简介
Spark Streaming是Spark Core的扩展,是构建于Spark Core之上的实时流处理系统。相对于其他实时流处理系统,Spark Streaming最大的优势在于其位于Spark技术栈中,也即流处理引擎与数据处理引擎在同一个软件栈中。在Spark Streaming中,数据的采集是以逐条方式,而数据处理是按批进行的。因此,其系统吞吐量会比流行的纯实时流处理引擎Storm高2~5倍。
Spark Streaming对流数据处理的过成大致可以分为:启动流处理引擎、接收和存储流数据、处理流数据和输出处理结果等四个步骤。其运行架构图如下所示:
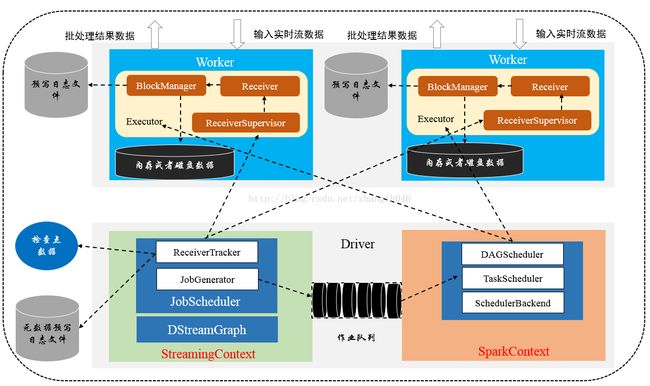
Step1 启动流处理引擎
StreamingContext为Spark Streaming在Driver端的上下文,是spark streaming程序的入口。在该对象的启 动过程中,会初始化其内部的组件,其中最为重要的是DStreamGraph以及JobScheduler组件的初始化。
class StreamingContext private[streaming] (
_sc: SparkContext,
_cp: Checkpoint,
_batchDur: Duration
) extends Logging {
...
private[streaming] val conf = sc.conf
private[streaming] val env = sc.env
private[streaming] val graph: DStreamGraph = {
if (isCheckpointPresent) {
_cp.graph.setContext(this)
_cp.graph.restoreCheckpointData()
_cp.graph
} else {
require(_batchDur != null, "Batch duration for StreamingContext cannot be null")
val newGraph = new DStreamGraph()
newGraph.setBatchDuration(_batchDur)
newGraph
}
}
...
private[streaming] val scheduler = new JobScheduler(this)
...
}
Spark Streaming中作业的生成方式类似Spark核心,对DStream进行的各种操作让他们之间构建起依赖关系,DStreamGraph记录了DStream之间的依赖关系等信息。
JobScheduler是Spark Streaming的Job总调度者。JobScheduler 有两个非常重要的成员:JobGenerator 和 ReceiverTracker。JobGenerator维护一个定时器,定时为每个 batch 生成RDD DAG的实例;ReceiverTracker负责启动、管理各个 receiver及管理各个receiver 接收到的数据。
通过调用StreamingContext#start()方法启动流处理引擎。在StreamingContext#start()中,调用StreamingContext#validate()方法对DStreamGraph及checkpoint等做有效性检查,然后启动新的线程设置SparkContext,并启动JobScheduler。
def start(): Unit = synchronized {
...
validate()
ThreadUtils.runInNewThread("streaming-start") {
sparkContext.setCallSite(startSite.get)
sparkContext.clearJobGroup()
sparkContext.setLocalProperty(SparkContext.SPARK_JOB_INTERRUPT_ON_CANCEL, "false")
savedProperties.set(SerializationUtils.clone(sparkContext
.localProperties.get()))
scheduler.start()
}
state = StreamingContextState.ACTIVE
StreamingContext.setActiveContext(this)
...
