(二)Spring框架原理之实例化bean和@Autowired实现原理
目录
一、UML类图及流程分析
1.UML类图组成
2.流程分析
二、源码分析
1.DefaultListableBeanFactory类实例化bean部分
2.AbstractBeanFactory抽象类
3.AbstractAutowireCapableBeanFactory抽象类
4.DefaultSingletonBeanRegistry类
5.AutowiredAnnotationBeanPostProcessor类
6.InjectionMetadata类
7.AutowiredFieldElement内部类
8.DefaultListableBeanFactory类处理@Autowired注解
两部分流程都较长,如果只对Bean的实例化感兴趣只需要看到5.DefaultSingletonBeanRegistry小节即可,后面是分析@Autowired注解的实现原理。
一、UML类图及流程分析
1.UML类图组成
UML类图组成如下:
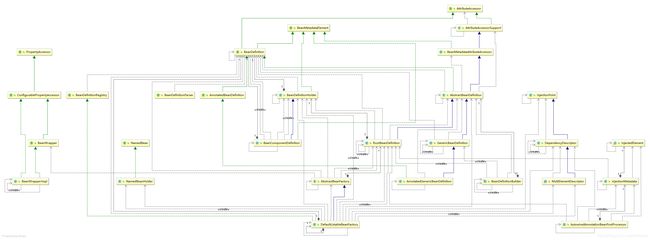
这个图中我们可以大致分为六个部分:
- 第一部分肯定是BeanDefinition的父类和子类组成的,这部分的组成有需要再细分一下,共可以分为六部分:
- AttributeAccessor接口:这个接口提供了setAttribute和getAttribute等操作属性的方法提供给子类实现;
- BeanMetadataElement接口:该接口只提供了一个getSource方法,提供子类获取源对象方法;
- BeanDefinition接口:bean定义的直接接口,这个接口提供了常见的scope、lazy、dependsOn、initMethod和destroyMethod等属性配置方法,规范了一个Spring管理的Bean必须实现哪些属性;
- AnnotatedBeanDefinition:注解bean定义,里面提供了两个方法,一个是获取注解元数据,另一个是获得方法元数据;
- BeanDefinitionHolder:该类和子类BeanComponentDefinition的作用便是持有bean的名字、别名和其对应的BeanDefinition,可以注册为内部bean的占位符;
- BeanDefinitionBuilder:普通BeanDefinition的构造器,这里面可以构造RootBeanDefinition、ChildBeanDefinition和GenericBeanDefinition等多个类型的bean定义,想要快速实例化一个bean定义可以用此类完成;
- BeanDefinitionParser接口:从名字便可以看出来其大致作用,用来解析BeanDefinition的接口,其主要是被Spring的NamespaceHandlerSupport实现子类来完成诸如
和 等XML标签的读取解析去获取Bean定义的; - BeanDefinitionRegistry接口:bean定义的注册中心,该接口的实现子类将可以完成注册、删除和获取bean定义等操作,Spring默认实现的Bean工厂DefaultListableBeanFactory便实现了该接口来管理bean定义;
- BeanWrapper接口:这部分的接口功能便是封装一个bean实例,且提供为这个bean调用对应的setter和getter方法,设置bean的具体成员属性值;
- @Autowired注解实现相关的类:如图中的最右侧部分的InjectionPoint实现层级和InjectionMetadata相关层级,这部分是存储实现@Autowired注解功能的必要参数,如class类型和这个class对象所需要的自动注入的对象;而DependencyDescriptor则保存了需要赋值的字段或者方法返回值和赋值的beanClass类型,随后再根据DependencyDescriptor的具体子类类型判断返回list、map、array或者单个的bean对象;
- NamedBeanHolder:用来存储beanName和已经初始化完成的bean实例,这个对象在参数为class类型调用getBean时被使用。
2.流程分析
Spring工厂实例化bean时对象的变化流程图:

我在分析该流程时将其分为了三个部分:
- 中间的核心部分:这部分的主要流程是在bean工厂的两个抽象类AbstractBeanFactory和AbstractAutowireCapableBeanFactory中完成的,主要的功能便是通过bean的名称调用getBean方法,随后在这两个类中完成初始化以及调用此过程中涉及到的接口,其中比较常用的便是FactoryBean和BeanPostProcessor两个接口,诸如其它的Aware接口也是在这个流程调用的;
- 右边的封装部分:虽然这部分调用的getBean也是BeanFactory接口声明的方法,但我们分析初始化Bean流程时可以把这个部分当成额外的封装部分,是对通过beanName获取bean的一种基于便利性的额外封装实现。这个流程主要是在DefaultListableBeanFactory类中完成的,其大致作用便是通过class类型获取唯一的候选者beanName,因为一个class类型可能会在工厂中匹配到多个beanName,因此需要做一些额外处理,当获得beanName之后再调用核心部分去实例化bean;
- 左边的功能拓展部分:这部分的入口是在获取到BeanWrapper之后,调用BeanPostProcessor实现类AutowiredAnnotationBeanPostProcessor来完成的。这部分的功能便是处理@Autowired注解,先通过BeanWrapper获取bean的class对象,再判断其字段和方法有哪些是被这个注解的,随后再依次处理判断,在获得自动注入的这些实例时,将再次调用getBean,形成一个递归调用,完成bean的获取和赋值到字段或方法上。
二、源码分析
1.DefaultListableBeanFactory类实例化bean部分
先从外部额外封装的getBean方法分析起,其关键源码部分如下:
public class DefaultListableBeanFactory
extends AbstractAutowireCapableBeanFactory
implements ConfigurableListableBeanFactory, BeanDefinitionRegistry,
Serializable {
@Override
public T getBean(Class requiredType) throws BeansException {
// 对外单个类参数获取bean,将会调用后面带有参数args的方法
return getBean(requiredType, (Object[]) null);
}
@Override
public T getBean(Class requiredType, @Nullable Object... args)
throws BeansException {
// 调用resolveBean方法解析bean
Object resolved = resolveBean(ResolvableType
.forRawClass(requiredType), args, false);
// 如果返回的是nll,则代表Spring工厂中没有class类型的bean信息
if (resolved == null) {
throw new NoSuchBeanDefinitionException(requiredType);
}
return (T) resolved;
}
@Nullable
private T resolveBean(ResolvableType requiredType,
@Nullable Object[] args, boolean nonUniqueAsNull) {
// 流程图中右侧的最后一步,将resolveNamedBean方法返回的NamedBeanHolder
// 类型判空,如果不为空则直接将内部的beanInstance实例返回,在
// resolveNamedBean方法中执行的是第三步,把ResolvableType转为beanName
NamedBeanHolder namedBean = resolveNamedBean(requiredType, args,
nonUniqueAsNull);
if (namedBean != null) {
return namedBean.getBeanInstance();
}
// 如果从当前的beanFactory中获取不到bean的信息则从父类beanFactory中
// 获取,依次递归下去,这里可以忽略这段代码(正常情况下没有层级关系)
...
