鸿蒙内核源码分析(物理内存篇) | 伙伴算法很像在卖标准猪肉块 | 给HarmonyOS源码加上中文注释 | v17.01
鸿蒙内核源码注释中文版 【 Gitee仓 | CSDN仓 | Github仓 | Coding仓 】项目中文注解鸿蒙官方内核源码,详细阐述鸿蒙架构和代码设计细节,精读内核源码最大的好处是:将孤立知识点织成一张高浓度,高密度底层网,对计算机体系化理解形成永久记忆,从此高屋建瓴分析/解决问题.
鸿蒙源码分析系列篇 【 CSDN | OSCHINA | WIKI 】 从 HarmonyOS 架构层视角整理成文, 并首创用生活场景讲故事的方式试图去解构内核,一窥究竟。
鸿蒙内核源码详细结构,内核知识500问 >> 进入阅读源码
如何初始化物理内存?
鸿蒙内核物理内存采用了段页式管理,先看两个主要结构体.结构体的每个成员变量的含义都已经注解出来,请结合源码理解.
#define VM_LIST_ORDER_MAX 9 //伙伴算法分组数量,从 2^0,2^1,...,2^8 (256*4K)=1M
#define VM_PHYS_SEG_MAX 32 //最大支持32个段
typedef struct VmPhysSeg {//物理段描述符
PADDR_T start; /* The start of physical memory area */ //物理内存段的开始地址
size_t size; /* The size of physical memory area */ //物理内存段的大小
LosVmPage *pageBase; /* The first page address of this area */ //本段首个物理页框地址
SPIN_LOCK_S freeListLock; /* The buddy list spinlock */ //伙伴算法自旋锁,用于操作freeList上锁
struct VmFreeList freeList[VM_LIST_ORDER_MAX]; /* The free pages in the buddy list */ //伙伴算法的分组,默认分成10组 2^0,2^1,...,2^VM_LIST_ORDER_MAX
SPIN_LOCK_S lruLock; //用于置换的自旋锁,用于操作lruList
size_t lruSize[VM_NR_LRU_LISTS]; //5个双循环链表大小,如此方便得到size
LOS_DL_LIST lruList[VM_NR_LRU_LISTS]; //页面置换算法,5个双循环链表头,它们分别描述五中不同类型的链表
} LosVmPhysSeg;
//注意: vmPage 中并没有虚拟地址,只有物理地址
typedef struct VmPage { //物理页框描述符
LOS_DL_LIST node; /**< vm object dl list */ //虚拟内存节点,通过它挂/摘到全局g_vmPhysSeg[segID]->freeList[order]物理页框链表上
UINT32 index; /**< vm page index to vm object */ //索引位置
PADDR_T physAddr; /**< vm page physical addr */ //物理页框起始物理地址,只能用于计算,不会用于操作(读/写数据==)
Atomic refCounts; /**< vm page ref count */ //被引用次数,共享内存会被多次引用
UINT32 flags; /**< vm page flags */ //页标签,同时可以有多个标签(共享/引用/活动/被锁==)
UINT8 order; /**< vm page in which order list */ //被安置在伙伴算法的几号序列( 2^0,2^1,2^2,...,2^order)
UINT8 segID; /**< the segment id of vm page */ //所属段ID
UINT16 nPages; /**< the vm page is used for kernel heap */ //分配页数,标识从本页开始连续的几页将一块被分配
} LosVmPage;//注意:关于nPages和order的关系说明,当请求分配为5页时,order是等于3的,因为只有2^3才能满足5页的请求理解它们是理解物理内存管理的关键,尤其是 LosVmPage ,鸿蒙内存模块代码通篇都能看到它的影子.内核默认最大允许管理32个段.
段页式管理简单说就是先将物理内存切成一段段,每段再切成单位为 4K 的物理页框, 页是在内核层的操作单元, 物理内存的分配,置换,缺页,内存共享,文件高速缓存的读写,都是以页为单位的,所以LosVmPage 很重要,很重要!
结构体的每个变量代表了一个个的功能点, 例如:LosVmPhysSeg.freeList[order].node,就是伙伴算法的各组块双向循环链表(LOS_DL_LIST), LOS_DL_LIST是整个鸿蒙内核最重要的结构体,在系列篇开篇就专门讲过它的重要性.
再比如 LosVmPage.refCounts 页被引用的次数,可理解被进程拥有的次数,当refCounts大于1时,被多个进程所拥有,说明这页就是共享页.当等于0时,说明没有进程在使用了,这时就可以被释放了.
看到这里熟悉JAVA的同学是不是似曾相识,这像是Java的内存回收机制.在内核层面,引用的概念不仅仅适用于内存模块,也适用于其他模块,比如文件/设备模块,同样都存在共享的场景.这些模块不在这里展开说,后续有专门的章节细讲.
段一开始是怎么划分的 ? 需要方案提供商手动配置,存在静态的全局变量中,鸿蒙默认只配置了一段.
struct VmPhysSeg g_vmPhysSeg[VM_PHYS_SEG_MAX];//物理段数组,最大32段
INT32 g_vmPhysSegNum = 0; //总段数
LosVmPage *g_vmPageArray = NULL;//物理页框数组
size_t g_vmPageArraySize;//总物理页框数
/* Physical memory area array */
STATIC struct VmPhysArea g_physArea[] = {//这里只有一个区域,即只生成一个段
{
.start = SYS_MEM_BASE, //整个物理内存基地址,#define SYS_MEM_BASE DDR_MEM_ADDR , 0x80000000
.size = SYS_MEM_SIZE_DEFAULT,//整个物理内存总大小 0x07f00000
},
};有了段和这些全局变量,就可以对内存初始化了. OsVmPageStartup 是对物理内存的初始化, 它被整个系统内存初始化 OsSysMemInit所调用. 直接上代码.
/******************************************************************************
完成对物理内存整体初始化,本函数一定运行在实模式下
1.申请大块内存g_vmPageArray存放LosVmPage,按4K一页划分物理内存存放在数组中.
******************************************************************************/
VOID OsVmPageStartup(VOID)
{
struct VmPhysSeg *seg = NULL;
LosVmPage *page = NULL;
paddr_t pa;
UINT32 nPage;
INT32 segID;
OsVmPhysAreaSizeAdjust(ROUNDUP((g_vmBootMemBase - KERNEL_ASPACE_BASE), PAGE_SIZE));//校正 g_physArea size
nPage = OsVmPhysPageNumGet();//得到 g_physArea 总页数
g_vmPageArraySize = nPage * sizeof(LosVmPage);//页表总大小
g_vmPageArray = (LosVmPage *)OsVmBootMemAlloc(g_vmPageArraySize);//实模式下申请内存,此时还没有初始化MMU
OsVmPhysAreaSizeAdjust(ROUNDUP(g_vmPageArraySize, PAGE_SIZE));//
OsVmPhysSegAdd();// 完成对段的初始化
OsVmPhysInit();// 加入空闲链表和设置置换算法,LRU(最近最久未使用)算法
for (segID = 0; segID < g_vmPhysSegNum; segID++) {//遍历物理段,将段切成一页一页
seg = &g_vmPhysSeg[segID];
nPage = seg->size >> PAGE_SHIFT;//本段总页数
for (page = seg->pageBase, pa = seg->start; page <= seg->pageBase + nPage;//遍历,算出每个页框的物理地址
page++, pa += PAGE_SIZE) {
OsVmPageInit(page, pa, segID);//对物理页框进行初始化,注意每页的物理地址都不一样
}
OsVmPageOrderListInit(seg->pageBase, nPage);//伙伴算法初始化,将所有页加入空闲链表供分配
}
}结合中文注释,代码很好理解, 此番操作之后全局变量里的值就都各就各位了,可以开始工作了.
如何分配/回收物理内存? 答案是伙伴算法
伙伴算法系列篇中有说过好几篇,这里再看图理解下什么伙伴算法,伙伴算法注重物理内存的连续性,注意是连续性!
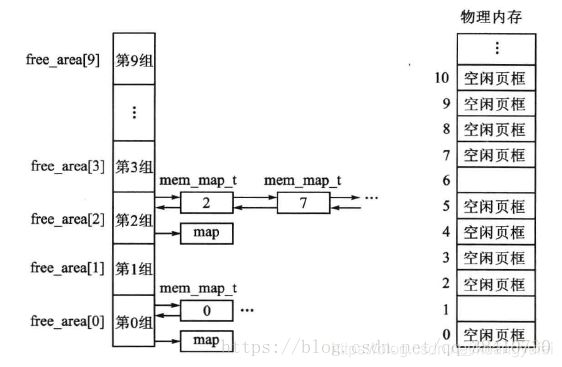
结合图比如,要分配4(2^2)页(16k)的内存空间,算法会先从free_area[2]中查看nr_free是否为空,如果有空闲块,则从中分配,如果没有空闲块,就从它的上一级free_area[3](每块32K)中分配出16K,并将多余的内存(16K)加入到free_area[2]中去。如果free_area[3]也没有空闲,则从更上一级申请空间,依次递推,直到free_area[max_order],如果顶级都没有空间,那么就报告分配失败。
释放是申请的逆过程,当释放一个内存块时,先在其对于的free_area链表中查找是否有伙伴存在,如果没有伙伴块,直接将释放的块插入链表头。如果有或板块的存在,则将其从链表摘下,合并成一个大块,然后继续查找合并后的块在更大一级链表中是否有伙伴的存在,直至不能合并或者已经合并至最大块2^max_order为止。
看过系列篇文章的可能都发现了,笔者喜欢用讲故事和打比方来说明内核运作机制, 为了更好的理解,同样打个比方, 笔者认为伙伴算法很像是卖标准猪肉块的算法.
物理内存是一整头猪,已经切成了1斤1斤的了,但是还都连在一起,每一斤上都贴了个标号, 而且老板只按 1斤(2^0), 2斤(2^1), 4斤(2^2),...256斤(2^8)的方式来卖.售货柜上分成了9组
张三来了要7斤猪肉,怎么办? 给8斤,注意是给8斤啊 ,因为它要严格按它的标准来卖. 张三如果归还了,查看现有8斤组里有没有序号能连在一块的,有的话2个8斤合成16斤,放到16斤组里去. 如果没有这8斤猪肉将挂到上图中第2组(2^3)再卖.
大家脑海中有画面了吗? 那么问题来了,它为什么要这么卖猪肉,好处是什么? 简单啊:至少两个好处:
第一:卖肉速度快,效率高,标准化的东西最好卖了.
第二:可防止碎肉太多,后面的人想买大块的猪肉买不到了. 请仔细想想是不是这样的?如果每次客户来了要多少就割多少出去,运行一段时候后你还能买到10斤连在一块的猪肉吗? 很可能给是一包碎肉,里面甚至还有一两一两的边角肉,碎肉的结果必然是管理麻烦,效率低啊.如果按伙伴算法的结果是运行一段时候后,图中0,1,2各组中都有可卖的猪肉啊,张三哥归还了那8斤(其实他指向要7斤)猪肉,王五兄弟来了要6斤,直接把张三哥归还的给王五就行了.效率极高.
那么问题又来了,凡事总有两面性,它的坏处是什么? 也简单啊 :至少两个坏处:
第一:浪费了!,白给的三斤对王五没用啊,浪费的问题有其他办法解决,但不是在这个层面去解决,而是由 slab分配器解决,这里不重点说后续会专门讲slab分配器是如何解决这个问题的.
第二:合并要求太严格了,一定得是伙伴(连续)才能合并成更大的块.这样也会导致时间久了很难有大块的连续性的猪肉块.
比方打完了,鸿蒙内核是如何实现卖肉算法的呢? 请看代码
LosVmPage *OsVmPhysPagesAlloc(struct VmPhysSeg *seg, size_t nPages)
{
struct VmFreeList *list = NULL;
LosVmPage *page = NULL;
UINT32 order;
UINT32 newOrder;
if ((seg == NULL) || (nPages == 0)) {
return NULL;
}
//因为伙伴算法分配单元是 1,2,4,8 页,比如nPages = 3时,就需要从 4号空闲链表中分,剩余的1页需要劈开放到1号空闲链表中
order = OsVmPagesToOrder(nPages);//根据页数计算出用哪个块组
if (order < VM_LIST_ORDER_MAX) {//order不能大于9 即:256*4K = 1M 可理解为向内核堆申请内存一次不能超过1M
for (newOrder = order; newOrder < VM_LIST_ORDER_MAX; newOrder++) {//没有就找更大块
list = &seg->freeList[newOrder];//从最合适的块处开始找
if (LOS_ListEmpty(&list->node)) {//理想情况链表为空,说明没找到
continue;//继续找更大块的
}
page = LOS_DL_LIST_ENTRY(LOS_DL_LIST_FIRST(&list->node), LosVmPage, node);//找第一个节点就行,因为链表上挂的都是同样大小物理页框
goto DONE;
}
}
return NULL;
DONE:
OsVmPhysFreeListDelUnsafe(page);//将物理页框从链表上摘出来
OsVmPhysPagesSpiltUnsafe(page, order, newOrder);//将物理页框劈开,把用不了的页再挂到对应的空闲链表上
return page;
}
/******************************************************************************
本函数很像卖猪肉的,拿一大块肉剁,先把多余的放回到小块肉堆里去.
oldOrder:原本要买 2^2肉
newOrder:却找到个 2^8肉块
******************************************************************************/
STATIC VOID OsVmPhysPagesSpiltUnsafe(LosVmPage *page, UINT8 oldOrder, UINT8 newOrder)
{
UINT32 order;
LosVmPage *buddyPage = NULL;
for (order = newOrder; order > oldOrder;) {//把肉剁碎的过程,把多余的肉块切成2^7,2^6...标准块,
order--;//越切越小,逐一挂到对应的空闲链表上
buddyPage = &page[VM_ORDER_TO_PAGES(order)];//@note_good 先把多余的肉割出来,这句代码很赞!因为LosVmPage本身是在一个大数组上,page[nPages]可直接定位
LOS_ASSERT(buddyPage->order == VM_LIST_ORDER_MAX);//没挂到伙伴算法对应组块空闲链表上的物理页框的order必须是VM_LIST_ORDER_MAX
OsVmPhysFreeListAddUnsafe(buddyPage, order);//将劈开的节点挂到对应序号的链表上,buddyPage->order = order
}
}为了方便理解代码细节, 这里说一种情况: 比如三哥要买3斤的,发现4斤,8斤的都没有了,只有16斤的怎么办? 注意不会给16斤,只会给4斤.这时需要把肉劈开,劈成 8,4,4,4斤给张三哥,剩下的8,4挂到链表上.
OsVmPhysPagesSpiltUnsafe干的就是劈猪肉的活.
伙伴算法的链表是怎么初始化的,再看段代码
//初始化空闲链表,分配物理页框使用伙伴算法
STATIC INLINE VOID OsVmPhysFreeListInit(struct VmPhysSeg *seg)
{
int i;
UINT32 intSave;
struct VmFreeList *list = NULL;
LOS_SpinInit(&seg->freeListLock);//初始化用于分配的自旋锁
LOS_SpinLockSave(&seg->freeListLock, &intSave);
for (i = 0; i < VM_LIST_ORDER_MAX; i++) {//遍历伙伴算法空闲块组链表
list = &seg->freeList[i]; //一个个来
LOS_ListInit(&list->node); //LosVmPage.node将挂到list->node上
list->listCnt = 0; //链表上的数量默认0
}
LOS_SpinUnlockRestore(&seg->freeListLock, intSave);
}
系列篇文章 进入 >> 鸿蒙系统源码分析(总目录) 【 CSDN | OSCHINA | WIKI 】查看
注释中文版 进入 >> 鸿蒙内核源码注释中文版 【 Gitee仓 | CSDN仓 | Github仓 | Coding仓 】阅读
内容仅代表个人观点,会反复修正,出精品注解,写精品文章,一律原创,转载需注明出处,不修改内容,不乱插广告,错漏之处欢迎指正笔者第一时间加以完善