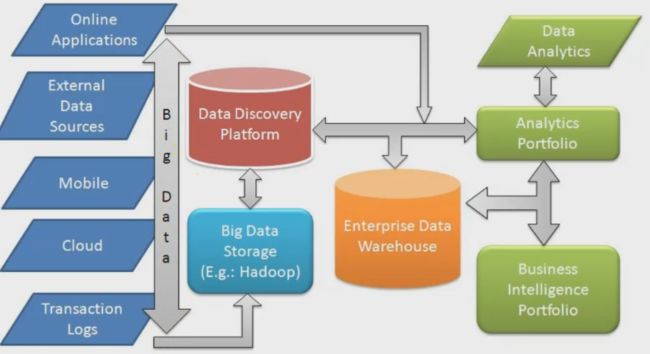
大数据及分析环境
bigdata主要体现在:量,速度,多样性
数据量,数据流速度(实时,批量,串流),数据多样性(结构化,半结构化(弹性内容),非结构化(写parser处理))
lambda architecture(数据系统架构)


DIKW金字塔:
data,information,knowledge,wisdom
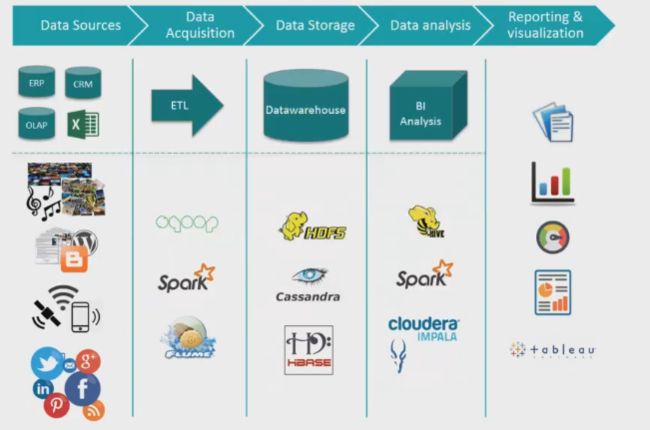
Excel,csv(rowbased),parquet(columnbased),avro(序列化,减少传输时的空间)
单机(mysql),分布式,hdfs,s3
HDD,SSD,Memory
batch:hadoop,spark,SQL Database
streaming:Storm,Kafka,Spark Streaming
rdbms,nosql
Spark简介
spark(计算框架)速度大幅超越hadoop(mapreduce)
spark streaming,sql,mllib,graphx
Resilient Distributed Datasets(RDD):
弹性分布式数据集
spark最基础的抽象结构。可容错且并行运行。两种类型:
平行集合:scala集合,可并行运行
hadoop数据集:并行运行在hdfs或者其他hadoop支持的存储系统上
RDD两种操作行为:
Transformations,Actions

很多个Transformation对应一个Action,RDD持久化存储在内存或硬盘中


窄依赖,宽依赖

spark元件

Spark Driver(执行应用程序,建立SparkContext并且安排任务、与ClusterManager沟通)、Executors(执行Driver安排的工作,将执行的结果存储在内存中,与存储系统进行交互)、Cluster Manager(资源分配管理)
运行任务流程
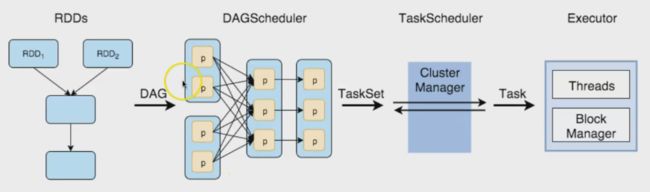
Spark元件运作方式:
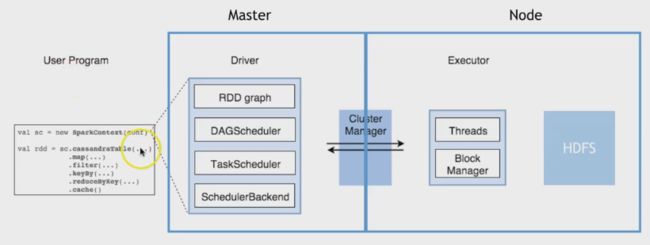
Spark1.X vs Spark2.x
以前用SparkContext作为进入点(使用时需要有一堆SqlContext,HiveContext……),现在都改为SparkSession。可以直接读取各种数据源,可以直接合Hive Metadata沟通,同时也包含设定和资源管理的功能。
实现SQL的功能:
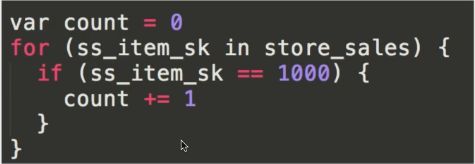
select count(*) from store_sales where ss_item_sk = 1000
spark1.x
传统做法:

