几乎每家公司都有自己的大数据平台, 数据平台的权限管理是个要想清楚的事情, 在确定好权限管理的策略前, 可以先聊聊权限管理可以从哪里入手, 这个东西也是分成几个层的.
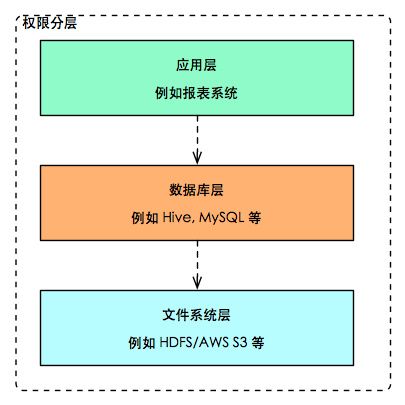
文件系统层面
类似 Hive 这样的数据平台, 所有的数据都存储在分布式文件系统上(例如 HDFS 或者 类似 AWS S3 的对象存储系统), 那么我们就可以在这个层面进行权限的控制, 例如使用 HDFS 的文件权限模型, 或者使用 AWS IAM 的权限进行控制. 但这种方式有几点不足:
- 权限只有在执行数据读取或者写入的阶段才会告知用户没有权限而报错, 用户体验不好
- 用户是可以看到数据的 Meta 信息的, 例如 Table 的 column 信息等.
- AWS EMR 中不支持一个 EMR cluster 中使用多个 InstanceProfile, 因此无法做到一个集群中执行计算的不同用户能够使用不同的 AWS Credential, 进而无法从这个层面控制权限. 一种解决方案是针对不同的用户使用不同的 EMR 集群提交计算任务, 这种方式会导致集群利用率低; 另一种解决方式就是在 EMR 中使用自己开发的 CredentialProvider 调用 AWS 的 STS 服务获取不同的 Credential 实现权限控制. 这个一句话两句话说不清楚, 改天可以单独写一篇: 如何在一个 EMR 集群中实现多租户的权限控制
数据库层面
文件系统之上就是数据库层面. 几乎所有的数据库都有自己的权限控制系统, Hive 也不例外. 业界可选的方案也很多. 基本上是可以控制表级别的权限: 用户对某个表是否有 CRUD 的权限.
如果觉得现有的方案不能满足需求, 定制化开发也相对容易, 只需要通过解析 SQL 获取到 SQL 代码中想要 CRUD 操作的 Table 的列表, 再请求权限系统看用户是否有对应的权限即可.

在数据库层面控制权限也有缺点: 太粗犷. 例如 SELECT 权限仅仅限制到 Table 一层, 用户一旦有了权限就可以查询全表数据, 就要求 Table 中的数据必须是严格控制的; 如果想控制用户仅仅查询 Table 中数据的子集, 最简单的解决办法是通过 View 的方式实现, 但如果用户多了这个方案就不现实. 业界已有的方案例如 Apache Sentry 和 Apache Ranger 也非常值得考虑或者借鉴.
应用层面
还好, 我们还有应用层. 应用层是指在数据库层面之上构建的数据应用, 最直观的例子就是报表. 在应用层面我们就可以更精细化的控制权限, 例如一个用户仅仅能查询到自己所在部门的业绩, 只需做一个他们部门的报表即可, 查询中写死了他所所在部门的 ID 就控制好权限.
三个层面的权限控制对比如下:
| 对比项/权限层面 | 文件系统层 | 数据库层 | 应用层 |
|---|---|---|---|
| 实现方式 | 通过文件系统控制权限 | 通过数据库权限控制表级别权限 | 根据业务需求实现应用层面的权限控制 |
| 权限控制粒度 | 文件级别, 粗犷 | Table级别, 粗犷 | 按需控制, 细致 |
| 实现难度 | 简单 | 简单 | 复杂, 需要业务开发 |
| 优点 | 容易兼容多中计算引擎 | 现有成熟方案实现较多 | 按需细粒度控制 |
| 缺点 | AWS EMR 单集群不支持多租户权限 | 多种计算引擎整合麻烦, 例如 Spark 和 Hive | 需要开发 |
选择原则
总结几个原则, 欢迎吐槽:
Least Privilege Principle
权限一律给到最小, 最容易犯的错误就是只读权限: 如果只有只读权限, 那就一定不会给写权限, 避免误操作的发生.
只读权限尽量贯彻到文件系统层
一般数据平台都会有只读权限的需求, 例如 Presto 集群作为 ad-hoc 查询, 基本上不会写 ETL 后的数据库, 那么从文件系统上限制 Presto 集群只有只读权限就非常合适, 确保一定不会有人写入数据到线上库
保留所有的访问日志
无论哪种方式的访问, 必须保留访问日志, 方便后续定位问题. 这一点在 AWS S3 上就很容实现, 直接通过 Access Log 功能即可保留访问日志.
-- EOF --