python爬虫步骤-黑客基础 编写Python爬虫入门步骤
原标题:黑客基础 编写Python爬虫入门步骤
信息时代,数据就是宝藏。数据的背后隐含着无穷的宝藏,这些宝藏也许就是信息量所带来的商业价值,而大数据本身也将成为桌面上的筹码。
黑客花无涯 带你走进黑客世界系列文章
学习黑客经典书籍 网络黑白 某宝有售
通过编写者两个小爬虫,我逐渐体会到了爬虫的一些作用,对其的一些巧妙应用,多线程的处理有时候会大大提高做事的效率,而一个功能强大的爬虫系统所能做的远不止这些。

说了那么多数据的重要性,本篇文章所提到爬取的数据不包括超过传统数据库系统处理能力的数据。而是从一个简单的爬虫程序上讲起,讲如何编写属于自己的爬虫,获取想要的简单数据,并让程序对数据进行分析进而得到我们想要的信息。
逻辑分析
编写爬虫首先要有个简单的逻辑思路,无非是发送请求-加载页面-获取页面的信息-提取想要的数据-数据可视化、以表格的形式呈现或者根据需求批量下载到本地。
所以这里我们不妨写两个工程程序进行测试,一是批量数据下载到本地,我们可以把腾讯服务器里用户QQ空间中的相册批量下载下来,寻找规律随机下载,或利用一些接口从服务器上爬取。二是对特定数据爬取,最好以可视化表格的形式表现出来,我们可以采集网站上一些数据,然后以表格显示。
案例一代码分析
现在我们开始写代码,用Python来实现这一功能,首先是发送请求信息。Python的Urllib模块提供了读取web页面数据的接口,我们可以读取万维网、FTP上的数据。用urllib.urlopen()方法用于打开一个URL地址。用read()方法可以读取URL上的数据。其间对字符串的处理自定义了函数,为获取想要的数据,编写了正则表达式。简单基础的Python编程,附上核心代码。
//自定义函数获取指定两个字符串之间的数据
defsfinds(start_str,end,html):start=html.find(start_str)ifstart=0:start+=len(start_str)end=html.find(end,start)ifend=0:returnhtml[start:end].strip()//自定义函数getHtml()用来读取网页数据defgetHtml(url):p=urllib.urlopen(url)html=p.read()returnhtml//自定义函数构造正则表达式来获取网络图片defgetImg(html):reg=rurl[^]*[^u]*[^r]*[^l]*[^]*/urlimgae=re.compile(reg)imglist=re.findall(imgae,str(html))returnimglist
有了以上定义的基本函数,就可以进行很多实战测试了。利用腾讯已有的一些接口来访问服务器空间上保存的数据,下面就是一个网络爬虫爬取数据,相册批量下载的测试效果图,可以下载任意QQ的相册,即使对方设置了权限限制。

图1软件打开效果图
接下来输入我们要下载相册的QQ号,可以看到程序会自动获取相册信息:

图2相册信息获取截图
然后我们的爬虫系统会自动下载保存图片,我们只需要耐心等待。
图3照片下载成果后提示截图
出去转了一圈,回头再来看的时候所有相册已经下载完毕,到程序文件夹里可以看到下载的照片。

图4下载的图片
接着又测试了一个QQ号,效果如图。
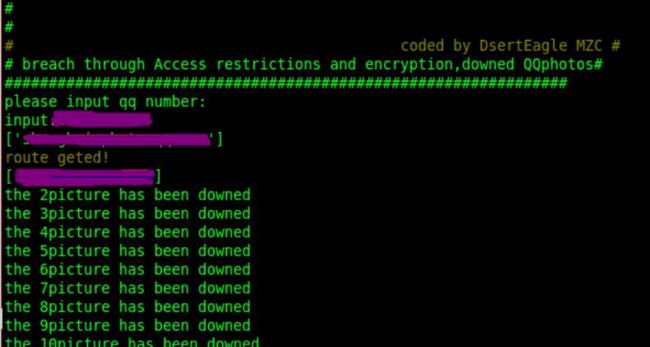

案例二逻辑分析
作为学习来讲,在案例二中我们涉及html数据解析。欧尼酱这个网站我之前没有听过,一次偶然发现里面有首还不错的日系音乐,于是决定拿这个网站为例子,爬取o站里部分音乐信息。首先打开一个页面,查看其源代码,如图7所示。
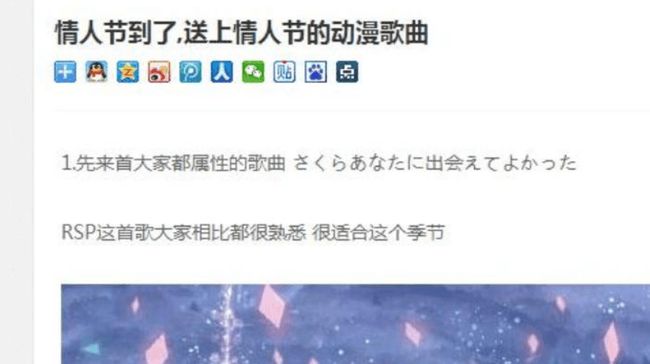
图7
从这个源代码中我们可以看到divcalss=”contentmarkitup-box”这个html标签中保存的是歌曲的名字,我们可以获取所有这个标签中包含的内容,以此来爬取页面所推荐的情人节日漫歌曲名字。
我们可以先获取页面的html数据信息,然后通过class或者ID查找特定的标签,接着对标签的内容进行获取,列表显示,核心代码如下:
//首先还是读取页面信息
学习黑客经典书籍 黑客技术攻防入门到精通 网络黑白书 某宝有售
中国黑客协会 普及网络安全知识,让更多的人学习并重视网络安全和信息安全。
中国黑客协会是一种精神的传承,黑客代表是一种精神,它是一种热爱祖国、坚持正义、开拓进取的精神。
接着对读取的信息进行处理,我们知道我们爬到的信息是有大幅度的html标签,我们要对数据进行html解析。对此我们有很多方法,HTMLParser模块、BeautifulSoup、SGMLParser,这里我们用SGMLParser,理由不多讲了,好用。返回搜狐,查看更多
责任编辑: