大数据学习总结(2021版)---Mysql基础
这里写目录标题
- 第1章:数据库
-
- 1.1 数据库概述
- 1.2 数据库表
- 1.3 表数据
- 第2章:MySql数据库
-
- 2.1 MySql启动和停止
- 2.2 登录MySQL数据库
- 2.3 SQLyog(MySQL图形化开发工具)
- 2.4 MySQL配置文件
- 第3章:SQL语句
-
- 3.1 SQL分类
- 3.2 SQL通用语法
- 3.3 数据库操作:database(创建、查看、删除、修改)
- 3.4 表结构相关语句
-
- 3.4.1 创建表
- 3.4.2 查看表
- 3.4.3 删除表
- 3.4.4 修改表结构格式
- 第4章:字段属性
-
- 4.1 主键
-
- 4.1.1增加主键
- 4.1.2 主键约束
- 4.1.3 更新主键 & 删除主键
- 4.1.4 主键分类
- 4.2 自动增长
-
- 4.2.1 新增自增长
- 4.2.2 自增长使用
- 4.2.3 修改自增长?????
- 4.2.4 删除自增长
- 4.3 唯一键
-
- 4.3.1 增加唯一键
- 4.3.2 唯一键约束
- 4.3.3 更新唯一键 & 删除唯一键
- 4.4 外键
-
- 4.4.2 新增外键
- 4.4.2 修改外键&删除外键
- 4.4.3 外键作用
- 4.4.4 外键条件
- 4.4.5 外键约束(不推荐)
- 4.4.6 创建外键约束的要求
- 4.4.7 外键约束的闭环问题
- 4.5 索引
-
- 4.5.1 创建索引
- 4.5.2 添加索引
- 4.5.3 查询索引
- 4.5.4 删除索引
- 4.5.5 索引的使用原则
- 4.5.6 索引的意义
- 第5章:关系
-
- 5.1 一对一
- 5.2 一对多
- 5.3多对多
- 第6章:范式
-
- 6.1 1NF(第一范式)
- 6.2 2NF(第二范式)???
- 6.3 3NF(第三范式)
- 6.4 逆规范化
- 第7章:数据高级操作(增、删、改、查)
-
- 7.1 新增数据
-
- 7.1.1 IGNORE关键字
- 7.1.2 主键冲突
- 7.1.3 蠕虫复制
- 7.2 更新数据
-
- 7.2.1 UPDATE语句中的内连接?????
- 7.2.2 UPDATE语句中的外连接?????
- 7.3 删除数据
-
- 7.3.1 DELETE语句中的内连接????
- 7.3.2 DELETE语句中的外连接????
- 7.3.3 快速删除数据表全部记录
- 7.4 查询数据
-
- 7.4.1 Select语句
- 7.4.3 字段别名
- 7.4.4 数据源
- 7.4.5 Where子句
- 7.4.6 聚合函数
- 7.4.7 Group by子句
- 7.4.8 Having子句
- 7.4.9 Order by子句
- 7.4.10 Limit子句
- 第8章:连接查询
-
- 8.1 连接查询分类
- 8.2 交叉连接
- 8.3 内连接
- 8.4 外连接
- 8.5 自然连接
- 8.6 子查询
- 8.6.1 子查询分类
-
- 8.6.2 单行子查询和多行子查询???
- 8.6.3 WHERE子句中的多行子查询???
- 8.6.4 子查询的EXISTS关键字
- 第9章:视图
-
- 9.2 查看视图
- 9.3 使用视图
- 9.4 修改视图
- 9.5 删除视图
- 9.6 视图意义
- 9.7 视图数据操作(不建议使用)
-
- 9.7.1 新增数据
- 9.7.2 删除数据
- 9.7.3 更新数据
- 9.8 视图算法
- 第10章:数据备份与还原
-
- 10.1 数据表备份
- 10.2 单表数据备份
- 10.3 SQL备份与还原
- 10.4 增量备份
- 10.5 大文件备份和还原(图形化操作,推荐!)
- 第11章:事务、事务安全
-
- 11.1 事务操作
- 11.2 自动事务处理
- 11.3 事务原理
- 11.4 回滚点
- 11.5 事务ACID属性
- 11.6 事务的隔离级别
-
- 11.6.1 read uncommitted
- 11.6.2 read committed
- 11.6.3 repeatable read
- 11.6.4 serializable ???
- 第12章:触发器
-
- 12.1 创建触发器
- 12.2 查看触发器
- 12.3 使用触发器
- 12.4 修改触发器&删除触发器
- 12.5 触发器记录???
- 第13章:函数
-
- 13.1 数字函数
- 13.2 日期函数
-
- 13.2.1 获取系统时间函数
- 13.2.2 日期格式化函数
- 13.2.3 日期偏移计算
- 13.2.4 计算日期之间相隔的天数
- 13.3 字符函数
- 13.4 条件函数
-
- 13.4.1 简单条件判断
- 13.4.2 复杂条件判断
- 13.5 自定义函数
-
- 13.5.1 创建函数
- 13.5.2 查看函数
- 13.5.3 修改函数&删除函数
- 13.5.4 函数参数
- 13.5.5 作用域
- 第14章:存储过程
-
- 14.1 创建过程
- 14.2 查看过程
- 14.3 调用过程
- 14.4 修改过程&删除过程
- 14.5 过程参数
第1章:数据库
1.1 数据库概述
- 什么是数据库
数据库就是存储数据的仓库,其本质是一个文件系统,数据按照特定的格式将数据存储起来,用户可以对数据库中的数据进行增加,修改,删除及查询操作。 - 什么是数据库管理系统
数据库管理系统(DataBase Management System,DBMS):指一种操作和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制,以保证数据库的安全性和完整性。用户通过数据库管理系统访问数据库中表内的数据。 - 常见的数据库管理系统
-
MYSQL :开源免费的数据库,小型的数据库.已经被Oracle收购了.MySQL6.x版本也开始收费。
-
Oracle :收费的大型数据库,Oracle公司的产品。Oracle收购SUN公司,收购MYSQL。
-
DB2 :IBM公司的数据库产品,收费的。常应用在银行系统中.
-
SQLServer:MicroSoft 公司收费的中型的数据库。C#、.net等语言常使用。
-
SyBase :已经淡出历史舞台。提供了一个非常专业数据建模的工具PowerDesigner。
-
SQLite : 嵌入式的小型数据库,应用在手机端。
-
Java相关的数据库:MYSQL,Oracle.
-
这里使用MySQL数据库。MySQL中可以有多个数据库,数据库是真正存储数据的地方。
1.2 数据库表
数据库中以表为组织单位存储数据。
表类似我们的Java类,每个字段都有对应的数据类型。
那么用我们熟悉的java程序来与关系型数据对比,就会发现以下对应关系。
- 类----------表
- 类中属性----------表中字段
- 对象----------记录
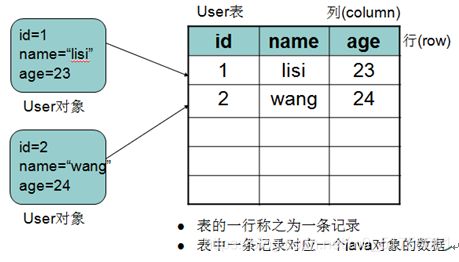
1.3 表数据
根据表字段所规定的数据类型,我们可以向其中填入一条条的数据,而表中的每条数据类似类的实例对象。表中的一行一行的信息我们称之为记录。

表记录与java类对象的对应关系
第2章:MySql数据库
2.1 MySql启动和停止
- 安装后,MySQL会以windows服务的方式为我们提供数据存储功能。开启和关闭服务的操作:右键点击我的电脑→管理→服务→可以找到MySQL服务开启或停止。
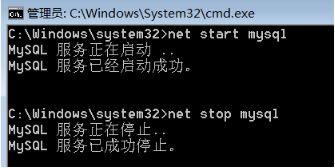
- 也可以在DOS窗口,通过命令完成MySQL服务的启动和停止(必须以管理运行cmd命令窗口)
2.2 登录MySQL数据库
MySQL是一个需要账户名密码登录的数据库,登陆后使用,它提供了一个默认的root账号,使用安装时设置的密码即可登录。
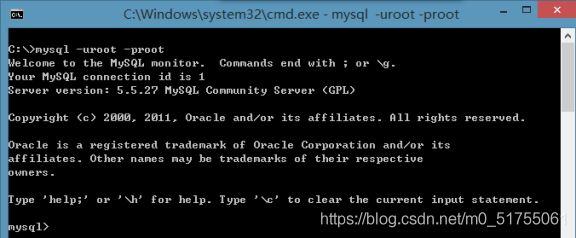
- 格式1:cmd> mysql –u用户名 –p密码
例如:mysql -u root –proot123456
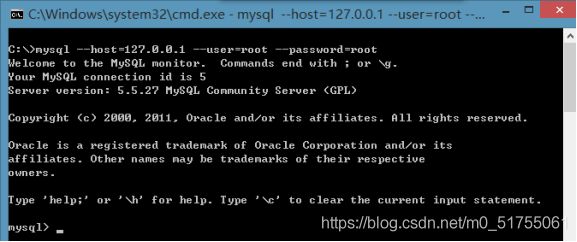
- 格式2:mysql --host=ip地址 --user=用户名 --password=密码
例如:mysql --host=127.0.0.1 --user=root --password=root
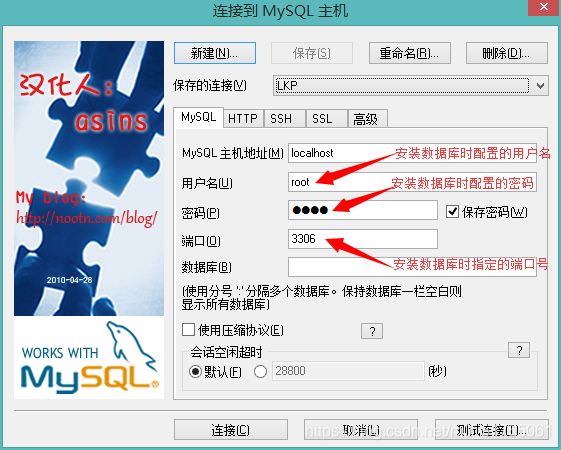
2.3 SQLyog(MySQL图形化开发工具)
- 建议:
我建议使用Navicat,具体怎么破解得百度,公司都用的这个,学习阶段用SQLyog也没关系 - 使用:
输入用户名、密码,点击连接按钮,进行访问MySQL数据库进行操作
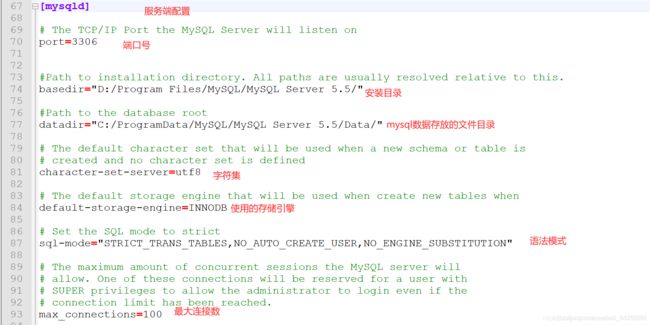
2.4 MySQL配置文件
- MySQL目录结构
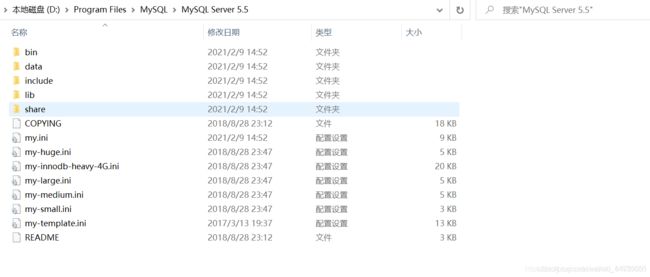
1)bin 目录
用于放置一些可执行文件,如 mysql.exe、mysqld.exe、mysqlshow.exe 等。
2)docs 目录
存放一些文档
3)Data 目录
登录数据库后,可使用 SHOW GLOBAL VARIABLES LIKE “%Datadir%”;命令查看 Data 目录位置。
Data 目录中用于放置一些日志文件以及数据库。我们创建和保存的数据都存在这个目录里。
4)include 目录
用于放置一些头文件,如:mysql.h、mysql_ername.h 等。
5)lib 目录
用于放置一系列库文件
6)share 目录
用于存放字符集、语言等信息
7)my.ini 文件
my.ini 是 MySQL 默认使用的配置文件,一般情况下,只要修改 my.ini 配置文件中的内容就可以对 MySQL 进行配置
- my.ini 文件
- [client]和[mysql]是客户端配置信息,[mysqld]是数据库配置信息
- [mysql]中默认no-beep表示当数据库发生错误的时候,不要让主板发出蜂鸣器的声音
- [mysqld]大致说明如下


第3章:SQL语句
3.1 SQL分类
-
数据定义语言:简称DDL(Data Definition Language),用来定义数据库对象:数据库,表,列等。关键字:create,alter,drop等
-
数据操作语言:简称DML(Data Manipulation Language),用来对数据库中表的记录进行更新。关键字:insert,delete,update等
-
数据控制语言:简称DCL(Data Control Language),用来定义数据库的访问权限和安全级别,及创建用户。
-
数据查询语言:简称DQL(Data Query Language),用来查询数据库中表的记录。关键字:select,from,where等
3.2 SQL通用语法
- 1.SQL语句可以单行或多行书写,以分号结尾
- 2.可使用空格和缩进来增强语句的可读性
- 3.MySQL数据库的SQL语句不区分大小写,建议使用大写,例如:SELECT * FROM user。
- 4.同样可以使用/**/的方式完成注释
- 5.MySQL中的我们常使用的数据类型如下

3.3 数据库操作:database(创建、查看、删除、修改)
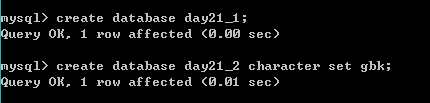
创建数据库
- 创建数据库 数据库中数据的编码采用的是安装数据库时指定的默认编码 utf8
create database 数据库名;
- #创建数据库 并指定数据库中数据的编码
create database 数据库名 character set 字符集;
举例:
- #如果创建之后 修改数据库编码
ALTER DATABASE day21_2 CHARACTER SET=utf8;
查看数据库
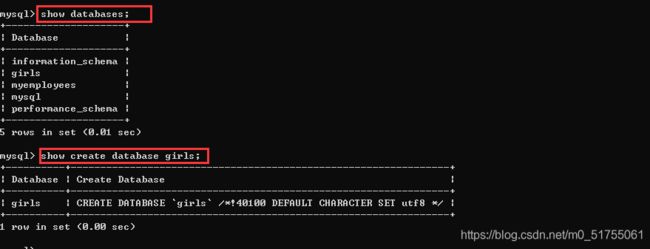
- 查看数据库MySQL服务器中的所有的数据库:
show databases;
- 查看某个数据库的定义的信息
show create database 数据库名;
举例:
删除数据库
- drop database 数据库名称;
drop database day21_2;
切换数据库:
- use 数据库名;
use day21_1;
查看正在使用的数据库:
select database();
3.4 表结构相关语句
3.4.1 创建表
格式:
create table 表名(
字段名 类型(长度) 约束,
字段名 类型(长度) 约束
);
例如:
## 创建分类表
CREATE TABLE sort (
sid INT, #分类ID
sname VARCHAR(100) #分类名称
);
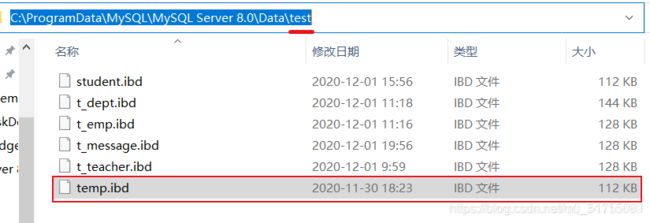
温馨提示:
你创建了数据库,就创建了一块逻辑空间,实际在磁盘上创建了一个文件夹,你创建了一个表,实际磁盘生成了一个.ibd文件,你可以在C:\ProgramData\MySQL\MySQL Server 8.0\Data目录下验证一下
举个例子,你创建了test数据库,然后你执行建表语句如下
CREATE TABLE temp(/*实验精度丢失问题*/
id INT UNSIGNED PRIMARY KEY,
num DECIMAL(20, 10) /*数字总位数20,保留小数点后10位*/
)
实际在你的磁盘上是这样存储的
3.4.2 查看表
- 查看当前数据库中的所有表
show tables;
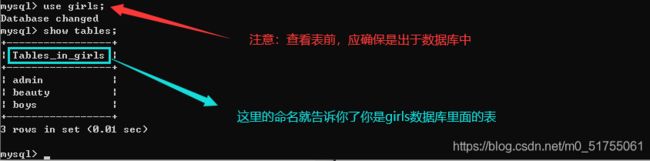
- 查看其它数据库的所有表
show tables from 库名;
说明:此处是当出于当前数据库下,但想查看其他数据库的表的情况
- 查看表结构:
- 方法一: desc 表名;
- 方法二: SHOW COLUMNS FROM 表名;
DESC student;
SHOW COLUMNS FROM student;
/* 这两种方式结果一模一样,第一种更常见,显然命令更短你也更愿意用 */
图形化结果类似于下图
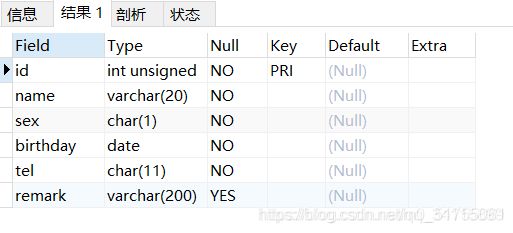
- 查看表内容
select * from 表名;
注意:*不可省略
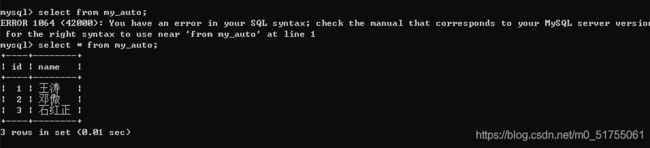
3.4.3 删除表
- 格式:drop table 表名;
drop table sort;
3.4.4 修改表结构格式
alter table 表名 add 列名 类型(长度) 约束;
- 作用:添加列
#1,为分类表添加一个新的字段为 分类描述 varchar(20)
ALTER TABLE sort ADD sdesc VARCHAR(20);
- 当然,想添加多个字段分类怎么做呢?
/*添加多个列方法一*/
ALTER TABLE student
ADD address VARCHAR(200) NOT NULL,
ADD home_tel CHAR(11) NOT NULL;
/*add语句之间用逗号分隔,最后用分号结束*/
/*添加多个列方法二*/
ALTER TABLE student
ADD (address VARCHAR(200) NOT NULL,home_tel CHAR(11) NOT NULL);
- 值得注意的是:
如果表需要添加多列,而有一列字段home_tel之前已经添加过了,结果会显示Duplicate column name ‘home_tel’,那么你本次添加的多列字段都是无效的,即全部添加失败
alter table 表名 modify 列名 类型(长度) 约束;
- 作用:修改列的类型长度及约束.
#2, 为分类表的分类名称字段进行修改,类型varchar(50) 添加约束 not null
ALTER TABLE sort MODIFY sname VARCHAR(50) NOT NULL; /* 添加约束NOT NULL */
ALTER TABLE student
MODIFY home_tel VARCHAR(20) NOT NULL; /*CHAR(11)修改为VARCHAR(200)*/
同理,和add类似,需要修改多个列的类型长度及约束,那么modify语句之间用逗号分隔,最后一句的末尾用分号结束。
alter table 表名 change 旧列名 新列名 类型(长度) 约束;
- 作用:修改列名
#3, 为分类表的分类名称字段进行更换 更换为 snamesname varchar(30)
ALTER TABLE sort CHANGE sname snamename VARCHAR(30);
同理,和add类似,需要修改多个列的字段名,那么change语句之间用逗号分隔,最后一句的末尾用分号结束。
直接来个例题:

假设有2个选项, 选择哪一个
-
A. ALTER TABLE cource CHANGE cname VARCHAR(30) NOT NULL FIRST;
-
B. ALTER TABLE cource MODIFY cname VARCHAR(30) NOT NULL FIRST;
请注意CHANGE和MODIFY的区别, MODIFY可以修改字段类型、字段属性,而CHANGE可修改字段名称,并且CHANGE需要旧列名和新列名,答案是B
alter table 表名 drop 列名;
- 作用:删除列
#4, 删除分类表中snamename这列
ALTER TABLE sort DROP snamename;
ALTER TABLE student
DROP home_address,
DROP home_tel;
同理,和add类似,需要删除多列,那么drop语句之间用逗号分隔,最后一句的末尾用分号结束。
rename table 表名 to 新表名;
- 作用:修改表名
#5, 为分类表sort 改名成 category
RENAME TABLE sort TO category;
alter table 表名 character set 字符集;
- 作用:修改表的字符集
#6, 为分类表 category 的编码表进行修改,修改成 gbk
ALTER TABLE category CHARACTER SET gbk;
第4章:字段属性
4.1 主键
- 主键: primary key,主要的键. 一张表只能有一个字段可以使用对应的键, 用来唯一的约束该字段里面的数据, 不能重复: 这种称之为主键.
- 一张表只能有最多一个主键, 主键请尽量使用整数类型而不是字符串类型
4.1.1增加主键
SQL操作中有多种方式可以给表增加主键: 大体分为三种.
- 方案1: 在创建表的时候,直接在字段之后,跟primary key关键字(主键本身不允许为空)
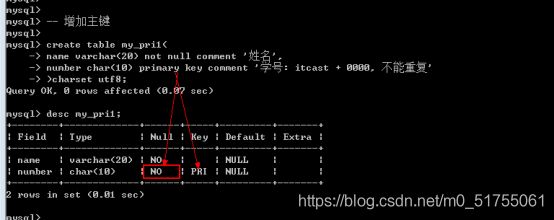
优点: 非常直接; 缺点: 只能使用一个字段作为主键 - 方案2: 在创建表的时候, 在所有的字段之后, 使用primary key(主键字段列表)来创建主键(如果有多个字段作为主键,可以是复合主键)
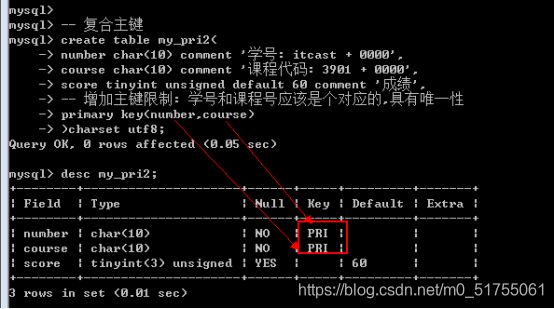
- 方案3: 当表已经创建好之后, 额外追加主键: 可以通过修改表字段属性, 也可以直接追加.
- Alter table 表名 add primary key(字段列表);
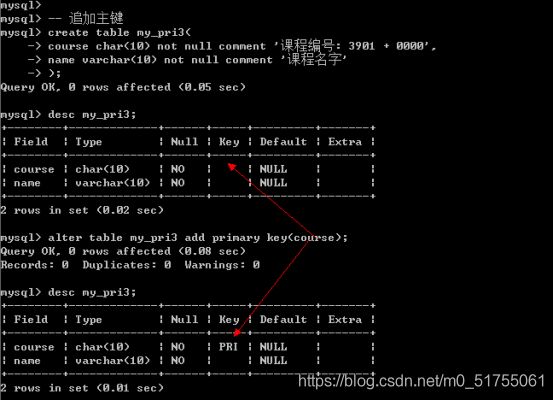
前提: 表中字段对应的数据本身是独立的(不重复)
4.1.2 主键约束
-
创建约束的目的就是保证数据的完整性和一致性。
-
主键对应的字段中的数据必须唯一,且不能为NULL, 一旦重复,数据操作失败(增和改)
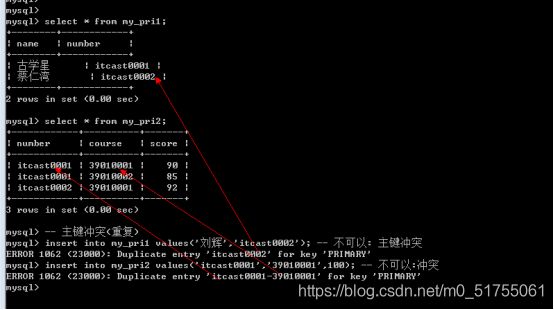
-
建议主键使用数字类型,因为数字的检索速度非常快,并且主键如果是数字类型,还可以设置自动增长。
-
主键的原理其实就是一个计数器。
4.1.3 更新主键 & 删除主键
没有办法更新主键: 主键必须先删除,才能增加
- Alter table 表名 drop primary key;
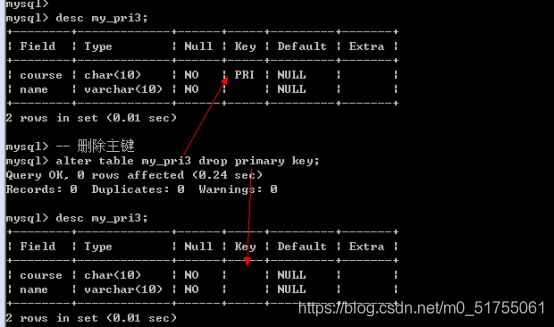
4.1.4 主键分类
在实际创建表的过程中, 很少使用真实业务数据作为主键字段(业务主键,如学号,课程号); 大部分的时候是使用逻辑性的字段(字段没有业务含义,值是什么都没有关系), 将这种字段主键称之为逻辑主键.
Create table my_student(
Id int primary key auto_increment comment ‘逻辑主键: 自增长’, -- 逻辑主键
Number char(10) not null comment ‘学号’,
Name varchar(10) not null
)
4.2 自动增长
-
自增长:
当对应的字段,不给值,或者说给默认值,或者给NULL的时候, 会自动的被系统触发, 系统会从当前字段中已有的最大值再进行+1操作,得到一个新的在不同的字段. -
自增长的字段必须定义为主键,默认起始值是1而不是0
4.2.1 新增自增长
自增长特点:
- 任何一个字段要做自增长必须前提是本身是一个索引(key一栏有值),auto_increment表示自动编号

