数据治理系列:大数据集群资源治理
https://mp.weixin.qq.com/s/kIuiv7qDo4yvxr-mIJf3QQ
随着移动互联网和大数据的蓬勃发展,“数据即资产”的理念深入人心。大数据已发展成为具有战略意义的生产资料,在各行各业发挥着极其重要的作用,而大数据也给很多企业带来了前所未有的自豪感和自信感。
但是,大数据真的是越“大”越好吗?大数据到达一定的规模,其所需承载的集群资源成本、数据开发维护成本和数据管理成本,将会呈几何式增长,同样也将会带来一笔巨额的开销。
如果缺少科学有效的治理管控,就会出现大量的“负”数据资产,这不仅会吞噬公司的利润,还会极大影响数据业务的发展以及平台运行的稳定。
很多大数据公司都会面临这样一些窘境:
- 新开发的数据任务,赶紧上,却发现集群资源不够了。
- 早上要跑完的任务,上午还没跑完,报表什么时候能看到?
- 上个月刚删了很多数据,存储又快满了,每天还有大量的数据在增长。
- 小文件数量这么多,集群 NameNode 内存快要爆了……
一个个头疼的问题接踵而至,面对这些问题我们是不是得换一个视角,给大数据集群资源来一场瘦身,取其精华、去其糟粕,让大数据集群资源环境更加健康,数据开发工作更加高效,公司投入产出比更加合理。
所以,大数据集群资源治理(以下简称“治理”)的工作亟待开展。
治理为何难以推动?
大多数公司在大数据发展初期都是野蛮生长的,它们更关注的是拥有更多的数据,更快速的完成数据业务开发,即使集群资源不够了,增加机器远比开展治理来得更快。
治理工作涉及众多的职能线与部门,角色不同,立场不同,治理投入度也不同。
即使集群资源达到一定规模,不得不治理时,各组织仍会以开发业务为核心,治理工作对他们来说优先级并不高,这也直接影响着治理效果。
治理工作如何开展?
治理工作需要从组织保障和治理工具两方面协同推进。公司的支持至关重要,有助于建设统一的数据文化,推进成立数据治理委员会,明确各组织的职责,制定治理制度、标准和流程等,以专职的治理团队负责治理工具建设和整体运营推进。
不同于传统数据资产管理,大数据集群资源治理聚焦计算资源和存储资源的缩容,在保障平台性能和稳定性的同时,又需要考量数据资产管理的赋能。
大数据集群资源的治理工作应结合公司现状,集中精力解决当前最大痛点,优先治理紧急的、投入产出比高的治理项。
对于紧急的治理项,如果涉及的部门和用户较少,能够通过面对面、邮件、社交媒体进行沟通,在短时间内解决的,采用线下手工治理方式。
对于非紧急治理项,涉及的部门和用户较广,并且需要长期治理的,则采用线上工具辅助治理,以减少人力投入成本。
为此,苏宁启动了“巡湖工程”、“千迁工程”等专项治理工程:
- 巡湖工程,主要任务是对大数据集群资源进行全面的巡检和治理。
- 千迁工程,是对高算力的 Hive 任务,进行分批次迁移至 SparkSQL 计算平台,同时保障治理工作的全面性和聚焦性。
在治理工作方式的演进上,苏宁采用了四个步骤:线下手工治理、半工具化治理、工具化治理和自驱动治理,最终实现各组织自我驱动型的治理常态。
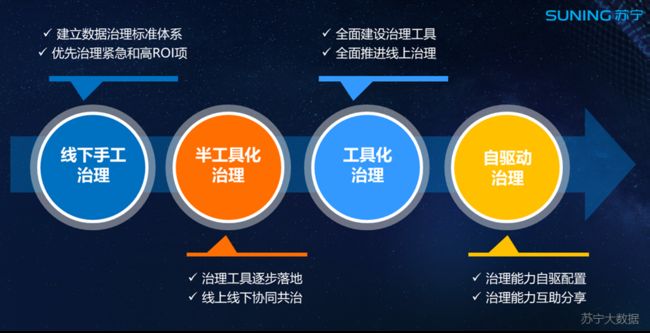
典型治理场景和方案
大数据集群资源治理是一项庞大且复杂的工程,苏宁结合自己的治理经历,从计算治理、存储治理、性能和稳定性治理三个方面,分享一下典型的治理场景和解决方案。
一、计算治理
毫无疑问,CPU 和内存是集群的稀缺资源,保障集群资源算力是首要任务。
一旦计算资源缺乏,将面临数据采集、数据存储、数据加工、数据稽核等一系列数据作业的延误,甚至崩溃。
如何降低计算资源的消耗,提高任务执行的性能,缩短任务产出的时间,是计算治理的核心目标。
