vb查看进程网络流量_一篇运维老司机的大数据平台监控宝典(1)-联通大数据集群平台监控体系进程详解...

“如果你是一个经验丰富的运维开发人员,那么你一定知道ganglia、nagios、zabbix、elasticsearch、grafana等组件。这些开源组件都有着深厚的发展背景及功能价值,但需要合理搭配选择,如何配比资源从而达到性能的最优,这里就体现了运维人的深厚功力。”
下文中,联通大数据平台维护团队将对几种常见监控组合进行介绍,并基于丰富的实战经验,对集群主机及其接口机监控进行系统性总结。
科普篇几种常见的监控工具选择
目前常见的监控组合如下:
- Nagios+Ganglia
- Zabbix
- Telegraf or collect + influxdb or Prometheus or elasticsearch + Grafana +alertmanager
Nagios、Ganglia、Zabbix属于较早期的开源监控工具,而grafana、prometheus则属于后起之秀。下面,将分别介绍三种监控告警方式的背景及其优缺点:
Nagios+Ganglia
Nagios最早是在1999年以“NetSaint”发布,主要应用在Linux和Unix平台环境下的监控告警,能够监控网络服务、主机资源,具备并行服务检查机制。
其可自定义shell脚本进行告警,但随着大数据平台承载的服务、数据越来越多之后,nagios便逐渐不能满足使用场景。例如:其没有自动发现的功能,需要修改配置文件;只能在终端进行配置,不方便扩展,可读性比较差;时间控制台功能弱,插件易用性差;没有历史数据,只能实时报警,出错后难以追查故障原因。
Ganglia是由UC Berkeley发起的一个开源监控项目,设计用于测量数以千计的节点。Ganglia的核心包含gmond、gmetad以及一个Web前端。主要用来监控系统性能,如:cpu 、mem、硬盘利用率,I/O负载、网络流量情况等,通过曲线很容易见到每个节点的工作状态,对合理调整、分配系统资源,提高系统整体性能起到重要作用。但随着服务、业务的多样化,ganglia覆盖的监控面有限,且自定义配置监控比较麻烦,展示页面查找主机繁琐、展示图像粗糙不精确是其主要缺点。
Zabbix
Zabbix是近年来兴起的监控系统,易于入门,能实现基础的监控,但是深层次需求需要非常熟悉Zabbix并进行大量的二次定制开发,难度较大;此外,系统级别报警设置相对比较多,如果不筛选的话报警邮件会很多;并且自定义的项目报警需要自己设置,过程比较繁琐。
jmxtrans or Telegraf or collect + influxdb or Prometheus or elasticsearch + Grafana +alertmanager
这套监控系统的优势在于数据采集、存储、监控、展示、告警各取所长。性能、功能可扩展性强,且都有活跃的社区支持。缺点在于其功能是松耦合的,较为考验使用者对于使用场景的判断与运维功力。毕竟,对于运维体系来说,没有“最好”,只有“最适合”。
早期,联通大数据平台通过ganglia与nagios有效结合,发挥ganglia的监控优势和nagios的告警优势,做到平台的各项指标监控。但随着大数据业务的突增、平台复杂程度的增加,nagios与ganglia对平台的监控力度开始稍显不足,并且开发成本过高。主要体现在配置繁琐,不易上手;开发监控采集脚本过于零散,不好统一配置管理,并且nagios没有历史数据,只能实时报警,出错后难以追查故障原因。
中期,我们在部分集群使用了zabbix,发现其对于集群层、服务层、角色层及角色实例监控项的多维度监控开发管理相对繁琐,并且如果想要把平台所有机器及业务的监控和告警集成到zabbix上,对于zabbix的性能将是很大的挑战。
于是我们采用以Prometheus+ Grafana+ alertmanager为核心组件的监控告警方式,搭建开发以完成对现有大规模集群、强复杂业务的有效监控。采用PGA(Prometheus+ Grafana+ alertmanager)监控告警平台的原因是其在数据采集选型、存储工具选型、监控页面配置、告警方式选择及配置方面更加灵活,使用场景更加广泛,且功能性能更加全面优秀。
实战篇平台搭建、组件选型、监控配置的技巧
1采集丶存储工具的选型
采集器选择
常见的采集器有collect、telegraf、jmxtrans(对于暴露jmx端口的服务进行监控)。笔者在经过对比之后选择了telegraf,主要原因是其比较稳定,并且背后有InfluxData公司支持,社区活跃度不错,插件版本更新周期也不会太长。Telegraf是一个用Go语言编写的代理程序,可采集系统和服务的统计数据,并写入InfluxDB、prometheus、es等数据库。Telegraf具有内存占用小的特点,通过插件系统,开发人员可轻松添加支持其他服务的扩展。
数据库选型
对于数据库选择,笔者最先使用influxdb,过程中需要注意调整增加influxdb的并发能力,并且控制数据的存放周期。对于上千台服务器的集群监控,如果存储到influxdb里,通过grafana界面查询时,会产生大量的线程去读取influxdb数据,很可能会遇到influxdb读写数据大量超时。
遇到这种情况,可以先查看副本存储策略:SHOW RETENTION POLICIES ON telegraf
再修改副本存储的周期:
ALTER RETENTION POLICY "autogen" ON "telegraf" DURATION 72h REPLICATION 1 SHARD DURATION 24h DEFAULT
需理解以下参数:
duration:持续时间,0代表无限制
shardGroupDuration:shardGroup的存储时间,shardGroup是InfluxDB的一个基本储存结构,大于这个时间的数据在查询效率上有所降低。
replicaN:全称是REPLICATION,副本个数
default:是否是默认策略
但是,由于influxdb开源版对于分布式支持不稳定,单机版的influxdb服务器对于上千台的服务器监控存在性能瓶颈(数据存储使用的普通sata盘,非ssd)。笔者后来选择使用es 或 promethaus联邦来解决(关于es的相关权限控制、搭建、调优、监控维护,以及promethaus的相关讲解将在后续文章具体阐述)。
2Grafana展示技巧
Grafana是近年来比较受欢迎的一款监控配置展示工具,其优点在于能对接各种主流数据库,并且能在官网及社区上下载精致的模板,通过导入json模板做到快速的展示数据。
主机监控项
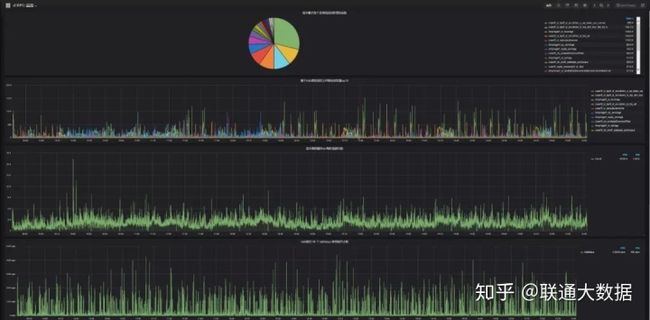
- 主机监控项概览:内核、内存、负载、磁盘io、网络、磁盘存储、inode占用、进程数、线程数。
- 主机监控大屏:以一台主机监控展示为样例,大家先看下效果图。

