学习和迁移中的个体差异:学习范例与抽象规则的稳定趋势
作者认为,在迁移学习任务当中,学习者可能会因为自身个体差异采用不同的学习方式。一些学习者可能专注于获取特定的样例和与样例相关的反应(称为样例学习者,Exemplar Learners),而另一部分学习者则试图抽象出与适当的反应相关的特定样例所反映的潜在规律(称为规则学习者,Rule Learners)。作者认为,除非任务强烈倾向于特定的模型解,否则在训练过程中两种学习者都会出现。并且作者还假设,在学习过程中,被试会稳定地偏向某一类型——即要么是样例学习者要么是规则学习者。
作者通过研究1a、1b、1c和研究2来验证。
实验1a:
实验1用函数学习范式揭示exemplar与rule的学习倾向,采用的是综合联想学习模型和规则学习模型的一个“外推模型”(extrapolation)。
*模型包括2部分,外推规则和联想学习部分。外推规则假设,当呈现一个新异的外推刺激,学习者将新异刺激与练习刺激相匹配,从接近的训练值中提取出刺激和反应对,然后估计出函数曲线,并运用该曲线对新刺激做出反应。联想学习部分假设学习者会学习刺激和反应之间的联系并且直接存储而不用抽取任何规则表征。
在这项初步研究中,作者试图根据学习者的外推表现来证明他们之间的差异,这种差异会告知参与者在训练试验中学到了什么。
*实验流程分为2个阶段(间隔1星期)。在阶段1,被试被要求假装他们为NASA工作,对一些数据以100为中心的双线性函数(V形)进行训练,对于小于100的输入(线索)值,使
用方程y=229.2−2.197x导出输出(准则)值;对于大于100的输入,输出值遵循方程y=2.197x−210
总共有200个trail试验在10个 block中呈现。
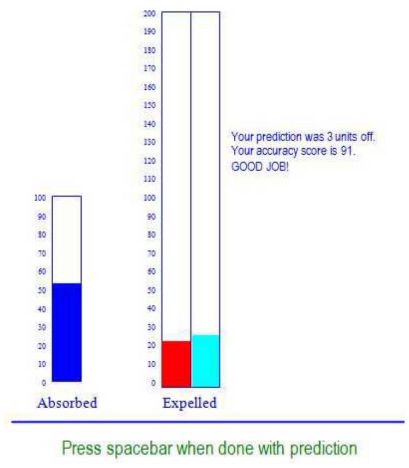
在每个trail当中有3个垂直条(如上图),条形图每5个单位有一个勾痕,范围从0到200,每10 个单位有一个值标签。 最左边的栏给出了输入值,参与者通过使用箭头键填充中间 栏来进行输出预测(向上和向下箭头键移动了栏5单元,左和右箭头键移动了栏1单 元), 并会收到三种形式的准确性反馈。第一种是最右边的条,代表了正确的输出值用以比较;第二种是以数字形式反馈具体的错误数;最后会给一个评分来表示精确度。
在功能学习任务之后,参与者会进行回忆并完成Kolb学习风格清单的任务。
*Kolb清单是一个12个项目的量表,向参与者展示句子的词干(例如,“我何时会学得更好”),并要求他们对四个回答选项进行从1到4排名(例如,“我听和看”或“我依靠逻辑思维”)每个回答选项对应四种学习模式中的一种(concrete experience, reflective observation, abstract conceptualization, and active experimentation)将被试的选项量化为分数,这可以体现出被试在学习方面的两个维度——吸收经验和处理经验(taking in experience and dealing with experience)
在阶段2,志愿者会先完成一个配对连结任务(研究1c的具体内容),再完成一个简单的RAPM任务:在每次试验中,参与者会看到8个box排列在一个3×3网格中(网格的右下角区块块丢失,无box) 每个网格包含从左到右和从上到下的模式.,参与者将从总共8个选项中选择完成水平和垂直模式的框。在完成RAPM任务后,志愿者们会完成一个认知量表Ospan,以检测学习效率和工作记忆能力。
研究1a的中心结论是,有些人(将其标记为规则学习者)正试图推导训练刺激之间的关系,而另一些人(将其标记为示例性学习者)则主要侧重于学习单个刺激。当然,研究不能证明这种差异在长期训练当中是否存在。对于该种差异,文章提出了两个观点:
1、是范例学习者专注于学习个体的刺激是一个基本的方向,它应该贯穿于功能学习任务的广泛训练中。
2、某些人可能首先专注于很好地学习各个训练刺激,然后完全了解这些刺激,然后在训练刺激的整个范围内提取潜在的规律性。
研究1b采用与1a相似的范式,同时实施了两种训练条件——一般训练条件与扩展训练条件,以阐明上述相互竞争的想法。
在一般条件下,在参与者首先满足特定训练块(MAE <10)的学习标准后,他们会再接受六个训练块;而在拓展条件下,参与者将接受额外的12个训练块。
研究1b将被试分为一般组和拓展组(按照第一个训练块的时间和误差分组)。1b在阶段1的引导故事、功能学习任务等都与实验1a相似,不同且关键的地方在于,当参与者完成第一个训练块后,会给2组被试额外增加6和12个block。(*如果被试在10个block训练后达不到标准,则会被记为非学习者non-learner,不被记录数据)
功能学习任务后,被试会接受简短的注意分散和干扰任务,其中拓展组在训练6个block后会额外获得一次休息时间。最后的转移阶段包括60次而不是36次试验——包含30个外推试验(与研究1a中的相同),20个内插试验和10个重复训练试验。在功能学习任务结束后,被试同样会接受一个简单的RAPM任务。
研究1b中的功能学习数据的模式与研究1a中的功能学习数据相同。总的来说,规则和范例学习者具有明显不同的外推特征,尽管他们表现出相对相似的训练和内插表现。适度的训练条件和扩展的训练条件在规则和范例学习者之间的区别以及这两种学习者分类所显示的表现方面表现出同等的结果(如图)

*左上方:根据研究1b中的中等训练条件,分类为规则学习者和分类为典型学习者的参与者在最后训练块上的平均预测。右上方面板:规则学习者和扩展学习条件下的示例学习者在最后一个训练块上的平均预测。左下第二块面板:在中等训练条件下,为规则学习者和典型学习者重复训练点预测。右下第二个面板:在扩展的训练条件下,为规则学习者和示例学习者重复训练点预测。左第三幅图:在中等训练条件下,规则学习者和示例学习者的平均插值预测。第三个右图:在扩展训练条件下,规则学习者和示例学习者的平均插值预测。左下图:在中等训练条件下,规则学习者和典型学习者的平均外推预测。右下图:在扩展训练条件下,规则学习者和典型学习者的平均外推预测。
在研究1a和1b的功能学习任务中报告的新的个体差异倾向通常会出现在一系列复杂的概念任务中。在研究1c中,作者采用Regehr和Brooks范式来测试在该类别学习任务中,研究1a中确定的个体差异是否继续影响exemplar和rule-based的过程,具体来说,作者研究了在关键实例上的转移是否与规则1的学习相对于研究1a中确定的典型学习者有所分歧。
研究1c主要对研究1a中第二阶段的概念学习任务进行阐述:在这项任务中,参与者会看到动物的图画,这些动物在五个二元维度上变化:身体形状(有角的或圆形的)、腿长(短或长)、腿数(2或6)、脖子(短或长)和斑点(有点或无斑点)。每张动物只有2个定义——digger /builder,而对不同组动物的分类遵循一些特定的规则:

*符合规则中至少2个的动物才是builder。
训练过程中,在电脑显示器上显示刺激信息,参与者试图通过按指定的键将每一个信息分类为digger /builder。被试不会明确地看到规则。一旦他们做出判断,反馈就会以“正确”或“不正确”的形式出现在屏幕上。有8个训练刺激(每个类别4个),参与者完成5个训练模块,总共40个训练试验
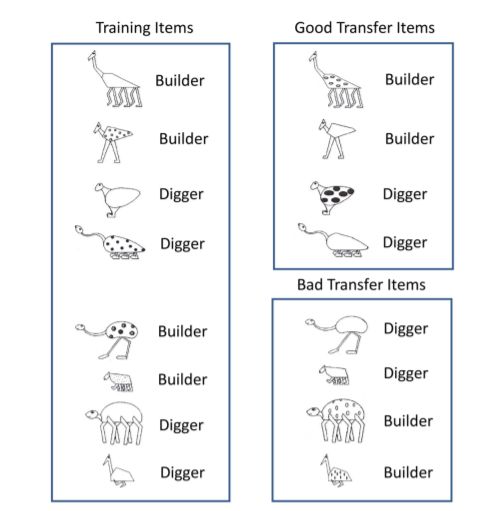
*训练刺激,通过给每只训练动物五个特质的特质形式说明,最大程度地提高了感知性(显着性)
