《python与量化投资-从基础到实战》读书笔记
DataFrame切片与筛选
DataFrame的三种切片方式:loc、iloc和ix。
- loc为location的缩写,第一个参数是行标签,第二个参数是列标签(为可选参数,默认为所有列标签)
- iloc为integer location的缩写。
- ix运用更广泛,能自动根据给出的索引类型是使用位置还是标签。
回归分析
回归分析是确定两种或两种以上变量之间相互依赖的定量关系的一种统计分析方法,运用十分广泛。回归分析,按照数量涉及的变量的多少,可分为一元回归分析和多元回归分析;按照因变量的多少可分为简单回归分析和多重回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析,回归分析在金融领域的应用十分广泛。比如在CAPM模型中,beta系数的计算本质上就是一元线性回归。
StatsModels模块曾经是scipy.stas下的子模块,后被重写并为现在独立的模块,可以利用强大的OLS(Ordinary Least Square)功能进行回归分析。
import statsmodels.api as sm
x = data['沪深300'].values
X = sm.add_constant(x) #添加常数项
y = data['中国平安'].values
#二者的收益率进行线性回归,斜率即beta系数
model = sm.OLS(y, X)
results = model.fit()
results.params
归因分析对于投资组合管理十分重要,某一组合的收益与损失可以被分解为多个表示投资组合权重的因子,认为一个虚拟投资组合是由两个随机因子和事先分配的权重构成的这一分析过程类似于多元线性回归。
插值
插值是在离散数据的基础上补插连续函数,使这条连续曲线通过全部给定的离散数据点。差值是离散函数逼近的重要方法,可根据函数在有限个点处的取值状况,估算出函数在其他点处的近似值。大部分金融数据都是离散数据,所以差值在金融领域的应用极其广泛,导入scipy.interpolate,此库对数据进行样条插值。
import scipy.interpolate as spi
X = data1.index
Y = data1.values
x = np.arange(0,len(data1), 0.15)
ipo1 = spi.splrep(X,Y,k=1)
ipo3 = spi.splrep(X,Y,k-3)
iy1 = spi.splev(x,ipo1)
iy3 = spi.splev(x,ipo3)
肥尾效应
凸优化
凸优化是一种比较特殊的优化,指求取最小的目标函数为凸函数的一类优化问题。在各行各业中都充斥着凸优化的问题,其中金融领域尤为明显,比如利用市场数据校准期权定价模型、效用函数优化、投资组合优化等,马科维茨投资组合理论是美国经济学家Markowitz(1952)在其发表《论文资产组合》的选择中提出的,它标志着现代投资组合理论研究的开始,Markowitz利用均值-方差模型的分析得出通过投资组合可以有效降低风险的结论。
投资组合的优化关键在于对组合中各标的权重的优化优化目标大致有以下三类,夏普最大化、收益最大化,风险最小化。
最优化投资组合的推导是一个约束最优化问题。
import scipy.optimize as sco
def statistics(weights):
weights = np.array(weights)
pret = np.sum(log_returns.mean() * weights * 252)
pvols = np.sqrt(np.dot(weights.T, np.dot(log_returns.cov() * 252, weights)))
return np.array([pret, pvols, pret/pvols])
def mim_sharpe(weights):
return -statistics(weights)[2]
Seaborn
import numpy.random as npr
import numpy as np
import matplotlib as mpl
import seaborn as sns
import matplotlib.pyplot as plt
def sinplot(flip=1):
x = np.linspace(0,14,100)
for i in range(1,7):
