一、目标网页分析
目标网站是某车之家关于品牌汽车车型的口碑模块相关数据,比如我们演示的案例奥迪Q5L的口碑页面如下:
https://k.autohome.com.cn/4851/#pvareaid=3311678
为了演示方式,大家可以直接打开上面这个网址,然后拖到全部口碑位置,找到我们本次采集需要的字段如下图所示:
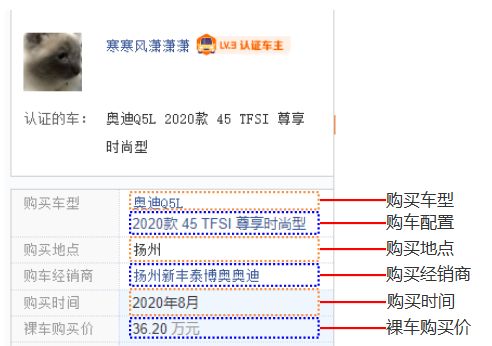
采集字段
我们进行翻页发现,浏览器网址发生了变化,大家可以对下如下几页的网址找出规律:
https://k.autohome.com.cn/4851/index_2.html#dataList https://k.autohome.com.cn/4851/index_3.html#dataList https://k.autohome.com.cn/4851/index_4.html#dataList
对于上面写网址,我们发现可变部分是车型(如4851)以及页码(如2,3,4),于是我们可以构建url参数如下:
# typeid是车型,page是页码
url = f'https://k.autohome.com.cn/{typeid}/index_{page}.html#dataList'
二、数据请求
通过简单的测试,发现似乎不存在反爬,那就简单了。
我们先引入需要用到的库:
import requests import pandas as pd import html from lxml import etree import re
然后创建一个数据请求的函数备用:
# 获取网页数据(传递参数 车型typeid和页码数)
def get_html(typeid,page):
# 组合出请求地址
url = f'https://k.autohome.com.cn/{typeid}/index_{page}.html#dataList'
# 请求数据(因为没有反爬,这里没有设置请求头和其他参数)
r = requests.get(url)
# 请求的网页数据中有网页特殊字符,通过以下方法进行解析
r = html.unescape(r.text)
# 返回网页数据
return r
请求来的数据就是网页html文本,我们接下来采用re解析出一共多少页码,再用xpath进行采集字段的解析。
三、数据解析
由于需要进行翻页,这里我们可以先通过re正则表达式获取总页码。通过查看网页数据,我们发现总页码可以通过如下方式获取:
try:
pages = int(re.findall(r'共(\d+)页',r)[0])
# 如果请求不到页数,则表示该车型下没有口碑数据
except :
print(f'{name} 没有数据!')
continue
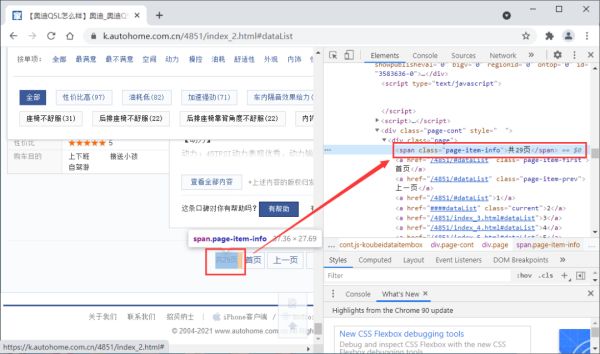
总页码采集
关于待采集字段信息,我们发现都在节点div[@class="mouthcon-cont-left"]里,可以先定位这个节点数据,然后再进行逐一解析。
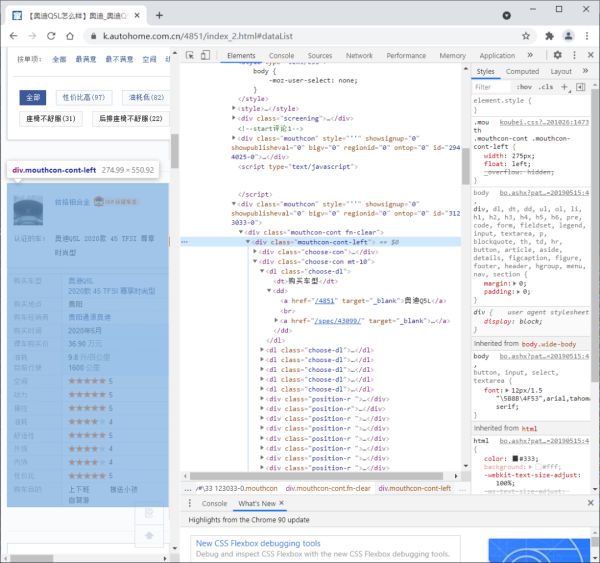
待采集字段信息所在节点