在训练之后,参与者完成一个测试阶段,包括三种类型的项目:重复训练项目、良好的转移项目和糟糕的转换移目。转移项目是通过简单地改变8个训练项目的点指定来创建的(例如,对于有斑点的动物,通过去除斑点创建转移项目;而对于没有斑点的动物,可以通过添加点来创建一个转移项)。对于一些参与者,其训练项目可能为他人的转移项目。当转移项目和训练项目为同一类别(digger/builder),称为良好的转移(Good Transfer);反之,当不属于同类时,则为糟糕的转移(Bad Transfer)
在刺激阶段,有八个重复训练项目,四个良好转移项目和四个不良转移项目。这16个测试刺激是以随机顺序呈现的。 参与者需将刺激分类为训练期间,但在测试部分不会收到任何反馈。
研究1c与之前的观点相切合,即在功能学习任务上被确定为范例学习者的参与者也对目前的分类任务采取了范例方法,而被确定为规则学习者的学习者通常试图发现刺激的类别结构背后的规则。同时作者还得出结论:尽管规则学习不怎么成功,但规则学习者仍然不会完全倾向于按照示例学习,这凸显了这些规则学习者尝试抽象化基本规则的倾向的持久性。因此,在研究2中,作者转向了一个不同的分类任务。在这个任务中,传输性能更直接地影响了分类规则的抽象(或其缺失)
研究2将研究1的功能学习任务替换为抽象连贯的类别分类任务。
研究2有两个主要目标。 第一个是复制关键发现,即当给定功能学习任务时,不同个体参与者将表现出2种趋势,即抽象提示和标准值之间的功能关系(规则学习者)或仅学习这些值(示例性学习者);其次是验证参与者在功能学习任务中显示的规则学习(抽象)和样例学习倾向将在不相关的新概念任务中是否持续存在。
*分类任务: 分类材料通过3×5索引卡呈现给参与者。 每张卡代表一台机器,并列出了四个属性。这四个描述机器的属性(机器的运行位置,参与的动作,使用的工具及其移动方式)在每张卡上的显示顺序相同。在训练中,参与者被告知他们将学习两种被称为“morkels”和“krenshaws”的假想机器,他们将看到一系列代表特定机器的卡片,并对这些卡片进行分类(morkels由两对连续有意义的特征构成,而krenshaws由两对相对有意义的特征构成)

分类任务一共48个trial,分为6个block,每个block中随机出现8个机器(4个“morkels”和4个“krenshaws”),被试只能知道自己的分类正确与否,并不能得到正确的分类答案的反馈。
训练阶段后,会将之前训练的共16个特征对按照随机顺序呈现给被试,被试被要求将16个特征对再进行分类为“morkels”和“krenshaws”。但被试不会收到正确与否的反馈,取而代之的是要求被试将分类的刺激按照1-7的等级排序(1最没把握,7最肯定)。
紧接着,被试会接受12个新的特征刺激(按照6个“morkels”和6个“krenshaws”的模板生成),并对新的刺激也进行一次分类。
研究2的阶段2与研究1相同,在所有任务结束后,被试也会接受配对连结任务与RAPM任务等。
研究2的结果指出规则学习者和典型学习者的学习率相似。规则学习者在插值试验中也显示出比典型学习者更低的MAE,因此,被归类为典型学习者的参与者与被归类为规则学习者的参与者外推模式的差异,不能通过已训练的指示标准值的学习准确性差异或转移到内插区域的能力来解释。
实验1a、1b、1c和实验2的研究结果为为描述和预测高阶概念学习中的个体差异而绘制的框架的主要原则提供了初步支持。作者提出,每种方法都可以反映不同类型学习者的倾向。对于功能学习任务,研究1a,1b和2都表明个体的外推性能不同。一部分人(示例学习者)的外推反映了输出值,通常在训练中学习到的输出范围内,而这种topography容易被exemplar模型捕获;而其他部分人(规则学习者)外推的特征是输出值超出了通常遵循底层函数的斜率的已知输出,这是一种隐含规则的topography或基于抽象的方法