plt.plot(x,np.sin(x+i*.5)*(7-i)*flip)
sns.set_style({'font.sans-serif':['Microsoft YaHei','SimHei']})
sinplot()
Seaborn一共有4个内置主题,分别为:paper、talk、poster和notebook,
plt.figure(figsize=(12,8))
sns.set_context('paper')
plt.subplot(221)
sinplot()
plt.title('paper')
sns.set_context('talk')
plt.subplot(222)
sinplot()
plt.title('talk')
sns.set_context('poster')
plt.subplot(223)
sinplot()
plt.title('poster')
sns.set_context('notebook')
plt.subplot(224)
sinplot()
plt.title('notebook')
seaborn有丰富的调色板库。
plt.figure(figsize=(12,8))
sns.set_palette('muted')
plt.subplot(221)
sinplot()
#plt.title('循环')
sns.set_palette('Blues_d')
plt.subplot(222)
sinplot()
#plt.title('渐变(深-浅)')
sns.set_palette('Blues')
plt.subplot(223)
sinplot()
#plt.title('渐变(浅-深)')
sns.set_palette('RdBu')
plt.subplot(224)
sinplot()
#plt.title('混合(红-蓝)')
seaborn提供了辅助图形。kde及rug参数可以选择是否显示核密度估计及边际毛毯图。
import numpy.random as npr
size = 1000
rn1 = npr.standard_normal(size)
sns.set_palette("muted")
fig,((ax1,ax2),(ax3,ax4))=plt.subplots(2,2,figsize=(10,10))
ax1.hist(rn1, bins=25)
ax1.set_title('fig1')
sns.distplot(rn1,bins=25,kde=False,ax=ax2)
ax2.set_title('fig2')
sns.distplot(rn1,bins=25,kde=True,ax=ax3)
ax2.set_title('fig3')
sns.distplot(rn1,bins=25,kde=True,rug=True,ax=ax4)
ax2.set_title('fig4')
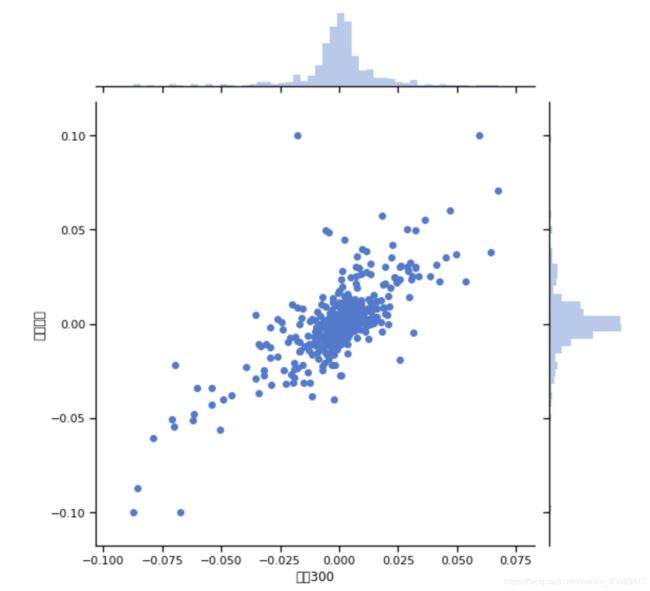
如果要达到jointplot的可视化,结果至少需要以下四步:1.计算两列数据的相关系数;2.画一个散点图;3画两个直方图;4拼合起来。但是jointplot可以快速达到此效果。
import pandas as pd
rn2 = pd.read_csv('data.csv',index_col='Date')
sns.jointplot(rn2['沪深300'],rn2['中国平安'],size=8)
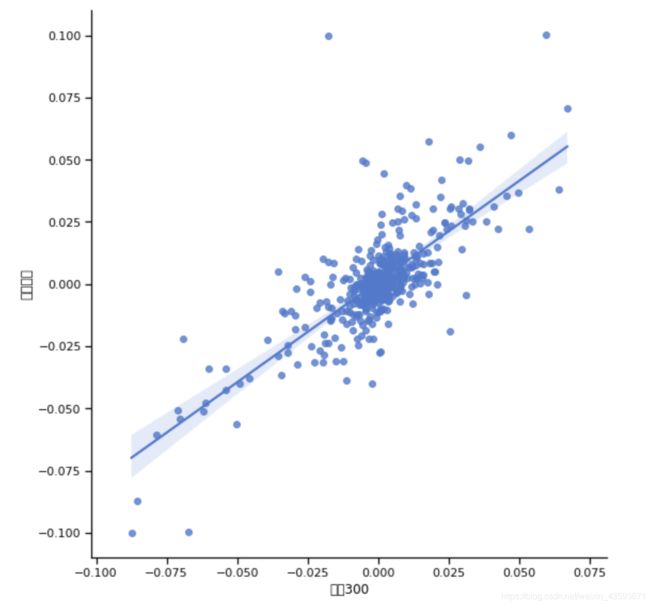
回归图
可使用lmplot函数
sns.lmplot('沪深300','中国平安',data=rn2,size=8)
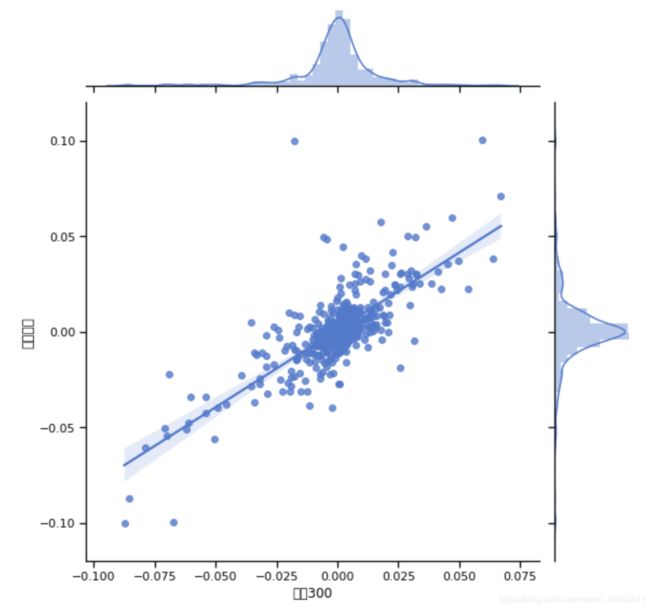
或者jointplot函数中的kind参数。
sns.jointplot(rn2['沪深300'],rn2['中国平安'],kind='reg',size=8)
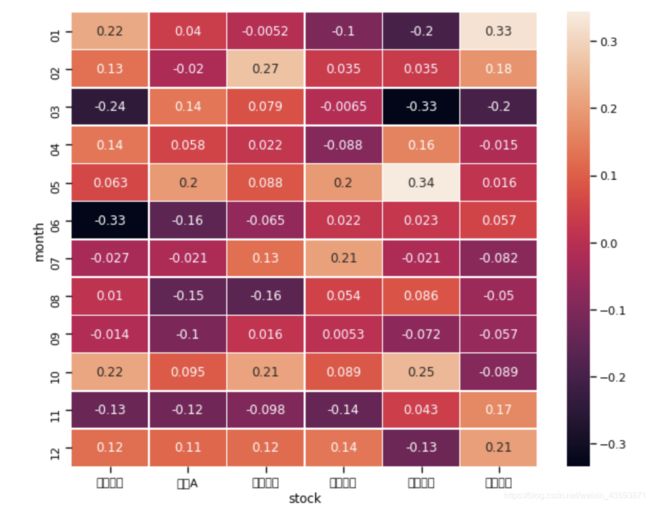
heatmap
rn3=pd.read_csv('data2.csv',index_col='Date')
rn3_rets = np.log(rn3.pct_change()+1)
rn3_rets.index=[str(x)[5:7] for x in rn3_rets.index]
rn3_group = rn3_rets.groupby(rn3_rets.index).sum()
rn3_group.index.name = 'month'
rn3_group.columns.name = 'stock'
rn3_group
plt.figure(figsize = (10,8))
sns.heatmap(rn3_group,annot=True,linewidths=.5)
结构网格图
sns.pairplot(rn3_rets.dropna())
Scikit-Learn
机器学习的功能主要包括分类、回归、降维和聚类。
· 主要的分类算法包括决策树(Decision Trees)、贝叶斯分类(Naïve Bayes),支持向量机(Support Vector Machines)、随机森林(Random Forest)等。
· 主要的回归算法有,SVR、Lasso等。
· 常见的降维方法有,主成分分析(PCA)、主题模型(LDA)。
scikit-learn还包含了特征提取、数据处理和模型评估这三大模块。
金融数据的获取
优矿中运行notebook。
import pandas as pd
df = pd.DataFrame()
for ticker in ['600000','000001']:
tmp_df = DataAPI.MktStockFactorsDateRangeGet(secID=u"",ticker=ticker,beginDate=u"20210226",endDate="20210302",field=u"secID,tradeDate,PS,PB,NetProfitGrowRate",pandas="1")
df = pd.concat([df,tmp_df],axis=0)
df.reset_index(drop = True)
#数据过滤,筛选出PE>0的代码
df = DataAPI.MktStockFactorsOneDayGet(tradeDate=u"20200303",secID=set_universe("A"),ticker=u"",field=u"secID,tradeDate,PE",pandas="1")
df[df.PE>0].head(10)
#ROE对模型的影响
df = DataAPI.MktStockFactorsOneDayGet(tradeDate=u"20210303",secID=set_universe("A"),ticker=u"",field=u"secID,tradeDate,ROE",pandas="1")
df.plot.hist(bins=100)
_ = df.boxplot(sym="rs")
#去极值,建模更稳定,“盖帽法”
df_ = df.copy()
df_.loc[df.ROE-df.ROE.mean()<-3*df.ROE.std(),'ROE'] = df.ROE.mean()-3*df.ROE.std()
df_.loc[df.ROE-df.ROE.mean()>3*df.ROE.std(),'ROE'] = df.ROE.mean()+3*df.ROE.std()
df_.plot.hist(bins=100)
#min-max标准化
((df_['ROE']-df_['ROE'].min()) / (df_['ROE'].max() - df_['ROE'].min())).plot.hist(bins=100)
#z-score标准化
((df_['ROE'] - df_['ROE'].mean()) / df_['ROE'].std()).plot.hist(bins=100)
#哑变量,类似于one-hot编码
import pandas as pd
df_industry = DataAPI.EquIndustryGet(industryVersionCD=u"010303",industry=u"",secID=df_['secID'].tolist(),ticker=u"",intoDate=u"20210308",field=u"secID,industryName1",pandas="1")
industry_list = df_industry['industryName1'].drop_duplicates().tolist()
def get(x):
ind_s = pd.Series([0]*len(industry_list),index = industry_list)
if len(df_industry[df_industry['secID'] == x]) > 0:
ind = df_industry[df_industry['secID']==x]['industryName1'].values[0]
ind_s.loc[ind] = 1
return ind_s
df_[industry_list] = df_['secID'].apply(lambda x: get(x))
df_.head()
回测平台介绍
start = '2017-01-01' # 回测起始时间
end = '2018-01-01' # 回测结束时间
universe = DynamicUniverse('HS300') # 证券池,支持股票、基金、期货、指数四种资产
benchmark = 'HS300' # 策略参考标准
freq = 'd' # 策略类型,'d'表示日间策略使用日线回测,'m'表示日内策略使用分钟线回测
refresh_rate = 1 # 调仓频率,表示执行handle_data的时间间隔,若freq = 'd'时间间隔的单位为交易日,若freq = 'm'时间间隔为分钟
#配置账户信息,支持多资产多账户
accounts = {
'fantasy_account': AccountConfig(account_type='security', capital_base=10000000)
}
def initialize(context):
pass
#每个单位时间(如果按天回测,则每天调用一次,如果按分钟,则每分钟调用一次)调用一次
def handle_data(context):
previous_date = context.previous_date.strftime('%Y-%m-%d')
# 获取因子PE的的历史数据集,截止到前一个交易日
hist = context.history(symbol=context.get_universe(exclude_halt=True), attribute='PE', time_range=1, style='tas')[previous_date]
# 将因子值从小到大排序,并取前100支股票作为目标持仓
signal = hist['PE'].order(ascending=True)
target_position = signal[:100].index
# 获取当前账户信息
account = context.get_account('fantasy_account')
current_position = account.get_positions(exclude_halt=True)
# 卖出当前持有,但目标持仓没有的部分
for stock in set(current_position).difference(target_position):
account.order_to(stock, 0)
# 根据目标持仓权重,逐一委托下单
for stock in target_position:
account.order(stock, 10000)
- universe(证券池)
支持全部A股及全部可在二级市场交易的ETF与LOF,还支持以三种方式获取证券池:DynamicUniverse、set_universe和StockScreener。
#静态
universe = ['000001.XSHE','600000.XSHG']
universe = set_universe('HS300',date='2021-03-01')
#动态
universe = DynamicUniverse('HS300')
universe = StockScreener(Factor.PE.nlarge(10))
1⃣️set_universe
用于返回预设的证券代码列表,支持行业成份股,指数成份股。其中SH50表示上证50;SH180表示上证180 ;HS00,表示沪深300;ZZ500表示中证500;CYB表示创业板;ZXB表示中小板;A表示全A。
#示例代码
set_universe(symbol,date)
#沪深300
set_universe("HS300")
#行业实例,IndSW,申万行业;YinHangL2,银行二级行业分类
set_universe(IndSW.YinHangL2)
#指数实例
set_universe(IdxCN.IdxShangZhengZongZhi)
#指定平安银行和股指期货
universe = ['000001.XSHE','IFM0']