一次接口时延优化与其中的思考
好玩的点
- 3.3 explain
- 3.5 对象大小
- 3.6.1 使用具体字段+覆盖索引
- 4 额外优化-TLAB
1. 背景
用户查询三个月内会议记录时,返回结果的平均时延高达三四秒。
1.1 优化目标
降低接口时延,响应时间要在200ms以内
优化有三个维度:分别是吞吐量、时延、系统容量。
- 吞吐量:指的是单位时间内系统能完成多少操作
- 时延:指的是操作的响应时间,比如说搜索商品的结果必须在200ms内展示给用户
- 系统容量:指的是在吞吐量和时延达标的情况下,对硬件环境的额外约束
1.2 涉及优化点
网络IO、SQL优化、对象大小、TLAB
1.3 涉及分析工具/命令
arthas、top、jstack、explain
1.4 调优步骤

我在分析的时候,喜欢先从系统层面去排查分析,比如从CPU、内存、网络、磁盘这几个维度上寻找,从而定位有问题的代码,自上而下。
1.5 压测数据准备
模拟线上用户最大的数据记录,三个月内一共有200条会议记录,每条会议记录平均有十个参会人
数据关系如下

2. 寻找接口瓶颈(循环HTTP请求)
2.1 top
压测时用top命令查看CPU的使用率

发现四核的机子,我们的应用占的CPU只有120%,不太合理,这时候可以用jstack命令看看Java进程里面的线程都在干嘛
2.2 jstack
我们可以用 top -Hp PID来显示进程内所有线程的情况,再把线程对应的PID转成十六进制,再用jstack命令查看该线程的工作情况,但是我觉得这样要一个一个地会比较麻烦
我比较喜欢直接用 jstack -l Java进程的PID > stack.txt,然后把文件拉下来分析。
只jstack一次可能是不准确的,jstack是打印线程快照,那么有可能在某一时刻打印出来的快照是正常的,所以应该多jstack几次来分析
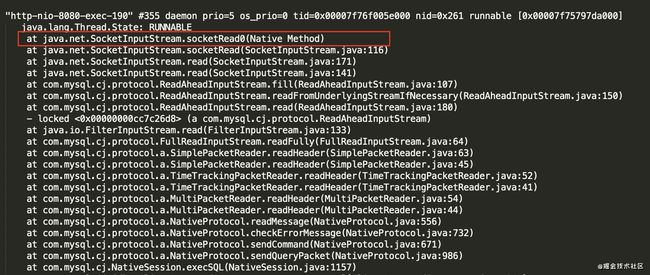
结果发现,有大量线程被阻塞在了java.net.SocketInputStream.socketRead0(Native Method)这上面,根据堆栈信息发现,是代码里面一个循环体里面进行了第三方的接口调用导致的
for (MeetingRecord meetingRecord : MeetingRecords) {
// 到其他应用获取某些信息,好家伙!!!
getVirtualRoomById(meetingRecord.getId());
}
当时就想看看这里的耗时有多久,就用arthas的trace命令看下
2.3 arthas
trace class-pattern method-pattern查看方法内部调用路径,并输出方法路径上的每个节点上耗时
![]()
这次请求的循环体里,耗时最小的一次调用为7ms,最大1069ms,一共22秒。

2.4 解决
知道原因就好办了,改成批量查询就好,再用arthas看看
![]()
好的,这个大头解决了。
不过时延还没达标,平均时延虽然降到了300ms,但是还没达标呢,只能继续优化
苦笑.png
3. 寻找系统瓶颈(SQL优化)
还是老样子,先用top命令看下CPU的使用率
3.1 top

好了,这时候看到CPU的使用率还挺正常的,继续用jstack命令分析
3.2 jstack
继续用jstack -l Java进程的PID > stack.txt分析,发现还是有挺多线程阻塞在java.net.SocketInputStream.socketRead0(Native Method)上,不过这次情况不一样,这些阻塞是由两条SQL引起的,我第一反应是不是慢查询,就赶紧把这两条SQL拿出来,用explain分析一下
3.3 explain
SQL1 : select * from meeting_record where staff_id = XXX and created_date between XXXX and XXXX,根据员工id和时间,范围检索会议记录
SQL 2: select * from meeting_member mm left join meeting m on mm.meeting_id = m.id where mm.meeting_id = XXXX,根据会议id,获取参会人(这里用了外键,所以SQL里面有left join)
3.3.1 SQL1分析
用explain去分析SQL1
select * from meeting_record where staff_id = XXX and created_date between XXXX and XXXX
+----+-------------+----------------+------------+------+-------------------------------+-------------------------------+---------+-------------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------------+------------+------+-------------------------------+-------------------------------+---------+-------------+------+----------+-----------------------+
| 1 | SIMPLE | meeting_record | NULL | ref | idx_staff_id_and_created_date | idx_staff_id_and_created_date | 22 | const,const | 1 | 100.00 | Using index condition |
+----+-------------+----------------+------------+------+-------------------------------+-------------------------------+---------+-------------+------+----------+-----------------------+
- type: ref,代表使用普通索引与某个值相比较,可能会找符合条件的多个数据行
- possible_type: 可能使用的索引
- key: idx_staff_id,表示用的是staff_id这个索引
- ref: const,表示与索引列匹配的值是一个常数
- Extra:
Using index condition,这里的索引是(staff_id,created_date),但是实际type的类型是ref,表示索引只是用了staff_id与某个值进行比较,没有用到created_date。 Extra为Using index condition表示将满足staff_id条件的索引项再用created_date去过滤,然后再回表获取所需要的字段
Using index condition: 索引下推,在5.6版本之后,筛选出索引记录后,再通过where中不满足索引检索的条件进行过滤,再回表查询。 这样的好处是省去很多回表操作,减少随机IO
3.3.2 SQL2分析
select * from meeting_member mm left join meeting m on mm.meeting_id = m.id where mm.meeting_id = XXXX
+----+-------------+-------+------------+--------+---------------+---------+---------+--------------------------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+---------+---------+--------------------------------------+------+----------+-------+
| 1 | SIMPLE | mm | NULL | ref | idx_mno | idx_mno | 131 | const | 1 | 100.00 | NULL |
| 1 | SIMPLE | m | NULL | eq_ref | PRIMARY | PRIMARY | 130 | mindlinker_meeting_dev.mm.meeting_no | 1 | 100.00 | NULL |
+----+-------------+-------+------------+--------+---------------+---------+---------+--------------------------------------+------+----------+-------+
这里没什么好讲的,唯一的问题是用了外键,老代码了,我也不知道当初为什么要用外键
分析下来,这两条SQL都不是慢查询,索引都用上了,看来不是这里的问题
3.4 jstat
既然SQL没问题,CPU利用率也合理,那么就看看内存吧
用jstat -gc PID 1000打印每秒GC的情况,发现的确很不对劲,一秒两三次YGC,十秒一次FGC

3.5 对象大小
结合上面的情况,我就猜是不是那两条SQL产生的对象是不是太大了,导致频繁YGC呢,算一算吧
- MarkWord: 8字节
- 类型指针: 4字节(开了类型指针压缩
-XX:+UseCompressedClassPointer) - 普通对象指针: 4字节(开了对象指针压缩
-XX:+UserCompressedOop) - 对齐填充:JVM是在内存里是以8个字节为单位进行读写的,所以当对象的大小不是8的整数倍时,需要填充
// MarkWord + 类型指针 + 属性大小 + 对齐填充
// 8 + 4 + 80 + 4 = 96 字节
public class MeetingRecord {
private long id; // 8字节
private String meetingNo; // 4字节
private String staffId; // 4字节
private Date createdDate; // 4字节
... // 把上面也加上一共80个字节
}
// MarkWord + 类型指针 + 属性大小 + 对齐填充
// 8 + 4 + 124 + 0 = 136 字节
public class Meeting {
private String id;
... // 一共124个字节
}
// MarkWord + 类型指针 + 属性大小 + 对齐填充
// 8 + 4 + 72 + 4 = 88 字节
public class MeetingMember {
private long id;
private String meetingNo;
... // 一共72个字节
}
按实体的关系,MeetingRecord : MeetingMember : Meeting = 1 : 10 : 1
但是这里有个问题,就是Meeting和MeetingMember用外键进行关联了,所以这个场景下的对象比例为
MeetingRecord : MeetingMember : Meeting = 1 : 10 : (1 + 10)
我是按200场会议,每场会议十个参会人来压测的,所以一个请求这两条SQL能产生的对象总大小约为
MeetingRecord * 200 + MeetingMember * 200 * 10 + Meeting * 200 * (10 + 1)
= 96 * 200 + 88 * 200 * 10 + 136 * 200 * 11
= 494400 B = 482 KB
好家伙,两条SQL给我整个482KB,优化SQL去。
指针压缩:由于Java对象的对齐填充机制,这就会导致Java对象的大小都会是8字节的整数倍。基于这种情况,JVM就将堆内存进行了块划分,以8字节为最小单位进行划分,类似操作系统的内存分页机制。因此
指针地址就可以不用存对象的真实的64位地址了,而是可以存一个映射地址编号
3.6 优化SQL
3.6.1 使用具体字段+覆盖索引
结合业务,其实MeetingRecord只需要获取Meeting的id即可
// 优化前
select * from meeting_record where staff_id = XXX and created_date between XXXX and XXXX
// 返回实际用到的值
select meeting_no from meeting_record where staff_id = XXX and created_date between XXXX and XXXX
由于这里只需要用到meeting_no这个字段,为了减少回表带来的随机IO,我们还可以利用覆盖索引来进行优化
// Extra为Using index condition
select meeting_no from meeting_record where staff_id = XXX and created_date between XXXX and XXXX
// 覆盖索引,把meeting_no增加到联合索引上
// 变成(staff_id,created_date,meeting_no)
select meeting_no from meeting_record where staff_id = XXX and created_date between XXXX and XXXX
再来用explain看看优化之后的情况
+----+-------------+----------------+------------+-------+------------------------------+------------------------------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------------+------------+-------+------------------------------+------------------------------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | meeting_record | NULL | range | idx_staff_created_meeting_no | idx_staff_created_meeting_no | 22 | NULL | 1 | 100.00 | Using where; Using index |
+----+-------------+----------------+------------+-------+------------------------------+------------------------------+---------+------+------+----------+--------------------------+
- type:
range表示索引使用了范围扫描 - Extra:
Using where; Using index表示先用staff_id进行检索,然后用where中的created_date进行索引的范围过滤,再获取meeting_no,因为索引上已经包含了meeting_no这个值,所以就不需要回表了
优化完毕
3.6.2 去除外键
// 优化前
select * from meeting_member mm left join meeting m on mm.meeting_id = m.id where mm.meeting_id = XXXX
// 去除外键
select * from meeting_member where meeting_no = XXX
// 返回具体的字段
select name,avatar,status... from meeting_member where meeting_no = XXX
3.7 优化后的情况
3.7.1 对象大小
MeetingRecord没了,因为只返回了MeetingRecord中的MeetingID
Meeting : MeetingMember = 1 : 10
Meeting * 200 + MeetingMember * 200 * 10
= 136 * 200 + 88 * 200 * 10
= 203200 B = 198 KB
比优化前要少个284 KB
3.7.2 GC情况

看上去正常多了,而且改到这里时,时延也达标了
4. 额外优化-TLAB
由于这个接口一次请求所产生的对象要占136KB以上的堆空间,就想到这些对象在Eden区分配的情况会是怎样的呢
因为Eden区是线程共享的,当多个线程一起在Eden区分配对象时,会出现线程安全的问题,因此需要加锁分配。为了提高分配效率,每个线程有自己的分配缓冲区(TLAB)来避免和减少使用锁,从而实现快速分配
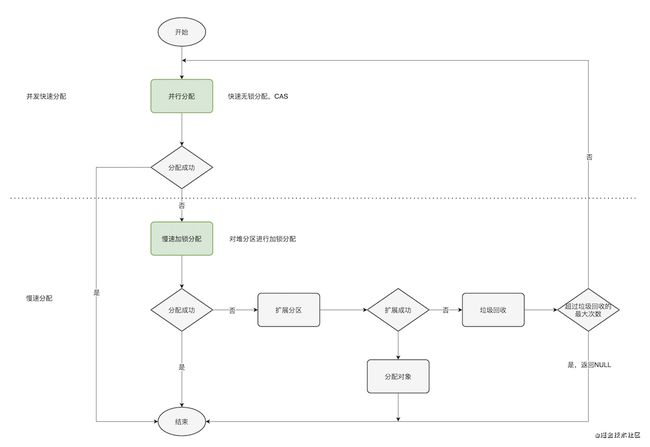
4.1 对象分配的流程

TLAB剩余空间的阈值这个可以通过TLABRefillWasteFraction来调整,默认为64,指的是TLAB中浪费空间和TLAB块的比例,也就是说100KB大小的TLAB会浪费 100 / 64 = 1.5KB。
这里我只关注绿色的部分,还有些地方没有画全,比如说分配新TLAB失败怎么办,慢速分配失败怎么办
4.2 TLAB的使用情况
用-XX:+PrintTLAB查看TLAB的使用情况

重点看这个
TLAB totals: thrds: 189 refills: 8959 max: 199 slow allocs: 676 max 34 waste: 1.1% gc: 3474216B max: 58648B slow: 2512B max: 344B fast: 282288B max: 5560B
- thrds: 总共有多少条线程使用了TLAB(189条线程)
- refills: 上次GC到这次GC期间,分配新的TLAB的次数(8959次)
- max: 单个线程中,分配新的TLAB的最大次数(199次)
- slow allocs: 所有线程的对象慢速分配的次数(676次)
- max: 单个线程中,对象慢速分配的最大次数(34次)
- waste: 所有线程中TLAB的内存浪费比例(1.1%)
- gc: 发生GC时,所有线程还没使用的TLAB空间
- slow: 产生新的TLAB时,旧的TLAB浪费的空间
- fast: 指在C1中,产生新的TLAB时,旧的TLAB浪费的空间
可以看到,从上一次GC到这次GC其间,重新分配了TLAB的次数达到了9000次,慢分配也有个676次。
4.3 申请TLAB和对象慢速分配的流程
因为申请新的TLAB和对象慢速分配,都需要在Eden区上操作,这时候就要考虑并发的问题了。
申请TLAB分区和对象慢分配流程图:
4.4 优化TLAB
4.4.1 优化前的TLAB情况
我压测的机器跟线上的机器配置差不多,都是2GB的内存,堆空间为1280MB,根据默认的JVM配置,年轻代的大小就是426MB,Eden区就是340MB
TLAB的总大小默认占Eden区的1%,也就是所有TLAB加起来为的空间为3481KB,按上面的线程来看,平均每条线程能分得的TLAB大小为18KB,比我之前算的两条SQL产生的对象大小还小。
4.4.2 调整TLAB大小
假设每条线程能获得200KB的TLAB,那么200条线程就是39MB,也就是说TLAB总大小要占Eden区的8%左右
那么就可以设置JVM参数-XX:TLABWasteTargetPercent=8来调整
看看效果

TLAB totals: thrds: 121 refills: 500 max: 11 slow allocs: 5 max 1 waste: 12.2% gc: 43304504B max: 8907064B slow: 16000B max: 15536B fast: 356856B max: 54400B
好多了,refills从9000降到了500,慢速分配从670次降到了5次,不过waste从1.1%上升到了12.2%
因为不是所有线程的TLAB都需要200KB这么大,所以某些线程的TLAB在上一次GC到这次GC其间,可能只用了几十KB,导致GC时TLAB剩下的空间都浪费了。所以waste的值也相应地上去了。所以调整这个
TLABWasteTargetPercent这个值需要折中,虽然分配效率提升了,但是相应地内存碎片、空间浪费的问题也更明显了
5. 额外补充
- 垃圾收集器
我选用的是CMS,因为CMS是一种以获取最短回收停顿时间为目标的收集器,符合我优化的目标。 那为毛不选G1呢? 主要是因为内存太小了,G1官方推荐使用的内存大小是6GB,而我只有2GB,如果使用G1的话,分区会很小,从而导致分配效率低下
- 业务逻辑优化
其实业务层还有很多地方优化,比如用limit来实现分页,防止一次查询过多的数据。不过这些改动需要客户端配合,就暂时没动
- 为什么不用缓存
主要是因为这部分逻辑都是旧代码,没有单元测试保证,不敢乱来,加上时间方面以及影响范围等各方面的考虑,决定采用最小改动
好了,完结撒花
参考
- GC参考手册-Java版
- 深入理解Java虚拟机
- JVM G1源码分析和调优