}
Step2 接收与存储流数据
JobScheduler启动时,会创建一个新的 ReceiverTracker 实例 receiverTracker,并调用其start() 方法。在ReceiverTracker #start()中会初始化一个endpoint: ReceiverTrackerEndpoint对象,该对象用于接收和处理ReceiverTracker和 receivers之间 发送的消息。此外,在ReceiverTracker#start()中还会调用 launchReceivers 将各个receivers 分发到 executors 上。
def start(): Unit = synchronized {
if (isTrackerStarted) {
throw new SparkException("ReceiverTracker already started")
}
if (!receiverInputStreams.isEmpty) {
endpoint = ssc.env.rpcEnv.setupEndpoint(
"ReceiverTracker", new ReceiverTrackerEndpoint(ssc.env.rpcEnv))
if (!skipReceiverLaunch) launchReceivers()
logInfo("ReceiverTracker started")
trackerState = Started
}
}
ReceiverTracker#launchReceivers()会从DStreamGraph.inputStreams 中抽取出receivers,也即数据接收器。得到receivers后,给消息接收处理器 endpoint 发送 StartAllReceivers(receivers)消息。
private def launchReceivers(): Unit = {
val receivers = receiverInputStreams.map { nis =>
val rcvr = nis.getReceiver()
rcvr.setReceiverId(nis.id)
rcvr
}
runDummySparkJob()
logInfo("Starting " + receivers.length + " receivers")
endpoint.send(StartAllReceivers(receivers))
}
endpoint在接收到消息后,首先会判别消息的类型,对不同的消息执行不同的处理操作。当收到StartAllReceivers类型的消息时,首先会计算每一个receiver要发送的目的executors,其计算主要遵循两条原则:一是尽可能的使receiver分布均匀;二是如果receiver本身的preferredLocation不均匀,则以preferredLocation为准。然后遍历每一个receiver,根据计算出的executors调用startReceiver方法来启动receivers。
case StartAllReceivers(receivers) =>
val scheduledLocations = schedulingPolicy.scheduleReceivers(receivers, getExecutors)
for (receiver <- receivers) {
val executors = scheduledLocations(receiver.streamId)
updateReceiverScheduledExecutors(receiver.streamId, executors)
receiverPreferredLocations(receiver.streamId) = receiver.preferredLocation
startReceiver(receiver, executors)
}
由于ReceiverInputDStream实例只有一个receiver,但receiver可能需要在多个worker上启动线程来接收数据,因此在startReceiver中需要将receiver及其对应的目的excutors转换成RDD。
val receiverRDD: RDD[Receiver[_]] =
if (scheduledLocations.isEmpty) {
ssc.sc.makeRDD(Seq(receiver), 1)
} else {
val preferredLocations = scheduledLocations.map(_.toString).distinct
ssc.sc.makeRDD(Seq(receiver -> preferredLocations))
}
转换为RDD后,需要把receiver所进行的计算定义为startReceiverFunc函数,该函数以receiver实例为参数构造ReceiverSupervisorImpl实例supervisor,构造完毕后使用新线程启动该supervisor并阻塞该线程。
val supervisor = new ReceiverSupervisorImpl(
receiver, SparkEnv.get, serializableHadoopConf.value, checkpointDirOption)
supervisor.start()
supervisor.awaitTermination()
最后,将receiverRDD以及要在receiverRDD上执行的函数作为Job提交,以真正在各个executors上启动Receiver。Job执行后将会持续的进行数据的接收。
val future = ssc.sparkContext.submitJob[Receiver[_], Unit, Unit](
receiverRDD, startReceiverFunc, Seq(0), (_, _) => Unit, ())
Receiver源源不断的接收到实时流数据后,根据接收数据的大小进行判断,若数据量很小,则会聚集多条数据成一块,然后进行块存储;若数据量很大,则直接进行块存储。对于这些数据,Receiver会直接交由ReceiverSupervisor,由其进行数据的转储操作。配置参数spark.streaming.receiver.writeAheadLog.enable的值决定是否预写日志。根据参数值会产生不同类型的存储receivedBlockHandler对象。
private val receivedBlockHandler: ReceivedBlockHandler = {