return null;
}
@Nullable
private NamedBeanHolder resolveNamedBean(
ResolvableType requiredType, @Nullable Object[] args,
boolean nonUniqueAsNull) throws BeansException {
// 根据requiredType中的class类型获取beanName集合,这里面将会判断list
// 集合beanDefinitionNames来获取普通的bean候选者,判断set集合
// manualSingletonNames中手动添加的单例对象,两者都会判断FactoryBean和
// 普通的bean对象,并选举出来称为候选者,具体流程不分析
String[] candidateNames = getBeanNamesForType(requiredType);
// 如果获取到的beanName是多个,则说明这一个class对应多个bean
if (candidateNames.length > 1) {
List autowireCandidates =
new ArrayList<>(candidateNames.length);
// 先判断beanDefinitionMap集合中是否含有该candidateName
// 如果有则后续进行转换到candidateNames数组
for (String beanName : candidateNames) {
if (!containsBeanDefinition(beanName) ||
getBeanDefinition(beanName).isAutowireCandidate()) {
autowireCandidates.add(beanName);
}
}
// 将List转换为原来的String[]数组
if (!autowireCandidates.isEmpty()) {
candidateNames = StringUtils
.toStringArray(autowireCandidates);
}
}
// 如果candidateNames数组长度为1,则说明class只有一个对应的bean
if (candidateNames.length == 1) {
String beanName = candidateNames[0];
// 直接获取0号位置的beanName,并调用getBean(beanName)方法初始化bean
// 随后将bean实例赋值到NamedBeanHolder中的beanInstance属性中
// 以便该方法返回后直接返回beanInstance属性对象
return new NamedBeanHolder<>(beanName, (T) getBean(beanName,
requiredType.toClass(), args));
}
else if (candidateNames.length > 1) {
Map candidates =
new LinkedHashMap<>(candidateNames.length);
// 对candidateNames进行依次处理
for (String beanName : candidateNames) {
// 如果是单例对象,即singletonObjects中含有此bean
if (containsSingleton(beanName) && args == null) {
// 直接先调用getBean(beanName)获取bean实例
Object beanInstance = getBean(beanName);
// 虽然放入到candidates集合中,以便后续返回具体的bean
candidates.put(beanName, (beanInstance instanceof NullBean?
null : beanInstance));
}
else {
// 如果是原型的,则先把class类型放到candidates中,后续返回时再
// 实例化返回
candidates.put(beanName, getType(beanName));
}
}
// 获取主要的候选者,即最终的bean返回对象,即声明对象时是否使用
// @Primary注解了,如果注解了则使用其中最后一个候选者
String candidateName = determinePrimaryCandidate(candidates,
requiredType.toClass());
// 如果判断的主要候选者为空(没有一个bean被@Primary注解)
if (candidateName == null) {
// 根据OrderComparator优先级获取优先级最高的bean
candidateName = determineHighestPriorityCandidate(candidates,
requiredType.toClass());
}
// 如果不为空
if (candidateName != null) {
// 从前面组装的candidates集合Map中获取对应的bean对象
// 这里获取到的可能是bean实例化对象,也有可能是class对象
Object beanInstance = candidates.get(candidateName);
// 如果beanInstance是空或者类型是class
if (beanInstance == null || beanInstance instanceof Class) {
// 调用getBean(candidateName)方法实例化bean
beanInstance = getBean(candidateName,
requiredType.toClass(), args);
}
// 使用NamedBeanHolder封装bean实例并返回
return new NamedBeanHolder<>(candidateName, (T)beanInstance);
}
// 前面传入的nonUniqueAsNull值是false,因此如果到这里candidateName
// 还是为null,则抛出异常没有唯一的bean可返回
if (!nonUniqueAsNull) {
throw new NoUniqueBeanDefinitionException(requiredType,
candidates.keySet());
}
}
// 如果候选者candidateNames为0,则直接返回null
return null;
}
} 这个类中主要方法栈为四层,调用这四个方法栈将会调用到其它的类中,如调用完之后将会返回已经实例化的bean对象,在调用方法栈中将会调用到AbstractBeanFactory类中的getBean方法中。也就是说DefaultListableBeanFactory类只是对getBean(class)这个方法进行了一层额外的封装,最终还是调用到了AbstractBeanFactory类中,因此我自己把这部分流程划为额外封装实现。
2.AbstractBeanFactory抽象类
前面说过,调用getBean(class)最终实例化bean时将会调用到这个类中,且这个类是核心部分的入口,可以说是非常重要了。接下来我们看下其部分关键源码:
public abstract class AbstractBeanFactory
extends FactoryBeanRegistrySupport
implements ConfigurableBeanFactory {
@Override
public Object getBean(String name) throws BeansException {
return doGetBean(name, null, null, false);
}
@Override
public T getBean(String name, Class requiredType)
throws BeansException {
return doGetBean(name, requiredType, null, false);
}
@Override
public Object getBean(String name, Object... args)
throws BeansException {
// 这三个方法都是调用了doGetBean,唯一的不同便在于传入的参数不一样
// 但是name这个参数是必须的
return doGetBean(name, null, args, false);
}
protected T doGetBean(final String name,
@Nullable final Class requiredType,
@Nullable final Object[] args, boolean typeCheckOnly)
throws BeansException {
// 或许这个方法看起来会很长,但实际上可以把其分为五个功能大点
// 一、使用aliasMap集合将传入的name转变成beanName
final String beanName = transformedBeanName(name);
Object bean;
// 二、先从singletonObjects单例缓存集合中获取bean对象,如果不为空
// 则直接返回赋值给sharedInstance对象如果为空则从singletonFactories集合
// 中获取单例工厂类,并调用getObject获取单例bean对象返回赋值
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
// 如果sharedInstance不为空,则调用getObjectForBeanInstance方法
// 判断其是否被FactoryBean封装的,如果是则调用该接口的getObject方法
// 获取bean对象,如果不是则直接返回,其具体的方法流程略过,主要是
// 判断FactoryBean接口的,有兴趣的可以去看下,后面都会用到
bean = getObjectForBeanInstance(sharedInstance, name, beanName,
null);
} else {
// 判断该beanName是否是原型且正在被创建的,如果是则抛出异常
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
// 三、判断该beanFactory的父类工厂是否含有该bean对象,此略过,最终
// 还是会跑到该方法的后续流程
BeanFactory parentBeanFactory = getParentBeanFactory();
if (parentBeanFactory != null &&
!containsBeanDefinition(beanName)) {
...
}
// typeCheckOnly传入的是false,因此会进入判断
if (!typeCheckOnly) {
// 该方法的作用便是将beanName添加到alreadyCreated集合中,标记为
// 已经实例化过beanName对应的bean对象
markBeanAsCreated(beanName);
}
// 该try-catch块将是实例化bean的地方,前面只是判断
try {
// 从mergedBeanDefinitions集合中获取具体的BeanDefinition对象
final RootBeanDefinition mbd =
getMergedLocalBeanDefinition(beanName);
// 判断该bean定义是否合乎标准,如非抽象类
checkMergedBeanDefinition(mbd, beanName, args);
// 四、处理@DependsOn注解中的bean对象,在这里将会先实例化注解中
// 引用的bean
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
// 如果获取的dependsOn不为空则依次遍历其中引入的值
for (String dep : dependsOn) {
// 判断是否是循环依赖,如果是则抛出异常,所谓循环依赖则是
// @Bean注解的A方法使用@DependsOn依赖了@Bean注解的B方法
// 但是B方法又使用了@DependsOn依赖了A方法,形成死循环
if (isDependent(beanName, dep)) {
throw new BeanCreationException();
}
// 跑到这里代表前面并没有死循环依赖的发生,则把彼此相关的
// 依赖关系放入到dependentBeanMap中,因此第一次是绝对会
// 执行到这里的
registerDependentBean(dep, beanName);
try {
// 实例化依赖的bean
getBean(dep);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException();
}
}
}
// 五、判断Bean是单例或是原型进行相应的实例化操作
if (mbd.isSingleton()) {
// 如果是单例,则使用lambda实例化一个ObjectFactory对象传入
// getSingleton方法实例化单例,这个方法也很重要,后续会分析
sharedInstance = getSingleton(beanName, () -> {
try {
// 实例化的ObjectFactory对象执行的方法也很简单
// 单纯的调用createBean方法创造bean对象
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
// 如果创造失败则销毁对象(清除缓存)
destroySingleton(beanName);
throw ex;
}
});
// 判断这个bean是否被FactoryBean封装
bean = getObjectForBeanInstance(sharedInstance, name,
beanName, mbd);
} else if (mbd.isPrototype()) {
// 如果bean是原型
Object prototypeInstance = null;
try {
// 记录原型bean正在被创建,在前面会进行判断
beforePrototypeCreation(beanName);
prototypeInstance = createBean(beanName, mbd, args);
}
finally {
// 执行完后将当前创建的原型bean标记去除
afterPrototypeCreation(beanName);
}
// 判断这个bean是否被FactoryBean封装
bean = getObjectForBeanInstance(prototypeInstance, name,
beanName, mbd);
} else {
// 如果是其它类型的scope参数
String scopeName = mbd.getScope();
final Scope scope = this.scopes.get(scopeName);
// scope属性不能为空
if (scope == null) {
throw new IllegalStateException();
}
try {
// Scope接口是Spring提供给外部使用的,因此如果指定了
// 自定义的Scope实现,调用里面的get方法将会执行普通的
// 原型bean流程,只是开发者可以在Scope中对该bean进行
// 额外的处理判断
Object scopedInstance = scope.get(beanName, () -> {
// 实际上ObjectFactory对象的操作流程和原型bean一模一样
beforePrototypeCreation(beanName);
try {
return createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
});
// 判断这个bean是否被FactoryBean封装
bean = getObjectForBeanInstance(scopedInstance, name,
beanName, mbd);
}
catch (IllegalStateException ex) {
throw new BeanCreationException();
}
}
}
catch (BeansException ex) {
cleanupAfterBeanCreationFailure(beanName);
throw ex;
}
}
// 这部分是判断如果要求的类型requiredType和获得的bean类型不一致进行
// 转换的地方,正常使用是不会出现这种情况的,因此暂时略过
if (requiredType != null && !requiredType.isInstance(bean)) {
...
