Python爬虫利器之Beautiful Soup入门详解,实战总结!!!
文章目录
-
- 1、简介
- 2、解析库
- 3、讲解
-
- 3.1、Tag(标签选择器)
- 3.2、标准选择器(find、find_all)
-
- 3.2.1、find_all()
- 3.2.2、find()
- 3.3、Select选择器
- 4、实战
1、简介
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
2、解析库
灵活又方便的网页解析库,处理高效,支持多种解析器。
利用它不用编写正则表达式即可方便地实现网页信息的提取。
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, “html.parser”) | Python的内置标准库、执行速度适中 、文档容错能力强 | Python 2.7.3 or 3.2.2前的版本中文容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) | 速度快、文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, “xml”) | 速度快、唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档 | 速度慢、不依赖外部扩展 |
3、讲解
3.1、Tag(标签选择器)
选择元素
import requests
from bs4 import BeautifulSoup
html = '''
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
'''
#使用BeautifulSoup对网页代码进行解析
#我这里使用的是Python标准库——html.parser
soup = BeautifulSoup(html, "html.parser")
# 获取html代码中的titile标签
print(soup.title)
![]()
注意:这里默认只匹配第一个,如果文章中有多个相同的标签,而且想要获取之后的标签,可根据class值或者一些其他方法进行定位,之后我会一一道来。
获取名称
print(soup.title.name)
获取属性


获取内容


嵌套选择


子节点
tag的 .contents 属性可以将tag的子节点以列表的方式输出
通过tag的 .children 生成器,可以对tag的子节点进行循环
import requests
from bs4 import BeautifulSoup
html = '''
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
'''
soup = BeautifulSoup(html, "html.parser")
print(soup.p.contents)
print("="*30)
for i in soup.p.children:
print(i)

父节点
通过 .parent 属性来获取某个元素的父节点


通过元素的 .parents 属性可以递归得到元素的所有父辈节点


兄弟节点


3.2、标准选择器(find、find_all)
3.2.1、find_all()
find_all( name , attrs , recursive , string , **kwargs )
find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件


keyword 参数
如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索,如果包含一个名字为 id 的参数,Beautiful Soup会搜索每个tag的”id”属性.


自定义参数查找:attrs


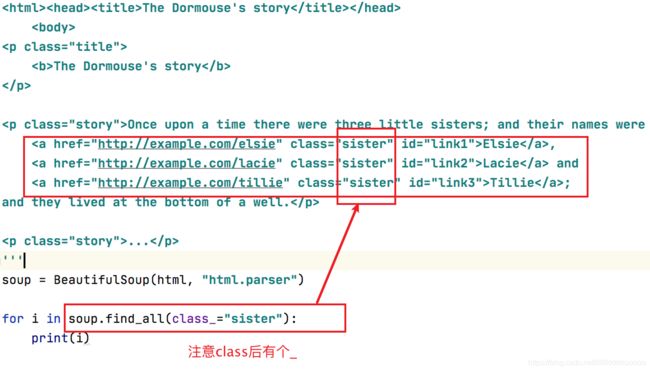

3.2.2、find()
find( name , attrs , recursive , text , **kwargs )
find返回单个元素,find_all返回所有元素

![]()
3.3、Select选择器
select
匹配全部
import requests
from bs4 import BeautifulSoup
html = '''
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
'''
soup = BeautifulSoup(html, "html.parser")
print(soup.select("p b"))
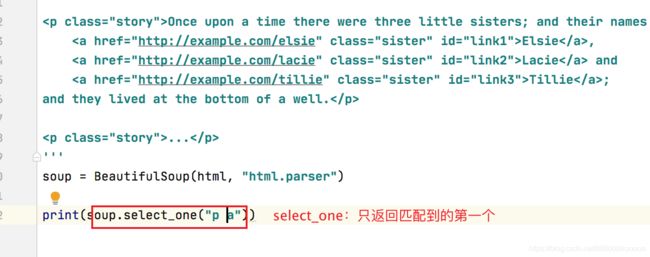
print(soup.select("p a"))
print(soup.select("head title"))
![]()
select_one
select_one只选择满足条件的第一个元素
![]()
4、实战
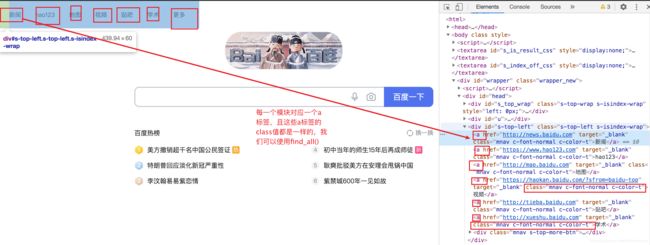
本次实战以百度首页为例

import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36"
}
url = "https://www.baidu.com"
response = requests.get(url=url,headers=headers)
soup = BeautifulSoup(response.text,"html.parser")
#获取全部class为mnav c-font-normal c-color-t的标签,进行遍历
divs = soup.find_all(class_="mnav c-font-normal c-color-t")
for div in divs:
print(div)
print("="*40)
可见获取成功

接下来获取每个模块对应的URL和文本值
for div in divs:
print(div['href'])
print(div.text)


import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36"
}
url = "https://www.baidu.com"
response = requests.get(url=url,headers=headers)
soup = BeautifulSoup(response.text,"html.parser")
#第一种方法
#通过contents,获取子节点信息
a_data = soup.find(class_="hot-title").contents
print(a_data[0].text)
#第二种方法
#先通过find使用class值定位,在使用find找到其下的div标签也就是我们需要的
a_data2 = soup.find(class_="hot-title").find("div")
print(a_data2.text)
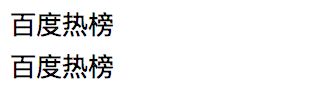
博主会持续更新,有兴趣的小伙伴可以点赞、关注和收藏下哦,你们的支持就是我创作最大的动力!
更多博主开源爬虫教程目录索引(宝藏教程,你值得拥有!)
