2021年 全网最细大数据学习笔记(四):Hadoop 之 HDFS的基本使用
文章目录
- 一、学前必备知识
- 二、Hadoop HDFS 命令
-
- 1、HDFS 常用命令总览
- 2、创建与查看 HDFS 目录
- 3、本地计算机和 HDFS 间的文件复制
- 4、复制与删除 HDFS 文件
- 5、查看 HDFS 文件内容
- 6、对比 hdfs dfs
- 三、Java 操作 HDFS
-
- 1、前置工作
- 2、示例代码
一、学前必备知识
- 2021年 全网最细大数据学习笔记(一):初识 Hadoop
- 2021年 全网最细大数据学习笔记(二):Hadoop 伪分布式安装
- 2021年 全网最细大数据学习笔记(三):Hadoop 集群的搭建与配置
二、Hadoop HDFS 命令
1、HDFS 常用命令总览
可以利用 HDFS 命令对 HDFS 进行操作。HDFS 有很多用户接口,其中命令行是最基本的,也是所有开发者必须熟悉的。所有命令行均由 bin/hadoop 脚本引发,不指定参数运行 Hadoop 脚本将显示所有命令的描述。若要完整了解 Hadoop 命令,可输入 hadoop fs -help 即可查看所有命令的帮助文件。HDFS 命令的格式如下:
hadoop fs –命令
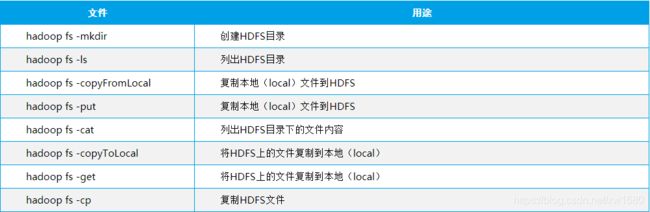
下面介绍一些常用的 HDFS 命令,如下表所示:
2、创建与查看 HDFS 目录
1、创建 HDFS 目录
命令:hadoop fs -mkdir。在 Hadoop 上创建目录与在 Linux 上创建目录类似,根目录用 / 表示。例如,创建 test 目录,打开 bigdata01 节点的终端,输入如下命令:
hadoop fs -mkdir /test
例如,在 test 目录下创建 amo 子目录,命令如下:
hadoop fs -mkdir /test/amo
例如,在 amo 目录下创建 demo 子目录,命令如下:
hadoop fs -mkdir /test/amo/demo
执行结果如下图所示:
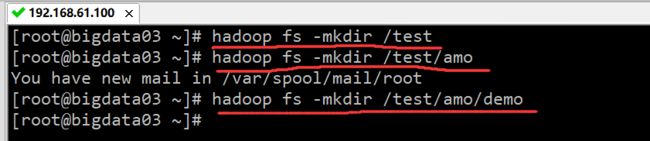
说明:在使用 HDFS 命令之前,必须先启动 Hadoop 集群,且命令执行在主节点的终端上。在创建 /test/amo 目录之前,必须先创建 test 目录,不能直接使用 hadoop fs -mkdir /test/amo 命令创建 amo 目录。
2、创建多级 HDFS 目录
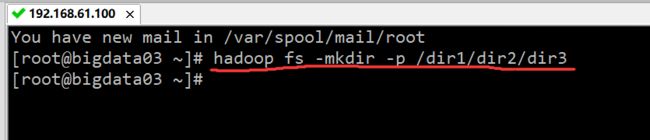
当创建目录时,如果要逐级地创建也很麻烦,所以 HDFS 提供了 -p 选项,可以帮助用户一次创建多级目录。例如,创建多级目录 /dir1/dir2/dir3 的命令为:
hadoop fs -mkdir -p /dir1/dir2/dir3
执行结果如下图所示:
3、查看 HDFS 目录
与 Linux 的 ls 命令类似,Hadoop 也有查看文件列表的命令,命令如下:
hadoop fs -ls
其中, 为可选参数。下面介绍查看命令的常用用法。
- 查看目录。查看上面创建的 test 目录,命令:hadoop fs -ls /test,执行结果如下图所示:
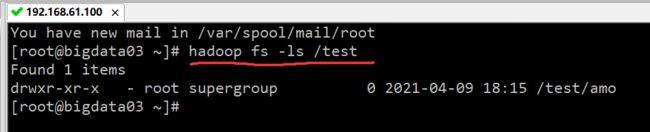
通过上图的执行结果可以看到,显示了 test 目录下的子目录和文件,如子目录 amo。 - 查看根目录。根目录是用
/表示的,查看根目录的命令为:hadoop fs -ls /,执行结果如下图所示:
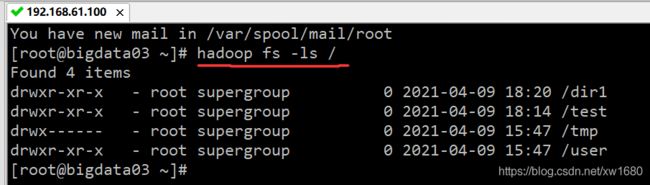
上述命令用来显示根目录下的子目录和文件。因为在之前的小节中创建了 dir1 和 test 目录,除了用户自己创建的目录以外,系统在安装的时候也已经创建了其他的目录,如 user 目录,user 目录与用户自己创建的目录具有相同的权限。 - 查看所有子目录。参数 -R 可用于查看所有 HDFS 子目录,R 代表 recursive(递归),命令:hadoop fs -ls -R /,执行结果如下图所示:
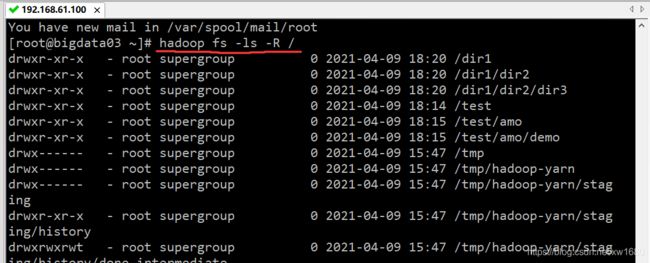
3、本地计算机和 HDFS 间的文件复制
1、从本地计算机复制文件到 HDFS
从本地计算机(Linux 虚拟机) 复制文件到 HDFS,也可称为上传文件到 HDFS。有两种命令可以使用,一种是 hadoop fs -put,另一种是 hadoop fs -copyFromLocal,在 bigdata01(主) 节点的终端输入如下命令:
hadoop fs -put /root/readme.txt /test/readme.txt
本段代码可以实现将本地 Linux 的文件 /root/readme.txt 上传到 HDFS 的 /test 下,文件名保持为 readme.txt,也可以在复制的时候重新命名文件。也可以不写复制的文件名,直接写要复制到的路径即可,如下所示,表示文件名保持不变。
hadoop fs -put /root/readme.txt /test
注意:在上传文件时,“/root/readme.txt” 该目录下的文件必须存在。查看复制的文件,命令如下:

使用 hadoop fs -copyFromLocal /root/readme.txt /test/readme.txt 也可实现上传文件的功能。
2、强制复制文件
当复制本地文件至 HDFS 目录时,如果文件已经存在,系统会提示 File exists,即文件已经存在,将不会复制,如下图所示:

当文件已经存在时,可以使用 -f 选项(f 是 force,强制),进行强制复制,命令如下:
hadoop fs -put -f /root/readme.txt /test/readme.txt
3、复制多个文件
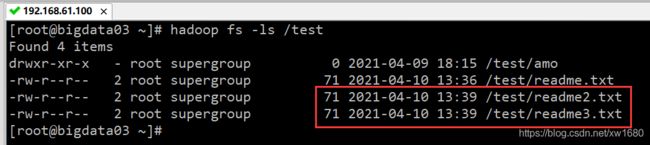
可以一次复制多个本地文件到 HDFS 目录,在下面的例子中,实现了复制“/root/readme2.txt” 和 “/root/readme3.txt” 这两个文件到 /test 目录。
hadoop fs -put /root/readme2.txt /root/readme3.txt /test
执行结果如下图所示:
4、复制目录
除了可以复制文件外,还可以复制目录。例如,将本地的目录 “/data/soft/hadoop-3.2.0/etc/” 到 HDFS 目录 /test,命令如下:
hadoop fs -put /data/soft/hadoop-3.2.0/etc /test
执行结果如下图所示:
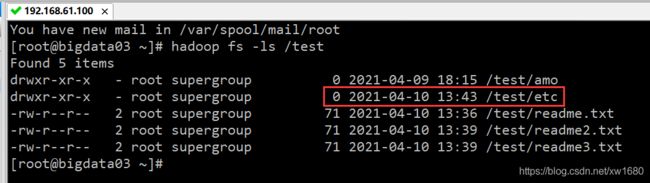
从上图中,只看到了 etc 的目录名称,还可以使用 hadoop fs -ls -R /test/etc 命令,来列出 HDFS 目录 /test/etc 下的所有文件。
5、复制并输入
在复制目录时使用到的是 -put 选项,还可以使用 -copyFromLocal 选项。但是两者的不同之处是:-put选项接受 stdin(标准输入)。下面看两个使用 -put 选项接受 stdin 的例子。
(1) 将原本显示在屏幕上的内容存储到 HDFS 文件,命令如下:
echo abd | hadoop fs -put - /test/echoin.txt
其中 echo abc 原本是要指定显示在屏幕上的内容 abc,现在通过 |(pipe 管道) 符号传递给 hadoop 的命令,并且存储到 HDFS 目录下的文件 echoin.txt 中。并列出 /test/echoin.txt 文件的内容,执行结果如下图所示:

(2) 将本地目录的列表存储到 HDFS 文件,命令如下:
ls /data/soft/hadoop-3.2.0/etc/hadoop | hadoop fs -put - /test/hadoopetc.txt
其中 “ls /data/soft/hadoop-3.2.0/etc/hadoop” 命令会把本地目录 ls /data/soft/hadoop-3.2.0/etc/hadoop 的列表显示在屏幕上,但是通过后面的 “|” 符号(pipe 管道) 传递给了 Hadoop 命令,所以最后会存储到 HDFS 目录下的 hadoopetc.txt 文件中。列出 /test/hadoopetc.txt 文件的内容,执行结果如下图所示:

6、将 HDFS 上的文件复制到本地计算机
将 HDFS 上的文件复制到本地计算机也称为文件下载。有两种命令可以使用,一种是 hadoop fs -get,另一种是 hadoop fs -copyToLocal,两种的用法相同,语法如下:
hadoop fs -get HDFS路径 本地路径
将 HDFS 的文件复制到本地计算机。首先在本地计算机上创建 localtest 测试目录,命令:mkdir localtest,然后将 HDFS 的文件 /test/hadoopetc.txt,复制到本地计算机的测试目录中 /localtest,命令:hadoop fs -get /test/hadoopetc.txt /root/localtest,最后查看本地 localtest 测试目录内文件和目录,命令:ls /root/localtest/,执行结果如下图所示:
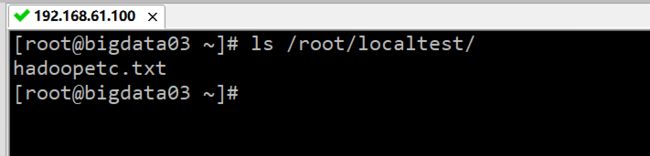
注意:在复制 HDFS 上的文件到本地的时候,此文件必须存在,否则会出现错误。另外,可以在复制文件的时候,重命名文件。
hadoop fs -get /test/hadoopetc.txt /root/localtest/amo.txt
4、复制与删除 HDFS 文件
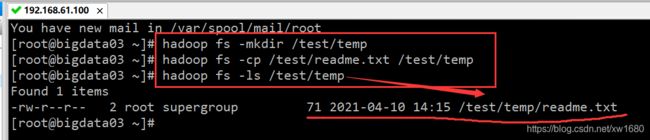
- 复制文件的命令为 “hadoop fs -cp”,示例,将 HDFS 文件 /test/readme.txt 复制到 HDFS 测试目录 /test/temp 上。
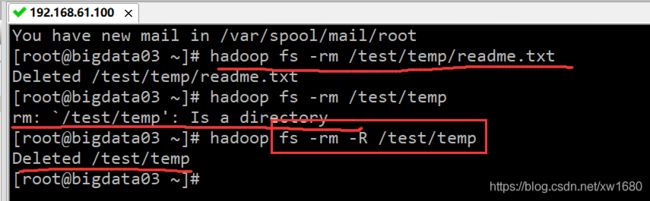
- 删除文件的命令为 “hadoop fs -rm”。删除 HDFS 目录的命令为 “hadoop fs -rm -R”。例如,删除 /test/temp/readme.txt 文件以及 temp目录。
5、查看 HDFS 文件内容
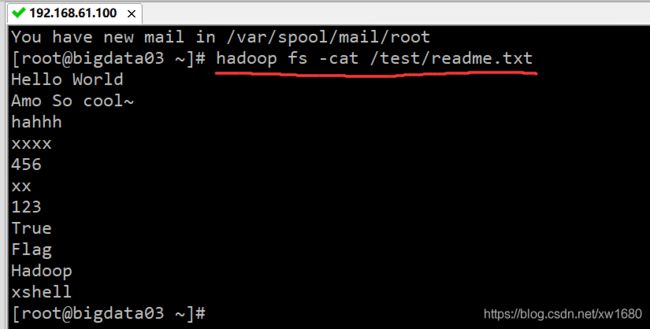
可以使用 hadoop fs -test、hadoop fs-cat、hadoop fs -tail 等不同参数形式查看 HDFS 集群中的文件内容。但是,只有文本文件的内容才可以查看,其他类型的文件则显示乱码。例如,查看 /test/readme.txt 文件,命令如下:
hadoop fs -cat /test/readme.txt
执行结果如下图所示:
6、对比 hdfs dfs
hdfs dfs 和 hadoop fs 命令没什么太大的区别,hdfs dfs 格式如下:
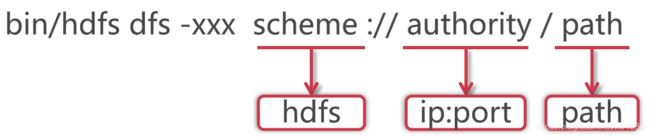 使用 hadoop bin 目录的 hdfs 命令,后面指定 dfs,表示是操作分布式文件系统的,这些属于固定格式。如果在 PATH 中配置了 hadoop 的 bin 目录,那么这里可以直接使用 hdfs 就可以了。这里的 xxx 是一个占位符,具体我们想对 hdfs 做什么操作,就可以在这里指定对应的命令了。大多数 hdfs 的命令和对应的 Linux 命令类似。HDFS 的 schema 是 hdfs,authority 是集群中 namenode 所在节点的 ip 和对应的端口号,把 ip 换成主机名也是一样的,path 是我们要操作的文件路径信息。其实后面这一长串内容就是 core-site.xml 配置文件中 fs.defaultFS 属性的值,这个代表的是 HDFS 的地址。说明:scheme://authority / 可以省略。因为 hdfs 在执行的时候会根据 HDOOP_HOME 自动识别配置文件中的 fs.defaultFS 属性。
使用 hadoop bin 目录的 hdfs 命令,后面指定 dfs,表示是操作分布式文件系统的,这些属于固定格式。如果在 PATH 中配置了 hadoop 的 bin 目录,那么这里可以直接使用 hdfs 就可以了。这里的 xxx 是一个占位符,具体我们想对 hdfs 做什么操作,就可以在这里指定对应的命令了。大多数 hdfs 的命令和对应的 Linux 命令类似。HDFS 的 schema 是 hdfs,authority 是集群中 namenode 所在节点的 ip 和对应的端口号,把 ip 换成主机名也是一样的,path 是我们要操作的文件路径信息。其实后面这一长串内容就是 core-site.xml 配置文件中 fs.defaultFS 属性的值,这个代表的是 HDFS 的地址。说明:scheme://authority / 可以省略。因为 hdfs 在执行的时候会根据 HDOOP_HOME 自动识别配置文件中的 fs.defaultFS 属性。
- 直接在命令行中输入 hdfs dfs,可以查看 dfs 后面可以跟的所有参数。
- -ls:查询指定路径信息。hdfs dfs -ls /
- -put:从本地上传文件。
- -cat:查看 HDFS 文件内容。
- -get:下载文件到本地。
- -mkdir [-p]:创建文件夹。
- -rm [-r]:删除文件/文件夹。
三、Java 操作 HDFS
1、前置工作
