HCIA-Big Data华为认证大数据工程师 课程笔记 + 课后习题
点击进入习题专辑(含答案)
文章目录
一、大数据发展趋势与鲲鹏大数据
导读
大数据时代的机遇与挑战
华为鲲鹏解决方案
课后习题
二、HDFS分布式文件管理系统和ZooKeeper
导读
HDFS分布式文件管理系统
ZooKeeper
课后习题
三、Hive分布式数据仓库
导读
Hive概述
Hive功能与架构
Hive基本操作
课后习题
四、HBase技术原理
导读
HBase基本介绍
HBase相关概念
HBase架构
HBase关键流程
HBase突出特点
HBase性能优化
HBase常用Shell命令
课后习题
五、MapReduce和Yarn技术原理
导读
MapReduce和Yarn基本介绍
MapReduce和Yarn功能与架构
Yarn的资源管理和任务调度
增强特性
课后习题
六、Spark基于内存的分布式计算
导读
Spark概述
Spark数据结构
Spark原理与架构
课后习题
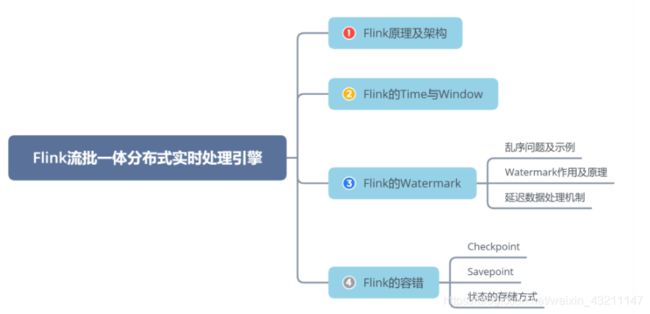
七、Flink流批一体分布式实时处理引擎
导读
Flink原理及架构
Flink的Time与Window
Flink的Watermark
Flink的容错
课后习题
八、Flume海量日志聚合
导读
Flume简介及架构
Flume关键特性介绍
Flume应用举例
课后习题
九、Loader数据转换
导读
Loader简介
Loader作业管理
课后习题
十、Kafka分布式信息订阅系统
导读
Kafka简介
Kafka架构与功能
Kafka数据管理
课后习题
十一、LDAP Kerberos
导读
统一身份认证管理
目录服务及Ldap基本原理介绍
单点登录及Kerberos基本原理介绍
华为大数据安全认证场景架构
课后习题
十二、分布式全文检索服务ElasticSearch
导读
ElasticSearch简介
ElasticSearch系统架构
ElasticSearch关键特性
课后习题
十三、Redis内存数据库
导读
Redis应用场景
Redis业务流程
Redis特性及数据类型
Redis的优化
Redis的应用案例
课后习题
十四、华为大数据解决方案
导读
ICT行业发展趋势概述
华为大数据服务
华为数据湖服务
课后习题
一、大数据发展趋势与鲲鹏大数据
导读

-
大数据从什么地方来?这些数据有哪些特点?
-
大数据可以应用在哪些社会领域?
-
大数据面临哪些挑战?
大数据时代的机遇与挑战
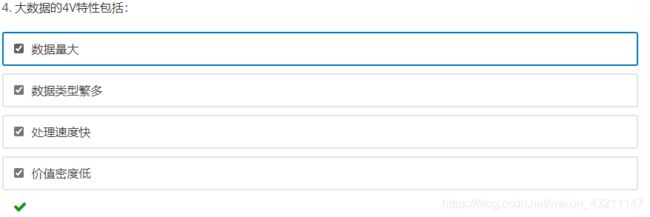
- 大数据的定义
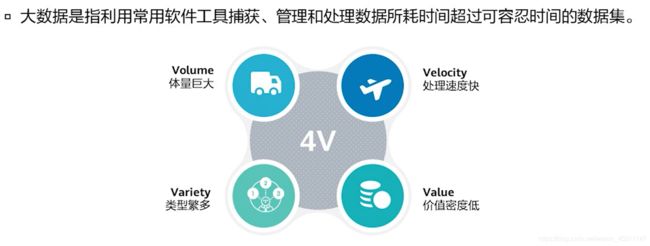
在3V的基础上,业界对4V的定义加上了价值密度低(Value),而IBM对4V的定义加上了
真实准确(Veracity)。
目前对大数据尚未有一个公认的定义,不同的定义基本上是从特征出发,试图给出大数据
的定义
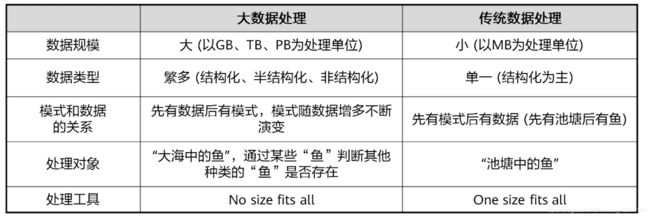
- 大数据处理与传统数据处理的差异
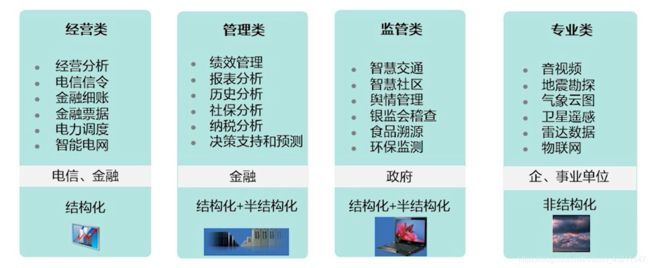
- 企业级大数据平台应用场景
• 社交网络和物联网技术拓展了数据采集技术渠道。
• 分布式存储和计算技术夯实了大数据处理的技术基础。
• 深度神经网络等新兴技术开辟大数据分析技术的新时代。
- 大数据应用的主要计算模式

- Hadoop大数据生态圈
Hadoop成为大数据批量处理的基础,但无法提供实时分析。

-
传统数据处理遭遇天花板

-
面临的挑战
▫ 业务部门无清晰的大数据需求
▫ 企业内数据孤岛严重
▫ 数据可用性低,质量差
▫ 数据相关管理技术和结构
▫ 数据安全问题
▫ 大数据人才的缺乏
▫ 数据开放与隐私的权衡 -
带来的机遇
▫ 大数据挖掘成为商业分析的核心
▫ 大数据成为信息技术应用的支撑点
▫ 大数据成为信息产业持续增长的新引擎
华为鲲鹏解决方案
- 基于鲲鹏处理器,构建整机计算功能
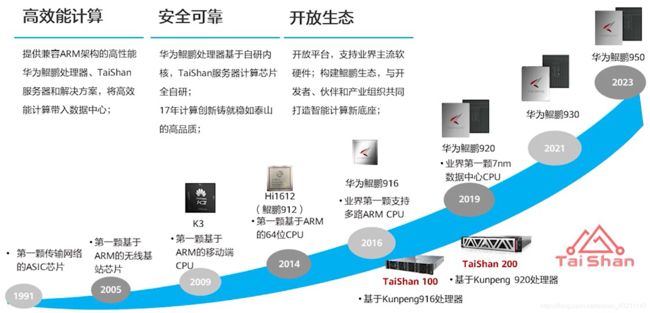
第一代TaiShan 100服务器是基于鲲鹏916处理器,2016年推出市场。2019年推出TaiShan
200服务器基于最新的鲲鹏920处理器,是市场的主打产品。
-
鲲鹏生态兼容的操作系统
-
华为云鲲鹏云服务支持丰富场景

-
华为大数据解决方案优势
高安全:
▫ 服务器及大数据平台自主可控
▫ 芯片级数据加密,数据不失密
高性能:
▫ 比同档通用服务器性能提升30%
▫ 支持5000+节点大数据集群
高效能:
▫ 比通用服务器能耗降低30%
▫ 同等算力需求下,机架空间省30% -
华为云大数据服务

DAYU寓意“大禹”治水, 围绕着企业数据湖,提供一站式数据资产管理、开发、探索和
共享能力。
- 华为云MRS服务综述

- 华为云MRS服务的优势

CarbonData是一种新型的Apache Hadoop本地文件格式,使用先进的列式存储、索引、压
缩和编码技术,以提高计算效率,有助于加速超过PB数量级的数据查询,可用于更快的交
互查询。同时,CarbonData也是一种将数据源与Spark集成的高性能分析引擎。


- 华为云MRS服务应用场景
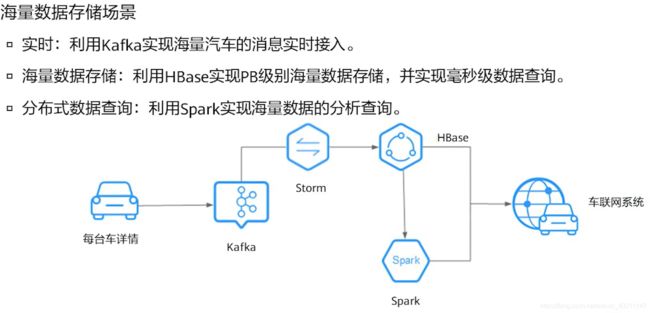
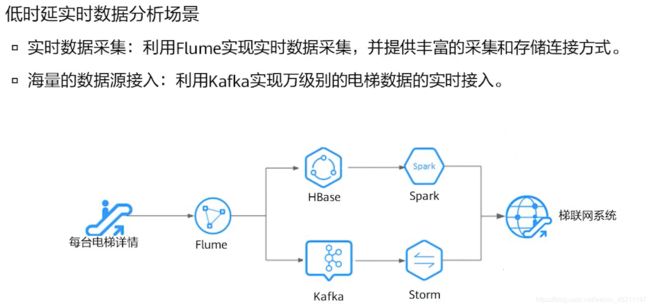
• 实时数据处理通常用于异常检测、欺诈识别、基于规则告警、业务流程监控等场景,在数
据输入系统的过程中,对数据进行处理。
• 例如在梯联网行业,智能电梯的数据,实时传入到MRS的流式集群中进行实时告警
课后习题
- 判断题

- 单选题

- 多选题

返回目录
二、HDFS分布式文件管理系统和ZooKeeper
导读

- 大数据平台提供的最基本的两个功能是什么?
存储和计算能力
- HDFS主要包括哪些角色?
NameNode,DataNode,Client
- 大数据生态圈组件为什么需要Zookeeper去提供分布式协调?
HDFS分布式文件管理系统
-
特性
高容错性:认为硬件总是不可靠的;
高吞吐量:对大量数据访问的应用提供吞吐量支持;
大文件存储:支持存储TB-PB级别的数据。
擅长:大文件存储与访问、流式数据访问
不擅长:大量小文件存储、随机写入、低延迟读取 -
基本系统架构

HDFS架构包含三个部分:NameNode,DataNode,Client。
▫ NameNode:NameNode用于存储、生成文件系统的元数据。运行一个实例。
▫ DataNode:DataNode用于存储实际的数据,将自己管理的数据块上报给NameNode ,运行多个实例。
▫ Client:支持业务访问HDFS,从NameNode ,DataNode获取数据返回给业务。多个实例,和业务一起运行。 -
Block 块
HDFS默认一个块128MB,一个文件被分成多个块,以块做存储单位。
抽象的块概念可以带来一下几个明显的好处:
• 支持大规模文件存储:文件以块为单位进行存储,一个大规模文件可以被分拆成若干个文件块,不同的文件块可以被分发到不同的节点上,因此,一个文件的大小不会受到单个节点的存储容量的限制,可以远远大于网络中任意节点的存储容量
• 简化系统设计:首先,大大简化了存储管理,因为文件块大小是固定的,这样就可以很容易计算出一个节点可以存储多少文件块;其次,方便了元数据的管理,元数据不需要和文件块一起存储,可以由其他系统负责管理元数据
• 适合数据备份:每个文件块都可以冗余存储到多个节点上,大大提高了系统的容错性和可用性 -
NameNode 和 DataNodes
| NameNode | DataNodes |
|---|---|
| 存储元数据 | 存储文件内容 |
| 元数据保存在内存中 | 文件内容保存在磁盘中 |
| 保存文件 block,datanode之间的映射关系 | 维护了block id 到datanode本地文件的映射关系 |

1、在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditLog
▫ FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据
▫ 操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作
名称节点(NameNode)记录了每个文件中各个块所在的数据节点的位置信息
2、数据节点(DataNode)是分布式文件管理系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并向名称节点自己所存储的块的列表。
每个数据节点的数据会被保存在各自节点的本地Linux文件系统中
-
HDFS体系结构

-
HDFS通信协议

-
HDFS高可用性(HA)
HDFS的高可靠性(HA)主要体现在利用zookeeper实现主备NameNode,以解决单点
NameNode故障问题。
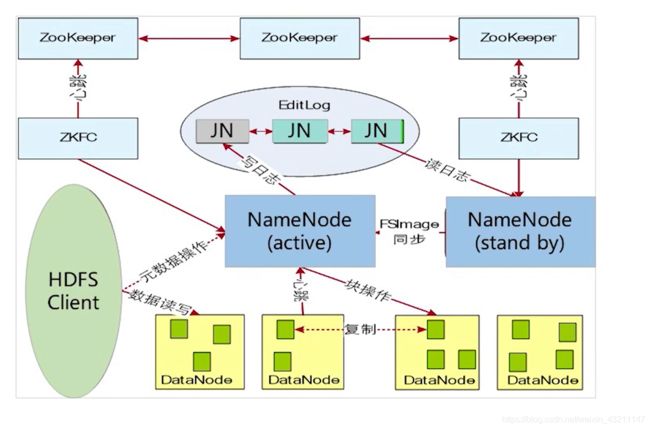
ZKFC(ZooKeeper Failover Controller) 用于监控NameNode节点的主备状态。
ZKFC控制NameNode主备仲裁
▫ ZKFC作为一个精简的仲裁代理,其利用zookeeper的分布式锁功能,实现主备仲裁,再通过命令通道,控制NameNode的主备状态。ZKFC与NN部署在一起,两者个数相
同。
JN(JournalNode) 用于存储Active NameNode生成的Editlog。Standby NameNode加载JN
上Editlog,同步元数据。
-
元数据的持久化
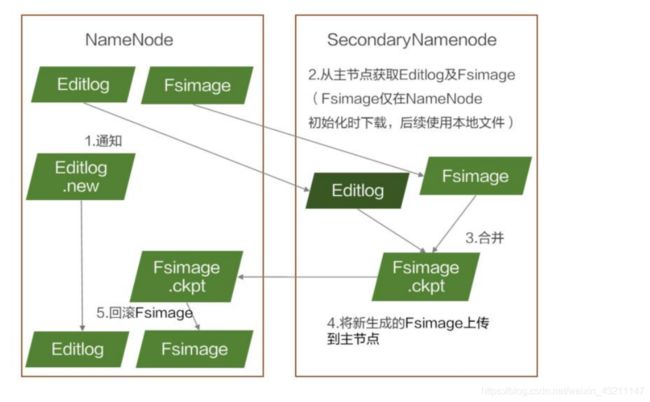
FSImage.ckpt: 在内存中对fsimage文件和EditLog文件合并(merge)后产生新的fsimage,写到磁盘上,这个过程叫checkpoint.。
EditLog.new: NameNode每隔1小时或Editlog满64MB就触发合并,合并时,将数据传到Standby NameNode时,因数据读写不能同步进行,此时NameNode产生一个新的日志文件Editlog.new用来存放这段时间的操作日志。 -
HDFS联邦(Federation)

各NameNode间元数据不共享,每个NameNode都有对应的standby,两两之间并不互相通信,一个失效也不会影响其他NameNode
-
数据副本机制

副本距离计算公式:
▫ Distance(Rack1/D1, Rack1/D1)=0,
▫ 同一台服务器的距离为0。
▫ Distance(Rack1/D1, Rack1/D3)=2,
▫ 同一机架不同的服务器距离为2。
▫ Distance(Rack1/D1, Rack2/D1)=4,
▫ 不同机架的服务器距离为4。
▫ 不同数据中心的节点距离为6。
副本放置策略:
第一个副本:放置在上传文件的数据节点;如果是集群外提交,则随机挑选一台磁盘不太满、CPU不太忙的节点
第二个副本:放置在与第一个副本不同的机架的节点上
第三个副本:与第一个副本相同机架的其他节点上
更多副本:随机节点 -
HDFS常用shell命令

-
HDFS数据写入流程

-
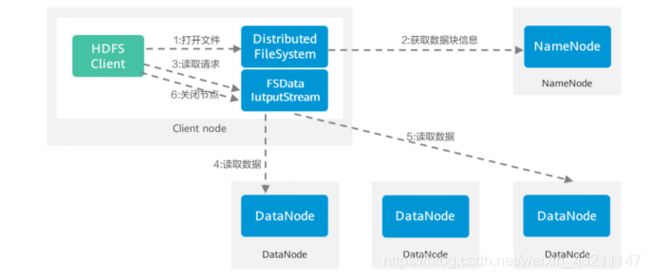
HDFS数据读取流程
ZooKeeper
- ZooKeeper体系架构
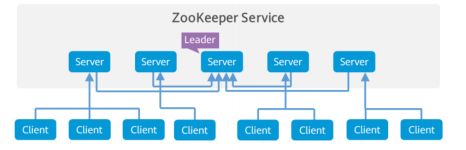

2x+1个节点与2x+2个节点的容灾能力相同(3个与4个相同,5个与6个相同…),考虑到选举以及完成写操作的速度与节点数的相关性,ZooKeeper应部署奇数个节点。
-
ZooKeeper关键特性

-
ZooKeeper读特性

-
ZooKeeper写特性
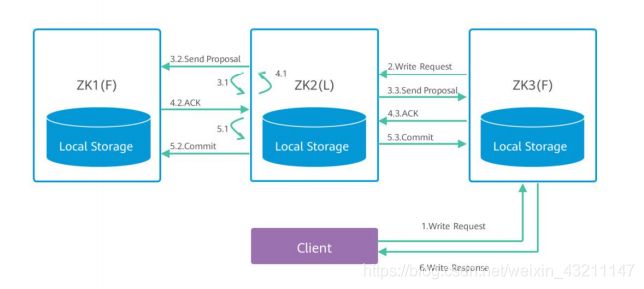
1、同读请求一样,客户端可以向任一server提出写请求,server将这一请求发送给leader。
2、leader获取写请求后,会向所有节点发送这条写请求信息,询问是否能够执行这次写
操作。
3、 follower节点根据自身情况给出反馈信息ACK应答消息,leader根据反馈信息,若获
取到的可以执行写操作的数量大于实例总数的一半,则认为本次写操作可执行。
4、 leader将结果反馈给各follower,并完成写操作,各follower节点同步leader的数据,
本次写操作完成。 -
ZooKeeper客户端常用命令

课后习题
思考题:
1.ZooKeeper为什么建议基数部署?
容灾能力相同,但部署成本低
2.HDFS数据块为什么一般比磁盘块大?
块比磁盘大,目的是为了最小化寻址开销。块足够大,那么从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。但也不能太大,因为map通常只处理一个块中的数据。如果Map数太少,则作业运行速度会比较慢
3.HDFS在数据写入时,能读取到吗?
当数据在写入的时候,写入数据不能立即可见,在命令空间是立即可见的。当写入超过一个块或者结束的时候,对一个新的reader就是可见的。当前正在写入的块,对其他reader是不可见的
判断题:

单选题:
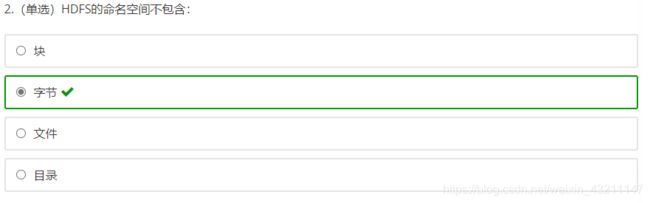

多选题:

1.Namespace(命名空间)的限制
由于Namenode在内存中存储所有的元数据(metadata),因此单个Namenode所能存储的对象(文件+块)数目收到Namenode所在JVM的heap size的限制。
2.性能的瓶颈(吞吐量)
由于是单个NameNode的HDFS架构,因此整个HDFS文件系统的吞吐量受限于单个Namenode的吞吐量。
3.隔离问题
由于HDFS仅有一个Namenode,无法隔离各个程序,因此HDFS上的一个实验程序就很有可能影响整个HDFS上运行的程序。
4.集群的可用性
在只有一个Namenode的HDFS中,此Namenode的宕机无疑会导致整个集群不可用。
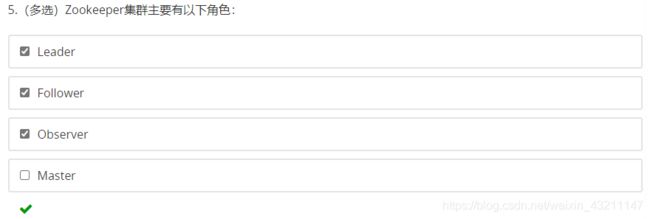
Leader: 通过选举算法确定,zk中的选举是精华,本人能力有限,怕说不清楚,所有不做讨论,作用发起投票,下达决议,更新系统
Follower: 接受客户连接,读写请求,发给leader,参与投票,返回客户端结果
Observer:同步leader
返回目录
三、Hive分布式数据仓库
导读
- 能够通过写SQL语句就可以进行大数据的统计分析?
通过HQL(类似SQL)的语句可以实现
- Hive中写HQL语句最终转换成了什么程序?
MapReduce
- Hive提供了哪些客户端接口供用户使用?
Hive CLI(Hive Command Line,Hive命令行),客户端可以直接在命令行模式下进行操作。
hwi(Hive Web Interface,Hive Web接口),Hive提供了更直观的Web界面。
hiveserver,Hive提供了Thrift服务,Thrift客户端目前支持C++/Java/PHP/Python/Ruby。
Hive概述
Hive是基于Hadoop的数据仓库软件,可以查询和管理PB级别的分布式数据
- Hive特性
灵活的ETL
支持Tez,Spark等多种计算引擎
可直接访问HDFS文件以及HBase
易用易编程 - Hive的使用场景
•Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提
交和调度的时候需要大量的开销。
• Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集
上执行查询一般有分钟级的时间延迟。因此,Hive 并不适合那些需要低延迟的应用,例如,
联机事务处理(OLTP)。
• Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。
Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
- Hive的优点
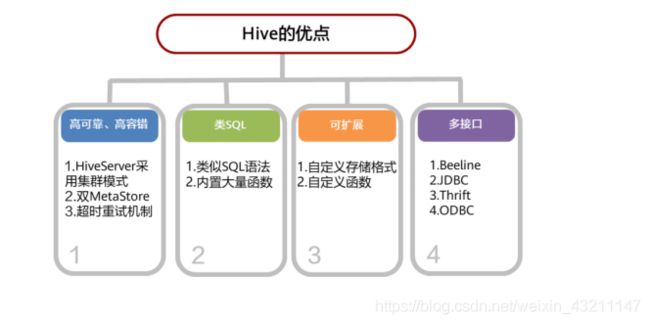
• HiveServer Hive对外提供SQL服务的主要进程。
• MetaStore Hive提供元数据信息的进程,可供HiveServer,SparkSQL,Oozie等组件调用。
• Beeline hive的命令行客户端。
• JDBC java统一数据库接口。
• Thrift 一种序列化、通信协议。
• ODBC 基于C/C++的数据库标准接口。
Hive功能与架构
- Hive的架构

• MetaStore : 存储表、列和Partition等元数据。
• Driver : 管理HiveQL执行的生命周期,并贯穿Hive任务整个执行期间。
• Compiler : 编译HiveQL并将其转化为一系列相互依赖的Map/Reduce任务。
• Optimizer : 优化器,分为逻辑优化器和物理优化器,分别对HiveQL生成的执行计划和MapReduce任务进行优化。
• Executor : 按照任务的依赖关系分别执行Map/Reduce任务。
• ThriftServer : 提供thrift接口,作为JDBC和ODBC的服务端,并将Hive和其他应用程序集成
起来。
• Clients : 包含命令行接口Beeline 和JDBC/ODBC 接口,为用户访问提供接口。
-
Hive运行流程

-
Hive数据存储模型
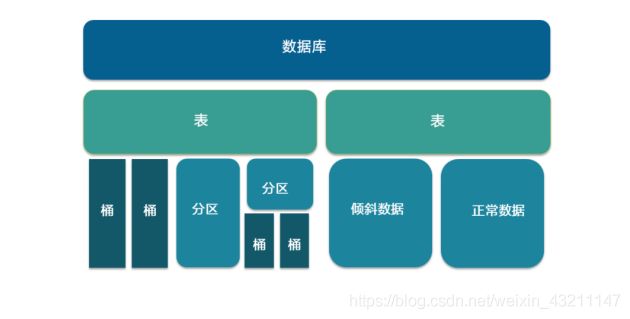
• 数据库:创建表时如果不指定数据库,则默认为default数据库。
• 表:物理概念,实际对应HDFS上的一个目录。
• 分区:对应所在表所在目录下的一个子目录。
• 桶:对应表或分区所在路径的一个文件。
• 倾斜数据:数据集中于个别字段值的场景,比如按照城市分区时,80%的数据都来自某个大城市。
• 正常数据:不存在倾斜的数据。

• 分区表:CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING);
• 分桶表:
▫ create table stu_buck(sno int,sname string,sex string,sage int,sdept string) clustered by(sno) sorted by(sno DESC) into 4 buckets row format delimited fields terminated by ‘,’;
▫ #设置变量,设置分桶为true, 设置reduce数量是分桶的数量个数
▫ set hive.enforce.bucketing = true;
▫ set mapreduce.job.reduces=4;
▫ #开会往创建的分通表插入数据(插入数据需要是已分桶, 且排序的)
▫ #可以使用distribute by(sno) sort by(sno asc) 或是排序和分桶的字段相同的时候使用Cluster by(字段)
▫ #注意使用cluster by 就等同于分桶+排序(sort)
▫ insert into table stu_buck select sno,sname,sex,sage,sdept from student distribute by(sno) sort by(sno asc);
- Hive支持的函数

• Round 四舍五入,Floor向下取整,abs 绝对值,rand 随机数
• To_data 返回日期 month 返回日期中月份 day 返回日期中的具体天
• hive> select day(‘2011-12-08 10:03:01’) from dual;
8
• 如果内置函数不能满足用户需求时,Hive可支持自定义函数。
• UDF用来解决 一行输入一行输出(One-to-One maping) 的需求。
Hive基本操作
- 运行Hive服务

- Hive SQL介绍

- Hive SQL介绍-DDL操作
DDL即数据定义语言,DDL操作都是对元数据的操作。主要包含如下操作:
▫ Create/Drop/Alter Database;
▫ Create/Drop/Truncate Table;
▫ Alter Table/Partition/Column;
▫ Create/Drop/Alter View;
▫ Create/Drop Index;
▫ Create/Drop Function;
▫ Show;
▫ Describe。

-
Hive SQL介绍-DML操作

-
Hive SQL介绍-DQL操作


课后习题
思考题:
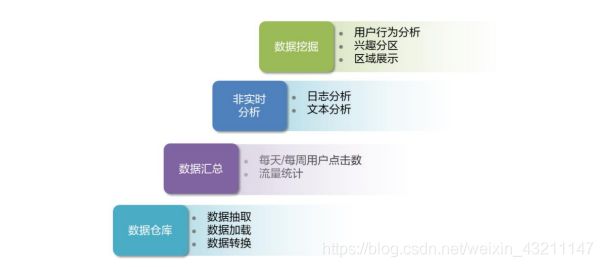
Hive的使用场景有哪些?
数据挖掘(用户行为分析,兴趣分析,区域展示)
数据汇总(每天/每周用户点击数,点击排行)
非实时分析(日志分析,统计分析)
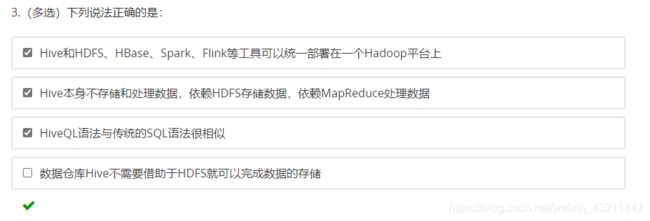
以下关于Hive SQL基本操作描述正确的是?
A.创建外部表使用external关键字,创建普通表需要指定internal关键字
创建普通表不需要指定internal关键字
B.创建外部表必须要指定location信息
不是必须的
C.加载数据到Hive时源数据必须是HDFS的一个路径
可以是本地也可以是HDFS
加local是从本地复制过去,不加local是从HDFS上剪切过去
D. 创建表时可以指定列分隔符
√
判断题:

单选题:

多选题:

返回目录
四、HBase技术原理
导读
- HBase能否应用于实时响应查询计算的应用场景?
HBase的优势在于实时计算,所有实时数据都直接存入HBase中,客户端通过API直接访问HBase,实现实时计算。由于它使用的是nosql,或者说是列式结构,从而提高了查找性能,使其能运用于大数据场景,这是它跟MapReduce的区别。
- 为什么说HBase是键值类型数据库?
KV将简单的键映射到(可能)更复杂的值,就像一个巨大的哈希表。
- HBase的主要角色有哪些?分别提供什么作用?
HMaster
监控RegionServer
处理RegionServer故障转移
处理元数据变更
处理region的分配或移除
空闲时对数据进行负载均衡
通过zookeeper发布自己的位置给客户端
RegionServer
负责存储Hbase的实际数据
处理分配给它的region
刷新缓存到HDFS上
维护HLog
执行压缩
负责处理Region分片
- Zookeeper对HBase提供了什么服务支持?
Zookeeper 作用有三点:
▫ 1、分布式锁
▫ 2、事件监控
▫ 3、存储HBase的Region Server数据,充当微型数据库
HBase基本介绍
- 简介
HBase :兼容结构化/非结构化数据,容量大,高并发,低时延,低成本的数据库

• 大表:bigtable结构
BigTable 是一个疏松的分布式的持久的多维排序的map,这个map有行健、列键和时间戳索引,每一个值都是连续的byte数组
• Zookeeper 作用有三点:
▫ 1、分布式锁
▫ 2、事件监控
▫ 3、存储HBase的Region Server数据,充当微型数据库
-
HBase与RDB的对比
HBase与传统的关系数据库的区别主要体现在以下几个方面:
▫ 数据索引:关系数据库通常可以针对不同列构建复杂的多个索引,以提高数据访问性能。HBase只有一个索引——行键,通过巧妙的设计,HBase中的所有访问方法,或者通过行键访问,或者通过行键扫描,从而使得整个系统不会慢下来
▫ 数据维护:在关系数据库中,更新操作会用最新的当前值去替换记录中原来的旧值,旧值被覆盖后就不会存在。而在HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留
▫ 可伸缩性:关系数据库很难实现横向扩展,纵向扩展的空间也比较有限。相反,HBase和BigTable这些分布式数据库就是为了实现灵活的水平扩展而开发的,能够轻易地通过在集群中增加或者减少硬件数量来实现性能的伸缩 -
HBase应用场景

• 对象存储:1B~100M 对象存储(图片、网页、文本、新闻) —— 海量存储
• 时序数据:时间序列数据(传感器、监控数据、股票K线)—— 高并发/海量存储
• 气象数据:卫星轨道、气象数据 —— 高并发/海量存储
• Cube分析:实时报表 —— 高并发/海量存储
• NewSQL:元数据库、索引查询 —— SQL、二级索引、动态列
• Feeds流:朋友圈 —— 高并发请求
• 消息/订单存储:聊天信息、订单/保存存储 —— 强同步 海量数据
• 用户画像:用户特征存储 —— 万列稀疏矩阵
• 兼容结构化/非结构化数据,数据存储容量大,高并发,低时延,低成本的数据库
HBase相关概念
-
数据模型

-
HBase表结构
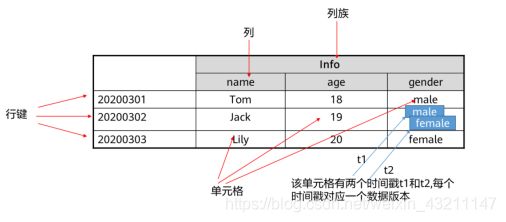

-
数据存储概念视图

-
数据存储物理视图

-
行存储
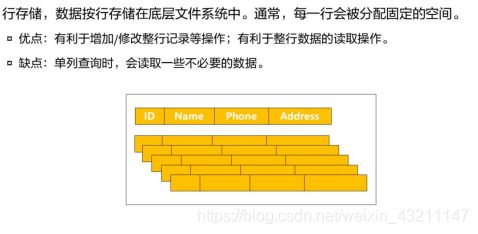
-
列存储

HBase架构

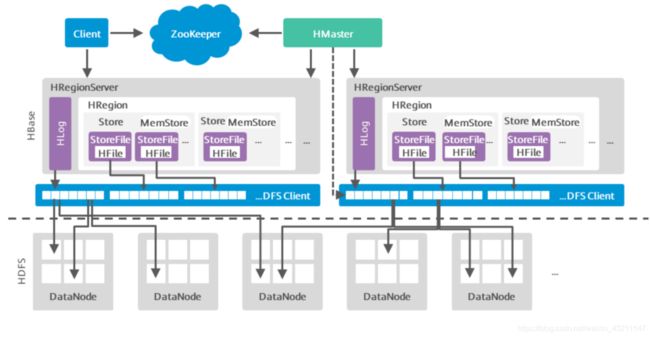
• Client使用HBase的RPC机制与Master、RegionServer进行通信。Client与Master进行管理类通信,与RegionServer进行数据操作类通信。
• RegionServer负责提供表数据读写等服务,是HBase的数据处理和计算单元。RegionServer一般与HDFS集群的DataNode部署在一起,实现数据的存储功能。
• HMaster,在HA模式下,包含主用Master和备用Master。
▫ 主用Master:负责HBase中RegionServer的管理,包括表的增删改查;RegionServer的负载均衡,Region分布调整;Region分裂以及分裂后的Region分配;RegionServer失效后的Region迁移等。
▫ 备用Master:当主用Master故障时,备用Master将取代主用Master对外提供服务。故障恢复后,原主用Master降为备用。
• HDFS为HBase提供高可靠的文件存储服务,HBase的数据全部存储在HDFS中。
• MemStore:当RegionServer中的MemStore大小达到配置的容量上限时,RegionServer会
将MemStore中的数据“flush”到HDFS中。
• StoreFile:随着数据的插入,一个Store会产生多个StoreFile,当StoreFile的个数达到配置
的最大值时,RegionServer会将多个StoreFile合并为一个大的StoreFile。