以下主要从任务复算治理、任务异常治理、任务削峰平谷治理、任务资源配置治理、计算框架优化几个角度,分别介绍计算治理优化。
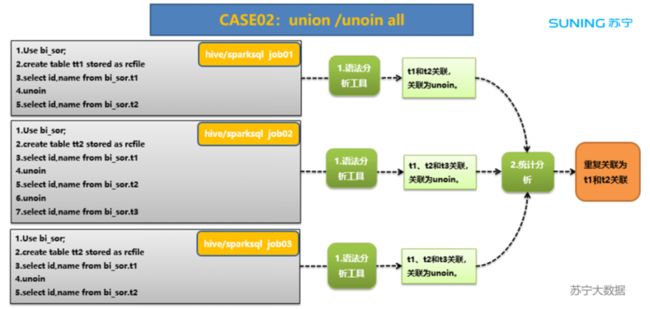
①任务复算治理
数仓建设过程中,往往存在事实表与维度表多次关联、事实表与事实表多次关联的现象,造成数据的重复计算。
任务复算治理,是面向大数据离线任务 Hive、SparkSQL 等 SQL 类的任务,通过对表与表关联的 union、join、子查询复杂关联等语法进行解析,识别重复计算的任务及其读取的关联表(源表)数据,并以此推动公共模型建设,减少任务重复计算。
其中,表关联 union 方式识别比较简单,示例如下:
②任务异常治理
任务出错率是衡量任务是否需要治理的重要指标,出错率过高意味着这个任务是没有价值的,一般可以被清除。如果任务确实需要使用,则必须进行优化。
以下作为一个参考,阈值可根据实际情况进行调整:

另外,当任务的目标表在一个或多个调度周期内未作更新,可认定为该任务未产出数据,任务清除下线的可能性很大。
③任务削峰平谷治理
从全天来看,任务执行会有明显的忙闲时之分。大部分公司的忙时主要集中在凌晨 0 点至 8 点,其余时间段相对为闲时,这就造成了忙时计算资源严重紧缺。
大家都想在早上 8 点前跑完任务,但是不是每个忙时任务都有这个必要呢?通过对忙时任务产出表的被读时间进行分析,可以识别出不合理调度执行的任务。
比如,如果任务在早上 8 点跑完,其写入的目标表在中午 12 点才被读取,是否可以将该任务避开忙时执行?
④任务资源配置治理
这里主要谈一下 Spark Streaming 实时任务资源治理。Spark Streaming 和 Spark 处理逻辑是相同的,都是收到外部数据流之后按照时间切分。
“微批”处理一个个切分后的文件,往往会存在资源分配过多的现象,这很容易被识别。

由上图可见,将数据按照时间划分成 N 等分。假设每批次 A 的间隔时长:batch_time;处理 B 的时长:total_delay;等待 C 的时长:wait_time。
当出现 batch_time>>total_delay 时,当前任务占用的资源会浪费 wait_time。
(可以通过UI查看任务资源使用情况,等待延时等信息)
通过缩减任务资源或多个任务合并成一个任务的方式来治理,都可以提升资源利用率。
虽然 total_delay 会加长,只要整体处理时间还在原定计划内,即可满足业务需求。
⑤计算框架优化
计算框架越来越多,也越来越成熟完善,选择适合自己的计算框架是关键。比如,由 Hive 任务迁移至 SparkSQL 任务、Storm 任务迁移至 Flink 任务,会带来性能上的明显提升。
但是,在海量数据任务的前提下,任务迁移绝非易事,需要综合考虑迁移的方案以及涉及的成本和风险。
二、存储治理
在数据爆发式增长的今天,存储资源的有效使用也面临着一系列的挑战。如何降低存储资源的消耗,节省存储成本,是存储治理的目标。
以下主要从生命周期管理、数据压缩治理、数据复存治理、数据价值治理几个角度介绍存储治理优化。
①生命周期管理
根据表生命周期对表进行清理删除,是最常见有效的存储治理方式。为降低数据丢失风险,可以先对表进行 rename 或通过 ranger 禁止表读写权限(相当于逻辑删除),7 天观察期过后删除至回收站,回收站默认保留 3 天后进行最终删除。
如果表的生命周期设置不合理(过长),也可以根据表的类型、业务情况进行稽核整改。
②数据压缩治理,参考hive、hdfs的存储格式压缩方式等
数据压缩治理是最简单有效的存储治理方式。数据压缩的好处显而易见,可以直接节省磁盘空间,提升磁盘利用率,并且加速网络传输。
但同时数据的压缩和解压,需要消耗计算资源。如果集群计算资源紧缺,并且数据经常被读,则建议根据实际场景选择合适的数据压缩方式。
在不同的存储格式和压缩算法下,简单查询、大宽表查询和复杂查询的执行表现均有差异,具体需结合实际场景选择使用。
③数据复存治理
比较简单的方式是通过解析 Hive 任务、SparkSQL 任务的代码逻辑,分析代码中的读表、写表、条件、字段函数,识别读表和写表是否重复存储。
另外,也可以通过表名、字段名的相似度进行识别,并结合某些周期产出数据,抽样进行相似度对比分析和识别。
如果表数据出现重复存储,还需要根据链路血缘关系找出上游任务,对整个链路上的表及上游任务实施“一锅端”治理。
④数据价值治理
梳理当前业务价值,从数据应用层(包括报表、指标、标签)源头分析投入产出比,对整体链路资源进行“从上至下”的价值治理。
如果表长时间未作更新(如 32 天)或未被读取,往往表明这张表价值很低,甚至没有价值,则可对表进行清理删除,这时可以优先考虑治理大表、分区表、高成本表。
三、性能和稳定性治理
集群的性能和稳定性治理涉及众多方面,这里重点谈一下小文件治理和数据倾斜治理。
①小文件治理
HDFS 虽然支持水平扩展,但是不适合大量小文件的存储。因为 NameNode 将文件系统的元数据存放在内存中,导致存储的文件数目受限于 NameNode 内存大小。当集群到了一定规模,NameNode 内存就会成为瓶颈。
小文件治理需要根据当前集群的文件数量,定义合适的小文件大小,比如小于 1M。
治理方式需要考虑从源头控制,在任务中配置文件合并参数,在 HDFS 存储之前进行小文件合并,但这又会延长任务执行时间。
所以,可选择在闲时进行周期性的小文件合并。另外,也可以设置小文件占比阈值,根据阈值触发小文件合并。
②数据倾斜治理
很多时候,我们在用 Hive 或 Spark 任务取数,只是跑了一个简单的 join 语句或group by,却跑了很长时间,往往会觉得这是集群资源不够导致的,但是很大情况下,是出现了“数据倾斜”的情况。
数据倾斜,在 MapReduce 编程模型中十分常见,大量的相同 key 被 partition 分配到一个分区里,造成了“某些任务累死,还拖了后腿,其他任务闲死”的情况,这并不利于资源最大化的有效利用。

由上图可见,通过对任务执行的监控日志分析,可以很方便的找出数据倾斜任务。
结合具体产生原因、数据分布和业务变化,有针对性的优化任务,任务执行时间能缩短几十倍以上,效果非常明显。
四、治理工具需要具备哪些能力?
面向治理责任人、项目主管、公司领导及治理运营人员,苏宁构建了统一的集群资源治理平台,全局把控集群计算资源、存储资源、性能和稳定性的整体情况,通过平台“识别通知、治理优化、监督考核”的支撑能力,实现一站式治理服务和闭环流程,降低治理投入的工作量,提升治理成效。

后记
建设了较为成熟的数据治理体系和标准流程,多项治理工作同步推进,均取得了显著的成果,为公司节约了可观的服务器资源投入成本。
并且,随着治理工作的推进,各组织也更主动的开展源头治理,大大减轻了事后治理的工作量。
治理工作不会一蹴而就,也不如前端业务那么容易出彩,显得“朴实无华”。每一位治理工作者都在背后默默的坚守付出,孜孜不倦地保障着大数据集群资源的最大化有效利用。
未来,苏宁大数据治理团队仍将持续推进治理工作,进一步提升治理工具产品支撑能力,赋能治理工作常态化、工具化和智能化。
我们崇尚科技与艺术的结合,最后赋诗一首,希望能帮助有需要的同仁更好的理解这项工作,更快的实现治理目标。