此外,我们发现每一页最多15个车型口碑数据,因此我们每页可以定位15个待采集信息数据集,遍历采集代码:
divs = r_html.xpath('.//div[@class="mouthcon-cont-left"]')
# 遍历每个全部的车辆销售信息
for div in divs:
# 找到车辆销售信息所在的地方
mt = div.xpath('./div[@class="choose-con mt-10"]')[0]
# 找到所需字段
infos = mt.xpath('./dl[@class="choose-dl"]')
# 设置空的字典,用于存储单个车辆信息
item = {}
# 遍历车辆信息字段
for info in infos:
key = info.xpath('.//dt/text()')[0]
# 当字段为购买车型时,进行拆分为车型和配置
if key == '购买车型':
item[key] = info.xpath('.//dd/a/text()')[0]
item['购买配置'] = info.xpath('.//span[@class="font-arial"]/text()')[0]
# 当字段为购车经销商时,需要获取经销商的id参数,再调用api获取其真实经销商信息(这里有坑)
elif key == '购车经销商':
# 经销商id参数
经销商id = info.xpath('.//dd/a/@data-val')[0] +','+ info.xpath('.//dd/a/@data-evalid')[0]
# 组合经销商信息请求地址
jxs_url = base_jxs_url+经销商id+'|'
# 请求数据(为json格式)
data = requests.get(jxs_url)
j = data.json()
# 获取经销商名称
item[key] = j['result']['List'][0]['CompanySimple']
else:
# 其他字段时,替换转义字符和空格等为空
item[key] = info.xpath('.//dd/text()')[0].replace("\r\n","").replace(' ','').replace('\xa0','')
四、数据存储
由于没啥反爬,这里直接将采集到的数据转化为pandas.DataFrame类型,然后存储为xlsx文件即可。
df = pd.DataFrame(items) df = df[['购买车型', '购买配置', '购买地点', '购车经销商', '购买时间', '裸车购买价']] # 数据存储在本地 df.to_excel(r'车辆销售信息.xlsx',index=None,sheet_name='data')
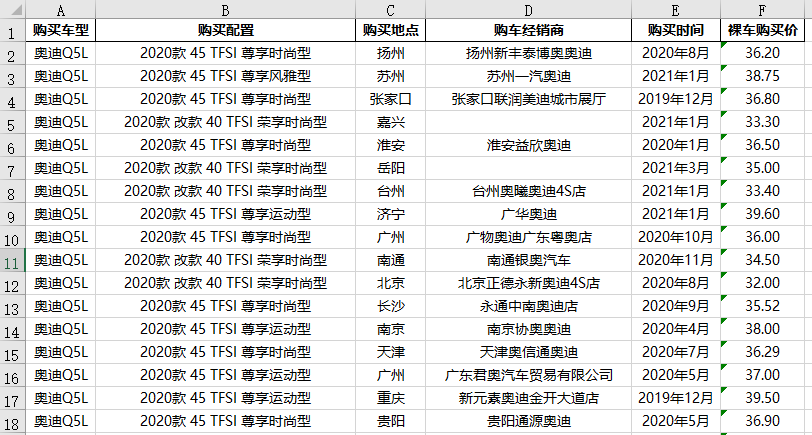
五、采集结果预览
整个爬虫过程比较简单,采集下来的数据也比较规范,以本文案例奥迪Q5L示例如下:
到此这篇关于Python爬虫之自动采集某车之家各车销售数据的文章就介绍到这了,更多相关Python采集汽车销售数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!