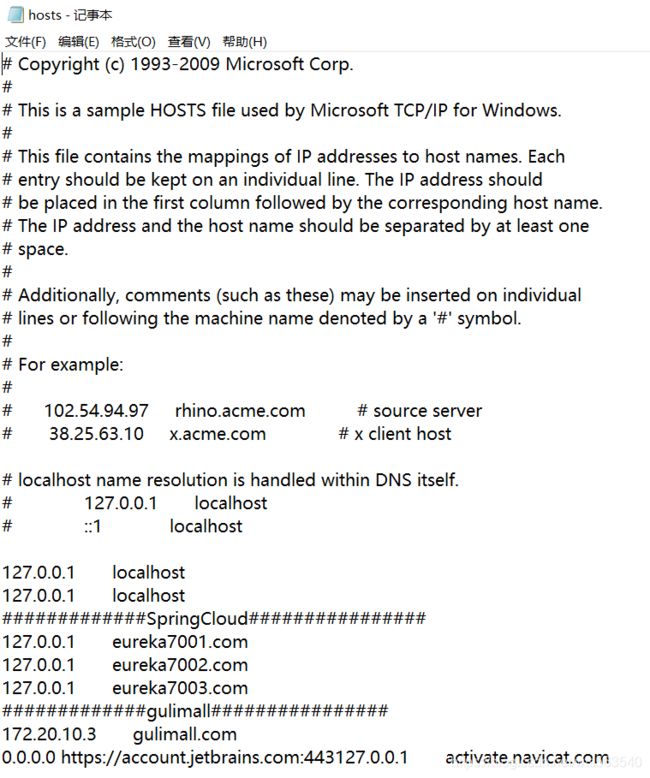
修改本地的C:\Windows\System32\drivers\etc\hosts文件,添加域名映射规则:
先把只读模式去掉,才可以编辑

192.168.43.125 gulimall.com
192.168.43.125 为Nginx所在的设备
测试Nginx的访问:http://gulimall.com/

关于Nginx的配置文件:


user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}注意这里的“include /etc/nginx/conf.d/*.conf;”,它是将“/etc/nginx/conf.d/*.conf”目录下的所有配置文件包含到nginx.conf文件中。下面是该文件的内容:

server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log /var/log/nginx/host.access.log main;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}在Nginx上配置代理,使得所有到gulimall.com的请求,都转到gulimall-product服务。
现在需要明确部署情况,我们的nginx部署在172.20.10.3(虚拟机ip)上,而且是以docker容器的方式部署的,部署时将本机的/mydata/nginx/conf/挂载到了nginx容器的“/etc/nginx ”目录,gulimall-product服务部署在172.20.10.2(主机ip)上。
在172.20.10.3上创建“gulimall.conf”文件:


修改配置文件完毕后,重启nginx。
访问:http://gulimall.com/
整个的数据流是这样的:浏览器请求gulimall.com,在本机被解析为172.20.10.3(虚拟机ip),172.20.10.3的80端口接收到请求后,解析请求头求得host,在然后使用在“gulimall.conf”中配置的规则,将请求转到“http://172.20.10.2:10002”(主机ip),然后该服务响应请求,返回响应结果。
但是这样做还是有些不够完美,“gulimall-product”可能部署在多台服务器上,通常请求都会被负载到不同的服务器上,这里我们直接指定一台设备的方式,显然不合适。
2)、nginx-搭建域名访问环境二(负载均衡到网关)
2.1)关于Nginx的负载均衡
使用Nginx作为Http负载均衡器
http://nginx.org/en/docs/http/load_balancing.html
默认的负载均衡配置:
http {
upstream myapp1 {
server srv1.example.com;
server srv2.example.com;
server srv3.example.com;
}
server {
listen 80;
location / {
proxy_pass http://myapp1;
}
}
}In the example above, there are 3 instances of the same application running on srv1-srv3. When the load balancing method is not specifically configured, it defaults to round-robin. All requests are proxied to the server group myapp1, and nginx applies HTTP load balancing to distribute the requests.
在上面的例子中,同一个应用程序有3个实例在srv1-srv3上运行。如果没有特别配置负载平衡方法,则默认为 round-robin。所有请求都代理到服务器组myapp1, nginx应用HTTP负载平衡来分发请求。
Reverse proxy implementation in nginx includes load balancing for HTTP, HTTPS, FastCGI, uwsgi, SCGI, memcached, and gRPC.
nginx中的反向代理实现包括HTTP、HTTPS、FastCGI、uwsgi、SCGI、memcached和gRPC的负载均衡。
To configure load balancing for HTTPS instead of HTTP, just use “https” as the protocol.
要为HTTPS而不是HTTP配置负载平衡,只需使用“HTTPS”作为协议。
When setting up load balancing for FastCGI, uwsgi, SCGI, memcached, or gRPC, use fastcgi_pass, uwsgi_pass, scgi_pass, memcached_pass, and grpc_pass directives respectively.
在为FastCGI、uwsgi、SCGI、memcached或gRPC设置负载均衡时,分别使用fastcgi_pass、uwsgi_pass、scgi_pass、memcached_pass和grpc_pass指令。
2)配置负载均衡:
1)修改“/mydata/nginx/conf/nginx.conf”,添加如下内容


注意:这里的88端口为“gulimall-gateway”服务的监听端口,也即访问“gulimall-product”服务通过该网关进行路由。
(2)修改“/mydata/nginx/conf/conf.d/gulimall.conf”文件


(3)在“gulimall-gateway”添加路由规则:
- id: gulimall_host_route
uri: lb://gulimall-product
predicates:
- Host=**.gulimall.com注意:这个路由规则,一定要放置到最后,否则会优先进行Host匹配,导致其他路由规则失效。
(4)配置完成后,重启Nginx,再次访问
docker restart nginx
再次访问的时候,返回404状态码

但是通过niginx请求“gulimall-product”服务的其他controller却能够顺利访问。
http://gulimall.com/api/product/category/list/tree

原因分析:Nginx代理给网关的时候,会丢失请求头的很多信息,如HOST信息,Cookie等。
解决方法:需要修改Nginx的路径映射规则,加上“ proxy_set_header Host $host;”
http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_set_header
However, if this field is not present in a client request header then nothing will be passed. In such a case it is better to use the $host variable - its value equals the server name in the “Host” request header field or the primary server name if this field is not present:
proxy_set_header Host $host;
修改“gulimall.conf”文件

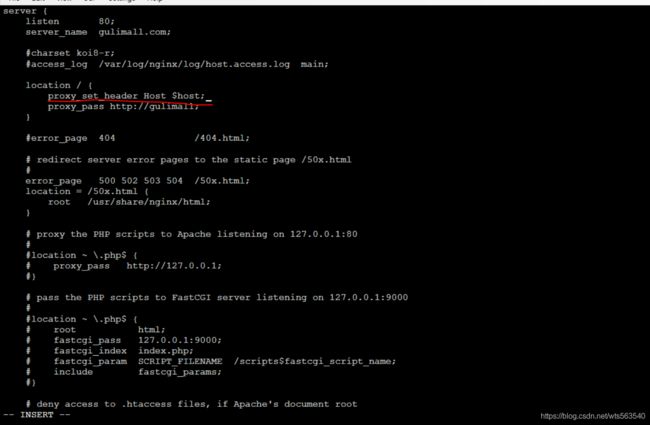
重启Nginx容器,再次访问Success:
docker restart nginx

3、性能压测与优化
3.1、压力测试
1)、基本介绍



2)、Apache JMeter安装使用
jmeter压力测试工具

查看响应结果
汇总图:

JMeter在windows下地址占用bug解决

堆内存与垃圾回收








3)、性能监控-jvisualvm使用



https://visualvm.github.io/uc/8u131/updates.xml.gz

实例:如下面我们想要可视化GC的过程,可以安装这个插件

安装完成后,重启jvisualvm
然后连接我们的gulimall-product服务进程

在GC选项卡能够看到GC发生过程:

3.2、性能优化
1)、中间件对性能的影响
(1)启动Jmeter
(2)创建线程组


(3)添加一个HTTP请求
这里我们测试Nginx的性能,先看Nginx是否能正常访问:

添加HTTP请求:
填写请求指标:
(4)添加“查看结果树”,“汇总报告”和“聚合报告”


(5)在nginx所在的机器172.20.10.3上,执行docker stats
通过docker stats命令,能够看到nginx容器的内存,cpu的占用情况

(6)启动jmeter
大概50秒左右,停止jmeter
(7)停止jmeter,查看报告
查看结果数,部分请求因socket关闭发送失败

查看汇总报告

查看聚合报告


2)、简单优化吞吐量测试


3)、Nginx动静分离
Nginx动静分离,也就是将访问静态资源和动态资源区分开,将静态资源放置到Nginx上

通过前面的吞吐量测试,我们能够看到访问静态资源对于“gulimall-product”服务造成的访问压力,在生产中我们可以考虑将这部分静态资源部署到Nginx上来优化。
在“gulimall-product”微服务中,原来的所有静态资源都放置到了resources/static,在做动静分离的时候,我们可以考虑将这些资源迁移到Nginx上。
迁移方法:
(1)找到Nginx存放静态资源的位置。这里我们使用的是Nginx容器,将本地“/mydata/nginx/html”映射到远程的“/usr/share/nginx/html”,所以应该将静态资源放置到该目录下。
(2)在/mydata/nginx/html目录下创建static文件夹: mkdir static
(3)使用SecureFX传送工具(换了一个连接虚拟机的客户端工具),将“gulimall-product/src/main/resources/static ”下的“index”静态资源放置到Nginx路径中。

(4)ctrl+R 修改index.html“”页面,将所有的对于静态资源的访问加上static路径


(5)修改Nginx的“gulimall.conf”文件,这里指定所有static的访问,都是到“/usr/share/nginx/html”路径下寻找


(6)、重启Nginx
docker restart nginx
(7)测试效果

4)、模拟线上应用内存崩溃宕机情况
再次进行压测:


执行压测
查看测试报告

同时通过jvisualvm查看GC过程

能够看到在老年代中存在耗时的GC过程,并且随着并发量增加,已经开始出现OutOfMemoryError异常了

并且服务也会down掉:

现在我们可以通过增加服务占用的内存大小,来控制减少Full GC发生的频率

5)、优化三级分类数据获取
来看我们之前编写的获取三级分类的业务逻辑:
@Override
public Map> getCatelogJson() {
//1.查出所有一级分类
List level1Categories = getLevel1Categories();
Map> parent_cid = level1Categories.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), level1 -> {
//2. 根据一级分类的id查找到对应的二级分类
List level2Categories = this.baseMapper.selectList(new QueryWrapper().eq("parent_cid", level1.getCatId()));
//3. 根据二级分类,查找到对应的三级分类
List catelog2Vos =null;
if(null != level2Categories || level2Categories.size() > 0){
catelog2Vos = level2Categories.stream().map(level2 -> {
//得到对应的三级分类
List level3Categories = this.baseMapper.selectList(new QueryWrapper().eq("parent_cid", level2.getCatId()));
//封装到Catalog3List
List catalog3Lists = null;
if (null != level3Categories) {
catalog3Lists = level3Categories.stream().map(level3 -> {
Catalog3List catalog3List = new Catalog3List(level2.getCatId().toString(), level3.getCatId().toString(), level3.getName());
return catalog3List;
}).collect(Collectors.toList());
}
return new Catelog2Vo(level1.getCatId().toString(), catalog3Lists, level2.getCatId().toString(), level2.getName());
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
} (1)先从数据库中查询所有的一级分类
(2)根据一级分类的ID到数据库中找到对应的二级分类
(3)根据二级分类的ID,到数据库中寻找到对应的三级分类
在这个逻辑实现中,每一个一级分类的ID,至少要经过3次数据库查询才能得到对应的三级分类,所以在大数据量的情况下,频繁的操作数据库,性能比较低。
我们可以考虑将这些分类数据一次性的load到内存中,在内存中来操作这些数据,而不是频繁的进行数据库交互操作,下面是优化后的查询
@Override
public Map> getCatelogJson() {
//一次性查询出所有的分类数据,减少对于数据库的访问次数,后面的数据操作并不是到数据库中查询,而是直接从这个集合中获取,
// 由于分类信息的数据量并不大,所以这种方式是可行的
List categoryEntities = this.baseMapper.selectList(null);
//1.查出所有一级分类
List level1Categories = getParentCid(categoryEntities,0L);
Map> parent_cid = level1Categories.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), level1 -> {
//2. 根据一级分类的id查找到对应的二级分类
List level2Categories = getParentCid(categoryEntities,level1.getCatId());
//3. 根据二级分类,查找到对应的三级分类
List catelog2Vos =null;
if(null != level2Categories || level2Categories.size() > 0){
catelog2Vos = level2Categories.stream().map(level2 -> {
//得到对应的三级分类
List level3Categories = getParentCid(categoryEntities,level2.getCatId());
//封装到Catalog3List
List catalog3Lists = null;
if (null != level3Categories) {
catalog3Lists = level3Categories.stream().map(level3 -> {
Catalog3List catalog3List = new Catalog3List(level2.getCatId().toString(), level3.getCatId().toString(), level3.getName());
return catalog3List;
}).collect(Collectors.toList());
}
return new Catelog2Vo(level1.getCatId().toString(), catalog3Lists, level2.getCatId().toString(), level2.getName());
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
}
/**
* 在selectList中找到parentId等于传入的parentCid的所有分类数据
* @param selectList
* @param parentCid
* @return
*/
private List getParentCid(List selectList,Long parentCid) {
List collect = selectList.stream().filter(item -> item.getParentCid() == parentCid).collect(Collectors.toList());
return collect;
}
整体的逻辑就是每次根据分类ID,找到所有子分类数据的时候,不再从数据库中查找,而是在内存中查询。
我们可以通过Jmeter来测试一下优化后的查询效率
请求参数设置如下:

下面是测试的比对:

三、缓存
1、缓存使用
对于复杂的业务,已经不能够通过代码层面的优化和数据库层面的优化,来达到增加吞吐量的目的。这就想要使用到缓存。


1)、缓存的演化
本地缓存

分布式本地缓存
分布式缓存-本地模式在分布式下的问题

这种情况下,每个服务维持一个缓存,所带来的问题:
(1)缓存不共享
在这种情况下,每个服务都有一个缓存,但是这个缓存并不共享,水平上当调度到另外一个台设备上的时候,可能它的服务中并不存在这个缓存,因此需要重新查询。
(2)缓存一致性问题
在一台设备上的缓存更新后,其他设备上的缓存可能还未更新,这样当从其他设备上获取数据的时候,得到的可能就是未给更新的数据。
2)、分布式缓存