- 表和Region

- Region的定位

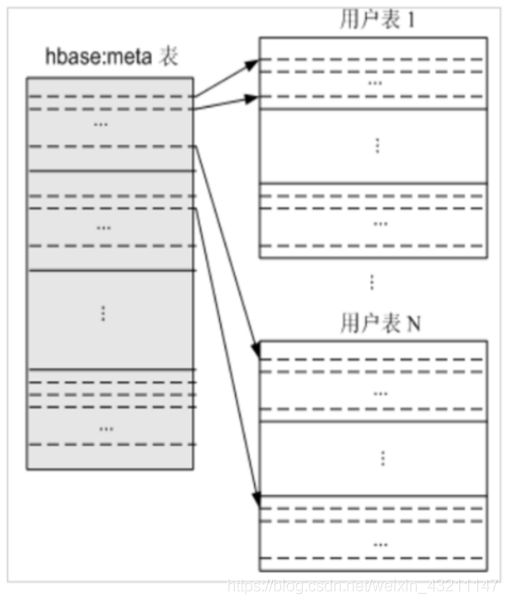
• hbase0.96之后,hbase就废弃了ROOT表**,仅保留hbase:meta

- HMaster高可用

HBase关键流程
- 用户读写数据过程

- 缓存的刷新

- StoreFile的合并

- Store工作原理
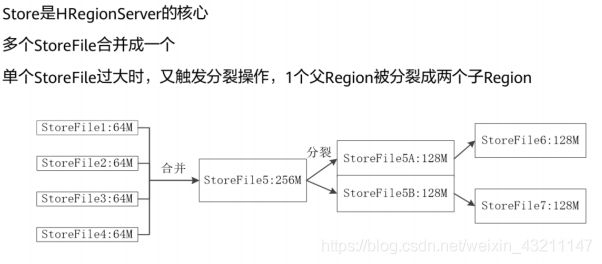
- HLog工作原理


HBase突出特点
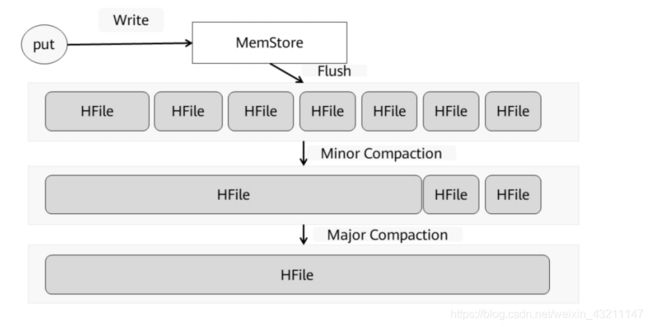
- 多HFile的影响

- Compaction

• Compaction都会首先对该Store中所有HFile进行一一排查,排除不满足条件的部分文件:
▫ 排除当前正在执行compact的文件及其比这些文件更新的所有文件(SequenceId更大)。
▫ 排除某些过大的单个文件,如果文件大小大于hbase.hzstore.compaction.max.size( 默认Long最大值 ),则被排除,否则会产生大量IO消耗。
• 经过排除的文件称为候选文件,HBase接下来会再判断是否满足major compaction条件,如果满足,就会选择全部文件进行合并。判断条件有下面三条,只要满足其中一条就会执行major compaction:
▫ 用户强制执行major compaction。
▫ 长时间没有进行compact(CompactionChecker的判断条件2)且候选文件数小于
hbase.hstore.compaction.max(默认10)。
▫ Store中含有Reference文件,Reference文件是split region产生的临时文件,只是简单的引用文件,一般必须在compact过程中删除。
• 如果不满足major compaction条件,就必然为minor compaction。
- OpenScanner
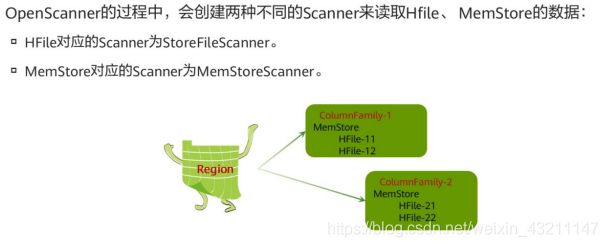
- BloomFilter

HBase性能优化
- 行键(Row Key)

- 构建HBase二级索引


HBase常用Shell命令

课后习题
- 思考题

D

A
- 单选题


- 多选题


返回目录
五、MapReduce和Yarn技术原理
导读
- MapReduce适用于数据密集型任务,还是计算密集型任务?
数据密集型任务
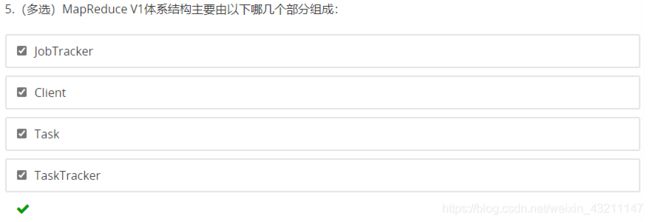
- MapReduce 1.x主要包括哪些角色?主要功能是什么?
Client:用户编写的MapReduce程序通过Client提交到JobTracker端
JobTracker:负责资源控制和作业调度;负责监控所有TaskTracker与Job的健康状况,一旦出现失败,就把相应的任务转移到其他节点;JobTracker会跟踪任务的执行进度、资源使用量等信息,并把这些信息告诉任务调度器(TaskTracker),而调度器会在资源出现空闲的时候,选择合适的任务去使用这些资源。
TaskTracker:会周期地通过“心跳”将本节点上的资源使用情况和任务运行进度汇报给JobTracker,同时接收jobTracker发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)
TaskTracker使用”slot”(槽)等量划分本节点上的资源量(CPU、内存等)。一个Task获取到一个Slot后才有机会运行。而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为MapSlot和ReduceSlot,分别提供给mapTask和reduceTask使用。
Task:分为MapTask和ReduceTask两种,均有TaskTracker启动。
- Yarn主要分担了MapReduce 1.x中的哪些功能?
MRv1中资源管理和作业管理均是由JobTracker实现的,集两个功能于一身,而在MRv2中,将这两部分分开了,其中,作业管理由ApplicationMaster实现,资源管理由新增系统YARN完成
- Yarn默认包含哪三种三种资源调度器?
FIFO调度器
先进先出,但不适合资源公平性
容量调度器
独立的专门队列保证小作业也可以提交后就启动,队列容量是专门保留的以整个集群的利用率为代价,与FIFO比,大作业执行的时间要长
公平调度器
不需要预留资源,调度器可以在运行的作业之间动态平衡资源,大作业启动时,因为是唯一运行的,所以获得集群的所有资源,之后小作业启动时,被分配到集群的一半的资源,这样每个作业都能公平共享资源
MapReduce和Yarn基本介绍
- MapReduce概述

- 资源调度与分配

- Yarn概述

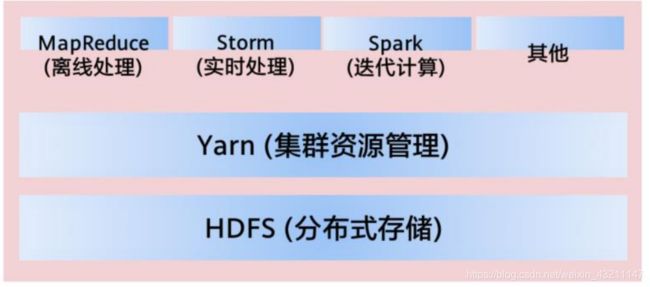
Yarn是轻量级弹性计算平台,除了MapReduce框架,还可以支持其他框架,比如Spark、Storm等
• 多种框架统一管理,共享集群资源:
▫ 资源利用率高
▫ 运维成本低
▫ 数据共享方便
MapReduce和Yarn功能与架构
- MapReduce工作流程
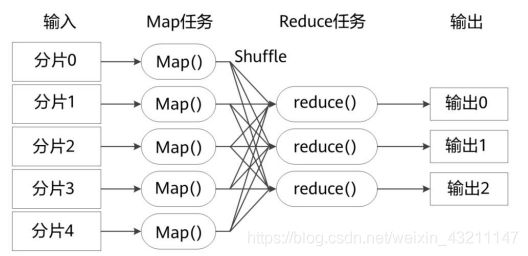
• 不同的Map任务之间不会进行通信
• 不同的Reduce任务之间也不会发生任何信息交换
• 用户不能显式地从一台机器向另一台机器发送消息
• 所有的数据交换都是通过MapReduce框架自身去实现的
- Map阶段详解
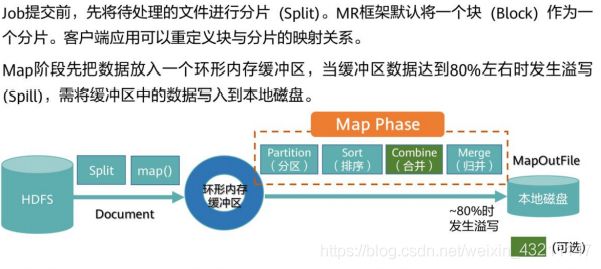
▫ 分区 (Partition)—默认采用Hash算法进行分区,MR框架根据Reduce Task个数来确定分区个数。具备相同Key值的记录最终被送到相同的Reduce Task来处理。
▫ 排序 (Sort) —将Map输出的记录排序,例如将(‘Hi’,’1’),(‘Hello’,’1’)重新排序为(‘Hello’,’1’), (’Hi’,’1’)。
▫ 组合 (Combine) —这个动作MR框架默认是可选的。例如将 (’Hi’,’1’), (’Hi’,’1’),(‘Hello’,’1’), (Hello’,’1’)进行合并操作为 (’Hi’,’2’), (‘Hello’,’2’)。
▫ 合并 (Spill) —Map Task在处理后会产生很多的溢出文件(spill file),这时需将多个溢出文件进行合并处理,生成一个经过分区和排序的Spill File (MOF:MapOutFile)。为减少写入磁盘的数据量,MR支持对MOF进行压缩后再写入。
- Reduce阶段详解


通常在Map Task任务完成MOF输出进度到3%时启动Reduce,从各个Map Task获取MOF文件。前面提到Reduce Task个数由客户端决定,Reduce Task个数决定MOF文件分区数。因此Map Task输出的MOF文件都能找到相对应的Reduce Task来处理。
- Shuffle过程详解

