Spark之处理布尔、数值和字符串类型的数据
☀️上次我们介绍了spark的基本知识和dataframe的技巧,感兴趣的小伙伴可以查看以下内容:
- Spark之Dataframe基本操作: spark之dataframe.
- Hadoop之spark浅析.: spark浅析.
今天我们来学习Spark对不同数据类型的操作,主要有布尔类型、数值类型和字符串类型。
1.转化成spark类型
为什么要转化为spark类型?这是因为我们导入数据到spark后,spark并不认识这些类型,我们需要使用lit这个函数来将其他语言的类型转换为为之对应的Spark表示。
#将原始类型转化为spark类型
from pyspark.sql.functions import lit
df.select(lit(5),lit("five"),lit(5.0))
看一下结果:

2.处理布尔类型
布尔类型在数据分析中尤为重要,因为它是过滤所有操作的基础,,布尔语句主要有四要素:and、or 、true和false。
选择InvoiceNo=536365的数据
df.where("InvoiceNo=536365").show(5,False)#show(int,false)false是指是否只显示20个字符,默认为true
选择(“InvoiceNo”) != 536365的数据
from pyspark.sql.functions import col
df.where(col("InvoiceNo") != 536365).select("InvoiceNo", "Description").show(5, False)
在之前我们提过,可以使用and或者or将多个Boolean连接起来,但是在Spark中最好是以链式连接的方式组合起来,形成顺序执行的过滤器,这做的原因是因为即使Boolean语句的顺序是顺序表达的,Spark也还会将所有的这些过滤器合并为一条语句,并同时执行这些过滤器,创建and语句。尽管你在语句中可以显式地使用and,但是如果将他们串起来就更容易理解和阅读;or语句也是这这样执行。
选择(“UnitPrice”)>600或者POSTAGE出现位置大于1,并且是DOT的数据
from pyspark.sql.functions import col
from pyspark.sql.functions import instr#返回字母第一次出现的位置
priceFileter=col("UnitPrice")>600
descripFilter=instr(df.Description,"POSTAGE")>=1
df.where(df.StockCode.isin("DOT")).where(priceFileter|descripFilter).show()
结果如下:

过滤dataframe也可以使用一个布尔类型的列
#过滤Dataframe 其中 instr(c1,c2)是在c1中寻找层c2的位置,找到返回数组下标,没有则返回0
from pyspark.sql.functions import instr
dotcodefilter=col("StockCode")=="DOT"
pricefilter=col("UnitPrice")>600
descriptfilter=instr(col("Description"),"POSTAGE")>=1
df.withColumn("isExpensive", dotcodefilter & (pricefilter | descriptfilter)).where("isExpensive").select("unitPrice", "isExpensive").show(5)
#等价于sql
%sql
SELECT UnitPrice, (StockCode = 'DOT' AND
(UnitPrice > 600 OR instr(Description, "POSTAGE") >= 1)) as isExpensive
FROM dfTable
WHERE (StockCode = 'DOT' AND
(UnitPrice > 600 OR instr(Description, "POSTAGE") >= 1))
结果如下:

2.处理数值型的数据
处理数值型的数据主要是进行数学运算,spark中具有很多数据计算的包
2.1 幂运算pow,计算(col(“Quantity”)*col(“UnitPrice”))^2+5
#处理数值型数据
from pyspark.sql.functions import expr,pow
quantity=pow(col("Quantity")*col("UnitPrice"),2)+5
df.select(expr("CustomerId"),quantity.alias("realQuantity")).show(2)
#下面是用selectExpr
df.selectExpr("CustomerId","(POWER((Quantity*UnitPrice),2)+5) as RealQ").show(2)
计算结果:

2.2 四舍五入 round为向上取整,bround为向下取整
from pyspark.sql.functions import lit,round,bround
df.select(round(lit("2.5")),bround(lit("2.5"))).show(2)
结果如下:

2.3 #计算两列的相关性corr
from pyspark.sql.functions import corr
COR=df.stat.corr("Quantity","UnitPrice")
df.select(corr("Quantity","UnitPrice")).show(2)
结果如下:

2.4 显示数据的count、mean、标准差、最小值、最大值
df.describe().show()
#也可通过计算得到
from pyspark.sql.functions import count,mean,stddev_pop,min,max
df.select(min("UnitPrice")).show()
结果如下:

3. 处理字符类型的数据
3.1 转化大小写
#处理字符类型的数据
#initcap函数将会给定字符串中空格分隔的每个单词首字母大写
from pyspark.sql.functions import initcap
df.select(initcap(col("Description"))).show(3,False)
结果如下:

#大小写转换lower upper
from pyspark.sql.functions import lower,upper,col
df.select(col("Description"),lower(col("Description")),upper(lower(col("Description")))).show(3)

#删除字符串周边的空格或者在在周围添加空格
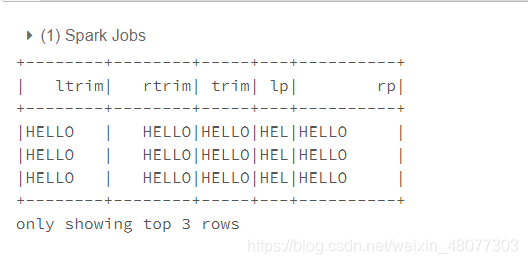
from pyspark.sql.functions import lit,ltrim,rtrim,rpad,lpad,trim
df.select(ltrim(lit(" HELLO ")).alias("ltrim"),#删除左边空格
rtrim(lit(" HELLO ")).alias("rtrim"),#删除右边空格
trim(lit(" HELLO ")).alias("trim"),#删除两边空格
lpad(lit("HELLO"),3," ").alias("lp"),#将左边的字符串填充一些特定的字符,如果n小于字符串个数,则只取原字符
rpad(lit("HELLO"),10," ").alias("rp")#将右边填充字符
).show(3)
参考资料
《Hadoop权威指南》
《大数据hadoop3.X分布式处理实战》
《Spark权威指南》
《Pyspark实战》