我们在工作中会遇到一些需求是需要通过代码操作 hdfs 的,下面我们就来看一下如何使用 java 代码操作 hdfs。在具体操作之前需要先明确一下开发环境,代码编辑器使用 idea,当然了 eclipse 也可以,笔者这里的话使用 idea,后续的文章也可能会使用 eclipse。在创建项目的时候创建 maven 项目,使用 maven 来管理依赖,比较方便。把 apache-maven-3.0.5-bin.zip 解压到某一个目录下面,解压之后,建议修改一下 maven 的配置文件,把 maven 仓库的地址修改到其它盘,例如 D 盘,默认是在 C 盘的用户目录下。修改 D:\Program Files\apache-maven-3.0.5-bin\apache-maven-3.0.5\conf 下的 settings.xml 文件,读者根据自己的实际路径进行修改,如下:
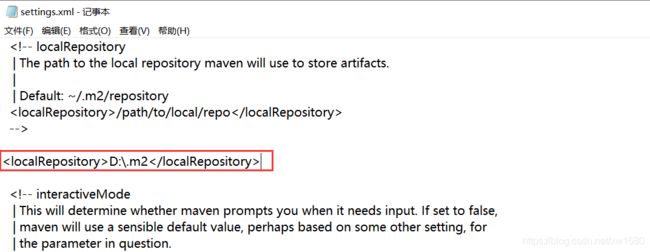
这样修改之后,maven 管理的依赖 jar 包都会保存到 D:.m2 目录下了。接下来需要配置 maven 的环境变量,和 Windows 中配置 JAVA_HOME 环境变量是一样的。先在环境变量中配置 M2_HOME=D:\Program Files\apache-maven-3.0.5-bin\apache-maven-3.0.5。然后在 PATH 环境变量中添加 %M2_HOME%\bin 即可。环境变量配置完毕以后,打开 cmd 窗口,输入 mvn 命令,只要能正常执行就说明 Windows 本地的 maven 环境配置好了。
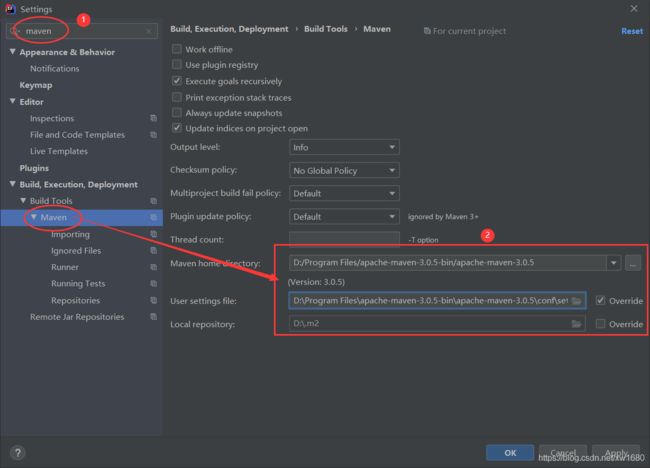
这还没完,还需要在 idea 中指定我们本地的 maven 配置。点击 idea 左上角的 File–>Settings,进入如下界面,搜索 maven,把本地的 maven 添加到这里面即可。
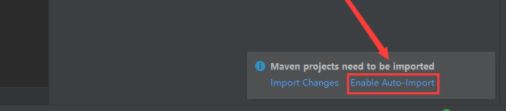
注意:项目创建好以后,在新打开的界面中需要点击右下角的 Enable Auto Import,这样添加到 maven 依赖会自动引入,否则会发现引入依赖了,但是代码中还是识别不了,这个时候还需要手动引入,比较麻烦。
有时候会由于网络原因导致依赖下载失败,默认情况下使用 maven 下载依赖的时候,会到 maven 的官方仓库中去下载,这个官库是国外的网址,所以在国内访问会比较慢。国内有多个 maven 仓库的镜像地址,所以我们可以修改 maven 下载依赖的源地址,改为国内的镜像地址即可。在这以国内阿里云提供的 maven 仓库镜像地址为例,修改 maven 安装目录下 conf 目录中的 settings.xmI 文件,找到里面的
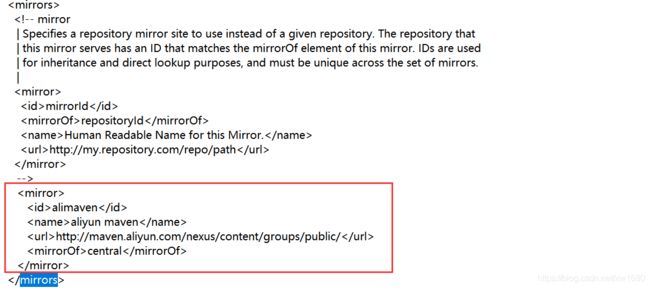
内容:
alimaven
aliyun maven
http://maven.aliyun.com/nexus/content/groups/public/
central
ok,项目创建好了以后,就需要引入 hadoop 的依赖了。在这里我们需要引入 hadoop-client 依赖包,到 maven 仓库中去找,添加到 pom.xml 文件中,
org.apache.hadoop
hadoop-client
3.2.0
示例代码如下:
package com.amo.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.FileInputStream;
import java.net.URI;
/**
* Java代码操作HDFS
* 文件操作:上传文件、下载文件、删除文件
