最近一直在研究文本检测方向的内容,把最近看的论文整理一下。近期有时间会把所有的写完,写一个综述。
- 基于文本框的坐标回归的方法
- CTPN: Detecting Text in Natural Image with Connectionist Text Proposal Network 开源代码
- TextBoxes: A Fast Text Detector with a Single Deep Neural Network 开源代码
- SegLink: Detecting Oriented Text in Natural Images by Linking Segments 开源代码
- TextBoxes++: A Single-Shot Oriented Scene Text Detector 开源代码
- EAST: An Efficient and Accurate Scene Text Detector 开源代码
- AdvancedEAST(无论文) 开源代码
- Pixel-Anchor: A Fast Oriented Scene Text Detector with Combined Networks
- 基于语义分割后进行实例分割的方法
- PixelLink: Detecting Scene Text via Instance Segmentation 开源代码
- PSENet: Shape Robust Text Detection with Progressive Scale Expansion Network 开源代码
3.字符级文本检测算法
- CRAFT: Character Region Awareness for Text Detection 开源代码
4.文本框回归和语义分割的组合方法
- LOMO:Look More Than Once- An Accurate Detector for Text of Arbitrary Shapes
- Arbitrary Shape Scene Text Detection with Adaptive Text Region Representation
- 端到端的文本检测识别
- Towards End-to-end Text Spotting with Convolutional Recurrent Neural Networks
- Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes 开源代码
- FOTS: Fast Oriented Text Spotting with a Unified Network
- 待刷
- PMTD: Pyramid Mask Text Detector
- TextMountain: Accurate Scene Text Detection via Instance Segmentation
一、EAST
论文关键idea
- 提出了一个两阶段的文本检测方法,分别为FCN网络阶段和NMS合并阶段,FCN可以直接生成文本区域,消除冗余过程及复杂的中间步骤。
- 该方法即可以检测单词级别,又可以检测文本行级别,检测的形状可以为矩形或者任意形状的四边形。
- 针对文本行的特点,采用了Locality-Aware NMS来对生成的文本区域进行过滤,降低了NMS的复杂度。
Pipeline
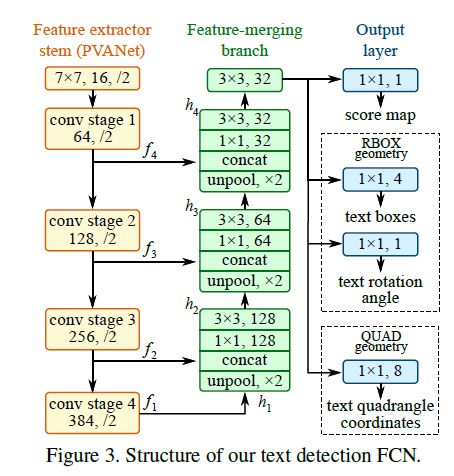
- 特征提取主网络:采用PVANet为基础网络(可以替换为VGG、Resnet等)。