}
// 返回bean对象
return (T) bean;
}
} 实际上doGetBean这个方法流程可以分为五个部分流程,如下图:

3.AbstractAutowireCapableBeanFactory抽象类
我们从上面的AbstractBeanFactory类已经分析到了createBean方法了,由于创建和初始化bean的核心流程都在AbstractAutowireCapableBeanFactory类的几个方法中,因此这个类的流程会比较多,大致流程可以看到下面的流程图:

接下来我们看下其关键部分源码:
public abstract class AbstractAutowireCapableBeanFactory
extends AbstractBeanFactory
implements AutowireCapableBeanFactory {
public T createBean(Class beanClass) throws BeansException {
// AbstractBeanFactory并没有调用这个方法,但是我们也可以看下
// 这个方法流程就是将beanClass封装成Bean定义且设置成原型
RootBeanDefinition bd = new RootBeanDefinition(beanClass);
bd.setScope(SCOPE_PROTOTYPE);
bd.allowCaching = ClassUtils.isCacheSafe(beanClass,
getBeanClassLoader());
return (T) createBean(beanClass.getName(), bd, null);
}
@Override
protected Object createBean(String beanName, RootBeanDefinition mbd,
@Nullable Object[] args)
throws BeanCreationException {
// 真正创造bean的方法,这个方法大致可以分为三个部分
RootBeanDefinition mbdToUse = mbd;
// 一、将beanName和bean定义解析成对应的class类型
Class resolvedClass = resolveBeanClass(mbd, beanName);
if (resolvedClass != null && !mbd.hasBeanClass() &&
mbd.getBeanClassName() != null) {
mbdToUse = new RootBeanDefinition(mbd);
// 确定具体的beanClass类型
mbdToUse.setBeanClass(resolvedClass);
}
// 准备方法覆盖,无关紧要
try {
mbdToUse.prepareMethodOverrides();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException();
}
// 二、如果bean定义的beforeInstantiationResolved属性为true
// 则直接使用BeanPostProcessor对bean进行处理,且处理后直接返回
// 不再使用Spring工厂的实例化流程,意味着Spring很多实例化中途的接口
// 都将不起作用,还没见到过这种实例化方式的。这里面将会调用
// InstantiationAwareBeanPostProcessor接口的before方法,调用
// BeanPostProcessor接口的after方法
try {
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null) {
return bean;
}
}
catch (Throwable ex) {
throw new BeanCreationException();
}
try {
// 三、调用doCreateBean方法实行真正创建bean流程
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
return beanInstance;
} catch (BeanCreationException |
ImplicitlyAppearedSingletonException ex) {
throw ex;
} catch (Throwable ex) {
throw new BeanCreationException();
}
}
protected Object doCreateBean(final String beanName,
final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// 根据createBean方法的流程来看,其相当于是外面再封装了一层,用来解析
// beanClass属性和提前使用BeanPostProcessor完成bean的实例化,真正的
// Spring实例化bean的流程其实是在这个方法中
// 在这个方法中共可以分为五个部分
BeanWrapper instanceWrapper = null;
// 一、如果是单例对象,则把factoryBeanInstanceCache缓存清掉,同时获取
// 缓存的BeanWrapper实例对象,单例对象(FactoryBean)在调用getType等
// 方法时将会被实例化后放到factoryBeanInstanceCache中,一般流程为null
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
// 如果instanceWrapper为null,则调用createBeanInstance实例化对象
// 在执行完这个方法后bean对象才会被实例化
if (instanceWrapper == null) {
// 具体实例化对象的地方,其大部分会调用instantiateBean方法利用反射来
// 完成bean的实例化
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
// 分别获取实例化对象和class类型
final Object bean = instanceWrapper.getWrappedInstance();
Class beanType = instanceWrapper.getWrappedClass();
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}
// 二、允许程序在创建bean对象后再修改合并后的bean定义
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
// 里面会调用MergedBeanDefinitionPostProcessor的实现类
// 其也是BeanPostProcessor的一个子接口
applyMergedBeanDefinitionPostProcessors(mbd, beanType,
beanName);
}
catch (Throwable ex) {
throw new BeanCreationException();
}
mbd.postProcessed = true;
}
}
// 三、快速缓存单例即使被BeanFactoryAware这样的生命周期接口触发
// 以便能够解决循环引用,前提是该单例bean正在创建中
boolean earlySingletonExposure = (mbd.isSingleton() &&
this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
// 将bean缓存到singletonObjects等单例集合中
// 大部分单例类都会调用到这里面,以便完成复杂的循环引用,当所有的
// 实例被后续的流程初始化后,最终的单例将变成最终的形态
addSingletonFactory(beanName, () ->
getEarlyBeanReference(beanName, mbd, bean));
}
Object exposedObject = bean;
// 四、对bean进行bean定义属性填充及执行一系列Spring初始化接口
try {
// 构造bean,这里面将会处理@Autowired和@Resource等操作bean成员属性
// 的注解,也会分别调用setter方法去设置对应的值,等下会分析
populateBean(beanName, mbd, instanceWrapper);
// initializeBean方法将会执行工厂接口的回调,如aware系列接口、
// InitializingBean接口、initMethod和BeanPostProcessor的接口调用
// 这里调用BeanPostProcessor是真正的调用其接口after和before方法
exposedObject = initializeBean(beanName, exposedObject, mbd);
} catch (Throwable ex) {
if (ex instanceof BeanCreationException &&
beanName.equals(((BeanCreationException) ex)
.getBeanName())) {
throw (BeanCreationException) ex;
} else {
throw new BeanCreationException();
}
}
// 五、判断单例对象是否造成了两次实例化导致单例对象出现不一致的现象
// 如果前面的提前存储单例对象成立,则进入(一般来说会进入)
if (earlySingletonExposure) {
// 再次获得提前放入的bean对象
Object earlySingletonReference = getSingleton(beanName, false);
// 如果提前放入的bean对象引入不为空
if (earlySingletonReference != null) {
// 如果经过populateBean和initializeBean方法后bean引用没变
// 则把早期的bean对象赋值给exposedObject对象
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
} else if (!this.allowRawInjectionDespiteWrapping &&
hasDependentBean(beanName)) {
// 如果经过两个初始化方法bean引用变了,则说明其它的bean已经
// 通过这两个方法实例化成功了单例bean,且两个单例bean不一致
// 抛出异常
String[] dependentBeans = getDependentBeans(beanName);
Set actualDependentBeans =
new LinkedHashSet<>(dependentBeans.length);
for (String dependentBean : dependentBeans) {
if (!removeSingletonIfCreatedForTypeCheckOnly(
dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException();
}
}
}
}
try {
// 注册需要销毁的bean对象:实现了DisposableBean和AutoCloseable接口
// 或者指明了destroy方法
registerDisposableBeanIfNecessary(beanName, bean, mbd);
} catch (BeanDefinitionValidationException ex) {
throw new BeanCreationException();
}
// 返回暴露的bean对象
return exposedObject;
}
protected void populateBean(String beanName, RootBeanDefinition mbd,
@Nullable BeanWrapper bw) {
// 这个方法共可以分为四个部分
// 该方法的主要作用便是使用bean定义属性值为BeanWrapper中的对象
// 填充对应的值
if (bw == null) {
// 如果bean定义为空且属性值不为空则抛出异常,否则直接跳过该方法
if (mbd.hasPropertyValues()) {
throw new BeanCreationException();
} else {
return;
}
}
// 一、根据InstantiationAwareBeanPostProcessor接口的
// postProcessAfterInstantiation方法返回值判断是否
// 继续执行填充bean对象属性
boolean continueWithPropertyPopulation = true;
if (!mbd.isSynthetic() &&
hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp =
(InstantiationAwareBeanPostProcessor) bp;
// 根据其接口方法返回值判断要不要继续执行后面的填充流程
if (!ibp.postProcessAfterInstantiation(bw
.getWrappedInstance(), beanName)) {
continueWithPropertyPopulation = false;
break;
}
}
}
}
// 为false则直接跳过
if (!continueWithPropertyPopulation) {
return;
}
// 获取bean定义中的属性值
PropertyValues pvs = (mbd.hasPropertyValues() ?
