一、基本图示

二、基本介绍
public class HashMap
extends AbstractMap
implements Map, Cloneable, Serializable
结构
- HashMap 继承了 AbstractMap 类
- HashMap 实现了 Map 接口
- HashMap 实现了 Cloneable 类,覆盖了 clone 方法,可以被克隆
- 实现了 Serializable 接口,支持序列化
特性
- 底层是使用了拉链法的散列表,Entry
- 元素是无序的,即遍历得到元素的顺序和放进去的元素的顺序不同
- 是线程不安全的
- key 和 value 都允许为 null
- 1 个 key 只能对应 1 个 value,1 个 value 对应多个 key
三、基本参数
// 初始容量为 16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 初始加载因子为 0.75f
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 空的哈希表
static final Entry[] EMPTY_TABLE = {};
// 实际使用的哈希表
transient Entry[] table = (Entry[]) EMPTY_TABLE;
// 阀值,用来规定什么时候扩容,阀值=当前数组长度 * 负载因子
int threshold;
HashMap 使用以 Entry 为单位的单向链表存储数据,用来存储 key,value,hash 和 下一个 Entry 的指向
static class Entry implements Map.Entry {
final K key;
V value;
Entry next;
int hash;
Entry(int h, K k, V v, Entry n) {
value = v;
next = n;
key = k;
hash = h;
}
...
}
四、构造函数
// 如果没有传入任何参数,则初始容量为 16,默认负载因子为 0.75f
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
// 一个参数的构造函数,用户可以自己设置初始容量
public HashMap(int initialCapacity) {
// 调用具有两个参数的构造函数,此时还是传入默认负载因子
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 用户可以自己设定初始变量和负载因子
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// 设置加载因子
this.loadFactor = loadFactor;
// 阀值设置为传入的容量
threshold = initialCapacity;
init();
}
五、添加方法
public V put(K key, V value) {
// 1.如果哈希表一开始是空的
if (table == EMPTY_TABLE) {
// 为哈希表分配存储空间,默认传入的 threshold 为 16
inflateTable(threshold);
}
// 2.如果传入的键为 null,则直接返回
if (key == null)
return putForNullKey(value);
// 3.如果传入的键不为 null,则根据传入的 key 值计算 hash 值
int hash = hash(key);
// 4.根据 hash 值和当前数组的长度计算在数组中的索引
int i = indexFor(hash, table.length);
// 5.如果这个这个索引所在的位置已经有元素了,就以这个索引的链表头为起点开始遍历以这个位置为头节点的链表
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
// 如果对应的键、值都相等
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
// oldValue 保存旧的值
V oldValue = e.value;
// 将新的值赋给旧的值
e.value = value;
e.recordAccess(this);
// 返回旧的值
return oldValue;
}
}
modCount++;
// 6.如果没有对应的 key 就添加 Entry 到 HashMap 中
addEntry(hash, key, value, i);
return null;
}
①. 首先判断哈希表是否为空,如果为空,则调用 inflateTable 函数对哈希表进行初始化。如果传入的值可能不是 2 的幂次方,则需要转化成 ≥ 初始值的最小的 2 次幂,然后对哈希表进行初始化。经过 inflateTable 方法之后的哈希表的长度都是 2 的幂,即 2^n
对于 roudUpPowerOf2 方法,如果传入的 toSize=10,则 capacity = 16,toSize = 16,capacity = 16,toSize = 17,capacity = 32...
private void inflateTable(int toSize) {
// 通过roundUpToPowerOf2(toSize)可以确保capacity为大于或等于toSize的最接近toSize的二次幂
int capacity = roundUpToPowerOf2(toSize);
// 这里设置阀值 = capacity * loadFactor
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
// 初始化哈希表,容量就是 capacity
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
②. 如果传入的 key 为 null,则返回 putForNullKey 方法,该方法会将 key 为 null 对应的元素永远放在 table[0] 位置,无论有没有发生哈希碰撞。如果 table[0] 所在的单链表已经有 key 为 null 的元素了,则新插入的会替换旧的 key 为 null 的元素
// 将 key 为 null 的键值对传入 table[0]
private V putForNullKey(V value) {
// 遍历 table[0] 的单链表
for (Entry e = table[0]; e != null; e = e.next) {
// 如果 table[0] 上已经有 key 为 null 的元素,则进行替换
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 如果 table[0] 上没有 key 为 null 的值
addEntry(0, null, value, 0);
return null;
}
通过一个图片可以更加直观的看到整个过程,第一次因为 table[0] 没有 key 为 null 的元素,就会插入到头部,第二次因为 table[0] 已经有 key 为 null 的元素了,便会直接覆盖
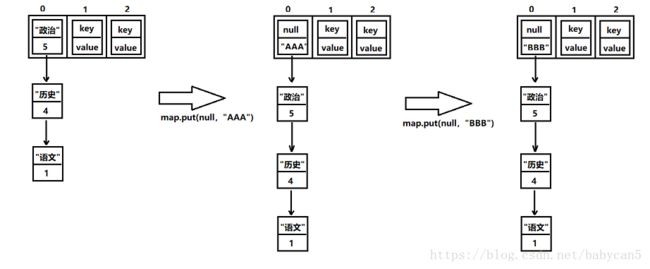
PS:在 hashmap 扩容之前的情况,此时 key 为 null 的 Entry 会一直在 table[0] 的第一个位置;而在扩容之后,可能会链表逆置,就不是上面那种情况了,但是,一定还是在 table[0] 的位置,只是不一定是第一个
③. 如果哈希表既不为空,key 也不为 null,则调用 hash 方法计算传入的 key 的 hash 值
inal int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
④. 根据计算出来的 hash 值和当前哈希表的长度来计算当前 key 在哈希表中的位置 i,此时哈希表的长度 length 都是 2 的幂
static int indexFor(int h, int length) {
return h & (length-1);
}
⑤. 遍历以 table[i] 为头节点的单链表,如果传入的值的 hash 值和 key 值和链表里面已经存在的值的 hash 值和 key 值相等,则用新的 Entry 的 value 覆盖原来节点的 value
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
// 如果对应的键、值都相等
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
// oldValue 保存旧的值
V oldValue = e.value;
// 将新的值赋给旧的值
e.value = value;
e.recordAccess(this);
// 返回旧的值
return oldValue;
}
}
⑥. 接下来便会调用 addEntry 方法,扩容和创建键值对的方法都和它有关,如果遇到下面这两种情况,则会来调用这个方法
- 哈希表的位置 i 没有元素
- 哈希表的位置 i 存在元素,但是要添加的元素的 hash 值或者 key 值与位置 i 的链表中的元素的这两个数值不等
该方法会先根据阀值大小判断是否需要进行扩容,如果需要则先扩容,扩容的时候还需要重新移动元素。等这一切都做完后,重复之前的步骤
- 计算要添加的元素的 hash 值
- 计算要添加的元素在新数组中的位置
void addEntry(int hash, K key, V value, int bucketIndex) {
// 如果键值对的数量大于等于阀值并且哈希表中对应的位置不为 null
if ((size >= threshold) && (null != table[bucketIndex])) {
// 将哈希表扩容为原来的 2 倍
resize(2 * table.length);
// 判断传入的 key 是否为空,不为空则再次调用 hash 方法计算 hash 值
hash = (null != key) ? hash(key) : 0;
// 根据新表的长度重新计算所放的位置
bucketIndex = indexFor(hash, table.length);
}
// 无论是否需要扩容,都需要创建新的节点,添加到指定位置
createEntry(hash, key, value, bucketIndex);
}
数组扩容的方法,其实就是创建一个新的 Entry 数组,用新的容量初始化,然后重新计算元素在 Entry 数组中的位置,即 hash 值
void resize(int newCapacity) {
// 获取旧的 table 数组
Entry[] oldTable = table;
// 获取旧的数组的长度
int oldCapacity = oldTable.length;
// 极端情况,如果旧的长度已经是最大容量
if (oldCapacity == MAXIMUM_CAPACITY) {
// 直接等于最大容量
threshold = Integer.MAX_VALUE;
return;
}
// 1.初始化一个新的 Entry 数组,传入的参数是旧的数组的两倍
Entry[] newTable = new Entry[newCapacity];
// 2.将键值对转移到新的 Entry 数组
transfer(newTable, initHashSeedAsNeeded(newCapacity));
// 3.将新的数组赋值给旧的数组
table = newTable;
// 4.重新计算阀值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
其中最关键的就是转移元素的方法 transfer,其实移动的时候也是考虑两种情况
- 所在的 table[i] 至少是长度 ≥ 2 的单链表,此时如果转移后依然还在同一个位置,则需要将以前的链表逆置
- 所在的 table[i] 只有一个元素,则直接根据新的位置转移到新的数组
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
// 遍历哈希表 table
for (Entry e : table) {
while(null != e) {
// next 用来保存头节点的下一个节点
Entry next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
// 计算在元素在新的哈希表中的位置
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
通过画图可以更加清楚的看到整个元素转移的过程,当然,这只是最极端的一种情况,即原来单链表上的元素转移到新的数组,依然还是同一个单链表。可以看到,经过转移之后,会将原来单链表的元素进行逆置,即和原来的顺序是完全相反的

扩容完了之后,需要创建节点并且添加到哈希表中去。需要分两种情况
- 如果没有发生哈希碰撞,则直接添加到对应的数组中,此时该位置只要这一个元素
- 如果发生哈希碰撞,则需要添加到对应元素的前面
// 创建 Entry 键值对,该键值对包括 key,value 已经指向的位置 next
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
Entry(int h, K k, V v, Entry n) {
value = v;
// 初始化 next 的指向
next = n;
key = k;
hash = h;
}
照样看个图,如果发生哈希碰撞,则新元素传到之前元素的前面。这里因为 Entry 的构造函数的最后一个参数就是指向下一个节点的引用 next,而传入的 e 就是当前已经存在的节点,因此新传入节点的 next 就是当前的 e

六、删除方法
删除元素也是根据 key 值来找到对应位置,然后遍历和判断进行删除的
public V remove(Object key) {
Entry e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
// 根据 key 值找到要删除的 Entry 键值对
final Entry removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
// 1.根据 key 得到对应的 hash 值
int hash = (key == null) ? 0 : hash(key);
// 2.根据 hash 值和数组长度获得在数组中的位置 i
int i = indexFor(hash, table.length);
// 3.