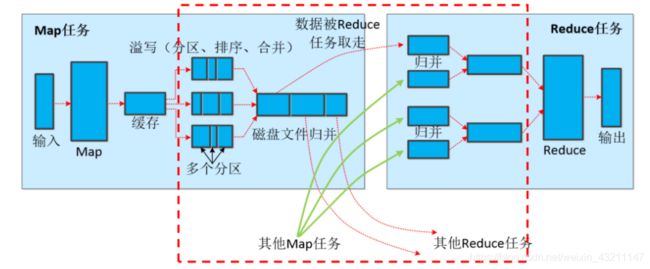
每个Map任务分配一个缓存;MapReduce默认100MB缓存;设置溢写比例0.8;排序是默认的操作;排序后可以合并(Combine)。
• 在Map任务全部结束之前进行归并,归并得到一个大的文件,放在本地磁盘。
• 文件归并时,如果溢写文件数量大于预定值(默认是3)则可以再次启动Combiner,少于3不需要。
• JobTracker会一直监测Map任务的执行,并通知Reduce任务来领取数据。
• Reduce任务通过RPC向JobTracker询问Map任务是否已经完成,若完成,则领取数据。
• Reduce领取数据先放入缓存,来自不同Map机器,先归并,再合并,写入磁盘。
• 多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的。
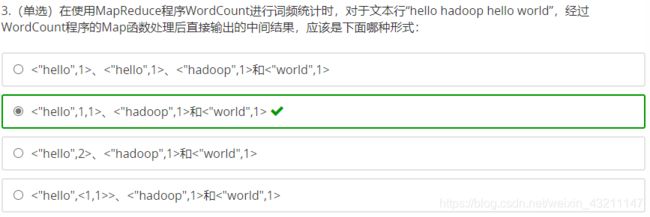
- 经典程序WordCount举例
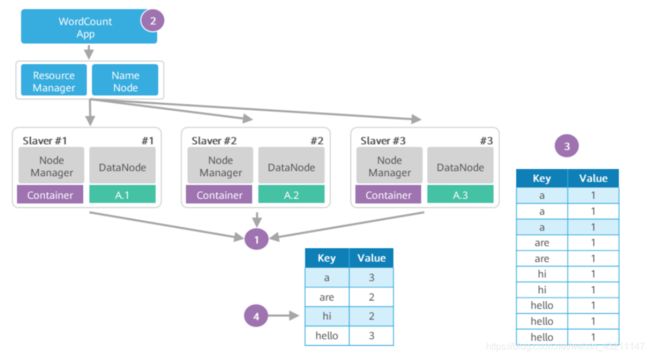
▫ 第一步:待处理的大文件A已经存放在HDFS上,大文件A被切分的数据块A.1、A.2、A.3分别
存放在Data Node #1、#2、#3上。
▫ 第二步:WordCount分析处理程序实现了用户自定义的Map函数和Reduce函数。WordCount
将分析应用提交给RM,RM根据请求创建对应的Job,并根据文件块个数按文件块分片,创建
3个 MapTask 和 3个Reduce Task,这些Task运行在Container中。
▫ 第三步:Map Task 1、2、3的输出是一个经分区与排序(假设没做Combine)的MOF文件,
记录形如表所示。
▫ 第四步:Reduce Task从 Map Task获取MOF文件,经过合并、排序,最后根据用户自定义的
Reduce逻辑,输出如表所示的统计结果。
- WordCount的Map过程
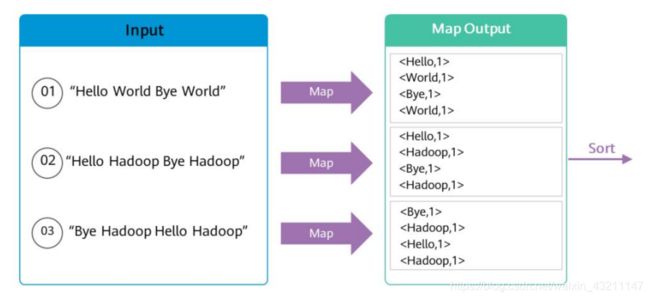
- WordCount的Reduce过程
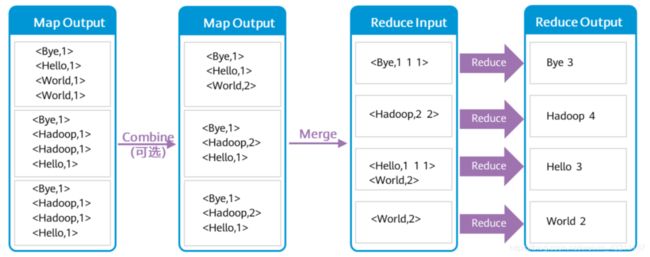
- Yarn的组件架构
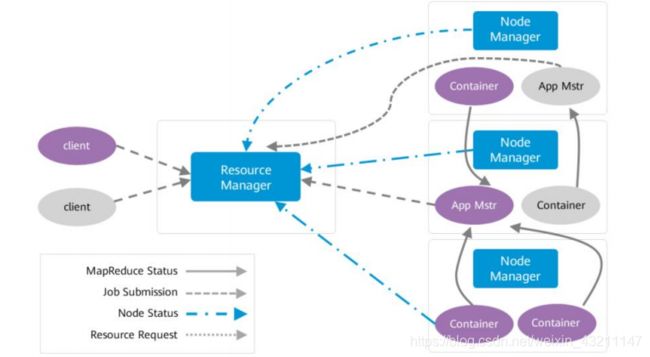
• 在图中有两个客户端向Yarn提交任务,蓝色表示一个任务流程,棕色表示另一个任务流程。
• 首先client提交任务,ResourceManager接收到任务,然后启动并监控起来的第一个
Container,也就是App Mstr。
• App Mstr通知nodemanager管理资源并启动其他container。
• 任务最终是运行在Container当中。
- MapReduce On Yarn任务调度流程

• 步骤1:用户向YARN 中提交应用程序, 其中包括ApplicationMaster 程序、启动ApplicationMaster 的命令、用户程序等。
• 步骤2:ResourceManager 为该应用程序分配第一个Container, 并与对应的NodeManager 通信,要求它在这个Container 中启动应用程序的ApplicationMaster 。
• 步骤3:ApplicationMaster 首先向ResourceManager 注册, 这样用户可以直接通过ResourceManage 查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
• 步骤4:ApplicationMaster 采用轮询的方式通过RPC 协议向ResourceManager 申请和领取
资源。
• 步骤5:一旦ApplicationMaster 申请到资源后,便与对应的NodeManager 通信,要求它
启动任务。
• 步骤6:NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
• 步骤7:各个任务通过某个RPC 协议向ApplicationMaster 汇报自己的状态和进度,以让ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC 向ApplicationMaster 查询应用程序的当前运行状态。
• 步骤8 应用程序运行完成后,ApplicationMaster 向ResourceManager 注销并关闭自己。
- Yarn HA方案

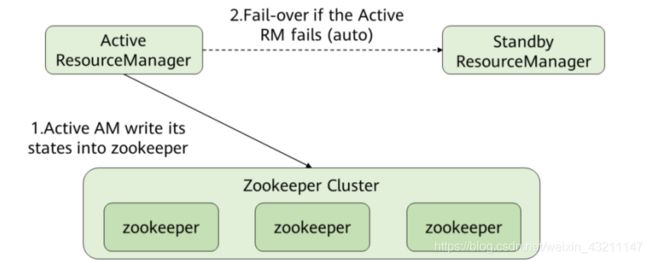
• ResourceManager的高可用性方案是通过设置一组Active/Standby的ResourceManager节点来实现的。与HDFS的高可用性方案类似,任何时间点上都只能有一个ResourceManager处于Active状态。当Active状态的ResourceManager发生故障时,可通过自动或手动的方式触发故障转移,进Active/Standby状态切换。
• 在未开启自动故障转移时,Yarn集群启动后,管理员需要在命令行中使用yarn rmadmin命令手动将其中一个ResourceManager切换为Active状态。当需要执行计划性维护或故障发生时,则需要先手动将Active状态的ResourceManager切换为Standby状态,再将另一个ResourceManager切换为Active状态。
• 开启自动故障转移后,ResourceManager会通过内置的基于ZooKeeper实现的ActiveStandbyElector来决定哪一个ResouceManager应该成为Active节点。当Active状态的ResourceManager发生故障时,另一个ResourceManager将自动被选举为Active状态以接替故障节点。
• 当集群的ResourceManager以HA方式部署时,客户端使用的“yarn-site.xml”需要配置所有ResourceManager地址。客户端(包括ApplicationMaster和NodeManager)会以轮询的方式寻找Active状态的ResourceManager。如果当前Active状态的ResourceManager无法连接,那么会继续使用轮询的方式找到新的ResourceManager。
- Yarn AppMaster容错机制
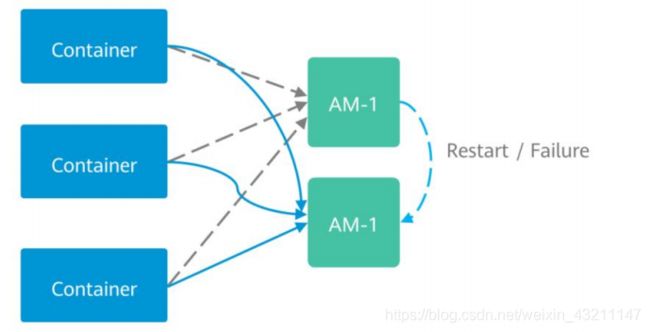
• 在YARN中,ApplicationMaster(AM)与其他Container类似也运行在NodeManager上(忽
略未管理的AM)。AM可能会由于多种原因崩溃、退出或关闭。如果AM停止运行,
ResourceManager(RM)会关闭ApplicationAttempt中管理的所有Container,包括当前任
务在NodeManager(NM)上正在运行的所有Container。RM会在另一计算节点上启动新的
ApplicationAttempt。
• 不同类型的应用希望以多种方式处理AM重新启动的事件。MapReduce类应用目标是不丢
失任务状态,但也能允许一部分的状态损失。但是对于长周期的服务而言,用户并不希望
仅仅由于AM的故障而导致整个服务停止运行。
• YARN支持在新的ApplicationAttempt启动时,保留之前Container的状态,因此运行中的
作业可以继续无故障的运行。
Yarn的资源管理和任务调度
-
资源管理

-
Yarn的三种资源调度器

增强特性
- Yarn动态内存管理
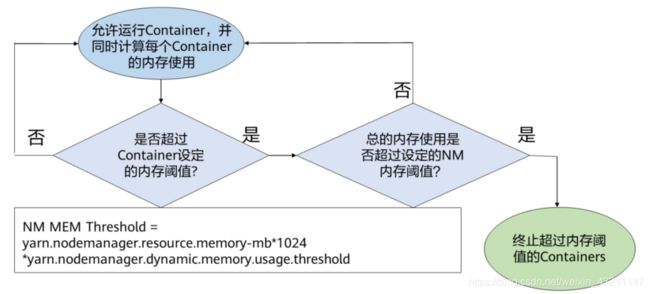
• 动态内存管理可用来优化NodeManager中Containers的内存利用率。任务在运行过程中可能产生多个Container。
• 当前,当单个节点上的Container超过Container运行内存大小时,即使节点总的配置内存利用还很低,NodeManager也会终止这些Containers。这样就会经常使用户作业失败。
• 动态内存管理特性在当前是一个改进,只有当NodeManager中的所有Containers的总内存使用超过了已确定的阈值,NM总内存阈值的计算方法是
yarn.nodemanager.resource.memory-mb10241024*yarn.nodemanager.dynamic.memory.usage.threshold,单位GB,那么那些内存使用过多的Containers才会被终止。
• 举例,假如某些Containers的物理内存利用率超过了配置的内存阈值,但所有Containers的总内存利用率并没有超过设置的NodeManager内存阈值,那么那些内存使用过多的Containers仍可以继续运行。
- Yarn基于标签调度

课后习题
- 思考题

A B D

C

B
- 判断题

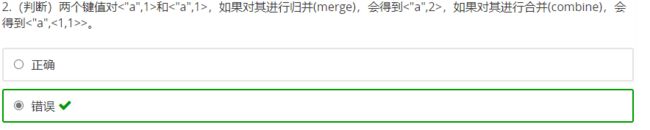
两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,如果归并,会得到
<“a”,<1,1>>
-
单选题

-
多选题
Client:用户编写的MapReduce程序通过Client提交到JobTracker端
JobTracker:负责资源控制和作业调度;负责监控所有TaskTracker与Job的健康状况,一旦出现失败,就把相应的任务转移到其他节点;JobTracker会跟踪任务的执行进度、资源使用量等信息,并把这些信息告诉任务调度器(TaskTracker),而调度器会在资源出现空闲的时候,选择合适的任务去使用这些资源。
TaskTracker:会周期地通过“心跳”将本节点上的资源使用情况和任务运行进度汇报给JobTracker,同时接收jobTracker发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)
TaskTracker使用”slot”(槽)等量划分本节点上的资源量(CPU、内存等)。一个Task获取到一个Slot后才有机会运行。而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为MapSlot和ReduceSlot,分别提供给mapTask和reduceTask使用。
Task:分为MapTask和ReduceTask两种,均有TaskTracker启动。
返回目录
六、Spark基于内存的分布式计算
导读
- 为什么说Spark是基于内存的分布式计算引擎?
- RDD宽依赖和窄依赖的主要区别是什么?
- RDD有哪些主要操作?
- Spark支持流计算吗?
Spark概述
-
简介

-
Spark应用场景

-
Spark的特点
轻:Spark核心代码有3万行。
Scala语言的简洁和丰富表达力。
巧妙利用了Hadoop和Mesos的基础设施。
快:Spark对小数据集可达到亚秒级的延迟。
对大数据集的迭代机器学习即席查询、图计算等应用,Spark 版本比基于MapReduce、Hive和Pregel的实现快。
内存计算、数据本地性和传输优化、调度优化。
灵:Spark提供了不同层面的灵活性。
Scala语言trait动态混入策略(如可更换的集群调度器、序列化库)。
允许扩展新的数据算子、新的数据源、新的language bindings 。
Spark支持内存计算、多迭代批量处理、即席查询、流处理和图计算等多种范式。
巧:巧妙借力现有大数据组件。
Spark借Hadoop之势,与Hadoop无缝结合。
图计算借用Pregel和PowerGraph的API以及PowerGraph的点分割思想。 -
Spark vs MapReduce
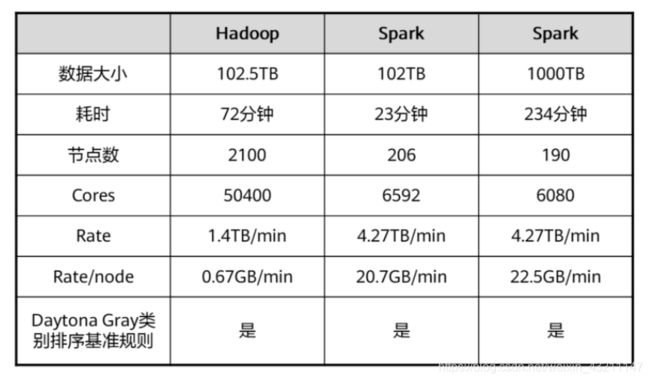
Spark用十分之一的资源,获得3倍与Mapreduce的性能。
Cores:集群总核数。
Rate:集群读取数据速度。
Rate/node:平均每节点读取数据速度。
Daytona Gray:Sort Benchmark的一个通用排序竞赛项目。
Spark数据结构
- Spark核心概念RDD

RDD是Spark对基础数据的抽象。
RDD的生成:从Hadoop文件系统(或与Hadoop兼容的其它存储系统)输入创建(如HDFS);从父RDD转换得到新的RDD。
RDD的存储:用户可以选择不同的存储级别存储RDD以便重用(11种);RDD默认存储于内存,但当内存不足时,RDD会溢出到磁盘中。
RDD的分区:为减少网络传输代价,和进行分布式计算,需对RDD进行分区。在需要进行分区时会根据每条记录Key进行分区,以此保证两个数据集能高效进行Join操作。
RDD的优点:RDD是只读的,静态的。因此可提供更高的容错能力;可以实现推测式执行。
-
RDD的依赖关系

Dependency(依赖)
窄依赖是指父RDD的每个分区最多被一个子RDD的一个分区所用。
宽依赖是指父RDD的每个分区对应一个子RDD的多个分区,是stage划分的依据。
Lineage(血统):依赖的链条
RDD数据集通过Lineage记住了它是如何从其他RDD中演变过来的。 -
宽窄依赖的区别 - 算子

-
宽窄依赖的区别 - 容错性

-
宽窄依赖的区别 - 传输

-
RDD的Stage划分

-
RDD操作类型

-
创建操作

-
控制操作

-
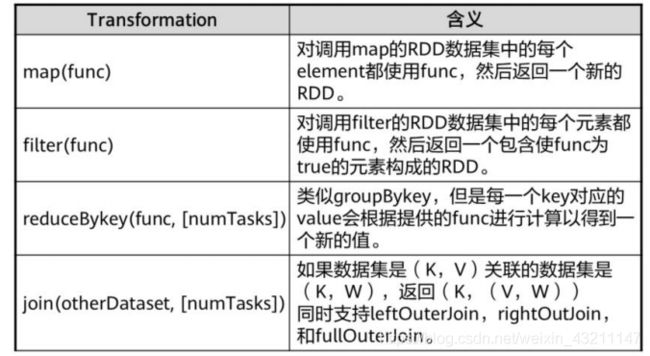
转换操作
-
行动操作
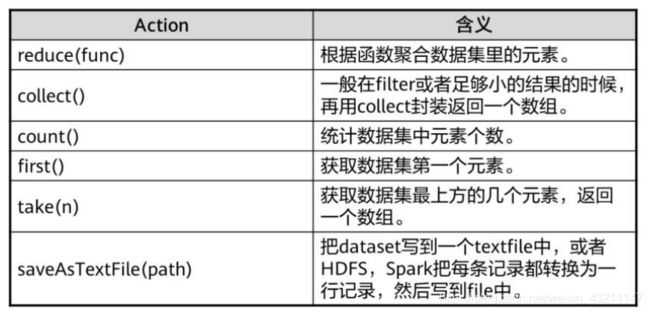
-
DataFrame概念

-
DataSet概念

-
RDD,DataSet,DataFrame的区别
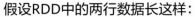

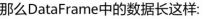

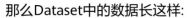

DataFrame与DataSet的区别
DataFrame
DataFrame每一行的类型固定为Row,只有通过解析才能获取各个字段的值,每一列的值没法直接访问。
DataFrame编译器缺少类型安全检查。
DataSet
每一行是什么类型是不一定的,可以是Person,也可以是Row。
DataSet类型安全。
RDD与DataFrame/DataSet的区别
RDD
用于Spark1.X各模块的API
不支持SparkSQL操作
不支持代码自动优化
DataFrame与DataSet
用于Spark2.X各模块的API
支持SparkSQL操作,还能注册临时表,进行sql语句操作
支持一些方便的保存方式,比如保存成csv、json等格式
基于SparkSql引擎构建,支持代码自动优化
RDD与DataFrame、DataSet三者的共性
三者都是分布式弹性数据集,支持相互转化。
三者有许多共同的函数,如filter,排序等。
三者都是Lazy的,在进行创建、转换时,不会立即执行。只有在遇到Action算子时,才会开始遍历运算。
Spark原理与架构
- Spark体系架构
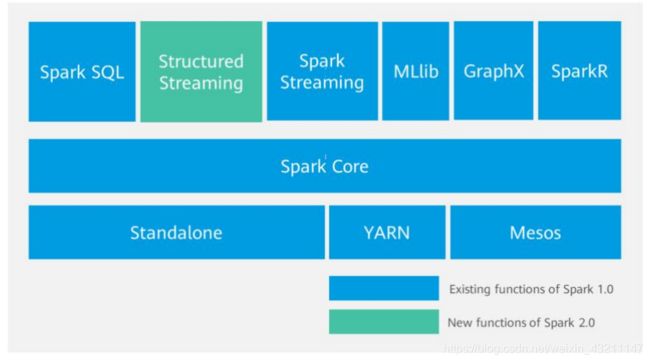
SparkCore:类似于MR的分布式内存计算框架,最大的特点是将中间计算结果直接放在内存中,提升计算性能。自带了Standalone模式的资源管理框架,同时,也支持YARN、 MESOS的资源管理统。FI集成的是Spark On Yarn的模式。其它模式暂不支持。
SparkSQL:Spark SQL是一个用于处理结构化数据的Spark组件,作为Apache Spark大数据框架的一部分,主要用于结构化数据处理和对数据执行类SQL查询。通过Spark SQL,可以针对不同数据格式(如:JSON,Parquet, ORC等)和数据源执行ETL操作(如:HDFS、数据库等),完成特定的查询操作。
SparkStreaming:微批处理的流处理引擎,将流数据分片以后用SparkCore的计算引擎中进行处理。相对于Storm,实时性稍差,优势体现在吞吐量上。
Mllib和GraphX主要一些算法库。
Structured Streaming为2.0版本之后的spark独有。
- 典型案例 - WordCount


- Spark SQL概述


Spark SQL对SQL语句的处理和关系型数据库采用了类似的方法,SparkSQL先会将
SQL语句进行解析(Parse)形成一个Tree, 然后使用Rule对Tree进行绑定、 优化等
处理过程。
词法和语法解析(Parse): 对读入的SQL语句进行词法和语法解析(Parse),分辨出
SQL语句中那些词是关键词(如SELECT、FROM、WHERE),哪些是表达式,哪些
是Projection,哪些是Data Source等,判断SQL语句是否规范,并形成逻辑计划。
绑定(Bind):将SQL语句和数据库的数据字典(列、 表和视图等)进行绑定(Bind),如果
相关的Projection和Data Source等都存在的话,则表示这个SQL语句是可以执行的。
优化(Optimize):Spark SQL会提供几个执行计划,返回从数据库查询的数据集。
执行(Execute):执行前面步骤获取的最优执行计划,返回从数据库查询的数据集
- Spark SQL vs Hive

Spark SQL和Hive的语法除了桶表操作外,基本一样。
Spark SQL完美兼容Hive的函数。
- Structured Streaming概述


Structured Streaming的核心是将流式的数据看成一张数据不断增加的数据库表,这种流式的数据处理模型类似于数据块处理模型,可以把静态数据库表的一些查询操作应用在流式计算中,Spark执行标准的SQL查询,从无边界表中获取数据。
无边界表:新数据不断到来,旧数据不断丢弃,实际上是一个连续不断的结构化数据流。
- Structured Streaming计算模型示例
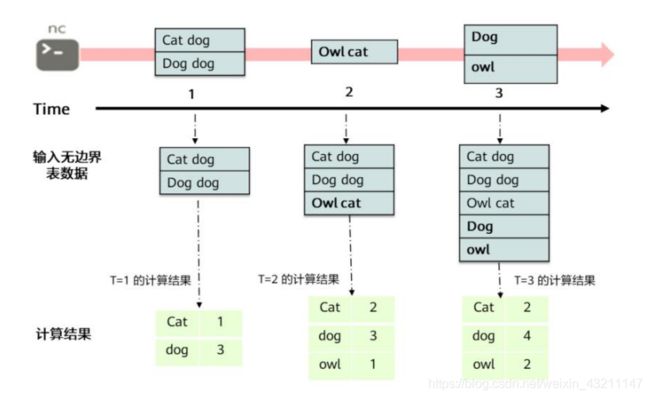
第一个lines DataFrame对象是一张数据输入的Input Table,最后的WordCounts
DataFrame是一个结果集Result Table。在lines DataFrame数据流之上的查询产生了
wordCounts的表示方式和在静态的Static DataFrame上的使用方式相同。然而,
Spark会监控socket连接,获取新的持续不断产生的数据。当新的数据产生时,Spark将
会在新数据上运行一个增量的counts查询,并且整合新的counts和之前已经计算出来的
counts,获取更新后的counts
- Spark Streaming概述


