Leetcode 题解 - 分治算法
其实,回溯、分治和动态规划算法可以划为一类,因为它们都会涉及递归。
回溯算法就一种简单粗暴的算法技巧,说白了就是一个暴力穷举算法,比如让你用回溯算法求子集、全排列、组合,你就穷举呗,就考你会不会漏掉或者多算某些情况。
动态规划是一类算法问题,肯定是让你求最值的。因为动态规划问题拥有最优子结构,可以通过状态转移方程从小规模的子问题最优解推导出大规模问题的最优解。
==分治算法呢,可以认为是一种算法思想,通过将原问题分解成小规模的子问题,然后根据子问题的结果构造出原问题的答案。==这里有点类似动态规划,所以说运用分治算法也需要满足一些条件,你的原问题结果应该可以通过合并子问题结果来计算。
其实这几个算法之间界定并没有那么清晰,有时候回溯算法加个备忘录似乎就成动态规划了,而分治算法有时候也可以加备忘录进行剪枝。
最典型的分治算法就是归并排序了,核心逻辑如下:
void sort(int[] nums, int lo, int hi) {
int mid = (lo + hi) / 2;
/****** 分 ******/
// 对数组的两部分分别排序
sort(nums, lo, mid);
sort(nums, mid + 1, hi);
/****** 治 ******/
// 合并两个排好序的子数组
merge(nums, lo, mid, hi);
}
「对数组排序」是一个可以运用分治思想的算法问题,只要我先把数组的左半部分排序,再把右半部分排序,最后把两部分合并,不就是对整个数组排序了吗?
下面来看一道具体的算法题。
241. 为运算表达式设计优先级(中等)
给定一个含有数字和运算符的字符串,为表达式添加括号,改变其运算优先级以求出不同的结果。你需要给出所有可能的组合的结果。有效的运算符号包含 +, - 以及 * 。
输入: "2*3-4*5"
输出: [-34, -14, -10, -10, 10]
解释:
2*(3-(4*5)) = -34
(2*3)-(4*5) = -14
(2*(3-4))*5 = -10
2*((3-4)*5) = -10
((2*3)-4)*5 = 10
解决本题的关键有两点:
1、不要思考整体,而是把目光聚焦局部,只看一个运算符。
这一点我们前文经常提及,比如解决二叉树系列问题只要思考每个节点需要做什么,而不要思考整棵树需要做什么。说白了,解决递归相关的算法问题,就是一个化整为零的过程,你必须瞄准一个小的突破口,然后把问题拆解,大而化小,利用递归函数来解决。
2、明确递归函数的定义是什么,相信并且利用好函数的定义。
这也是前文经常提到的一个点,因为递归函数要自己调用自己,你必须搞清楚函数到底能干嘛,才能正确进行递归调用。
下面来具体解释下这两个关键点怎么理解。
我们先举个例子,比如我给你输入这样一个算式:
1 + 2 * 3 - 4 * 5
请问,这个算式有几种加括号的方式?请在一秒之内回答我。
估计你回答不出来,因为括号可以嵌套,要穷举出来肯定得费点功夫。
不过呢,嵌套这个事情吧,我们人类来看是很头疼的,但对于算法来说嵌套括号不要太简单,一次递归就可以嵌套一层,一次搞不定大不了多递归几次。
所以,作为写算法的人类,我们只需要思考,如果不让括号嵌套(即只加一层括号),有几种加括号的方式?
还是上面的例子,显然我们有四种加括号方式:
(1) + (2 * 3 - 4 * 5)
(1 + 2) * (3 - 4 * 5)
(1 + 2 * 3) - (4 * 5)
(1 + 2 * 3 - 4) * (5)
发现规律了么?其实就是按照运算符进行分割,给每个运算符的左右两部分加括号,这就是之前说的第一个关键点,不要考虑整体,而是聚焦每个运算符。
现在单独说上面的第三种情况:
(1 + 2 * 3) - (4 * 5)
我们用减号-作为分隔,把原算式分解成两个算式1 + 2 * 3和4 * 5。
分治分治,分而治之,这一步就是把原问题进行了「分」,我们现在要开始「治」了。
1 + 2 * 3可以有两种加括号的方式,分别是:
(1) + (2 * 3) = 7
(1 + 2) * (3) = 9
或者我们可以写成这种形式:
1 + 2 * 3 = [9, 7]
而4 * 5当然只有一种加括号方式,就是4 * 5 = [20]。
然后呢,你能不能通过上述结果推导出(1 + 2 * 3) - (4 * 5)有几种加括号方式,或者说有几种不同的结果?
显然,可以推导出来(1 + 2 * 3) - (4 * 5)有两种结果,分别是:
9 - 20 = -11
7 - 20 = -13
那你可能要问了,1 + 2 * 3 = [9, 7]的结果是我们自己看出来的,如何让算法计算出来这个结果呢?
这个简单啊,再回头看下题目给出的函数签名:
// 定义:计算算式 input 所有可能的运算结果
List<Integer> diffWaysToCompute(String expression);
这个函数不就是干这个事儿的吗?这就是我们之前说的第二个关键点,明确函数的定义,相信并且利用这个函数定义。
你甭管这个函数怎么做到的,你相信它能做到,然后用就行了,最后它就真的能做到了。
那么,对于(1 + 2 * 3) - (4 * 5)这个例子,我们的计算逻辑其实就是这段代码:
List<Integer> diffWaysToCompute("(1 + 2 * 3) - (4 * 5)") {
List<Integer> res = new LinkedList<>();
/****** 分 ******/
List<Integer> left = diffWaysToCompute("1 + 2 * 3");
List<Integer> right = diffWaysToCompute("4 * 5");
/****** 治 ******/
for (int a : left)
for (int b : right)
res.add(a - b);
return res;
}
好,现在(1 + 2 * 3) - (4 * 5)这个例子是如何计算的,你应该完全理解了吧,那么回来看我们的原始问题。
原问题1 + 2 * 3 - 4 * 5是不是只有(1 + 2 * 3) - (4 * 5)这一种情况?是不是只能从减号-进行分割?