if (WriteAheadLogUtils.enableReceiverLog(env.conf)) {
//先写 WAL,再存储到 executor 的内存或硬盘
new WriteAheadLogBasedBlockHandler(env.blockManager, receiver.streamId,
receiver.storageLevel, env.conf, hadoopConf, checkpointDirOption.get)
} else {
//直接存到 executor 的内存或硬盘
new BlockManagerBasedBlockHandler(env.blockManager, receiver.storageLevel)
}
}
根据receivedBlockHandler进行块存储。将 block 存储之后,会获得 block 描述信息 blockInfo:ReceivedBlockInfo,这其中包含:streamId、数据位置、数据条数、数据 size 等信息。接着,封装以 block 作为参数的 AddBlock(blockInfo) 消息并发送给 ReceiverTracker 以通知其有新增 block 数据块。
//调用 receivedBlockHandler.storeBlock 方法存储 block,并得到一个 blockStoreResult
val blockStoreResult = receivedBlockHandler.storeBlock(blockId, receivedBlock)
//使用blockStoreResult初始化一个ReceivedBlockInfo实例
val blockInfo = ReceivedBlockInfo(streamId, numRecords, metadataOption, blockStoreResult)
//发送消息通知 ReceiverTracker 新增并存储了 block
trackerEndpoint.askWithRetry[Boolean](AddBlock(blockInfo))
ReceiverTracker再把这些信息转发给ReceivedBlockTracker,由其负责管理收到数据块元信息。
private def addBlock(receivedBlockInfo: ReceivedBlockInfo): Boolean = {
receivedBlockTracker.addBlock(receivedBlockInfo)
}
step3 处理流数据
JobScheduler中有两个主要的成员,一个是上文提到的ReceiverTracker,另一个则是JobGenerator 。在JobScheduler启动时,会创建一个新的 JobGenerator 实例 jobGenerator,并调用其start() 方法。在 JobGenerator 的主构造函数中,会创建一个定时器:
private val timer = new RecurringTimer(clock, ssc.graph.batchDuration.milliseconds,
longTime => eventLoop.post(GenerateJobs(new Time(longTime))), "JobGenerator")
定时器中定义了批处理时间间隔ssc.graph.batchDuration.milliseconds。每当批处理时间到来时,会执行一次eventLoop.post(GenerateJobs(new Time(longTime)))方法来向 eventLoop 发送 GenerateJobs(new Time(longTime))消息,eventLoop收到消息后会基于当前batch内的数据进行Job的生成及提交执行。
private def generateJobs(time: Time) {
// Checkpoint all RDDs marked for checkpointing to ensure their lineages are
// truncated periodically. Otherwise, we may run into stack overflows (SPARK-6847).
ssc.sparkContext.setLocalProperty(RDD.CHECKPOINT_ALL_MARKED_ANCESTORS, "true")
Try {
// allocate received blocks to batch
jobScheduler.receiverTracker.allocateBlocksToBatch(time)
// generate jobs using allocated block
graph.generateJobs(time)
} match {
case Success(jobs) =>
val streamIdToInputInfos = jobScheduler.inputInfoTracker.getInfo(time)
jobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos))
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time, e)
PythonDStream.stopStreamingContextIfPythonProcessIsDead(e)
}
eventLoop.post(DoCheckpoint(time, clearCheckpointDataLater = false))
}
由源码可知,eventLoop 在接收到 GenerateJobs(new Time(longTime))消息后首先调用了allocateBlocksToBatch()方法将已收到的blocks分配给batch。紧接着调用DStreamGraph类中的generateJobs()方法来生成基于该batch的Job序列。然后将批处理时间time、作业序列Seq[Job]和本批次数据的源信息包装为JobSet,调用JobScheduler.submitJobSet(JobSet)提交给JobScheduler,JobScheduler将这些作业发送给Spark核心进行处理。
Step4 输出处理结果
由于数据的处理有Spark核心来完成,因此处理的结果会从Spark核心中直接输出至外部系统,如数据库或者文件系统等,同时输出的数据也可以直接被外部系统所使用。由于实时流数据的数据源源不断的流入,Spark会周而复始的进行数据的计算,相应也会持续输出处理结果。