这种做法含有大量的虚拟函数,数据缓存在内存中,没有循环展开,SIMD或Pipeline
手写做法:
这种做法没有虚拟函数,数据在CPU寄存器中,编译器循环展开,SIMD,Pipeline,使得简单的循环非常高效,得以透过底层的硬件进行优化。
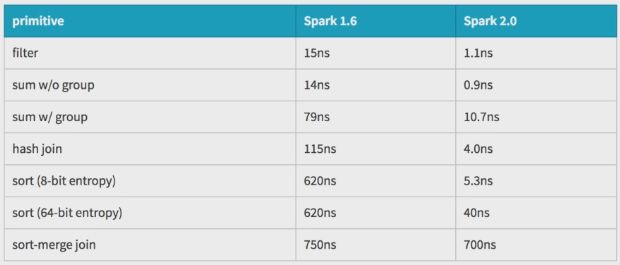
spark2.x经过优化能自动用简单的方法处理:

pyspark

语法:
textFile = spark.read.text("README.md")
wordCount = textFile.flatmap(lambda x:x.split(''))\
.map(lambda x:(x,1))\
.reduceByKey(lambda x,y:x+y)\
.collect()
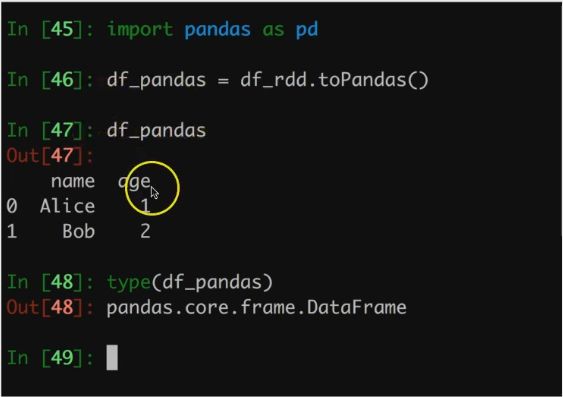
可以自由游走于RDD和Pandas Dataframe之间


sparkSQL
sql:select,from,join,group,order,where
select a.id,b.name,b.age,sum(c.onlinetime) as onlinetime
from userid a
join userinfo b
on a.userid = b.userid
join(
select userid,logintime - logouttime as onlinetime
from log
where df between '2016-01-01' and '2017-09-01'
)c
on a.userid = c.userid
group by a.id,b.name,b.age
order by onlinetime DESC
limit 100
pyspark混合sql
context = HiveContext(sc)
results = context.sql(
"SELECT * FROM people")
names = results.map(lambda p:p.name)
数据来源可以包括S3,HDFS,Cassandra,数据格式可以是json,text,parquet,都可以转成DataFrame操作
context.jsonFile("s3n://...")
.registerTempTable("json")
results=context.sql(
"""SELECT *
FROM people
JOIN json ...""")
sparksql与hive高度整合,可以从hive的metastore中读取数据表格。可以通过JDBC或ODBC连接spark sql,享受spark的运算能力。
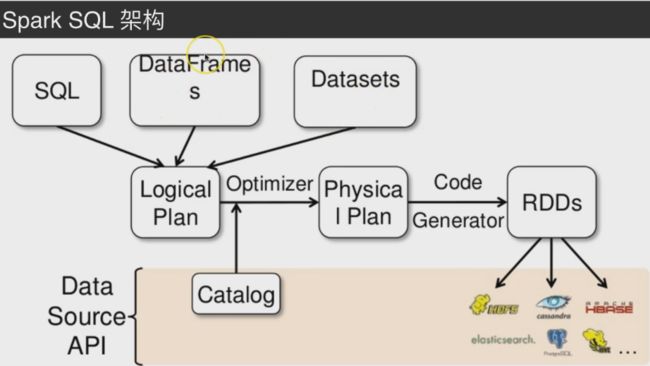
catalyst(催化剂)
pyspark的sparksql语法:
spark.read.csv()……
读取json数据的时候不需要再写parser
df = spark.read.json()
df.show() 得到dataframe
df.select("name").show()
df.write.csv()……