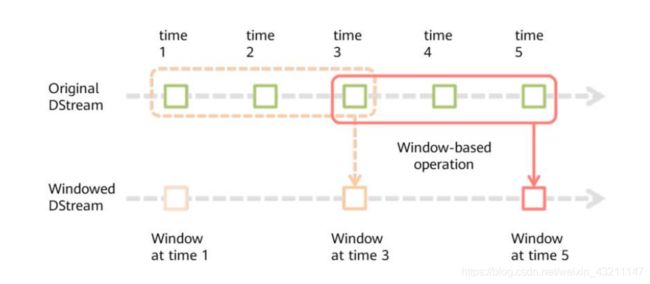
Spark Streaming基本原理:把输入数据以秒(毫秒)为单位切分,再定时提交这些切分后的数据。
- 窗口间隔和滑动间隔

- Spark Streaming vs Storm

课后习题
- 思考题

- 轻,快,灵,巧
- 基于内存计算,计算速度快
- 窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用,宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition。
- 离线批处理、实时流处理、交互式查询

- transformation(转换操作)、action(行动操作)
- spark core
- 宽依赖、窄依赖
-
单选题
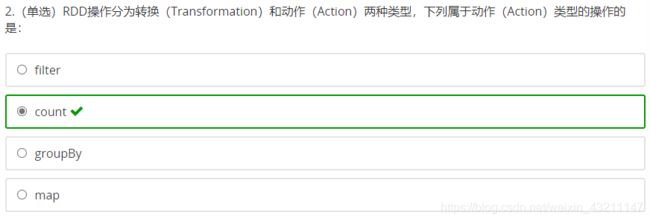

-
多选题

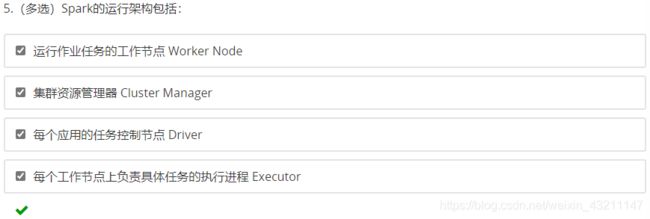
返回目录
七、Flink流批一体分布式实时处理引擎
导读
- Flink看待数据的观点是流,为什么又可以作批处理计算?
- Flink中三种时间是什么时间?每种时间作用是什么?
- Flink如何使用Watermark来解决数据乱序和延迟问题的?
Flink原理及架构
- Flink简介

- Flink关键机制
四个机制:状态,时间,检查点,窗口
- Flink核心理念

什么是状态?例如开发一套流计算的系统或者任务做数据处理,可能经常要对数据
进行统计,如Sum、Count、Min、Max,这些值是需要存储的。因为要不断更新,
这些值或者变量就可以理解为一种状态。如果数据源是在读取Kafka、RocketMQ,
可能要记录读取到什么位置,并记录Offset,这些Offset 变量都是要计算的状态。
如果通过外部去访问,如Redis,HBase,它一定是通过网络及RPC。如果通过
Flink 内部去访问,它只通过自身的进程去访问这些变量。同时Flink 会定期将这些
状态做Checkpoint 持久化,把Checkpoint 存储到一个分布式的持久化系统中,
比如HDFS。这样的话,当Flink 的任务出现任何故障时,它都会从最近的一次
Checkpoint 将整个流的状态进行恢复,然后继续运行它的流处理。对用户没有任
何数据上的影响。
- Flink Runtime整体架构
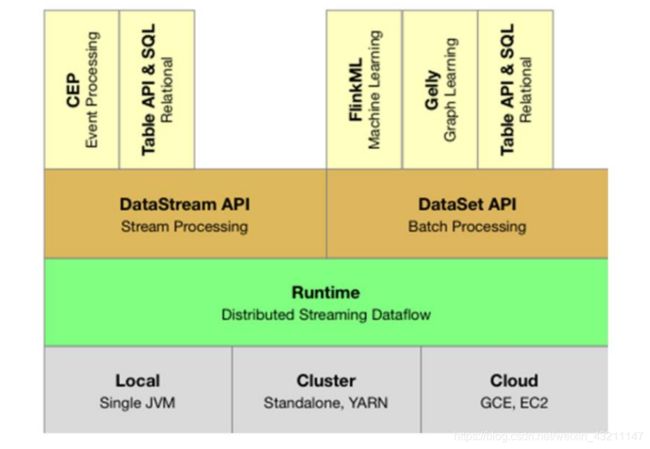
Flink是一个分层架构的系统,主要分为三层,每一层所包含的组件都提供了特定的抽象,用来服务上层组件。部署层面上,可以单机,集群,云上部署,一般YARN集群部署比较多;核心层面上,有一个分布式的流式数据处理引擎;API层面上,有流式处理API,批处理API。流式处理支持事件处理,表操作。批处理支持机器学习,图计算,也支持表操作。
Flink提供了三种部署方案local,Cluster,Cloud即:本地部署,集群部署和云部署。
Runtime层是Flink流处理以及批处理时共用的一个引擎,以JobGraph形式接收程序。JobGraph即为一个一般化的并行数据流图(data flow),它拥有任意数量的Task来接收和产生data stream。
DataStream API和DataSet API都会使用单独编译的处理方式生成JobGraph。
DataSet API使用optimizer来决定针对程序的优化方法,而DataStream API则
使用stream builder来完成该任务。
Table API:对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过SQL
的DSL对关系表进行各种查询操作,支持Java和Scala。
Libraries层对应的是Flink不同的API对应的一些功能:处理逻辑表查询的Table,
机器学习的FlinkML,图像处理的Gelly,复杂事件处理的CEP。
- Flink 核心概念 -DataStream


DataStream之间的算子操作
含有Window的是窗口操作,与后面的窗口操作相关连,之间的关系可以通过
reduce,fold,sum,max函数进行管关联。
connect:进行Stream之间的连接,可以通过flatmap,map函数进行操作。
JoinedStream :进行Stream之间的join操作,类似于数据库中的join,可
以通过join函数等进行关联。
CoGroupedStream:Stream之间的联合,类似于关系数据库中的group
操作,可以通过coGroup函数进行关联。
KeyedStream:主要是对数据流依据key进行处理,可以通过keyBy函数进
行处理。
-
Flink核心概念 - DataSet

-
Flink程序

一个程序的基本构成:
获取execution environment:执行环境StreamExecutionEnvironment是所有Flink程序的基础
创建执行环境有三种方式,分别为:
StreamExecutionEnvironment.getExecutionEnvironment
StreamExecutionEnvironment.createLocalEnvironment
StreamExecutionEnvironment.createRemoteEnvironment
- Flink数据源

- Flink程序运行图
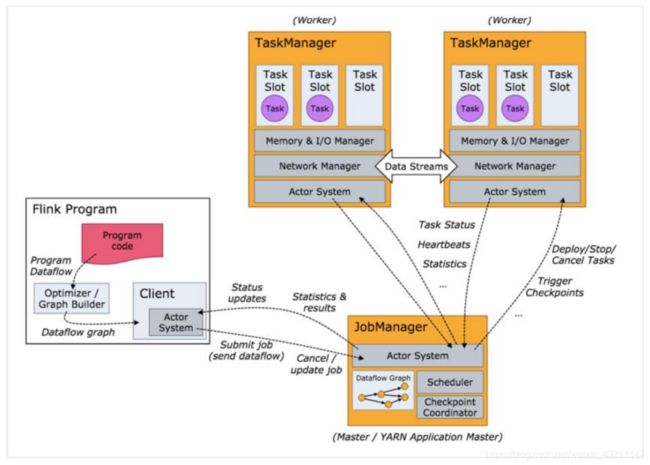
Flink是一个基于Master-Slave风格的架构,Flink集群启动时,会启动一个JobManager进程、至少一个TaskManager进程。当Flink程序提交后,会创建一个Client来进行预处理,将程序转换为一个表示完整Job的DAG,并提交到JobManager,最后JobManager将Job中的各个Task分配给TaskManager。Flink 中的计算资源通过Task Slot来定义。每个task slot 代表了TaskManager的一个固定大小的资源池。例如,一个拥有3个slot的TaskManager会将其管理的内存平均分成三分分给各个slot。将资源slot 化意味着来自不同job的task不会出现内存竞争。slot目前仅支持内存的隔离,不支持CPU隔离
Flink程序在执行的时候,会先被转化为一个Streaming Dataflows,一个Streaming Dataflow是由一组Stream和Transformation Operator组成的DAG。
- Flink作业运行流程

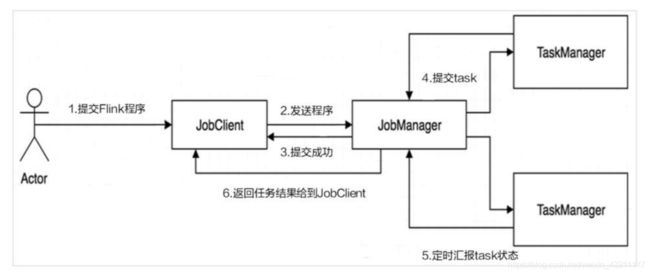
Client:Flink Client主要给用户提供向Flink系统提交用户任务(流式作业)的能力。
TaskManager:Flink系统的业务执行节点,执行具体的用户任务。TaskManager可以有多个,各个TaskManager都平等。
JobManager:Flink系统的管理节点,管理所有的TaskManager,并决策用户任务在哪些Taskmanager执行。JobManager在HA模式下可以有多个,但只有一个主JobManager。
TaskSlot(任务槽)类似yarn中的container用于资源隔离,但是该组件只包含内存资源,不包含cpu资源。每一个TaskManager当中包含3个Task Slot,TaskManager最多能同时并发执行的任务是可以控制的,那就是3个,因为不能超过slot的数量。 slot有独占的内存空间,这样在一个TaskManager中可以运行多个不同的作业,作业之间不受影响。slot之间可以共享JVM资源, 可以共享Dataset和数据结构,也可以通过多路复用(Multiplexing) 共享TCP连接和心跳消息(Heatbeat Message)。
Task任务执行的单元。

- 一个完整的Flink程序 - java
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.api.common.functions.FilterFunction;
public class Example {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Person> flintstones = env.fromElements(
new Person("Fred", 35),new Person("Wilma", 35),new Person("Pebbles", 2));
DataStream<Person> adults = flintstones.filter(new FilterFunction<Person>() {
@Override
public boolean filter(Person person) throws Exception {
return person.age >= 18;}});
adults.print();
env.execute();}
public static class Person {
public String name;public Integer age;public Person() {
};
public Person(String name, Integer age) {
this.name = name;this.age = age;};
public String toString() {
return this.name.toString() + ": age " + this.age.toStri();};}}
本示例将有关人的记录流作为输入,并对其进行过滤以仅包括成年人。env在此示例中表示执行环境,每个Flink应用程序都需要一个执行环境。流应用程序应使用StreamExecutionEnvironment。在应用程序中进行的DataStream API调用会生成一个作业图,该作业图附加到StreamExecutionEnvironment。当env.execute()被称为这个图打包,然后发送到任务管理器,这样就可以并行工作并且分片分发到任务管理器中执行。作业的每个并行切片都将在任务槽中执行。
-
Flink的数据处理
无状态计算:无状态计算会观察每个独立的事件,并且会在最后一个时间出结果,
例如一些报警和监控,一直观察每个事件,当触发警报的事件来临就会触发警告。
有状态计算:有状态的计算就会基于多个事件来输出结果,比如说计算过去一个小
时的平均温度等等。
Apache Flink 擅长处理无界和有界数据集:精确的时间控制和状态化使得 Flink
的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小
数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。 -
有界流与无界流