在这种下,一个服务的不同副本共享同一个缓存空间,缓存放置到缓存中间件中,这个缓存中间件可以是redis等,而且缓存中间件也是可以水平或纵向扩展的,如Redis可以使用redis集群。它打破了缓存容量的限制,能够做到高可用,高性能。
2、整合redis测试
在“gulimall-product”项目中引入redis
org.springframework.boot
spring-boot-starter-data-redis
Reids是通过“RedisAutoConfiguration”来完成的,它将所有的配置信息,都放置到了“RedisProperties”中。
配置redis主机地址
spring:
redis:
host: 172.20.10.3
port: 6379这里我们的Redis服务器为172.20.10.3,部署的是Redis容器。
在“”类中,提供了两种操作Redis的方式:
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RedisOperations.class)
@EnableConfigurationProperties(RedisProperties.class)
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
@Bean
@ConditionalOnMissingBean(name = "redisTemplate")
//将保存进入Redis的键值都是Object
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
RedisTemplate template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean
//保存进Redis的数据,键值是(String,String)
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
} 关于“StringRedisTemplate”
public class StringRedisTemplate extends RedisTemplate {
/**
* Constructs a new StringRedisTemplate instance. {@link #setConnectionFactory(RedisConnectionFactory)}
* and {@link #afterPropertiesSet()} still need to be called.
*/
public StringRedisTemplate() {
setKeySerializer(RedisSerializer.string());//键序列化为String
setValueSerializer(RedisSerializer.string());//key序列化为String
setHashKeySerializer(RedisSerializer.string());
setHashValueSerializer(RedisSerializer.string());
} 综上:SpringBoot整合Redis的方式
(1)引入“spring-boot-starter-data-redis”
(2)简单配置Redis的host等信息
(3)使用SpringBoot自动配置好的"StringRedisTemplate"来操作redis。
测试:
引入StringRedisTemplate
@Autowired
StringRedisTemplate redisTemplate;
@Test
public void testStringRedisTemplate(){
ValueOperations ops = stringRedisTemplate.opsForValue();
//保存
ops.set("hello","world_"+ UUID.randomUUID().toString());
//查询
String hello = ops.get("hello");
System.out.println("之前保存的数据是:"+hello);
} 
在Redis上查看结果

3、改造三级分类业务
先从缓存中获取分类三级分类数据,如果没有再从数据库中查询,并且将查询结果以JSON字符串的形式存放到Reids中的。
@Override
public Map> getCatelogJson() {
//给缓存中放json字符串,拿出json字符串,还要逆转为能用的对象类型【序列化与反序列化】
//1、加入缓存逻辑
//JSON好处是跨语言,跨平台兼容。
String catalogJSON = redisTemplate.opsForValue().get("catalogJSON");
if (StringUtils.isEmpty(catalogJSON)){
//2、缓存中没有,查询数据库
Map> catelogJsonFromDB = getCatelogJsonFromDB();
//3、将查到的数据再放入缓存,将对象转为JSON在缓存中
String jsonString = JSON.toJSONString(catelogJsonFromDB);
redisTemplate.opsForValue().set("catalogJSON",jsonString);
return catelogJsonFromDB;
}
//转为我们指定的对象。
Map> result = JSON.parseObject(catalogJSON,new TypeReference>>(){});
return result;
} private Map> getDataFromDB() {
String catalogJSON = redisTemplate.opsForValue().get("catalogJSON");
if (!StringUtils.isEmpty(catalogJSON)) {
//如果缓存不为null直接缓存
Map> result = JSON.parseObject(catalogJSON, new TypeReference>>() {
});
return result;
}
System.out.println("查询了数据库。。。。。");
List selectList = baseMapper.selectList(null);
//查出所有一级分类
List level1Category = getParent_cid(selectList, 0L);
//2、封装数据
Map> parent_cid = level1Category.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
//1、每一个的一级分类,查到这个一级分类的二级分类
List categoryEntities = getParent_cid(selectList, v.getCatId());
//2、封装上面的结果
List catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
//1、找当前二级分类的三级分类封装vo
List level3Catelog = getParent_cid(selectList, l2.getCatId());
if (level3Catelog != null) {
List collect = level3Catelog.stream().map(l3 -> {
//2、封装成指定格式
Catelog2Vo.Catalog3Vo catelog3Vo = new Catelog2Vo.Catalog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(collect);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
//3、将查到的数据再放入缓存,将对象转为JSON在缓存中
String jsonString = JSON.toJSONString(parent_cid);
redisTemplate.opsForValue().set("catalogJSON", jsonString, 1, TimeUnit.DAYS);
return parent_cid;
}
4、压力测试出的内存泄露及解决
启动“gulimall-product”和“gulimall-gateway”
执行压测:

测试报告:

再次访问页面出现了异常:

堆外内存溢出的原因,

解决方法:
修改“gulimall-product”的“pom.xml”文件,更换为Jedis
org.springframework.boot
spring-boot-starter-data-redis
io.lettuce
lettuce-core
redis.clients
jedis
再次执行压测,没有出现Error:

使用Redis作为缓存后,吞吐量得到了很大的提升,响应时间也缩短了很多:

5、高并发下缓存失效问题--缓存击穿、穿透、雪崩
前面我们将查询三级分类数据的查询进行了优化,将查询结果放入到Redis中,当再次获取到相同数据的时候,直接从缓存中读取,没有则到数据库中查询,并将查询结果放入到Redis缓存中

但是在分布式系统中,这样还是会存在问题。
缓存穿透

缓存雪崩

缓存击穿

简单来说:缓存穿透是指查询一个永不存在的数据;缓存雪崩是值大面积key同时失效问题;缓存击穿是指高频key失效问题;
1)、加锁解决缓存击穿问题

将查询db的方法加锁,这样在同一时间只有一个方法能查询数据库,就能解决缓存击穿的问题了
现在针对于单体应用上的加锁,我们来测试一下它是否能够正常工作。
(1)删除“redis”中的“catelogJson”

(2)修改三级分类的代码
@Override
public Map> getCatelogJson() {
//给缓存中放json字符串,拿出json字符串,还要逆转为能用的对象类型【序列化与反序列化】
/**
* 1、空结果缓存,解决缓存穿透
* 2、设置过期时间(随机加值);解决缓存雪崩
* 3、加锁,解决缓存击穿
*/
//1、加入缓存逻辑
//JSON好处是跨语言,跨平台兼容。
String catalogJSON = redisTemplate.opsForValue().get("catalogJSON");
if (StringUtils.isEmpty(catalogJSON)){
//2、缓存中没有,查询数据库
System.out.println("缓存不命中.....将要查询数据库...");
Map> catelogJsonFromDB = getCatelogJsonFromDB();
//3、将查到的数据再放入缓存,将对象转为JSON在缓存中
String jsonString = JSON.toJSONString(catelogJsonFromDB);
redisTemplate.opsForValue().set("catalogJSON",jsonString,1, TimeUnit.DAYS);
return catelogJsonFromDB;
}
System.out.println("缓存命中...直接返回...");
//转为我们指定的对象。
Map> result = JSON.parseObject(catalogJSON,new TypeReference>>(){});
return result;
}
//从数据库查询并封装分类数据
public Map> getCatelogJsonFromDB() {
//只要同一把锁就能锁住需要这个锁的所有线程
//1、synchronized(this):SpringBoot所有的组件在容器中都是单例的
// TODO 本地锁:synchronized,JUC(lock)。在分布式情况下想要锁住所有,必须使用分布式锁
//使用DCL(双端检锁机制)来完成对于数据库的访问
synchronized (this){
//得到锁以后,我们应该再去缓存中确定一次,如果没有才需要继续查询
String catalogJSON = redisTemplate.opsForValue().get("catalogJSON");
if (!StringUtils.isEmpty(catalogJSON)){
//如果缓存不为null直接缓存
Map> result = JSON.parseObject(catalogJSON,new TypeReference>>(){});
return result;
}
System.out.println("查询了数据库。。。。。");
/**
* 1、将数据库的多次查询变为1次
*/
List selectList = baseMapper.selectList(null);
//查出所有一级分类
List level1Category = getParent_cid(selectList,0L);
//2、封装数据
Map> parent_cid = level1Category.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
//1、每一个的一级分类,查到这个一级分类的二级分类
List categoryEntities = getParent_cid(selectList,v.getCatId());
//2、封装上面的结果
List catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
//1、找当前二级分类的三级分类封装vo
List level3Catelog = getParent_cid(selectList,l2.getCatId());
if (level3Catelog != null){
List collect = level3Catelog.stream().map(l3 -> {
//2、封装成指定格式
Catelog2Vo.Catelog3Vo catelog3Vo = new Catelog2Vo.Catelog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatelog3List(Collections.singletonList(collect));
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
}
}
在上述方法中,我们将业务逻辑中的确认缓存没有和查数据库放到了锁里,但是最终控制台却打印了两次查询了数据库。这是因为在将结果放入缓存的这段时间里,有其他线程确认缓存没有,又再次查询了数据库,因此我们要将结果放入缓存也进行加锁
2)、锁时序问题

(1)删除“redis”中的“catelogJson”
优化代码逻辑后
@Override
public Map> getCatelogJson() {
//给缓存中放json字符串,拿出json字符串,还要逆转为能用的对象类型【序列化与反序列化】
/**
* 1、空结果缓存,解决缓存穿透
* 2、设置过期时间(随机加值);解决缓存雪崩
* 3、加锁,解决缓存击穿
*/
//1、加入缓存逻辑
//JSON好处是跨语言,跨平台兼容。
String catalogJSON = redisTemplate.opsForValue().get("catalogJSON");
if (StringUtils.isEmpty(catalogJSON)){
//2、缓存中没有,查询数据库
System.out.println("缓存不命中.....将要查询数据库...");
Map> catelogJsonFromDB = getCatelogJsonFromDB();
}
System.out.println("缓存命中...直接返回...");
//转为我们指定的对象。
Map> result = JSON.parseObject(catalogJSON,new TypeReference>>(){});
return result;
}
//从数据库查询并封装分类数据
public Map> getCatelogJsonFromDB() {
//只要同一把锁就能锁住需要这个锁的所有线程
//1、synchronized(this):SpringBoot所有的组件在容器中都是单例的
// TODO 本地锁:synchronized,JUC(lock)。在分布式情况下想要锁住所有,必须使用分布式锁
//使用DCL(双端检锁机制)来完成对于数据库的访问
synchronized (this){
//得到锁以后,我们应该再去缓存中确定一次,如果没有才需要继续查询
String catalogJSON = redisTemplate.opsForValue().get("catalogJSON");
if (!StringUtils.isEmpty(catalogJSON)){
//如果缓存不为null直接缓存
Map> result = JSON.parseObject(catalogJSON,new TypeReference>>(){});
return result;
}
System.out.println("查询了数据库。。。。。");
/**
* 1、将数据库的多次查询变为1次
*/
List selectList = baseMapper.selectList(null);
//查出所有一级分类
List level1Category = getParent_cid(selectList,0L);
//2、封装数据
Map> parent_cid = level1Category.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
//1、每一个的一级分类,查到这个一级分类的二级分类
List categoryEntities = getParent_cid(selectList,v.getCatId());
//2、封装上面的结果
List catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
//1、找当前二级分类的三级分类封装vo
List level3Catelog = getParent_cid(selectList,l2.getCatId());
if (level3Catelog != null){
List collect = level3Catelog.stream().map(l3 -> {
//2、封装成指定格式
Catelog2Vo.Catelog3Vo catelog3Vo = new Catelog2Vo.Catelog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatelog3List(Collections.singletonList(collect));
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
//3、将查到的数据再放入缓存,将对象转为JSON在缓存中
String jsonString = JSON.toJSONString(parent_cid);
redisTemplate.opsForValue().set("catalogJSON",jsonString,1, TimeUnit.DAYS);
return parent_cid;
}
} 这里我们使用了双端检锁机制来控制线程的并发访问数据库。一个线程进入到临界区之前,进行缓存中是否有数据,进入到临界区后,再次判断缓存中是否有数据,这样做的目的是避免阻塞在临界区的多个线程,在其他线程释放锁后,重复进行数据库的查询和放缓存操作。
注:关于双端检锁机制的简单了解,可以参照:https://www.cnblogs.com/cosmos-wong/p/11914878.html
(3)后执行压测,使用100个线程来回发送请求:

优化后多线程访问时仅查询一次数据库

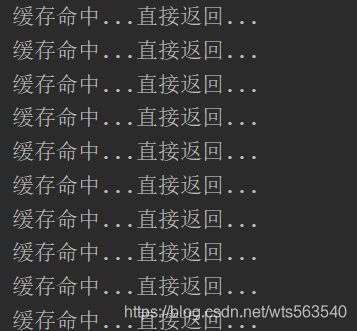
5)结论
通过观察日志,能够发现只有一个线程查询了数据库,其他线程都是直接从缓存中获取到数据的。所以在单体应用上实现了多线程的并发访问。
由于这里我们的“gulimall-product”就部署了一台,所以看上去一切祥和,但是在如果部署了多台,问题就出现了,主要问题就集中在我们所使用的锁上。我们锁使用的是“synchronized ”,这是一种本地锁,它只是在一台设备上有效,无法实现分布式情况下,锁住其他设备的相同操作。
我们现在的操作模型,表现为如下的形式:

6、本地锁在分布式下的问题
1)、删除“redis”中的“catelogJson”
2)、复制服务
为了演示在分布式情况下本地锁的工作状况,我们将“gulimall-product”按照如下的方式复制了2份


这样形成了2个复制的和一个原生的:

3)、启动服务
同时启动四个服务,此时在Nacos中我们可以看到“gulimall-product”服务具有四个实例:
4)、执行压测
在修改Jmeter的HTTP请求参数:

注意:之前我们在配置Nginx的时候,配置了upstream,所以它会将请求转给网关,通过网关负载均衡到“gulimall”服务的多个实例上:
在Jmeter中修改本次测试所使用的线程数和循环次数:

启动Jmeter进行压测
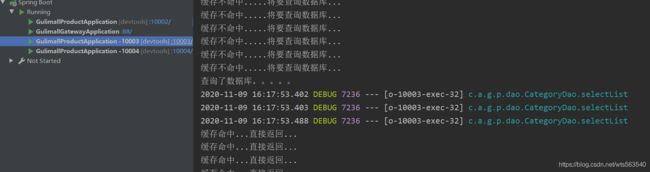
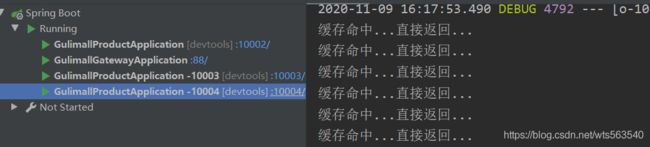
5)、查看结果
查看各个微服务的输出:
10002

10003:
10004:

总结:
能够发现,四个服务,分别存在着四个缓存未命中的情况,也就意味着会有四次查询数据库的操作,显然我们的synchronize锁未能实现限制其他服务实例进入临界区,也就印证了在分布式情况下,本地锁只能针对于当前的服务生效。
7、分布式锁原理与使用
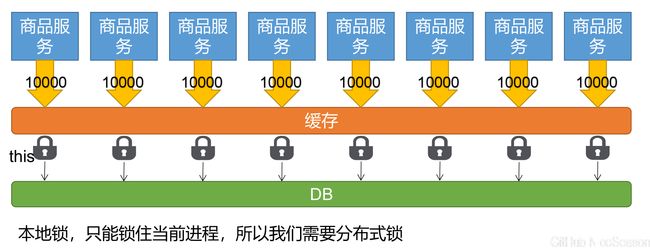
1) 、本地缓存面临问题
当有多个服务存在时,每个服务的缓存仅能够为本服务使用,这样每个服务都要查询一次数据库,并且当数据更新时只会更新单个服务的缓存数据,就会造成数据不一致的问题