- 主机用途分类
联通大数据公司作为专业的大数据服务运营商,后台支持的主机数量规模庞大,各主机用途大不相同,那么就需要做好主机分类。用盒子的概念来说,机房是父类盒子,里面放置集群计算节点子盒子和接口机子盒子。集群主机、接口机分离,这样当一台主机故障时,方便更快的查找定位。

- 主机资源占用top10
主要从cpu占用、内存占用、负载、线程数多个维度统计同一主机群体(如:A机房接口机是一个主机群体,B机房计算节点是一个主机群体)占用资源最多的前十台机器。

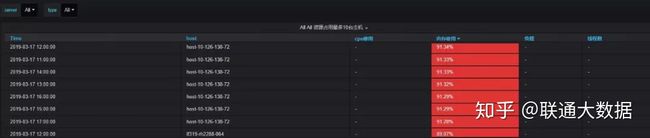

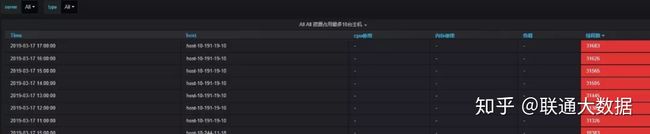
- 进程资源占用top10
通过主机监控大屏和主机资源占用top10定位故障主机的故障时间段和异常指标,只能初步的帮助运维人员排查机器故障的原因。例如,当机器负载过高时,在主机监控大屏中往往能看出主机的cpu使用,读写io、网络io会发生急速增长,却不能定位是哪个进程导致。当重启故障主机之后,又无法排查历史故障原因。因此对于主机层面监控,增加了进程资源占用top10,能获取占用cpu,内存最高的进程信息(进程开始运行时间、已运行时长、进程pid、cpu使用率、内存使用率等有用信息)。这样,当主机因为跑了未经测试的程序,或者因运行程序过多,或程序线程并发数过多时,就能有效的通过历史数据定位机器故障原因。

总结:主机层面可监控项还有很多,关键点在于对症下药,把排查故障的运维经验转化为采集数据的合理流程,再通过数据关联来分析排查故障。
平台监控项
平台监控项种类繁多,有hdfs、yarn、zookeeper、kafka、storm、spark、hbase等平台服务。每个服务下有多种角色类别,如hdfs服务中包括Namenode、Datenode、Failover Controller、JournalNode 。每个角色类别下又有多个实例。如此产生的监控指标实例达几十万个。目前联通大数据使用的CDH版本大数据平台,基础监控指标全面多样。根据现状,平台层面我们主要配置比较关键的一些监控项。
- 集群yarn队列资源占用多维画像
帮助平台管理人员合理评估个队列资源使用情况,快速做出适当调整。

- zeeplin操作日志
zeepline并没有相关的可视化审计日志,通过实时的获取zeeplin操作日志来展现zeeplin操作,方便运维人员审计。
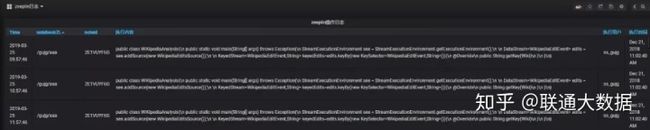
- hdfs各目录文件数及存储多维画像
实时统计各业务用户的数据目录存储,便于分析hdfs存储增量过大的目录。

- 集群namenode RPC 实时多维画像
当hadoop集群节点数达到千台左右时,集群业务对于yarn队列资源使用达到百分之八十以上,且集群写多读少,很容易造成namenode-rpc等待队列深度过大,造成namenode-rpc延迟,这将会严重影响集群整体业务的运行。半小时能跑完的任务,可能会跑数个小时。根本原因还是集群承载业务数量过多,并且业务逻辑设计不合理,造成yarn任务执行过程频繁操作hdfs文件系统,产生了大量的rpc操作。更底层的,每个dn节点的磁盘负载也会过高,造成数据读写io超时。
通过提取namenode日志、hdfs审计日志,多维度分析,可通过hdfs目录和hdfs操作类型两个方面确认rpc操作过多的业务。并且根据具体是哪种类型的操作过多,来分析业务逻辑是否合理来进行业务优化。例如有某大数据业务的逻辑是每秒往hdfs目录写入上千个文件,并且每秒遍历下hdfs目录。但触发加工是十分钟触发一次,因此该业务产生了大量的rpc操作,严重影响到集群性能,后调优至5分钟遍历次hdfs目录,集群性能得到极大优化。

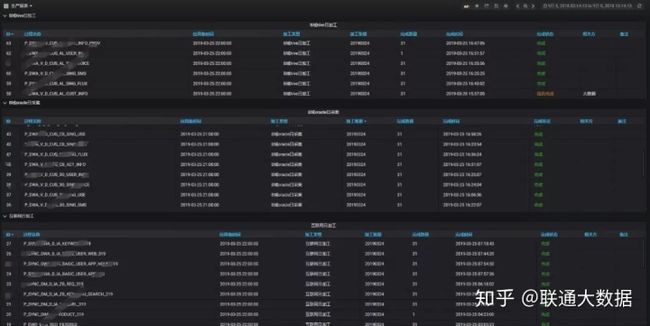
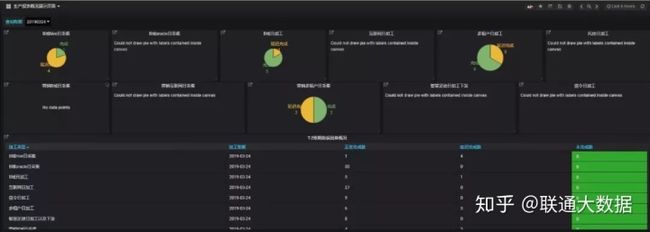
日常生产监控项
- 生产报表
由于联通大数据平台承载业务体量很大,通过后台查询繁琐,而通过可视化展示能方便生产运维人员快速了解日生产情况,定位生产延迟原因。
结语:关于平台监控的内容在本文中就先介绍到这里,在下一篇中,笔者将针对平台告警做出经验分享,介绍如何建立统一采集模板、告警各集群的全量监控指标、进行分组告警并自动化恢复等内容。