- 特征合并分支:依次将主网络中1/32,1/16,1/8,1/4特征图进行合并。
- 输出层:RBOX则输出6个通道(旋转矩形),QUAD则输出9个通道(四边形)。
标签生成过程
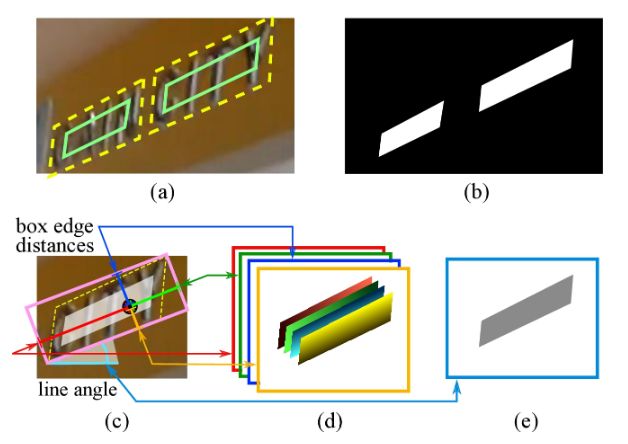
(a)文本框(黄色虚线)和缩小的文本框(绿色实线)
(b)Text score map,正样本区域,会进行shrink,在ICDAR2015上的系数为0.3。
(c)RBOX生成过程,粉色代表四边形最小外接矩形,蓝色、绿色、黄色、红色分别为距粉色文本框的上、右、下、左的距离,淡蓝色为角度。
(d) 每个像素到矩形边界的4个通道距离。
(e)旋转角度。
Locality-Aware NMS
如果使用传统的NMS,复杂度为O(n^2),过于复杂。
在文本检测中,附近像素点预测的几何图形是高度相关的,可以逐行使用NMS进行合并(猜测是由于文本朝向大多数为横向),再对每一行合并的结果再使用NMS进行合并。合并区域的所有像素点的预测值采用加权平均,不同于普通NMS的丢弃,可以充分利用每一个像素点的预测值。
缺点
由于感受野的限制,对于长文本的的检测效果较差。
个人总结
EAST通过FCN网络将不同尺度的特征图融合,增强了特征图的信息表达,最后在Pixel上直接回归出带角度的框,根据文本检测的特点提出局部感知NMS加快后置处理的速度并且充分利用了每一个预测结果。整个算法过程优雅简洁,之前的文本检测都是基于目标检测框架,通过设置适合文本大小的Anchors(Textbox)或者CTPN的后连接。而EAST却巧妙利用了语义分割的思想,打开了文字检测的新大门。
二、Advanced EAST
无论文,算法来自于ICPR比赛,主要针对于EAST对长文本检测差进行改进。
网络结构
作者发现EAST对长文本检测差主要受到感受野的限制,于是对于RBOX不再预测距文本框上下左右的距离,而是将Text score map分为文本头部、中部和尾部三部分。
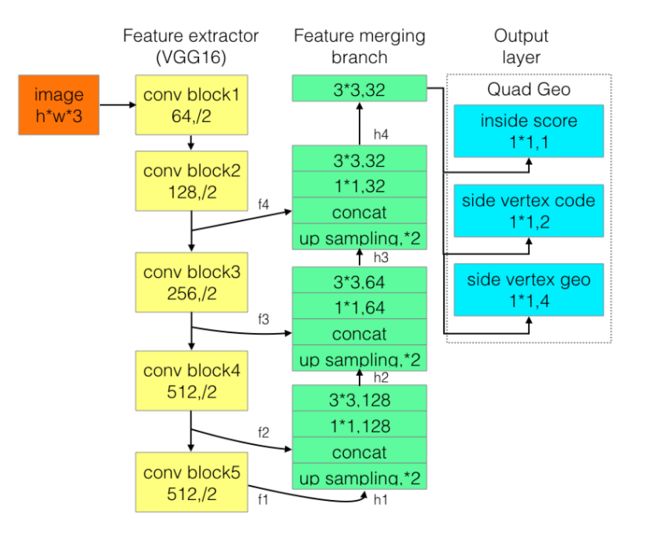
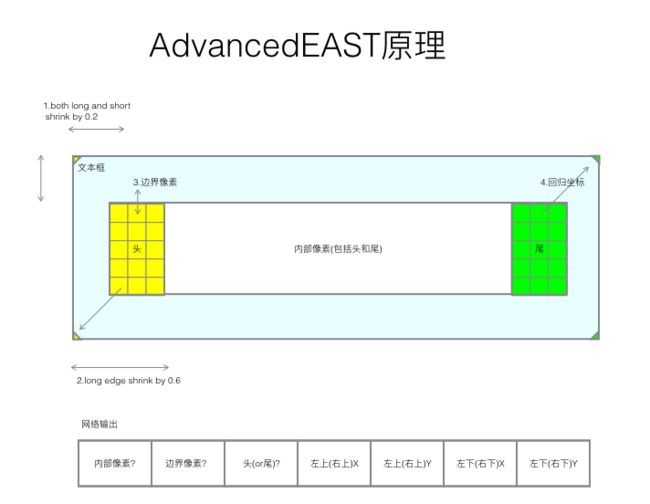
输出层分别是1位score map, 是否在文本框内;2位vertex code,是否属于文本框边界像素以及是头还是尾;4位geo,是边界像素可以预测的2个顶点坐标。其中所有像素构成了文本框形状,然后只用边界像素去预测回归顶点坐标。边界像素定义为黄色和绿色框内部所有像素,是用所有的边界像素预测值的加权平均来预测头或尾的短边两端的两个顶点。头和尾部分边界像素分别预测2个顶点,最后得到4个顶点坐标。
后置处理
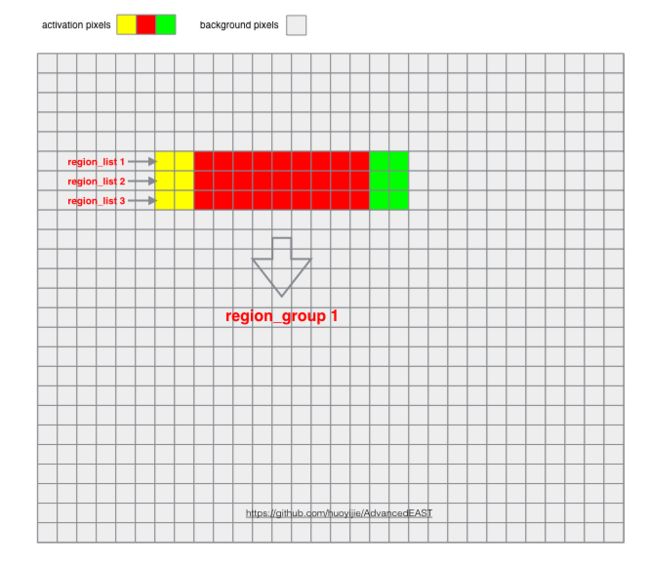
1由预测矩阵根据配置阈值得出激活像素集合
2.左右邻接像素集合生成region list集合
3.上下邻接region list组成region group(文本框激活区域)集合
4.遍历每个region group,生成其头和尾边界像素集合,
5.根据头和尾边界像素预测的到顶点Delta值与该边界像素坐标值计算顶点坐标,每个顶点的所有预测值的加权平均值作为最后的预测坐标值,并输出score
实测图
在作者预训练的736的权重下对营业执照进行预测,对长文本的检测效果变好,但是对密集文本的效果变差,感觉作者的后置处理的逻辑还有优化的空间。


个人总结
Advanced EAST是基于EAST对于长文本检测表现差的痛点进行改进,通过将文本区域切割成头、中、尾,其中头尾预测角点,减少了预测长文本时的困难度。但是并没有从根本上去解决长文本预测问题,因为在像素点分类时,依旧需要判断是否是头或尾,还是需要用到整个文本区域的信息。因此长文本预测问题仅在回归框的维度上解决了,在分类维度上依旧存在。并且新提出的NMS,虽然相对于局部感知NMS的复杂度更低,稀疏文本上表现较好,但是对于密集文本效果较差,对于后置处理还需要进行优化。
三、PixelLink
论文关键idea
- 直接通过实例分割结果中提取文本位置,而不是从边界框回归,实现文本检测。
- 受到SegLink的Link思想的启发,加入了Link将像素点进行连接,得到文本框。
Pipeline
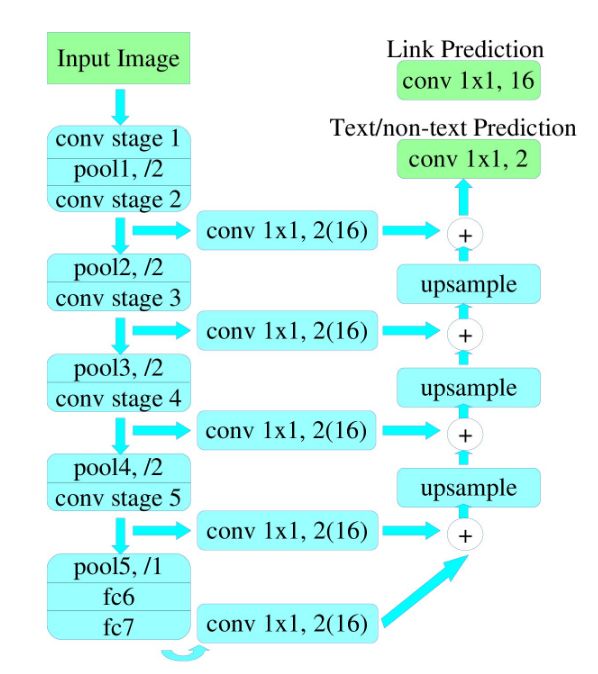
论文中给出了两种网络结构:PixelLink+VGG16 2s和PixelLink+VGG16 4s ,下图的网络结构为PixelLink+VGG16 2s。
对于PixelLink+VGG16 2s网络结构:其融合的特征层包括:{conv2_2, conv3_3, conv4_3, conv5_3, fc_7},得到的特征图分辨率为原图的二分之一 。
对于PixelLink+VGG16 4s网络结构:其融合的特征层包括:{conv3_3,conv4_3, conv5_3, fc_7},得到的特征图分辨率为原图的四分之一 。
- 使用VGG16作为基础网络,将最后的FC6和FC7改为卷积层,Pool5的stride改为1,因此整个网络下采样16倍,FC7得到的特征图和Conv5得到的特征图大小相同。
-
对已提取的特征层,采用自顶向下的方法进行融合,融合操作包括先向上采样(双线性插值),然后再进行add操作。注意:这里包含了两种操作:pixel cls和pixel link,对应的卷积核通道数分别为2和16。
 PixelLink+VGG16 2s.png
PixelLink+VGG16 2s.png
标签生成过程
- 像素的生成规则:在文本行bbox内的pixel被标注成positive,如果存在重叠文本时,则非重叠的文本框区域内的像素被标注成positive,否则被标注成negative。(个人觉得对于重叠文本的处理存在问题)
- 像素间的link生成规则:给定一个像素,若其分别与邻域的八个像素两两属于同一个文本实例,则将其两两之间的link标注为positive,否则标注为negative 。
像素连接规则
对于预测的像素和链接,可以分别对它们应用两个不同的阈值。即筛选出正像素和正链接,然后使用正向链接将正像素组合在一起,从而产生CC的集合,每个CC代表检测到的文本实例,实现了实例分割。值得注意的是,给定两个相邻的正像素,它们的连接是由它们两个预测的,并且当两个连接预测中的一个或两个都为正时它们应该连接。连接的规则采用的是Disjoint set data structure(并查集)的方法。
提取边界框
通过OpenCV(2014)中的minAreaRect的函数将语义分割得到的CC组件进行实例分割,包含CC的最小外接矩形(带角度)。没有再进行边框回归,这也是和SegLink等回归方法的关键区别:PixelLink是直接从分割结果中提取bbox,而SegLink采用的是边框回归。
下图表示输入样本和提取边界框的过程。虚线框中的八个热图代表八个方向上的链接预测。
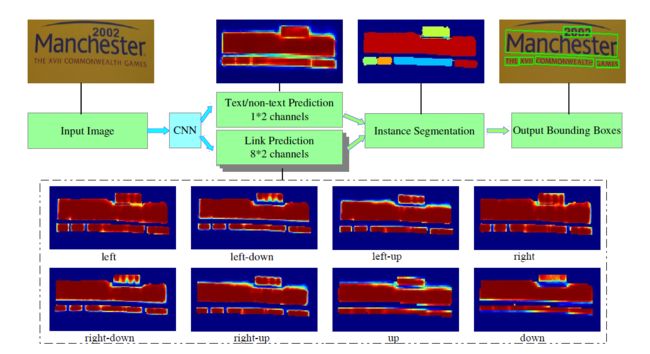
分割后的过滤
由于PixelLink尝试通过链接将像素组合在一起,因此不可避免地会带来一些噪点预测,因此后过滤步骤是必要的。简单而有效的解决方案是通过检测框的简单几何特征进行过滤,例如宽度,高度,面积和高宽比等。在ICDAR2015中,作者过滤了短边小于10个像素点,面积小于300的文本实例。(不同的数据集需要调整不同的策略)
整个后处理过程
网络对每个像素点输出了18个预测值,分别是文本/非文本以及八个领域正链接/负链接,使用两个阈值对其进行过滤,得到正像素及其正链接。通过像素连接规则,将像素点连成若干个CC组件,再使用minAreaRect得到不同CC组件的外接矩形作为其预测文本框。最后使用后过滤规则消除部分噪音区域。然有些词在文本/非文本预测中难以分离,但它们可以通过链接预测分离。
PixelLink的优势
PixelLink作为一种基于分割的方法,与基于回归的方法相比有几个优势:
- PixelLink可以用更少的数据训练得更快,并且表现得比其他更好。在经过大约25K次训练迭代(不到EAST或SegLink所需的一半)之后,PixelLink可以达到与SegLink或EAST相当的性能。但是,PixelLink是从零开始进行培训的,其他则需要从ImageNet预模型进行微调。
 训练.png
训练.png
原因:像我们人类一样,问题越简单,我们可以学得越快,我们需要的教材就越少,而且我们能够表现得越好。这可能也同样适用于深度学习。在PixelLink中,预测神经元只需要观察特征图上的自身及其相邻像素的状态,所以有两个因素可能起作用:
1、对感受野的要求。当采用VGG16作为主干时,SegLink在长文本检测中表现比EAST好得多,这种差距应该由他们对接受领域的不同要求引起。EAST使用PVANET2x作为头网络时远好于VGG16,EAST的预测神经元被训练观察整个图像,以便预测任何长度的文本。SegLink虽然也是基于回归的,但它的只是试图预测文本片段,因此对感受野的要求比EAST要低。
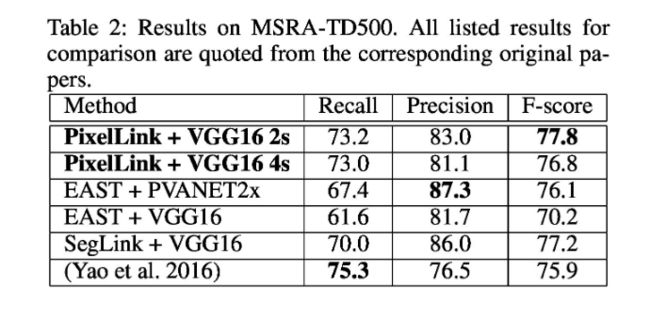 TD500中检测长文本.png
TD500中检测长文本.png
2、任务复杂度不同。基于边框回归的方法中,边界任务难度框表示为四边形或旋转矩形。每个预测神经元必须学会预测它们的位置为精确的数值,即四个顶点的坐标或中心点,宽度,高度和旋转角度。这种方法已经被诸如Faster R-CNN,SSD,YOLO等算法所证明是有效的。但是,这种预测并不直观和简单。神经元必须学习很多,并努力学习以胜任他们的任务。
PixelLink的不同tricks效果分析
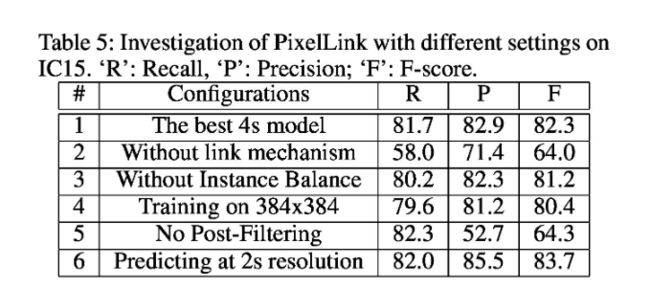
- 实验二:Link的设计很重要,它可以将语义分割转换为实例分割。
- 实验三:OHEM的方法平衡正负样本,可以提高模型性能。
- 实验四:使用低分辨率图像进行训练,准确率和召回率显著下降,高分辨率图像对于pixel类的方法可以提高性能。
- 实验五:不使用后过滤,虽然召回率小幅提高,但是精度大幅度下降,说明像素+链接的方法会带来大量小区域的噪音。
- 实验六:2S的方法好于4S的方法,高分辨率的特征图可以带来性能的提升,但是2S的速度大于4S速度的两倍,可能权衡性能和速度自行选择。
个人总结
个人非常喜欢这边论文,实验做的非常全,从各个维度各个tricks去评估了算法。
PixelLIink,使用pixel分类进行语义分割,link链接进行实例分割,不同于以往的边框回归的方法,降低了对感受野的要求以及预测神经元的任务复杂度,相比于其他方法不需要大数据集,更少的训练步数,就能得到具有竞争力的结果。
但是,缺点也很明显。
- 需要调整的参数太多:对于不同数据集需要调整不同的pixel和link的两个阈值,需要设计不同的后过滤策略。
