深度学习模型压缩算法综述(三):知识蒸馏算法+实战
深度学习模型压缩算法综述(三):知识蒸馏算法
- 本文禁止转载
- 项目地址:
- 联系作者:
- 知识蒸馏:
-
- 分类模型训练目标:
- two-stage检测模型训练目标:
-
- 基本思路:
- 损失函数:
- one-stage检测模型训练目标:
-
- 基本思路:
- 损失函数:
- 基于特征的NMS算法:
- Deep Mutual Learning:
-
- 基本思路:
- 基本原理:
- 迭代训练:
- 目标检测模型知识蒸馏实验一:
-
- 环境参数:
- 项目地址:
- 实验结果:
- 目标检测模型知识蒸馏实验二:
-
- 环境参数
- 项目地址:
- 实验结果:
- 关注我的公众号:
- 联系作者:

本文禁止转载
项目地址:
https://github.com/Sharpiless/yolov5-distillation-5.0
联系作者:
B站:https://space.bilibili.com/470550823
CSDN:https://blog.csdn.net/weixin_44936889
AI Studio:https://aistudio.baidu.com/aistudio/personalcenter/thirdview/67156
Github:https://github.com/Sharpiless
知识蒸馏:
知识蒸馏主要是让让新模型(通常是一个参数量更少的模型)近似原模型(模型即函数)。注意到,在机器学习中,我们常常假定输入到输出有一个潜在的函数关系,这个函数是未知的:从头学习一个新模型就是从有限的数据中近似一个未知的函数。如果让新模型近似原模型,因为原模型的函数是已知的,我们可以使用很多非训练集内的伪数据来训练新模型。
分类模型训练目标:
原来我们需要让新模型的softmax分布与真实标签匹配,现在只需要让新模型与原模型在给定输入下的softmax分布匹配了。但是由于softmax函数是一个约等于arg max的近似,它所能描述的知识(对输出的概率描述)非常有限,一种常用的解决方法是直接让新旧模型匹配logits输出,即最小化:

文章《Distilling the Knowledge in a Neural Network》则考虑了一个更广义的softmax函数:

其中T是一个类似温度的概念,当T趋向于0时,softmax的输出将收敛为一个one-hot向量;当T趋向于足够大时,softmax的输出分布则更加平缓。那么这时就可以使用较高的T训练、使用T=1推理,这样就是为什么叫做“蒸馏”。
此时的损失函数(最小化两个分布的交叉熵)变为:

该损失函数对于某个logit zi的梯度为:

已知当x趋向于0时,ex-1与x是等价无穷小,则当T足够大是,有:

如果假设所有logits对每个样本都是零均值化,即:

则有:

所以如果迁移数据上的真实标签已知,可以同时优化新模型输出分布与真实标签分布的交叉熵,损失加权时需要将软标签的损失项乘以T2,保证梯度数量级相当。
two-stage检测模型训练目标:
基本思路:
《Learning Efficient Object Detection Models with Knowledge Distillation》这篇文章应该是第一篇使用知识蒸馏解决高效目标检测网络的训练问题的文章。作者指出,尽管知识蒸馏可以提升简单的分类模型的性能,但将其应用于目标检测模型时,会面临回归、区域建议和不宽松的类标问题。为了解决这些问题,作者使用了加权交叉熵损失解决类别不均衡问题、教师边界损失解决回归问题,同时使用可调整层来更好地从教师网络的中间层分布进行学习。

损失函数:
基本的损失函数如下:

其中:
-
N和M分别是RCN和RPN的batch-size
-
Lcls由两部分组成,一部分是学生网络的输出与真实标定的损失,另一部分损失是与教师网络输出的损失:

其中:

wc是不同类别(two-stage中包括背景类)的分类权重,用于均衡教师网络输出背景类较多的问题,例如VOC数据集中一般设置wbg=1.5。同时也可以参考分类模型的蒸馏,加入温度T。 -
由平滑损失和提出的教师边界损失组成:
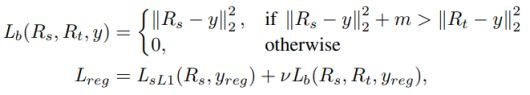
其中m是边界,即表示当学生网络的性能超过教师网络一定的值(可以是负数,表示接近教师网络的性能)时,就不计算学生网络的损失。 -
Lhint是启发式的损失函数,鼓励学生模仿老师的特征表示:

V表示学生网络的guided layer,而Z表示教师网络中的hint layer,即加入特征向量做相近,期望使得学生网络学习到更多特征表示。当hint layer 和 guided layer不匹配时,需要用一个adaption layer进行转换。hint and guided都是FC时就用FC,都是conv layer就用1x1conv来匹配。而且作者发现即便channels数一样时,一个额外的adaptation layer也有助于实现高效的知识迁移。
one-stage检测模型训练目标:
基本思路:
One-stage目标检测任务的训练目标难度更大,因为teacher网络会预测出更多的背景bbox,如果直接用teacher的预测输出作为student学习的soft label会有严重的类别不均衡问题。解决这个问题需要引入新的方法。
主要是《Object detection at 200 Frames Per Second》这篇文章中提出了针对该问题的解决方案,即针对YOLOv3中分类、回归、objectness三个不同的head适配不同的蒸馏损失函数,并对分类和回归的损失函数用objectness分值进行抑制,以解决前景背景类别不均衡问题。
并且该文章使用未标注数据作为蒸馏损失,跟检测损失(有标注数据)加权求和作为最终的损失函数。

损失函数:
假设o、p、b分别为objectness、类别概率和坐标框,原本的yolo目标检测的损失函数为:
![]()
这篇文章分别对这几个损失函数做出改进,具体思路为只有当teacher network的objectness value高时,才学习bounding box坐标和class probabilities。
- object loss:

- classification loss:
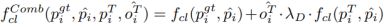
- regression loss:
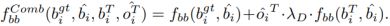
基于特征的NMS算法:
如果不做NMS,直接将teacher network的预测框输出给student network,则会导致student network接收到的object相关的loss会非常大,这样训练几轮以后就会对这些object过拟合了。因此这里采取了类似NMS算法的feature map NMS进行重复框进行去除。

这篇文章做出的假设是,假如几个相邻的grid cell所预测bbox的类别一样,那么这些bbox极有可能预测的是同一个object。因此FM-NMS算法的做法是:每次取3*3个相邻的grid cell,对这9个grid cell中预测类别相同的bbox的得分进行排序,最后只选择得分最高的那个bbox传给后续的student network。
Deep Mutual Learning:
基本思路:
通常来说,蒸馏模型是从功能强大的大型网络或集成网络转移到结构简单,运行快速的小型网络。本文决定打破这种预先定义好的“强弱关系”,提出了一种深度相互学习策略(deep mutual learning, DML),在此策略中,一组学生网络在整个训练过程中相互学习、相互指导,而不是静态的预先定义好教师和学生之间的单向转换通路。即相互学习通过利用一组小的未经训练的网络协作进行训练,可以简洁而有效的提高网络的泛化能力。

基本原理:
假设我们有这 θ 0 , . . . , θ K \theta_0,...,\theta_K θ0,...,θK几个分类网络,他们对应的logits输出为 z j m z^m_j zjm。
对于M个类别的N个样本:
![]()
我们可以计算 θ j \theta_j θj(下式 j = 1 j=1 j=1)对于输入 x i x_i xi预测为类别m的概率:
其交叉熵损失函数为:
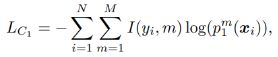
为了提高模型 θ 1 \theta_1 θ1的泛化性,我们可以使用另一个网络 θ 2 \theta_2 θ2的经验来指导。K-L散度是一种量化两种概率分布P和Q之间差异的方式,又叫相对熵。在概率学和统计学上,我们经常会使用一种更简单的、近似的分布来替代观察数据或太复杂的分布。K-L散度能帮助我们度量使用一个分布来近似另一个分布时所损失的信息量:

此时两个模型的损失函数就可以更新为:

迭代训练:
DML在每次训练迭代中,都计算两个模型的预测,并根据另一个模型的预测更新两个网络的参数,一直迭代直至收敛:

目标检测模型知识蒸馏实验一:
环境参数:
数据集:VOC2012
GPU:V100*1
Batch Size:8
Steps:70000
Baseline:Yolov3-MobileNetV1
Teacher model:Yolov3-Resnet34
项目地址:
https://aistudio.baidu.com/aistudio/projectdetail/1878840
实验结果:

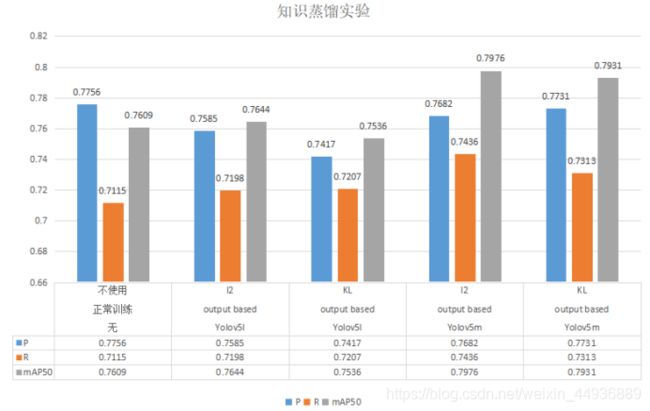
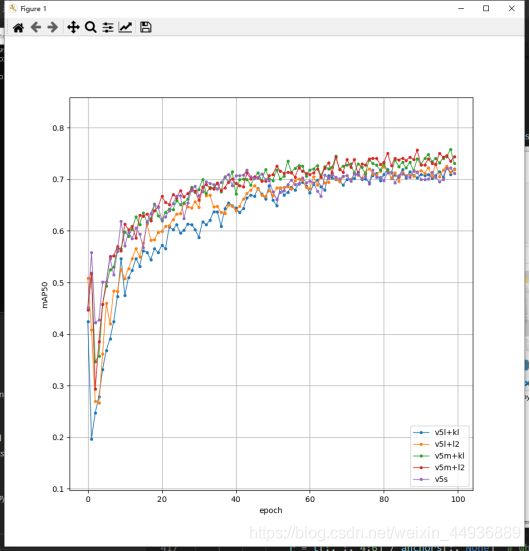
目标检测模型知识蒸馏实验二:
环境参数
数据集:VOC2007
Batch Size:8
Epoches:100
Baseline:Yolov5s
Teacher model:Yolov5l/m(mAP50 = 0.80/0.81)
Temperature:4
项目地址:
https://github.com/Sharpiless/yolov5-distillation-5.0
实验结果:
使用《Object detection at 200 Frames Per Second》论文里面的损失函数,除了蒸馏训练的logits损失,其余蒸馏损失均使用L2损失。
此外这里使用的teacher model精度相当,只是模型参数量不同。
关注我的公众号:
感兴趣的同学关注我的公众号——可达鸭的深度学习教程:

联系作者:
B站:https://space.bilibili.com/470550823
CSDN:https://blog.csdn.net/weixin_44936889
AI Studio:https://aistudio.baidu.com/aistudio/personalcenter/thirdview/67156
Github:https://github.com/Sharpiless