python爬取豆瓣影评
爬取内容:用户评论数据:用户ID、评论时间、评论星数、评论标题

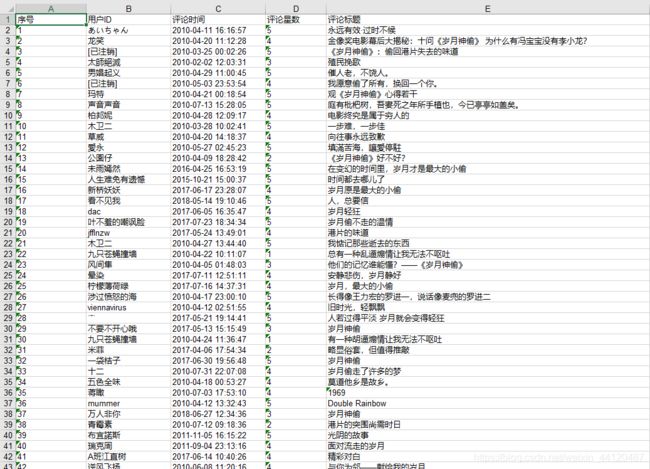
爬取效果:会将爬取的内容以excel的形式保存到本地
程序源代码:
# @coding:utf-8
# @Time : 2021/5/28 10:24
# @Author : TomHe
# @File : main.py
# @Software : PyCharm
import time
import xlwt
import requests
from bs4 import BeautifulSoup
# 请求页面
def get_code(page_url):
headers = {
'User-Agent': 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
res = requests.get(url = page_url, headers = headers)
page_code = res.text
return page_code
# 解析网页源码 获取数据
def parse_code(page_code, rule):
res_list = []
soup = BeautifulSoup(page_code, 'html.parser')
res = soup.select(rule)
for item in res:
res_list.append(item.string)
return res_list
# 获取评论星数 单独处理
def get_comment_star(page_code):
soup = BeautifulSoup(page_code, 'html.parser')
res = soup.select('.main-hd>.main-title-rating')
comment_star_list = []
for item in res:
# 获取含有评论星数的类名
class_name = item['class'][0]
# 从该类名中获取星数 例:allstar50 => 5
comment_star = class_name[len(class_name) - 2:len(class_name) - 1]
comment_star_list.append(comment_star)
return comment_star_list
# 获取电影信息
def get_comments_info(page_code):
# 用户ID
userID_list = parse_code(page_code, '.main-hd>.name')
# 评论时间
comment_time_list = parse_code(page_code, '.main-hd>.main-meta')
# 评论星数
comment_star_list = get_comment_star(page_code)
# 评论内容
comment_title = parse_code(page_code, '.main-bd>h2>a')
for (userID, comment_time, comment_star, comment_title) in zip(userID_list, comment_time_list, comment_star_list,
comment_title):
# 电影信息字典 保存每部电影的详细信息
comment_info = {
}
comment_info['userID'] = userID
comment_info['comment_time'] = comment_time
comment_info['comment_star'] = comment_star
comment_info['comment_title'] = comment_title
comments_info.append(comment_info)
# 将数据写入到excel表格中
def write_data2excel(data, sheet):
global row
for item in data:
sheet.write(row, 0, str(row))
sheet.write(row, 1, item.get('userID'))
sheet.write(row, 2, item.get('comment_time'))
sheet.write(row, 3, item.get('comment_star'))
sheet.write(row, 4, item.get('comment_title'))
row = row + 1
# 将数据以excel格式保存到本地
def save_data(data, table_name):
# 1.1 创建excel表格
wk = xlwt.Workbook()
sheet = wk.add_sheet('表格', cell_overwrite_ok = True)
# 1.2 初始化表头
sheet.write(0, 0, "序号")
sheet.write(0, 1, "用户ID")
sheet.write(0, 2, "评论时间")
sheet.write(0, 3, "评论星数")
sheet.write(0, 4, "评论标题")
# 1.3 写入数据
write_data2excel(data, sheet)
# 1.4 关闭excel表格
wk.save(table_name + '.xls')
print('爬取的数据成功保存到了 ' + table_name + '.xls 文件中!!!')
# 爬虫主程序
def spider(base_url):
# 网页页码数
page_num = 0
# 循环爬取评论信息
while (page_num < 5):
# 动态更新网页url
current_url = base_url.format(page_num * 20)
page_code = get_code(current_url)
get_comments_info(page_code)
print('第 ' + str(page_num + 1) + ' 页数据爬取完成...')
page_num = page_num + 1
# 调用休眠函数 减缓爬取速度 具体间隔时间可修改
time.sleep(2)
# 将数据保存到 moviesComment200 表格中
save_data(comments_info, 'moviesComment100')
if __name__ == '__main__':
# excel表格行数
row = 1
# 写入excel表格的评论信息数组
comments_info = []
# 豆瓣电影 岁月神偷评论
base_url = 'https://movie.douban.com/subject/3792799/reviews?start={}'
spider(base_url)
该代码只爬取了前5页评论,如需爬取更多,可自行手动更改while循环的条件。。。
运行效果: