tensorflow2学习(三):双卷积神经网络(CNN3D)高光谱图像分类
参考文章双卷积池化结构的3D-CNN高光谱遥感影像分类方法,将双卷积神经网络(CNN3D)应用与高光谱图像HSI分类,记录有亲自实现的Python源代码,环境:TF2+Python3+cuda10.1+CuDNN7.6 .
tensorflow2学习(三):双卷积神经网络(CNN3D)高光谱图像分类
一、参考资料
1. Conv3D参数
2. Keras的网络层介绍
3. keras使用入门及3D卷积神经网络资源
4 .Keras源码实例
5. 双卷积池化结构的3D-CNN高光谱遥感影像分类方法
二、网络结构
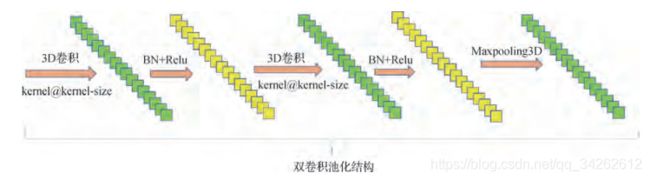
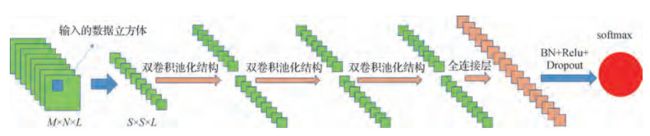
针对数据集Indian-Pines数据集设计的网络部分结构(Chanel_Last):
| Input | N * 200 * 19 * 19 * 1 |
|---|---|
| Conv3D | N * 40 * 17 * 17 * 16 |
| Conv3D(16, kernel_size=(3, 3, 3), input_shape=(200, 19, 19, 1), strides=(5, 1, 1)) | |
| Conv3D | N * 40 * 17 * 17 * 16 |
| Conv3D(16, kernel_size=(3, 3, 3), padding=‘same’) | |
| MaxPooling | N * 20 * 8 * 8 * 16 |
| MaxPooling3D(pool_size=2) | |
| Conv3D | N * 20 * 8 * 8 * 32 |
| Conv3D(32, kernel_size=(3, 3, 3), padding=‘same’)) | |
| Conv3D | N * 20 * 8 * 8 * 32 |
| Conv3D(32, kernel_size=(3, 3, 3), padding=‘same’) | |
| MaxPooling | N * 10 * 4 * 4 * 32 |
| MaxPooling3D(pool_size=2) | |
| Conv3D | N * 10 * 4 * 4 * 64 |
| Conv3D(64, kernel_size=(3, 3, 3), padding=‘same’)) | |
| Conv3D | N * 10 * 4 * 4 * 64 |
| Conv3D(64, kernel_size=(3, 3, 3), padding=‘same’) | |
| MaxPooling | N * 5 * 2 * 2 * 64 |
| MaxPooling3D(pool_size=2) |
详细结构可以参考代码部分。
三、代码
import os
from tensorflow.keras.layers import Conv3D, MaxPooling3D, Dropout, Dense, Flatten, Activation, BatchNormalization
import tensorflow as tf
from DataLoad import loadData
path_image = 'Indian-pines/Indian_pines_corrected.mat'
path_label = 'Indian-pines/Indian_pines_gt.mat'
key_image = 'indian_pines_corrected'
key_label = 'indian_pines_gt'
window_size = 19
input_size = 200
X_train_new, X_val_new, y_train_new, y_val_new, train_samples = loadData(path_image, path_label, key_image, key_label)
batch_size = 16
model = tf.keras.Sequential([
Conv3D(16, kernel_size=(3, 3, 3), input_shape=(200, 19, 19, 1), strides=(5, 1, 1)), # 17
BatchNormalization(),
Activation(tf.nn.relu),
Conv3D(16, kernel_size=(3, 3, 3), padding='same'),
BatchNormalization(),
Activation(tf.nn.relu),
MaxPooling3D(pool_size=2), # 8
Conv3D(32, kernel_size=(3, 3, 3), padding='same'),
BatchNormalization(),
Activation(tf.nn.relu),
Conv3D(32, kernel_size=(3, 3, 3), padding='same'),
BatchNormalization(),
Activation(tf.nn.relu),
MaxPooling3D(pool_size=2), # 4
Conv3D(64, kernel_size=(3, 3, 3), padding='same'),
BatchNormalization(),
Activation(tf.nn.relu),
Conv3D(64, kernel_size=(3, 3, 3), padding='same'),
BatchNormalization(),
Activation(tf.nn.relu),
MaxPooling3D(pool_size=2), # 2
Flatten(),
Dense(128),
BatchNormalization(),
Activation(tf.nn.relu),
Dropout(0.5),
Dense(16, activation=tf.nn.softmax)]
)
epoch = 100
tf.keras.backend.set_learning_phase(True)
model.compile(
optimizer=tf.keras.optimizers.RMSprop(0.0003),
loss=tf.keras.losses.categorical_crossentropy,
metrics=[tf.keras.metrics.categorical_accuracy])
model_dir = 'model/CNN6_IP2'
model_file = 'model_weights'
model_saved_path = model_dir + '/' + model_file
is_load_model = input('Would you like load the existed model weights if it exist ? y/n\n')
if is_load_model == 'y':
model.load_weights(model_saved_path)
print('An existed model_weight table has been gotten...')
else:
print('A new model will be gotten...')
print('*****************************************')
epoch = int(input('Please input epoch : '))
if epoch < 0:
epoch = 0
print('*****************************************')
if epoch != 0:
hist = model.fit(
X_train_new,
y_train_new,
batch_size=batch_size,
epochs=epoch,
shuffle=True
)
loss, acc = model.evaluate(
X_val_new,
y_val_new,
batch_size=batch_size
)
print('train: val', y_train_new.shape, y_val_new.shape)
print('acc:', acc)
if not os.path.exists(model_dir):
os.mkdir(model_dir)
model.save_weights(model_saved_path)
print('model_weights have been saved at ' + model_saved_path)
print(model.summary())
import numpy as np
import tensorflow as tf
from scipy.io import loadmat
from sklearn.model_selection import train_test_split
def loadData(path_image='Indian-pines/Indian_pines_corrected.mat',
path_label='Indian-pines/Indian_pines_gt.mat',
key_image='indian_pines_corrected',
key_label='indian_pines_gt',
window_size=19, input_size=200):
mat = loadmat(path_image)
# print(mat.keys())
features = mat[key_image]
features_shape = features.shape
mat_labels = loadmat(path_label)
labels = mat_labels[key_label]
labels = np.reshape(labels, (-1, 1))
f2 = np.zeros((labels.shape[0], window_size, window_size, input_size), dtype='float32')
parameter_b = np.array([i - window_size // 2 for i in range(window_size)])
for i in range(features_shape[0]):
for j in range(features_shape[1]):
index = i * features_shape[1] + j
for p in range(window_size):
for q in range(window_size):
f2[index][p][q] = \
features[(i + parameter_b[p]) % features_shape[0]][(j + parameter_b[q]) % features_shape[1]]
index = np.where(np.reshape(labels, (-1)) == 0)
labels = np.delete(labels, index, axis=0)
# print(np.unique(labels))
tmp = np.unique(labels)
for i in range(len(labels)):
labels[i][0] = np.where(tmp == labels[i][0])[0][0]
f2 = np.delete(f2, index, axis=0)
labels = np.reshape(labels, (-1))
dataset = [f2, labels]
(X, Y) = (dataset[0], dataset[1]) # -1,19,19,200
X = X.swapaxes(1, 3)
print('X_shape: ', X.shape)
train_set = X[:, :, :, :, np.newaxis]
print('TrainSet_shape: ', train_set.shape)
classes = 16
Y = tf.keras.utils.to_categorical(Y, classes)
train_set = train_set.astype('float32')
train_set -= np.mean(train_set)
train_set /= np.max(train_set)
# Split the data
X_train_new, X_val_new, y_train_new, y_val_new = train_test_split(train_set, Y, test_size=0.8, random_state=4)
return X_train_new, X_val_new, y_train_new, y_val_new, labels.shape[0]