- 自增长字段必须是数字(整型)
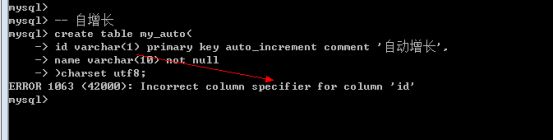
- 一张表最多只能有一个自增长
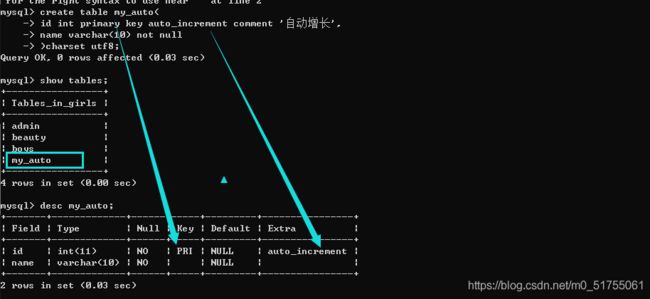
4.2.2 自增长使用
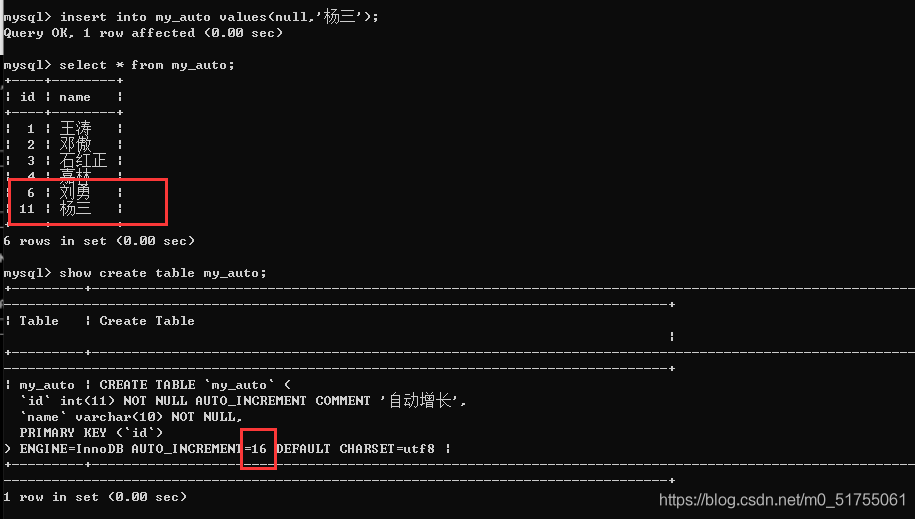
- 当自增长被给定的值为NULL或者默认值的时候会触发自动增长.
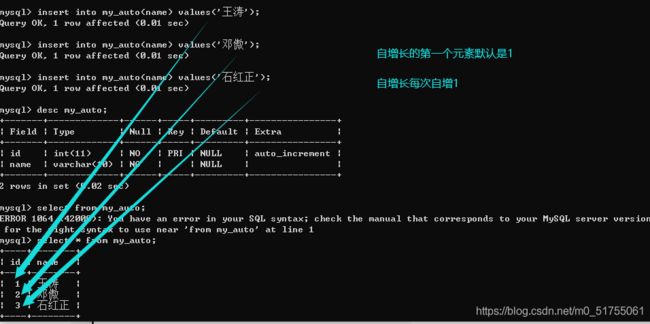
- 自增长如果对应的字段输入了值,那么自增长失效: 但是下一次还是能够正确的自增长(从最大值+1)
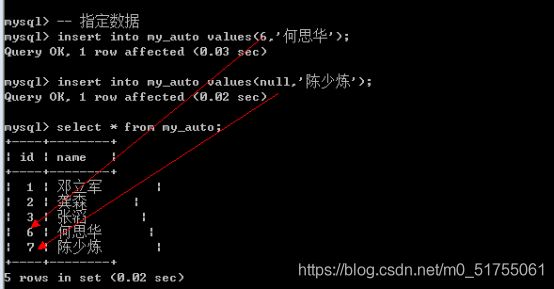
- 如何确定下一次是什么自增长呢? 可以通过查看表创建语句看到.
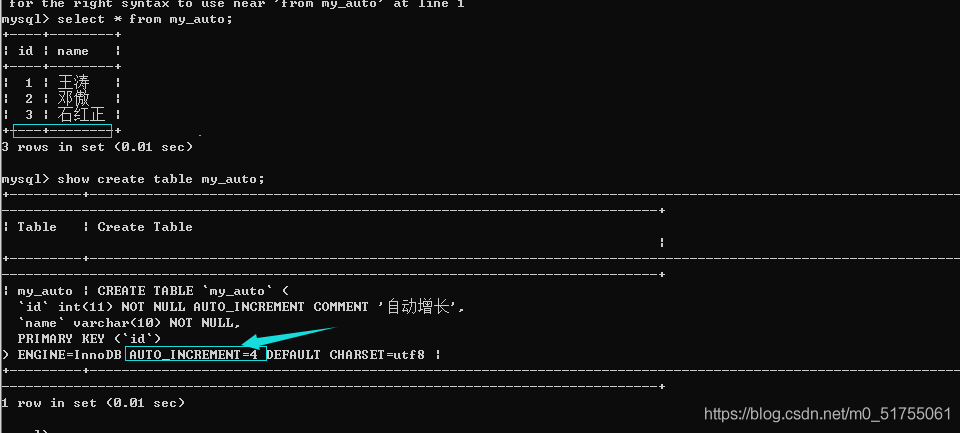
4.2.3 修改自增长?????
- 自增长如果是涉及到字段改变: 必须先删除自增长,后增加(一张表只能有一个自增长)
- 修改当前自增长已经存在的值: 修改只能比当前已有的自增长的最大值大,不能小(小不生效)
Alter table 表名 auto_increment = 值;
??????????
思考: 为什么自增长是从1开始?为什么每次都是自增1呢?
所有系统的变现(如字符集,校对集)都是由系统内部的变量进行控制的.
查看自增长对应的变量: show variables like ‘auto_increment%’;
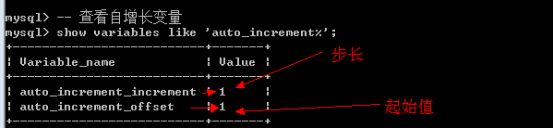
修改起始值和步长
- 可以修改变量实现不同的效果: 修改是对整个数据修改,而不是单张表: (修改是会话级)
- Set auto_increment_increment = 5; – 一次自增5

- 测试效果: 自动使用自增长
4.2.4 删除自增长
- 自增长是字段的一个属性: 可以通过modify来进行修改(保证字段没有auto_increment即可)
- Alter table 表名 modify 字段 类型;
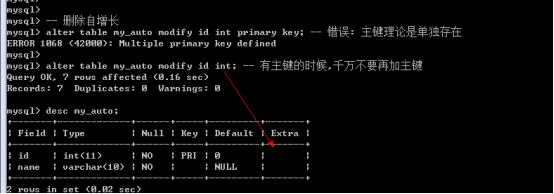
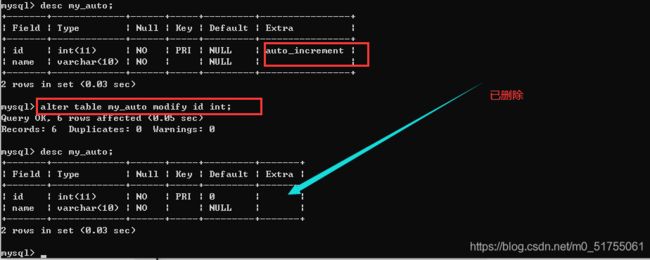
注意:
- alter table my_auto modify id int primary key;错误,主键理论是单独存在的
- 有主键的时候,千万不要再加主键
4.3 唯一键
一张表往往有很多字段需要具有唯一性,数据不能重复: 但是一张表中只能有一个主键: 唯一键(unique key)就可以解决表中有多个字段需要唯一性约束的问题.
唯一键的本质与主键差不多: 唯一键默认的允许自动为空,而且可以多个为空(空字段不参与唯一性比较)
4.3.1 增加唯一键
基本与主键差不多: 三种方案
- 方案1: 在创建表的时候,字段之后直接跟unique/ unique key
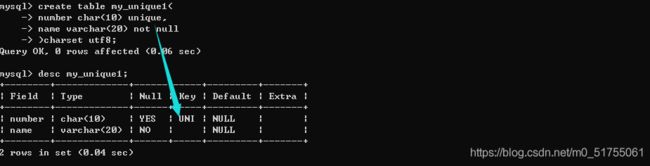
- 方案2: 在所有的字段之后增加unique key(字段列表); – 复合唯一键
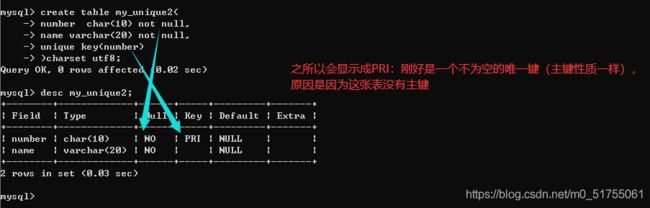
- 方案3: 在创建表之后增加唯一键
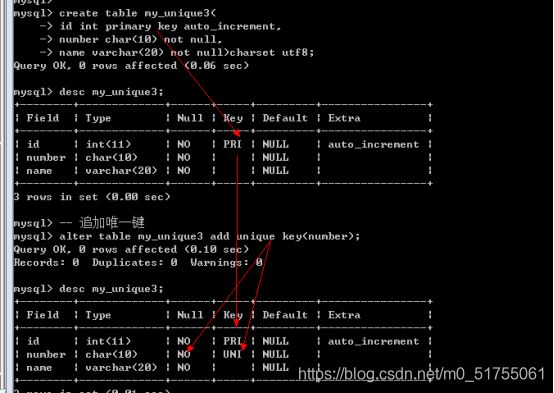
4.3.2 唯一键约束
唯一键与主键本质相同: 唯一的区别就是唯一键默认允许为空,而且是多个为空.
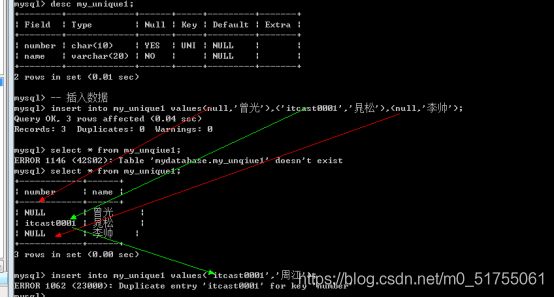
如果唯一键也不允许为空: 与主键的约束作用是一致的.
4.3.3 更新唯一键 & 删除唯一键
-
更新唯一键
- 先删除后新增(唯一键可以有多个: 可以不删除).
-
删除唯一键
-
Alter table 表名 drop unique key; – 错误: 唯一键有多个
-
Alter table 表名 drop index 索引名字; – 唯一键默认的使用字段名作为索引名字
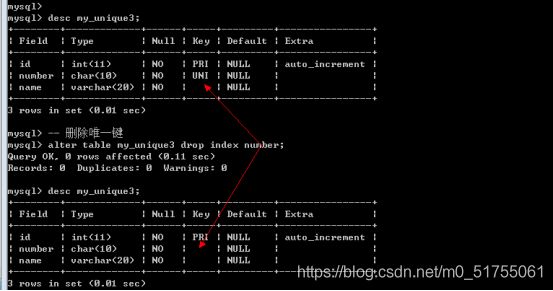
-
4.4 外键
4.4.2 新增外键
外键: foreign key, 外面的键(键不在自己表中): 如果一张表中有一个字段(非主键)指向另外一张表的主键,那么将该字段称之为外键.
- 创建表的时候增加外键: 在所有的表字段之后,
·- foreign key(外键字段) references 外部表(主键字段)
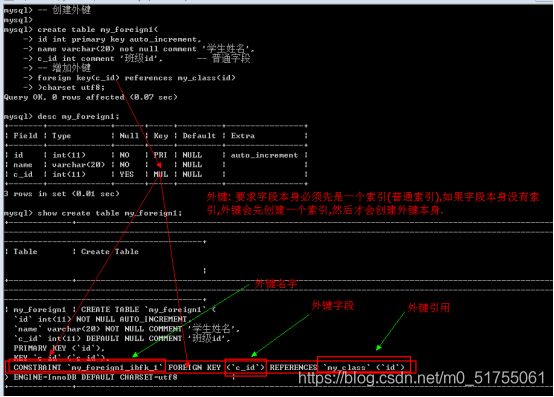
- 在新增表之后增加外键: 修改表结构
- Alter table 表名 add [constraint 外键名字] foreign key(外键字段) references 父表(主键字段);
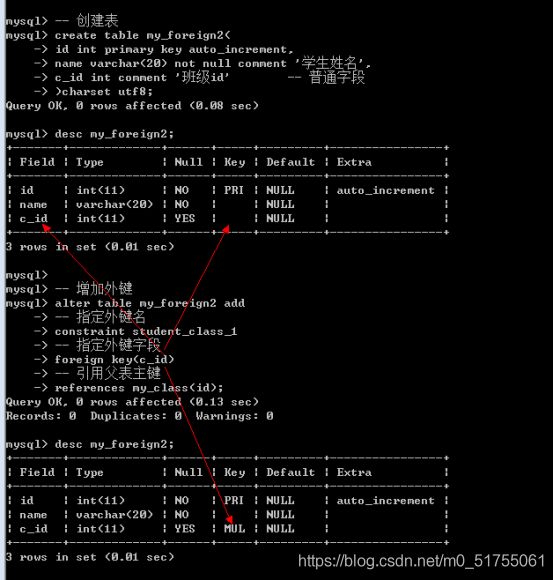
- Alter table 表名 add [constraint 外键名字] foreign key(外键字段) references 父表(主键字段);
4.4.2 修改外键&删除外键
-
外键不可修改
-
只能先删除后新增.
-
删除外键语法
- Alter table 表名 drop foreign key 外键名;
- 一张表中可以有多个外键,但是名字不能相同
-
外键删除不能通过查看表的结构体现,应通过查看表的创建语句查看(看图)
-
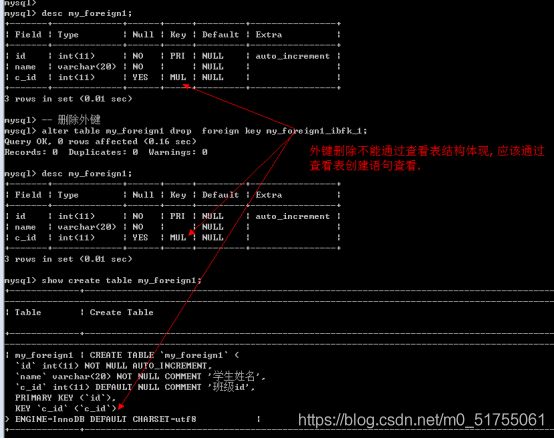
4.4.3 外键作用
外键默认的作用有两点: 一个对父表,一个对子表(外键字段所在的表)
- 对子表约束: 子表数据进行写操作(增和改)的时候, 如果对应的外键字段在父表找不到对应的匹配: 那么操作会失败.(约束子表数据操作)
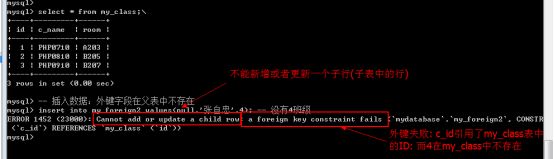
- 对父表约束: 父表数据进行写操作(删和改: 都必须涉及到主键本身), 如果对应的主键在子表中已经被数据所引用, 那么就不允许操作
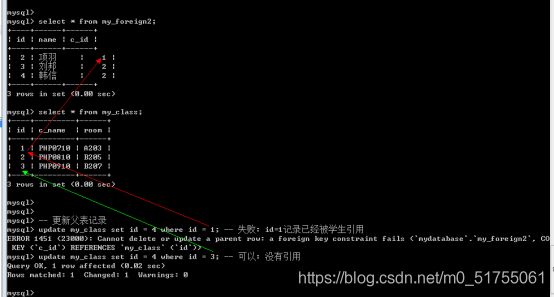
4.4.4 外键条件
- 1.外键要存在: 首先必须保证表的存储引擎是innodb(默认的存储引擎): 如果不是innodb存储引擎,那么外键可以创建成功,但是没有约束效果.
- 2.外键字段的字段类型(列类型)必须与父表的主键类型完全一致.
- 3.一张表中的外键名字不能重复.
- 4,增加外键的字段(数据已经存在),必须保证数据与父表主键要求对应.

4.4.5 外键约束(不推荐)
-
所谓外键约束: 就是指外键的作用.
-
之前所讲的外键作用: 是默认的作用; 其实可以通过对外键的需求, 进行定制操作.
-
需要注意的是:外键约束的定义是写在子表上的,但是不推荐使用外键约束
MySQL字段约束有四种,主键约束,非空约束,唯一约束,外键约束。外键约束是唯一不推荐的约束
- 提示:主键约束其实就是非空约束和唯一约束合二为一的情况
外键约束有三种约束模式: 都是针对父表的约束(子表约束父表)
-
District: 严格模式(默认的), 父表不能删除或者更新一个已经被子表数据引用的记录
-
Cascade: 级联模式: 父表的操作, 对应子表关联的数据也跟着被更新
-
Set null: 置空模式: 父表的操作之后,子表对应的数据(外键字段)被置空
通常的一个合理的做法(约束模式): 删除的时候子表置空, 更新的时候子表级联操作
指定模式(约束模式)的语法
Foreign key(外键字段) references 父表(主键字段) on delete set null on update cascade;
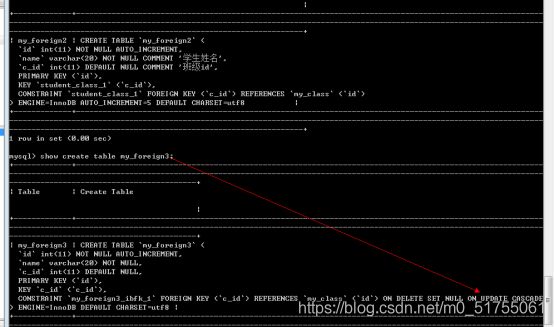
-
更新操作: 级联更新
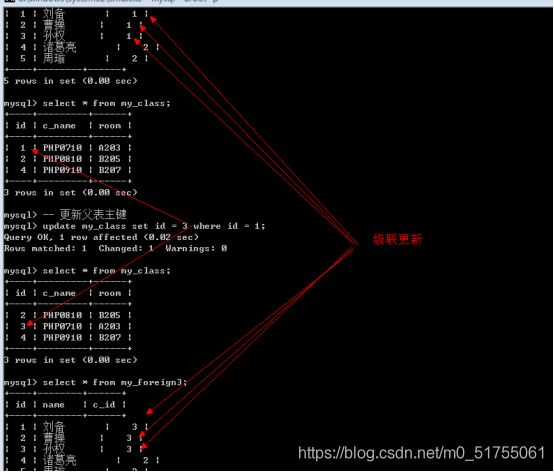
- 更新主键数字语法:
update 表名 set 字段 = 数字(修改后) where 字段 = 1(修改前);
- 更新主键数字语法:
-
删除操作: 置空
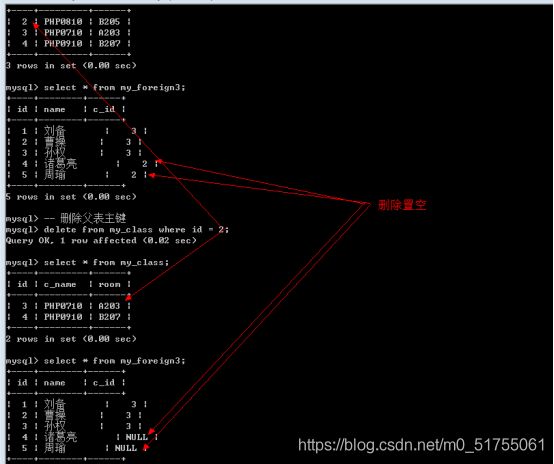
-
删除置空的前提条件: 外键字段允许为空(如果不满足条件,外键无法创建)
-
外键虽然很强大, 能够进行各种约束: 但是对于PHP来讲, 外键的约束降低了PHP对数据的可控性: 通常在实际开发中, 很少使用外键来处理.
-
4.4.6 创建外键约束的要求
创建外键约束的目的是保持数据一致性和完整性,以及实现一对一或者一对多的关系。
创建外键约束要求有以下几点:
-
父表和子表必须使用相同的存储引擎,而且禁止使用临时表。
注意:具有外键列的表称为子表;子表所参照的表称为父表。 -
数据表的存储引擎只能是InnoDB。
-
外键列和参照列必须具有相似的数据类型。其中数字的长度或是否有符号位必须相同;而字符的长度则可以不同。
注意:加 FOREIGN KEY 关键字的列称为外键列;外键列所参照的列称为参照列。 -
外键列和参照列必须创建索引。如果外键列不存在索引的话,MySQL将自动创建索引。如果参照列不存在索引的话,MySQL不会自动创建索引。
注意:MySQL会为主键自动创建索引。
4.4.7 外键约束的闭环问题
比如说我们创建了2张表
/*先创建父表*/
CREATE TABLE t_dept(
deptno INT UNSIGNED PRIMARY KEY,
dname VARCHAR(20) NOT NULL UNIQUE,
tel CHAR(4) UNIQUE
)
/*再创建子表*/
CREATE TABLE t_emp(
empno INT UNSIGNED PRIMARY KEY,
ename VARCHAR(20) NOT NULL,
sex ENUM("男", "女") NOT NULL,
deptno INT UNSIGNED NOT NULL,
hiredate DATE NOT NULL,
FOREIGN KEY (deptno) REFERENCES t_dept(deptno)
);
父表t_dept加一个数据如下:

子表t_emp加一个数据如下:

此时我想删除父表的数据,结果报错

结果发现有子表t_emp外键约束着父表,删除失败。必须先删除子表的约束数据才能删除父表的数据,那这样就失去了增减改查的灵活性了,并且更严重的是,
如果形成外键闭环,我们将无法删除任何一张表的数据记录。
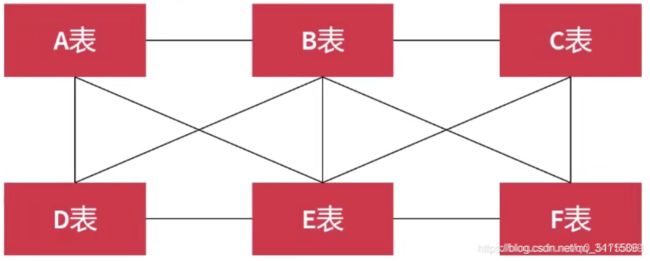
如上图,A约束B,B约束C…,这样每一个表都算作父表,所谓的先删除子表的数据就是不可能的。因为有外键闭环的存在,所以我们不推荐外键约束
4.5 索引
-
几乎所有的索引都是建立在字段之上.
-
索引: 系统根据某种算法, 将已有的数据(未来可能新增的数据),单独建立一个文件: 文件能够实现快速的匹配数据, 并且能够快速的找到对应表中的记录.
4.5.1 创建索引
建表的时候创建索引,也可以在已存在的表上添加索引。
CREATE TABLE 表名称(
......,
INDEX [索引名称] (字段),
......
);
//举例
CREATE TABLE t_message(
id INT UNSIGNED PRIMARY KEY,
content VARCHAR(200) NOT NULL,
type ENUM("公告", "通报", "个人通知") NOT NULL,
create_time TIMESTAMP NOT NULL,
INDEX idx_type (type)
);
4.5.2 添加索引
向已存在的表中添加索引的方式如下
-
CREATE INDEX 索引名称 ON 表名(字段); /添加索引方式1/
-
ALTER TABLE 表名 ADD INDEX 索引名称(字段); /添加索引方式2/
CREATE INDEX idx_type ON t_message(type); /*添加索引方式1*/
ALTER TABLE t_message ADD INDEX idx_type(type);/*添加索引方式2*/
经常被用来做检索条件的字段需要加上索引,内部是二叉树,所以查询很快。如果是几千条数据,不必加索引,全盘检索也很快
4.5.3 查询索引
- SHOW INDEX FROM 表名;
/*查看t_message表的索引*/
SHOW INDEX FROM t_message;
查出来如下,有添加的普通索引和主键索引
![]()
4.5.4 删除索引
- DROP INDEX 索引名称 ON 表名;
/* 在t_message表中删除idx_type索引 */
DROP INDEX idx_type ON t_message;
4.5.5 索引的使用原则
-
数据量很大,且经常被查询的数据表可以设置索引 (即读多写少的表可以设置索引)
-
索引只添加在经常被用作检索条件的字段上 (比如电子商城需要在物品名称关键字加索引)
-
不要在大字段上创建索引 (比如长度很长的字符串不适合做索引,因为查找排序时间变的很长)
4.5.6 索引的意义
- 提升查询数据的效率
- 约束数据的有效性(唯一性等)
- 增加索引的前提条件: 索引本身会产生索引文件(有时候有可能比数据文件还大) ,会非常耗费磁盘空间.
- 如果某个字段需要作为查询的条件经常使用, 那么可以使用索引(一定会想办法增加);
- 如果某个字段需要进行数据的有效性约束, 也可能使用索引(主键,唯一键)
Mysql中提供了多种索引
- 主键索引: primary key
- 唯一索引: unique key
- 全文索引: fulltext index
- 普通索引: index
- 全文索引: 针对文章内部的关键字进行索引
- 全文索引最大的问题: 在于如何确定关键字
第5章:关系
将实体与实体的关系, 反应到最终数据库表的设计上来: 将关系分成三种: 一对一, 一对多(多对一)和多对多.
所有的关系都是指的表与表之间的关系.
5.1 一对一
一对一: 一张表的一条记录一定只能与另外一张表的一条记录进行对应; 反之亦然.
举例:
学生表: 姓名,性别,年龄,身高,体重,婚姻状况, 籍贯, 家庭住址,紧急联系人

表设计成以上这种形式: 符合要求. 其中姓名,性别,年龄,身高,体重属于常用数据; 但是婚姻,籍贯,住址和联系人属于不常用数据. 如果每次查询都是查询所有数据,不常用的数据就会影响效率, 实际又不用.
解决方案: 将常用的和不常用的信息分离存储,分成两张表
- 常用信息表

- 不常用信息表:
- 保证不常用信息与常用信息一定能够对应上: 找一个具有唯一性(确定记录)的字段来共同连接两张表

一个常用表中的一条记录: 永远只能在一张不常用表中匹配一条记录;反过来,一个不常用表中的一条记录在常用表中也只能匹配一条记录: 一对一的关系
5.2 一对多
一对多: 一张表中有一条记录可以对应另外一张表中的多条记录; 但是返回过, 另外一张表的一条记录只能对应第一张表的一条记录. 这种关系就是一对多或者多对一.
母亲与孩子的关系: 母亲,孩子两个实体
- 妈妈表

- 孩子表

以上关系: 一个妈妈可以在孩子表中找到多条记录(也有可能是一条); 但是一个孩子只能找到一个妈妈: 是一种典型的一对多的关系.
但是以上设计: 解决了实体的设计表问题, 但是没有解决关系问题: 孩子找不出妈,妈也找不到孩子.
解决方案: 在某一张表中增加一个字段,能够找到另外一张表的中记录: 应该在孩子表中增加一个字段指向妈妈表: 因为孩子表的记录只能匹配到一条妈妈表的记录.
- 妈妈表

- 孩子表

5.3多对多
多对多: 一张表中(A)的一条记录能够对应另外一张表(B)中的多条记录; 同时B表中的一条记录也能对应A表中的多条记录: 多对多的关系
老师教学: 老师和学生
-
老师表
-
学生表
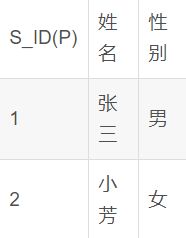
以上设计方案: 实现了实体的设计, 但是没有维护实体的关系.
一个老师教过多个学生; 一个学生也被多个老师教过.
解决方案: 在学生表中增加老师字段: 不管在哪张表中增加字段, 都会出现一个问题: 该字段要保存多个数据, 而且是与其他表有关系的字段, 不符合表设计规范: 增加一张新表: 专门维护两张表之间的关系
- 中间关系表: 老师与学生的关系

增加中间表之后: 中间表与老师表形成了一对多的关系: 而且中间表是多表,维护了能够唯一找到一表的关系; 同样的,学生表与中间表也是一个一对多的关系: 一对多的关系可以匹配到关联表之间的数据.
学生找老师: 找出学生id -> 中间表寻找匹配记录(多条) -> 老师表匹配(一条)
老师找学生: 找出老师id -> 中间表寻找匹配记录(多条) -> 学生表匹配(一条)
第6章:范式
-
范式: Normal Format, 是一种离散数学中的知识, 是为了解决一种数据的存储与优化的问题: 保存数据的存储之后, 凡是能够通过关系寻找出来的数据,坚决不再重复存储: 终极目标是为了减少数据的冗余.
-
范式: 是一种分层结构的规范, 分为六层: 每一次层都比上一层更加严格: 若要满足下一层范式,前提是满足上一层范式.
-
六层范式: 1NF,2NF,3NF…6NF, 1NF是最底层,要求最低;6NF最高层,最严格.
-
Mysql属于关系型数据库: 有空间浪费: 也是致力于节省存储空间: 与范式所有解决的问题不谋而合: 在设计数据库的时候, 会利用到范式来指导设计.
-
但是数据库不单是要解决空间问题,要保证效率问题: 范式只为解决空间问题, 所以数据库的设计又不可能完全按照范式的要求实现: 一般情况下,只有前三种范式需要满足.
-
范式在数据库的设计当中是有指导意义: 但是不是强制规范.
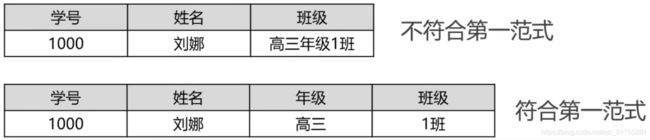
6.1 1NF(第一范式)
-
第一范式: 在设计表存储数据的时候, 如果表中设计的字段存储的数据,在取出来使用之前还需要额外的处理(拆分),那么说表的设计不满足第一范式。
-
第一范式要求字段的数据具有原子性: 不可再分.
-
第一范式是数据库的基本要求,不满足第一范式就不是关系型数据库
让我们简单化这个问题:
1NF—原子性
- eg1:
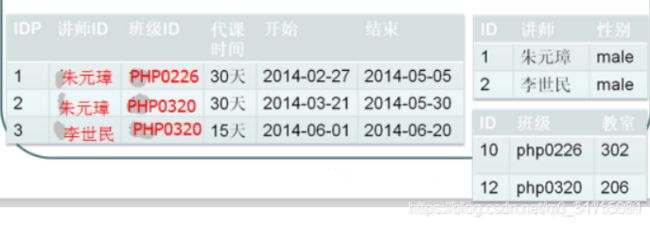
数据表的每一列都是不可分割的基本数据项,同一列中不能有多个值,也不能存在重复的属性。 - eg2:讲师代课表
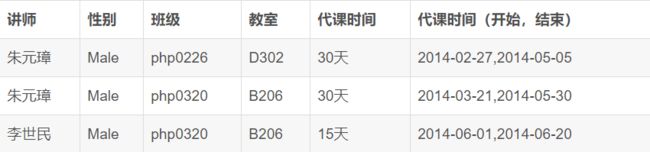
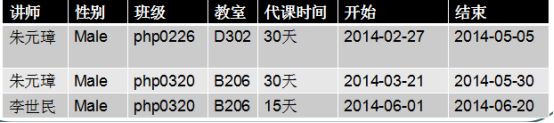
上表设计不存在问题: 但是如果需求是将数据查出来之后,要求显示一个老师从什么时候开始上课,到什么时候节课: 需要将代课时间进行拆分: 不符合1NF, 数据不具有原子性, 可以再拆分.
解决方案: 将代课时间拆分成两个字段就解决问题.
6.2 2NF(第二范式)???
第二范式: 在数据表设计的过程中,如果有复合主键(多字段主键), 且表中有字段并不是由整个主键来确定, 而是依赖主键中的某个字段(主键的部分): 存在字段依赖主键的部分的问题, 称之为部分依赖: 第二范式就是要解决表设计不允许出现部分依赖.
定义太绕了,简单点:2NF—唯一性
- eg1:
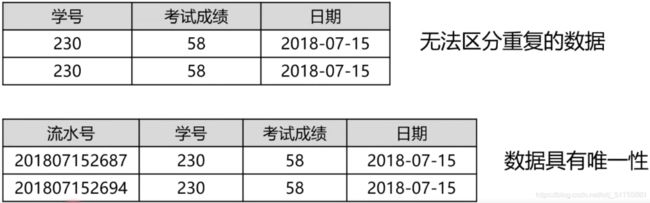
学号为230的学生在2018-07-15考试第一次58没及格,然后当天补考第二次还是58没及格,于是数据库就有了重复的数据。解决办法就是添加一个流水号,让数据变得唯一。
- eg2:讲师带课表??????

以上表中: 因为讲师没有办法作为独立主键, 需要结合班级才能作为主键(复合主键: 一个老师在一个班永远只带一个阶段的课): 代课时间,开始和结束字段都与当前的代课主键(讲师和班级): 但是性别并不依赖班级, 教室不依赖讲师: 性别只依赖讲师, 教室只依赖班级: 出现了性别和教室依赖主键中的一部分: 部分依赖.不符合第二范式.
解决方案1: 可以将性别与讲师单独成表, 班级与教室也单独成表.
解决方案2: 取消复合主键, 使用逻辑主键

ID = 讲师 + 班级(业务逻辑约束: 复合唯一键)
6.3 3NF(第三范式)
要满足第三范式,必须满足第二范式
第三范式: 理论上讲,应该一张表中的所有字段都应该直接依赖主键(逻辑主键: 代表的是业务主键), 如果表设计中存在一个字段, 并不直接依赖主键,而是通过某个非主键字段依赖,最终实现依赖主键: 把这种不是直接依赖主键,而是依赖非主键字段的依赖关系称之为传递依赖. 第三范式就是要解决传递依赖的问题.
定义很绕,我们简单点:3NF—关联性
每列都与主键有直接关系,不存在传递依赖
- eg1:
根据主键爸爸能关联儿子女儿,但是女儿的玩具、衣服都不是依赖爸爸的,而是依赖女儿的,这些东西不是与爸爸有直接关系,所以拆分两个表。
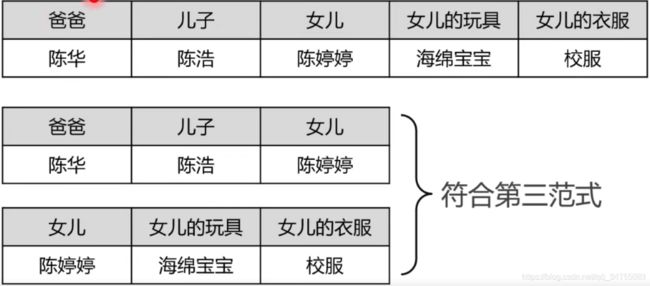
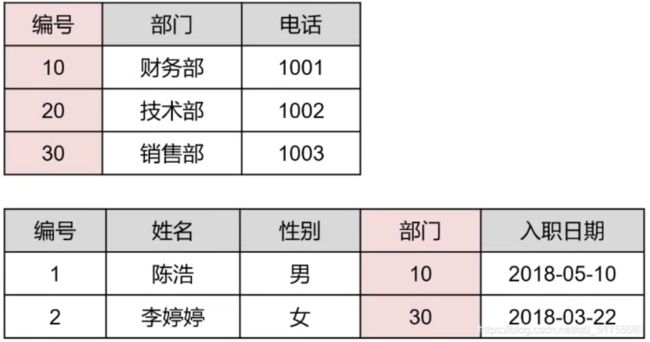
满足第三范式后,检索、提取数据非常方便,如果不满足,虽然表也能建成功,但是检索就会花费很多时间,比如如果是第一个表,逻辑上要找女儿的衣服,去查找女儿是找不到的,此时女儿不是主键。数据表拆分之后,根据主键列女儿陈婷婷,可以很快的找到女儿的衣服校服。主键查找是很快的。
依照第三范式,数据可以拆分到不同的数据表,彼此保持关联
- eg2:讲师带课表

以上设计方案中: 性别依赖讲师存在, 讲师依赖主键; 教室依赖班级,班级依赖主键: 性别和教室都存在传递依赖.
解决方案: 将存在传递依赖的字段,以及依赖的字段本身单独取出,形成一个单独的表, 然后在需要对应的信息的时候, 使用对应的实体表的主键加进来.
讲师表

讲师表: ID = 讲师
班级表
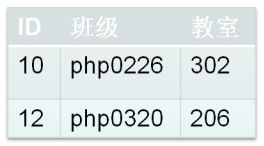
班级表中: ID = 班级
6.4 逆规范化
有时候, 在设计表的时候,如果一张表中有几个字段是需要从另外的表中去获取信息. 理论上讲, 的确可以获取到想要的数据, 但是就是效率低一点. 会刻意的在某些表中,不去保存另外表的主键(逻辑主键), 而是直接保存想要的数据信息: 这样一来,在查询数据的时候, 一张表可以直接提供数据, 而不需要多表查询(效率低), 但是会导致数据冗余增加.
如讲师代课信息表
逆规范化: 磁盘利用率与效率的对抗
第7章:数据高级操作(增、删、改、查)
7.1 新增数据
基本语法
Insert into 表名 [字段1,字段2,......] values (值1,值2,......); /*插入单条记录*/
Insert into 表名 [字段1,字段2,......] values (值1,值2,......), (值1,值2,......); /*插入多条记录*/
表名后面不写字段列表也可以插入数据,但是会影响速度。Mysql会进行词法分析,找到对应表结构,然后自动给你补上字段列表。所以表名后面不写字段列表,数据库难以高效的操作。
INSERT INTO t_dept(deptno, dname, loc)
VALUES(50, "技术部", "北京");
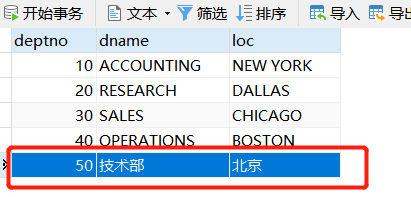
INSERT INTO t_dept(deptno, dname, loc)
VALUES(60, "后勤部", "北京"),(70,"保安部","北京");
eg:向技术部添加一条员工记录
分析:测验insert语句里面子查询的问题,并且这个子查询是单行子查询,不能是多行子查询,还必须是单行单列的。
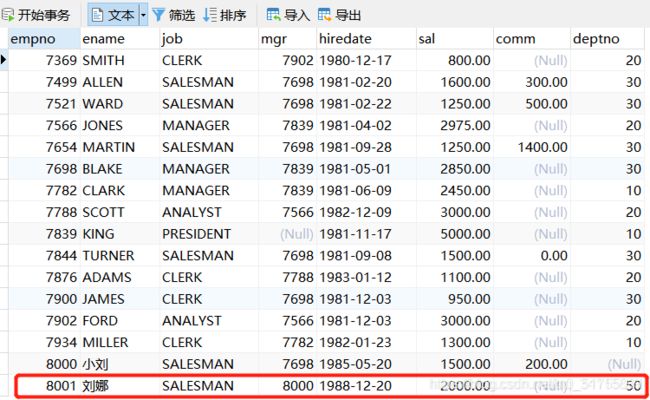
INSERT INTO t_emp
(empno, ename, job, mgr, hiredate, sal, comm, deptno)
VALUES(8001, "刘娜", "SALESMAN", 8000, "1988-12-20", 2000, NULL,
(SELECT deptno FROM t_dept WHERE dname="技术部"));
INSERT语句方言
MySQL的INSERT语句还有一种方言语法
INSERT INTO 表名 SET 字段1=值1, 字段2=值2......
为什么称之为方言语法呢?就是因为这个语法只能在MySQL使用,不能在Oracle使用,当然你只用MySQL就可以使用这种方言语法,很简洁。
INSERT INTO t_emp
SET empno=8002,ename="JACK",job="SALESMAN",mgr=8000,
hiredate="1985-3-14",sal=2500,comm=NULL,deptno=50;
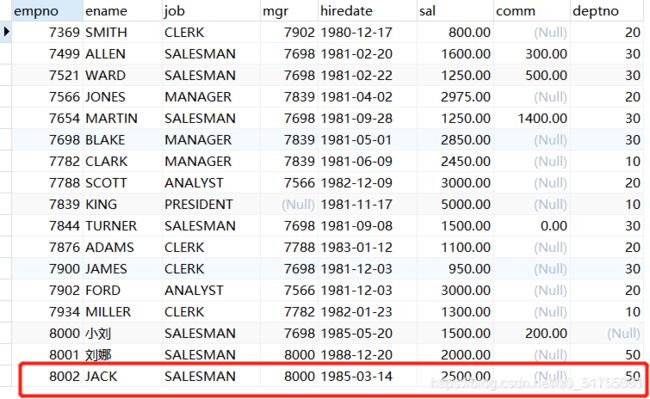
在数据插入的时候, 假设主键对应的值已经存在: 插入一定会失败!
7.1.1 IGNORE关键字
IGNORE关键字只会插入数据库不存在的记录。比如主键冲突、唯一性冲突,数据库会报错,加上IGNORE之后数据库会忽略这条数据不会报错。
简单点就是,没加IGNORE关键字前,加入已经存在的记录(主键等,具有唯一新的字符),会报错。加IGNORE关键字后,不会报错,直接忽略此条错误数据,把其他正常数据加入表中
INSERT [IGNORE] INTO 表名 ......;
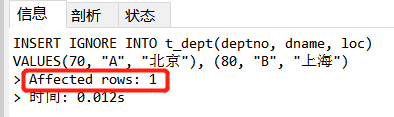
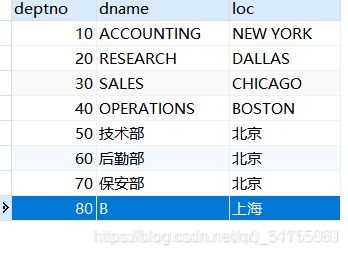
INSERT IGNORE INTO t_dept(deptno, dname, loc)
VALUES(70, "A", "北京"), (80, "B", "上海"); /*70部门已经存在*/
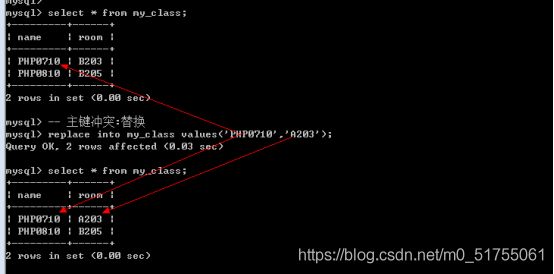
7.1.2 主键冲突
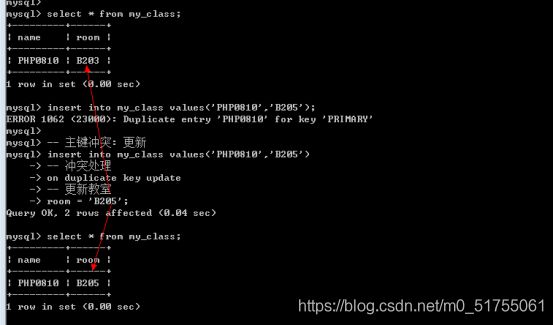
当主键存在冲突的时候(Duplicate key),你可以添加ignore关键字选择忽略,数据库不会报错,但是确实非得添加这个记录怎么办呢?可以选择性的进行处理: 更新和替换
主键冲突:更新操作
- Insert into 表名[(字段列表:包含主键)] values(值列表) on duplicate key update 字段 = 新值;
主键冲突: 替换
- Replace into 表名 [(字段列表:包含主键)] values(值列表);
7.1.3 蠕虫复制
蠕虫复制: 从已有的数据中去获取数据,然后将数据又进行新增操作: 数据成倍的增加.
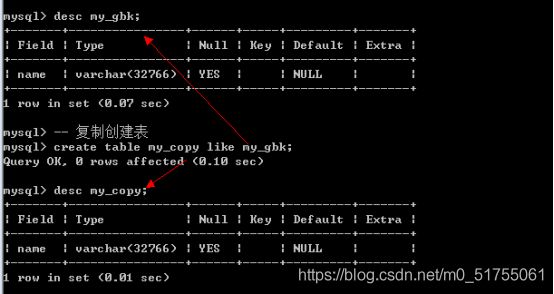
表创建高级操作: 从已有表创建新表(复制表结构)
- Create table 表名 like 数据库.表名;
蠕虫复制: 先查出数据, 然后将查出的数据新增一遍
- Insert into 表名[(字段列表)] select 字段列表/* from 数据表名;
举例:创建表test1 和 test2:
-- test1
create table test1(
id int not null primary key auto_increment,
name varchar(20),
gender int(1) default 0,
age int(2) not null);
-- test2//复制表结构
create table test2 like test1;
- 向test1 插入一条数据
insert into test1 values(default, 'tom', default, 18);
- 此时test1 有一条记录,test2 没有记录。
对test2 进行蠕虫复制:
- 1)从test1 获取原始数据(test1 和test2 的表结构必须相同)。
insert into test2 select * from test1;
此时,test2 记录数为 1
- 2)test2 蠕虫复制操作
INSERT INTO test2 SELECT * FROM test2;
你会发现报错:
mysql> insert into test2 select * from test2;
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
原因就是主键冲突,解决办法,不复制主键:
insert into test2(name,gender,age) select name,gender,age from test2;
此时,test2 记录数为2。
…
重复操作,记录数数量从 1-2-4-8-16-32-64…增长。
例如:
mysql> insert into test2(name,gender,age) select name,gender,age from test2;
Query OK, 1 row affected (0.01 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> insert into test2(name,gender,age) select name,gender,age from test2;
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> insert into test2(name,gender,age) select name,gender,age from test2;
Query OK, 4 rows affected (0.01 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> insert into test2(name,gender,age) select name,gender,age from test2;
Query OK, 8 rows affected (0.01 sec)
Records: 8 Duplicates: 0 Warnings: 0
mysql> insert into test2(name,gender,age) select name,gender,age from test2;
Query OK, 16 rows affected (0.01 sec)
Records: 16 Duplicates: 0 Warnings: 0
mysql> select count(*) from test2;
+----------+
| count(*) |
+----------+
| 32 |
+----------+
1 row in set (0.01 sec)
所以,若表有主键并且有自增长,那不复制主键的值即可。
还有一种,主键没有自增长,那不复制主键可以吗?答案是不行。因为主键的前提是不能为空,赋值则发生主键冲突,不赋值则引发非空约束
蠕虫复制的意义
- 从已有表拷贝数据到新表中
- 可以迅速的让表中的数据膨胀到一定的数量级: 测试表的压力以及效率
7.2 更新数据
基本语法
UPDATE [IGNORE] 表名 SET 字段1=值1, 字段2=值2, ......
[WHERE 条件1 ......]
[ORDER BY ......]
[LIMIT ......];
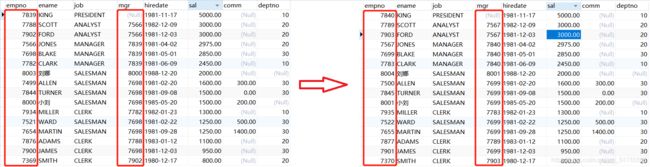
eg1:把每个员工的编号和他上司的编号+1,用order by子句完成
UPDATE t_emp SET empno=empno+1, mgr=mgr+1
ORDER BY empno DESC;
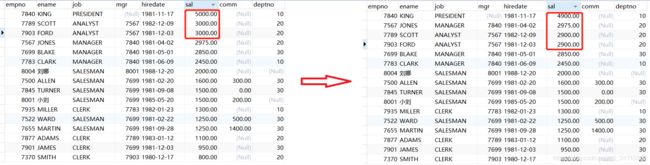
eg2:把月收入前三名的员工底薪减100元,用LIMIT子句完成
UPDATE t_emp
SET sal=sal-100
ORDER BY sal+IFNULL(comm,0) DESC
LIMIT 3;
eg3:把10部门中,工龄达到20年的员工,底薪增加200元
UPDATE t_emp
SET sal=sal+200
WHERE deptno=10 AND DATEDIFF(NOW(),hiredate)/365 >= 20
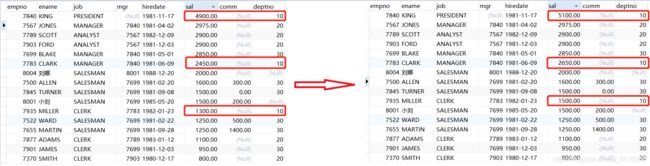
7.2.1 UPDATE语句中的内连接?????
7.2.2 UPDATE语句中的外连接?????
7.3 删除数据
基本语法
DELETE [IGNORE] FROM 表名
[WHERE 条件1, 条件2, ...]
[ORDER BY ...]
[LIMIT ...];
子句执行顺序:FROM -> WHERE -> ORDER BY -> LIMIT -> DELETE
ignore表示删除失败就直接忽略而不是报错。
eg1:删除10部门中,工龄超过20年的员工记录
DELETE from t_emp
WHERE deptno=10 AND DATEDIFF(NOW(),hiredate)/365 >20;
eg2:删除20部门中工资最高的员工记录
DELETE FROM t_emp
WHERE deptno=20
ORDER BY sal+IFNULL(comm,0) DESC
LIMIT 1;
提示:如果表中存在主键自增长,那么当删除之后, 自增长不会还原,下一条数据记录插入会在上一次计数的基础继续增加
7.3.1 DELETE语句中的内连接???
-
DELETE语句是在事务机制下删除记录,删除记录之前,先把要删除的记录保存到日志文件里,然后再删除记录。
-
TRUNCATE语句在事务机制之外删除记录,速度远超过DELETE语句。
7.3.2 DELETE语句中的外连接???
7.3.3 快速删除数据表全部记录
DELETE语句是在事务机制下删除记录,删除记录之前,先把要删除的记录保存到日志文件里,然后再删除记录。
TRUNCATE语句在事务机制之外删除记录,速度远超过DELETE语句。
-
方法一:使用 delete from [表名] 生成日志
-
方法二:使用 truncate table [表名] 无日志生成
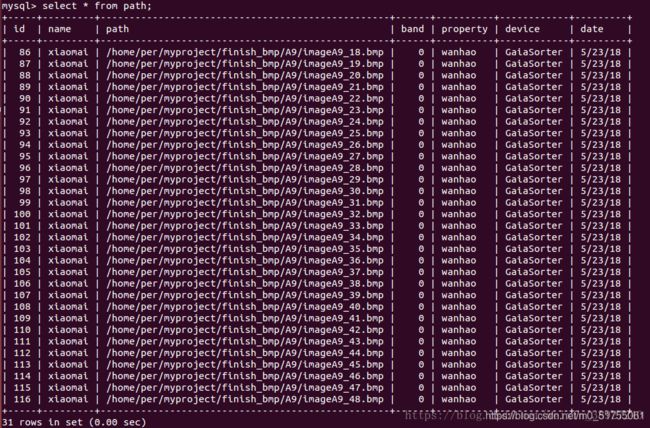
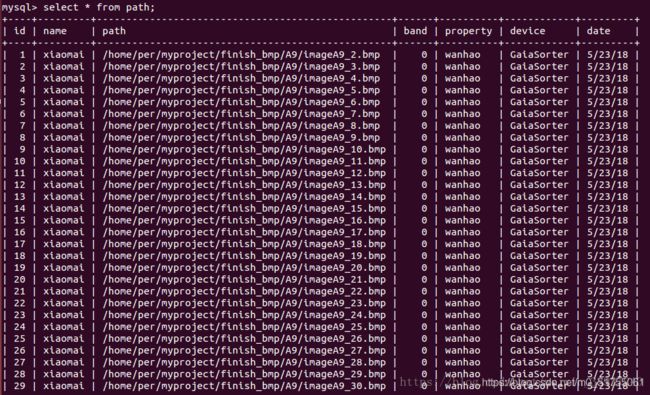
注意:两种方式删除后再插入数据,第一条id的值不一样
方法一:删除后再插入数据
方法二:删除后再插入数据
7.4 查询数据
7.4.1 Select语句
最基本的查询语句就是SELECT和FROM关键字组成,SELECT语句屏蔽了物理层的操作,用户不必关系数据的真实存储,交互由数据库高效的查询数据。
-
All或者*: 默认保留所有的结果
-
Distinct: 去重, 查出来的结果,将重复给去除(所有字段都相同)
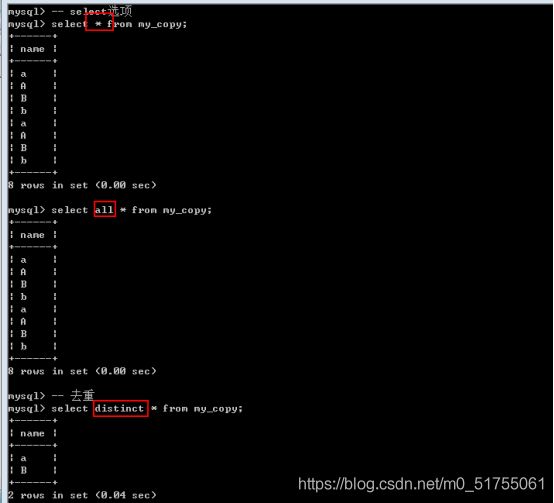
注意点:
- 1.distinct关键字只能在select子句中使用一次,写2个distinct直接报错

- 2.distinct关键字只能写在select子句的第一个字段前面,否则报错,若有多个字段,则distinct失效。
SELECT job, DISTINCT ename FROM t_emp;
/* distinct写在第二个字段前面 */
 distinct没有写在第一个字段前面,结果直接报错
distinct没有写在第一个字段前面,结果直接报错
- 3.若有多个字段,即使写在第一个字段前面,distinct也失效。
若有多个字段,即使写在第一个字段前面,distinct也失效。
SELECT DISTINCT job, ename FROM t_emp;
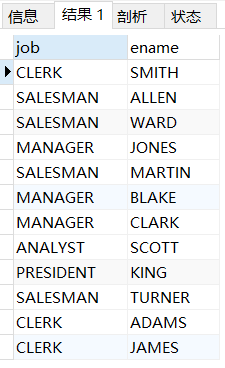
job并没有想象中的去重,distinct失效了,因为针对了你的所有字段,只要有一个字段不同就算是不同,所以distinct失效了。
4.综上1、2所述,distinct只能存在于select子句查询一个字段的情况,否则要么失效,要么语法报错。
7.4.3 字段别名
字段别名: 当数据进行查询出来的时候, 有时候名字并不一定就满足需求(多表查询的时候, 会有同名字段). 需要对字段名进行重命名: 别名
语法:字段名 [as] 别名;
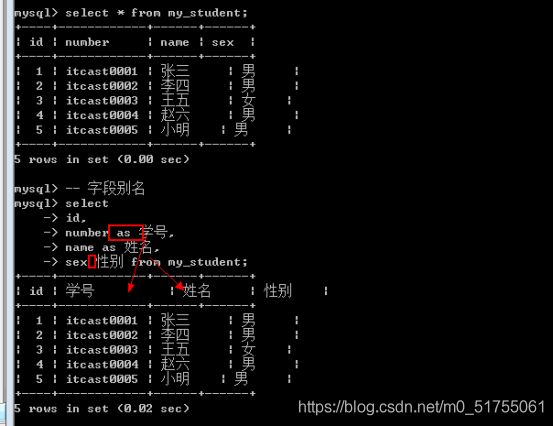
-
这查询的结果集修改了字段,并不会修改底层数据表的字段
-
小细节:查询语句的执行顺序是先词法分析与优化,读取SQL语句,然后FROM子句选择数据来源,最后SELECT子句选择输出内容
7.4.4 数据源
数据源: 数据的来源, 关系型数据库的来源都是数据表。本质上只要保证数据类似二维表,最终都可以作为数据源。
数据源分为多种: 单表数据源, 多表数据源, 查询语句
7.4.5 Where子句
-
Where子句: 用来判断数据,筛选数据.
-
Where子句返回结果: 0或者1, 0代表false,1代表true.
-
语法格式
SELECT ... FROM ... WHERE 条件 [AND | OR] 条件 ......;
-
判断条件:
-
比较运算符: >, <, >=, <= ,!= ,<>, =, like, between and, in/not in
-
逻辑运算符: &&(and), ||(or), !(not)
-
Where原理:
- where是唯一一个直接从磁盘获取数据的时候就开始判断的条件语句,从磁盘取出一条记录, 开始进行where判断。判断结果如果成立则保存到内存,失败直接放弃.
注意点:
- 扩展:其中IFNULL(comm, 0)表示如果comm为null,则返回0
- DATEDIFF(NOW(),hiredate)表示当前时间减去入职时间hiredate的天数。
- WHERE子句中,条件执行的顺序是从左到右的。所以我们应该把索引条件或者筛选掉记录最多的条件写在最左侧。因为索引查询速度快,筛选记录最多的条件更容易触发短路语句的效果,这样就无须执行后续条件就能完成查询。
7.4.6 聚合函数
聚合函数在数据查询分析中,应用十分广泛。聚合函数可以对数据求和、求最大值和最小值、求平均值等等。
比如SQL提供了如下聚合函数
-
Count(): 统计分组后的的记录数: 每一组有多少记录
- count(*)用于获得包含空值的记录数
- count(列名)用于获得包含非空值的记录数
-
Max(): 统计每组中非空的最大值
-
Min(): 统计非空的最小值
-
Avg(): 统计平均值
-
Sum(): 统计和
注意:聚合函数永远不可能出现在where子句里,一定会报错
7.4.7 Group by子句
为什么要分组呢?因为默认情况下汇总函数是对全表范围内的数据做统计。
Group by:主要用来分组查询, 通过一定的规则将一个数据集划分为若干个小的区域,然后针对每个小区域分别进行数据汇总处理。也就是根据某个字段进行分组(相同的放一组,不同的分到不同的组)
- 基本语法: group by 字段名;
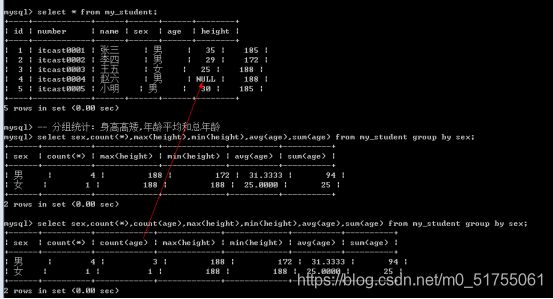
图形化例子:
eg:根据不同的部门号分组显示平均工资
SELECT deptno, ROUND(AVG(sal)) FROM t_emp GROUP BY deptno;/*round四舍五入为整数*/
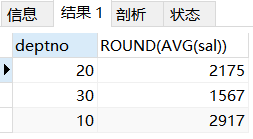
- 逐级分组
数据库支持多列分组条件,执行的时候逐级分组
eg:查询每个部门里,每种职位的人员数量和平均底薪
SELECT deptno, job, COUNT(*), AVG(sal)
FROM t_emp
GROUP BY deptno, job
ORDER BY deptno;
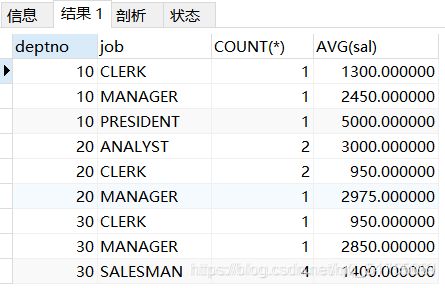
- 对分组结果集再次做汇总计算(回溯统计)
SELECT deptno, AVG(sal), SUM(sal), MAX(sal), MIN(sal), COUNT(*)
FROM t_emp
GROUP BY deptno WITH ROLLUP
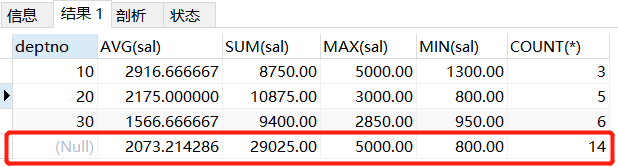
使用了WITH ROLLUP之后,你发现最底下还有一行,对应列再次做聚合计算,avg列再次做平均值计算,sum列对上面几个部门数据再次进行sum计算…
多字段回溯: 考虑第一层分组会有此回溯: 第二次分组要看第一次分组的组数, 组数是多少,回溯就是多少,然后加上第一层回溯即可.
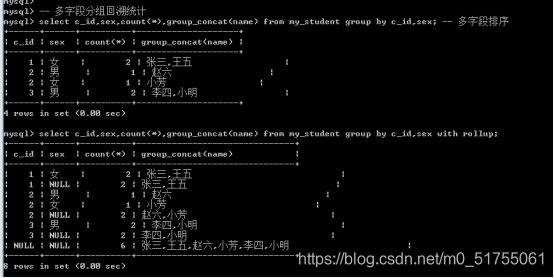
- GROUP_CONCAT函数
这个函数可以把分组查询中的某个字段拼接成一个字符串
eg:查询每个部门内底薪超过2000元的人数和员工姓名
SELECT deptno, COUNT(*), GROUP_CONCAT(ename)
FROM t_emp
WHERE sal >= 2000
GROUP BY deptno;
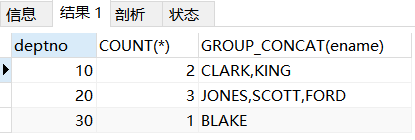
看到ename都是逗号连接的字符串
小提示:语句的执行顺序如下:
FROM -> WHERE -> GROUP BY -> SELECT -> ORDER BY -> LIMIT
FROM 选择数据来源,WHERE选择条件,符合条件的记录留下来,然后经过GROUP BY分组,分完组根据SELECT子句里面聚合函数做计算,然后ORDER BY对结果集排序,最后交给LIMIT挑选返回哪些分页的数据显示。
注意:分组会自动排序: 根据分组字段:默认升序
Group by 字段 [asc|desc]; – 对分组的结果然后合并之后的整个结果进行排序
多字段分组: 先根据一个字段进行分组,然后对分组后的结果再次按照其他字段进行分组
7.4.8 Having子句
我们前面也说了,WHERE子句不允许出现聚合函数
HAVING子句的出现主要是为了WHERE子句不能使用聚合函数的问题,HAVING子句不能独立存在,必须依赖于GROUP BY子句而存在,GROUP BY 执行完成就立即执行HAVING子句
eg1:查询部门平均底薪超过2000的员工数量
SELECT deptno, COUNT(*)
FROM t_emp
GROUP BY deptno HAVING AVG(sal) >= 2000;
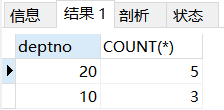
1.要注意HAVING子句判断只能和具体数值判断大小,不能和字段以及聚合函数判断,比较要有数值。比如查询工资大于平均工资的人的数量就不能写HAVING sal > AVG(sal),子句判断不是和数值在比较,直接报错。表连接能解决这个问题,后面再讲。
2.HAVING子句的特殊用法
如果按照数字1分组,MySQL会按照SELECT子句中的列进行分组,HAVING子句也可以正常使用
比如按照部门分组,查询各个部门总人数
SELECT deptno, COUNT(*) FROM t_emp GROUP BY 1;
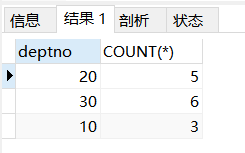
3.HAVING的出现是不是可以完全替换WHERE?
那肯定是不行的,Where是针对磁盘数据进行判断,进入到内存之后会进行分组操作,分组结果就需要having来处理.
SELECT deptno, COUNT(*) FROM t_emp
GROUP BY 1
HAVING deptno IN(10, 30);/*效率低了*/
SELECT deptno, COUNT(*) FROM t_emp
WHERE deptno IN(10, 30)
GROUP BY 1;
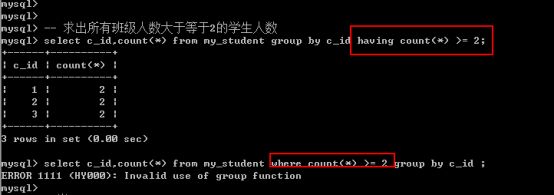
从功能上来说,上面两种写法没有什么区别,但是WHERE优先级在GROUP BY之前,是先把数据按条件筛选完了再分组好呢,还是分完组再去筛选好呢?肯定是前者。所以WHERE能完成的就用WHERE完成,不要放到HAVING中。大量的数据从磁盘读取到内容代价比较大,先筛选完了,再把符合条件的记录读取到内存中显然更好。
4.Having能做where能做的几乎所有事情, 但是where却不能做having能做的很多事情.
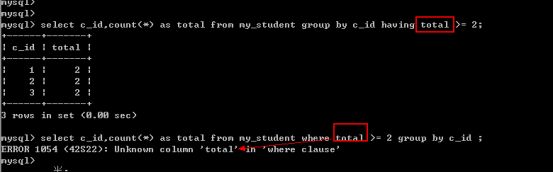
- 分组统计的结果或者说统计函数都只有having能够使用.
- Having能够使用字段别名,where不能,where是从磁盘取数据,而名字只可能是字段名,别名是在字段进入到内存后才会产生
7.4.9 Order by子句
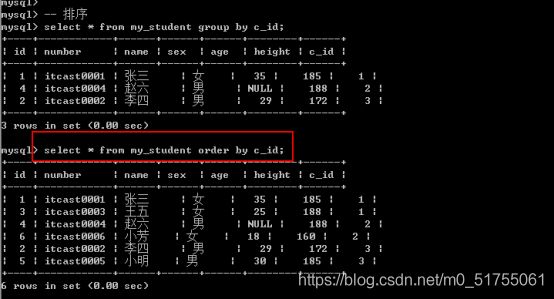
Order by: 排序, 根据某个字段进行升序或者降序排序, 依赖校对集.
- 单字段排序:
Order by 字段名 [asc|desc]; -- asc是升序(默认的),desc是降序
- 多字段排序:
使用order by 规定首要条件和次要条件排序。数据库会先按照首要条件排序,遇到首要排序内容相同的记录,那么会启用次要条件再次排序。
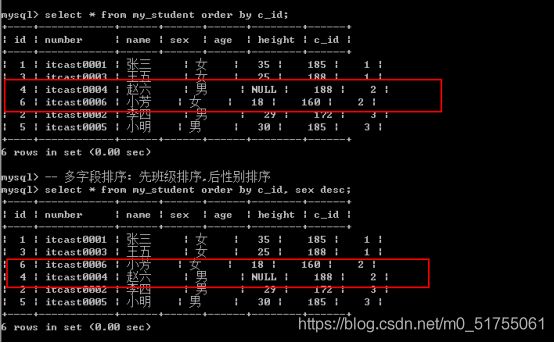
使用图形化界面再举一个例子:
执行如下语句
SELECT empno, ename, sal, hiredate
FROM t_emp ORDER BY sal DESC, hiredate ASC;
可以看到当首要排序条件sal记录相同时,会按照hiredate进行升序排列
7.4.10 Limit子句
Limit子句是一种限制结果的语句,用来做数据分页的。
比如我们看朋友圈,只会加载少量的部分信息,不会一次性加载全部朋友圈,那样只会浪费CPU时间、内存、网络带宽。而结果集的记录可能很多,可以使用limit关键字限定结果集数量。
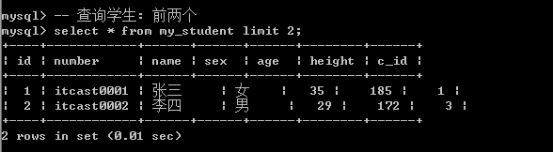
Limit有两种使用方式
- 方案1: 只用来限制长度(数据量): limit 数据量;
- 方案2: 限制起始位置,限制数量: limit 起始位置,长度;
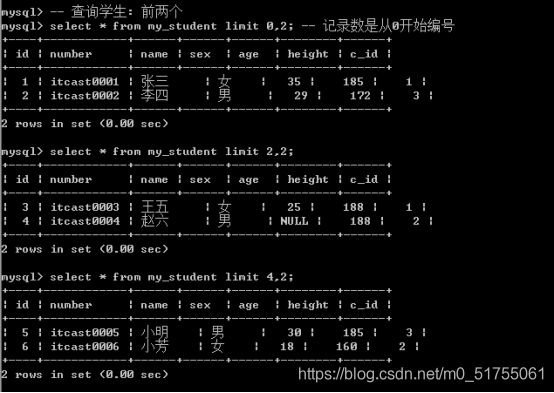
Limit方案2主要用来实现数据的分页: 为用户节省时间,提交服务器的响应效率, 减少资源的浪费.
对于用户来讲: 可以点击的分页按钮: 1,2,3,4
对于服务器来讲: 根据用户选择的页码来获取不同的数据: limit offset,length;
-
Length: 每页显示的数据量: 基本不变
-
Offset: offset = (页码 - 1) * 每页显示量
小提示:子句的执行顺序 FROM -> SELECT -> LIMIT,先选择数据来源,再选择输出内容,最后选择显示的限定条件
第8章:连接查询
-
连接查询: 将多张表(可以大于2张)进行记录的连接(按照某个指定的条件进行数据拼接): 最终结果是: 记录数有可能变化, 字段数一定会增加(至少两张表的合并)
-
连接查询的意义: 在用户查看数据的时候,需要显示的数据来自多张表.
-
连接查询: join, 使用方式: 左表 join 右表
8.1 连接查询分类
SQL中将连接查询分成四类: 内连接,外连接,自然连接和交叉连接
8.2 交叉连接
交叉连接: cross join, 从一张表中循环取出每一条记录, 每条记录都去另外一张表的所有记录逐个进行匹配,并保留所有记录,最终形成的结果叫做笛卡尔积.
基本语法: 左表 [cross] join 右表。其中cross可以省略
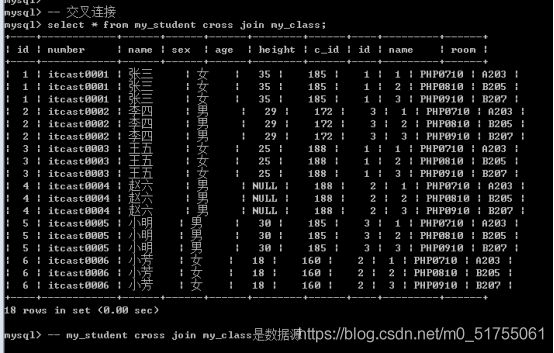
笛卡尔积对于我们的查询没有意义,应该尽量避免(交叉连接没用)
交叉连接存在的价值: 保证连接这种结构的完整性
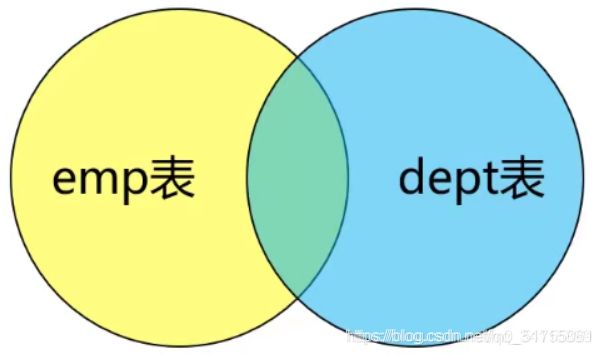
8.3 内连接
内连接: [inner] join, 从左表中取出每一条记录,去右表中与所有的记录进行匹配,匹配必须是某个条件在左表中与右表中相同最终才会保留结果,否则不保留.
如下,某个条件左右表相同部分的交集
基本语法
SELECT ...... FROM 表1
[INNER] JOIN 表2 ON 条件
[INNER] JOIN 表3 ON 条件
......
内连接其实有多种语法形式,想用哪种看个人喜好,效率上没有区别。
SELECT ... FROM 表1 JOIN 表2 ON 连接条件;
SELECT ... FROM 表1 JOIN 表2 WHERE 连接条件;
SELECT ... FROM 表1, 表2 WHERE 连接条件;
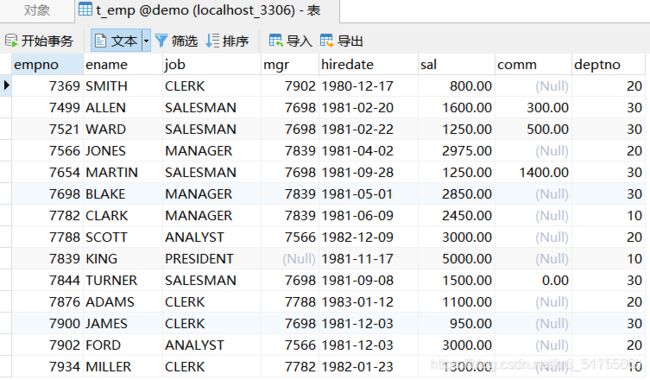
我们来做个例题,首先我们看到前提条件给出了3张表
- 1.员工表t_emp
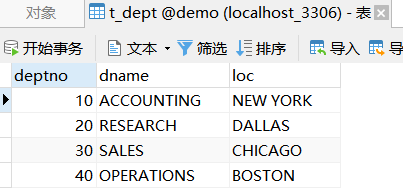
- 2.部门表t_dept
- 3.薪资等级表t_salgrade
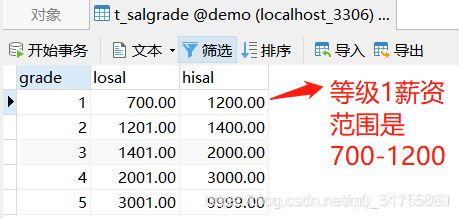
有人会问了,内连接语法看起来就是交叉连接多了一个ON条件,但是区别可大了,来直观感受一下
SELECT * FROM t_emp JOIN t_dept /*交叉连接*/
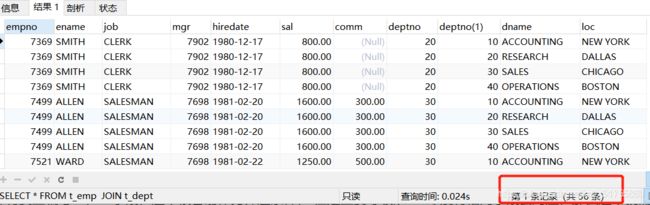
交叉连接产生笛卡尔积,保留所有结果,导致出现了56条记录
SELECT * FROM t_emp e JOIN t_dept d ON e.deptno = d.deptno; /*内连接*/
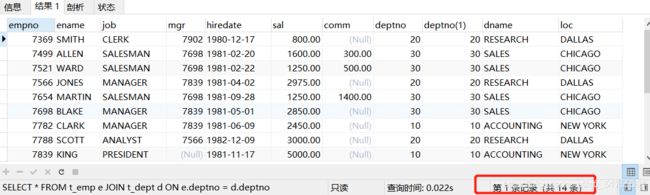
内连接就只针对符合条件的记录去连接,结果集少了很多条记录。
注意:在查询数据的时候,不同表有同名字段,这个时候需要加上表名才能区分,而表名太长,通常可以使用别名,这里两张表都有deptno,表名也缩短为了一个字母
再来看看具体例题
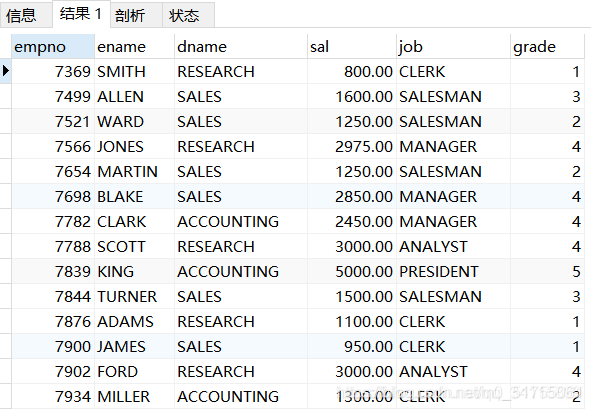
eg1:查询每个员工的工号、姓名、部门名称、底薪、职位、工资等级
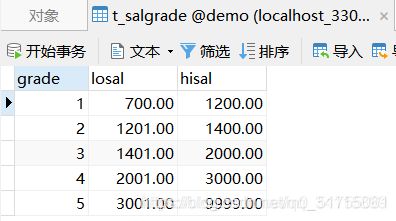
分析:工号empno、姓名ename、底薪sal、职位job是在员工表t_emp,部门名称dname是在部门表t_dept,工资等级grade是在薪资等级表t_salgrade。现在就涉及到了3个表的操作,而员工表t_emp和部门表t_dept都有员工编号deptno字段,这个很容易作为筛选条件, 但是工资等级grade却没有相同字段去对应,那么这个就需要找到逻辑关系的对应,用底薪sal去判断薪资等级中的薪水范围即可
SELECT e.empno, e.ename, d.dname, e.sal, e.job, s.grade
FROM t_emp e JOIN t_dept d ON e.deptno = d.deptno
JOIN t_salgrade s ON e.sal BETWEEN s.losal AND s.hisal;
eg2:查询与SCOTT相同部门的员工
分析:还是那3张表,要查和某个人相同部门的员工,有人就开始这么做,上去就是一个sql
SELECT ename
FROM t_emp
WHERE deptno=(SELECT deptno FROM t_emp WHERE ename="SCOTT")
AND ename!="SCOTT";
括号中的查询我们称为子表,子表中查询到deptno然后把结果集给父表继续查询,写完感觉自我良好,殊不知自己写了一个领导看到就想把你开除的sql。
FROM先执行,获取了数据表的每条记录,再去WHERE进行筛选,万一有上万条数据呢?WHERE会逐一判断上万条数据是否满足条件的时候都要去查询一个子表,相当于SELECT deptno FROM t_emp WHERE ename="SCOTT"被你执行了上万次,而子表也是上万条数据,每一次父表的条件判断又会执行上万次子表查询,数据量小的时候看不出差异,数据量大了就很明显了。
这里用表连接的效率远远高于子查询
SELECT e2.ename
FROM t_emp e1 JOIN t_emp e2 ON e1.deptno=e2.deptno
WHERE e1.ename="SCOTT" AND e2.ename!="SCOTT";
先内连接减少数据源结果集的数量,然后进行筛选。能达到和子查询一样的效果,效率比子查询要高。
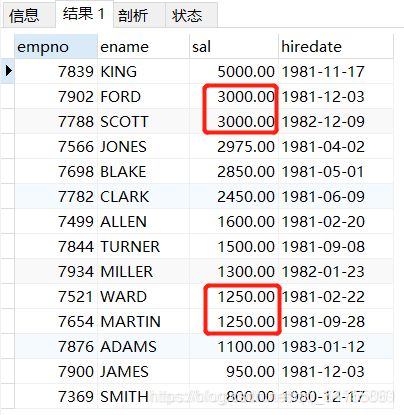
eg3:查询底薪超过公司平均底薪的员工信息
SELECT e.empno, e.ename, e.sal
FROM t_emp e JOIN
(SELECT AVG(sal) avg FROM t_emp) t
ON e.sal >= t.avg;
把平均底薪查询结果当作一个表再和员工表t_emp连接,返回FROM子句。之前说过,这个问题是WHERE解决不了的,WHERE里面不能出现聚合函数的,直接写WHERE sal >= AVG(sal)肯定报错,而HAVING子句又只能和数值比较,这里e.sal>=t.avg表达式两边都是变量,HAVING子句无法解决
eg4:查询RESEARCH部门人数、最高底薪、最低底薪、平均底薪、平均工龄
SELECT COUNT(*), MAX(e.sal), MIN(e.sal), AVG(e.sal),
AVG(DATEDIFF(NOW(),e.hiredate)/365)
FROM t_emp e JOIN t_dept d ON e.deptno=d.deptno
WHERE d.dname="RESEARCH";

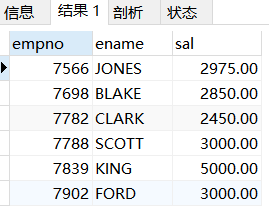
eg5:查询每种职业的最高工资、最低工资、平均工资、最高工资等级和最低工资等级
分析:涉及到工资等级,需要薪资等级表t_salgrade,那么就是员工表和薪资等级表的连接,因为同一种职业不同人有不同的收入,所有根据收入等级排工资等级,逻辑要捋清楚。
SELECT
e.job,
MAX(e.sal + IFNULL(e.comm,0)),
MIN(e.sal + IFNULL(e.comm,0)),
AVG(e.sal + IFNULL(e.comm,0)),
MAX(s.grade),
MIN(s.grade)
FROM t_emp e JOIN t_salgrade s
ON (e.sal + IFNULL(e.comm,0)) BETWEEN s.losal AND s.hisal
GROUP BY e.job;
8.4 外连接
- 外连接分为两种:左(外)连接和右(外)连接。
左外连接就是保留左表所有记录,与右表做连接。如果右表有符合条件的记录就与左表连接。如果右表没有符合条件的记录,就用NULL与左表连接。右外连接同理。
-
基本语法: 左表 left/right join 右表 on 左表.字段 = 右表.字段;
-
为什么要有外连接?
我们还是以内连接中提到的3张数据表为例子。
如果有一名临时员工,没有固定的部门编号,那么我们查询每名员工和他的部门名称,用内连接就会漏掉临时员工,所以要引入外连接语法才能解决这个问题。外连接与内连接的区别在于,除了符合条件的记录之外,结果集中还会保留不符合条件的记录。
- 含有临时员工的员工表t_emp
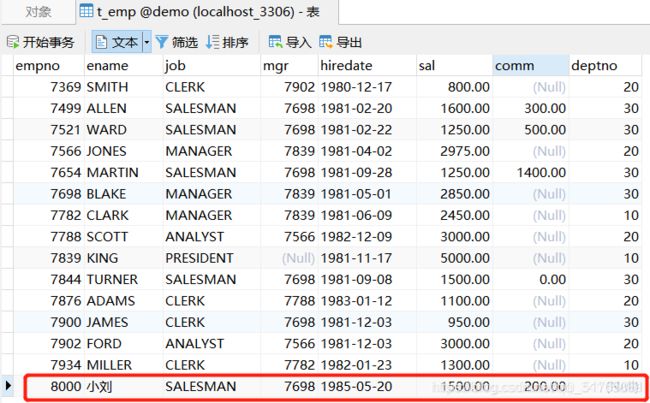
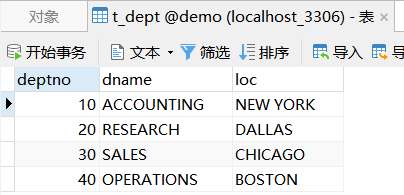
- 部门表t_dept
- 薪资等级表t_salgrade
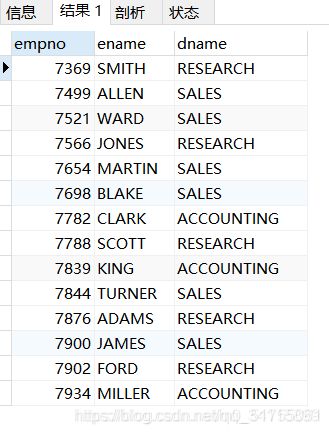
eg1:查询每名员工和他的部门名称
假设我们使用内连接,我们根本查不到临时员工信息,因为临时员工没有部门编号,如下:
SELECT e.empno, e.ename, d.dname
FROM t_emp e JOIN t_dept d
ON e.deptno=d.deptno;
当我们使用外连接时,就能够查到临时员工,如下:
/*左连接*/
SELECT e.empno, e.ename, d.dname
FROM t_emp e LEFT JOIN t_dept d
ON e.deptno=d.deptno;
/*右连接,换一下表的顺序,结果集一样*/
SELECT e.empno, e.ename, d.dname
FROM t_dept d RIGHT JOIN t_emp e
ON e.deptno=d.deptno;
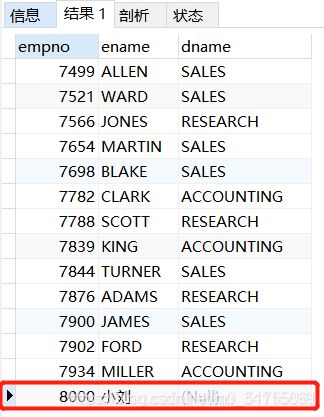
左表是员工表,左连接保留所有记录,没有部门编号的临时员工信息也会保留,右表部门编号没有与之匹配,那就用NULL连接。
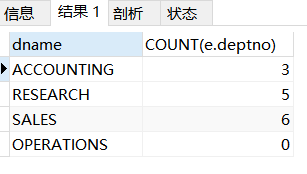
eg2:查询每个部门的名称和部门的人数
有人容易写出下面的错误sql语句
SELECT d.dname, COUNT(*)
FROM t_dept d LEFT JOIN t_emp e
ON d.deptno=e.deptno
GROUP BY d.deptno;/*按部门分组,所以有group by*/
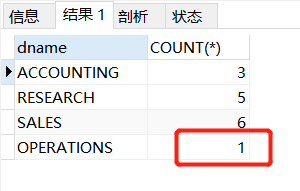
这题很多细节,很多人会出错,40部门的部门名称为dname为OPERATIONS里没有员工,居然还是有一条记录,因为你在连接的时候左表记录全部保留,在右表中没有员工与OPERATIONS部门匹配,连接的是NULL,这也是一条记录,所以这里才会出现1。
但是你也不要写成COUNT(d.deptno),因为左边部门表记录全保留,d.deptno有40部门,40部门的dname就是OPERATIONS,右表与之连接的都是NULL,道理和上面一样。
所以你得按照右边员工表计算,COUNT(e.deptno),记录各个部门非空记录数。40部门没有员工,右表e.deptno没有40,NULL不会被COUNT(e.deptno)计算入内,所以是0,符合预期。
正确的sql语句如下:
SELECT d.dname, COUNT(e.deptno)
FROM t_dept d LEFT JOIN t_emp e
ON d.deptno=e.deptno
GROUP BY d.deptno;/*按部门分组,所以有group by*/
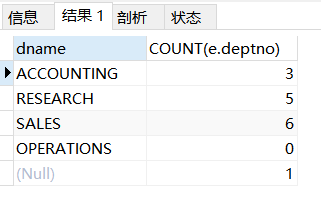
eg3:查询每个部门的名称和部门的人数,如果是没有部门的临时员工,部门名称用NULL代替
分析:我们上一个例子已经做到了查询部门名称和部门的人数,现在就差一个临时员工和他的部门的问题。临时员工在t_emp表,所以你要保留这个表的所有内容再把eg2例子的查询语句一起联合查询
(SELECT d.dname, COUNT(e.deptno)
FROM t_dept d LEFT JOIN t_emp e
ON d.deptno=e.deptno
GROUP BY d.deptno) UNION
(SELECT d.dname, COUNT(*)
FROM t_dept d RIGHT JOIN t_emp e
ON d.deptno=e.deptno
GROUP BY d.deptno);
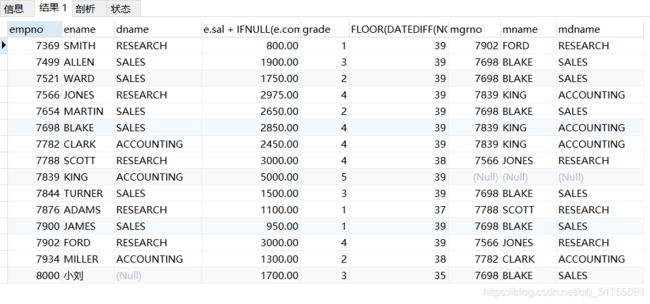
eg4:查询每名员工的编号、姓名、部门名称、月薪、工资等级、工龄、上司编号、上司姓名、上司部门(这个题有点综合,没点基础做不出来)
分析:要查员工的编号、姓名、部门名称、工龄,涉及到员工表t_emp、部门表t_dept,查工资等级涉及到薪资等级表t_salgrade,有的员工是其他员工的上司,所以我们为员工表再做一次查询连接起来当作领导表,连接条件是员工的领导编号和领导的员工编号相等时,这个领导表查出来的员工,就是员工表里对应员工的领导。sql如下,你细品
SELECT
e.empno, e.ename, d.dname,
e.sal + IFNULL(e.comm,0), s.grade,
FLOOR(DATEDIFF(NOW(),e.hiredate)/365),
t.empno AS mgrno, t.ename AS mname, t.dname AS mdname
FROM t_emp e LEFT JOIN t_dept d ON e.deptno=d.deptno
LEFT JOIN t_salgrade s ON e.sal BETWEEN s.losal AND s.hisal
LEFT JOIN
(SELECT e1.empno, e1.ename, d1.dname
FROM t_emp e1 JOIN t_dept d1
ON e1.deptno=d1.deptno
) t ON e.mgr=t.empno;
外连接的注意事项:
内连接只保留符合条件的记录,所以查询条件写在ON子句和WHERE子句中的效果是相同的。但是外连接里,条件写在WHERE子句里,不符合条件的记录是会被过滤掉的,而不是保留下来。
我们来看看具体差别
SELECT e.ename, d.dname, d.deptno
FROM t_emp e
LEFT JOIN t_dept d ON e.deptno=d.deptno
AND e.deptno=10; /*这里是and不是where*/
分析:左连接保留左表全部,按条件连接右表,不仅要部门编号相同,还要部门编号为10,不满足的用NULL连接,所以总记录条数就是左表的COUNT(*)数量
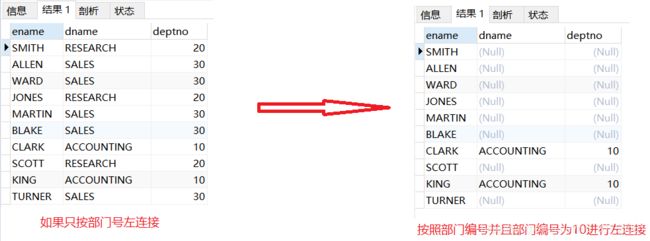
改为WHERE之后
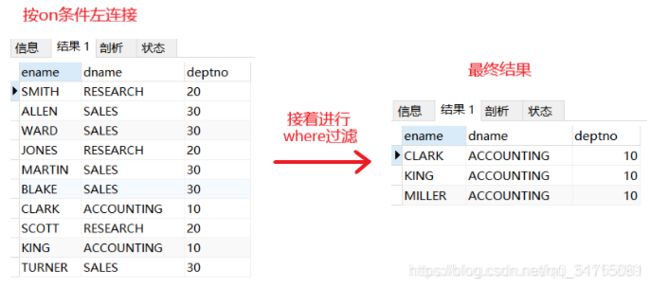
SELECT e.ename, d.dname, d.deptno
FROM t_emp e
LEFT JOIN t_dept d ON e.deptno=d.deptno
WHERE e.deptno=10;
分析:左连接保留左表全部,按照部门号进行对应连接,连接完再进行筛选员工部门号位10的记录,不满足的就过滤。一步步的执行过程如下图
8.5 自然连接
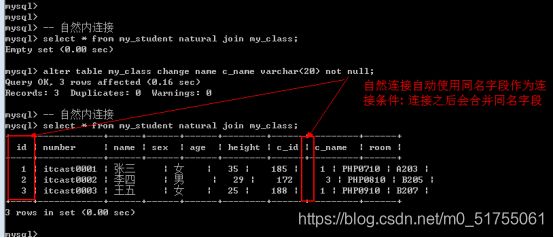
自然连接: natural join, 自然连接, 就是自动匹配连接条件: 系统以字段名字作为匹配模式(同名字段就作为条件, 多个同名字段都作为条件).
-
自然内连接: 左表 natural join 右表;
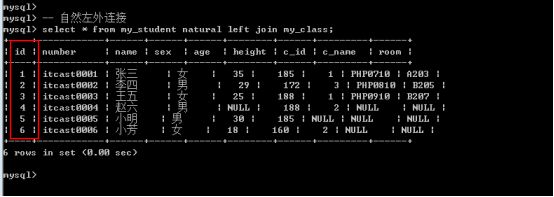
-
自然外连接: 左表 natural left/right join 右表;
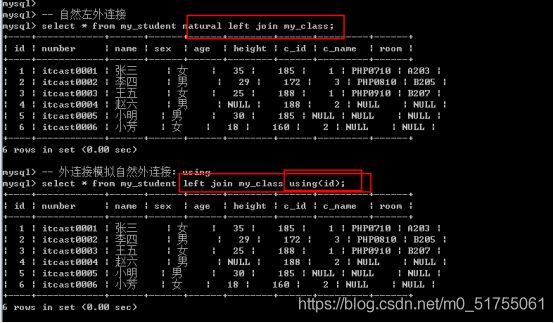
其实, 内连接和外连接都可以模拟自然连接: 使用同名字段,合并字段 -
左表 left/right/inner join 右表 using(字段名); – 使用同名字段作为连接条件: 自动合并条件
多表连接: A表 inner join B表 on 条件 left join C表 on条件 …
执行顺序: A表内连接B表,得到一个二维表, 左连接C表形成二维表.
8.6 子查询
子查询: sub query, 查询是在某个查询结果之上进行的.(一条select查询的sql语句内部包含了另外一条select查询的sql语句).
8.6.1 子查询分类
- Where子查询:
子查询出现where条件中,where语句里不推荐使用子查询,每执行一次where条件筛选,就会进行一次子查询,效率低下。像这种反复子查询就属于相关子查询,where语句的子查询都属于相关子查询,我们要避免相关子查询的存在。
比如查询底薪超过公司平均底薪的员工信息

