xgboost调参_模型搭建方法——XGBoost函数使用整合篇
XGBoost作为机器学习的一个基础方法,在多因子模型中作为一个模型被使用,是一个非常有效的非线性训练方法。Python中也有很多库来帮助我们实现模型的训练过程。
这篇文章不介绍XGBoost的原理,主要介绍在多因子模型中,使用XGBoost模型训练时候的一些参数调整和问题。主要利用Python的函数包来实现。
一、模型参数
clf = XGBClassifier(learning_rate=0.05,
n_estimators=500, # 树的个数--1000棵树建立xgboost
max_depth=6, # 树的深度
min_child_weight = 1, # 叶子节点最小权重
gamma=0.1, # 惩罚项中叶子结点个数前的参数
subsample=0.8, # 随机选择80%样本建立决策树
colsample_btree=0.8, # 随机选择80%特征建立决策树
objective='binary:logistic',# 指定损失函数
scale_pos_weight=5, # 解决样本个数不平衡的问题
seed=1000,
nthread=20, # CPU线程数
)
clf.fit(X,y,eval_metric='auc')#训练clf
clf.predict(X_test) #输出预测结果
clf.predict_proba(x_test) #输出预测的概率值(1)n_estimators:总迭代次数,决策树的个数
(2)learning_rate:学习率,控制每次迭代更新权重时的步长
-
值越小,训练越慢
默认0.3,典型值为0.01-0.2
(3)max_depth:决策树的深度
-
值越大,越容易过拟合;值越小,越容易欠拟合
默认值为6,典型值3-10
(4)min_child_weight:孩子节点中最小的样本权重和。指建立每个模型所需要的最小样本数
默认值为1
值越大,越容易欠拟合;值越小,越容易过拟合(值较大时,避免模型学习到局部的特殊样本)
(5)gamma:惩罚项系数,指定节点分裂所需的最小损失函数下降值
模型在默认情况下,对于一个节点的划分只有在其loss function 得到结果大于0的情况下才进行,而gamma 给定了所需的最低loss function的值
默认值为0
(6)subsample:训练每棵树时,使用的数据占全部训练集的比例。
colsample_btree:训练每棵树时,使用的特征占全部特征的比例
默认值为1,典型值为0.5-1
主要用于防止过拟合
(7)scale_pos_weight:主要用于二分类
正样本的权重,在二分类任务中,当正负样本比例失衡时,设置正样本的权重,模型效果更好。例如,当正负样本比例为1:10时,scale_pos_weight=10。
(8)seed:随机数的种子
默认值为0
可以用于产生可重复的结果(每次取一样的seed即可得到相同的随机划分)
(9)nthread:有时候使用-1会报错,建议根据自己的CPU数量设置
nthread=-1时,使用全部CPU进行并行运算(默认)
nthread=1时,使用1个CPU进行运算。
(10)booster:
gbtree 树模型做为基分类器(默认)
gbliner 线性模型做为基分类器
(11)silent:
-
silent=0时,不输出中间过程(默认)
silent=1时,输出中间过程
(12)objective:目标函数
“reg:linear” –线性回归。
“reg:logistic” –逻辑回归。
“binary:logistic” –二分类的逻辑回归问题,输出为概率。
“binary:logitraw” –二分类的逻辑回归问题,输出的结果为wTx。
“count:poisson” –计数问题的poisson回归,输出结果为poisson分布。
“multi:softmax” –让XGBoost采用softmax目标函数处理多分类问题,同时需要设置参数num_class(类别个数)
“multi:softprob” –和softmax一样,但是输出的是ndata * nclass的向量,可以将该向量reshape成ndata行nclass列的矩阵。每行数据表示样本所属于每个类别的概率。
“rank:pairwise” –通过最小化pairwise loss来执行rank排名
(13)eval_metric:
回归任务(默认rmse)
rmse--均方根误差
mae--平均绝对误差
分类任务(默认error)
auc--roc曲线下面积
error--错误率(二分类)
merror--错误率(多分类)
logloss--负对数似然函数(二分类)
mlogloss--负对数似然函数(多分类)
二、模型调参
模型需要进行调参的参数有:
n_estimators
learning_rate
subsample
colsample_bytree
min_child_weight
max_depth
gamma
reg_alpha
虽然可以使用网格调参法,但是项目太多当数据量较大的时候会非常慢,因此可以采hyperopt模块来调参——随机网格寻优。
def Huber_train(X,y):
X_train=np.array(X).reshape(-1,1)
y_train=y.copy()
huber = HuberRegressor(alpha=0.001, epsilon=1.15, fit_intercept=True,max_iter=500,tol=1e-06)
huber.fit(X_train,y_train)
#########定义XGB模型############
def Huber_model(argsDict,X_train=X_train, y_train=y_train):
alpha=argsDict["alpha"]
epsilon=argsDict["epsilon"]
fit_intercept=argsDict["fit_intercept"]
huber = HuberRegressor(alpha=alpha,
epsilon=epsilon,
fit_intercept=fit_intercept,
max_iter=500,tol=1e-06)
tscv = TimeSeriesSplit(max_train_size=None, n_splits=5) ##设定时序交叉验证参数
metric = cross_val_score(huber, X_train, y_train, cv=tscv, scoring="neg_median_absolute_error",n_jobs=40).mean()
print(metric)
return -metric
#######################随机网格寻优#####################
#########计算得到最新的Huber########
def cal_Huber(argsDict, X, y):
alpha = argsDict["alpha"]
epsilon = argsDict["epsilon"]
fit_intercept = argsDict["fit_intercept"]
huber = HuberRegressor(alpha=alpha,
epsilon=epsilon,
fit_intercept=fit_intercept,
max_iter=500, tol=1e-06)
huber.fit(X, y) # 训练clf
return huber
# 定义参数的搜索空间
space = {
"alpha": hp.uniform('alpha',0,0.1),
"epsilon": hp.uniform("epsilon", 1, 2),
"fit_intercept": hp.randint("fit_intercept", 2),
}
###目前hyperopt支持的搜索算法有随机搜索(对应是hyperopt.rand.suggest),模拟退火(对应是hyperopt.anneal.suggest),TPE算法
algo = partial(tpe.suggest,n_startup_jobs=10) # 定义随机搜索算法。搜索算法本身也有内置的参数决定如何去优化目标函数
best = fmin(Huber_model,space,algo=algo,max_evals=100,max_queue_len=40) # 对定义的参数范围,调用搜索算法,对模型进行搜索
print(best,Huber_model(best))
clf=cal_Huber(best,X_train,y_train)
return clf可以看到通过随机网格寻优可以得到我们希望的最优解。
三、交叉验证
关于交叉验证的参数,目前在多因子模型中k折交叉验证并没有效果,更应该采取的是时序交叉验证,因此在进行交叉验证的时候选择时序交叉验证:
from sklearn.model_selection import TimeSeriesSplit
from sklearn.model_selection import cross_val_score
tscv = TimeSeriesSplit(max_train_size=None, n_splits=5) ##设定时序交叉验证参数
metric = cross_val_score(huber, X_train, y_train, cv=tscv, scoring="neg_median_absolute_error",n_jobs=40).mean()对于TimeSeriesSplit而言,有两个参数:
n_splits:表示分割的数目,必须至少为2。
max_train_size:int,可选,表示单个训练集的最大大小。
对于cross_val_score最重要的参数是scoring:看到说明文档中给予的方法,根据实际情况使用。
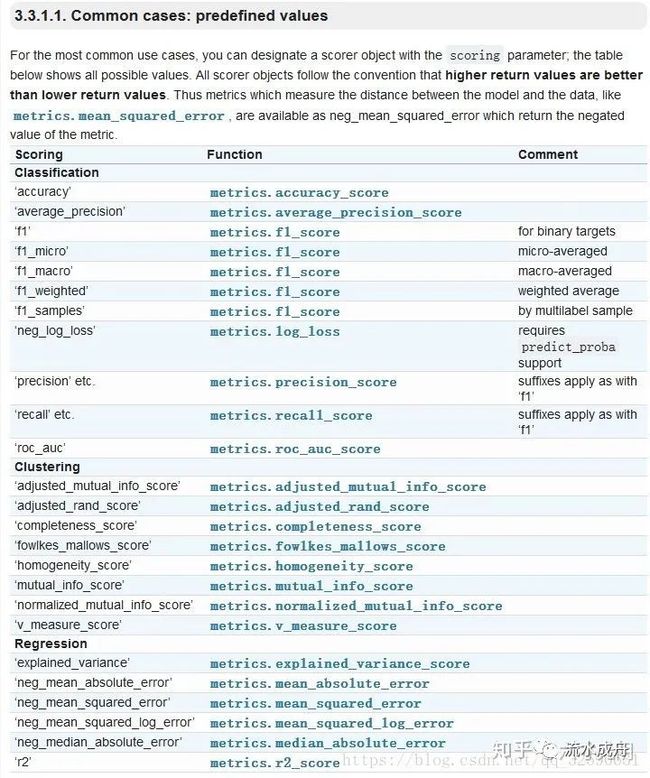
但目前由库里生成的时序交叉验证并没有和实际非常吻合,因此需要尽量自己写一个时序交叉验证;代码也很简单,但是相比于库里的程序,运行会慢一些~