神经网络学习小记录57——各类激活函数Activation Functions介绍与优缺点分析
神经网络学习小记录57——各类激活函数Activation Functions介绍与优缺点分析
- 学习前言
- 什么是激活函数
- 常用的激活函数
-
- 1、Sigmoid
- 2、Tanh
- 3、ReLU
- 先进的激活函数
-
- 1、LeakyReLU
- 2、PReLU
- 3、ReLU6
- 4、Swish
- 5、Mish
- 5、Swish和Mish的梯度对比。
- 绘制代码
学习前言
激活函数在神经网络当中的作用是赋予神经网络更多的非线性因素。如果不用激活函数,网络的输出是输入的线性组合,这种情况与最原始的感知机相当,网络的逼近能力相当有限。如果能够引入恰当的非线性函数作为激活函数,这样神经网络逼近能力就能够更加强大。

什么是激活函数
激活函数(Activation functions)对于神经网络模型学习与理解复杂和非线性的函数来说具有十分重要的作用。它们将非线性特性引入到我们的网络中。
如果网络中不使用激活函数,网络每一层的输出都是上层输入的线性组合,无论神经网络有多少层,输出都是输入的线性组合。
如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,此时神经网络就可以应用到各类非线性场景当中了。
常见的激活函数如sigmoid、tanh、relu等,它们的输入输出映射均为非线性,这样才可以给网络赋予非线性逼近能力。
下图为Relu激活函数,由于在0点存在非线性转折,该函数为非线性激活函数:

常用的激活函数
1、Sigmoid
Sigmoid函数是一个在生物学中常见的S型函数,它能够把输入的连续实值变换为0和1之间的输出,如果输入是特别大的负数,则输出为0,如果输入是特别大的正数,则输出为1。即将输入量映射到0到1之间。
Sigmoid可以作为非线性激活函数赋予网络非线性区分能力,也可以用来做二分类。其计算公式为:
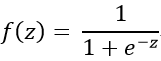
优点:
- 曲线过渡平滑,处处可导;
缺点:
- 幂函数运算较慢,激活函数计算量大;
- 求取反向梯度时,Sigmoid的梯度在饱和区域非常平缓,很容易造称梯度消失的问题,减缓收敛速度。
2、Tanh

Tanh是一个奇函数,它能够把输入的连续实值变换为-1和1之间的输出,如果输入是特别大的负数,则输出为-1,如果输入是特别大的正数,则输出为1;解决了Sigmoid函数的不是0均值的问题。
Tanh可以作为非线性激活函数赋予网络非线性区分能力。其计算公式为: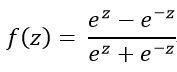
优点:
- 曲线过渡平滑,处处可导;
- 具有良好的对称性,网络是0均值的。
缺点:
- 与Sigmoid类似,幂函数运算较慢,激活函数计算量大;
- 与Sigmoid类似,求取反向梯度时,Tanh的梯度在饱和区域非常平缓,很容易造称梯度消失的问题,减缓收敛速度。
3、ReLU

线性整流函数(Rectified Linear Unit, ReLU),是一种深度神经网络中常用的激活函数,整个函数可以分为两部分,在小于0的部分,激活函数的输出为0;在大于0的部分,激活函数的输出为输入。计算公式为:
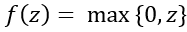
优点:
- 收敛速度快,不存在饱和区间,在大于0的部分梯度固定为1,有效解决了Sigmoid中存在的梯度消失的问题;
- 计算速度快,ReLU只需要一个阈值就可以得到激活值,而不用去算一大堆复杂的指数运算,具有类生物性质。
缺点:
- 它在训练时可能会“死掉”。如果一个非常大的梯度经过一个ReLU神经元,更新过参数之后,这个神经元的的值都小于0,此时ReLU再也不会对任何数据有激活现象了。如果这种情况发生,那么从此所有流过这个神经元的梯度将都变成 0。合理设置学习率,会降低这种情况的发生概率。
先进的激活函数
1、LeakyReLU