- From子查询:
子查询跟在from之后,通常这种子查询的结果集作为一个临时表,from子查询只会执行一次,不是相关子查询,所以查询效率高。

- SELECT子查询,
子查询跟在SELECT之后,SELECT子查询也是相关子查询,不推荐

8.6.2 单行子查询和多行子查询???
8.6.3 WHERE子句中的多行子查询???
8.6.4 子查询的EXISTS关键字
EXISTS关键字是把原来在子查询之外的条件判断,写到了子查询的里面。
SELECT ... FROM 表名 WHERE [NOT] EXISTS (子查询)
eg:查询工资等级是3级或者4级的员工信息
SELECT empno, ename, sal
FROM t_emp
WHERE EXISTS(
SELECT * /*这里选择其他字段也可以,比如grade*/
FROM t_salgrade
WHERE sal BETWEEN losal AND hisal
AND grade IN(3,4)
)
只要子查询结果为不为空,那么EXISTS这个条件就是满足的,这条记录就满足条件不会被过滤
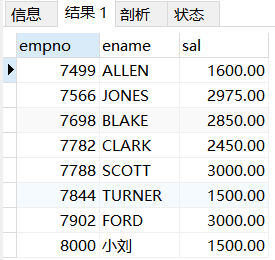
这里只是演示WHERE多行子查询的EXISTS关键字,解决这个问题用表连接其实好的多。如下:
SELECT empno, ename, sal
FROM t_emp
JOIN t_salgrade
ON sal BETWEEN losal AND hisal AND grade IN(3,4)
第9章:视图
视图: view, 是一种有结构(有行有列)但是没结果(结构中不真实存放数据)的虚拟表, 虚拟表的结构来源不是自己定义, 而是从对应的基表中产生(视图的数据来源).
基本语法
Create view 视图名字 as select语句;
-
select语句可以是普通查询;可以是连接查询; 可以是联合查询; 可以是子查询.
-
创建单表视图: 基表只有一个
-
创建多表视图: 基表来源至少两个
9.2 查看视图
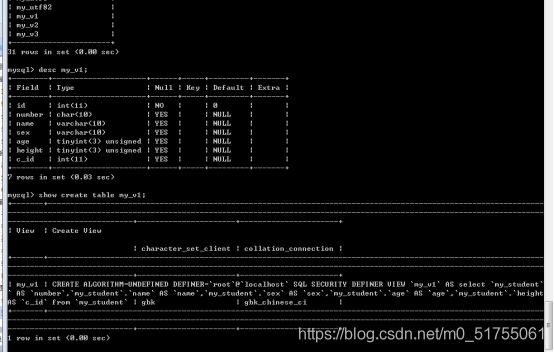
查看视图: 查看视图的结构
-
视图是一张虚拟表: 表, 表的所有查看方式都适用于视图: show tables [like]/desc 视图名字/show create table 视图名;
-
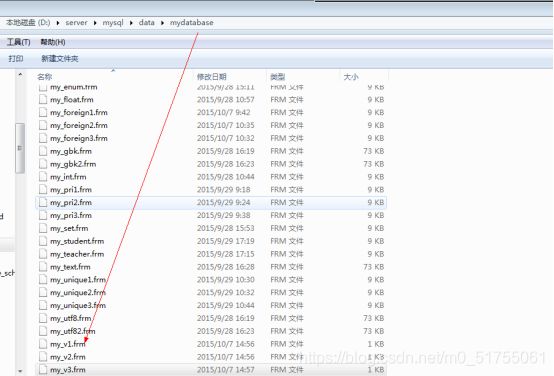
视图一旦创建: 系统会在视图对应的数据库文件夹下创建一个对应的结构文件: frm文件
9.3 使用视图
使用视图主要是为了查询: 将视图当做表一样查询即可
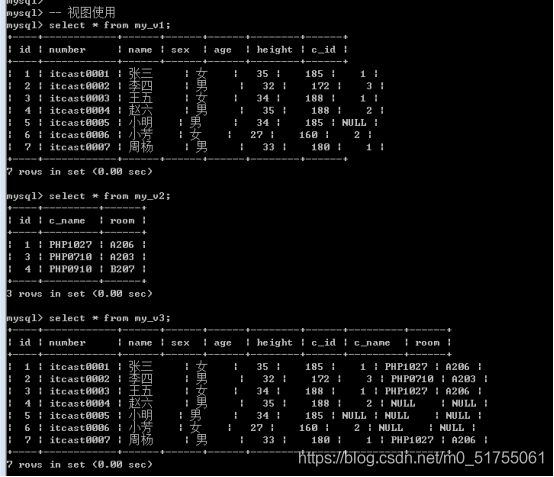
视图的执行: 其实本质就是执行封装的select语句.
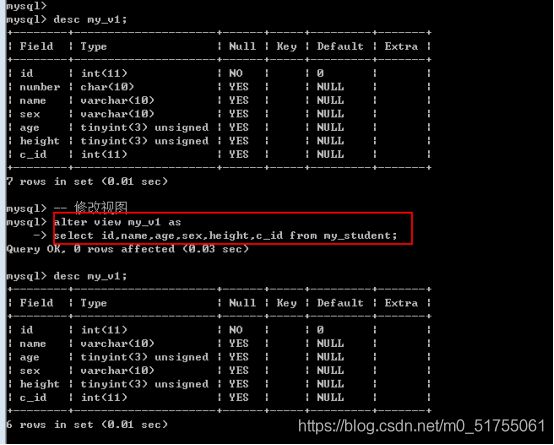
9.4 修改视图
视图本身不可修改, 但是视图的来源是可以修改的.
修改视图: 修改视图本身的来源语句(select语句)
Alter view 视图名字 as 新的select语句;
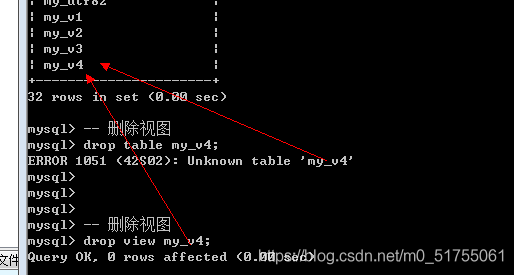
9.5 删除视图
Drop view 视图名字;
9.6 视图意义
- 视图可以节省SQL语句: 将一条复杂的查询语句使用视图进行保存: 以后可以直接对视图进行操作
- 数据安全: 视图操作是主要针对查询的, 如果对视图结构进行处理(删除), 不会影响基表数据(相对安全).
- 视图往往是在大项目中使用, 而且是多系统使用: 可以对外提供有用的数据, 但是隐藏关键(无用)的数据: 数据安全
- 视图可以对外提供友好型: 不同的视图提供不同的数据, 对外好像专门设计
- 视图可以更好(容易)的进行权限控制
9.7 视图数据操作(不建议使用)
-
视图是的确可以进行数据写操作的: 但是有很多限制
-
将数据直接在视图上进行操作.
9.7.1 新增数据
数据新增就是直接对视图进行数据新增.
- 多表视图不能新增数据
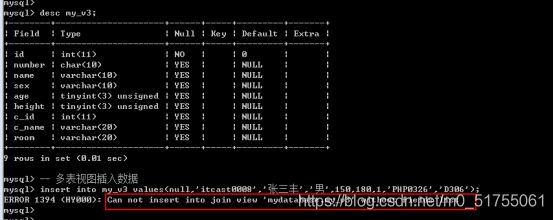
可以向单表视图插入数据: 但是视图中包含的字段必须有基表中所有不能为空(或者没有默认值)字段
9.7.2 删除数据
- 多表视图不能删除数据
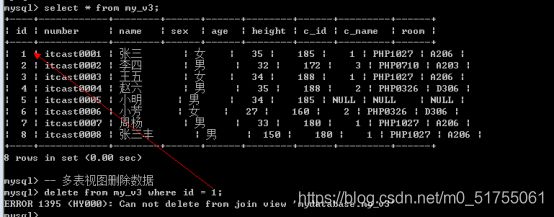
- 单表视图可以删除数据
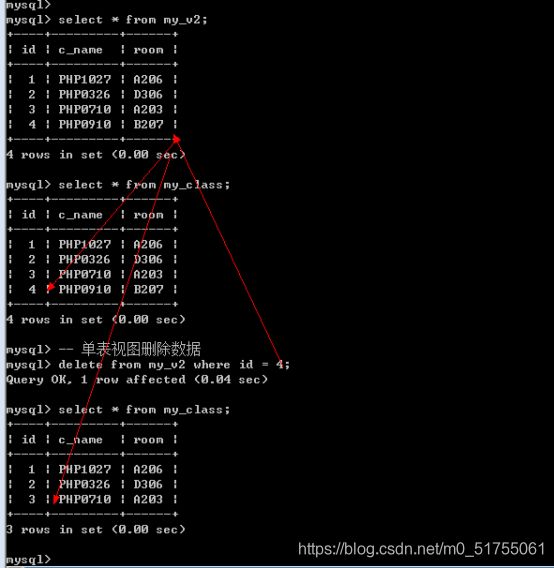
9.7.3 更新数据
9.8 视图算法
视图算法: 系统对视图以及外部查询视图的Select语句的一种解析方式.
视图算法分为三种
-
Undefined: 未定义(默认的), 这不是一种实际使用算法, 是一种推卸责任的算法: 告诉系统,视图没有定义算法, 系统自己看着办
-
Temptable: 临时表算法: 系统应该先执行视图的select语句,后执行外部查询语句
-
Merge: 合并算法: 系统应该先将视图对应的select语句与外部查询视图的select语句进行合并,然后执行(效率高: 常态)
算法指定: 在创建视图的时候
Create algorithm = 指定算法 view 视图名字 as select语句;
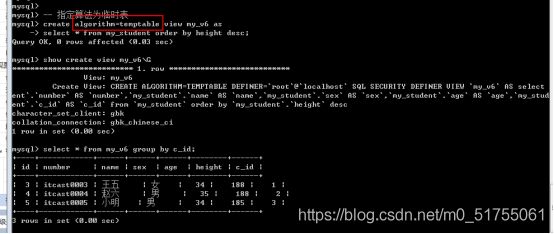
视图算法选择: 如果视图的select语句中会包含一个查询子句(五子句), 而且很有可能顺序比外部的查询语句要靠后, 一定要使用算法temptable,其他情况可以不用指定(默认即可).
第10章:数据备份与还原
-
备份: 将当前已有的数据或者记录保留
-
还原: 将已经保留的数据恢复到对应的表中
为什么要做备份还原?
防止数据丢失: 被盗, 误操作
保护数据记录
数据备份还原的方式有很多种:
数据表备份, 单表数据备份, SQL备份, 增量备份.
10.1 数据表备份
-
不需要通过SQL来备份: 直接进入到数据库文件夹复制对应的表结构以及数据文件, 以后还原的时候,直接将备份的内容放进去即可.
-
数据表备份有前提条件: 根据不同的存储引擎有不同的区别.
-
存储引擎: mysql进行数据存储的方式: 主要是两种: innodb和myisam(免费)
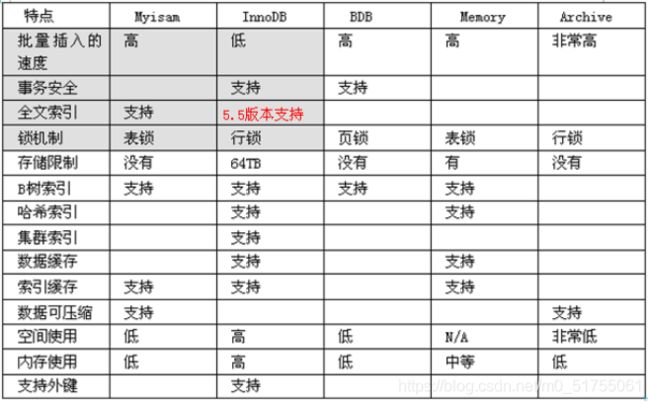
对比myisam和innodb: 数据存储方式
-
Innodb: 只有表结构,数据全部存储到ibdata1文件中
-
Myisam: 表,数据和索引全部单独分开存储
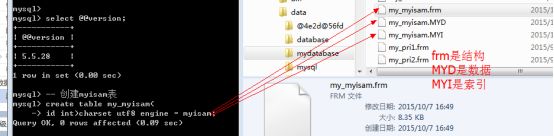
这种文件备份通常适用于myisam存储引擎: =直接复制三个文件即可, 然后直接放到对应的数据库下即可以使用.
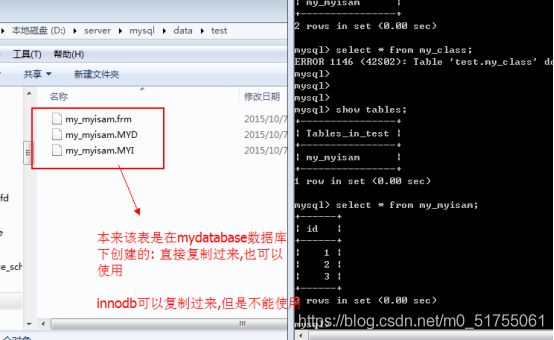
10.2 单表数据备份
每次只能备份一张表; 只能备份数据(表结构不能备份)
如果业务数据非常多,建议只导出表结构,然后用SELECT INTO OUTFILE把数据导出成文本文档,具体操作可以看10.5节图形化操作。
备份: 从表中选出一部分数据保存到外部的文件中(outfile)
Select */字段列表 into outfile 文件所在路径 from 数据源;
前提: 外部文件不存在
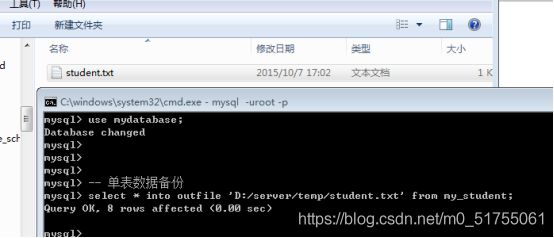
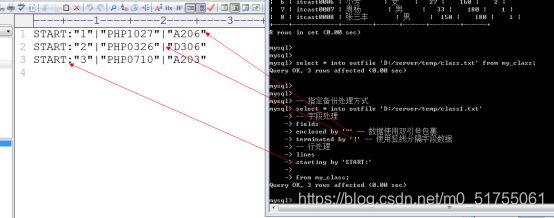
高级备份: 自己制定字段和行的处理方式
Select */字段列表 into outfile 文件所在路径 fields 字段处理 lines 行处理 from 数据源;
Fields: 字段处理
-
Enclosed by: 字段使用什么内容包裹, 默认是’’,空字符串
-
Terminated by: 字段以什么结束, 默认是”\t”, tab键
-
Escaped by: 特殊符号用什么方式处理,默认是’\’, 使用反斜杠转义
Lines: 行处理
-
Starting by: 每行以什么开始, 默认是’’,空字符串
-
Terminated by: 每行以什么结束,默认是”\r\n”,换行符
数据还原: 将一个在外部保存的数据重新恢复到表中(如果表结构不存在,那么sorry)
Load data infile 文件所在路径 into table 表名[(字段列表)] fields字段处理 lines 行处理;
怎么备份的怎么还原
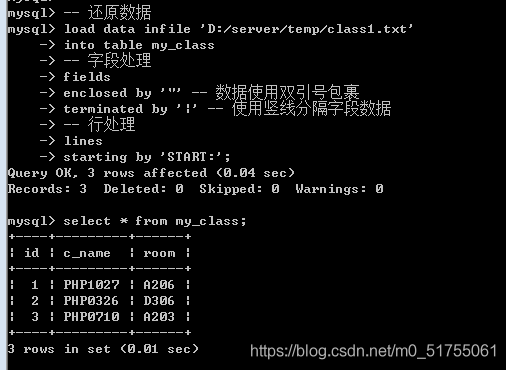
10.3 SQL备份与还原
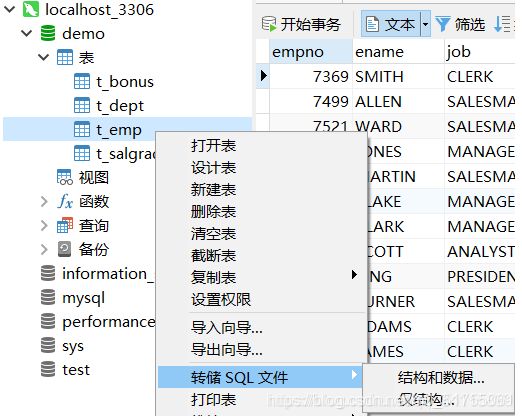
备份的是SQL语句: 系统会对表结构以及数据进行处理,变成对应的SQL语句, 然后进行备份: 还原的时候只要执行SQL指令即可.(主要就是针对表结构)
备份: mysql没有提供备份指令: 需要利用mysql提供的软件
图形化操作如下,选中数据表,点击右键
10.4 增量备份
不是针对数据或者SQL指令进行备份: 是针对mysql服务器的日志文件进行备份
增量备份: 指定时间段开始进行备份., 备份数据不会重复, 而且所有的操作都会备份(大项目都用增量备份)
10.5 大文件备份和还原(图形化操作,推荐!)
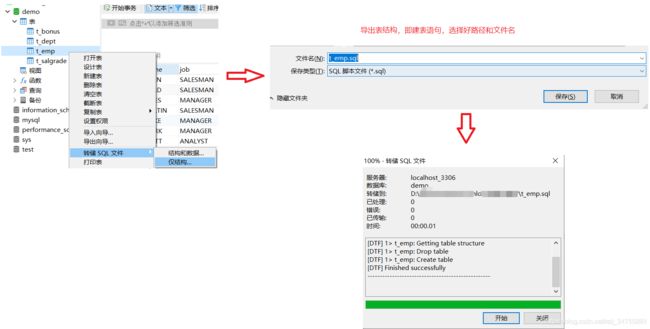
业务数据比较多的时候,只导出表结构到sql文件,业务数据文件导出到txt文件,这样就跳过了sql词法分析和语法优化,哪怕导入几千万条数据,也可以在1分钟内导入完毕
1.导出表结构
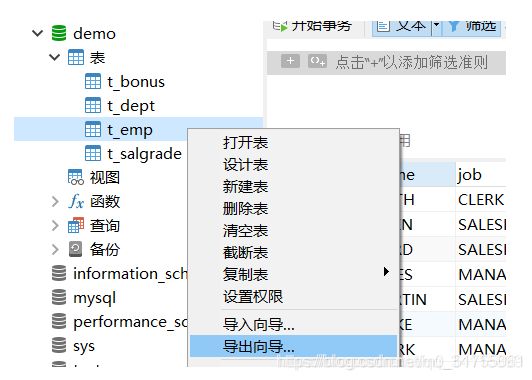
2.导出表中业务数据
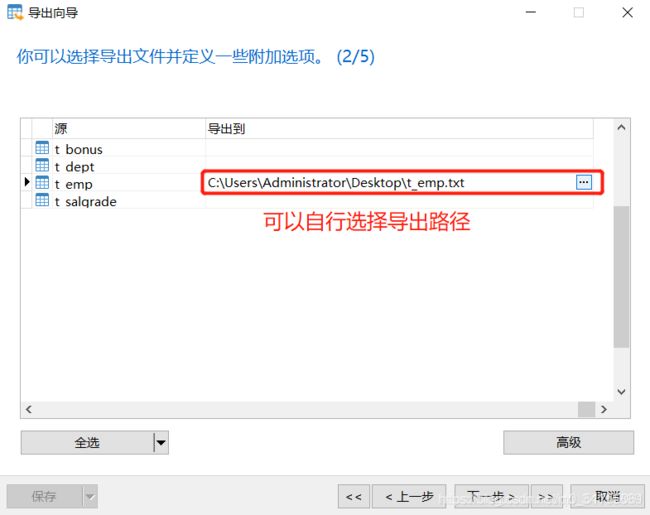
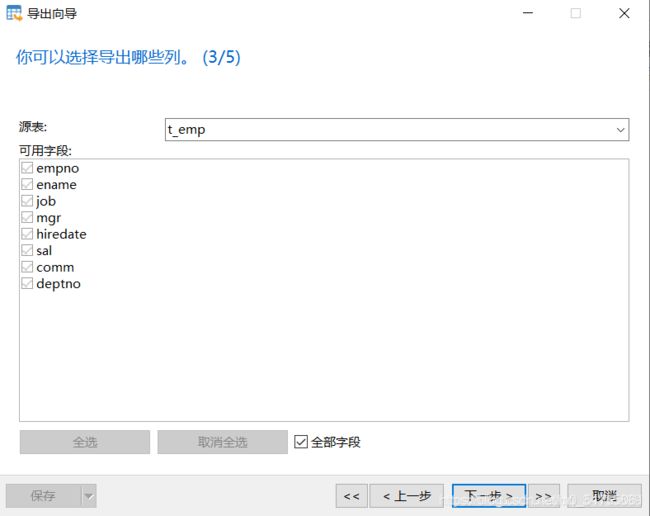
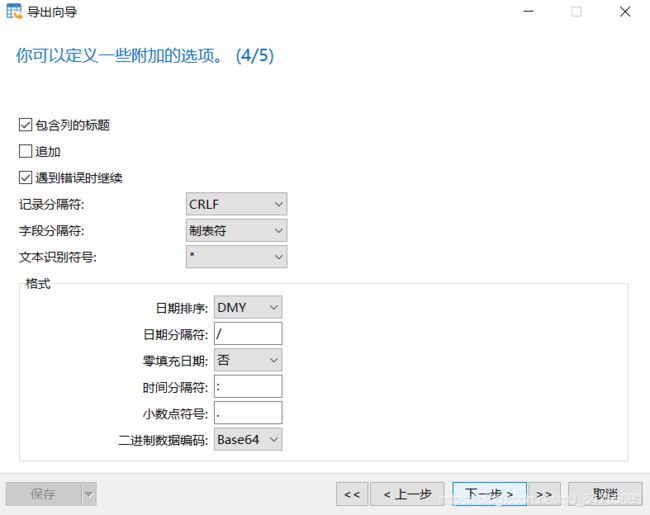
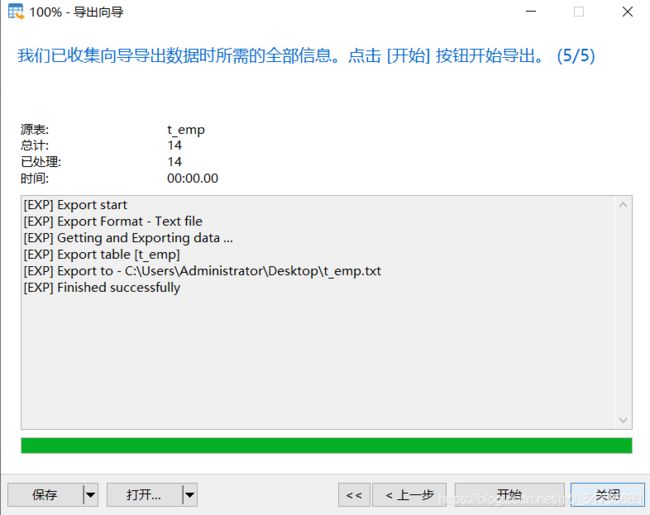

3.删除表,为导入做准备
4.导入表结构
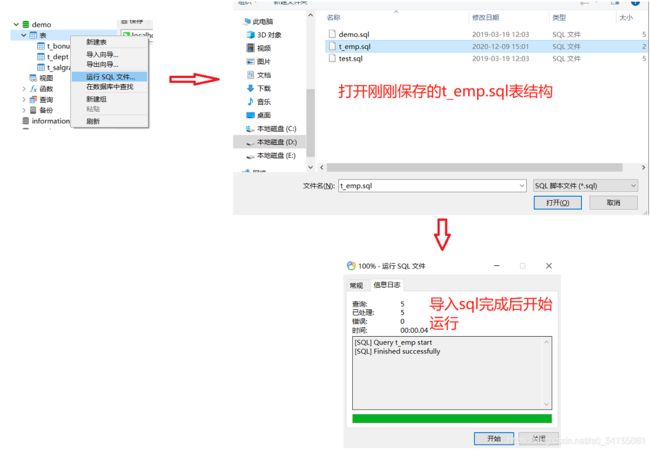
5.刷新后看到表结构
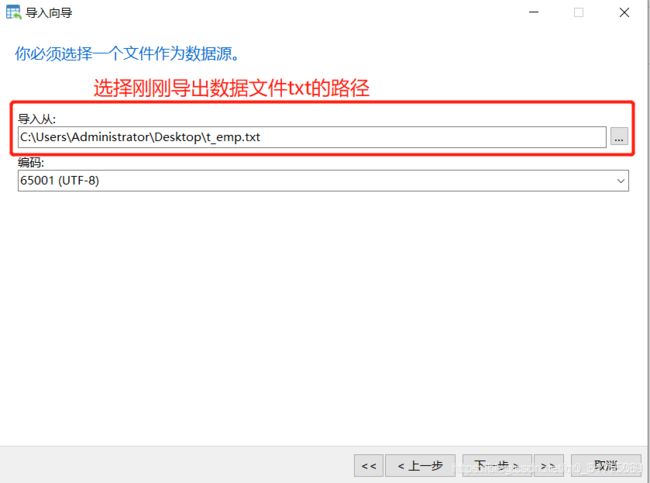
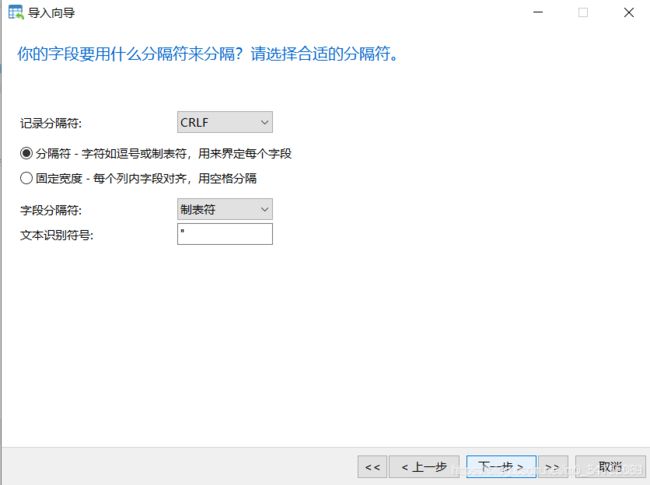
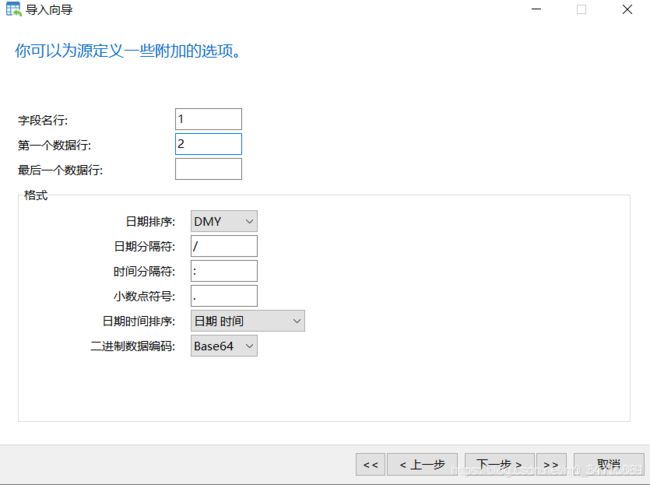
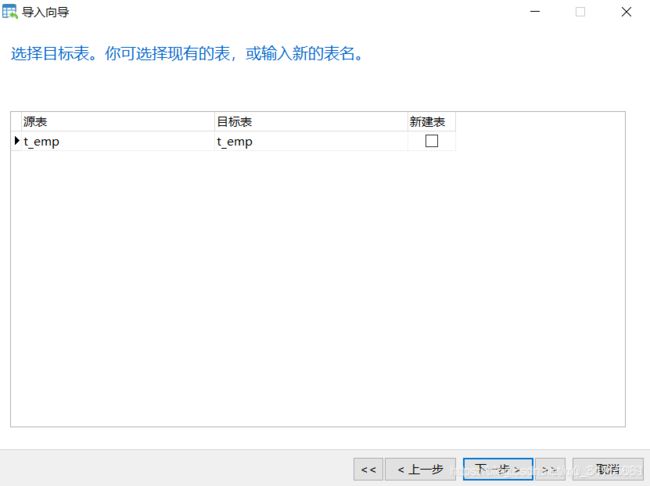
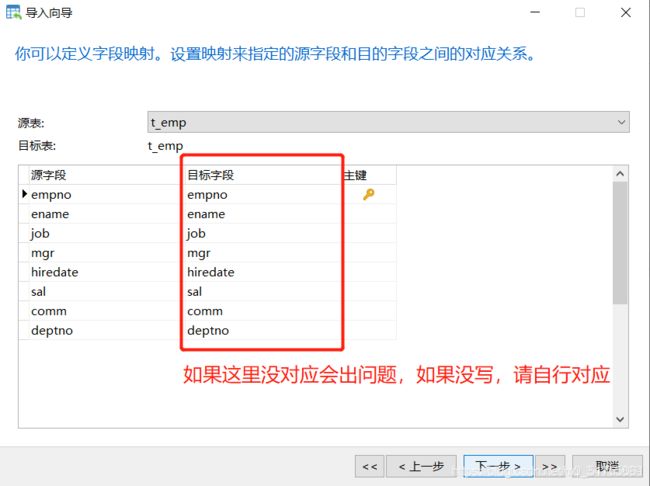
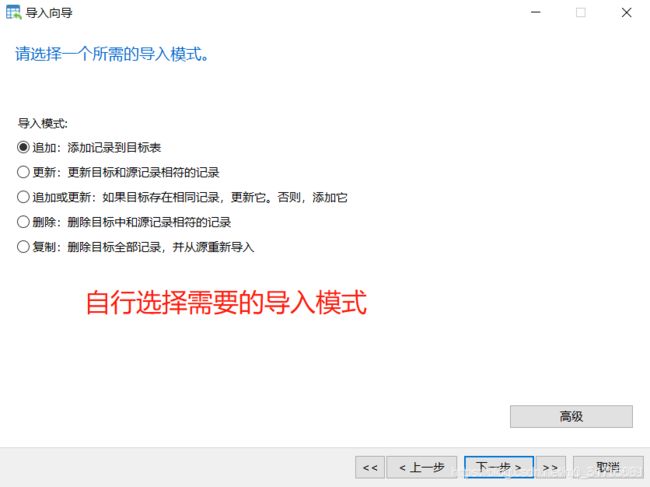
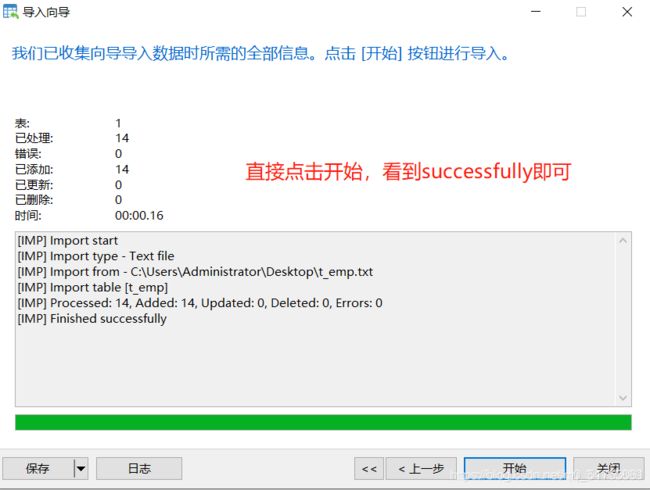
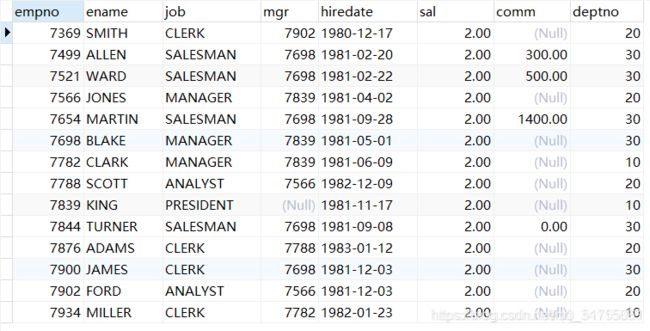
7.刷新表即可看到导入成功
第11章:事务、事务安全
-
事务: transaction, 一系列要发生的连续的操作
-
事务安全: 一种保护连续操作同时满足(实现)的一种机制
-
事务安全的意义: 保证数据操作的完整性
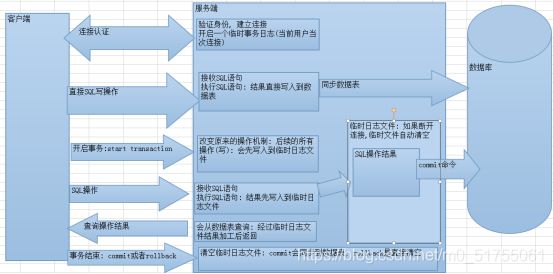
如果SQL语句直接操作文件是很危险的,比如你要给员工涨工资,正在update操作的时候,系统断电了,你就不知道谁已经涨了谁还没涨。
我们应该利用日志来间接写入。
MySQL总共5种日志,其中只有redo日志和undo日志与事务有关
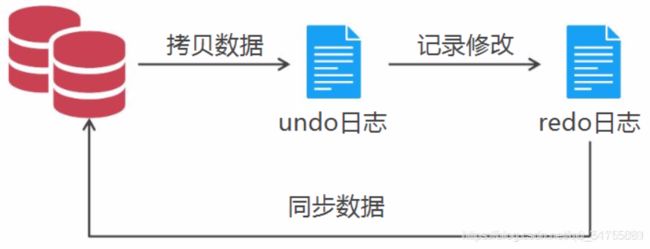
日志就相当于数据文件的一个副本,SQL语句操作什么样的记录,MySQL就会把这些记录拷贝到undo日志,然后增删改查的操作就会记录到redo日志,最后把redo日志和数据库文件进行同步就行了。即使同步过程中断电了,有了redo日志的存在,重启MySQL数据库之后继续同步数据,同步成功后我们修改的数据就真正同步到数据库里面了,有事务的数据库抵抗风险的能力变强了。
RDBMS=SQL语句+事务(ACID)
事务是一个或者多个SQL语句组成的整体,要么全部执行成功,要么全部失败。
11.1 事务操作
事务操作分为两种: 自动事务(默认的), 手动事务
默认情况下,MySQL执行每条SQL语句都会自动开启和提交事务。为了让多条SQL语句纳入到一个事物之下,可以手动管理事务。
START TRANSACTION;
SQL语句
[COMMIT | ROLLBACK];
START TRANSACTION;
DELETE FROM t_emp;
DELETE FROM t_dept;
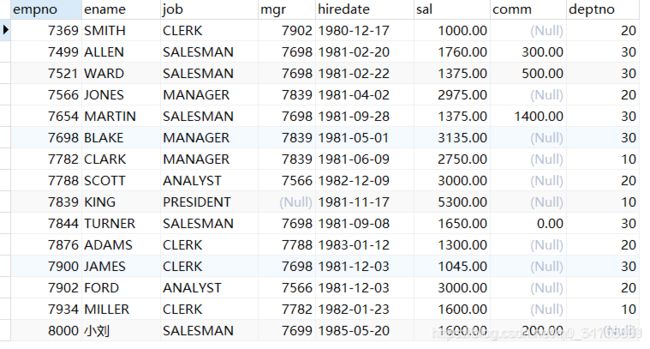
SELECT * FROM t_emp;
SELECT * FROM t_dept;
开启事务: 告诉系统以下所有的操作(写)不要直接写入到数据表, 先存放到redo日志。
删除员工表t_emp和部门表t_dept之后,SQL语句查询两表的的数据均为空

但是去看数据表的数据却仍然存在,这是为什么呢?
因为你开启了事务,你现在的操作还在redo日志里面,并没有同步到数据库文件里面,你只有COMMIT之后才会同步
继续执行
ROLLBACK;
去数据表查看,2张数据表都被清空了。
当然你也可以直接回滚,执行ROLLBACK;
ROLLBACK;
这样你的redo日志被清空,下次操作的时候重新往redo日志里面进行操作,就不会受到上一次操作的影响。
11.2 自动事务处理
在mysql中: 默认的都是自动事务处理, 用户操作完会立即同步到数据表中.
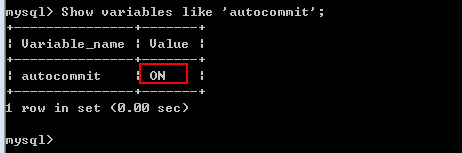
自动事务: 系统通过autocommit变量控制
Show variables like ‘autocommit’;
关闭自动提交: set autocommit = off/0;
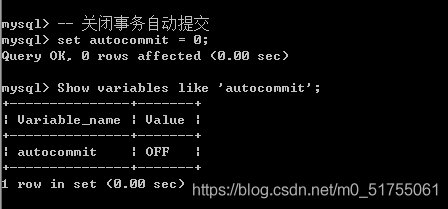
再次直接写操作
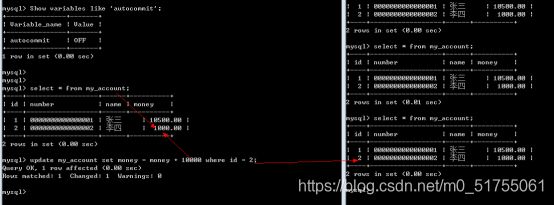
自动关闭之后,需要手动来选择处理: commit提交, rollback回滚
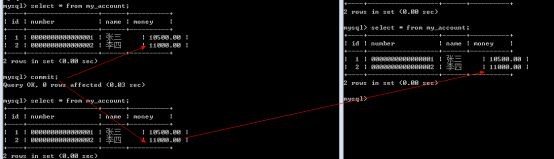
注意: 通常都会使用自动事务
11.3 事务原理
事务操作原理: 事务开启之后, 所有的操作都会临时保存到事务日志, 事务日志只有在得到commit命令才会同步到数据表,其他任何情况都会清空(rollback, 断电, 断开连接)
11.4 回滚点
回滚点: 在某个成功的操作完成之后, 后续的操作有可能成功有可能失败, 但是不管成功还是失败,前面操作都已经成功: 可以在当前成功的位置, 设置一个点: 可以供后续失败操作返回到该位置, 而不是返回所有操作, 这个点称之为回滚点.
设置回滚点语法: savepoint 回滚点名字;
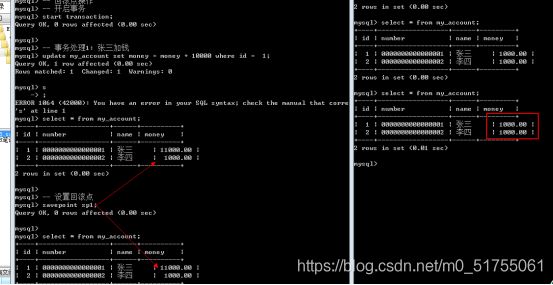
回到回滚点语法: rollback to 回滚点名字;
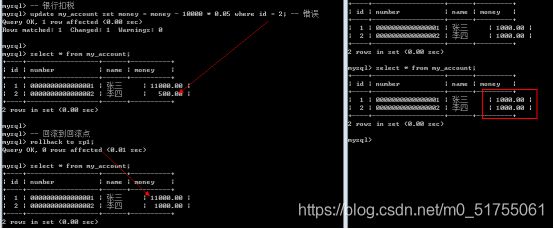
11.5 事务ACID属性
A: Atomic原子性,一个事物中的所有操作要么全部完成,要么全部失败。事物执行后,不允许停留在中间某个状态。
C: Consistency一致性,不管在任何给定的时间,并发事务有多少,事务必须保证运行结果的一致性。事务可以并发执行,但是最终MySQL却串行执行。
怎么保证一致性?

阻止事务之间相互读取临时数据
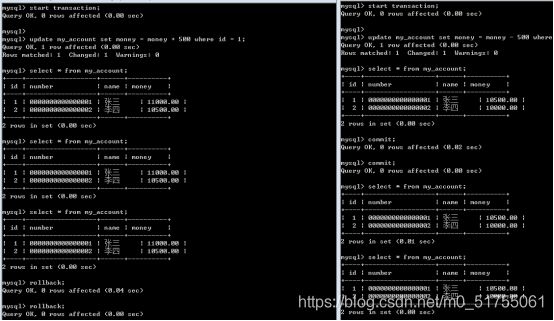
I: Isolation隔离性,每个事务只能看到事务内的相关数据,别的事务的临时数据在当前事务是看不到的。隔离性要求事务不受其他并发事务的影响,在给定时间内,该事务是数据库运行的唯一事务。
怎么保证隔离性?
undo和redo日志中的数据都会被标记属于哪个事务的,所以事务执行过程中就只能读到自己的临时数据了。
D: Durability持久性,事务一旦提交,结果便是永久性的。即便发生宕机,仍然可依靠事务日志完成数据持久化。
锁机制: innodb默认是行锁, 但是如果在事务操作的过程中, 没有使用到索引,那么系统会自动全表检索数据, 自动升级为表锁
-
行锁: 只有当前行被锁住, 别的用户不能操作
-
表锁: 整张表被锁住, 别的用户都不能操作
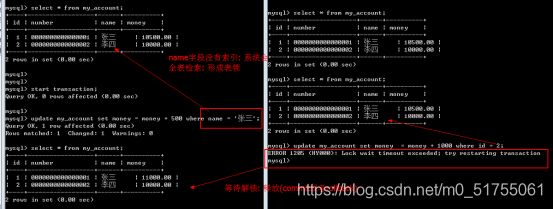
11.6 事务的隔离级别
在某些特定场合,我们又想让事务之间读取到一些临时数据,这就需要修改事务的隔离级别
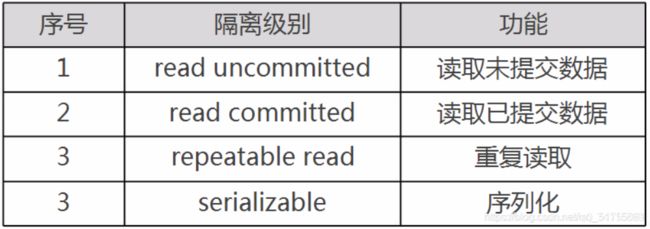
11.6.1 read uncommitted
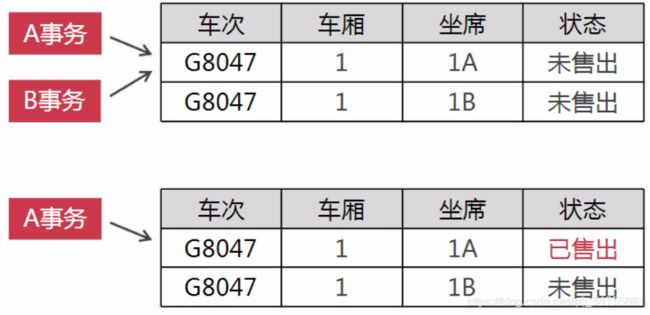
场景一:比如买票的场景,逢年过节都需要买票回家,假如A和B都在买同一辆车的车票,此时还剩最后一张票,A点击购买,但是还没付款提交,因为查看不到事务之间的临时数据,所以B查看时,也还剩一张票,于是B点击购买,立即付款提交,结果A就会购买失败。所以理想的情况应该是,当A点击购买去付款时,B应该看得到这个临时数据,显示没有票才对。
eg1:查看事务之间能否读取未提交的数据
新建一个查询
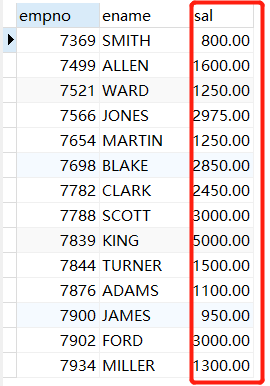
START TRANSACTION;
UPDATE t_emp SET sal=1;
此时开启事务并进行更新操作,但是没有commit
再新建一个查询
START TRANSACTION;
SELECT empno, ename, sal FROM t_emp;
COMMIT;
注意:这里没有修改数据,仅仅只是select查询数据,redo日志没有改变,所以不会做同步到文件的操作,commit之后会清空对应的undo日志数据。
结果显示如下,前者在事务中修改sal为1,后者却看不到。
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; /*代表可以读取其他事务未提交的数据*/
START TRANSACTION;
SELECT empno, ename, sal FROM t_emp;
COMMIT;
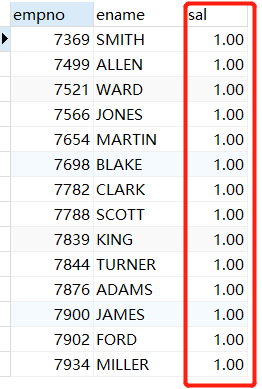
结果立马就变了,但是要注意,因为前者并未commit,所以数据库表文件的数据还没有修改
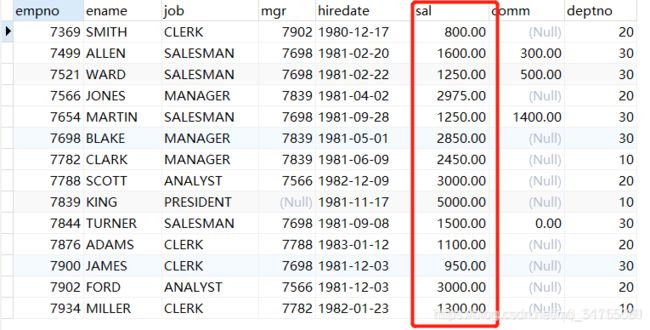
11.6.2 read committed
场景二:银行转账的场景,A事务执行往Scott账户转账1000的操作,B事务执行扣除Scott账户100块的操作,如果A能读取到B事务未提交的数据,那么转账后就会修改为5900,而此时因为100块是错误的消费,所以需要回滚,此时账户就只有5900块了,凭空消失100块,所以只有A事务读取到B事务提交后的数据才能保证转账的正确性。这种场景就和买票的场景完全不同。

还是eg1的例子,此时修改隔离级别的SQL语句即可
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;/*只能读取其他事务提交的数据*/
START TRANSACTION;
SELECT empno, ename, sal FROM t_emp;
COMMIT;
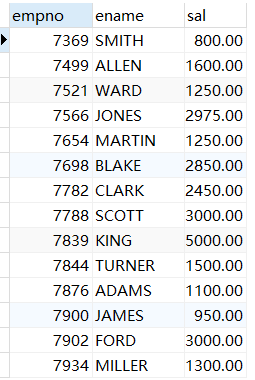
其他事物提交的数据都会同步到数据库表文件中,所以这里就是从数据库表文件中读取的数据。
11.6.3 repeatable read
场景三:你在淘宝或者京东等电商,点击购买,选好收货地址之类的之后,点击提交订单,就会让你输入支付密码支付,此时显示的价格是undo日志的价格,如果此时卖家涨价,你购买的还是涨价之前的价格,这种场景就是可重复读。
 新建一个查询1
新建一个查询1
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;/*事务在执行中反复读取数据,得到的结果是一致的*/
START TRANSACTION;
SELECT empno, ename, sal FROM t_emp;
这里一定要先执行一次select语句,保证undo日志拷贝过一次数据
再新建一个查询2
START TRANSACTION;
UPDATE t_emp SET sal=1;
此时数据库表文件的数据如下
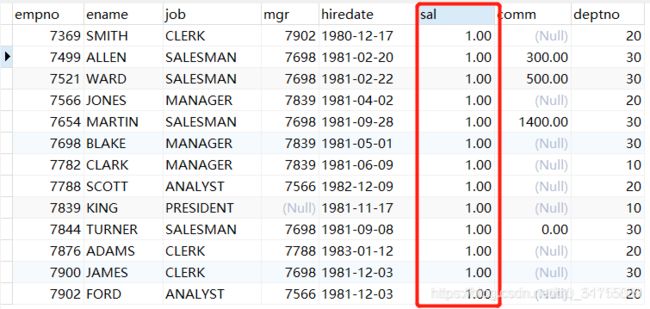
此时在查询1处执行SELECT empno, ename, sal FROM t_emp;
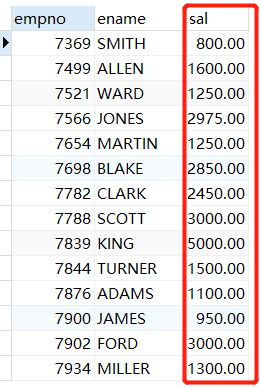
虽然数据库表文件的数据已经修改了,但是查询1处的事务隔离级别是可以反复读,每次都从undo日志里面读取,所以这里还是修改前的价格,直到提交commit,commit之后清空对应的undo日志记录,下次会重新从数据库文件里面拷贝数据,那个时候才是sal=1的数据。
注意:MySQL默认事务隔离级别就是REPEATABLE READ
11.6.4 serializable ???
由于事务并发执行所带来的各种问题,前三种隔离级别只适用于在某种业务场景中,凡事序列化的隔离性,让事务逐一执行,就不会产生上述问题了。但是序列化的隔离级别使用的特别少,它让事务的并发性大大降低。
第12章:触发器
触发器: trigger, 事先为某张表绑定好一段代码 ,当表中的某些内容发生改变的时候(增删改)系统会自动触发代码,执行.
触发器: 事件类型, 触发时间, 触发对象
-
事件类型: 增删改, 三种类型insert,delete和update
-
触发时间: 前后: before和after
-
触发对象: 表中的每一条记录(行)
一张表中只能拥有一种触发时间的一种类型的触发器: 最多一张表能有6个触发器
12.1 创建触发器
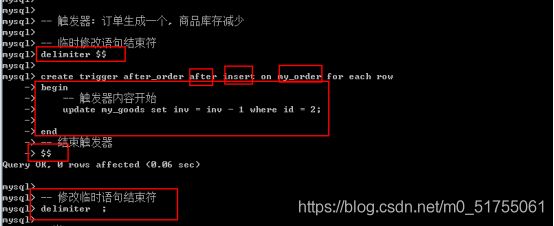
在mysql高级结构中: 没有大括号, 都是用对应的字符符号代替
触发器基本语法
– 临时修改语句结束符
Delimiter 自定义符号: 后续代码中只有碰到自定义符号才算结束
Create trigger 触发器名字 触发时间 事件类型 on 表名 for each row
Begin – 代表左大括号: 开始
– 里面就是触发器的内容: 每行内容都必须使用语句结束符: 分号
End – 代表右带括号: 结束
– 语句结束符
自定义符号
– 将临时修改修正过来
Delimiter ;
如果触发器内部只有一条要执行的SQL指令, 可以省略大括号(begin和end)
Create trigger 触发器名字 触发时间 事件类型 on 表名 for each row
一条SQL指令;
触发器: 可以很好的协调表内部的数据处理顺序和关系. 但是从JAVA角度出发, 触发器会增加数据库维护的难度, 所以较少使用触发器.
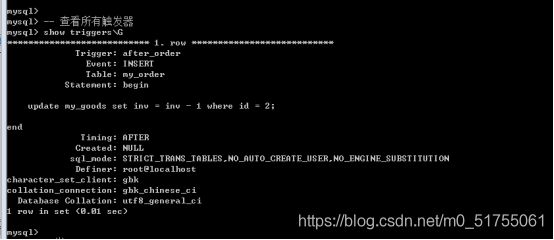
12.2 查看触发器
查看所有触发器或者模糊匹配
Show triggers [like ‘pattern’];
-
\g 的作用是分号和在sql语句中写’;’是等效的
-
\G 的作用是将查到的结构旋转90度变成纵向
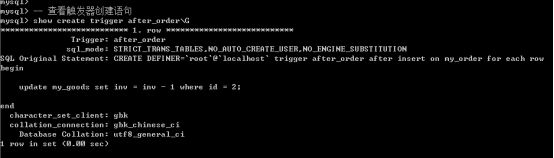
可以查看触发器创建语句
Show create trigger 触发器名字;
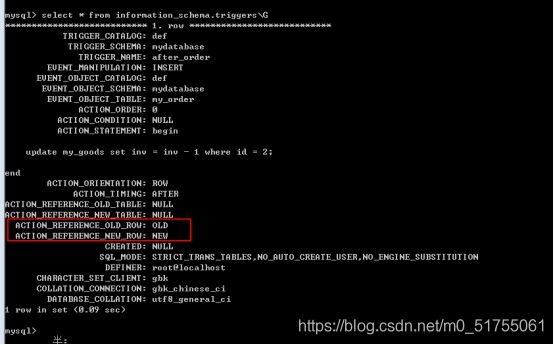
所有的触发器都会保存一张表中: Information_schema.triggers
12.3 使用触发器
触发器: 不需要手动调用, 而是当某种情况发生时会自动触发.(订单里面插入记录之后)
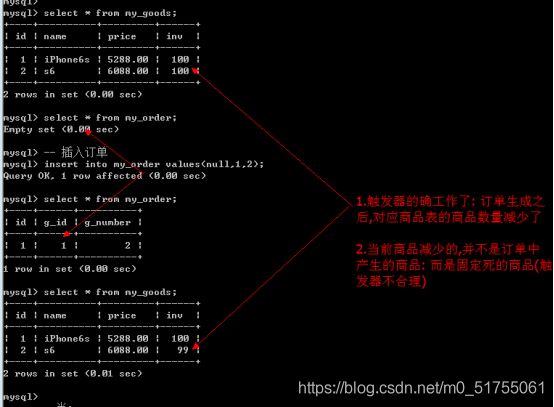
12.4 修改触发器&删除触发器
触发器不能修改,只能先删除,后新增.
Drop trigger 触发器名字;
12.5 触发器记录???
第13章:函数
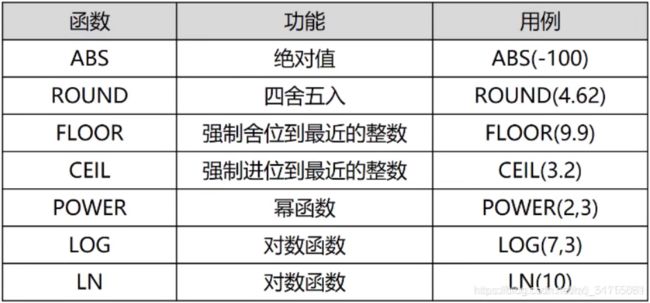
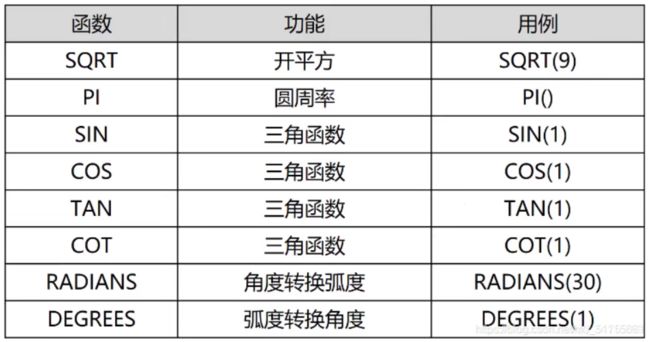
13.1 数字函数
eg:求四舍五入
select round(4.6288*100)/100;
13.2 日期函数
13.2.1 获取系统时间函数
- NOW()函数能获得系统日期和时间,格式yyyy-MM-dd hh:mm:ss,数据库的最小时间单位是秒s,而不是毫秒ms
- CURDATE()函数能获得当前系统日期,格式yyyy-MM-dd
- CURTIME()函数能获得当前系统时间,格式hh:mm:ss
SELECT NOW(), CURDATE(), CURTIME();

13.2.2 日期格式化函数
DATE_FORMAT(日期, 表达式)
该函数用于格式化日期,返回用户想要的日期格式
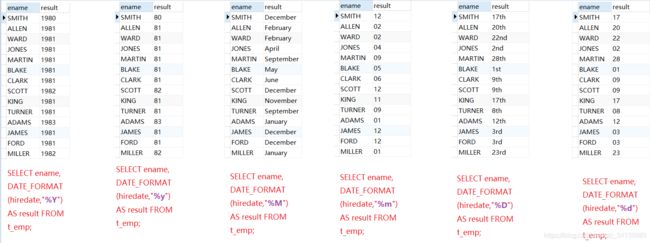
eg:比如查看员工入职的年份
SELECT ename, DATE_FORMAT(hiredate,"%Y") AS result FROM t_emp;
占位符说明
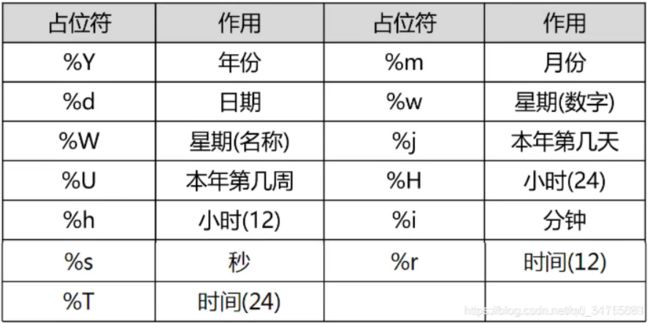
eg:查询某个日期是星期几
SELECT DATE_FORMAT("2021-1-1","%w");
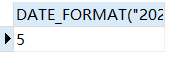
结果是星期5,如果是大写%W,那么就输出英文Friday
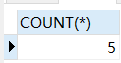
eg:利用日期函数,查询1981年上半年入职的员工有多少个
SELECT COUNT(*) FROM t_emp
WHERE DATE_FORMAT(hiredate,"%Y")=1981
AND DATE_FORMAT(hiredate,"%m")<=6;
13.2.3 日期偏移计算
注意:MySQL数据库里面,两个日期不能直接加减,日期也不能与数字加减
比如 select hiredate+1 from t_emp;
其实hiredate是"1980-12-18"变成了19801218,然后+1,结果是19801219
DATE_ADD(日期, INTERVAL 偏移量 偏移的时间单位)
该函数可以实现日期的偏移计算,而且时间单位很灵活
举几个例子
/*100天之后是什么时间*/
SELECT DATE_ADD(NOW(), INTERVAL 100 DAY);
/*300分钟之前是什么时间*/
SELECT DATE_ADD(NOW(), INTERVAL -300 MINUTE);
/*6个月零3天之前是什么时间*/
SELECT DATE_ADD(DATE_ADD(NOW(),INTERVAL -6 MONTH),INTERVAL -3 DAY)
把日期偏移函数和日期格式化函数混合用一下
eg:6个月零3天之前是什么时间,保留年月日即可
SELECT
DATE_FORMAT(DATE_ADD(DATE_ADD(NOW(),INTERVAL -6 MONTH), INTERVAL -3 DAY), "%Y/%m/%d");
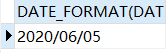
13.2.4 计算日期之间相隔的天数
DATEDIFF(日期1, 日期2)
该函数用来计算两个日期之间相差的天数为日期1-日期2。
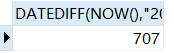
eg:比如计算现在和2019-1-1相差多少天
SELECT DATEDIFF(NOW(),"2019-1-1");
13.3 字符函数
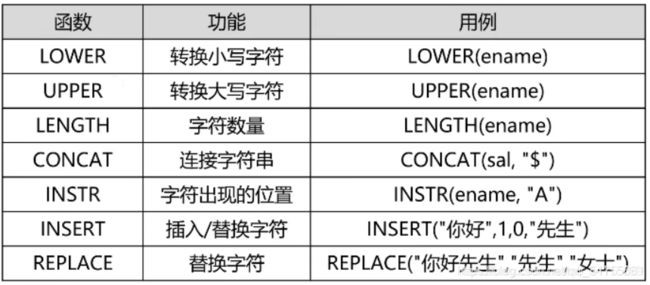
eg:查询员工表中姓名小写、姓名大写、姓名包含的字符数、底薪末尾添加$,姓名包含有A
SELECT
LOWER(ename), UPPER(ename), LENGTH(ename),
CONCAT(sal,"$"),INSTR(ename,"A")
FROM t_emp;
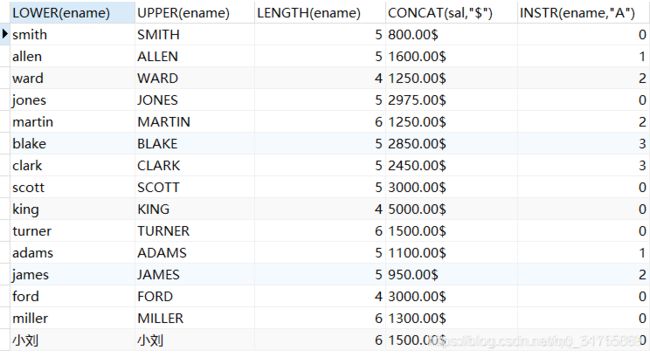
- 这里对于汉字,LOWER和UPPER函数是没有转换作用的,
- 对于LENGTH函数,因为这里的数据库编码是UTF8字符集,所以一个汉字占3个字节,长度为6,
- INSTR函数会返回首次出现A的位置,从1开始,如果没有包含A,则返回0。
INSERT例子
/*插入"先生"并替换从1开始的3个字符*/
SELECT INSERT("女士早上好", 1, 3, "先生");
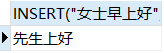
REPLACE例子
SELECT REPLACE("女士早上好","女士","先生");

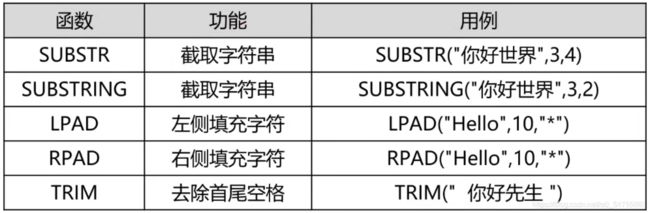
SUBSTR、SUBSTRING、LPAD、TRIM例子
SELECT SUBSTR("你好世界", 3, 4), SUBSTRING("你好世界", 3, 2),
LPAD(SUBSTRING("13312345678", 8, 4),11,"*"),
TRIM(" Hello World ");

说明:SUBSTR(“你好世界”, 3, 4)表示获取从1开始下标为[3,4]闭区间位置子串,SUBSTRING(“13312345678”, 8, 4)表示获取从下标8开始后面的4个字符,LPAD(SUBSTRING(“13312345678”, 8, 4),11,"")表示子串将由""左填充到11个字符的长度,TRIM就是去除首尾空格。
13.4 条件函数
13.4.1 简单条件判断
SQL语句可以利用条件函数来实现编程语言里的条件判断
IFNULL(表达式, 值)
IF(表达式, 值1, 值2)
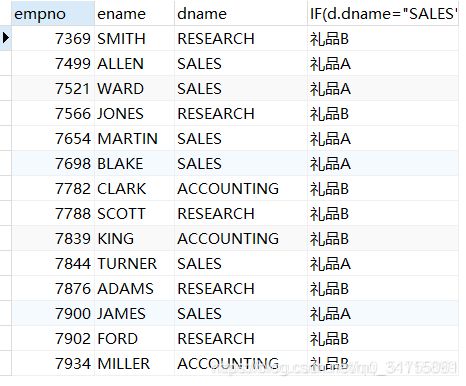
eg:SALES部门发放礼品A,其余部门发放礼品B,打印每名员工获得的礼品
SELECT
e.empno, e.ename, d.dname,
IF(d.dname="SALES","礼品A","礼品B")
FROM t_emp e JOIN t_dept d ON e.deptno=d.deptno;
13.4.2 复杂条件判断
复杂的条件判断可以用条件语句来实现,比IF语句功能更强大
CASE
WHEN 表达式 THEN 值1
WHEN 表达式 THEN 值2
...
ELSE 值N
END
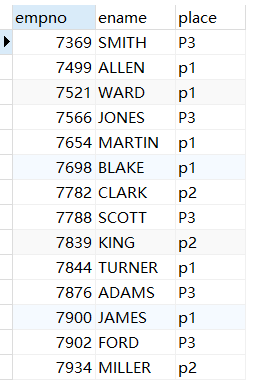
eg:公司集体旅游,每个部门目的地不同,SALES部门去P1地点,ACCOUNTING部门去P2地点,RESEARCH部门去P3地点,查询每名员工的旅行地点。
SELECT
e.empno, e.ename,
CASE
WHEN d.dname="SALES" THEN "p1"
WHEN d.dname="ACCOUNTING" THEN "p2"
WHEN d.dname="RESEARCH" THEN "P3"
END AS place
FROM t_emp e JOIN t_dept d ON e.deptno=d.deptno;
eg:公司调整员工基本工资,具体方案如下:
1.SALES部门中工龄超过20年,涨幅10%
2.SALES部门中工龄不满20年,涨幅5%
3.ACCOUNTING部门,涨幅300
4.RESEARCH部门里低于部门平均底薪,涨幅200
5.没有部门的员工,涨幅100
UPDATE t_emp e LEFT JOIN t_dept d ON e.deptno=d.deptno
LEFT JOIN (SELECT deptno, AVG(sal) avg FROM t_emp GROUP BY deptno) t
ON e.deptno=d.deptno
SET sal=(
CASE
WHEN d.dname="SALES" AND DATEDIFF(NOW(),e.hiredate)/365>=20
THEN e.sal*1.1
WHEN d.dname="SALES" AND DATEDIFF(NOW(),e.hiredate)/365<20
THEN e.sal*1.05
WHEN d.dname="ACCOUNTING" THEN e.sal+300
WHEN d.dname="RESEARCH" AND e.sal<t.avg THEN e.sal+200
WHEN e.deptno IS NULL THEN e.sal+100
ELSE e.sal
END
);
13.5 自定义函数
函数要素: 函数名, 参数列表(形参和实参), 返回值, 函数体(作用域)
13.5.1 创建函数
创建语法
Create function 函数名([形参列表]) returns 数据类型 – 规定要返回的数据类型
Begin
– 函数体
– 返回值: return 类型(指定数据类型);
End
定义函数
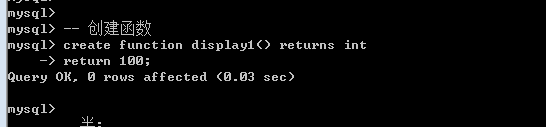
自定义函数与系统函数的调用方式是一样: select 函数名([实参列表]);

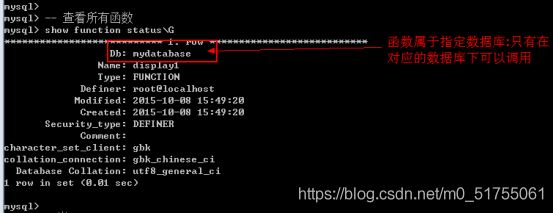
13.5.2 查看函数
查看所有函数: show function status [like ‘pattern’];
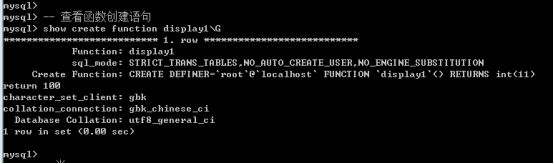
查看函数的创建语句: show create function 函数名;
13.5.3 修改函数&删除函数
函数只能先删除后新增,不能修改.
Drop function 函数名;
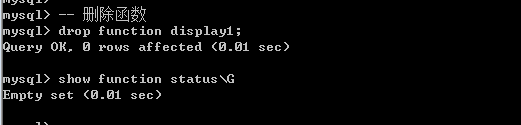
13.5.4 函数参数
参数分为两种: 定义时的参数叫形参, 调用时的参数叫实参(实参可以是数值也可以是变量)
形参: 要求必须指定数据类型
Function 函数名(形参名字 字段类型) returns 数据类型
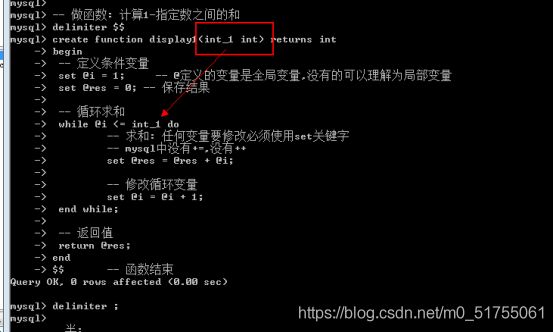
在函数内部使用@定义的变量在函数外部也可以访问
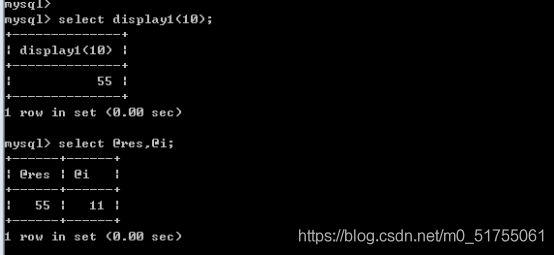
13.5.5 作用域
Mysql中的作用域与js中的作用域完全一样
全局变量可以在任何地方使用; 局部变量只能在函数内部使用.
-
全局变量: 使用set关键字定义, 使用@符号标志
-
局部变量: 使用declare关键字声明, 没有@符号: 所有的局部变量的声明,必须在函数体开始之前
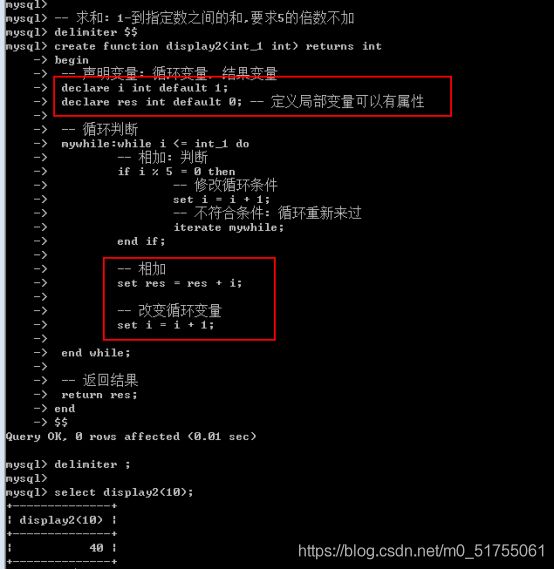
第14章:存储过程
-
存储过程简称过程,procedure, 是一种用来处理数据的方式.
-
存储过程是一种没有返回值的函数.
14.1 创建过程
Create procedure 过程名字([参数列表])
Begin
-- 过程体
End

14.2 查看过程
函数的查看方式完全适用于过程: 关键字换成procedure
查看所有过程: show procedure status [like ‘pattern’];
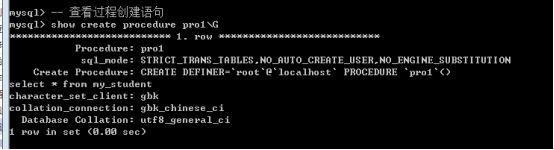
查看过程创建语句: show create procedure 过程名;
14.3 调用过程
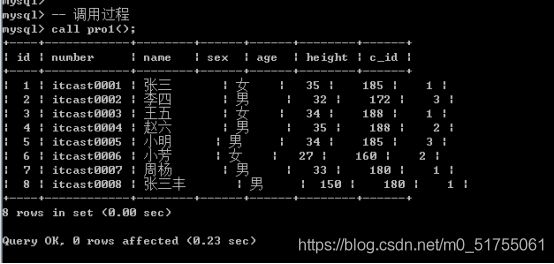
过程没有返回值: select是不能访问的.加粗样式

过程有一个专门的调用关键字: call
14.4 修改过程&删除过程
过程只能先删除,后新增
- Drop procedure 过程名;
14.5 过程参数
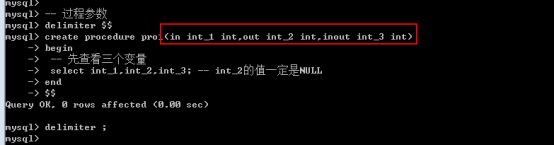
函数的参数需要数据类型指定, 过程比函数更严格.
过程还有自己的类型限定: 三种类型
-
In: 数据只是从外部传入给内部使用(值传递): 可以是数值也可以是变量
-
Out: 只允许过程内部使用(不用外部数据), 给外部使用的.(引用传递: 外部的数据会被先清空才会进入到内部): 只能是变量
-
Inout: 外部可以在内部使用,内部修改也可以给外部使用: 典型的引用传递: 只能传变量
基本使用
Create procedure 过程名(in 形参名字 数据类型, out 形参名字 数据类型, inout 形参名字 数据类型)
调用: out和inout类型的参数必须传入变量,而不能是数值
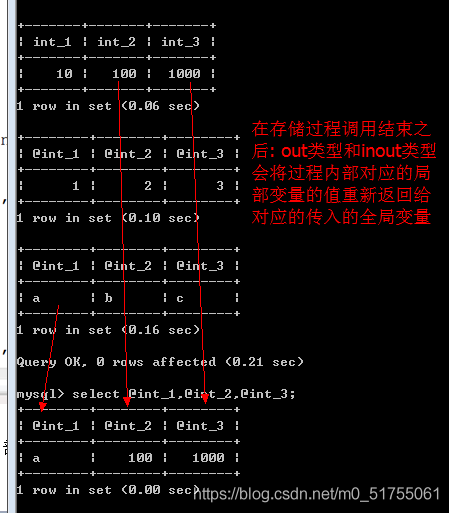
![]()
正确调用: 传入变量
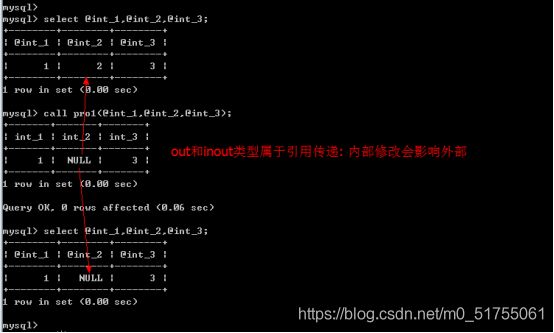
存储过程对于变量的操作(返回)是滞后的: 是在存储过程调用结束的时候,才会重新将内部修改的值赋值给外部传入的全局变量.
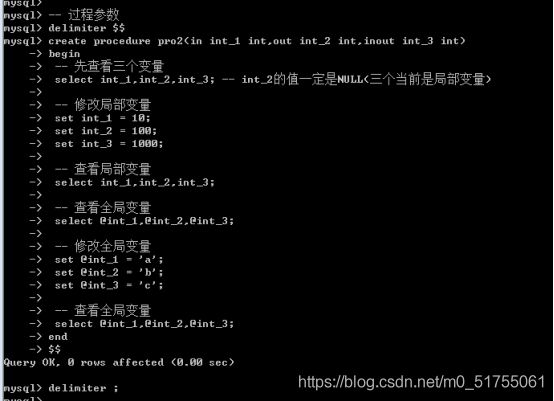
测试: 传入数据1,2,3: 说明局部变量与全局变量无关
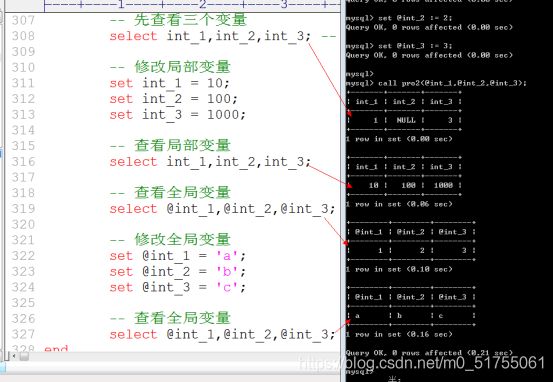
最后: 在存储过程调用结束之后, 系统会将局部变量重复返回给全局变量(out和inout)