-
流与批处理机制


Flink的Time与Window
-
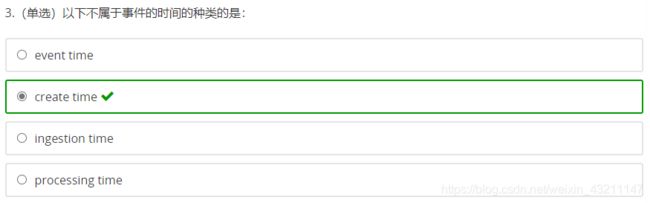
流处理中的时间分类


-
三种时间的区别
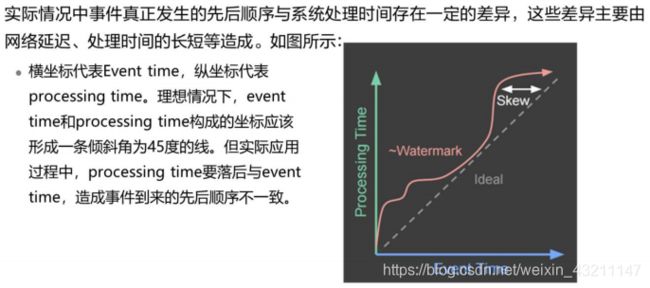
-
Window概述

-
Window类型

-
TimeWindow分类

-
滚动窗口

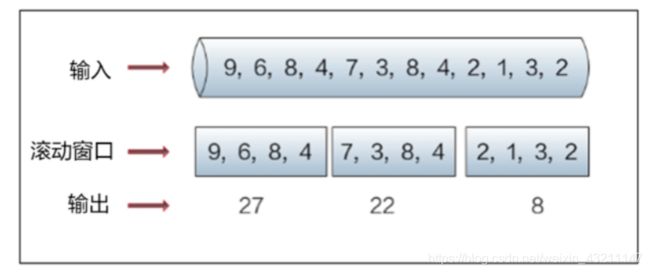
-
滑动窗口

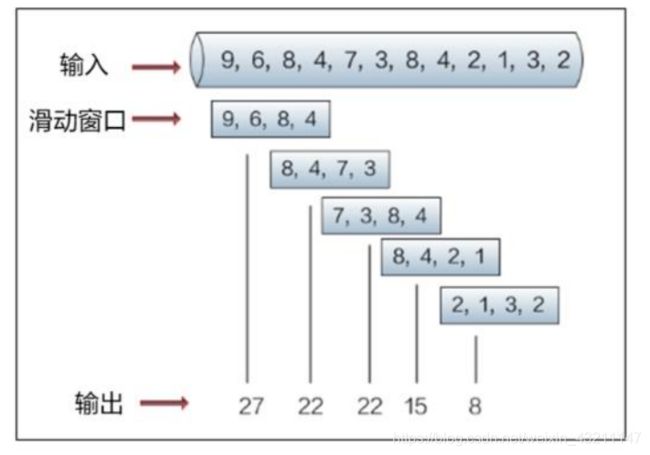
- 会话窗口


- 代码定义

Flink的Watermark
- 乱序问题


- Watermark原理

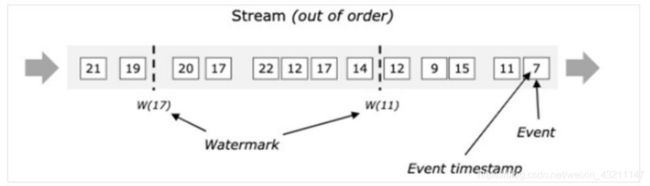




当Flink接收到每一条数据时,都会产生一条Watermark,这条Watermark就等于
当前所有到达数据中的maxEventTime - 延迟时长,也就是说,Watermark是由
数据携带的,一旦数据携带的Watermark比当前未触发的窗口的停止时间要晚,那
么就会触发相应窗口的执行。由于Watermark是由数据携带的,因此,如果运行过
程中无法获取新的数据,那么没有被触发的窗口将永远都不被触发。
上图中,我们设置的允许最大延迟到达时间为2s,所以时间戳为7s的事件对应的
Watermark是5s,时间戳为12s的事件的Watermark是10s,如果我们的窗口1是
1s5s,窗口2是6s10s,那么时间戳为7s的事件到达时的Watermarker恰好触
发窗口1,时间戳为12s的事件到达时的Watermark恰好触发窗口2。
- 延迟数据处理机制

- Side Output机制



需要注意的是,设置了 allowedLateness 之后,延迟的数据也可能触发窗口,对于 Session window 来说,可能会对窗口进行合并,产生预期外的行为。
- Allowed Lateness机制

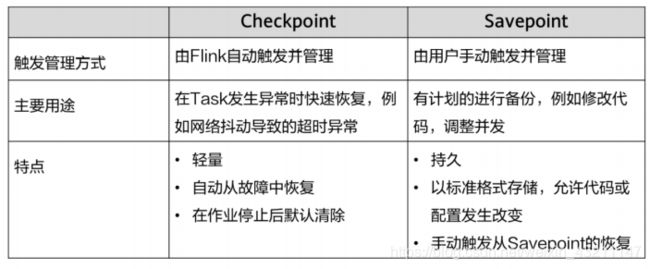
Flink的容错
- Flink容错机制

课后习题
- 思考题
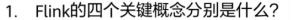
流数据的连续处理,事件时间,有状态流处理,状态快照
![]()
DataStream API和DataSet API
-
判断题


-
单选题

-
多选题

返回目录
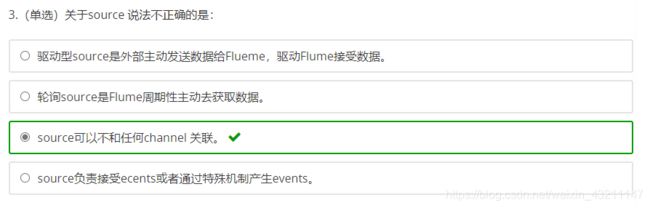
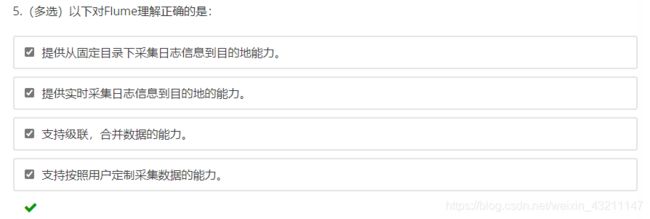
八、Flume海量日志聚合
导读

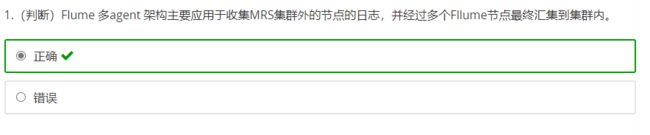
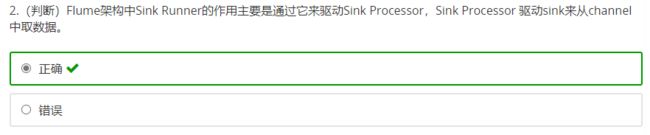
- Flume的Agent主要包括哪三个组件?
- Flume怎么保证数据传输的可靠性?
- Flume如果采用memory channel,当Agent宕机,数据会丢失吗?
Flume简介及架构
Flume关键特性介绍
Flume应用举例
课后习题

返回目录
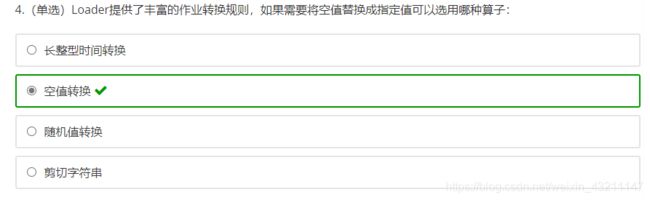
九、Loader数据转换
导读

- Loader是什么?
- Loader的架构是怎样的?
- Loader如何使用?
Loader简介
Loader作业管理
课后习题



返回目录
十、Kafka分布式信息订阅系统
导读

- 在有可能会宕机情况下,点对点消息传递模式和发布订阅消息传递模式,哪种数据更加可靠?
- Flume将消息传递给消费者与Kafka将消息传递给消费者采用模式是否相同?
- Kafka如果有多个Consumer Group是否可以订阅相同Topic中的消息?
- Kafka的Producer有哪三种ack机制?分别代表什么含义?
Kafka简介
Kafka架构与功能
Kafka数据管理
课后习题





返回目录
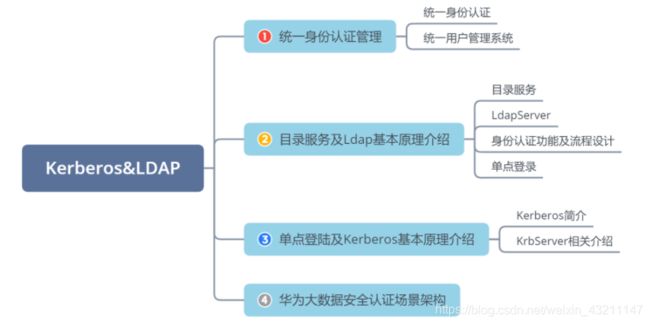
十一、LDAP Kerberos
导读
- 什么是统一身份认证?
- Kerberos和LDAP的组合如何实现数据安全?
- 华为大数据安全认证的架构?
统一身份认证管理
目录服务及Ldap基本原理介绍
单点登录及Kerberos基本原理介绍
华为大数据安全认证场景架构
课后习题





返回目录
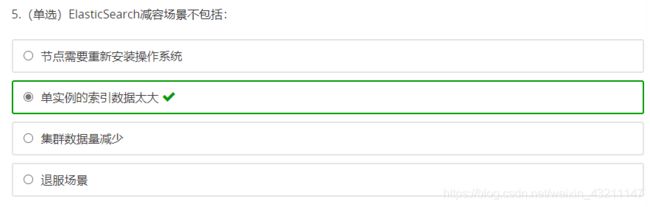
十二、分布式全文检索服务ElasticSearch
导读

- ElasticSearch的生态圈(Elastic Stack)还包含哪两个组件?
- 对于非结构化数据,也即对全文数据的搜索主要有哪两种方法?
- ElasticSearch是否需要Zookeeper进行分布式协调管理?
- ElasticSearch如何进行倒排索引?
ElasticSearch简介
ElasticSearch系统架构
ElasticSearch关键特性
课后习题




返回目录
十三、Redis内存数据库
导读
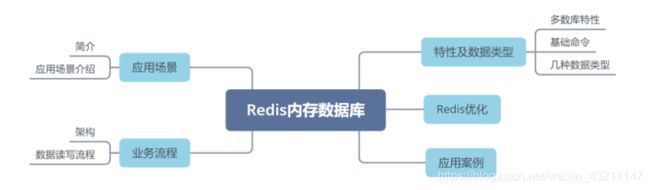
- Redisd的应用场景有哪些?
- Redis支持哪些数据结构?
- Redis性能优化的常见方法?
Redis应用场景
Redis业务流程
Redis特性及数据类型
Redis的优化
Redis的应用案例
课后习题





返回目录
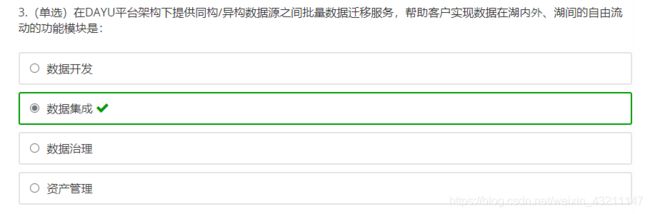
十四、华为大数据解决方案
导读

- ICT行业面临的挑战?
- 华为大数据服务都有哪些?
- 华为智能数据湖有哪些特点?
ICT行业发展趋势概述
华为大数据服务
华为数据湖服务
课后习题




返回目录
持续更新中~~~