LeakyReLU是ReLU函数的改进版,普通的ReLU是将所有的负值都设为零,Leaky ReLU则是给所有负值赋予一个非零斜率。其计算公式为:
L e a k y R e L U ( x ) = { x , x ≥ 0 α x , x < 0 LeakyReLU(x) = \left\{ \begin{aligned} x ,& & {x \ge 0} \\ \alpha x ,& & {x < 0} \\ \end{aligned} \right. LeakyReLU(x)={ x,αx,x≥0x<0
优点:
- LeakyReLU具有ReLU的优点;
- 解决了ReLU函数存在的问题,防止死亡神经元的出现。
缺点:
- α参数人工选择,具体的的值仍然需要讨论。
2、PReLU
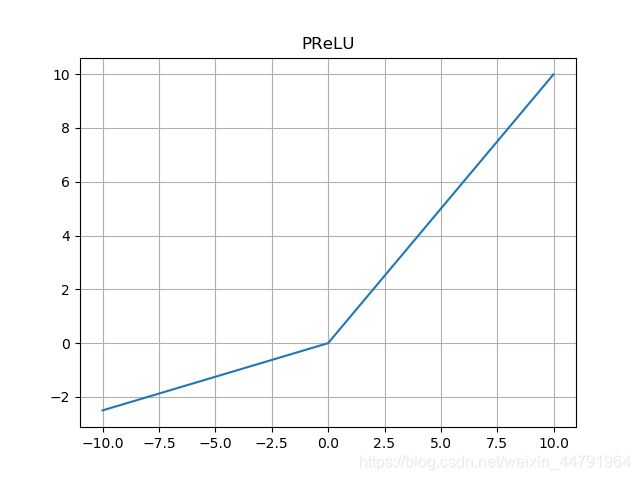
PReLU也是ReLU和LeakyReLU函数的改进版,普通的ReLU是将所有的负值都设为零,PReLU是给所有负值赋予一个非零斜率,与LeakyReLU不同的是,PReLU是一个参数,由神经网络自适应训练获得。其计算公式为:
P R e L U ( x ) = { x , x ≥ 0 α x , x < 0 PReLU(x) = \left\{ \begin{aligned} x ,& & {x \ge 0} \\ \alpha x ,& & {x < 0} \\ \end{aligned} \right. PReLU(x)={ x,αx,x≥0x<0
优点:
- PReLU具有LeakyReLU的优点;
- 解决了LeakyReLU函数存在的问题,让神经网络自适应选择参数。
3、ReLU6

ReLU6就是普通的ReLU但是限制最大输出为6,用在MobilenetV1网络当中。目的是为了适应float16/int8 的低精度需要
R e L U 6 ( x ) = m i n ( m a x ( 0 , x ) , 6 ) ReLU6(x) = min(max(0,x),6) ReLU6(x)=min(max(0,x),6)
优点:
- ReLU6具有ReLU函数的优点;
- 该激活函数可以在移动端设备使用float16/int8低精度的时候也能良好工作。如果对 ReLU 的激活范围不加限制,激活值非常大,则低精度的float16/int8无法很好地精确描述如此大范围的数值,带来精度损失。
缺点:
- 与ReLU缺点类似。
4、Swish

Swish是Sigmoid和ReLU的改进版,类似于ReLU和Sigmoid的结合,β是个常数或可训练的参数。Swish 具备无上界有下界、平滑、非单调的特性。Swish 在深层模型上的效果优于 ReLU。
f ( x ) = x ⋅ sigmoid ( β x ) f(x) = x · \text{sigmoid}(βx) f(x)=x⋅sigmoid(βx)
优点:
- Swish具有一定ReLU函数的优点;
- Swish具有一定Sigmoid函数的优点;
- Swish函数可以看做是介于线性函数与ReLU函数之间的平滑函数.。
缺点:
- 运算复杂,速度较慢。
5、Mish