Entry prev = table[i];
Entry e = prev;
while (e != null) {
Entry next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
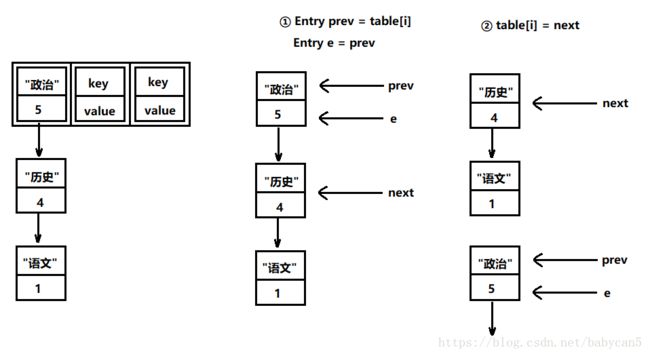
删除元素需要考虑两种情况,即该元素在链表第一个,还是在第一个元素后面的位置
1.
如果是第一个位置,则 prev 和 e 同时指向一个 Entry 键值对,然后会直接跳过第一个元素,直接指向第 2 个元素,用一个图示来看一下
2.
如果是 ≥1 的位置,e 指向要删除的元素,prev 指向 e 的前一个元素,next 指向 e 的后一个元素,最后 prev 跳过 e 直接指向 next 引用。用一个图示来看一下

七、获取方法
HashMap 的 get 方法是根据 key 值来获取 value,需要考虑两种情况
- 获取的 key 为 null
- 获取的 key 不为 null
// 根据 key 值获取 value 的方法
public V get(Object key) {
// 如果传入的 key 值为 null
if (key == null)
// 则有特殊的获取方法
return getForNullKey();
// 如果 key 值不为 null,先得到该键值对
Entry entry = getEntry(key);
// 如果没有找到对应键值对,返回 null,否则返回 key 对应的 value
return null == entry ? null : entry.getValue();
}
如果获取的 key 为 null,则直接遍历 table[0] 的键值对
// 获取 key 为 null 的方法
private V getForNullKey() {
if (size == 0) {
return null;
}
// 因为 key 为 null 的键值对只可能在 table[0],直接遍历 table[0]
for (Entry e = table[0]; e != null; e = e.next) {
// 只要遍历到 key 为 null 的键值对,就返回这个键值对的 value
if (e.key == null)
return e.value;
}
return null;
}
如果 key 值不为 null,先得到对应的键值对 Entry
final Entry getEntry(Object key) {
if (size == 0) {
return null;
}
// 获取传入 key 的 hash 值
int hash = (key == null) ? 0 : hash(key);
// 根据 hash 值和当前哈希数组的长度计算键值对在数组中的位置
// 遍历该位置对应的链表
for (Entry e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
// 如果 hash 值和 key 值都相等,返回该键值对 e
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
// 没有则返回 null
return null;
}
八、参考
https://mp.weixin.qq.com/s/2paXbnkZBPNs-LwZuDzm5g
http://www.cnblogs.com/skywang12345/p/3310835.html#h4
https://blog.csdn.net/u011240877/article/details/53351188#6hashmap-%E7%9A%84%E8%8E%B7%E5%8F%96%E6%96%B9%E6%B3%95-get
https://blog.csdn.net/fan2012huan/article/details/51088211#comments
https://blog.csdn.net/ghsau/article/details/16843543