* Created by AmoXiang
*/
public class HdfsOp {
public static void main(String[] args) throws Exception {
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS", "hdfs://bigdata01:9000");
//获取操作HDFS的对象
FileSystem fileSystem = FileSystem.get(conf);
//获取HDFS文件系统的输出流
FSDataOutputStream fos = fileSystem.create(new Path("/winin.txt"));
//获取本地文件的输入流
FileInputStream fis = new FileInputStream("D:\\file\\test.txt");
//上传文件:通过工具类把输入流拷贝到输出流里面,实现本地文件上传到HDFS
IOUtils.copyBytes(fis, fos, 1024, true);
}
}
执行代码,发现报错,提示权限拒绝,说明 Windows 中的这个用户没有权限向 HDFS 中写入数据。
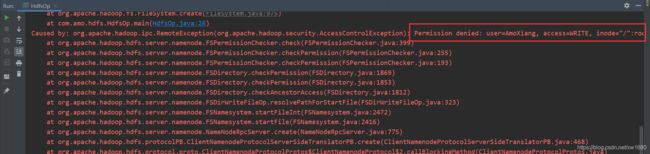
解决办法有两个:
(1) 去掉 hdfs 的用户权限检验机制,通过在 hdfs-site.xml 中配置 dfs.permissions.enabled 为 false 即可。
(2) 把代码打包到 linux 中执行。
在这里为了在本地测试方便,我们先使用第一种方式。
-
停止 Hadoop 集群。cd /data/soft/hadoop-3.2.0、sbin/stop-all.sh
-
修改 hdfs-site.xml 配置文件。注意:集群内所有节点中的配置文件都需要修改,先在 bigdata01 节点上修改,然后再同步到另外两个节点上。vi etc/hadoop/hdfs-site.xml
dfs.replication 2 dfs.namenode.secondary.http-address bigdata01:50090 dfs.permissions.enabled false -
同步到另外两个节点中。scp -rq etc/hadoop/hdfs-site.xml bigdata02:/data/soft/hadoop-3.2.0/etc/hadoop/、scp -rq etc/hadoop/hdfs-site.xml bigdata03:/data/soft/hadoop-3.2.0/etc/hadoop/
-
启动集群:sbin/start-all.sh
-
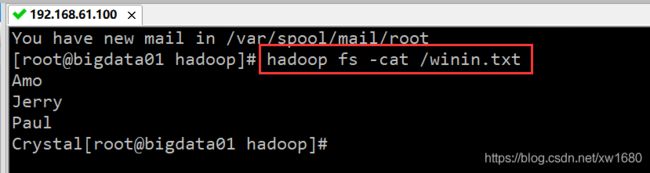
重新再执行代码,没有报错,到 hdfs 上查看数据。
在执行代码的时候会发现输出了很多红色的警告信息,虽然不影响代码执行,但是看起来很碍眼,强迫症实在忍不了。如何解决这个问题呢?通过分析错误信息发现第一个是缺少 log4j 的实现类,第二个是缺少 log4j 的配置文件。
-
pom.xml 中增加 log4j 依赖。
org.slf4j slf4j-api 1.7.10 org.slf4j slf4j-log4j12 1.7.10 -
resources 目录下添加 log4j.properties 文件。在项目的 src\main\resources 目录中添加 log4j.properties。