Mish与Swish激活函数类似,Mish具备无上界有下界、平滑、非单调的特性。Mish在深层模型上的效果优于 ReLU。无上边界可以避免由于激活值过大而导致的函数饱和。
M i s h = x ∗ t a n h ( l n ( 1 + e x ) ) Mish=x * tanh(ln(1+e^x)) Mish=x∗tanh(ln(1+ex))
优点:
- Mish具有一定ReLU函数的优点,收敛快速;
- Mish具有一定Sigmoid函数的优点,函数平滑;
- Mish函数可以看做是介于线性函数与ReLU函数之间的平滑函数.。
缺点:
- 运算复杂,速度较慢。
5、Swish和Mish的梯度对比。
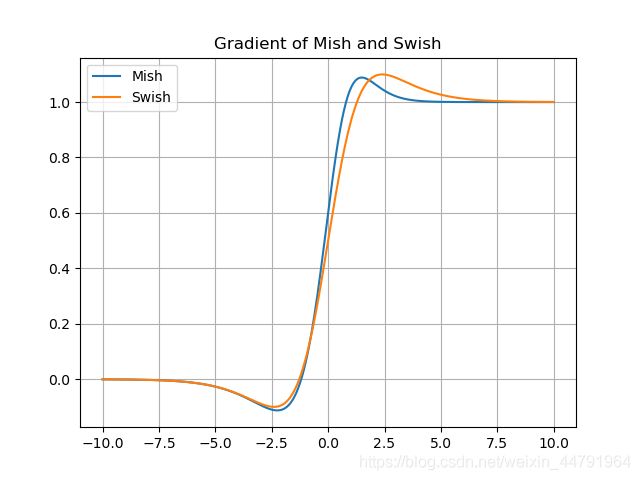
Mish与Swish激活函数非常接近。
绘制代码
import matplotlib.pyplot as plt
import numpy as np
def Sigmoid(x):
y = np.exp(x) / (np.exp(x) + 1)
return y
def Tanh(x):
y = (np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x))
# y = np.tanh(x)
return y
def ReLU(x):
y = np.where(x < 0, 0, x)
return y
def LeakyReLU(x, a):
# LeakyReLU的a参数不可训练,人为指定。
y = np.where(x < 0, a * x, x)
return y
def PReLU(x, a):
# PReLU的a参数可训练
y = np.where(x < 0, a * x, x)
return y
def ReLU6(x):
y = np.minimum(np.maximum(x, 0), 6)
return y
def Swish(x, b):
y = x * (np.exp(b*x) / (np.exp(b*x) + 1))
return y
def Mish(x):
# 这里的Mish已经经过e和ln的约运算
temp = 1 + np.exp(x)
y = x * ((temp*temp-1) / (temp*temp+1))
return y
def Grad_Swish(x, b):
y_grad = np.exp(b*x)/(1+np.exp(b*x)) + x * (b*np.exp(b*x) / ((1+np.exp(b*x))*(1+np.exp(b*x))))
return y_grad
def Grad_Mish(x):
temp = 1 + np.exp(x)
y_grad = (temp*temp-1) / (temp*temp+1) + x*(4*temp*(temp-1)) / ((temp*temp+1)*(temp*temp+1))
return y_grad
if __name__ == '__main__':
x = np.arange(-10, 10, 0.01)
plt.plot(x, Sigmoid(x))
plt.title("Sigmoid")
plt.grid()
plt.show()
plt.plot(x, Tanh(x))
plt.title("Tanh")
plt.grid()
plt.show()
plt.plot(x, ReLU(x))
plt.title("ReLU")
plt.grid()
plt.show()
plt.plot(x, LeakyReLU(x, 0.1))
plt.title("LeakyReLU")
plt.grid()
plt.show()
plt.plot(x, PReLU(x, 0.25))
plt.title("PReLU")
plt.grid()
plt.show()
plt.plot(x, ReLU6(x))
plt.title("ReLU6")
plt.grid()
plt.show()
plt.plot(x, Swish(x, 1))
plt.title("Swish")
plt.grid()
plt.show()
plt.plot(x, Mish(x))
plt.title("Mish")
plt.grid()
plt.show()
plt.plot(x, Grad_Mish(x))
plt.plot(x, Grad_Swish(x, 1))
plt.title("Gradient of Mish and Swish")
plt.legend(['Mish', 'Swish'])
plt.grid()
plt.show()