PCA 简介
PCA(Principal Component Analysis),即主成分分析。PCA是一种研究数据相似性或差异性的可视化方法,采取降维的思想,PCA 可以找到距离矩阵中最主要的坐标,把复杂的数据用一系列的特征值和特征向量进行排序后,选择主要的前几位特征值,来表示样品之间的关系。通过 PCA 可以观察个体或群体间的差异。PC 后面的百分数表示对应特征向量对数据的解释量,此值越大越好。
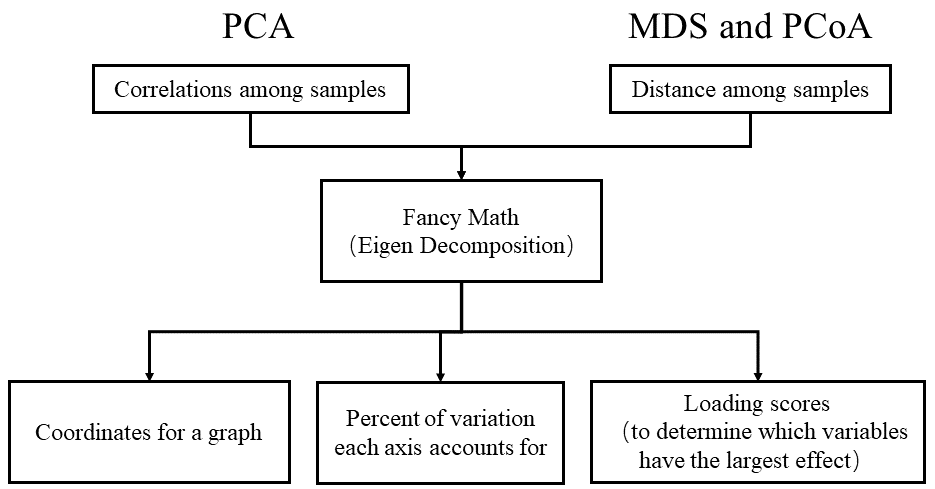
和PCA类似的数据降维方法还有MDS和PCoA。它们三者之间的区别联系如下图。
PCA creates plots based on correlations among samples.
MDS and PCoA create plots based on distances among samples.
PCA算法
PCA的计算过程比较复杂,可以参考B站up主上传的YouTube上的视频(点击观看)作为参考。PS:YouTube上的StatQuest系列视频及其通俗易懂,强推。
PCA在R语言中的实现
(R代码下载:点击下载)
data.matrix <- matrix(nrow = 100,ncol = 10) #创建一个100行10列的空矩阵
colnames(data.matrix) <- c(paste("wt",1:5,sep = ""),paste("ko",1:5,sep = "")) #命名矩阵的列
rownames(data.matrix) <- paste("gene",1:100,sep = "") #命名矩阵的行
# for循环填充矩阵
for (i in 1:100) {
wt.values <- rpois(5,lambda = sample(x=10:1000,size = 1))
ko.values <- rpois(5,lambda = sample(x=10:1000,size = 1))
data.matrix[i,] <- c(wt.values,ko.values)
}
pca <- prcomp(t(data.matrix),scale = TRUE) #t()函数的功能的将矩阵的行列位置进行置换,本例中研究的是“样本”,不是“Gene”
#prcomp()的结果是三个值:x,sdev和rotation。三个值在后面都会用到
plot(pca$x[,1],pca$x[,2])
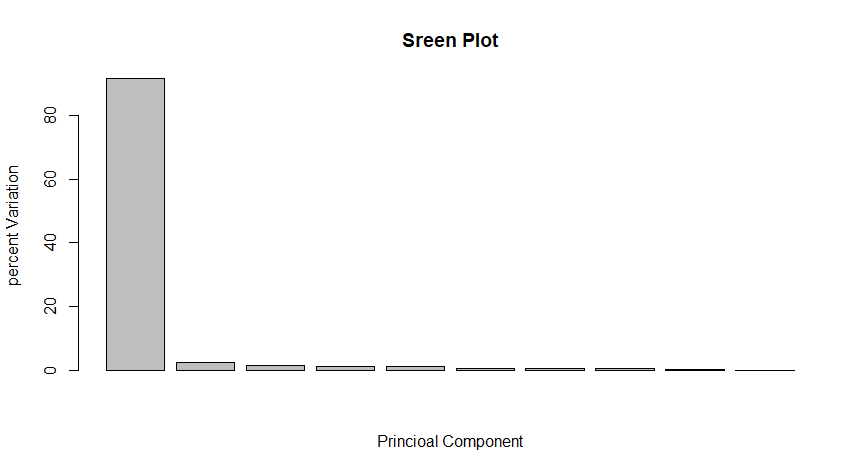
pca.var <- pca$sdev^2 # 计算原始数据中的每个数据在每个PC上的比重
pca.var.per <- round(pca.var/sum(pca.var)*100,1) #计算每个PC占所有PC的和的比列
barplot(pca.var.per,main = "Sreen Plot",xlab = "Princioal Component",ylab = "percent Variation")#柱状图显示每个PC所占的比列
library(ggplot2)#调用ggplot2()
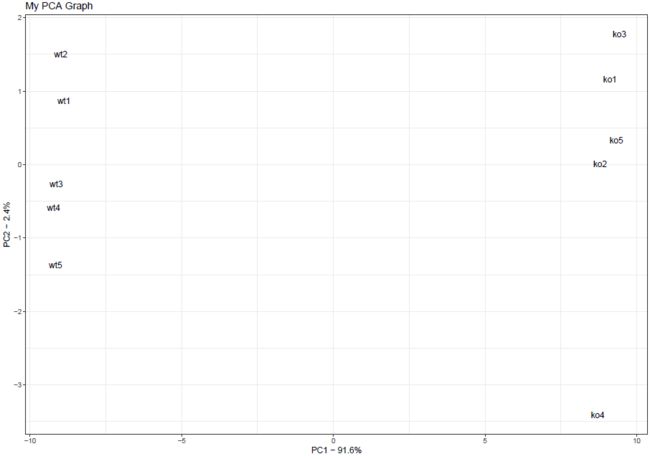
pca.data <- data.frame(Sample=rownames(pca$x),X=pca$x[,1],Y=pca$x[,2])#创建数据框
#ggplot2绘图
ggplot(data = pca.data,aes(x=X,y=Y,label=Sample))+
geom_text()+
xlab(paste("PC1 - ",pca.var.per[1],"%",sep = ""))+
ylab(paste("PC2 - ",pca.var.per[2],"%",sep = ""))+
theme_bw()+
ggtitle("My PCA Graph")
loading_scores <- pca$rotation[,1] #查看PC1的loading scores
gene_scores <- abs(loading_scores) #计算loading score的绝对值
gene_score_ranked <- sort(gene_scores,decreasing = TRUE) #降序排列loading scores
top_10_genes <- names(gene_score_ranked[1:10])
top_10_genes
pca$rotation[top_10_genes,2]
代码生成
在网站https://carbon.now.sh上生成带感的代码图片。