【吐血整理】Python 常用的数学运算与统计函数(附视频讲解)
目录
- 一、abs 函数--获取数字的绝对值 [视频讲解](https://live.csdn.net/v/165274)
- 二、divmod 函数--获取两个数值的商和余数 [视频讲解](https://live.csdn.net/v/165276)
- 三、len 函数--获取对象的长度或项目个数
- 四、max 函数--获取可迭代对象(或元素)的最大值
- 五、min 函数--获取可迭代对象(或元素)的最小值
- 六、pow 函数--获取两个数值的幂运算值
- 七、round 函数--对数值进行四舍五入求值
- 八、sum 函数--对可迭代对象进行求和计算
一、abs 函数–获取数字的绝对值 视频讲解
abs() 函数用于获取数字的绝对值,其语法格式如下:
abs(x)
参数说明:
- x:表示数值,参数可以是整数、浮点数或者复数;
- 返回值:返回数字的绝对值。如果参数是一个复数,则返回复数的模。
补充说明:设复数 z=a+bi(a,b∈R),其中规定 i 为虚数单位,且(a、b是任意实数),我们将复数中的实数a称为复数z的实部(real part),记作Re z=a;实数b称为复数z的虚部(imaginary part),记作 Im z=b。当a=0且b≠0时,z=bi,我们就将其称为纯虚数。将复数的实部与虚部的平方和的正的平方根的值称为该复数的模,记作∣z∣。复数z的模|z|= a 2 + b 2 \sqrt[]{a^2+b^2} a2+b2
,它的几何意义是复平面上一点(a,b)到原点的距离。|z|2=(a+bi)(a-bi) 。例:
计算1:若 z=1+i,则 |z^2-2z| = ?
两个实部相等,虚部互为相反数的复数互为共轭复数(conjugate complex number)。复数z的共轭复数记作 z ‾ \overline{z} z
Python 中的复数与数学中的复数的形式完全一致,都是由实部和虚部组成,并且使用 j 或 J 表示虚部。当表示一个复数时,可以将实部和虚部相加,例如,一个复数,实部为 3.14,虚部为 12.5j,则这个复数为 3.14+12.5j。如下图所示:

【示例1】获取整数与浮点数的绝对值。在获取绝对值时,比较常见的数值就是整数与浮点数,使用abs()函数获取整数与浮点数绝对值的示例代码如下:
In [1]: abs(520) # 求整数绝对值
Out[1]: 520
In [2]: abs(-88) # 求负数绝对值
Out[2]: 88
In [3]: abs(-88.88) # 浮点负数绝对值
Out[3]: 88.88
In [4]: abs(0) # 求0绝对值
Out[4]: 0
【示例2】获取复数的模。
In [5]: abs(1-2j) # 获取1-2j复数的模
Out[5]: 2.23606797749979
In [6]: abs(1+5j)
Out[6]: 5.0990195135927845 # 获取1+5j复数的模
In [7]: abs(6*8j) # 获取6*8j复数的模
Out[7]: 48.0
In [8]: abs(-1-1j) # 获取-1-1j复数的模
Out[8]: 1.4142135623730951
【示例3】输出绝对值不大于3的所有整数。
num_list = [-3, -2, -1, 0, 1, 2, 9] # 创建一组整数列表
for num in num_list: # 遍历列表元素
if abs(num) <= 3: # 绝对值不大于3
print(num, end=" ") # 输出:-3 -2 -1 0 1 2
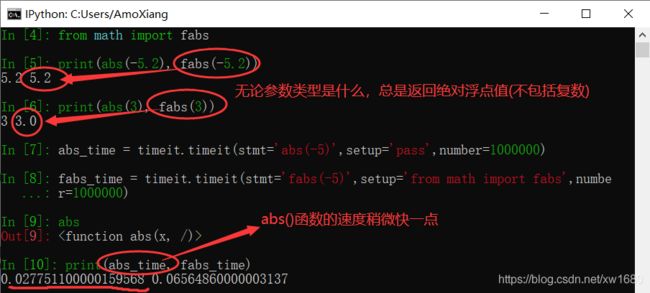
【示例4】abs()函数与math.fabs()方法的比较。
二、divmod 函数–获取两个数值的商和余数 视频讲解
divmod() 函数用于返回两个数值(非复数)相除得到的商和余数组成的元组。其语法格式如下:
divmod(x, y)
参数说明:
- x:被除数;
- y:除数;
- 返回值:返回由商和余数组成的元组。
【示例1】获取商和余数的元组。
print(divmod(9, 2)) # 被除数为9,除数为2 ==>(4, 1)
print(divmod(100, 10)) # 被除数为100,除数为10==>(10, 0)
print(divmod(15.5, 2)) # 被除数为15.5,除数为2==>(7.0, 1.5)
"""
说明:通过divmod()函数获取商和余数的元组时,元组中的第一个元素为商,第二个元素为余数。
提示:如果参数x和y都是整数,相当于(a//b,a%b)
如果参数x或y是浮点数,相当于(math.floor(a/b),a%b)
"""
【示例2】商和余数解决图书拆包问题。

示例代码如下:
books = [845, 1089, 988, 432, 675, 3246] # 图书册数
num = 16 # 每包16册
for b in books:
result = divmod(b, num) # 计算商和余数
# 输出结果
print(str(b) + '拆分为: ' + str(result[0]) + '包' + str(result[1]) + '册')
【示例3】负数取余问题。
print(divmod(30, -8)) # (-4, -2)
print(divmod(-30, -8)) # (3, -6)
print(divmod(-30, 8)) # (-4, 2)
【示例4】将时间秒数转换为"时:分:秒"的形式。
import datetime
seconds = 3888 # 秒数
# 第一种方法
m, s = divmod(seconds, 60)
h, m = divmod(m, 60)
# 第一种方式: 1:04:48
print('第一种方式:', f'{
h:d}:{
m:02d}:{
s:02d}') # 格式化输出
# 第二种方法:第二种方式: 1:04:48
se = str(datetime.timedelta(seconds=seconds))
print('第二种方式:', se)
三、len 函数–获取对象的长度或项目个数
len() 函数的主要功能是获取一个(字符、列表、元组等)可迭代对象的长度或项目个数。其语法格式如下:
len(s)
参数说明:
- 参数 s:要获取其长度或者项目个数的对象。如字符串、元组、列表、字典等;
- 返回值:对象长度或项目个数。
【示例1】获取字符串长度。
# 字符串中每个符号仅占用一个位置,所以该字符串长度为34
str1 = '今天会很残酷,明天会更残酷,后天会很美好,但大部分人会死在明天晚上。'
# 在获取字符串长度时,空格也需要占用一个位置,所以该字符串长度为10
str2 = 'hello word'
print('str1字符串的长度为:', len(str1)) # 打印str1字符串长度
print('str2字符串的长度为', len(str2)) # 打印str2字符串长度
# 打印str2字符串去除空格后的长度9
print('str2字符串去除空格后的长度为:', len(str2.replace(' ', '')))
【示例2】获取列表长度。
# 在获取列表长度时,len函数不会在意列表内元素的类型
list_ = [1, 2, 3, 4, '123', 2.15]
# 同时定义两个元素类型不同的列表
list1, list2 = [1, 2, 3], ['a', 'b', 'c']
list3 = ['库里', '杜兰特', '詹姆斯', '哈登', '威少'] # 定义一个列表
print('list列表的长度为 : ', len(list_)) # 打印list列表长度
print('list1列表的长度为: ', len(list1)) # 打印list1列表长度
print('list2列表的长度为:', len(list2)) # 打印list2列表长度
print('共有', len(list3), '名球员') # 获取列表元素个数
# 获取列表下标为1~4范围的长度,不包含下标为4的元素
print('列表中指定元素范围的长度为:', len(list_[1:4]))
【示例3】获取元组长度。
tuple1 = (1, 11, 111, 1111, 11111) # 创建元素长度不同的元组
print('tuple1元组长度为:', len(tuple1)) # 打印tuple1元组长度
print('元组中指定元素范围的长度为:', len(tuple1[1:3])) # 打印tuple1元组指定元素范围的长度
# 创建星期英文元组
tuple2 = ('Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday')
print('tuple2元组中元素长度最大为:', max(len(i) for i in tuple2)) # 打印tuple2元组中长度最大值
# 打印tuple2元组中长度最大的元素
print('tuple2元组中长度最大的元素为:', max(tuple2, key=lambda i: len(i)))
# 打印tuple2元组中长度最小的元素
print('tuple2元组中长度最小的元素为:', min(tuple2, key=lambda i: len(i)))
# 创建国际旅游胜地前四名的二维元组
tuple3 = (('威尼斯', 1), ('阿姆斯特丹运河', 2), ('马尔代夫', 3), ('迪拜', 4))
print('二维元组tuple3的长度为:', len(tuple3)) # 打印二维元组的长度
# 打印二维元组中旅游胜地名称最长的元组
print('旅游胜地名称最长的元组为:', max(tuple3, key=lambda i: len(i[0])))
【示例4】获取字典长度。
# 人物基本信息
dict_name = {
'Name': 'Aaron', 'Age': 18, 'height': 1.72, 'weight': 55, 'sex': 'g'}
print('dict_name字典长度度为:', len(dict_name)) # 打印dict_name字典长度
# 使用dict()函数创建一个字典
dictionary = dict((('邓肯', '石佛'), ('吉诺比利', '妖刀'), ('帕克', '跑车')))
print('字典:', dictionary) # 输出字典
print('字典中的元素个数为:', len(dictionary)) # 获取字典中的元素个数
# 某淘汰比赛中,前五名的参赛人员与对应编号
dict_info = {
'17123': {
'name': 'Lee'},
'121234': {
'name': 'Jeff'},
'153': {
'name': 'Rodriguez'},
'16423': {
'name': 'Jackson'},
'1344349': {
'name': 'Williams'}}
# 打印参赛编号最长的那位参赛者名称
print('获取数据中参赛编号最长的那位参赛者名称:',
max(dict_info.items(), key=lambda i: len(i[0]))[1].get('name'))
# 打印赛者名称最长的那位参赛者名称
print('获取参赛者名称最长的那位参赛者名称:',
max(dict_info.items(), key=lambda i: len(i[1].get('name')))[1].get('name'))
【示例5】计算一个字符串中包含“aeiou”这5个字符的数量。
import re
def count_vowels(str):
# 使用正则表达式匹配所有包括aeiou的字符,然后计算长度
return len(re.findall(r'[aeiou]', str, re.IGNORECASE))
print(count_vowels('foobar')) # 3
print(count_vowels('gym')) # 0
【示例6】判断列表中的元素是否有重复的。
def all_unique(lst):
# 先将列表转化为集合,利用集合去重功能,删除重复元素,然后再和原来的列表对比
return len(lst) == len(set(lst))
x = [1, 1, 2, 2, 3, 2, 3, 4, 5, 6]
y = [1, 2, 3, 4, 5]
print(all_unique(x)) # False
print(all_unique(y)) # True
【示例7】计算字符串的字节长度。
def byte_size(string):
return len(string.encode('utf-8')) # 使用encode()函数设置编码格式
print(byte_size('Hello World')) # 11
print(byte_size('人生苦短,我用Python')) # 27
【示例8】根据指定字符长度添加符号或字符。
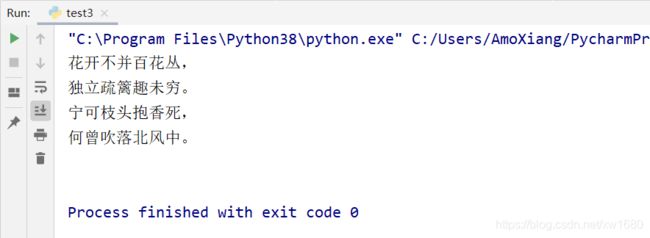
# 古诗字符串
str_text = '花开不并百花丛独立疏篱趣未穷宁可枝头抱香死何曾吹落北风中'
list_text = [] # 保存筛选诗句的列表
# 通过字符串长度遍历字符串文字下标,由于0求余等于0所以需要从1开始并加1
for i in range(1, len(str_text) + 1):
# 通过指定字符串下标的方式将字符串中文字添加至列表中
list_text.append(str_text[i - 1])
if i % 7 == 0: # 每七个字为一句,此处求满足七字条件
if i % 2 == 0: # 偶数添加句号
list_text.append('。\n')
else: # 奇数添加逗号
list_text.append(',\n')
print(''.join(list_text)) # 打印将列表元素拼接成字符串
程序运行结果如下图所示:
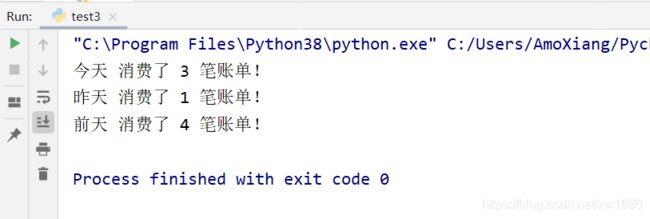
【示例9】统计每天手机消费账单数量。
# 模拟账单数据
bill = {
'今天': [{
'time': '07:40', '金额': -6.5, '订单号': '22001407'},
{
'time': '07:54', '金额': -21, '订单号': '22001430'},
{
'time': '08:22', '金额': -11, '订单号': '22101511'}],
'昨天': [{
'time': '07:40', '金额': -6.5, '订单号': '22001447'}],
'前天': [{
'time': '07:00', '金额': -13.2, '订单号': '22001431'},
{
'time': '07:26', '金额': -10, '订单号': '22001433'},
{
'time': '08:05', '金额': -3, '订单号': '22001561'},
{
'time': '08:22', '金额': -2.5, '订单号': '22001766'}]}
for key in bill.keys(): # 遍历都有哪天的账单
print(key, '消费了', len(bill.get(key)), '笔账单!') # 打印每天账单的数量
程序运行结果如下图所示:
四、max 函数–获取可迭代对象(或元素)的最大值
max() 函数是 python 开发中使用较多的函数,主要功能为获取传入的多个参数的最大值,或者传入的可迭代对象(或之中的元素)的最大值。其语法格式如下:
max(iterable, *[, key, default])
# max(arg1, arg2, *args[, key])
参数说明:
- iterable:可迭代对象,如字符串、列表、元组、字典等;
- default:命名参数,用来指定最大值不存在时返回的默认值;
- key:命名参数,其为一个函数,用来指定获取最大值的方法;
- arg:指定数值;
- 返回值:返回给定参数的最大值。
使用 max() 函数,如果是数值型参数,则取数值大者;如果是字符型参数,取字母表排序靠后者。当 max() 函数中存在多个相同的最大值时,返回的是最先出现的那个最大值。注意:用 max 获取元素中的最大值,本质是获取元素的编码值大小,谁的编码值大,谁就最大。如果是数字和英文字母、标点,看谁的 ASCII 码值大小就可以了。汉字的编码值大于数字、英文字母和英文标点符号,常用数字、字目和标点的 ASCII 码值对照表如下图所示:
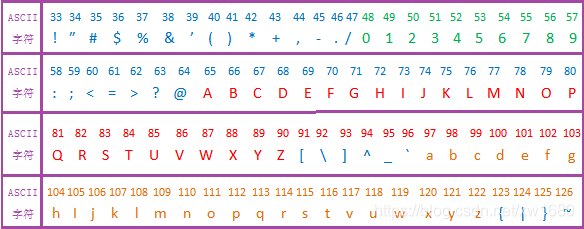
说明:字符串按位比较,两个字符串第一位字符的 ascii 码谁大,字符串就大,不再比较后面的;第一个字符相同就比第二个字符串,以此类推。
【示例1】在字符、数字、标点及汉字中取最大值。
num1 = '123456789' # 数字的ASCII码范围49-57之间 !‘#$%&‘()*+,-./的ASCII码范围33—47之间
num2 = '35*120-2020=?' # * - = ?的ASCII码分别是 42 45 61 63
print(max(num1)) # 1-9数字的ASCII码是49-57,9的ASCII码值是57,所以输出9
print(max(num2)) # ?的ASCII码是63,其他标点符号和数字的ASCII码都小于63,所以输出?