所有的服务都到同一个redis进行获取数据,就可以避免这个问题
2)、分布式锁
当分布式项目在高并发下也需要加锁,但本地锁只能锁住当前服务,这个时候就需要分布式锁
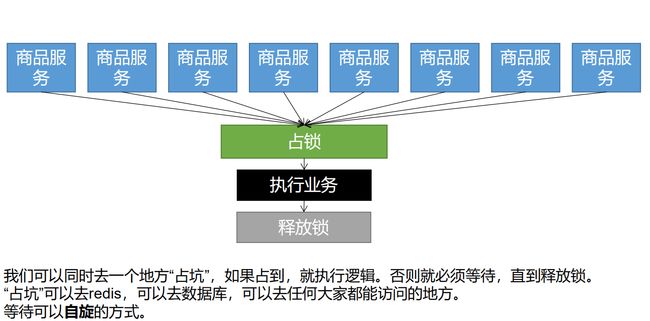
3) 、分布式锁的演进
基本原理
下面使用redis来实现分布式锁,使用的是SET key value [EX seconds] [PX milliseconds] [NX|XX],http://www.redis.cn/commands/set.html
(1)打开SecureCRT,创建四个Redis的redis-cli连接
(2)同时执行“set loc 1 NX”观察四个窗口的输出
将命令批量发送到四个窗口的的方式:
阶段一

public Map> getCatalogJsonDbWithRedisLock() {
//阶段一
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111");
//获取到锁,执行业务
if (lock) {
//加锁成功。。。执行业务
//2、设置过期时间,必须和加锁是同步的,原子的
Map> dataFromDB = getDataFromDB();
redisTemplate.delete("lock");//删除锁
return dataFromDB;
}else {
//没获取到锁,等待100ms重试
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatalogJsonDBWithRedisLock();
}
} 问题: 1、setnx占好了位,业务代码异常或者程序在页面过程中宕机。没有执行删除锁逻辑,这就造成了死锁
解决:设置锁的自动过期,即使没有删除,会自动删除
阶段二

public Map> getCatelogJsonFromDBWithRedisLock() {
//1、占分布式锁。去redis占坑
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "111");
if (lock){
//加锁成功。。。执行业务
//2、设置过期时间
redisTemplate.expire("lock",30,TimeUnit.SECONDS);
Map> dataFromDB = getDataFromDB();
redisTemplate.delete("lock");//删除锁
return dataFromDB ;
}else {
//加锁失败。。。重试。 synchronized()
//没获取到锁,等待100ms重试
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatelogJsonFromDBWithRedisLock();//自旋的方式
}
} 问题: 1、setnx设置好,正要去设置过期时间,宕机。又死锁了。 解决: 设置过期时间和占位必须是原子的。redis支持使用setnx ex命令
阶段三
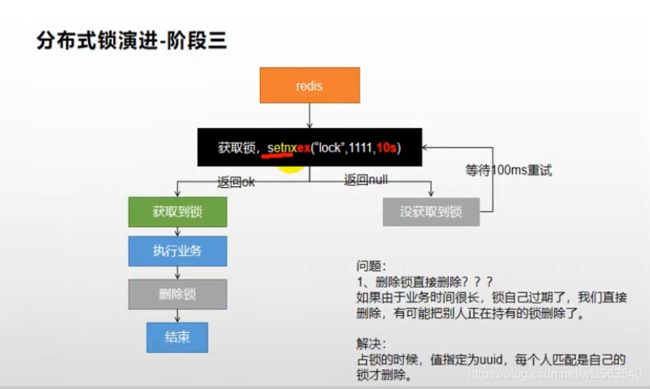
public Map> getCatelogJsonFromDBWithRedisLock() {
//1、占分布式锁。去redis占坑
String uuid = UUID.randomUUID().toString();
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid,300,TimeUnit.SECONDS);
if (lock){
//加锁成功。。。执行业务
//2、设置过期时间,必须和加锁是同步的,原子的
Map> dataFromDB = getDataFromDB();
redisTemplate.delete("lock");//删除锁
return dataFromDB;
}else {
//加锁失败。。。重试。 synchronized()
//没获取到锁,等待100ms重试
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatelogJsonFromDBWithRedisLock();//自旋的方式
}
} 问题: 1、删除锁直接删除??? 如果由于业务时间很长,锁自己过期了,我们直接删除,有可能把别人正在持有的锁删除了。 解决: 占锁的时候,值指定为uuid,每个人匹配是自己的锁才删除。
阶段四

public Map> getCatelogJsonFromDBWithRedisLock() {
//1、占分布式锁。去redis占坑
String uuid = UUID.randomUUID().toString();
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid,300,TimeUnit.SECONDS);
if (lock){
//加锁成功。。。执行业务
//2、设置过期时间,必须和加锁是同步的,原子的
Map> dataFromDB = getDataFromDB();
String lockValue = redisTemplate.opsForValue().get("lock");
if (uuid.equals(lockValue)) {
//删除我自己的锁
redisTemplate.delete("lock");//删除锁
}
return dataFromDB;
}else {
//加锁失败。。。重试。 synchronized()
//没获取到锁,等待100ms重试
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatelogJsonFromDBWithRedisLock();//自旋的方式
}
} 问题: 1、如果正好判断是当前值,正要删除锁的时候,锁已经过期,别人已经设置到了新的值。那么我们删除的是别人的锁 解决: 删除锁必须保证原子性。使用redis+Lua脚本完成
阶段五-最终形态

public Map> getCatelogJsonFromDBWithRedisLock() {
//1、占分布式锁。去redis占坑
String uuid = UUID.randomUUID().toString();
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid,300,TimeUnit.SECONDS);
if (lock){
//加锁成功。。。执行业务
//2、设置过期时间,必须和加锁是同步的,原子的
Map> dataFromDB = getDataFromDB();
//获取值对比+对比成功删除=原子操作 Lua脚本解锁
// String lockValue = redisTemplate.opsForValue().get("lock");
// if (uuid.equals(lockValue)) {
// //删除我自己的锁
// redisTemplate.delete("lock");//删除锁
// }
String script = "if redis.call(\"get\",KEYS[1]) == ARGV[1] then\n" +
" return redis.call(\"del\",KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
//删除锁
Integer lock1 = redisTemplate.execute(new DefaultRedisScript(script, Integer.class), Arrays.asList("lock"), uuid);
return dataFromDB;
}else {
//加锁失败。。。重试。 synchronized()
//没获取到锁,等待100ms重试
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatelogJsonFromDBWithRedisLock();//自旋的方式
}
} 保证加锁【占位+过期时间】和删除锁【判断+删除】的原子性。更难的事情,锁的自动续期

8、Redisson
Redison使用手册:https://github.com/redisson/redisson/wiki/%E7%9B%AE%E5%BD%95
导入依赖:以后使用Redisson作为分布式锁,分布式对象等功能框架
org.redisson
redisson
3.12.5
另外Redison也提供了一个集成到SpringBoot上的starter

由于我们使用的单节点,所以配置了单节点的Redisson,https://github.com/redisson/redisson/wiki/2.-%E9%85%8D%E7%BD%AE%E6%96%B9%E6%B3%95#261-%E5%8D%95%E8%8A%82%E7%82%B9%E8%AE%BE%E7%BD%AE
创建“MyRedisConfig ” 配置类:
@Configuration
public class MyRedisConfig {
@Bean(destroyMethod="shutdown")
public RedissonClient redisson() throws IOException {
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.137.14:6379");
RedissonClient redisson = Redisson.create(config);
return redisson;
}
}测试是否注入了RedissonClient,
@Autowired
RedissonClient redissonClient;
@Test
public void testRedison(){
System.out.println(redissonClient);
}
1)、Redisson-lock锁测试
Redison分布式锁:https://github.com/redisson/redisson/wiki/8.-%E5%88%86%E5%B8%83%E5%BC%8F%E9%94%81%E5%92%8C%E5%90%8C%E6%AD%A5%E5%99%A8
在Redison中分布式锁的使用,和java.util.concurrent包中的所提供的锁的使用方法基本相同。
测试Redisson的Lock锁的使用:
@GetMapping("/hello")
@ResponseBody
public String hello(){
//1.获取一把锁,只要名字一样,就是同一把锁
RLock lock = redisson.getLock("my-lock");
//2.加锁和解锁
try {
lock.lock();
System.out.println("加锁成功,执行业务方法..."+Thread.currentThread().getId());
Thread.sleep(30000);
} catch (Exception e){
}finally {
lock.unlock();
System.out.println("释放锁..."+Thread.currentThread().getId());
}
return "hello";
}
同时发送两个请求到:http://localhost:10000/hello

能够看到在加锁期间另外一个请求一直都是出于挂起状态,需要等待上一个请求处理完毕后,它才能接着执行。

查看Redis:

3)、Redisson-lock看门狗原理-redisson如何解决死锁
设想一种情况,一个请求线程在执行业务方法的时候,突然发生了中断,此时没有来得及执行释放锁操作,那么同时等待的另外一个线程是否会发生死锁。为了模拟这种情形,我们同时启动10000和10001,同时发送请求。
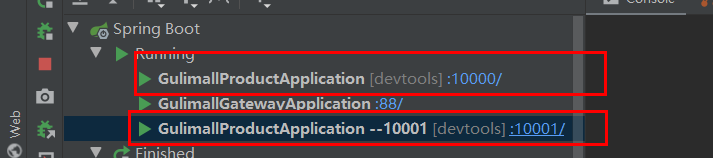
同时发送请求:
- http://localhost:10000/hello
- http://localhost:10001/hello
在10000端口上的服务在获取锁后,突然中断它的运行

观察Redis,能够看到这个锁仍然仍然存在:

此时在10001上运行的服务先是等待一会,然后成功获取到了锁:

观察Redis能够看大这个锁变为了针对于10001端口的了:

通过上面的实践能够看到,在加锁后,即便我们没有释放锁,也会自动的释放锁,这是因为在Redisson中会为每个锁加上“leaseTime”,默认是30秒
大家都知道,如果负责储存这个分布式锁的Redisson节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是30秒钟,也可以通过修改Config.lockWatchdogTimeout来另行指定。
https://github.com/redisson/redisson/wiki/8.-%E5%88%86%E5%B8%83%E5%BC%8F%E9%94%81%E5%92%8C%E5%90%8C%E6%AD%A5%E5%99%A8
在Redis中,我们能够看到这一点:

小结:redisson的lock具有如下特点
(1)阻塞式等待。默认的锁的时间是30s。
(2)锁定的制动续期,如果业务超长,运行期间会自动给锁续上新的30s,无需担心业务时间长,锁自动被删除的问题。
(3)加锁的业务只要能够运行完成,就不会给当前锁续期,即使不手动解锁,锁默认在30s以后自动删除。
lock方法还有一个重载的方法,lock(long leaseTime, TimeUnit unit) :
@Override
public void lock(long leaseTime, TimeUnit unit) {
try {
lock(leaseTime, unit, false);
} catch (InterruptedException e) {
throw new IllegalStateException();
}
}lock.lock(10,TimeUnit.SECOND);//设置10秒钟自动解锁,自动解锁时一定要大于业务执行时间
问题:lock(long leaseTime, TimeUnit unit),在锁到期后,是否会自动续期?
答:在指定了超时时间后,不会进行自动续期,此时如果有多个线程,即便业务仍然在执行,超时时间到了后,锁也会失效,其他线程就会争抢到锁。
(1)设置了超时时间后,就会发送给Redis的执行脚本,进行占锁,默认超时就是我们指定的时间。
(2)未指定超时时间,就使用30*1000【LockWatchdogTimeout看门狗的默认时间】的时间作为重新续期后的超时时间。
关于续期周期,只要锁占领成功,就会自动启动一个定时任务【重新给锁设置过期时间,新的过期时间就是看门狗的默认时间】,每隔10s都会自动再次续期,续成30s。这个10s中是根据( internalLockLeasTime)/3得到的。
尽管相对于lock(),lock(long leaseTime, TimeUnit unit)存在到期后自动删除的问题,但是我们对于它的使用还是比较多的,通常都会评估一下业务的最大执行用时,在这个时间内,如果仍然未能执行完成,则认为出现了问题,则释放锁执行其他逻辑。
4)、读写锁测试
保证一定能够读取到最新的数据,修改期间,写锁是一个排他锁(互斥锁),读锁是一个共享锁,写锁没释放读就必须等待。
(1)在Redis增加一个新的key“writeValue”,值为11111

(2)增加write和read的controller方法
@GetMapping("/write")
@ResponseBody
public String writeValue(){
RReadWriteLock writeLock=redisson.getReadWriteLock("rw-loc");
String uuid = null;
RLock lock = writeLock.writeLock();
lock.lock();
try {
uuid = UUID.randomUUID().toString();
redisTemplate.opsForValue().set("writeValue",uuid);
Thread.sleep(30-000);
} catch (Exception e) {
e.printStackTrace();
}finally {
lock.unlock();
}
return uuid;
}
@GetMapping("/read")
@ResponseBody
public String redValue(){
String uuid = null;
RReadWriteLock readLock=redisson.getReadWriteLock("rw-loc");
RLock lock = readLock.readLock();
lock.lock();
try {
uuid = redisTemplate.opsForValue().get("writeValue");
} catch (Exception e) {
e.printStackTrace();
}finally {
lock.unlock();
}
return uuid;
}
(3)启动gulimall-product
(4)分别访问“http://localhost:10000/read”和“http://localhost:10000/write”,观察现象。
- 执行写操作时,读操作必须要等待;
- 可以同时执行多个读操作,读操作之间互不影响;
- 在写操作时查看Redis中“rw-lock”的状态

读写锁补充
(1)修改“read”和“write”的controller方法
@GetMapping("/write")
@ResponseBody
public String writeValue(){
RReadWriteLock writeLock=redisson.getReadWriteLock("rw-loc");
String uuid = null;
RLock lock = writeLock.writeLock();
lock.lock();
try {
log.info("写锁加锁成功");
uuid = UUID.randomUUID().toString();
redisTemplate.opsForValue().set("writeValue",uuid);
Thread.sleep(30000);
} catch (Exception e) {
e.printStackTrace();
}finally {
lock.unlock();
log.info("写锁释放");
}
return uuid;
}
@GetMapping("/read")
@ResponseBody
public String redValue(){
String uuid = null;
RReadWriteLock readLock=redisson.getReadWriteLock("rw-loc");
RLock lock = readLock.readLock();
lock.lock();
try {
log.info("读锁加锁成功");
uuid = redisTemplate.opsForValue().get("writeValue");
Thread.sleep(30000);
} catch (Exception e) {
e.printStackTrace();
}finally {
lock.unlock();
log.info("读锁释放");
}
return uuid;
}
}
(2)先发送一个写请求,然后同时发送四个读请求
(3)观察现象
- 在写操作期间,四个读操作被阻塞,此时查看Redis中“rw-loc”状态,是写状态

- 写操作完毕后,查看Redis中的“rw-loc”状态,状态为读状态

同时会出现三个读锁的
- 查看控制台输出

能够看到三个读操作是同时获取到锁的。
另外在先执行读操作时,写操作被阻塞。
小结:
- 读+读:相当于无锁,并发读,只会在redis中记录,所有当前的读锁,都会同时加锁成功
- 写+读:等待写锁释放;
- 写+写:阻塞方式
- 读+写:写锁等待读锁释放,才能加锁
所以只要存在写操作,不论前面是或后面执行的是读或写操作,都会阻塞。
5)、闭锁测试

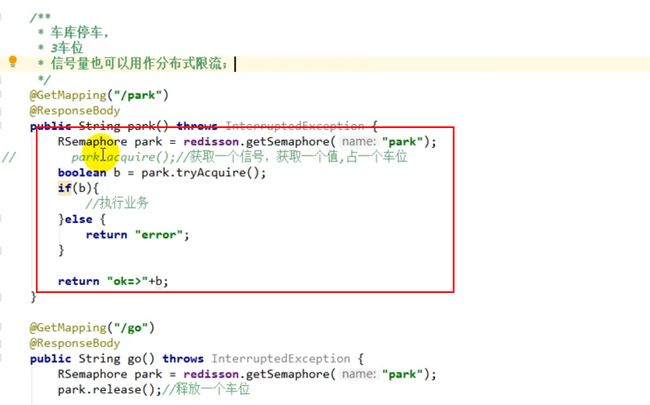
6)、信号量测试
先在redis中设置park的值为3


信号量作为分布式限流:
7)、缓存一致性解决
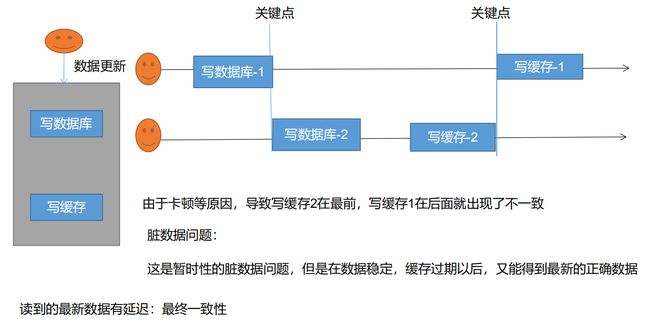
缓存一致性是为了解决数据库和缓存的数据不同步问题的。
1)缓存一致性——双写模式
2)缓存一致性——失效模式

3)缓存一致性——解决方案
- 无论是双写模式还是失效模式,都会导致缓存的不一致问题。即多个实例同时更新会出事。怎么办?
- 1、如果是用户纬度数据(订单数据、用户数据),这种并发几率非常小,不用考虑这个问题,缓存数据加上过期时间,每隔一段时间触发读的主动更新即可
- 2、如果是菜单,商品介绍等基础数据,也可以去使用canal订阅binlog的方式。
- 3、缓存数据+过期时间也足够解决大部分业务对于缓存的要求。
- 4、通过加锁保证并发读写,写写的时候按顺序排好队。读读无所谓。所以适合使用读写锁。(业务不关心脏数据,允许临时脏数据可忽略);
- 总结:
- 我们能放入缓存的数据本就不应该是实时性、一致性要求超高的。所以缓存数据的时候加上过期时间,保证每天拿到当前最新数据即可。
- 我们不应该过度设计,增加系统的复杂性
- 遇到实时性、一致性要求高的数据,就应该查数据库,即使慢点
4)缓存一致性——解决canal

使用Redisson的锁机制优化三级分类数据的查询。
/**
* 使用Redisson分布式锁来实现多个服务共享同一缓存中的数据
* @return
*/
public Map> getCatelogJsonFromDbWithRedissonLock() {
RLock lock = redissonClient.getLock("CatelogJson-lock");
//该方法会阻塞其他线程向下执行,只有释放锁之后才会接着向下执行
lock.lock();
Map> catelogJsonFromDb;
try {
//从数据库中查询分类数据
catelogJsonFromDb = getCatelogJsonFromDb();
} finally {
lock.unlock();
}
return catelogJsonFromDb;
}
我们系统的一致性解决方案:
1、缓存的所有数据都有过期时间,数据过期下一次查询触发主动更新
2、读写数据的时候,加上分布式的读写锁。
在更新分类数据的时候,删除缓存中的旧数据。
9、SpringCache-简介
1)、简洁

SpringCache的文档:https://docs.spring.io/spring/docs/5.3.0-SNAPSHOT/spring-framework-reference/integration.html#cache
2)、基础概念

3)、SpringCache-整合&体验@Cacheable
整合SpringCache,简化缓存的开发
1)引入依赖
org.springframework.boot
spring-boot-starter-cache
引入spring-boot-starter-data-redis
org.springframework.boot
spring-boot-starter-data-redis
io.lettuce
lettuce-core
2)编写配置
(1)缓存的自动配置了哪些?
- CacheAutoConfiguration,会导入RedisCacheConfiguration
- 自动配置了缓存管理器RedisCacheManager
(2)配置使用Redis作为缓存
修改“application.properties”文件,指定使用redis作为缓存,spring.cache.type=redis
(3)和缓存有关的注解
- @Cacheable: Triggers cache population. 触发将数据保存到缓存的操作
- @CacheEvict: Triggers cache eviction. 触发将数据从缓存中删除的操作
- @CachePut: Updates the cache without interfering with the method execution. 在不影响方法执行的情况下更新缓存。
- @Caching: Regroups multiple cache operations to be applied on a method. 组合以上多个操作
- @CacheConfig: Shares some common cache-related settings at class-level.在类级别上共享一些公共的与缓存相关的设置。
(4)测试使用缓存
(1)开启缓存功能,在主启动类上,标注@EnableCaching
(2)只需要使用注解,就可以完成缓存操作
(3)在业务方法的头部标上@Cacheable,加上该注解后,表示当前方法需要将进行缓存,如果缓存中有,方法无效调用,如果缓存中没有,则会调用方法,最后将方法的结果放入到缓存中。
(4)指定缓存分区。每一个需要缓存的数据,我们都需要来指定要放到哪个名字的缓存中。通常按照业务类型进行划分。
如:我们将一级分类数据放入到缓存中,指定缓存名字为“category”
@Cacheable({"category"})
@Override
public List getLevel1Categories() {
//找出一级分类
List categoryEntities = this.baseMapper.selectList(new QueryWrapper().eq("cat_level", 1));
return categoryEntities;
} (5)访问:http://localhost:10000/
(6)查看Redis

能够看到一级分类信息,已经被放入到缓存中了,而且再次访问的时候,没有查询数据库,而是直接从缓存中获取。
4)、@Cacheable细节设置
上面我们将一级分类数据的信息缓存到Redis中了,缓存到Redis中数据具有如下的特点:
- 如果缓存中有,方法不会被调用;
- key默认自动生成;形式为"缓存的名字::SimpleKey [](自动生成的key值)";
- 缓存的value值,默认使用jdk序列化机制,将序列化后的数据缓存到redis;
- 默认ttl时间为-1,表示永不
然而这些并不能够满足我们的需要,我们希望:
- 能够指定生成缓存所使用的key;
- 指定缓存的数据的存活时间;
- 将缓存的数据保存为json形式;
针对于第一点,我们使用@Cacheable注解的时候,设置key属性,接受一个SpEL
@Cacheable(value = {"category"},key = "'level1Categorys'")针对于第二点,在配置文件中指定ttl:
spring.cache.redis.time-to-live=3600000 #这里指定存活时间为1小时清空redis,再次进行访问:http://localhost:10000/
查看Redis
更多关于key的设置,在文档中给予了详细的说明:https://docs.spring.io/spring/docs/5.3.0-SNAPSHOT/spring-framework-reference/integration.html#cache-annotations-cacheable

5)、自定义缓存配置
上面我们解决了第一个命名问题和第二个设置存活时间问题,但是如何将数据以JSON的形式缓存到Redis呢?
这涉及到修改缓存管理器的设置,CacheAutoConfiguration导入了RedisCacheConfiguration,而RedisCacheConfiguration中自动配置了缓存管理器RedisCacheManager,而RedisCacheManager要初始化所有的缓存,每个缓存决定使用什么样的配置,如果RedisCacheConfiguration有,就用已有的,没有就用默认配置。
想要修改缓存的配置,只需要给容器中放一个“redisCacheConfiguration”即可,这样就会应用到当前RedisCacheManager管理的所有缓存分区中。
private org.springframework.data.redis.cache.RedisCacheConfiguration createConfiguration(
CacheProperties cacheProperties, ClassLoader classLoader) {
Redis redisProperties = cacheProperties.getRedis();
org.springframework.data.redis.cache.RedisCacheConfiguration config = org.springframework.data.redis.cache.RedisCacheConfiguration
.defaultCacheConfig();
config = config.serializeValuesWith(
SerializationPair.fromSerializer(new JdkSerializationRedisSerializer(classLoader)));
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixKeysWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}
Redis中的序列化器:org.springframework.data.redis.serializer.RedisSerializer
在Redis中放入自动配置类,设置JSON序列化机制
package com.atguigu.gulimall.product.config;
import org.springframework.boot.autoconfigure.cache.CacheProperties;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.StringRedisSerializer;
/**
* @Description: MyCacheConfig
* @Author: WangTianShun
* @Date: 2020/11/11 12:57
* @Version 1.0
*/
@EnableConfigurationProperties(CacheProperties.class)
@Configuration
@EnableCaching
public class MyCacheConfig {
/**
* 配置文件中的东西没有用到
*
* 1、原来和配置文件绑定的配置类是这样的
* @ConfigurationProperties(prefix="spring.cache")
* public class CacheProperties
* 2、让他生效
* @EnableConfigurationProperties(CacheProperties.class)
* @return
*/
@Bean
RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties){
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));
config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
//将配置文件中的所有配置都生效
CacheProperties.Redis redisProperties = cacheProperties.getRedis();
//设置配置文件中的各项配置,如过期时间
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixKeysWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}
}
查看Redis能够看到以JSON的形式,将数据缓存下来了:

在配置文件中,还可以指定一些缓存的自定义配置
spring.cache.type=redis
#设置超时时间,默认是毫秒
spring.cache.redis.time-to-live=3600000
#设置Key的前缀,如果指定了前缀,则使用我们定义的前缀,否则使用缓存的名字作为前缀
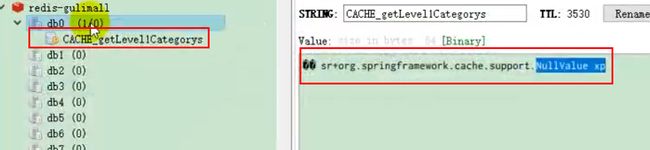
spring.cache.redis.key-prefix=CACHE_
spring.cache.redis.use-key-prefix=true
#是否缓存空值,防止缓存穿透
spring.cache.redis.cache-null-values=true基于这个配置,在如果出现了null值,也会被保存到redis中:
如果配置“spring.cache.redis.use-key-prefix=false”,则生成的key没有前缀:

6)、@CacheEvict
在上面实例中,在读模式中,我们将一级分类信息缓存到redis中,当请求再次获取数据时,直接从缓存中进行获取,但是如果执行的是写模式呢?
在写模式下,有两种方式来解决缓存一致性问题,双写模式和失效模式,在SpringCache中可以通过@CachePut来实现双写模式,使用@CacheEvict来实现失效模式。
实例:使用缓存失效机制实现更新数据库中值的是,使得缓存中的数据失效
(1)修改updateCascade方法,添加@CacheEvict注解,指明要删除哪个分类下的数据,并且确定key:
@Cacheable(value = {"category"}, key = "#root.methodName") //代表当前方法的结果需要缓存,如果缓存中有,方法不用调用。如果缓存中没有,最后将方法放入缓存。
@Override
public List getLevel1Category() {
List categoryEntities = baseMapper.selectList(new QueryWrapper().eq("parent_cid", 0));
return categoryEntities;
}
(2)启动gulimall-product,启动renren-fast,启动gulimall-gateway,启动项目的前端页面
(3)检查redis中是否有“category”命名空间下的数据,没有则访问http://localhost:10000/,生成数据
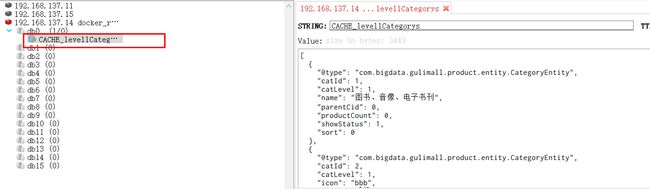
(4)修改数据:

(5)检查Redis中对应数据是否还存在

检查后发现数据没了,说明缓存失效策略是有效的。
另外在修改了一级缓存时,对应的二级缓存也需要更新,需要修改原来二级分类的执行逻辑。
将“getCatelogJson”恢复成为原来的逻辑,但是设置@Cacheable,非侵入的方式将查询结果缓存到redis中:
@Cacheable(value = {"category"},key = "#root.methodName")
@Override
public Map> getCatelogJson() {
log.info("查询数据库");
//一次性查询出所有的分类数据,减少对于数据库的访问次数,后面的数据操作并不是到数据库中查询,而是直接从这个集合中获取,
// 由于分类信息的数据量并不大,所以这种方式是可行的
List categoryEntities = this.baseMapper.selectList(null);
//1.查出所有一级分类
List level1Categories = getParentCid(categoryEntities,0L);
Map> parent_cid = level1Categories.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), level1 -> {
//2. 根据一级分类的id查找到对应的二级分类
List level2Categories = getParentCid(categoryEntities,level1.getCatId());
//3. 根据二级分类,查找到对应的三级分类
List catelog2Vos =null;
if(null != level2Categories || level2Categories.size() > 0){
catelog2Vos = level2Categories.stream().map(level2 -> {
//得到对应的三级分类
List level3Categories = getParentCid(categoryEntities,level2.getCatId());
//封装到Catalog3List
List catalog3Lists = null;
if (null != level3Categories) {
catalog3Lists = level3Categories.stream().map(level3 -> {
Catalog3List catalog3List = new Catalog3List(level2.getCatId().toString(), level3.getCatId().toString(), level3.getName());
return catalog3List;
}).collect(Collectors.toList());
}
return new Catelog2Vo(level1.getCatId().toString(), catalog3Lists, level2.getCatId().toString(), level2.getName());
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
} 访问:http://gulimall.com/
再次访问,发现控制台数据未更新,还是第一次访问时的输出:

查看Redis中缓存的数据:

