python安全攻防---爬虫基础---get和post提交数据
get提交数据1
get提交的数据就附在提交给服务器的url之后,以?开头参数之间以&隔开,例如/admin/user/123456.aspx?name=123&id=123
案例:写个脚本,在sogou自动搜索周杰伦,并将搜索页面的数据获取
程序如下:
import requests
query = input("请输入一个你喜欢的明星:")
url = f'https://www.sogou.com/web?query={query}'
dict = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
'Referer':'https://www.sogou.com/web?query=zhoujielun&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=3117&sst0=1621925126921&lkt=11,1621925123805,1621925126101&sugsuv=001E74F4CA65D1685D50D56F6038D197&sugtime=1621925126921'
}
response = requests.get(url,headers=dict)
print(response)
print(response.text)
对于dict里面的内容,我们可以在浏览器手动获得,我以Chrome浏览器为例:
F12或者右键页面,找到检查,点击
找到network,如果没有数据,刷新一下,随便点击左边的内容,然后找到Request Headers,就可以找到Referer和User-Agent的值了
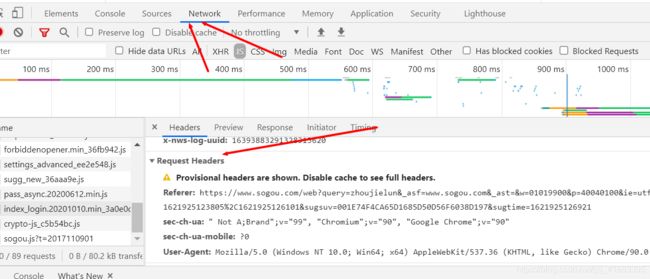
对于get的提交数据,使用requests.get(url,headers=dict),url是我们爬虫的页面,url也有我们提交的数据,后面增加的headers是为了反反爬虫的。
运行结果:
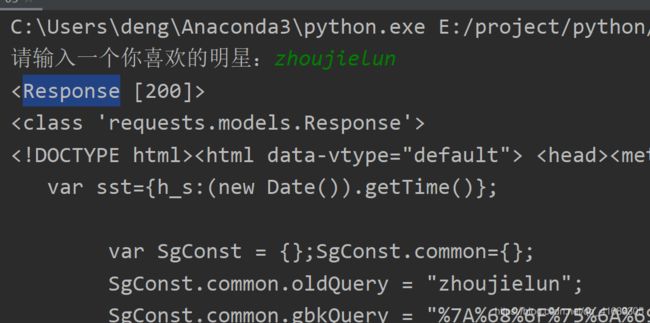
get提交数据2
案例:爬取豆瓣数据排行榜的数据
地址:https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=
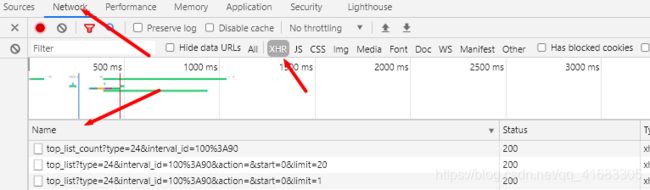
再第二个连接中我们找到了我们需要的数据

观察Headers,找到url和header参数,并且可以发现是get请求

写出程序:
import requests
url = 'https://movie.douban.com/j/chart/top_list'
#重新封装参数
param = {
'type': '24',
'interval_id': '100:90',
'action': '',
'start': 0,
'limit': 20,
}
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
}
resp = requests.get(url=url,params=param,headers=headers)
print(resp.json())
resp.close()
这里可以在使用get方法时使用paams指定get的参数。
![]()
post提交数据
post提交数据的方法则是直接将数据放在http的body部分
response = requests.post(url=url,data=data)
data是我们需要提交的数据,字典形式
其他和post一样