print(num2, max(num2), num2.index(max(num2))) # 输出数字num2、num2的最大值和最大值的索引
# 参数是一个空的可迭代对象时,必须指定命名参数default
print(max((), default=100))
chart1 = 'abcdefghijkABCDEFGHI' # 大写字母的ASCII范围65~73 小写字母的ASCII范围 97~107
print(max(chart1)) # k的ASCII码值107,其他字母、标点符号和数字的ASCII码都小于107,所以输出k
chart2 = 'lmnopqxyz123456789' # 小写字母的ASCII码值比数字的ASCII码值要大
print(max(chart2)) # z的ASCII码是122,在这些元素中最大
print(chart2, max(chart2), chart2.index(max(chart2))) # 输出chart2、chart2的最大值和最大值对应的索引
print(chart2.replace(max(chart2), 'ss')) # 将chart2的最大值替换为ss
chart3 = 'john,23,2002.06.02' # 用max()函数获取字母、数字和标点最大值,就是求ASCII值最大者
print(max(chart3[5:])) # 从字符串第5个元素开始获取最大的元素
print(max(chart3), min(chart3)) # 输出chart3的最大值和最小值
chart4 = '.,*56789ABCdeabcef~{' # 字母的ASCII编码值>数字的ASCII码值,标点符号的ASCII值范围较大
print(max(chart4)) # k的ASCII码是126,在这些元素中是最大的
print(max(chart4[-8:-2:2])) # 从字符串的最后一位开始到倒数第8个字符,步进值为2获取最大元素
chart5 = '莱科宁358english' # 汉字的编码值比数字、字母和英文标点的值都大
print(max(chart5)) # “莱”的码值为33713,“科”的码值为31185,“宁”的码值为23425
print(max(x for x in range(10))) # 生成10以内的数字并获取最大值输出
【示例2】在列表中使用max()函数。
listnum1 = [1, 3, 5, 7, 9] # 创建整数数字列表
listnum2 = [-10, -5, 0, 5, 3, 10, 15, -20, 25, -39, -123] # 创建包含负数的数字列表
print(max(listnum1)) # 输出listnum1的最大值
print(max(listnum2)) # 输出listnum2的最大值
print(max(listnum2, key=lambda x: abs(x))) # 获取listnum2列表中元素绝对值的最大值,abs():绝对值函数
print(max(listnum2[2:7])) # 在列表第2项到第7项(不含第7项)求最大值
listcha1 = ['a', '-5', 'b', 'c', 'd', '5', '3', 'e'] # 创建包含数字、字母的列表
print(max(listcha1)) # 小写字母的ASCII码值大于数字,并且按照字母排序递增
print(max(listcha1[1:5])) # 在列表第1项到第5项(不含第5项)求最大值
list1 = ['20', 5, 10] # 元素为混合类型的列表
print(max(list1, key=int)) # 指定key为int()函数后再取最大值
# 创建F1赛车车手积分列表,积分在后,练习对列表中数据不同位置元素求最大值
listcha2 = ['莱科宁 236', '汉密尔顿 358', '维泰尔 294', '维斯塔潘 216', '博塔斯 227']
# 创建F1赛车车手积分列表,积分在前
listcha3 = ['236 莱科宁', '358 汉密尔顿', '294 维泰尔', '216 维斯塔潘', '227 博塔斯']
print(max(listcha2)) # 输出为:莱科宁 236
print(max(listcha2[-3:-1])) # 输出为:维泰尔 294 在倒数第3个元素和倒数第2个元素查找最大值
print(max(listcha2, key=lambda x: x[-3:])) # 获取每个列表的倒数3个元素的最大值,即比较积分
print(max(listcha3)) # 输出为:358 汉密尔顿
# 取每个列表的第4项到最后一项的数据比较获取最大值,即获取姓名的最大值
print(max(listcha3, key=lambda x: (x[4:])))
# 创建汽车销量2维列表,内层列表中包含汽车销量和汽车名称
listcar = [[837624, 'RAV4'], [791275, '途观'], [651090, '索罗德'], [1080757, '福特F系'], [789519, '高尔夫'], [747646, 'CR-V'],
[1181445, '卡罗拉']]
print(max(listcar)) # 输出列表listcar的最大值
print(max(listcar, key=lambda x: x[1])) # 按照列表listcar的第2项(车名)进行迭代取最大值
# 创建NBA球员数据嵌套列表,嵌套列表中包含球员名称、出场场次、出场时间和平均得分
listnba = [['哈登', 78, 36.8, 36.1], ['乔治', 77, 36.9, 28.0], ['阿德托昆博', 72, 32.8, 27.7], ['恩比德', 64, 33.7, 27.5],
['詹姆斯', 55, 35.2, 27.4], ['库里', 69, 33.8, 27.3]]
print(max(listnba)) # 输出列表listnba的最大值
print(max(listnba, key=lambda x: x[3])) # 按照列表的第4项,即球员的场平均分迭代取最大值
print(max(listnba, key=lambda x: (x[2], x[1], x[3]))) # 按照第3项出场时间迭代取最大值
print(max(listnba, key=lambda x: x[3] * x[1])) # 按球员平均得分和比赛场次的乘积(即总得分)迭代求最大值
print(max(listnba, key=lambda x: (str(x[3]))[1:])) # 按平均分的后3位迭代求最大值
# 创建学生考试成绩嵌套列表,嵌套列表包含考试名次、语文成绩、数学成绩、理综成绩、英语成绩
liststud = [[1, 101, 128, 278, 123], [2, 129, 135, 222, 120], [3, 127, 138, 227, 107], [4, 98, 135, 217, 108],
[5, 123, 101, 201, 101], [6, 89, 125, 197, 90]]
print(max(liststud[1])) # 输出为:222 取第2个列表中元素的最大值
# 输出为:[2, 129, 135, 222, 120] 按照每个列表第2项迭代
print(max(liststud, key=lambda x: x[1]))
# 按每个列表元素的第2项到第5项的和迭代取最大值
print(max(liststud, key=lambda x: x[1] + x[2] + x[3] + x[4]))
【示例3】在元组中使用max()函数。
tuple1 = (2, 4, 8, 16, 32, 64, 128, 256, 512, 1024) # 数字元组
print(max(tuple1)) # 输出数字元组中的最大值
print(max(tuple1[3:9])) # 输出数字元组中第4个到第9个数值的最大值