不是,每个运算符都可以把原问题分割成两个子问题,刚才已经列出了所有可能的分割方式:
(1) + (2 * 3 - 4 * 5)
(1 + 2) * (3 - 4 * 5)
(1 + 2 * 3) - (4 * 5)
(1 + 2 * 3 - 4) * (5)
所以,我们需要穷举上述的每一种情况,可以进一步细化一下解法代码:
List<Integer> diffWaysToCompute(String input) {
List<Integer> res = new LinkedList<>();
for (int i = 0; i < input.length(); i++) {
char c = input.charAt(i);
// 扫描算式 input 中的运算符
if (c == '-' || c == '*' || c == '+') {
/****** 分 ******/
// 以运算符为中心,分割成两个字符串,分别递归计算
List<Integer> left = diffWaysToCompute(input.substring(0, i));
List<Integer> right = diffWaysToCompute(input.substring(i + 1));
/****** 治 ******/
// 通过子问题的结果,合成原问题的结果
for (int a : left)
for (int b : right)
if (c == '+')
res.add(a + b);
else if (c == '-')
res.add(a - b);
else if (c == '*')
res.add(a * b);
}
}
// base case
// 如果 res 为空,说明算式是一个数字,没有运算符
if (res.isEmpty()) {
res.add(Integer.parseInt(input));
}
return res;
}
有了刚才的铺垫,这段代码应该很好理解了吧,就是扫描输入的算式input,每当遇到运算符就进行分割,递归计算出结果后,根据运算符来合并结果。
这就是典型的分治思路,先「分」后「治」,先按照运算符将原问题拆解成多个子问题,然后通过子问题的结果来合成原问题的结果。
当然,一个重点在base case: 递归函数必须有个 base case 用来结束递归,代表着你「分」到什么时候可以开始「治」。我们是按照运算符进行「分」的,一直这么分下去,什么时候是个头?显然,当算式中不存在运算符的时候就可以结束了。那为什么以res.isEmpty()作为判断条件?因为当算式中不存在运算符的时候,就不会触发 if 语句,也就不会给res中添加任何元素。
95. 不同的二叉搜索树 II (中等)
给你一个整数 n ,请你生成并返回所有由 n 个节点组成且节点值从 1 到 n 互不相同的不同 二叉搜索树 。可以按 任意顺序 返回答案。
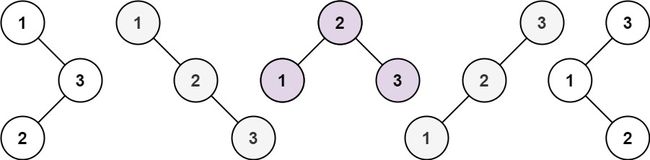
输入:n = 3
输出:[[1,null,2,null,3],[1,null,3,2],[2,1,3],[3,1,null,null,2],[3,2,null,1]]
解题思路:[分治算法] 将 连续的数,一个个遍历,作为根节点,每次遍历中,将 左边的数组 和 右边的数组 分别进行构建子树,并接到 当前根节点上
class Solution {
public List<TreeNode> generateTrees(int n) {
return generateSubtrees(1, n);
}
private List<TreeNode> generateSubtrees(int start, int end){
List<TreeNode> res = new LinkedList<>();
if(start > end){
res.add(null);
}
for(int i = start; i <= end; i++){
List<TreeNode> left = generateSubtrees(start, i - 1);
List<TreeNode> right = generateSubtrees(i + 1, end);
for(TreeNode a : left){
for(TreeNode b : right){
TreeNode root = new TreeNode(i);
root.left = a;
root.right = b;
res.add(root);
}
}
}
return res;
}
}
96. 不同的二叉搜索树(中等)
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。
输入:n = 3
输出:5
解题思路:
方法一:递归+备忘录(不加备忘录会超时)
class Solution {
// 备忘录
int[][] memo;
public int numTrees(int n) {
// 备忘录的值初始化为 0
memo = new int[n+1][n+1];
return count(1, n);
}
// 定义:闭区间 [lo, hi] 的数字能组成 count(lo, hi) 种 BST
public int count(int lo, int hi){
//base case
if(lo > hi) return 1;
// 查备忘录
if (memo[lo][hi] != 0) {
return memo[lo][hi];
}
int res = 0;
for(int i = lo; i<= hi; i++){
//分别计算以i为根节点时左,右子树的个数
int left = count(lo, i-1);
int right = count(i+1, hi);
// 左右子树的组合数乘积是 BST 的总数
res += left*right;
}
// 将结果存入备忘录
memo[lo][hi] = res;
return res;
}
}
方法二:动态规划
class Solution {
public int numTrees(int n) {
int[] dp = new int[n + 1];
dp[0] = 1;
dp[1] = 1;
//计算由i个节点可以组成的二叉搜索树的个数
for(int i = 2; i <= n; i++){
//计算以j为根节点的二叉搜索树的个数
for(int j = 1; j <= i; j++){
dp[i] += dp[j - 1] * dp[i - j]; //二叉搜索树得个数等于左右子树个数的乘积
}
}
return dp[n];
}
}