- 无法很好的处理噪音较多或者背景多样化的数据:从实验五(不使用后过滤)中可以看出,这种只观察领域的pixel方法,虽然对感受野要求大大降低,但是同时数据中如果噪音多,性能可能会大大下降。
改进方面可以找一个和EAST对感受野折中的方法。
四、PSENET
论文关键idea
- 提出了一种新颖的渐进扩展网络(PSENet),它可以精确地检测任意形状的文本实例。
- 提出了一种渐进的尺度扩展算法,它能够准确地将紧密的文本实例分开。
- PSENET显著优于现有的曲线文本检测数据集Cut-CtTW1500的方法。此外,它还实现了关于规则四边形文本基准的竞争结果:ICDAR2015和ICDAR2017MLT。
Pipeline
论文中对网络结构交代的并不是和清楚,我看了源码之后整理了一下。
backbone是Resnet网络(这里将蓝色特征图用{C5,C4,C3,C2}对应{P5,P4,P3,P2}),采用了FPN结构。
- C5(1/32,通道数2048),经过CBR(1X1X2048X256卷积,通道数降维至256,BN,RELU),双线性插值上采样至1/4之后得到了P5。
- C4(1/16,通道数1024),经过CBR(1X1X1024X256卷积,通道数降维至256,BN,RELU)之后,和P5对应像素点相加,再接一个CBR(3X3X256X256卷积,平滑化,BN,RELU),双线性插值上采样至1/4之后得到了P4。
- C3(1/8,通道数512),经过CBR(1X1X512X256卷积,通道数降维至256,BN,RELU)之后,和P4对应像素点相加,再接一个CBR(3X3X256X256卷积,平滑化,BN,RELU),双线性插值上采样至1/4之后得到了P3。
- C2(1/4,通道数256),经过CBR(1X1X256X256卷积,BN,RELU)之后,和P3对应像素点相加,再接一个CBR(3X3X256X256卷积,平滑化,BN,RELU)之后得到了P2。
- P2,P3,P4,P5concat成一个通道数1024维的F,经过CBR(3X3X1024X256卷积,通道数降维至256,BN,RELU),再经过一个1X1X256X7卷积降维为7通道数。(1+n,n为S的数量),之后再使用上采样(1S则上采样4倍,2S则上采样2倍,4S则不进行上采样)得到输出。

渐进尺度扩展算法
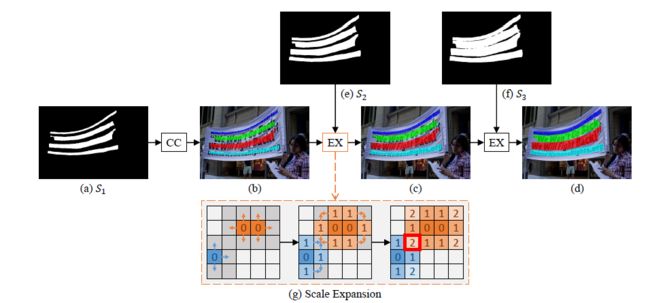
假如n=3,我们可以得到三个分割结果S1,S2,S3,首先使用S1(最小内核)的分割结果进行初始化,得到四个联通的CC组件{C1(深蓝色),C2(绿色),C3(红色),C4(天蓝色)}。基于最小内核完成了实例分割,将紧密的文本实例分开。然后我们通过合并S2的结果得到图(c),再合并S3的结果得到图(d)。合并过程如图(g)所示。扩展基于广度搜索算法,该算法从多个核的像素开始,然后迭代地合并相邻的文本像素。注意,在展开过程中可能存在冲突的像素,如图3(g)中的红色框所示。在我们的实践中处理冲突的原则是,混淆的像素只能在先到先得的基础上由一个单一内核合并。 由于“渐进的”扩展过程,这些边界冲突不会影响最终检测和性能。
标签生成过程
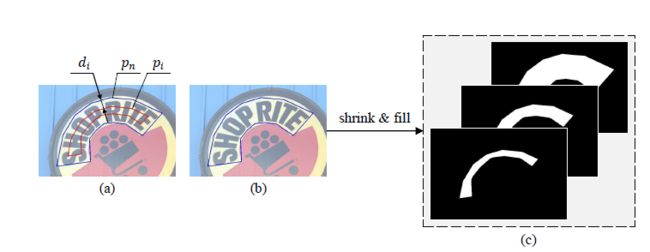
PSENet产生具有不同内核规模的分割结果{S1,S2,S3,S4,S5,S6},因此,它需要相应的Ground Truth。使用 Vatti clipping algorithm 把图(a)中的原始蓝色区域Pn缩减di个像素得到红色区域Pi,图(b)代表原始的文本实例mask区域,图(c)表示依次缩减得到的S1,S2,S3对应的G1,G2,G3。
实测图
默认参数。仅在ICDAR2015上进行训练,预测结果断框明显(需要调整m,m越大越难区分紧密文本,m越小越容易断框)

个人总结
作者也是基于实例分割去完成文本检测,但是基于实例分割方法的痛点就是对紧密文本的区分能力弱,作者没有使用link的思想在语义分割的基础上完成实例分割(pixel-link使用link去分割密集文本),而是使用最小内核的思想完成实例分割,再用渐进式的方法使用不同内核补充实例分割区域。对于弯曲文本的效果远优于其他算法。但是需要合理的选择超参数,不用数据集需要调整不同的n,m值(这两个值可以去看下论文)。
五、SegLink
论文关键idea
- 提出了文本行检测的两个基本组成元素:segment和link。
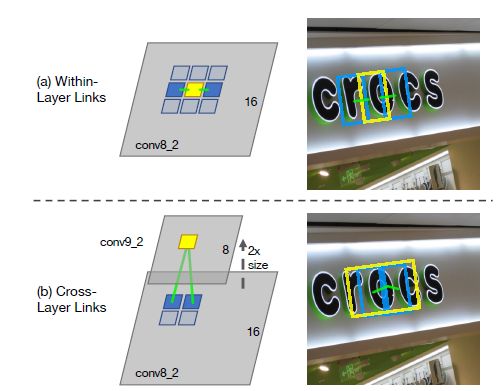
- 提出了两种link类型: 层内连接(within-layer link)和跨层连接(cross-layer link)。
Pipeline
- backbone用的是基于VGG的SSD结构,fc6改成3X3X512X1024的s=1卷积;fc7改成1X1X1024X1024的s=1卷积得到Conv7;先用1X1X1024X256进行降维,再用3X3X256X512的S=2卷积缩小特征图尺寸得到Conv8_2;先用1X1X512X128进行降维,再用3X3X128X256的S=2卷积缩小特征图尺寸得到Conv9_2;先用1X1X256X128进行降维,再用3X3X128X256的S=2卷积缩小特征图尺寸得到Conv10_2;先用1X1X256X128进行降维,再用3X3X128X256的S=2卷积缩小特征图尺寸得到Conv10_2;最后用3X3X256X256的S=2的卷积缩小特征图尺寸得到Conv11。(这边和代码的实际实现有出入,代码FC6使用了空洞卷积,并且少一层layer,论文中的结构图画错了。结构图中conv8_2的输出应该是512个,conv9_2的输出应该是256个)
- 提取不同层的feature map,论文中提取了conv4_3, conv7, conv8_2, conv9_2, conv10_2, conv11。
- 对不同层的feature map使用3X3的卷积层产生最终的输出(包括segment和link),不同特征层输出的维度是不一样的,因为除了conv4_3层外,其它层存在跨层的link.这里segment是text的带方向bbox信息(它可能是个单词,也可能是几个字符,总之是文本行的部分),link是不同bbox的连接信息(文章将其也增加到网络中自动学习)。
- 然后通过融合规则,将segment的box信息和link信息进行融合,得到最终的文本行。
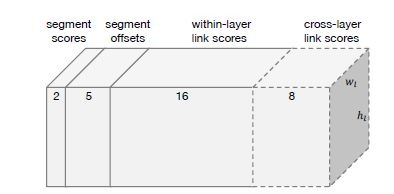
- 网络输出维度:对于conv4_3层,处于顶层,无跨层,其输出的维度为2X8+2+5=23;对于conv7, conv8_2, conv9_2, conv10_2, conv11其输出的维度为2X8(同一层的link)+2X4(跨层的link,前一层是后一层的邻居,但后一层不是前一层的邻居)+2(得分)+5(x, y, w, h, θ)=31

Combining Segments with Links
- 首先通过人工设定的 α 和β 作为阈值分别过滤部分segments和link。(作者测试了对于阈值的选择敏感度低)
- 将每个segment看成node,link看成edge,建立图模型,再用DFS(depth first search)找到连通分量,每个连通分量包含一系列segments(用B表示),用下面的Algorithm1进行融合输出单词的box

个人总结
感觉文章主要是对CTPN的改进,采用了多尺度的SSD作为backbone,加入了角度预测,没有使用CTPN简单的后连接规则,而是选择在网络中加入Link的思想,由网络去判断框与框是否需要进行连接。可以较好的处理长文本,由于加入了link对密集文本也有一定的区分能力。
缺点:
- α和β这两个阈值是通过网格搜索的方法求得,这里采用0.1step进行超参数穷举搜索。
- 不能检测很大的文本,这是因为link主要是用于连接相邻的segments,而不能用于检测相距较远的文本行。
- anchors的设定均是1:1,大部分参考了SSD修改来进行文本检测,感觉还有很多需要探索的地方。
六、Textboxes
论文关键idea
- 提出了端到端的神经网络文本检测模型(无需后处理)
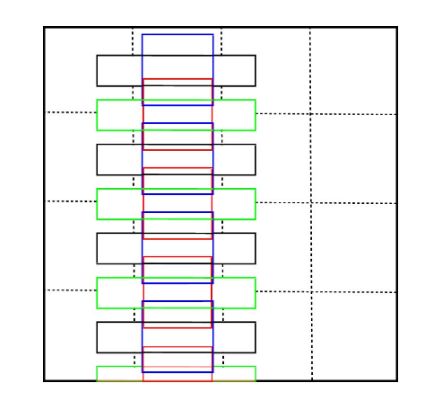
- 采用不规则的1X5卷积核而不是标准的3X3卷积核。这种尺寸的卷积核可以产生矩形的接收区域,它可以更好地融合具有较大纵横比的字,还可以避免方形接收区带来的噪声信号。
- 修改了SSD默认的宽高比,分别为[1 2 3 5 7 10],目的是适应文本行长度比较长,宽度比较短的特性,也就是说现在的default box是长条形。同时为了避免框在水平方向密集而在垂直方向稀疏的问题,在垂直方向的偏移量为1/2的单元格高度。(蓝色和红色分别是1:1的anchors,黑色和绿色分别是1:5的anchors,蓝色框在垂直方向下移1/2单元格高度得到红色框。同理黑色框在垂直方向下移1/2单元格高度得到绿色框。)
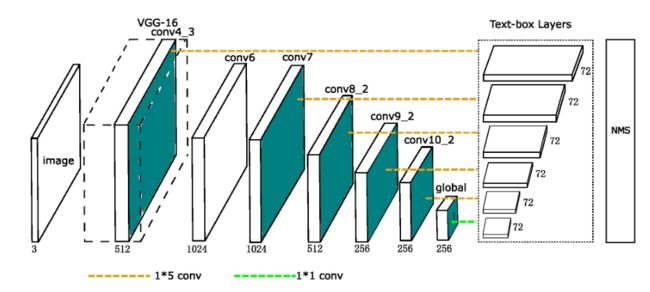
Pipeline
- backbone用的是基于VGG的SSD结构,具体可参考SegLink中列出的网络结构。
- Text-box layers 在不同的feature map(包括conv4_3,conv7,conv8_2,conv9_2,conv10_2,pool11)上分别通过不规则卷积核得到了各自最后的输出,通道数为72(12X(2+4),每半个单元格6个框,一个单元格12个框,每个框预测w,h,x,y以及文本/非文本),NMS后得到最后的结果。
标签生成过程和损失函数
这部分和SSD完全一致。
多尺度预测
虽然在anchors尺寸和卷积核尺寸上针对文本检测进行了改进和优化,但是在检测长文本行(即超过了默认框的最大比例)还是会出现检测不到的情况。针对这个问题,论文提出在预测时将原图片放缩到不同的大小,分别为 300X300,700X700,300X700,500X700,1600X1600(宽X高)。注意在训练时使用的是300X300。
个人总结
- 论文大部分均是基于SSD,针对文本检测修改了anchors尺寸,卷积核尺寸,创新点较少。
- 依赖于anchors尺寸的先验设计,不同数据集上需要进行调整。
- 多尺度预测提高了对anchors未覆盖到的长文本的检测效果,但是也带来了额外的计算开销,多尺度的尺寸也需要手动设计。
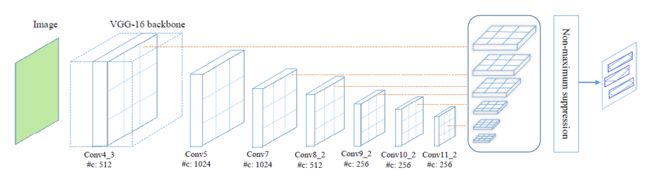
七、Textboxes++
论文主要是针对Textboxes进行改进,最大的提升是可以预测旋转文本框。其他方面的改进比较小,有兴趣可以看看原始论文看看作者的工作。在此不再赘述。
Pipeline
依旧是SSD结果作为backbone。
如何处理带角度框
