Deep Learning-2-Python实现卷积神经网络正、反向传播--让你彻底了解CNN
Yolov-1-TX2上用YOLOv3训练自己数据集的流程(VOC2007-TX2-GPU)
Yolov--3--TensorRT中yolov3性能优化加速(基于caffe)
yolov-5-目标检测:YOLOv2算法原理详解
yolov--8--Tensorflow实现YOLO v3
yolov--9--YOLO v3的剪枝优化
yolov--10--目标检测模型的参数评估指标详解、概念解析
yolov--12--YOLOv3的原理深度剖析和关键点讲解
1、卷积神经网络的正向传播
一个新的激活函数——Relu(线性整流函数)
(Rectified Linear Unit, ReLU)
最近几年卷积神经网络中,激活函数往往不选择sigmoid或tanh函数,而是选择relu函数。Relu函数的定义是:
Relu函数图像如下图所示:
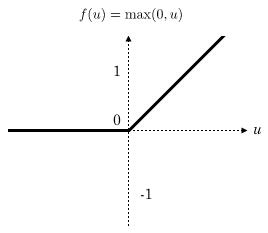
Relu函数作为激活函数,有下面几大优势:
- 速度快 和sigmoid函数需要计算指数和倒数相比,relu函数其实就是一个max(0,x),计算代价小很多。
- 减轻梯度消失问题 回忆一下计算梯度的公式。其中,是sigmoid函数的导数。在使用反向传播算法进行梯度计算时,每经过一层sigmoid神经元,梯度就要乘上一个。从下图可以看出,函数最大值是1/4。因此,乘一个会导致梯度越来越小,这对于深层网络的训练是个很大的问题。而relu函数的导数是1,不会导致梯度变小。当然,激活函数仅仅是导致梯度减小的一个因素,但无论如何在这方面relu的表现强于sigmoid。使用relu激活函数可以让你训练更深的网络。

https://zhuanlan.zhihu.com/p/32824193 
- 稀疏性 通过对大脑的研究发现,大脑在工作的时候只有大约5%的神经元是激活的,而采用sigmoid激活函数的人工神经网络,其激活率大约是50%。有论文声称人工神经网络在15%-30%的激活率时是比较理想的。因为relu函数在输入小于0时是完全不激活的,因此可以获得一个更低的激活率。
1、sigmoid 只会输出正数,以及靠近0的输出变化率最大,tanh和sigmoid不同的是,tanh输出可以是负数,ReLu是输入只能大于0,如果你输入含有负数,ReLu就不适合,如果你的输入是图片格式,ReLu就挺常用的。

卷积神经网络的示意图

网络架构
如上图所示,一个卷积神经网络由若干卷积层、Pooling层、全连接层组成。
对于上图展示的卷积神经网络:
INPUT -> CONV -> POOL -> CONV -> POOL -> FC -> FC
全连接神经网络每层的神经元是按照一维排列的,也就是排成一条线的样子;而卷积神经网络每层的神经元是按照三维排列的,也就是排成一个长方体的样子,有宽度、高度和深度。
卷积神经网络输出值的计算
卷积层输出值的计算
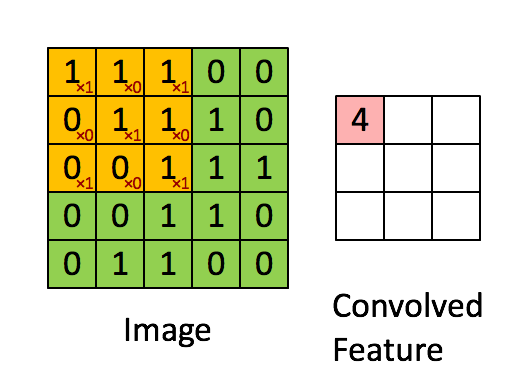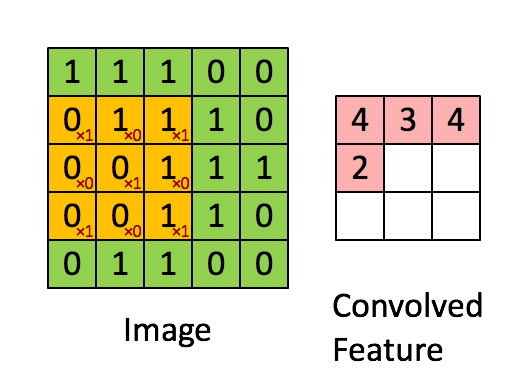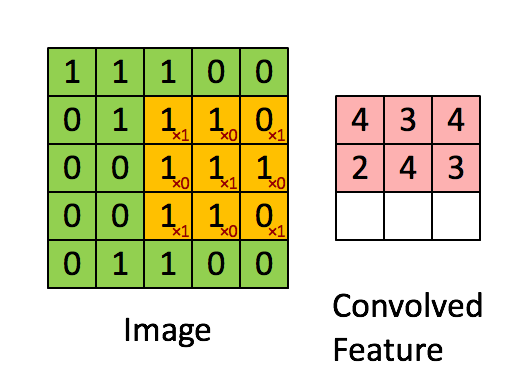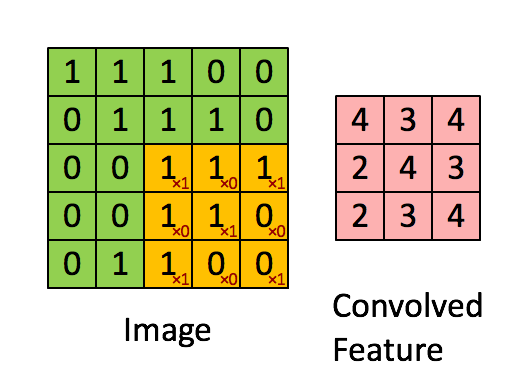

以上就是卷积层的计算方法。这里面体现了局部连接和权值共享:
每层神经元只和上一层部分神经元相连(卷积计算规则),且filter的权值对于上一层所有神经元都是一样的。对于包含两个3*3*3的fitler的卷积层来说,其参数数量仅有(3*3*3+1)*2=56个,且参数数量与上一层神经元个数无关。
我们利用卷积公式可以简化卷积神经网络的表达。


从上图可以看到,A左上角的值与B对应区块中右下角的值相乘,而不是与左上角的相乘。
因此,数学中的卷积和卷积神经网络中的『卷积』还是有区别的,为了避免混淆,我们把卷积神经网络中的『卷积』操作叫做互相关(cross-correlation)操作。
卷积和互相关操作是可以转化的。首先,我们把矩阵A翻转180度,然后再交换A和B的位置(即把B放在左边而把A放在右边。卷积满足交换率,这个操作不会导致结果变化),那么卷积就变成了互相关。
Pooling层输出值的计算
Pooling层主要的作用是下采样,通过去掉Feature Map中不重要的样本,进一步减少参数数量。Pooling的方法很多,最常用的是Max Pooling。Max Pooling实际上就是在n*n的样本中取最大值,作为采样后的样本值。下图是2*2 max pooling:

除了Max Pooing之外,常用的还有Mean Pooling——取各样本的平均值。
对于深度为D的Feature Map,各层独立做Pooling,因此Pooling后的深度仍然为D。
2、卷积神经网络的反向传播
3、CNN的全连接层
https://blog.csdn.net/qq_39521554/article/details/81385159
在CNN结构中,经多个卷积层和池化层后,连接着1个或1个以上的全连接层.与MLP类似,全连接层中的每个神经元与其前一层的所有神经元进行全连接.全连接层可以整合卷积层或者池化层中具有类别区分性的局部信息.为了提升 CNN网络性能,全连接层每个神经元的激励函数一般采用ReLU函数。
最后一层全连接层的输出值被传递给一个输出,可以采用softmax逻辑回归(softmax regression)进行 分 类,该层也可 称为 softmax层(softmax layer).
对于一个具体的分类任务,选择一个合适的损失函数是十分重要的,CNN几种常用的损失函数并分析了它们各自的特点.通 常,CNN的全连接层与MLP 结构一样,CNN的训练算法也多采用BP算法
举个例子:

最后的两列小圆球就是两个全连接层,在最后一层卷积结束后,进行了最后一次池化,输出了20个12*12的图像,然后通过了一个全连接层变成了1*100的向量。
这是怎么做到的呢,其实就是有20*100个12*12的卷积核卷积出来的,对于输入的每一张图,用了一个和图像一样大小的核卷积,这样整幅图就变成了一个数了,如果厚度是20就是那20个核卷积完了之后相加求和。这样就能把一张图高度浓缩成一个数了。
全连接的目的是什么呢?
因为传统的网络我们的输出都是分类,也就是几个类别的概率甚至就是一个数--类别号,那么全连接层就是高度提纯的特征了,方便交给最后的分类器或者回归。
但是全连接的参数实在是太多了,你想这张图里就有20*12*12*100个参数,前面随便一层卷积,假设卷积核是7*7的,厚度是64,那也才7*7*64,所以现在的趋势是尽量避免全连接,
目前主流的一个方法是全局平均值。也就是最后那一层的feature map(最后一层卷积的输出结果),直接求平均值。有多少种分类就训练多少层,这十个数字就是对应的概率或者叫置信度。
以VGG-16为例:

对224x224x3的输入,最后一层卷积可得输出为7x7x512,如后层是一层含4096个神经元的FC,则可用卷积核为7x7x512x4096的全局卷积来实现这一全连接运算过程,其中该卷积核参数如下:
“filter size = 7*7, padding = 0, stride = 1, Depth_in = 512, D_out = 4096”
经过此卷积操作后可得输出为1x1x4096。
如需再次叠加一个2048的FC,则可设定参数为“filter size = 1*1, padding = 0, stride = 1, Depth_in = 4096, D_out = 2048”的卷积层操作。
4、softmax函数详解
softmax函数
softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类!
假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的softmax值就是

更形象的如下图表示:

softmax直白来说就是将原来输出是3,1,-3通过softmax函数一作用,就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标!
举一个我最近碰到利用softmax的例子:我现在要实现基于神经网络的句法分析器。用到是基于转移系统来做,那么神经网络的用途就是帮我预测我这一个状态将要进行的动作是什么?比如有10个输出神经元,那么就有10个动作,1动作,2动作,3动作...一直到10动作。(这里涉及到nlp的知识,大家不用管,只要知道我现在根据每个状态(输入),来预测动作(得到概率最大的输出),最终得到的一系列动作序列就可以完成我的任务即可)
原理图如下图所示:

那么比如在一次的输出过程中输出结点的值是如下:
[0.2,0.1,0.05,0.1,0.2,0.02,0.08,0.01,0.01,0.23]
那么我们就知道这次我选取的动作是动作10,因为0.23是这次概率最大的,那么怎么理解多分类呢?很容易,如果你想选取俩个动作,那么就找概率最大的俩个值即可~(这里只是简单的告诉大家softmax在实际问题中一般怎么应用)
参考:
1、https://blog.csdn.net/weixin_37251044/article/details/81349287
2、http://m.elecfans.com/article/666866.html
3、http://www.mamicode.com/info-detail-2232195.html
4、https://www.zybuluo.com/hanbingtao/note/485480