2、示例代码
package com.amo.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URI;
/**
* Java代码操作HDFS
* 文件操作:上传文件、下载文件、删除文件
* Created by AmoXiang
*/
public class HdfsOp {
public static void main(String[] args) throws Exception {
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS", "hdfs://bigdata01:9000");
//获取操作HDFS的对象
FileSystem fileSystem = FileSystem.get(conf);
// put(fileSystem);
// get(fileSystem);
delete(fileSystem);
}
/**
* 文件上传
*
* @param fileSystem
* @throws IOException
*/
private static void put(FileSystem fileSystem) throws IOException {
//获取HDFS文件系统的输出流
FSDataOutputStream fos = fileSystem.create(new Path("/win_in2.txt"));
//获取本地文件的输入流
FileInputStream fis = new FileInputStream("D:\\file\\test.txt");
//上传文件:通过工具类把输入流拷贝到输出流里面,实现本地文件上传到HDFS
IOUtils.copyBytes(fis, fos, 1024, true);
}
/**
* 下载文件
*
* @param fileSystem
* @throws IOException
*/
private static void get(FileSystem fileSystem) throws IOException {
//获取HDFS文件系统的输入流
FSDataInputStream fis = fileSystem.open(new Path("/test.txt"));
//获取本地文件的输出流
FileOutputStream fos = new FileOutputStream("D:\\file\\test.txt");
//下载文件
IOUtils.copyBytes(fis, fos, 1024, true);
}
/**
* 删除文件
*
* @param fileSystem
* @throws IOException
*/
private static void delete(FileSystem fileSystem) throws IOException {
//删除文件,目录也可以删除
//如果要递归删除目录,则第二个参数需要设置为true
//如果是删除文件或者空目录,第二个参数会被忽略
boolean flag = fileSystem.delete(new Path("/win_in2.txt"), true);
if (flag) {
System.out.println("删除成功!");
} else {
System.out.println("删除失败!");
}
}
}