tuple2 = ('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug',
'Sept', 'Oct', 'Nov', 'Dec', 'Mon', 'Tues', 'Wed', 'Thur', 'Fri') # 月份、星期简写元组
print(max(tuple2)) # 输出tuple2的最大值(先比较元组的第1个元素,如果相同,再比较第2个元素…)
print(max(tuple2, key=lambda x: len(x))) # 输出元组中长度最大(即字符最多)的元组
# NBA球队成绩元组
tuple3 = ('勇士 57', '掘金 54', '开推者 53', '火箭 53', '爵士 50', '雷霆 49', '马刺 48', '快船 48')
print(max(tuple3, key=lambda x: x[-2:])) # 获取元组后两项数据的最大值,即获胜场次取最大值
tuple4 = (('肖申克的救赎', 1994, 9.3), ('教父', 1972, 9.2), ('教父2', 1974, 9.1),
('蝙蝠侠:黑暗骑士', 2008, 9.0), ('低俗小说', 1994, 8.9)) # 电影信息元组
print(max(tuple4, key=lambda x: x[1])) # 按每个元组的第2项取最大值,即出品年份
print(max(tuple4, key=lambda x: x[2])[0]) # 按元组的第3项(打分)取最大值,只输出最大值的第一个元素
tuple5 = ((90, 128, 87.103), (78, 99, 134.106), (98, 102, 133.80), (66, 78, 97.56), (98, 123, 88.79))
print(max(max(tuple5, key=lambda x: x[1]))) # 按照tuple5的第2项取最大值,然后在最大值中再取最大值
print(max(tuple5, key=lambda x: (x[0] + x[1] + x[2]))) # 按照元组的3项之和获取最大值
print(max(tuple5, key=lambda x: (x[0], x[1]))) # 按元组第1项和第2项取最大值,第1项相同,比较第2项
【示例4】在字典中使用max()函数。
dict1 = {
'name': 'john', 'age': 23, 'money': 1200, 'gender': 'male'} # 创建会员信息字典,name为会员姓名
dict2 = {
'name': 'anne', 'age': 22, 'money': 1500, 'gender': 'female'} # 创建会员信息字典,age为会员年龄
dict3 = {
'name': 'james', 'age': 33, 'money': 578, 'gender': 'male'} # 创建会员信息字典,money为会员账户积分
# 创建会员信息字典,gender为会员性别,male为男性,female为女性
dict4 = {
'name': 'nick', 'age': 46, 'money': 158, 'gender': 'male'}
dict5 = {
'name': 'May', 'age': 18, 'money': 3210, 'gender': 'female'} # 创建会员信息字典
lsitdc = [dict1, dict2, dict3, dict4, dict5] # 创建2维会员信息字典
print(max(dict1)) # 默认获取键的最大值,即'name''age''money'和'gender'的最大值
# 将性别为女性的年纪最大的会员输出出来,一定要先限制性别,再按年纪取最大值,否则将按年纪排名,不区分性别
print(max(list(filter(lambda item: item['gender'] == 'female', lsitdc)), key=lambda item: item['age']))
# 输出积分超过500,年龄最大的的会员
print(max(list(filter(lambda item: item['money'] > 500, lsitdc)), key=lambda item: item['age']))
print(max(lsitdc, key=lambda x: x['money'])) # 按积分输出最大者
print(max(lsitdc, key=lambda x: x['age']).get('name')) # 输出年龄最大会员,只输出名字
def dic_key(dic): # 编写函数dic_key,设置max()函数的获取最大值的键
return dic['money'] # 设置'money'为max()函数获取最大值的键
print(max(lsitdc, key=dic_key)) # 调用dic_key函数,获取字典中积分最高的会员
dictcar = [{
'名称': '卡罗拉', '销量': 1181445}, {
'名称': '福特F系', '销量': 1080757}, {
'名称': 'RAV4', '销量': 837624},
{
'名称': '思域', '销量': 823169}, {
'名称': '途观', '销量': 791275}]
print(max(dictcar, key=lambda x: x['名称'])) # 按照名称取最大值,即'卡罗拉''福特F系'等中取最大值
print(max(dictcar, key=lambda x: x['销量'])) # 按照销量取最大值,即1181445、1080757...等中取最大值
dictage = {
'李冰冰': '1996', '张步韵': '1999', '赵构': '1903', '邱子丹': '2008', '杨百风': '2012'}
print(max(dictage)) # 默认获取键的最大值,即'李冰冰''张步韵'…'杨百风'等的最大值
print(max(dictage.values())) # 用value取最大值,需要设定值(values)为迭代项
# 最大值对应的键
print(list(dictage.keys())[list(dictage.values()).index(max(dictage.values()))])
print(max(dictage.values())[-2:]) # 获取value最大值项的后两个字符
print(max([x for x in dictage.keys()])) # 在字典中获取键(key)最大的项
print(max([x for x in dictage.values()])) # 在字典中获取值(value)最大的项
# 用zip()函数将字典的键和值调换位置,然后获取最大值
print(max(zip(dictage.values(), dictage.keys())))
dictall = {
'大众': 643518, '奔驰': 319163, '宝马': 265051, '福特': 252323, '雪铁龙': 227967, '雷诺': 130825, '现代': 114878,
'奥迪': 255300}
newdict = zip(dictall.values(), dictall.keys()) # 用zip()函数将字典的键和值调换位置
print(max(newdict)) # 获取新生成字典的最大值
print(max(zip(dictall.values(), dictall.keys()), key=lambda x: x[1])) # 按位置置换后字典value取最大值
【示例5】获取字符串、列表、元组、集合与字典中最大值。
a_str = ['刀', '枪', '剑', '戟'] # 字符型列表
a_int = [1, 2, 3, 4] # 数值型列表
b_int = [2, 4, 6, 8]
print('字符串中最大值为:', max('HELLO WORLD'))
print('直接指定参数中的最大值:', max(7, 9, 3, 2, 1))
print('字符列表中最大元素为:', max(a_str))
print('数值型最大列表为:', max(a_int, b_int))
a_tuple = (1, 3, 5, 7, 9) # 数值元组
print('元组中最大值为:', max(a_tuple))
a_set = {
2, 4, 6, 8, 0} # 数值型集合
print('集合中最大值为:', max(a_set))
a_dict = {
1: 2, 3: 4, 5: 6} # 字典
print('字典中最大值为:', max(a_dict)) # 默认情况下获取字典中键的最大值
【示例6】自定义key的方法。
lis = [1, 100, 111, 2, -2, 2.57, -223] # 定义测试数据
ma = max(lis) # 取原数据的最大值
print(ma)
ml = max(lis, key=lambda x: abs(x)) # 转换为绝对值后再取最大值
print(ml)
def funn(x):
return pow(x, 3) # 计算x的立方
mf = max(lis, key=funn)
print(mf)
五、min 函数–获取可迭代对象(或元素)的最小值
min() 函数用于执行与 max() 函数相反的操作,用于获取指定的多个参数中的最小值或可迭代对象元素中的最小值。其语法格式如下:
min(iterable, *[, default=obj, key=func])
# min(arg1, arg2, *args, *[, key=func])
参数说明:
- iterable:可迭代对象,如字符串、列表、元组、字典等;
- default:命名参数,用来指定最小值不存在时返回的默认值;
- key:命名参数,其为一个函数,用来指定获取最小值的方法;
- arg:指定数值;
- 返回值:返回给定参数的最小值。
说明:min() 函数在参数使用上与 max() 函数基本一致,只是在执行上是与 max() 函数相反的操作。
【示例1】取字符、数值、标点及汉字中的最小值。
str1 = '0123456789' # 数字-字符串
str2 = 'abcdABCD' # 字母-字符串
str3 = '你好' # 汉字-字符串
str4 = '!~@#¥%……&*' # 符号-字符串
print('数字-字符串最小值为:', min(str1))
print('字母-字符串最小值为:', min(str2))
print('汉字-字符串最小值为:', min(str3))
print('符号-字符串最小值为:', min(str4))
# 获取多个数值中的最小值
print(min(6, 8, 10, 6, 100))
print(min(-20, 100 / 3, 7, 100))
print(min(0.2, -10, 10, 100))
【示例2】在列表中使用min()函数。
import random # 导入随机数模块
list1 = [98, 79, 88, 100, 56, 100] # 元素为数值的列表
list2 = [-80, -20, -10] # 元素为负数的列表
list3 = ['1', '2', '5', '8'] # 元素为字符串数字的列表
list4 = ['你', '好', 'p', 'y', 't', 'h', 'o', 'n'] # 元素为汉字与英文字母的列表
print('list1列表中最小值为:', min(list1))
print('list2列表中最小值为:', min(list2))
print('list3列表中最小值为:', min(list3))
print('list4列表中最小值为:', min(list4))
list5 = [1, -3, 5, -7, 8] # 包含正、负数的列表
list6 = [3, 3.15, 2.11, 6] # 包含小数的列表
# 指定键为求绝对值函数,参数会进行求绝对值后再取较小者
print('list5列表中最小值为:', min(list5, key=abs))
# 获取小数中的绝对值
print('list6列表中最小值为:', min(list6))
seq = [] # 空列表
i = 0
while i < 10: # 循环10次
# 每循环一次向列表中添加一个随机数
seq.append(random.randint(1, 100))
i += 1
getMin = min(seq) # 获取最小值
print('原列表值:', seq)
print('列表最小值:', getMin)
【示例3】在元组中使用min()函数。
num = (7, 14, 21, 28, 35, 42, 49, 56, 63) # 创建一个数值元组
team = ('马刺', '火箭', '勇士', '湖人') # 创建字符元组
print('num元组中的最小值为:', min(num))
print('team元组中的最小值为:', min(team))
name = ('Jack', 'MacKenzie', 'Cal', 'Rainbo', 'Ralph', 'Abagael') # 英文名字元组
print('英文名字元组中的最小值为:', min(name))
print('英文名字长度最小的是:', min(name, key=lambda i: len(i)))
fraction = ('数学 98', '英语 99', '语文 93') # 学生成绩
print('成绩最差的学科为:', min(fraction, key=lambda i: i[3:])[:3])
# 北、上、广、深GDP值
gdp = (('北京', '30320亿'), ('上海', '32679亿'), ('广州', '23000亿'), ('深圳', '24620亿'))
print('GDP值最低的是元组中下标为', gdp.index(min(gdp, key=lambda i: i[1][0:6])), '的那组数据')
print('GDP值最低的城市为:', min(gdp, key=lambda i: i[1][0:6])[0])
【示例4】在字典中使用min()函数。
# qq号数据
qq = {
'小明qq': 875897, '小红qq': 5343215, '小李qq': 77582, '小华qq': 873541843}
print('qq号码最短的是:', min(qq.values(), key=lambda i: i))
print('最短的qq号码是:', min(qq.items(), key=lambda i: i[1])[0][:2], '的')
city = ['北京', '天津', '上海', '长春'] # 城市列表
temperature = ['29', '30', '23', '22'] # 温度列表
dict1 = dict(zip(city, temperature)) # 通过映射函数创建字典
print('温度最低的数据为:', min(dict1.items(), key=lambda i: i[1]))
print('温度最低的城市为:', min(dict1.items(), key=lambda i: i[1])[0])
# 模拟人员技能工资数据
dict2 = {
'布兰特': {
'月薪': 3800, '技能等级': '3级'},
'查尔斯': {
'月薪': 2600, '技能等级': '2级'},
'爱德华': {
'月薪': 6300, '技能等级': '6级'}}
print('技能等级最低的员工是:', list(dict2.keys())[list(dict2.values()).
index(min(dict2.values(), key=lambda i: i['技能等级']))])
print('月薪最低的那员工的技能等级为:', min(dict2.values(), key=lambda i: i['月薪'])['技能等级'])
print('月薪最低值为:', min(dict2.values(), key=lambda i: i['月薪'])['月薪'])
# 将月薪最低员工的工资调整为3500
min(dict2.values(), key=lambda i: i['月薪'])['月薪'] = 3500
print('调整后的人员技能工资数据为:\n', dict2)
【示例5】删除字符串中出现次数最少的字符。
from collections import defaultdict
a = input('请输入一个字符串(按下Enter结束):')
dd = defaultdict(int) # 创建一个值默认为 0 的字典
for i in a:
dd[i] += 1 # 统计各个字符的出现次数
for i in dd: # 删除出现次数最少的字符
if dd[i] == min(dd.values()):
a = a.replace(i, '')
print(a)
程序运行结果如下:
六、pow 函数–获取两个数值的幂运算值
pow() 函数用于返回两个数值的幂运算值,如果提供可选参数 z 的值,则返回幂乘结果之后再对 z 取模。其语法格式如下:
pow(x, y[, z])
参数说明:
- x:必需参数,底数;
- y:必需参数,指数;
- z:可选参数,对结果取模。
- 返回值:结果返回 x 的 y 次方(相当于 x**y),如果提供 z 的值,则返回结果之后再对 z 求余(相当于pow(x,y)%z)。
【示例1】获取两个数值的幂运算值。
# 参数x和y都是整数,则结果也是整数,除非y是负数,如果y是负数,则结果返回的是浮点数
print(pow(3, 2)) # 相当于print(3**2) 9
print(pow(-2, 7)) # x参数为负数 -128
print(pow(2, -2)) # y参数为负数 0.25
# 参数x和y有一个是浮点数,则结果将转换成浮点数
print(pow(2, 0.7)) # 1.624504792712471
print(pow(3.2, 3)) # 32.76800000000001
【示例2】获取幂运算值与指定整数的模值。
# 指定参数z的值,参数x和y必须为整数,且参数y不能为负数
print(pow(2, 3, 3)) # 相当于print(pow(2,3)%3)
七、round 函数–对数值进行四舍五入求值
round() 函数用于返回数值的四舍五入值,其语法格式如下:
round(number[, ndigits])
参数说明:
- number:表示需要格式化的数值;
- ndigits:可选参数,表示小数点后保留的位数;
- 如果不提供 ndigits 参数(即只提供number参数),四舍五入取整,返回的是整数;
- 如果把参数 ndigits 设置为0,则保留0位小数进行四舍五入,返回的值是浮点型。
- 如果参数 ndigits 大于0,则四舍五入到指定的小数位;
- 如果参数 ndigits 小于0,则对浮点数的整数部分进行四舍五入,参数 ndigits 用来控制对整数部分的后几位进行四舍五入,小数部分全部清0,返回类型是浮点数。如果传入的整数部分位数小于参数 number 的绝对值,则返回 0.0。
- 返回值:返回四舍五入值。
使用 round() 函数四舍五入的规则如下:
如果保留位数的后一位是小于5的数字,则舍去。例如,3.1415保留两位小数为3.14。
如果保留位数的后一位是大于5的数字,则进上去。例如,3.1487保留两位小数为3.15。
如果保留位数的后一位是5,且该位数后有数字,则进上去。例如,8.2152保留两位小数为8.22;又如8.2252保留两位小数为8.23。
如果保留位数的后一位是5,且该位数后没有数字。要根据保留位数的那一位来决定是进上去还是舍去:
如果是奇数则进上去,如果是偶数则舍去。例如,1.35保留一位小数为1.4;又如1.25保留一位小数为1.2。
【示例1】小数点右侧四舍五入求值。
print(round(3.1415926)) # 3
print(round(3.1415926, 0)) # 3.0
print(round(3.1415926, 3)) # 3.142
print(round(-0.1233, 2)) # -0.12
print(round(20 / 6, 2)) # 3.33
print(round(10.15, 1)) # 10.2
print(round(10.85, 1)) # 10.8
注意:在使用round()函数对浮点数进行操作时,有时结果不像预期那样,比如round(2.675,2)的结果是2.67而不是预期的2.68,这不是bug,而是浮点数在存储的时候因为位数有限,实际存储的值和显示的值有一定误差。除非对浮点数精确度没什么要求,否则尽量避开用round()函数进行四舍五入求值。

【示例2】小数点右侧四舍五入求值。
print(round(23645.521, -1)) # 23650.0
print(round(23645.521, -2)) # 23600.0
print(round(23645.521, -3)) # 24000.0
print(round(23645.521, -6)) # 0.0
【示例3】整数四舍五入求值。
print(round(23665)) # 23665
print(round(23665, -2)) # 23700
print(round(23665, -4)) # 20000
【示例4】解决round()函数出现的5不入的情况。
In [13]: round(2.675,2)
Out[13]: 2.67
In [14]: round(1.25,1)
Out[14]: 1.2
出现这种结果与浮点数的精度有关。在计算机中浮点数不一定能精确表达,因为换算成一串 1 和 0 后可能是无限位数的情况,这时计算机会自动进行截断处理。那么在计算机中保存的 1.25 可能要比实际数字小一点点。正因为小了一点点就导致了它离 1.2 要更近一点点,所以保留一位小数时就近似到了 1.2。在进行精确计算时,想要避免这种问题,可以使用 Python 内置的 decimal 模块中提供的 Decimal 类的 quantize() 方法实现。代码如下:
import decimal # 导入十进制定点和浮点运算模块
print('使用round()函数实现:')
print('内置函数round():', round(1.25, 1)) # 1.2
d = decimal.Decimal(1.25) # 浮点值
print('使用decimal模块实现:')
print('1.25四舍五入的结果:', end='')
print(d.quantize(decimal.Decimal('1.0'), rounding=decimal.ROUND_HALF_UP)) # 1.3
def myround(_float, _len):
if str(_float)[-1] == '5': # 判断最后一位是否为5
return round(float(str(_float)[:-1] + '6'), _len) # 将最后一位替换为6
else:
return round(_float, _len) # 不是特殊情况直接进行四舍五入操作
print('自定义函数实现:')
print('1.25四舍五入的结果:', end='')
print(myround(1.25, 1)) # 1.3
八、sum 函数–对可迭代对象进行求和计算
sum() 函数用于对列表、元组或集合等可迭代对象进行求和计算。其语法格式如下:
sum(iterable[, start])
参数说明:
- iterable:可迭代对象,如列表、元组、range 对象等;
- start:可选参数,指定相加的参数(即序列值相加后再次相加的值),如果没有设置此参数,则默认为 0;
- 返回值:求和结果。
注意:在使用 sum() 函数对可迭代对象进行求和时,需要满足参数必须为可迭代对象且可迭代对象中的元素类型必须是数值型,否则将提示 TypeError。
【示例1】列表元素求和。
num_list = [2, 4, 6, 8, 10] # 普通列表
print(f'num_list列表元素和为:{
sum(num_list)}') # 30
print(f'num_list列表元素和加1:{
sum(num_list, 1)}') # 31
# 10名学生Python理论成绩列表
grade_list = ['98', '99', '97', '100', '100', '96', '94', '89', '95', '100']
# grade_list = [int(i) for i in grade_list] # 循环将字符类型转换为int
# print('Python理论总成绩为:', sum(grade_list)) # 968
# 还可以使用高阶函数省去自己书写循环迭代部分
print(sum(list(map(lambda x: int(x), grade_list)))) # 968
# 其他序列类似:如元组、集合等。
【示例2】猜大小。程序随机生成三位数的数字与中奖号码的三位数字相加之和的大、小性质相同,即猜中。其中,三个号码相加之和在19(含)至27(含)之间时为大,在0(含)至8(含)之间时为小。代码如下:
import random
# 随机生成10组三位数的数字
num_list = random.sample(range(100, 1000), 10)
print(num_list)
for num in num_list:
# 将随机的三位数分割为列表
num_list2 = list(map(int, str(num)))
# 三位数的数字相加并进行比较
if 19 <= sum(num_list2) <= 27:
print(f"{
str(num)}:大,猜中!")
elif 0 <= sum(num_list2) <= 8:
print(f"{
str(num)}:小!")
程序运行结果如下:

【示例3】获取哪班学生运动项目决赛积分最高。
# 模拟学生运动项目决赛积分
sport = {
'一班': [{
'项目': '田径100米', '名次': 3, '积分': 16, '性别': '男子'},
{
'项目': '田径100米', '名次': 1, '积分': 20, '性别': '女子'}, ],
'二班': [{
'项目': '田径100米', '名次': 2, '积分': 18, '性别': '男子'},
{
'项目': '田径100米', '名次': 3, '积分': 16, '性别': '女子'}, ],
'三班': [{
'项目': '田径100米', '名次': 1, '积分': 20, '性别': '男子'},
{
'项目': '田径100米', '名次': 2, '积分': 18, '性别': '女子'}]
}
fraction_list = [] # 保存积分的数据
class_list = list(sport.keys()) # 保存班级的列表
for i in sport.values():
# 将每个班的积分总和添加至列表中
fraction_list.append(sum(list(map(lambda v: v['积分'], i))))
# 获取分数最高的下标
max_index = fraction_list.index(max(fraction_list))
# 本次学生运动项目决赛积分最高的是: 三班
print('本次学生运动项目决赛积分最高的是:', class_list[max_index])
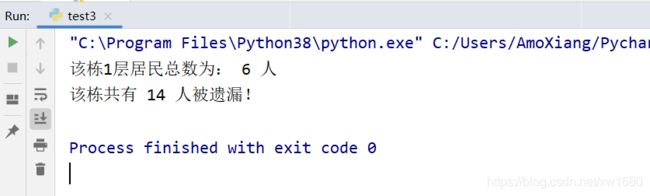
【示例4】获取社区对居民统计的遗漏人员。
# 社区对某栋楼居民数据采集时,遗漏的数据
family1 = {
'楼层': '1层', '房间号': '101室', '家庭人数': '4人'}
family2 = {
'楼层': '1层', '房间号': '103室', '家庭人数': '2人'}
family3 = {
'楼层': '3层', '房间号': '302室', '家庭人数': '1人'}
family4 = {
'楼层': '5层', '房间号': '503室', '家庭人数': '4人'}
family5 = {
'楼层': '6层', '房间号': '601室', '家庭人数': '3人'}
family_list = [family1, family2, family3, family4, family5] # 家庭居民信息列表
floor_list = list(filter(lambda l: l['楼层'] == '1层', family_list)) # 楼层为1层居民数据
# 获取楼层为1层居民总数
floor_number = sum(map(lambda n: int(n.get('家庭人数')[0]), floor_list))
total_quantity = sum(map(lambda n: int(n.get('家庭人数')[0]), family_list))
print('该栋1层居民总数为:', floor_number, '人')
print('该栋共有', total_quantity, '人被遗漏!')
程序运行结果如下: