飞桨论文复现之U-GAT-IT
U-GAT-IT
这是一篇对U-GAT-IT论文的个人解读U-GAT-IT, 飞桨论文复现课程
ABSTRACT
提出了一种新的无监督图像到图像转换方法,它以端到端的方式结合了新的注意力模块和新的可学习的归一化功能.注意模块引导模型基于辅助分类器获得的关注图来关注区分源域和目标域的更重要区域.与先前基于注意力的方法不同,这些方法无法处理域之间的几何变化,新提出的模型可以转换存在大幅度变化的图像.此外,新的AdaLIN(自适应图层实例标准化)功能可帮助注意力引导模型根据数据集通过学习参数灵活地控制形状和纹理的变化量.实验结果表明,与现有的具有固定网络架构和超参数的现有模型相比,该方法具有优越性.
INTRODUCTION
图像到图像转换旨在学习一个在两个不同域里映射图像的函数, 其应用包括image inpainting(图像修复), super resolution(超分辨率), colorization(图像着色)和style transfer(风格迁移)
近年来围绕GAN实现图像转换的研究非常多,比如CycleGAN, UNIT, MUNIT, DRIT, FUNIT, SPADE.但这些方法仍有性能上的差异,具体取决于域间形状和纹理的变化量上.比如,它们可以很好完成纹理的映射但对于形状变化较大的时候就显得力不从心.因此通常需要一些预处理操作,图像裁剪和对齐来限制数据的分布.U-GAT-IT正是为了实现这种多任务下鲁棒性能设计的.
U-GAT-IT的贡献在于提出
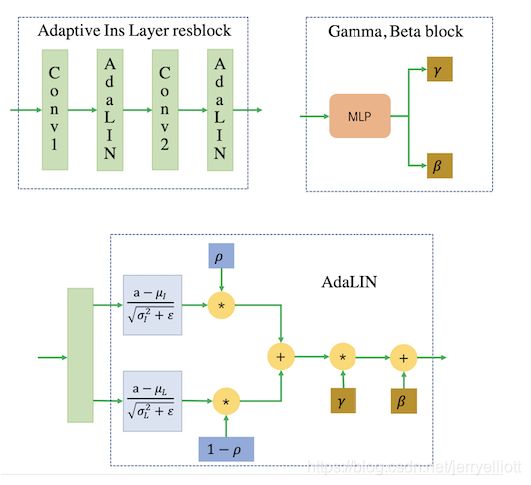
- 引入注意力机制, 这里的注意力机制采用全局和平均池化下的类激活图(CAM, Class Activation Map)来实现的,CAM如图所示.

2. 提出了自适应图层实例归一化(AdaLIN, Adaptive Layer Instance Normalization), 自适应图层实例归一化的参数是在训练期间通过在实例归一化(IN)和图层归一化(LN)之间选择合适的比率从数据集中学习的,其作用是帮助注意力机制引导模型灵活控制形状和纹理的变化量.
MODEL
整个模型框架中包含两个生成器和两个判别器,在生成器和判别器部分均加入了attention模块.模型基于辅助分类器获得注意力图,通过区分源域和目标域,指导转换专注于更重要的区域,而忽略次要区域.这些注意力图在生成器和判别器中都有嵌入来专注于重要的语义区域,促进形状变换.生成器中的注意力图引起对专门区分这两个域的区域的关注,而鉴别器中的注意力图则通过关注目标域中真实图像和伪图像之间的差异来帮助进行微调.因此,无需修改模型架构或超参数,就可以完成变化较大的image translation任务.下面具体介绍生成器和判别器.
生成器
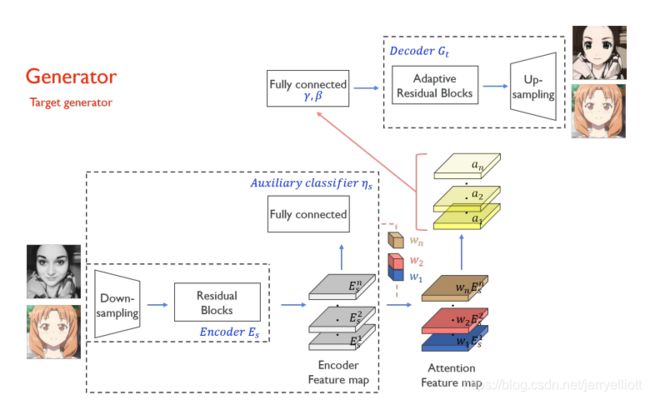
首先图像经过一个下采样模块,然后经过一个残差块,得到编码后的特征图,编码后的特征图分两路,一路是通过一个辅助分类器,得到有每个特征图的权重信息,然后与另外一路编码后的特征图相乘,得到有注意力的特征图.注意力特征图依然是分两路,一路经过一个1x1卷积和激活函数层得到黄色的a1…an特征图,然后黄色特征图通过全连接层得到解码器中 Adaptive Layer-Instance Normalization层的gamma和beta,另外一路作为解码器的输入,经过一个自适应的残差块(含有Adaptive Layer-Instance Normalization)以及上采样模块得到生成结果.
这里讲一下AdaLIN的具体公式:
![]()
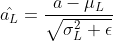
![]()
![]()
AdaIN能很好的将内容特征转移到样式特征上,但AdaIN假设特征通道之间不相关,意味着样式特征需要包括很多的内容模式,而LN则没有这个假设,但LN不能保持原始域的内容结构,因为LN考虑的是全局统计信息,所以作者将AdaIN和LN结合起来,结合两者的优势,有选择地保留或改变内容信息,有助于解决广泛的图像到图像的翻译问题.
生成器总结:
- 编码器中没有采用AdaILN以及ILN,而且只采用了IN,原文给出了解释:在分类问题中,LN的性能并不比批归一化好,由于辅助分类器与生成器中的编码器连接,为了提高辅助分类器的精度,使用实例归一化(批归一化,小批量大小为1)代替AdaLIN;
- 使用类别激活图(CAM)来得到注意力权重;
- 通过注意力特征图得到解码器中AdaILN的gamma和beta;
- 解码器中残差块使用的AdaILN,而其他块使用的是ILN;
- 使用镜像填充,而不是0填充;
- 所有激活函数使用的是RELU.
判别器
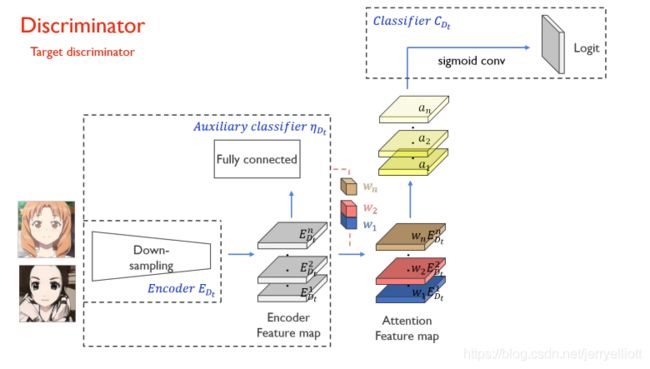
具体结构与生成器类似,判别器的设计采用一个全局判别器(Global Discriminator)以及一个局部判别器(Local Discriminator)结合实现,所谓的全局判别器和局部判别器的区别就在于全局判别器对输入的图像进行了更深层次的特征压缩.在判别器中也加入了 CAM 模块,虽然在判别器下 CAM 并没有做域的分类,但是加入注意力模块对于判别图像真伪是有益的,文中给出的解释是注意力图通过关注目标域中的真实图像和伪图像之间的差异来帮助进行微调.
损失函数
损失函数总共有四个,分别是Adversarial loss, Cycle loss, Identity loss和CAM loss.
Adversarial loss: ![]()
Cycle loss: ![]()
Identity loss: ![]()
CAM loss: ![]()
![]()