上面我们将一级和三级分类信息都缓存到了redis中,现在我们想要实现一种场景是,更新分类数据的时候,将缓存到redis中的一级和三级分类数据都清空。
借助于“@Caching”来完成
@Caching(evict={
@CacheEvict(value = {"category"},key = "'level1Categorys'"),
@CacheEvict(value = {"category"},key = "'getCatelogJson'")
})
@Override
@Transactional
public void updateCascade(CategoryEntity category) {
this.updateById(category);
relationService.updateCategory(category.getCatId(),category.getName());
}查询redis,一级和三级分类数据已经被删除。
除了可以使用@Cache外,还可以使用@CacheEvict来完成:
@CacheEvict(value = {"category"},allEntries = true)它表示要删除“category”分区下的所有数据。
可以看到存储同一类型的数据,都可以指定未同一个分区,可以批量删除这个分区下的数据。以后建议不使用分区前缀,而是使用默认的分区前缀。
7)、SpringCache-原理与不足
Spring-Cache的不足:
1)读模式
- 缓存穿透:查询一个null值。解决,缓存空数据;cache-null-value=true;
- 缓存击穿:大量并发进来同时查询一个正好过期的数据。解决方法,是进行加锁,默认是没有加锁的,查询时设置Cacheable的sync=true即可解决缓存击穿。
- 缓存雪崩:大量的key同时过期。解决方法:加上随机时间;加上过期时间。“spring.cache.redis.time-to-live=3600000”
2)写模式(缓存与数据一致)
- 读写加锁;
- 引入canal,感知到mysql的更新去更新数据库;
- 读多写少,直接去数据库查询就行;
总结:
- 常规数据(读多写少,即时性,一致性要求不高的数据):完全可以使用spring-cache;写模式,只要缓存的数据有过期时间就足够了;
- 特殊数据:特殊设计;
四、检索
pom添加thymeleaf
org.springframework.boot
spring-boot-starter-thymeleaf
在虚拟机mydata/nginx/html/路径下创建search文件夹然后把搜索页的静态资源上传到该文件里

host添加
172.20.10.3 search.gulimall.com
配置nginx


重启nginx

修改网关断言配置
- id: gulimall_host_route
uri: lb://gulimall-product
predicates:
- Host=gulimall.com
- id: gulimall_search_route
uri: lb://gulimall-search
predicates:
- Host=search.gulimall.com

pom添加devtools
org.springframework.boot
spring-boot-devtools
true
关闭thymeleaf缓存
spring.thymeleaf.cache=false1. 检索条件分析
-
全文检索:skuTitle-》keyword
-
排序:saleCount(销量)、hotScore(热度分)、skuPrice(价格)
-
过滤:hasStock、skuPrice区间、brandId、catalog3Id、attrs
-
聚合:attrs
完整查询参数 keyword=小米&sort=saleCount_desc/asc&hasStock=0/1&skuPrice=400_1900&brandId=1&catalog3Id=1&at trs=1_3G:4G:5G&attrs=2_骁龙845&attrs=4_高清屏
2. DSL分析
GET gulimall_product/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"skuTitle": "华为"
}
}
],
"filter": [
{
"term": {
"catalogId": "225"
}
},
{
"terms": {
"brandId": [
"2"
]
}
},
{
"term": {
"hasStock": "false"
}
},
{
"range": {
"skuPrice": {
"gte": 1000,
"lte": 7000
}
}
},
{
"nested": {
"path": "attrs",
"query": {
"bool": {
"must": [
{
"term": {
"attrs.attrId": {
"value": "6"
}
}
}
]
}
}
}
}
]
}
},
"sort": [
{
"skuPrice": {
"order": "desc"
}
}
],
"from": 0,
"size": 5,
"highlight": {
"fields": {"skuTitle": {}},
"pre_tags": "",
"post_tags": ""
},
"aggs": {
"brandAgg": {
"terms": {
"field": "brandId",
"size": 10
},
"aggs": {
"brandNameAgg": {
"terms": {
"field": "brandName",
"size": 10
}
},
"brandImgAgg": {
"terms": {
"field": "brandImg",
"size": 10
}
}
}
},
"catalogAgg":{
"terms": {
"field": "catalogId",
"size": 10
},
"aggs": {
"catalogNameAgg": {
"terms": {
"field": "catalogName",
"size": 10
}
}
}
},
"attrs":{
"nested": {
"path": "attrs"
},
"aggs": {
"attrIdAgg": {
"terms": {
"field": "attrs.attrId",
"size": 10
},
"aggs": {
"attrNameAgg": {
"terms": {
"field": "attrs.attrName",
"size": 10
}
}
}
}
}
}
}
}修改映射
PUT gulimall_product
{
"mappings": {
"properties": {
"attrs": {
"type": "nested",
"properties": {
"attrId": {
"type": "long"
},
"attrName": {
"type": "keyword"
},
"attrValue": {
"type": "keyword"
}
}
},
"autoGeneratedTimestamp": {
"type": "long"
},
"brandId": {
"type": "long"
},
"brandImg": {
"type": "keyword"
},
"brandName": {
"type": "keyword"
},
"catalogId": {
"type": "long"
},
"catalogName": {
"type": "keyword"
},
"description": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"hasStock": {
"type": "boolean"
},
"hotScore": {
"type": "long"
},
"parentTask": {
"properties": {
"id": {
"type": "long"
},
"nodeId": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"set": {
"type": "boolean"
}
}
},
"refreshPolicy": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"retry": {
"type": "boolean"
},
"saleCount": {
"type": "long"
},
"shouldStoreResult": {
"type": "boolean"
},
"skuId": {
"type": "long"
},
"skuImg": {
"type": "keyword"
},
"skuPrice": {
"type": "keyword"
},
"skuTitle": {
"type": "text",
"analyzer": "ik_smart"
},
"spuId": {
"type": "keyword"
}
}
}
}

迁移数据
POST _reindex
{
"source": {
"index": "product"
},
"dest": {
"index": "gulimall_product"
}
}

修改gulimall-search的常量
修改com.atguigu.gulimall.search.constant.EsConstant类,代码如下
public class EsConstant {
public static final String PRODUCT_INDEX = "gulimall_product"; //sku数据在es中的索引
}3. 检索代码编写
1) 请求参数和返回结果
请求参数的封装
package com.atguigu.gulimall.search.vo;
import lombok.Data;
import java.util.List;
/**
* @Description: SearchParam
* @Author: WangTianShun
* @Date: 2020/11/12 16:21
* @Version 1.0
*
* 封装页面所有可能传递过来的查询条件
* catalog3Id=225&keyword=小米&sort=saleCount_asc
*/
@Data
public class SearchParam {
private String keyword;//页面传递过来的全文匹配关键字
private Long catalog3Id;//三级分类id
/**
* sort=saleCount_asc/desc
* sort=skuPrice_asc/desc
* sort=hotScore_asc/desc
*/
private String sort;//排序条件
/**
* 好多的过滤条件
* hasStock(是否有货)、skuPrice区间、brandId、catalog3Id、attrs
* hasStock=0/1
* skuPrice=1_500
*/
private Integer hasStock;//是否只显示有货
private String skuPrice;//价格区间查询
private List brandId;//按照品牌进行查询,可以多选
private List attrs;//按照属性进行筛选
private Integer pageNum = 1;//页码
}
返回结果
package com.atguigu.gulimall.search.vo;
import com.atguigu.common.to.es.SkuEsModel;
import lombok.Data;
import java.util.List;
/**
* @Description: SearchResponse
* @Author: WangTianShun
* @Date: 2020/11/12 16:49
* @Version 1.0
*/
@Data
public class SearchResult {
/**
* 查询到的商品信息
*/
private List products;
private Integer pageNum;//当前页码
private Long total;//总记录数
private Integer totalPages;//总页码
private List brands;//当前查询到的结果,所有涉及到的品牌
private List catalogs;//当前查询到的结果,所有涉及到的分类
private List attrs;//当前查询到的结果,所有涉及到的属性
//=====================以上是返给页面的信息==========================
@Data
public static class BrandVo{
private Long brandId;
private String brandName;
private String brandImg;
}
@Data
public static class CatalogVo{
private Long catalogId;
private String catalogName;
private String brandImg;
}
@Data
public static class AttrVo{
private Long attrId;
private String attrName;
private List attrValue;
}
}
2) 主体逻辑
修改“com.atguigu.gulimall.search.controller.SearchController”类,代码如下:
/**
* 自动将页面提交过来的所有请求查询参数封装成指定的对象
* @param param
* @return
*/
@GetMapping("/list.html")
public String listPage(SearchParam searchParam, Model model) {
SearchResult result = mallSearchService.search(searchParam);
System.out.println("===================="+result);
model.addAttribute("result", result);
return "list";
}修改“com.atguigu.gulimall.search.service.MallSearchService”类,代码如下:
/**
*
* @param param 检索的所有参数
* @return 返回检索的结果,里面包含页面需要的所有信息
*/
SearchResult search(SearchParam param);主要逻辑在service层进行,service层将封装好的SearchParam组建查询条件,再将返回后的结果封装成SearchResult
package com.atguigu.gulimall.search.service.impl;
import com.alibaba.fastjson.JSON;
import com.atguigu.common.to.es.SkuEsModel;
import com.atguigu.gulimall.search.config.GulimallElasticSearchConfig;
import com.atguigu.gulimall.search.constant.EsConstant;
import com.atguigu.gulimall.search.service.MallSearchService;
import com.atguigu.gulimall.search.vo.SearchParam;
import com.atguigu.gulimall.search.vo.SearchResult;
import org.apache.commons.lang.StringUtils;
import org.apache.lucene.search.join.ScoreMode;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.*;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.bucket.nested.NestedAggregationBuilder;
import org.elasticsearch.search.aggregations.bucket.nested.ParsedNested;
import org.elasticsearch.search.aggregations.bucket.terms.ParsedLongTerms;
import org.elasticsearch.search.aggregations.bucket.terms.ParsedStringTerms;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
/**
* @Description: MallSearchServiceImpl
* @Author: WangTianShun
* @Date: 2020/11/12 16:24
* @Version 1.0
*/
@Service
public class MallSearchServiceImpl implements MallSearchService {
@Autowired
RestHighLevelClient restHighLevelClient;
//去es进行检索
@Override
public SearchResult search(SearchParam param) {
//动态构建出查询需要的DSL语句
SearchResult result = null;
//1、准备检索请求
SearchRequest searchRequest = buildSearchRequest(param);
try {
//2、执行检索请求
SearchResponse response = restHighLevelClient.search(searchRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
//分析响应数据封装我们需要的格式
result = buildSearchResult(response,param);
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
/**
* 准备检索请求
* 模糊匹配、过滤(按照属性、分类、品牌、价格区间、库存),排序,分页,高亮,聚合分析
* @return
*/
private SearchRequest buildSearchRequest(SearchParam param) {
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//构建DSL语句的
/**
* 过滤(按照属性、分类、品牌、价格区间、库存)
*/
//1、构建bool-query
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
sourceBuilder.query(boolQuery);
//1.1 must-模糊匹配、
if (!StringUtils.isEmpty(param.getKeyword())){
boolQuery.must(QueryBuilders.matchQuery("skuTitle",param.getKeyword()));
}
//1.2.1 filter-按照三级分类id查询
if (null != param.getCatalog3Id()){
boolQuery.filter(QueryBuilders.termQuery("catalogId",param.getCatalog3Id()));
}
//1.2.2 filter-按照品牌id查询
if (null != param.getBrandId() && param.getBrandId().size()>0) {
boolQuery.filter(QueryBuilders.termsQuery("brandId",param.getBrandId()));
}
//1.2.3 filter-按照是否有库存进行查询
if (null != param.getHasStock() ) {
boolQuery.filter(QueryBuilders.termQuery("hasStock", param.getHasStock() == 1));
}
//1.2.4 filter-按照区间进行查询 1_500/_500/500_
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("skuPrice");
if (!StringUtils.isEmpty(param.getSkuPrice())) {
String[] prices = param.getSkuPrice().split("_");
if (prices.length == 1) {
if (param.getSkuPrice().startsWith("_")) {
rangeQueryBuilder.lte(Integer.parseInt(prices[0]));
}else {
rangeQueryBuilder.gte(Integer.parseInt(prices[0]));
}
} else if (prices.length == 2) {
//_6000会截取成["","6000"]
if (!prices[0].isEmpty()) {
rangeQueryBuilder.gte(Integer.parseInt(prices[0]));
}
rangeQueryBuilder.lte(Integer.parseInt(prices[1]));
}
boolQuery.filter(rangeQueryBuilder);
}
//1.2.5 filter-按照属性进行查询
List attrs = param.getAttrs();
if (null != attrs && attrs.size() > 0) {
//attrs=1_5寸:8寸&2_16G:8G
attrs.forEach(attr->{
BoolQueryBuilder queryBuilder = new BoolQueryBuilder();
String[] attrSplit = attr.split("_");
queryBuilder.must(QueryBuilders.termQuery("attrs.attrId", attrSplit[0]));//检索的属性的id
String[] attrValues = attrSplit[1].split(":");
queryBuilder.must(QueryBuilders.termsQuery("attrs.attrValue", attrValues));//检索的属性的值
//每一个必须都得生成一个nested查询
NestedQueryBuilder nestedQueryBuilder = QueryBuilders.nestedQuery("attrs", queryBuilder, ScoreMode.None);
boolQuery.filter(nestedQueryBuilder);
});
}
//把以前所有的条件都拿来进行封装
sourceBuilder.query(boolQuery);
/**
* 排序,分页,高亮,
*/
//2.1 排序 eg:sort=saleCount_desc/asc
if (!StringUtils.isEmpty(param.getSort())) {
String[] sortSplit = param.getSort().split("_");
sourceBuilder.sort(sortSplit[0], sortSplit[1].equalsIgnoreCase("asc") ? SortOrder.ASC : SortOrder.DESC);
}
//2.2、分页
sourceBuilder.from((param.getPageNum() - 1) * EsConstant.PRODUCT_PAGESIZE);
sourceBuilder.size(EsConstant.PRODUCT_PAGESIZE);
//2.3 高亮highlight
if (!StringUtils.isEmpty(param.getKeyword())) {
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("skuTitle");
highlightBuilder.preTags("");
highlightBuilder.postTags("");
sourceBuilder.highlighter(highlightBuilder);
}
/**
* 聚合分析
*/
//5. 聚合
//5.1 按照品牌聚合
TermsAggregationBuilder brand_agg = AggregationBuilders.terms("brand_agg").field("brandId").size(50);
//品牌聚合的子聚合
TermsAggregationBuilder brand_name_agg = AggregationBuilders.terms("brand_name_agg").field("brandName").size(1);
TermsAggregationBuilder brand_img_agg = AggregationBuilders.terms("brand_img_agg").field("brandImg");
brand_agg.subAggregation(brand_name_agg);
brand_agg.subAggregation(brand_img_agg);
sourceBuilder.aggregation(brand_agg);
//5.2 按照catalog聚合
TermsAggregationBuilder catalog_agg = AggregationBuilders.terms("catalog_agg").field("catalogId").size(20);
TermsAggregationBuilder catalog_name_agg = AggregationBuilders.terms("catalog_name_agg").field("catalogName").size(1);
catalog_agg.subAggregation(catalog_name_agg);
sourceBuilder.aggregation(catalog_agg);
//5.3 按照attrs聚合
NestedAggregationBuilder nestedAggregationBuilder = new NestedAggregationBuilder("attr_agg", "attrs");
//按照attrId聚合
TermsAggregationBuilder attr_id_agg = AggregationBuilders.terms("attr_id_agg").field("attrs.attrId");
//按照attrId聚合之后再按照attrName和attrValue聚合
TermsAggregationBuilder attr_name_agg = AggregationBuilders.terms("attr_name_agg").field("attrs.attrName").size(1);
TermsAggregationBuilder attr_value_agg = AggregationBuilders.terms("attr_value_agg").field("attrs.attrValue").size(50);
attr_id_agg.subAggregation(attr_name_agg);
attr_id_agg.subAggregation(attr_value_agg);
nestedAggregationBuilder.subAggregation(attr_id_agg);
sourceBuilder.aggregation(nestedAggregationBuilder);
String s = sourceBuilder.toString();
System.out.println("构建的DSL"+s);
SearchRequest request = new SearchRequest(new String[]{EsConstant.PRODUCT_INDEX}, sourceBuilder);
return request;
}
/**
* 构建结果数据
* @param response
* @return
*/
private SearchResult buildSearchResult(SearchResponse response,SearchParam param) {
SearchResult result = new SearchResult();
//1、返回的所有查询到的商品
SearchHits hits = response.getHits();
List esModels = new ArrayList<>();
if (null != hits.getHits() && hits.getHits().length>0){
for (SearchHit hit : hits.getHits()) {
String sourceAsString = hit.getSourceAsString();
SkuEsModel esModel = JSON.parseObject(sourceAsString, SkuEsModel.class);
if (!StringUtils.isEmpty(param.getKeyword())) {
HighlightField skuTitle = hit.getHighlightFields().get("skuTitle");
esModel.setSkuTitle(skuTitle.fragments()[0].string());
}
esModels.add(esModel);
}
}
result.setProducts(esModels);
//2、当前所有商品涉及到的所有属性
List attrVos = new ArrayList<>();
ParsedNested attr_agg = response.getAggregations().get("attr_agg");
ParsedLongTerms attr_id_agg = attr_agg.getAggregations().get("attr_id_agg");
for (Terms.Bucket bucket : attr_id_agg.getBuckets()) {
SearchResult.AttrVo attrVo = new SearchResult.AttrVo();
//1、得到属性的id;
long attrId = bucket.getKeyAsNumber().longValue();
//2、得到属性的名字
String attrName = ((ParsedStringTerms) bucket.getAggregations().get("attr_name_agg")).getBuckets().get(0).getKeyAsString();
//3、得到属性的所有值
List attrValues = ((ParsedStringTerms) bucket.getAggregations().get("attr_value_agg")).getBuckets().stream().map(item -> {
String keyAsString = item.getKeyAsString();
return keyAsString;
}).collect(Collectors.toList());
attrVo.setAttrId(attrId);
attrVo.setAttrName(attrName);
attrVo.setAttrValue(attrValues);
attrVos.add(attrVo);
}
result.setAttrs(attrVos);
//3、当前所有品牌涉及到的所有属性
List brandVos = new ArrayList<>();
ParsedLongTerms brand_agg = response.getAggregations().get("brand_agg");
for (Terms.Bucket bucket : brand_agg.getBuckets()) {
SearchResult.BrandVo brandVo = new SearchResult.BrandVo();
//1、得到品牌的id
long brandId = bucket.getKeyAsNumber().longValue();
//2、得到品牌的名
String brandName = ((ParsedStringTerms) bucket.getAggregations().get("brand_name_agg")).getBuckets().get(0).getKeyAsString();
//3、得到品牌的图片
String brandImg = ((ParsedStringTerms) bucket.getAggregations().get("brand_img_agg")).getBuckets().get(0).getKeyAsString();
brandVo.setBrandId(brandId);
brandVo.setBrandName(brandName);
brandVo.setBrandImg(brandImg);
brandVos.add(brandVo);
}
result.setBrands(brandVos);
//4、当前商品所涉及的分类信息
ParsedLongTerms catalog_agg = response.getAggregations().get("catalog_agg");
List catalogVos = new ArrayList<>();
List buckets = catalog_agg.getBuckets();
for (Terms.Bucket bucket : buckets) {
SearchResult.CatalogVo catalogVo = new SearchResult.CatalogVo();
//得到分类id
String keyAsString = bucket.getKeyAsString();
catalogVo.setCatalogId(Long.parseLong(keyAsString));
//得到分类名
ParsedStringTerms catalog_name_agg = bucket.getAggregations().get("catalog_name_agg");
String catalog_name = catalog_name_agg.getBuckets().get(0).getKeyAsString();
catalogVo.setCatalogName(catalog_name);
catalogVos.add(catalogVo);
}
result.setCatalogs(catalogVos);
//===========以上从聚合信息获取到=============
//5、分页信息-页码
result.setPageNum(param.getPageNum());
//6、分页信息-总记录数
long total = hits.getTotalHits().value;
result.setTotal(total);
//7、分页信息-总页码-计算
int totalPages = total%EsConstant.PRODUCT_PAGESIZE == 0 ?(int) total/EsConstant.PRODUCT_PAGESIZE:((int)total/EsConstant.PRODUCT_PAGESIZE+1);
result.setTotalPages(totalPages);
return result;
}
}
4. 页面效果
1) 基本数据渲染
将商品的基本属性渲染出来

2) 筛选条件渲染
将结果的品牌、分类、商品属性进行遍历显示,并且点击某个属性值时可以通过拼接url进行跳转
分类:
系统:

function searchProducts(name,value){
//原来的页面
var href = location.href + "";
if (href.indexOf("?") != -1){
location.href = location.href + "&" +name+ "=" + value;
}else {
location.href = location.href + "?" +name+ "=" + value;
}
}
/**
* @param url 目前的url
* @param paramName 需要替换的参数属性名
* @param replaceVal 需要替换的参数的新属性值
* @param forceAdd 该参数是否可以重复查询(attrs=1_3G:4G:5G&attrs=2_骁龙845&attrs=4_高清屏)
* @returns {string} 替换或添加后的url
*/
function replaceParamVal(url, paramName, replaceVal,forceAdd) {
var oUrl = url.toString();
var nUrl;
if (oUrl.indexOf(paramName) != -1) {
if( forceAdd && oUrl.indexOf(paramName+"="+replaceVal)==-1) {
if (oUrl.indexOf("?") != -1) {
nUrl = oUrl + "&" + paramName + "=" + replaceVal;
} else {
nUrl = oUrl + "?" + paramName + "=" + replaceVal;
}
} else {
var re = eval('/(' + paramName + '=)([^&]*)/gi');
nUrl = oUrl.replace(re, paramName + '=' + replaceVal);
}
} else {
if (oUrl.indexOf("?") != -1) {
nUrl = oUrl + "&" + paramName + "=" + replaceVal;
} else {
nUrl = oUrl + "?" + paramName + "=" + replaceVal;
}
}
return nUrl;
};3) 分页数据渲染
将页码绑定至属性pn,当点击某页码时,通过获取pn值进行url拼接跳转页面
$(".page_a").click(function () {
var pn=$(this).attr("pn");
location.href=replaceParamVal(location.href,"pageNum",pn,false);
console.log(replaceParamVal(location.href,"pageNum",pn,false))
})4) 页面排序和价格区间
页面排序功能需要保证,点击某个按钮时,样式会变红,并且其他的样式保持最初的样子;
点击某个排序时首先按升序显示,再次点击再变为降序,并且还会显示上升或下降箭头
页面排序跳转的思路是通过点击某个按钮时会向其class属性添加/去除desc,并根据属性值进行url拼接
综合排序[[${(!#strings.isEmpty(p) && #strings.startsWith(p,'hotScore') &&
#strings.endsWith(p,'desc')) ?'↓':'↑' }]]
销量[[${(!#strings.isEmpty(p) && #strings.startsWith(p,'saleCount') &&
#strings.endsWith(p,'desc'))?'↓':'↑' }]]
价格[[${(!#strings.isEmpty(p) && #strings.startsWith(p,'skuPrice') &&
#strings.endsWith(p,'desc'))?'↓':'↑' }]]
评论分
上架时间
-
$(".sort_a").click(function () {
//添加、剔除desc
$(this).toggleClass("desc");
//获取sort属性值并进行url跳转
let sort = $(this).attr("sort");
sort = $(this).hasClass("desc") ? sort + "_desc" : sort + "_asc";
location.href = replaceParamVal(location.href, "sort", sort,false);
return false;
});价格区间搜索函数
$("#skuPriceSearchBtn").click(function () {
var skuPriceFrom = $("#skuPriceFrom").val();
var skuPriceTo = $("#skuPriceTo").val();
location.href = replaceParamVal(location.href, "skuPrice", skuPriceFrom + "_" + skuPriceTo, false);
})5)是否有库存
仅显示有货
6)关键字搜索修改
function searchProducts(name, value) {
//原来的页面
// var href = location.href + "";
// if (href.indexOf("?") != -1) {
// location.href = location.href + "&" + name + "=" + value;
// } else {
// location.href = location.href + "?" + name + "=" + value;
// }
location.href = replaceParamVal(location.href,name,value,true);
} $("#skuPriceSearchBtn").click(function () {
//1、拼上价格区间的查询条件
var skuPriceFrom = $("#skuPriceFrom").val();
var skuPriceTo = $("#skuPriceTo").val();
location.href = replaceParamVal(location.href, "skuPrice", skuPriceFrom + "_" + skuPriceTo, false);
});
/*TODO 是否有库存路径有bug*/
$("#showHasStock").change(function(){
if ($(this).prop('checked')){
location.href = replaceParamVal(location.href, "hasStock", 1, false);
}else {
//没选中
var re = eval('/(hasStock=)([^&]*)/gi');
location.href = (location.href+"").replace(re,'');
}
return false;
})5) 面包屑导航
修改gulimall-search的pom
定义springcloud的版本
1.8
7.4.2
Hoxton.SR8
添加依赖管理
org.springframework.cloud
spring-cloud-dependencies
${spring-cloud.version}
pom
import
org.springframework.cloud
spring-cloud-starter-openfeign
主启动类添加 开启远程调用

修改com.atguigu.gulimall.search.feign.ProducteFeignService类,代码如下
package com.atguigu.gulimall.search.feign;
import com.atguigu.common.utils.R;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
/**
* @Description: ProducteFeignService
* @Author: WangTianShun
* @Date: 2020/11/15 21:27
* @Version 1.0
*/
@FeignClient("gulimall-product")
public interface ProducteFeignService {
@GetMapping("/product/attr/info/{attrId}")
public R attrInfo(@PathVariable("attrId") Long attrId);
}
修改com.atguigu.common.utils.R类,代码如下
//利用fastJson进行逆转
public T getData(String key,TypeReference typeReference) {
Object data = get(key);
String s = JSON.toJSONString(data);
T t = JSON.parseObject(s, typeReference);
return t;
} 修改“com.atguigu.gulimall.search.feign.ProducteFeignService” 类,代码如下:
package com.atguigu.gulimall.search.vo;
import lombok.Data;
/**
* @Description: AttrResponseVo
* @Author: WangTianShun
* @Date: 2020/11/15 21:36
* @Version 1.0
*/
@Data
public class AttrResponseVo {
/**
* 属性id
*/
private Long attrId;
/**
* 属性名
*/
private String attrName;
/**
* 是否需要检索[0-不需要,1-需要]
*/
private Integer searchType;
/**
* 属性图标
*/
private String icon;
/**
* 可选值列表[用逗号分隔]
*/
private String valueSelect;
/**
* 属性类型[0-销售属性,1-基本属性,2-既是销售属性又是基本属性]
*/
private Integer attrType;
/**
* 启用状态[0 - 禁用,1 - 启用]
*/
private Long enable;
/**
* 所属分类
*/
private Long catelogId;
/**
* 快速展示【是否展示在介绍上;0-否 1-是】,在sku中仍然可以调整
*/
private Integer showDesc;
private Long attrGroupId;
private String catelogName;
private String groupName;
private Long[] catelogPath;
}
修改“com.atguigu.gulimall.search.vo.SearchResult” 类,代码如下:
package com.atguigu.gulimall.search.vo;
import com.atguigu.common.to.es.SkuEsModel;
import lombok.Data;
import java.util.ArrayList;
import java.util.List;
/**
* @Description: SearchResponse
* @Author: WangTianShun
* @Date: 2020/11/12 16:49
* @Version 1.0
*/
@Data
public class SearchResult {
/**
* 查询到的商品信息
*/
private List products;
private Integer pageNum;//当前页码
private Long total;//总记录数
private Integer totalPages;//总页码
private List pageNavs;//导航页码
private List brands;//当前查询到的结果,所有涉及到的品牌
private List catalogs;//当前查询到的结果,所有涉及到的分类
private List attrs;//当前查询到的结果,所有涉及到的属性
//=====================以上是返给页面的信息==========================
//面包屑导航数据
private List navs = new ArrayList<>();
@Data
public static class NavVo{
private String navName;
private String navValue;
private String link;
}
@Data
public static class BrandVo{
private Long brandId;
private String brandName;
private String brandImg;
}
@Data
public static class CatalogVo{
private Long catalogId;
private String catalogName;
private String brandImg;
}
@Data
public static class AttrVo{
private Long attrId;
private String attrName;
private List attrValue;
}
}
修改“com.atguigu.gulimall.search.service.impl.MallSearchServiceImpl” 类,代码如下:
在封装结果时,将查询的属性值进行封装
//6、构建面包屑导航功能
List attrs = param.getAttrs();
if (attrs != null && attrs.size() > 0) {
List navVos = attrs.stream().map(attr -> {
String[] split = attr.split("_");
SearchResult.NavVo navVo = new SearchResult.NavVo();
//6.1 设置属性值
navVo.setNavValue(split[1]);
//6.2 查询并设置属性名
try {
R r = producteFeignService.attrInfo(Long.parseLong(split[0]));
if (r.getCode() == 0) {
AttrResponseVo attrResponseVo = JSON.parseObject(JSON.toJSONString(r.get("attr")), new TypeReference() {
});
navVo.setNavName(attrResponseVo.getAttrName());
}else {
navVo.setNavName(split[0]);
}
} catch (Exception e) {
}
//6.3 设置面包屑跳转链接(当点击该链接时剔除点击属性)
//取消了这个面包屑以后,我们就要跳转到那个地方,将请求地址的url里面的当前置空
//拿到所有的查询条件,去掉当前
String queryString = param.get_queryString();
String encode = null;
try {
encode = URLEncoder.encode(attr, "UTF-8");
encode = encode.replace("+","20%");//浏览器对空格编码和java不一样
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
String replace = queryString.replace("&attrs=" + encode, "");
navVo.setLink("http://search.gulimall.com/list.html" + (replace.isEmpty()?"":"?"+replace));
return navVo;
}).collect(Collectors.toList());
result.setNavs(navVos);
}
return result; 因为远程调用可以给他添加缓存

页面渲染
7) 条件筛选联动
就是将品牌和分类也封装进面包屑数据中,并且在页面进行th:if的判断,当url有该属性的查询条件时就不进行显示了
修改“com.atguigu.gulimall.search.service.impl.MallSearchServiceImpl”类,代码如下:
//6、构建面包屑导航功能
List attrs = param.getAttrs();
if (attrs != null && attrs.size() > 0) {
List navVos = attrs.stream().map(attr -> {
String[] split = attr.split("_");
SearchResult.NavVo navVo = new SearchResult.NavVo();
//6.1 设置属性值
navVo.setNavValue(split[1]);
//6.2 查询并设置属性名
try {
R r = producteFeignService.attrInfo(Long.parseLong(split[0]));
result.getAttrIds().add(Long.valueOf(split[0]));
if (r.getCode() == 0) {
AttrResponseVo attrResponseVo = JSON.parseObject(JSON.toJSONString(r.get("attr")), new TypeReference() {
});
navVo.setNavName(attrResponseVo.getAttrName());
}else {
navVo.setNavName(split[0]);
}
} catch (Exception e) {
}
//6.3 设置面包屑跳转链接(当点击该链接时剔除点击属性)
//取消了这个面包屑以后,我们就要跳转到那个地方,将请求地址的url里面的当前置空
//拿到所有的查询条件,去掉当前
String replace = replaceQueryString(param, attr,"attrs");
navVo.setLink("http://search.gulimall.com/list.html" + (replace.isEmpty()?"":"?"+replace));
return navVo;
}).collect(Collectors.toList());
result.setNavs(navVos);
}
//品牌、分类
if (null != param.getBrandId() && param.getBrandId().size() > 0){
List navs = result.getNavs();
SearchResult.NavVo navVo = new SearchResult.NavVo();
navVo.setNavName("品牌");
//TODO 远程查询所有品牌
R r = producteFeignService.brandInfo(param.getBrandId());
if (0 == r.getCode()){
List brands = r.getData("brands", new TypeReference>() {
});
StringBuffer buffer = new StringBuffer();
String replace = "";
for (BrandVo brand : brands) {
buffer.append(brand.getBrandName()+";");
replace = replaceQueryString(param, brand.getBrandId()+"","attrs");
}
navVo.setNavValue(buffer.toString());
navVo.setLink("http://search.gulimall.com/list.html" + (replace.isEmpty()?"":"?"+replace));
}
navs.add(navVo);
}
//TODO 分类,不需要导航取消
return result;
}
private String replaceQueryString(SearchParam param, String value,String key) {
String queryString = param.get_queryString();
String encode = null;
try {
encode = URLEncoder.encode(value, "UTF-8");
encode = encode.replace("+","20%");//浏览器对空格编码和java不一样
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return queryString.replace("&"+key+"=" + encode, "");
}
attrIds作为记录url已经有的属性id

远程调用获取品牌信息
修改“com.atguigu.gulimall.search.feign.ProducteFeignService”类,代码如下:
@RequestMapping("/product/brand/infos")
public R brandInfo(@RequestParam("brandIds") List brandIds); 修改“com.atguigu.gulimall.search.vo.BrandVo”类,代码如下:
package com.atguigu.gulimall.search.vo;
import lombok.Data;
/**
* @author WangTianShun
* @date 2020/10/15 10:00
*/
@Data
public class BrandVo {
private Long brandId;
private String brandName;
}
修改“com.atguigu.gulimall.product.app.BrandController”类,代码如下:
/**
* 信息
*/
@RequestMapping("/infos")
public R info(@RequestParam("brandIds") List brandIds){
List brands = brandService.getBrandsById(brandIds);
return R.ok().put("brands", brands);
} 修改“com.atguigu.gulimall.product.service.BrandService”类,代码如下:
List getBrandsById(List brandIds); 修改“com.atguigu.gulimall.product.service.impl.BrandServiceImpl”类,代码如下:
@Override
public List getBrandsById(List brandIds) {
List brandId = baseMapper.selectList(new QueryWrapper().in("brand_id", brandIds));
return brandId;
}
屏幕尺寸:
五、异步
1、继承Thread
2、实现Runnable3、实现Callable接口+FutureTask(可以拿到返回结果,可以处理异常)
4、线程池
package com.atguigu.gulimall.search.thread;
import java.util.concurrent.*;
/**
* @Description: ThreadTest
* @Author: WangTianShun
* @Date: 2020/11/16 8:50
* @Version 1.0
*/
public class ThreadTest {
public static ExecutorService service = Executors.newFixedThreadPool(10);
public static void main(String[] args) throws ExecutionException, InterruptedException {
System.out.println("main.............start.......");
/**
* 1、继承Thread
*
* 2、实现Runnable
*
* 3、实现Callable接口+FutureTask(可以拿到返回结果,可以处理异常)
*
* 4、线程池
* 给线程池直接提交任务
* service.execute(new Runnable01());
* 创建
* 1)、Executors
*
*总结:
* 我们以后再业务代码里面,以上三种启动线程的方式都不用。将所有的多线程异步任务都交给线程池执行
*
* 区别:
* 1、2不能得到返回值。3可以获取返回值
* 1、2、3都不能控制资源
* 4可以控制资源,性能稳定。
*/
//当前系统中池只有一两个,每个异步任务,提交给线程池让他自己去执行就行
// 1、继承Thread
// Thread01 thread01 = new Thread01();
// thread01.start();//启动线程
// 2、实现Runnable
// Runnable01 runnable01 = new Runnable01();
// new Thread(runnable01).start();
// 3、实现Callable接口+FutureTask
FutureTask futureTask = new FutureTask<>(new Callable01());
new Thread(futureTask).start();
//阻塞等待整个线程执行完成,获取返回结果
Integer integer = futureTask.get();
// 4、线程池
service.execute(new Runnable01());
System.out.println("main.............end......."+integer);
}
public static class Thread01 extends Thread{
@Override
public void run() {
System.out.println("当前线程:"+Thread.currentThread().getId());
int i = 10/2;
System.out.println("当前运行结果:" + i);
}
}
public static class Runnable01 implements Runnable{
@Override
public void run() {
System.out.println("当前线程:"+Thread.currentThread().getId());
int i = 10/2;
System.out.println("当前运行结果:" + i);
}
}
public static class Callable01 implements Callable{
@Override
public Integer call() throws Exception {
System.out.println("当前线程:"+Thread.currentThread().getId());
int i = 10/2;
System.out.println("当前运行结果:" + i);
return i;
}
}
}
1、线程池
1)、七大参数
(1)、corePoolSize[5],核心线程数[一直存在,除非(allowCoreThreadTimeOut)];线程池,创建好以后就准备就绪的线程数量,就等待接收异步任务去执行
5个 Thread thread = new Thread(); thread.start();
(2)、maximumPoolSize[200]:最大线程数量;控制资源
(3)、keepAliveTime:存活时间。如果当前正在运行的线程数量大于core数量
释放空闲的线程(maximumPoolSize-corePoolSize)。只要线程空闲大于指定的keepAliveTime;
(4)、unit:时间单位
(5)、BlockingQueue
workQueue:阻塞队列。如果任务有很多。就会将多的任务放在队列里面 只要有线程空闲,就会去队列里面取出新的任务继续执行
(6)、ThreadFactory:线程创建的工厂
(7)、RejectedExecutionHandler handler:如果队列满了,按照我们指定的拒绝策略,拒绝执行
2)、工作顺序
1)、线程池创建,准备好core数量的核心线程,准备接受任务
1.1、core满了,就将再进来的任务放入阻塞队列中。空闲的core就会自己去阻塞队列获取任务执行
1.2、阻塞队垒满了,就直接开新线程执行,最大只能开到max指定的数量
1.3、max满了就用RejectedExecutionHandler拒绝任务
1.4、max都执行完成,有很多空闲,在指定的时间keepAliveTime以后,释放空闲的线程(max-core)。
new LinkedBlockingQueue<>(),默认是Integer的最大值。内存不够
一个线程池 core 7, max 20, queue 50, 100并发进来怎么分配的
7个会立即执行。50个进入队列,在开13个进行执行。剩下30个就是用拒绝策略
如果不想抛弃还要执行,CallerRunsPolicy
ThreadPoolExecutor executor = new ThreadPoolExecutor(
5,
200,
10,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(100000),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());3)、常见的4种线程池
newCachedThreadPool
创建一个可缓存的线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程
newFixedThreadPool
创建一个定长线程池,可控制线程最大并发数,超出的线程会在对垒中等待。
newScheduledThreadPool
创建一个定长线程池。支持定势及周期性人去执行
newSingleThreadExecutor
创建一个单线程化的线程池,他只会用唯一的工作线程来执行任务,保证所有任务。
4)、使用线程池的好处

2、CompletableFuture组合式异步编程

1)、创建异步对象
(1) runAsync 和 supplyAsync方法
CompletableFuture 提供了四个静态方法来创建一个异步操作。
public static CompletableFuture runAsync(Runnable runnable)
public static CompletableFuture runAsync(Runnable runnable, Executor executor)
public static CompletableFuture supplyAsync(Supplier supplier)
public static CompletableFuture supplyAsync(Supplier supplier, Executor executor) 没有指定Executor的方法会使用ForkJoinPool.commonPool() 作为它的线程池执行异步代码。如果指定线程池,则使用指定的线程池运行。以下所有的方法都类同。
- runAsync方法不支持返回值。
- supplyAsync可以支持返回值。
public static void main(String[] args) throws ExecutionException, InterruptedException {
System.out.println("main.............start.......");
// CompletableFuture future = CompletableFuture.runAsync(() -> {
// System.out.println("当前线程:" + Thread.currentThread().getId());
// int i = 10 / 2;
// System.out.println("当前运行结果:" + i);
// }, executor);
CompletableFuture future = CompletableFuture.supplyAsync(() -> {
System.out.println("当前线程:" + Thread.currentThread().getId());
int i = 10 / 2;
System.out.println("当前运行结果:" + i);
return i;
}, executor);
Integer integer = future.get();
System.out.println("main.............end......."+integer);
}
2)、计算结果完成时的回调方法
当CompletableFuture的计算结果完成,或者抛出异常的时候,可以执行特定的Action。主要是下面的方法:
//可以处理异常,无返回值
public CompletableFuture whenComplete(BiConsumer action)
public CompletableFuture whenCompleteAsync(BiConsumer action)
public CompletableFuture whenCompleteAsync(BiConsumer action, Executor executor)
//可以处理异常,有返回值
public CompletableFuture exceptionally(Function fn) 可以看到Action的类型是BiConsumer它可以处理正常的计算结果,或者异常情况。
public class ThreadTest {
public static ExecutorService executor = Executors.newFixedThreadPool(10);
public static void main(String[] args) throws ExecutionException, InterruptedException {
System.out.println("main.............start.......");
// CompletableFuture future = CompletableFuture.runAsync(() -> {
// System.out.println("当前线程:" + Thread.currentThread().getId());
// int i = 10 / 2;
// System.out.println("当前运行结果:" + i);
// }, executor);
CompletableFuture future = CompletableFuture.supplyAsync(() -> {
System.out.println("当前线程:" + Thread.currentThread().getId());
int i = 10 / 0;
System.out.println("当前运行结果:" + i);
return i;
}, executor).whenComplete((result,exception)->{
//虽然能得到异常信息,但是没法修改返回数据
System.out.println("异步任务完成了...结果是"+result+";异常是"+exception);
//可以感知异常,同时返回默认值
}).exceptionally(throwable -> {
return 10;
});
Integer integer = future.get();
System.out.println("main.............end......."+integer);
}
3)、handle 方法
handle 是执行任务完成时对结果的处理。 handle 方法和 thenApply 方法处理方式基本一样。不同的是 handle 是在任务完成后再执行,还可以处理异常的任务。thenApply 只可以执行正常的任务,任务出现异常则不执行 thenApply 方法。
public CompletionStage handle(BiFunction fn);
public CompletionStage handleAsync(BiFunction fn);
public CompletionStage handleAsync(BiFunction fn,Execut /**
* 方法执行完成后的处理
*/
CompletableFuture future = CompletableFuture.supplyAsync(() -> {
System.out.println("当前线程:" + Thread.currentThread().getId());
int i = 10 / 5;
System.out.println("当前运行结果:" + i);
return i;
}, executor).handle((result,exception)->{
if (result != null){
return result*2;
}
if (exception != null){
return 0;
}
return 0;
});
Integer integer = future.get();
System.out.println("main.............end......."+integer);
} 
4)、线程串行化

- thenRun:不能获取上一步的执行结果
- thenAcceptAsync:能接受上一步结果,但是无返回值
- thenApplyAsync:能接受上一步结果,有返回值
/**
* 线程串行化
* 1)、thenRun 不能获取得到上一步的执行结果
*/
// CompletableFuture thenRunAsync = CompletableFuture.supplyAsync(() -> {
// System.out.println("当前线程:" + Thread.currentThread().getId());
// int i = 10 / 5;
// System.out.println("当前运行结果:" + i);
// return i;
// }, executor).thenRunAsync(() -> {
// System.out.println("任务2启动了。。。。");
// }, executor);
/**
* 线程串行化
* 1)、thenRun 不能获取得到上一步的执行结果,无返回值
* 2)、thenAcceptAsync能接收上一步返回结果,但无返回值
*/
// CompletableFuture thenRunAsync = CompletableFuture.supplyAsync(() -> {
// System.out.println("当前线程:" + Thread.currentThread().getId());
// int i = 10 / 5;
// System.out.println("当前运行结果:" + i);
// return i;
// }, executor).thenAcceptAsync(res -> {
// System.out.println("任务2启动了。。。。"+res);
// }, executor);
/**
* 线程串行化
* 1)、thenRun 不能获取得到上一步的执行结果,无返回值
* 2)、thenAcceptAsync能接收上一步返回结果,但无返回值
* 3)、thenApplyAsync能接收上一步的返回结果,也有返回值
*/
CompletableFuture thenApplyAsync = CompletableFuture.supplyAsync(() -> {
System.out.println("当前线程:" + Thread.currentThread().getId());
int i = 10 / 5;
System.out.println("当前运行结果:" + i);
return i;
}, executor).thenApplyAsync(res -> {
System.out.println("任务2启动了。。。。" + res);
return "hello" + res;
}, executor);
System.out.println("main.............end......."+ thenApplyAsync.get());
} 5)、两任务组合-都要完成
thenCombine 会把两个 CompletionStage 的任务都执行完成后,把两个任务的结果一块交给 thenCombine 来处理。
- runAfterBoth
两个CompletionStage,都完成了计算才会执行下一步的操作(Runnable)
public CompletionStage runAfterBoth(CompletionStage other,Runnable action);
public CompletionStage runAfterBothAsync(CompletionStage other,Runnable action);
public CompletionStage runAfterBothAsync(CompletionStage other,Runnable action,Executor - thenAcceptBoth
当两个CompletionStage都执行完成后,把结果一块交给thenAcceptBoth来进行消耗
public CompletionStage thenAcceptBoth(CompletionStage other,BiConsumer action);
public CompletionStage thenAcceptBothAsync(CompletionStage other,BiConsumer action);
public CompletionStage thenAcceptBothAsync(CompletionStage other,BiConsumer action, Executor executor); - thenCombine
thenCombine 会把 两个 CompletionStage 的任务都执行完成后,把两个任务的结果一块交给 thenCombine 来处理。
public CompletionStage thenCombine(CompletionStage other,BiFunction fn);
public CompletionStage thenCombineAsync(CompletionStage other,BiFunction fn);
public CompletionStage thenCombineAsync(CompletionStage other,BiFunction fn,Executor executor); /**
* 不能得到两个任务的参数,也无返回结果
*/
// future01.runAfterBothAsync(future02,()->{
// System.out.println("任务三开始。。。");
// },executor);
/**
* 能得到两个任务的参数,无返回结果
*/
// future01.thenAcceptBothAsync(future02,(f1,f2)->{
// System.out.println("任务三开始。。。之前的结果"+f1+":"+f2);
// },executor);
/**
* 能得到两个任务的参数,无返回结果
*/
CompletableFuture thenCombineAsync = future01.thenCombineAsync(future02, (f1, f2) -> {
System.out.println("任务三开始。。。之前的结果" + f1 + ":" + f2);
return f1 + ":" + f2 + "->haha";
}, executor);
System.out.println("main.............end......." + thenCombineAsync.get());
} 
6)、两任务组合-只要有一个任务完成就执行第三个
- runAfterEither 方法
两个CompletionStage,任何一个完成了都会执行下一步的操作(Runnable)
public CompletionStage runAfterEither(CompletionStage other,Runnable action);
public CompletionStage runAfterEitherAsync(CompletionStage other,Runnable action);
public CompletionStage runAfterEitherAsync(CompletionStage other,Runnable action,Executor executor); - acceptEither 方法
两个CompletionStage,谁执行返回的结果快,我就用那个CompletionStage的结果进行下一步的消耗操作。
public CompletionStage acceptEither(CompletionStage other,Consumer action);
public CompletionStage acceptEitherAsync(CompletionStage other,Consumer action);
public CompletionStage acceptEitherAsync(CompletionStage other,Consumer - applyToEither 方法
两个CompletionStage,谁执行返回的结果快,我就用那个CompletionStage的结果进行下一步的转化操作。
public CompletionStage applyToEither(CompletionStage other,Function fn);
public CompletionStage applyToEitherAsync(CompletionStage other,Function fn);
public CompletionStage applyToEitherAsync(CompletionStage other,Function CompletableFuture- thenCompose 方法
thenCompose 方法允许你对两个 CompletionStage 进行流水线操作,第一个操作完成时,将其结果作为参数传递给第二个操作。
public CompletableFuture thenCompose(Function> fn);
public CompletableFuture thenComposeAsync(Function> fn) ;
public CompletableFuture thenComposeAsync(Function7)、多任务组合

- allOf
CompletableFuture futureAttr = CompletableFuture.supplyAsync(() -> {
System.out.println("查询商品的属性");
return "黑色+256g";
},executor);
CompletableFuture futureImg = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(3000);
System.out.println("查询商品的图片信息");
} catch (InterruptedException e) {
e.printStackTrace();
}
return "hello.jpg";
},executor);
CompletableFuture futureDesc = CompletableFuture.supplyAsync(() -> {
System.out.println("查询商品的介绍");
return "华为";
},executor);
CompletableFuture allOf = CompletableFuture.allOf(futureAttr, futureImg, futureDesc);
allOf.get();//等待所有线程执行完
System.out.println("main.............end......."+futureAttr.get()+"=>"+futureImg.get()+"=>"+futureDesc.get() );
}

- anyOf
CompletableFuture futureAttr = CompletableFuture.supplyAsync(() -> {
System.out.println("查询商品的属性");
return "黑色+256g";
},executor);
CompletableFuture futureImg = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(3000);
System.out.println("查询商品的图片信息");
} catch (InterruptedException e) {
e.printStackTrace();
}
return "hello.jpg";
},executor);
CompletableFuture futureDesc = CompletableFuture.supplyAsync(() -> {
System.out.println("查询商品的介绍");
return "华为";
},executor);
// CompletableFuture allOf = CompletableFuture.allOf(futureAttr, futureImg, futureDesc);
// allOf.get();//等待所有线程执行完
CompletableFuture 
六、商品详情
1、搭建好域名跳转环境
1、用记事本打开C:\Windows\System32\drivers\etc\host(记得先把属性的只读模式去掉)

2、配置Nginx

之前配置了*.gulimall.com可以匹配上item.gulimall.com
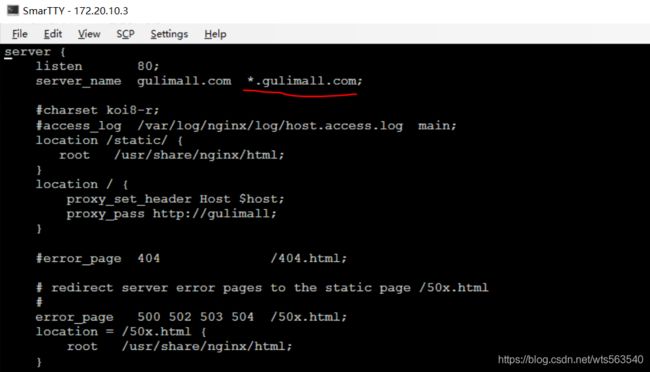
3、改网关

4、把详情页的html导入gulimall-product项目里
5、给虚拟机的nginx传入详情页的静态资源(static里再创建一个文件夹item)

6、把item.html的路径改了(ctrl+r)

![]()
添加“com.atguigu.gulimall.product.web.ItemController”类,代码如下:
package com.atguigu.gulimall.product.web;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
/**
* @Description: ItemController
* @Author: WangTianShun
* @Date: 2020/11/16 15:31
* @Version 1.0
*/
@Controller
public class ItemController {
/**
* 展示当前sku的详情
* @param skuId
* @return
*/
@GetMapping("/{skuId}.html")
public String skuItem(@PathVariable("skuId") Long skuId){
System.out.println("准备查询"+skuId+"的详情");
return "item";
}
}
修改gulimall-search的list.html
![]()
测试效果

2、模型抽取
模仿京东商品详情页,如下图所示,包括sku基本信息,图片信息,销售属性,图片介绍和规格参数

因此建立以下vo
添加“com.atguigu.gulimall.product.vo.SkuItemVo”类,代码如下:
package com.atguigu.gulimall.product.vo;
import com.atguigu.gulimall.product.entity.SkuImagesEntity;
import com.atguigu.gulimall.product.entity.SkuInfoEntity;
import com.atguigu.gulimall.product.entity.SpuInfoDescEntity;
import lombok.Data;
import java.util.List;
/**
* @Description: ItemVo
* @Author: WangTianShun
* @Date: 2020/11/16 16:20
* @Version 1.0
*/
@Data
public class SkuItemVo {
//1、sku基本信息获取 pms_sku_info
SkuInfoEntity info;
//2、sku的图片信息 pms_sku_images
List images;
//3、获取spu的销售属性组合
List saleAttr;
//4、获取spu的介绍
SpuInfoDescEntity desc;
//5、获取spu的规格参数信息
List groupAttrs;
}
添加“com.atguigu.gulimall.product.vo.SkuItemSaleAttrVo”类,代码如下:
package com.atguigu.gulimall.product.vo;
import lombok.Data;
import java.util.List;
/**
* @Description: SkuItemSaleAttrVo
* @Author: WangTianShun
* @Date: 2020/11/16 21:05
* @Version 1.0
*/
@Data
public class SkuItemSaleAttrVo {
private Long attrId;
private String attrName;
private String attrValues;
}
添加“com.atguigu.gulimall.product.vo.SpuItemAttrGroupVo”类,代码如下:
package com.atguigu.gulimall.product.vo;
import lombok.Data;
import lombok.ToString;
import java.util.List;
/**
* @Description: SpuItemAttrGroupVo
* @Author: WangTianShun
* @Date: 2020/11/16 21:02
* @Version 1.0
*/
@ToString
@Data
public class SpuItemAttrGroupVo {
private String groupName;
private List attrs;
}
3、 封装商品属性
(1) 总体思路
修改“com.atguigu.gulimall.product.web.ItemController”类,代码如下:
@Controller
public class ItemController {
@Autowired
SkuInfoService skuInfoService;
/**
* 展示当前sku的详情
* @param skuId
* @return
*/
@GetMapping("/{skuId}.html")
public String skuItem(@PathVariable("skuId") Long skuId, Model model) {
SkuItemVo skuItemVo = skuInfoService.item(skuId);
model.addAttribute("item", skuItemVo);
return "item";
}修改“com.atguigu.gulimall.product.service.SkuInfoService”类,代码如下:
SkuItemVo item(Long skuId);修改“com.atguigu.gulimall.product.service.impl.SkuInfoServiceImpl”类,代码如下:
@Override
public SkuItemVo item(Long skuId) {
SkuItemVo skuItemVo = new SkuItemVo();
//1、sku基本信息获取 pms_sku_info
SkuInfoEntity info = getById(skuId);
skuItemVo.setInfo(info);
Long catalogId = info.getCatalogId();
Long spuId = info.getSpuId();
//2、sku的图片信息 pms_sku_images
List images = skuImagesService.getImagesBySkuId(skuId);
skuItemVo.setImages(images);
//3、获取spu的销售属性组合
List saleAttrVos = skuSaleAttrValueService.getSaleAttrsBySpuId(spuId);
skuItemVo.setSaleAttr(saleAttrVos);
//4、获取spu的介绍 pms_spu_info_desc
SpuInfoDescEntity desc = spuInfoDescService.getById(spuId);
skuItemVo.setDesc(desc);
//5、获取spu的规格参数信息
List attrGroupVos = attrGroupService.getAttrGroupWithAttrsBySpuId(spuId,catalogId);
skuItemVo.setGroupAttrs(attrGroupVos);
return skuItemVo;
} (2) 获取spu的图片信息
修改“com.atguigu.gulimall.product.service.SkuImagesService”类,代码如下:
List getImagesBySkuId(Long skuId); 修改“com.atguigu.gulimall.product.service.impl.SkuImagesServiceImpl”类,代码如下:
@Override
public List getImagesBySkuId(Long skuId) {
List imagesEntities = this.baseMapper.selectList(new QueryWrapper().eq("sku_id", skuId));
return imagesEntities;
}
(3) 获取spu的销售属性
由于我们需要获取该spu下所有sku的销售属性,因此我们需要先从pms_sku_info查出该spuId对应的skuId,
在pms_sku_sale_attr_value表中查出上述skuId对应的属性
因此我们需要使用连表查询,并且通过分组将单个属性值对应的多个spuId组成集合,效果如下
修改“com.atguigu.gulimall.product.service.SkuSaleAttrValueService”类,代码如下:
List getSaleAttrsBySpuId(Long spuId); 修改“com.atguigu.gulimall.product.service.impl.SkuSaleAttrValueServiceImpl”类,代码如下:
@Override
public List getSaleAttrsBySpuId(Long spuId) {
SkuSaleAttrValueDao dao = this.baseMapper;
List saleAttrVos = dao.getSaleAttrsBySpuId(spuId);
return saleAttrVos;
} 修改“com.atguigu.gulimall.product.dao.SkuSaleAttrValueDao”类,代码如下:
List getSaleAttrsBySpuId(@Param("spuId") Long spuId); 修改SkuSaleAttrValueDao.xml
(5) 获取spu的规格参数信息
由于需要通过spuId和catalogId查询对应规格参数,所以我们需要通过pms_attr_group表获得catalogId和attrGroupName

然后通过 pms_attr_attrgroup_relation获取分组对应属性id
再到 pms_product_attr_value查询spuId对应的属性

最终sql效果,联表含有需要的所有属性
修改“com.atguigu.gulimall.product.service.AttrGroupService”类,代码如下:
List getAttrGroupWithAttrsBySpuId(Long spuId, Long catalogId); 修改“com.atguigu.gulimall.product.service.AttrGroupService”类,代码如下:
@Override
public List getAttrGroupWithAttrsBySpuId(Long spuId, Long catalogId) {
//1、查出当前spu对应的所有属性的分组信息以及当前分组下的所有属性对应的值
//1.1、
AttrGroupDao baseMapper = this.getBaseMapper();
List vos = baseMapper.getAttrGroupWithAttrsBySpuId(spuId,catalogId);
return vos;
} 修改“com.atguigu.gulimall.product.service.AttrGroupService”类,代码如下:
@Mapper
public interface AttrGroupDao extends BaseMapper {
List getAttrGroupWithAttrsBySpuId(@Param("spuId") Long spuId, @Param("catalogId") Long catalogId);
} 修改AttrGroupDao.xml
3、页面渲染
1)、添加thymeleaf的名称空间
 预约抢购
预约抢购
-
 190103 人预约
190103 人预约
-
 预约剩余
预约剩余
- 京东价
-
¥
4499.00
-
预约享资格
-
预约说明
无货, 此商品暂时售完
![]()
![]()
![]()
<
>
-
 关注
关注
 对比
对比
-
- 选择[[${attr.attrName}]]
-
[[${val}]]
![]()
主体
- 品牌
- 华为(HUAWEI)
包装清单
手机(含内置电池) X 1、5A大电流华为SuperCharge充电器X 1、5A USB数据线 X 1、半入耳式线控耳机 X 1、快速指南X 1、三包凭证 X 1、取卡针 X 1、保护壳 X 1
修改:获取spu的销售属性的逻辑
由于我们需要获取该spu下所有sku的销售属性,因此我们需要先从pms_sku_info查出该spuId对应的skuId,
在pms_sku_sale_attr_value表中查出上述skuId对应的属性
因此我们需要使用连表查询,并且通过分组将单个属性值对应的多个spuId组成集合,效果如下
为什么要设计成这种模式呢?
因为这样可以在页面显示切换属性时,快速得到对应skuId的值,比如白色对应的sku_ids为30,29,8+128GB对应的sku_ids为29,31,27,那么销售属性为白色、8+128GB的商品的skuId则为二者的交集29
添加“com.atguigu.gulimall.product.vo.AttrValueWithSkuIdVo”类,代码如下:
@Data
public class AttrValueWithSkuIdVo {
private String attrValue;
private String skuIds;
}
修改“com.atguigu.gulimall.product.vo.SkuItemSaleAttrVo”类,代码如下:
@Data
public class SkuItemSaleAttrVo {
private Long attrId;
private String attrName;
private List attrValues;
}
修改SkuItemSaleAttrVo.xml
效果如下:

4、页面的sku切换
通过控制class中是否包换checked属性来控制显示样式,因此要根据skuId判断
- 选择[[${attr.attrName}]]
-
[[${vals.attrValue}]]
5、使用异步编排
添加线程池属性配置类,并注入到容器中
package com.atguigu.gulimall.product.config;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
/**
* @Description: ThreadPoolConfigProperties
* @Author: WangTianShun
* @Date: 2020/11/17 13:40
* @Version 1.0
*/
@ConfigurationProperties(prefix = "gulimall.thread")
@Component
@Data
public class ThreadPoolConfigProperties {
private Integer core;
private Integer maxSize;
private Integer keepAliveTime;
}
添加application.yml
#线程池属性的配置
gulimall:
thread:
core: 20
max-size: 200
keep-alive-time: 10
线程池配置,获取线程池的属性值这里直接调用与配置文件相对应的属性配置类
package com.atguigu.gulimall.product.config;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* @Description: MyThreadConfig
* @Author: WangTianShun
* @Date: 2020/11/17 13:31
* @Version 1.0
*/
//如果ThreadPoolConfigProperties.class类没有加上@Component注解,那么我们在需要的配置类里开启属性配置的类加到容器中
//@EnableConfigurationProperties(ThreadPoolConfigProperties.class)
@Configuration
public class MyThreadConfig {
@Bean
public ThreadPoolExecutor threadPoolExecutor(ThreadPoolConfigProperties pool){
return new ThreadPoolExecutor(pool.getCore(),
pool.getMaxSize(),
pool.getKeepAliveTime(),
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(100000),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
}
}
为了使我们的任务进行的更快,我们可以让查询的各个子任务多线程执行,但是由于各个任务之间可能有相互依赖的关系,因此就涉及到了异步编排。
在这次查询中spu的销售属性、介绍、规格参数信息都需要spuId,因此依赖sku基本信息的获取,所以我们要让这些任务在1之后运行。因为我们需要1运行的结果,因此调用thenAcceptAsync()可以接受上一步的结果且没有返回值。
最后时,我们需要调用get()方法使得所有方法都已经执行完成
@Autowired
ThreadPoolExecutor executor;
@Override
public SkuItemVo item(Long skuId) throws ExecutionException, InterruptedException {
SkuItemVo skuItemVo = new SkuItemVo();
// 使用异步编排
CompletableFuture infoFuture = CompletableFuture.supplyAsync(() -> {
//1、sku基本信息获取 pms_sku_info
SkuInfoEntity info = getById(skuId);
skuItemVo.setInfo(info);
return info;
}, executor);
CompletableFuture saleAttrFuture = infoFuture.thenAcceptAsync((res) -> {
//3、获取spu的销售属性组合
List saleAttrVos = skuSaleAttrValueService.getSaleAttrsBySpuId(res.getSpuId());
skuItemVo.setSaleAttr(saleAttrVos);
}, executor);
CompletableFuture descFuture = infoFuture.thenAcceptAsync(res -> {
//4、获取spu的介绍 pms_spu_info_desc
SpuInfoDescEntity desc = spuInfoDescService.getById(res.getSpuId());
skuItemVo.setDesc(desc);
}, executor);
CompletableFuture baseAttrFuture = infoFuture.thenAcceptAsync((res) -> {
//5、获取spu的规格参数信息
List attrGroupVos = attrGroupService.getAttrGroupWithAttrsBySpuId(res.getSpuId(), res.getCatalogId());
skuItemVo.setGroupAttrs(attrGroupVos);
}, executor);
CompletableFuture imageFuture = CompletableFuture.runAsync(() -> {
//2、sku的图片信息 pms_sku_images
List images = skuImagesService.getImagesBySkuId(skuId);
skuItemVo.setImages(images);
}, executor);
//等待所有任务都完成
CompletableFuture.allOf(saleAttrFuture, descFuture, baseAttrFuture, imageFuture).get();
return skuItemVo;
}
未完,请看下一篇
谷粒商城-个人笔记(高级篇三):https://mp.csdn.net/editor/html/109713677