对于黄色实线为真实框,我们先求其最小外接水平矩形得到绿色实线框,黑色虚线框和绿色虚线框均为预设置的anchors,计算和绿色实线框IOU最大的预设框即绿色虚线框,回归其四个点坐标至真实框(红色箭头)。
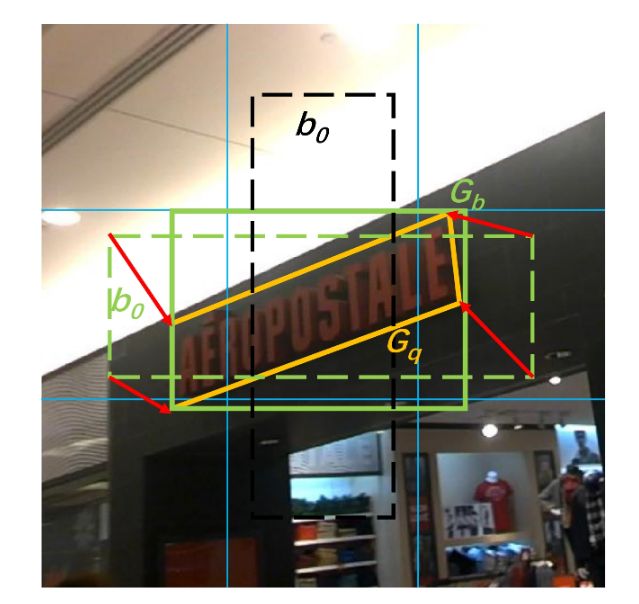
个人总结
- 创新很少,依旧在用SSD框架。
- 个人看了2018年其他文本检测论文,仅个人认为对于深度学习的文本检测任务不会向Textboxes系列方向上发展。
八、CRAFT
论文关键idea
- 提出了检测单个字符及字符间连接关系的文本检测方法
- 由于没有公开的字符级标注数据集,因此提出了一种弱监督学习方法进行训练
Pipeline
-
整个网络采用了类似U-net的VGG16架构,最后输出两张下采样两倍的结果图,Region score map(像素点是字符中心的概率)和 Affinity score map(像素点是相邻字符之间的空间的中心概率)。
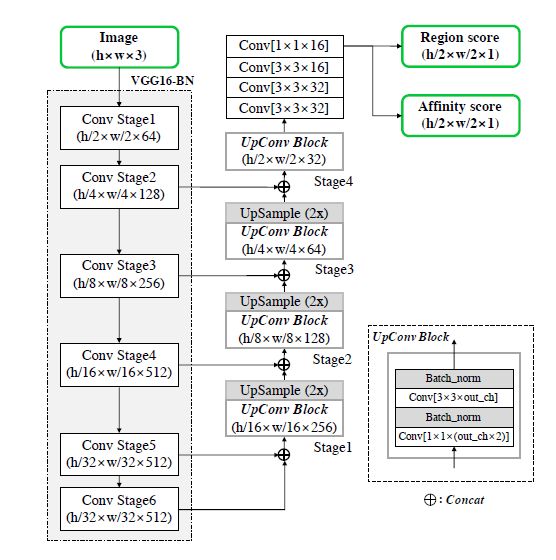 Pipeline.png
Pipeline.png
标签生成过程
对于字符区域和字符间连接关系,并没有采用mask的0,1标记,而是使用了高斯热图对字符区域中心点概率进行了编码(方法来自于姿态估计,对于无严格边界的任务效果好)。
- 对于字符区域标签的生成:
(1)准备一张二维高斯热图
(2)计算高斯图区域和每个文字框的透视变换
(3)将高斯图变换到文字框区域 -
对于字符间连接关系的标签生成:
(1)画出字符区域的对角线
(2)连接相邻字符区域的上下三角形的中心点,形成四边形
(3)对该四边形重复字符区域的标签生成过程
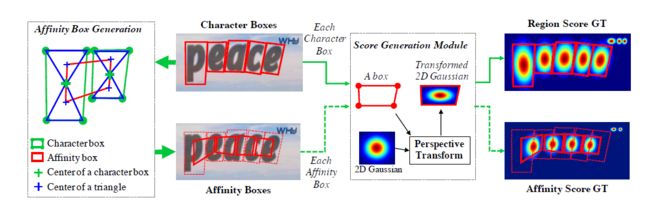 标签生成过程.png
标签生成过程.png
弱监督学习方法
通过实际切割出来的字符个数与单词级别的标注的字符个数的比值作为弱监督学习的标签置信度。当置信度低于0.5时,忽略得到的字符级标注框,因为不准确的切割会对模型的训练造成不利的影响,在这种情况下可以认为字符是等宽的,采用等宽切割得到字符级标注框。公式就不编辑了,具体LOSS可以去原论文看。
-
由单词级标注转换为字符级标注的弱监督学习过程
(1)裁剪出单词级别标注区域
(2)通过网络预测Region score
(3)使用分水岭算法(watershed algorithm)
(4)获得字符级别的边界框
(5)还原字符级边界框到原始图像中,得到字符级标注
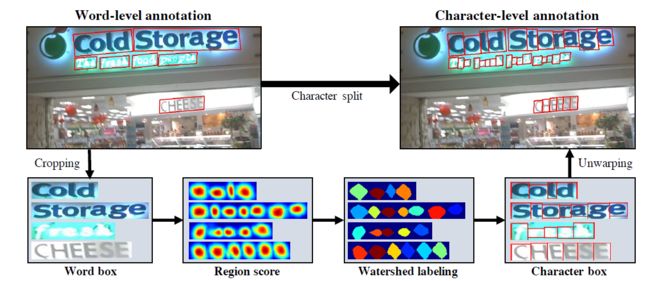 字符切割方法.png
字符切割方法.png
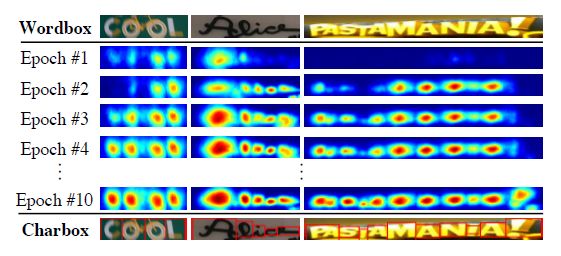 转换.png
转换.png
 i训练过程.png
i训练过程.png
CRAFT的优势
- 由于定位的是字符,对于尺寸缩放不敏感,无需多尺度训练和预测来解决尺度方差问题(基于像素点分割的方法都具有此优势)。
- 用ICDAR2013和ICDAR2017作为训练集进行训练,得到了很强的泛化性能,说明算法学习到了文本的一般特征。
- 网络Pipeline优雅简单,最后得到两张下采样两倍的得分图。
- 表现出的性能优越。
- 后处理简单,无需NMS,只需设置两个阈值进行过滤。
实测图


个人总结
作者提出的基于字符级的检测方法令人耳目一新,在训练时需要字符级的标注数据集去指导单词级的标注数据集进行弱监督学习的思路很有意思。
缺点:
- 训练复杂,需要进行弱监督训练得到字符级标注框,再训练网络。
- 标注字符级数据集代价高。(考虑传统算法对单词级标注框进行切割)
- 无法区分阿拉伯语等粘连在一起的语言。