mbd.getPropertyValues() : null);
// 二、判断bean的自动注入模式为AUTOWIRE_BY_NAME或AUTOWIRE_BY_TYPE
// 一般都是使用默认的后续流程,只有特殊指定才会进入这两步,这两个
// 方法的作用便是把当前的bean定义根据参数名字或者类型从bean工厂中
// 获取对应的bean,并且保存到newPvs对象中,如mybatis的mapper便是
// 使用type类型获取到sqlSessionTemplate和sqlSessionFactory两个bean的
if (mbd.getResolvedAutowireMode() == AUTOWIRE_BY_NAME ||
mbd.getResolvedAutowireMode() == AUTOWIRE_BY_TYPE) {
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
// 根据autotowire的名称(如适用)添加属性值
if (mbd.getResolvedAutowireMode() == AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
// 根据自动装配的类型(如果适用)添加属性值
if (mbd.getResolvedAutowireMode() == AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}
// 判断是否有InstantiationAwareBeanPostProcessor接口,有为true
boolean hasInstAwareBpps =
hasInstantiationAwareBeanPostProcessors();
// 是否需要检查依赖,一般而言此值默认为false,暂时忽略
boolean needsDepCheck = (mbd.getDependencyCheck() !=
AbstractBeanDefinition.DEPENDENCY_CHECK_NONE);
// 三、如果有InstantiationAwareBeanPostProcessor接口则进入
PropertyDescriptor[] filteredPds = null;
if (hasInstAwareBpps) {
if (pvs == null) {
pvs = mbd.getPropertyValues();
}
// 依次获取InstantiationAwareBeanPostProcessor接口调用其
// postProcessProperties方法和postProcessPropertyValues方法
// 并获得这两个方法的返回值,以便后续使用
// 解析@Autowired注解并赋值便是在段方法中完成的,后面会分析
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp =
(InstantiationAwareBeanPostProcessor) bp;
PropertyValues pvsToUse = ibp.postProcessProperties(pvs,
bw.getWrappedInstance(), beanName);
// 此方法流程已被官方删除,原来的流程实际调用的也是
// postProcessProperties,因此这一段可以忽略
if (pvsToUse == null) {
...
}
pvs = pvsToUse;
}
}
}
// 略过
if (needsDepCheck) {
if (filteredPds == null) {
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw,
mbd.allowCaching);
}
checkDependencies(beanName, mbd, filteredPds, pvs);
}
// 四、如果返回的pvs不为空,则说明这些属性需要设置到BeanWrapper中
if (pvs != null) {
applyPropertyValues(beanName, mbd, bw, pvs);
}
}
protected Object initializeBean(final String beanName,
final Object bean, @Nullable RootBeanDefinition mbd) {
// 这个方法共可以分为四个部分
// 一、调用invokeAwareMethods方法,从名字就可以看出来,这个方法是用来
// 调用Aware系列接口,包括BeanNameAware、BeanClassLoaderAware和
// BeanFactoryAware,System.getSecurityManager()语句只是为了判断当前
// 系统有没有权限调用Aware接口
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction 想要理清楚这里面的流程,还是需要自己亲自走一遍创建的源码流程,否则不管看多少次流程分析到头来也还是会生疏忘记。
4.DefaultSingletonBeanRegistry类
这个类主要负责单例对象的缓存和一些判断。接下来看下其部分关键源码:
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry
implements SingletonBeanRegistry {
// 保存单例对象的Map集合
private final Map singletonObjects =
new ConcurrentHashMap<>(256);
// 保存单例对象和其对应的ObjectFactory集合
private final Map> singletonFactories =
new HashMap<>(16);
// 提前缓存单例的集合
private final Map earlySingletonObjects =
new HashMap<>(16);
// 正在创建单例的集合
private final Set singletonsCurrentlyInCreation =
Collections.newSetFromMap(new ConcurrentHashMap<>(16));
// 注册成功的单例bean对象
private final Set registeredSingletons =
new LinkedHashSet<>(256);
@Override
@Nullable
public Object getSingleton(String beanName) {
// 在前面创建bean的流程中调用的便是这个方法
return getSingleton(beanName, true);
}
protected Object getSingleton(String beanName,
boolean allowEarlyReference) {
// 这个方法实际上只是从缓存中获取单例对象
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null &&
isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// 进入到这里说明缓存对象没有命中
singletonObject = this.earlySingletonObjects.get(beanName);
// 再判断提前缓存的单例对象集合能不能命中
if (singletonObject == null && allowEarlyReference) {
// 如果提前缓存的单例对象也无法命中则从singletonFactories
// 集合中查找对应的ObjectFactory对象,如果不为空则调用其
// getObject初始化bean对象
ObjectFactory singletonFactory = this
.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 调用getObject初始化单例bean对象,并缓存起来
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName,
singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
protected void addSingleton(String beanName, Object singletonObject) {
// 添加单例说明这个单例对象已经完全初始化完成,因此可以把提前缓存在
// earlySingletonObjects和singletonFactories集合的bean删除,直接放进
// singletonObjects和registeredSingletons集合
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
public Object getSingleton(String beanName,
ObjectFactory singletonFactory) {
// 这个方法在前面初始化单例bean时会被调用,且singletonFactory对象
// 是由lambda实例化的一个对象,里面只有一个调用createBean方法语句
synchronized (this.singletonObjects) {
Object singletonObject = this.singletonObjects.get(beanName);
// 先判断单例bean缓存有没有这个bean,如果有就直接返回,没有则进入判断
if (singletonObject == null) {
// 该单例bean有另外一个线程正在初始化中抛出异常
if (this.singletonsCurrentlyInDestruction) {
throw new BeanCreationNotAllowedException();
}
// 记录单例beanName正在实例化中
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions =
(this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<>();
}
try {
// 调用getObject方法(实际为调用createBean方法,因为这个
// 对象方法中只有调用createBean方法语句)
singletonObject = singletonFactory.getObject();
newSingleton = true;
} catch (IllegalStateException ex) {
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
throw ex;
}
} catch (BeanCreationException ex) {
if (recordSuppressedExceptions) {
for (Exception suppressedException :
this.suppressedExceptions) {
ex.addRelatedCause(suppressedException);
}
}
throw ex;
} finally {
if (recordSuppressedExceptions) {
this.suppressedExceptions = null;
}
// 标记beanName已经创建完成
afterSingletonCreation(beanName);
}
// 如果创建过程中为抛出异常则添加到单例缓存中
if (newSingleton) {
addSingleton(beanName, singletonObject);
}
}
// 返回单例对象
return singletonObject;
}
}
} 5.AutowiredAnnotationBeanPostProcessor类
这个类是BeanPostProcessor接口的实现类,是完成@Autowired注解原理的地方,接下来看到其关键源码:
public class AutowiredAnnotationBeanPostProcessor
extends InstantiationAwareBeanPostProcessorAdapter
implements MergedBeanDefinitionPostProcessor, PriorityOrdered,
BeanFactoryAware {
// 这个集合中保存了@Autowired和@Value注解
private final Set> autowiredAnnotationTypes =
new LinkedHashSet<>(4);
@Override
public PropertyValues postProcessProperties(PropertyValues pvs,
Object bean, String beanName) {
// 找到这个bean哪些字段和方法需要自动注入
InjectionMetadata metadata = findAutowiringMetadata(beanName,
bean.getClass(), pvs);
try {
// 调用注入流程
metadata.inject(bean, beanName, pvs);
} catch (BeanCreationException ex) {
throw ex;
} catch (Throwable ex) {
throw new BeanCreationException();
}
return pvs;
}
private InjectionMetadata findAutowiringMetadata(String beanName,
Class clazz, @Nullable PropertyValues pvs) {
// 返回到类名作为缓存键,以便向后兼容自定义调用者。
String cacheKey = (StringUtils.hasLength(beanName) ?
beanName : clazz.getName());
// 首先对并发映射进行快速检查,使用最小的锁定。
InjectionMetadata metadata = this
.injectionMetadataCache.get(cacheKey);
// 先进行一层缓存判断,但是不上锁,可以让一大批线程通过这个判断方法
// 完成是否需要刷新的判断,而不需要阻塞线程
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
synchronized (this.injectionMetadataCache) {
metadata = this.injectionMetadataCache.get(cacheKey);
// 进行第二次判断,此时判断的对象是需要刷新的,且并发量高只有几个
// 线程会同时到这里,保证了最小粒度线程判断,这种使用方法和单例对
// 象的两重判断原理一样,都是为了避免同一个class执行多次if块里面
// 的流程
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
if (metadata != null) {
metadata.clear(pvs);
}
// 根据类获取需要自动注入的字段和方法
metadata = buildAutowiringMetadata(clazz);
// 放入缓存
this.injectionMetadataCache.put(cacheKey, metadata);
}
}
}
return metadata;
}
private InjectionMetadata buildAutowiringMetadata(
final Class clazz) {
// 看起来这个方法很长,但实际上只执行了两个有用的逻辑
List elements =
new ArrayList<>();
Class targetClass = clazz;
do {
// 当前类所需要自动注入的元素集合
final List currElements =
new ArrayList<>();
// 依次遍历字段判断哪些字段拥有autowiredAnnotationTypes集合中的注解
// 如果有的话则将其封装添加到currElements集合中
ReflectionUtils.doWithLocalFields(targetClass, field -> {
AnnotationAttributes ann = findAutowiredAnnotation(field);
if (ann != null) {
if (Modifier.isStatic(field.getModifiers())) {
return;
}
boolean required = determineRequiredStatus(ann);
currElements.add(new AutowiredFieldElement(field,
required));
}
});
// 类似遍历字段的,这里只是遍历了方法,其它流程一样
ReflectionUtils.doWithLocalMethods(targetClass, method -> {
Method bridgedMethod = BridgeMethodResolver
.findBridgedMethod(method);
if (!BridgeMethodResolver.isVisibilityBridgeMethodPair(method,
bridgedMethod)) {
return;
}
AnnotationAttributes ann =
findAutowiredAnnotation(bridgedMethod);
if (ann != null && method.equals(ClassUtils
.getMostSpecificMethod(method, clazz))) {
if (Modifier.isStatic(method.getModifiers())) {
return;
}
boolean required = determineRequiredStatus(ann);
PropertyDescriptor pd = BeanUtils
.findPropertyForMethod(bridgedMethod, clazz);
currElements.add(new AutowiredMethodElement(method,
required, pd));
}
});
// 添加到需要返回的集合elements中
elements.addAll(0, currElements);
// 再遍历父类,依次循环
targetClass = targetClass.getSuperclass();
} while (targetClass != null && targetClass != Object.class);
// 封装成注入元数据类型
return new InjectionMetadata(clazz, elements);
}
} 可以看到这个类执行的操作只是获取该bean被@Autowired和@Value注解的字段和方法,然后使用InjectedElement和InjectionMetadata对象封装。
6.InjectionMetadata类
从上面的流程我们知道了会调用到这个类的inject方法中来,接下来我们看下其部分关键源码:
public class InjectionMetadata {
// 需要注入的bean class类型
private final Class targetClass;
// 该bean class需要注入的字段和方法集合
private final Collection injectedElements;
public void inject(Object target, @Nullable String beanName,
@Nullable PropertyValues pvs) throws Throwable {
Collection checkedElements = this.checkedElements;
Collection elementsToIterate =
(checkedElements != null ? checkedElements :
this.injectedElements);
// 如果需要注入的字段和方法集合迭代器不为空
if (!elementsToIterate.isEmpty()) {
// 依次循环调用元素的inject方法,
for (InjectedElement element : elementsToIterate) {
element.inject(target, beanName, pvs);
}
}
}
} 7.AutowiredFieldElement内部类
这个类是InjectionMetadata.InjectedElement内部类的子类实现,主要针对的是需要自动注入字段的执行,需要注意的是这个类也是AutowiredAnnotationBeanPostProcessor的内部类实现。接下来我们看其关键源码部分:
private class AutowiredFieldElement
extends InjectionMetadata.InjectedElement {
@Override
protected void inject(Object bean, @Nullable String beanName,
@Nullable PropertyValues pvs) throws Throwable {
Field field = (Field) this.member;
Object value;
// 先判断是否已经被缓存了
if (this.cached) {
// 如果缓存了就直接从bean工厂中获取或直接返回cachedFieldValue的值
value = resolvedCachedArgument(beanName, this.cachedFieldValue);
}
else {
// 没有缓存则将字段封装成DependencyDescriptor对象
DependencyDescriptor desc = new DependencyDescriptor(field,
this.required);
// 设置对应的bean类型
desc.setContainingClass(bean.getClass());
Set autowiredBeanNames = new LinkedHashSet<>(1);
TypeConverter typeConverter = beanFactory.getTypeConverter();
try {
// 直接调用bean工厂的resolveDependency方法解析这个bean涉及的
// 依赖bean,并且最终返回bean值
value = beanFactory.resolveDependency(desc, beanName,
autowiredBeanNames, typeConverter);
}
catch (BeansException ex) {
throw new UnsatisfiedDependencyException(null, beanName,
new InjectionPoint(field), ex);
}
synchronized (this) {
// 如果未缓存,则说明是第一次
if (!this.cached) {
// 如果返回的值不为空
if (value != null || this.required) {
this.cachedFieldValue = desc;
// 注册这个bean和自动注入值的依赖关系
registerDependentBeans(beanName, autowiredBeanNames);
if (autowiredBeanNames.size() == 1) {
// 如果返回值只有一个,则封装成对象类型
// ShortcutDependencyDescriptor缓存起来
String autowiredBeanName = autowiredBeanNames
.iterator().next();
// 从bean工厂中判断确实这个value返回值存在且类型正确
if (beanFactory.containsBean(autowiredBeanName) &&
beanFactory.isTypeMatch(autowiredBeanName,
field.getType())) {
// 缓存起来
this.cachedFieldValue =
new ShortcutDependencyDescriptor(
desc, autowiredBeanName, field.getType());
}
}
} else {
this.cachedFieldValue = null;
}
// 设置为缓存状态
this.cached = true;
}
}
}
if (value != null) {
ReflectionUtils.makeAccessible(field);
// 利用映射把获得的value值set到字段上
field.set(bean, value);
}
}
} 这个类的作用便是缓存且调用bean工厂获取需要注入的bean值,然后set到相应的字段或者方法上。
8.DefaultListableBeanFactory类处理@Autowired注解
我们可以先分析一下处理自动注入依赖的方法流程图:

直入主题,其关键部分源码如下:
public class DefaultListableBeanFactory
extends AbstractAutowireCapableBeanFactory
implements ConfigurableListableBeanFactory, BeanDefinitionRegistry,
Serializable {
@Override
@Nullable
public Object resolveDependency(DependencyDescriptor descriptor,
@Nullable String requestingBeanName,
@Nullable Set autowiredBeanNames,
@Nullable TypeConverter typeConverter) throws BeansException {
// 这个方法也是一个中间方法,前面两个判断不用管,只需要看到最后一个即可
descriptor.initParameterNameDiscovery(getParameterNameDiscoverer());
if (Optional.class == descriptor.getDependencyType()) {
return createOptionalDependency(descriptor, requestingBeanName);
} else if (ObjectFactory.class == descriptor.getDependencyType() ||
ObjectProvider.class == descriptor.getDependencyType()) {
return new DependencyObjectProvider(descriptor,
requestingBeanName);
}
else if (javaxInjectProviderClass == descriptor.getDependencyType()){
return new Jsr330Factory().createDependencyProvider(descriptor,
requestingBeanName);
} else {
// 正常流程直接看到这一步来即可,调用返回的result一般情况下为null
Object result = getAutowireCandidateResolver()
.getLazyResolutionProxyIfNecessary(
descriptor, requestingBeanName);
if (result == null) {
// 因此一般情况下会调用这个方法获取bean对象,这个方法也是需要重点
// 分析的
result = doResolveDependency(descriptor, requestingBeanName,
autowiredBeanNames, typeConverter);
}
return result;
}
}
@Nullable
public Object doResolveDependency(DependencyDescriptor descriptor,
@Nullable String beanName,
@Nullable Set autowiredBeanNames,
@Nullable TypeConverter typeConverter) throws BeansException {
// 像前面介绍的流程一样,将DependencyDescriptor对象转换为InjectionPoint
// 这个方法也很长,需要慢慢分析,大致可以分为六个部分
InjectionPoint previousInjectionPoint =
ConstructorResolver.setCurrentInjectionPoint(descriptor);
try {
// 一、如果是ShortcutDependencyDescriptor类型的则会直接调用getBean
// 方法,但是一般都是DependencyDescriptor类型,大部分情况可忽略
Object shortcut = descriptor.resolveShortcut(this);
if (shortcut != null) {
return shortcut;
}
// 二、从descriptor对象的注解中尝试获取值,只有当方法返回的类型是
// QualifierAnnotationAutowireCandidateResolver才会这样做,默认的
// 是ContextAnnotationAutowireCandidateResolver类型,此流程可忽略
Class type = descriptor.getDependencyType();
Object value = getAutowireCandidateResolver()
.getSuggestedValue(descriptor);
if (value != null) {
// 如果获得的值是String类型,则需要使用使用Expression语法获取值
if (value instanceof String) {
String strVal = resolveEmbeddedValue((String) value);
BeanDefinition bd = (beanName != null &&
containsBean(beanName) ?
getMergedBeanDefinition(beanName) : null);
// 实际会调用Expression语法获取值
value = evaluateBeanDefinitionString(strVal, bd);
}
TypeConverter converter = (typeConverter != null ?
typeConverter : getTypeConverter());
try {
// 对返回的值进行类型转换
return converter.convertIfNecessary(value, type,
descriptor.getTypeDescriptor());
} catch (UnsupportedOperationException ex) {
return (descriptor.getField() != null ?
converter.convertIfNecessary(value, type,
descriptor.getField()) :
converter.convertIfNecessary(value, type,
descriptor.getMethodParameter()));
}
}
// 三、解决自动注入的值为数组、Map集合或者Collection集合,如果是
// 数组则直接把bean工厂中这个类型的按照Comparator排序返回;如果是
// Collection集合且类型为接口则获取对应的bean对象且进行类型转换和
// 排序处理;如果是Map则直接key为beanName,value为这个类型的对象;
// 这几个类型descriptor对象将被封装成MultiElementDescriptor类型
// 这个类型后续将会调用bean工厂的getBean方法,获取集合需要的bean对象
// 这里实际会调用到findAutowireCandidates方法中,只是中间解析了上面
// 所说的三种集合类型,findAutowireCandidates这个方法等下分析
Object multipleBeans = resolveMultipleBeans(descriptor,
beanName, autowiredBeanNames, typeConverter);
if (multipleBeans != null) {
return multipleBeans;
}
// 四、直接调用findAutowireCandidates方法获取Map集合key为beanName
// Object为bean对象
Map matchingBeans =
findAutowireCandidates(beanName, type, descriptor);
if (matchingBeans.isEmpty()) {
// 如果为空且required为true,则检查beanDefinitionNames中
// 是否有该类型的bean,如果没有则抛出异常
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type,
descriptor.getResolvableType(), descriptor);
}
return null;
}
String autowiredBeanName;
Object instanceCandidate;
// 五、处理获取到的候选matchingBeans集合,分为单个和多个,数量为0
// 的情况以前面已经处理了
if (matchingBeans.size() > 1) {
// 如果候选有多个,则使用Comparator获取最高优先级的候选者
// 或者beanName一模一样的bean对象
autowiredBeanName = determineAutowireCandidate(matchingBeans,
descriptor);
if (autowiredBeanName == null) {
// 如果候选者为空且required为true,则检查并抛出异常
if (isRequired(descriptor) ||
!indicatesMultipleBeans(type)) {
return descriptor.resolveNotUnique(descriptor
.getResolvableType(), matchingBeans);
} else {
// required为false则直接返回null
return null;
}
}
// 获取候选者
instanceCandidate = matchingBeans.get(autowiredBeanName);
}
else {
// 仅有一个,直接获取第一个的key和值
Map.Entry entry =
matchingBeans.entrySet().iterator().next();
autowiredBeanName = entry.getKey();
instanceCandidate = entry.getValue();
}
// 六、对获取到的单个候选者进行处理
if (autowiredBeanNames != null) {
autowiredBeanNames.add(autowiredBeanName);
}
// 如果从候选者们获取到的的类型是class,则需要调用resolveCandidate
// 方法来通过class类型实例化bean,resolveCandidate方法会直接调用
// bean工厂的getBean方法;如果不是class类型,那一定是实例化好的
// bean对象
if (instanceCandidate instanceof Class) {
instanceCandidate = descriptor
.resolveCandidate(autowiredBeanName, type, this);
}
Object result = instanceCandidate;
// 进行required参数的判断,不满足抛异常
if (result instanceof NullBean) {
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type,
descriptor.getResolvableType(), descriptor);
}
result = null;
}
// 判断获取的类型和值是否一样,不一样则抛出异常
if (!ClassUtils.isAssignableValue(type, result)) {
throw new BeanNotOfRequiredTypeException(autowiredBeanName,
type, instanceCandidate.getClass());
}
return result;
}
finally {
ConstructorResolver.setCurrentInjectionPoint(
previousInjectionPoint);
}
}
protected Map findAutowireCandidates(
@Nullable String beanName, Class requiredType,
DependencyDescriptor descriptor) {
// 在获取到beanName和这个bean的class类型后将会调用这个方法来获取
// 这个class类型的一系列候选者,该方法一共可以分为三个部分
// 一、或者这个beanName的候选者名称
String[] candidateNames = BeanFactoryUtils
.beanNamesForTypeIncludingAncestors(
this, requiredType, true, descriptor.isEager());
Map result =
new LinkedHashMap<>(candidateNames.length);
// 一、判断resolvableDependencies集合中类型相同的对象
// 遍历判断已经解析过的依赖对象,如果类型相同或者是需要实例化的父类
// 则将其添加到result中
for (Map.Entry, Object> classObjectEntry :
this.resolvableDependencies.entrySet()) {
Class autowiringType = classObjectEntry.getKey();
if (autowiringType.isAssignableFrom(requiredType)) {
Object autowiringValue = classObjectEntry.getValue();
autowiringValue = AutowireUtils
.resolveAutowiringValue(autowiringValue, requiredType);
if (requiredType.isInstance(autowiringValue)) {
result.put(ObjectUtils.identityToString(autowiringValue),
autowiringValue);
break;
}
}
}
// 二、对前一步获取到的对象和候选者名称进行遍历处理,处理后的结果将会添加
// 到result中addCandidateEntry方法后面会分析
for (String candidate : candidateNames) {
if (!isSelfReference(beanName, candidate) &&
isAutowireCandidate(candidate, descriptor)) {
addCandidateEntry(result, candidate, descriptor,
requiredType);
}
}
// 三、如果需要返回的候选者结果集为空,正常情况下前面获取到的result为空
// 这个方法块中获取到的result也为空,但是其具体作用场景尚不清楚
// 因此暂时略过
if (result.isEmpty()) {
// 如果第一轮没有找到任何内容,考虑回退匹配对应的名称对象
boolean multiple = indicatesMultipleBeans(requiredType);
...
}
return result;
}
private void addCandidateEntry(Map candidates,
String candidateName,
DependencyDescriptor descriptor, Class requiredType) {
// 解决不同的descriptor对象
if (descriptor instanceof MultiElementDescriptor) {
// MultiElementDescriptor类型则直接调用bean工厂的getBean方法获取
// 处理化bean对象
Object beanInstance = descriptor.resolveCandidate(candidateName,
requiredType, this);
if (!(beanInstance instanceof NullBean)) {
candidates.put(candidateName, beanInstance);
}
} else if (containsSingleton(candidateName) ||
(descriptor instanceof StreamDependencyDescriptor &&
((StreamDependencyDescriptor) descriptor).isOrdered())) {
// 如果是单例或者是StreamDependencyDescriptor类型,也是调用
// bean工厂的getBean方法获取处理化bean对象,只是value可能为NullBean
Object beanInstance = descriptor.resolveCandidate(candidateName,
requiredType, this);
candidates.put(candidateName, (beanInstance instanceof NullBean ?
null : beanInstance));
} else {
// 无法识别处理的则将String名字编程对象的class对象,以方便后续流程
// 直接初始化class类型对应的bean对象
candidates.put(candidateName, getType(candidateName));
}
}
} 至此,两个流程的分析便已经结束了,要想了解其具体流程还是需要自己去走一遍源码,并且仔细分析一下各个方法的搭配和前后流程关系,否则不管看多少遍都是无用功。